266 lines
15 KiB
Markdown
266 lines
15 KiB
Markdown
# 12 | 多线程之锁优化(上):深入了解Synchronized同步锁的优化方法
|
||
|
||
你好,我是刘超。从这讲开始,我们就正式进入到第三模块——多线程性能调优。
|
||
|
||
**在并发编程中,多个线程访问同一个共享资源时,我们必须考虑如何维护数据的原子性。**在JDK1.5之前,Java是依靠Synchronized关键字实现锁功能来做到这点的。Synchronized是JVM实现的一种内置锁,锁的获取和释放是由JVM隐式实现。
|
||
|
||
到了JDK1.5版本,并发包中新增了Lock接口来实现锁功能,它提供了与Synchronized关键字类似的同步功能,只是在使用时需要显式获取和释放锁。
|
||
|
||
Lock同步锁是基于Java实现的,而Synchronized是基于底层操作系统的Mutex Lock实现的,每次获取和释放锁操作都会带来用户态和内核态的切换,从而增加系统性能开销。因此,在锁竞争激烈的情况下,Synchronized同步锁在性能上就表现得非常糟糕,它也常被大家称为重量级锁。
|
||
|
||
特别是在单个线程重复申请锁的情况下,JDK1.5版本的Synchronized锁性能要比Lock的性能差很多。例如,在Dubbo基于Netty实现的通信中,消费端向服务端通信之后,由于接收返回消息是异步,所以需要一个线程轮询监听返回信息。而在接收消息时,就需要用到锁来确保request session的原子性。如果我们这里使用Synchronized同步锁,那么每当同一个线程请求锁资源时,都会发生一次用户态和内核态的切换。
|
||
|
||
到了JDK1.6版本之后,Java对Synchronized同步锁做了充分的优化,甚至在某些场景下,它的性能已经超越了Lock同步锁。这一讲我们就来看看Synchronized同步锁究竟是通过了哪些优化,实现了性能地提升。
|
||
|
||
## Synchronized同步锁实现原理
|
||
|
||
了解Synchronized同步锁优化之前,我们先来看看它的底层实现原理,这样可以帮助我们更好地理解后面的内容。
|
||
|
||
**通常Synchronized实现同步锁的方式有两种,一种是修饰方法,一种是修饰方法块。**以下就是通过Synchronized实现的两种同步方法加锁的方式:
|
||
|
||
```
|
||
// 关键字在实例方法上,锁为当前实例
|
||
public synchronized void method1() {
|
||
// code
|
||
}
|
||
|
||
// 关键字在代码块上,锁为括号里面的对象
|
||
public void method2() {
|
||
Object o = new Object();
|
||
synchronized (o) {
|
||
// code
|
||
}
|
||
}
|
||
|
||
```
|
||
|
||
下面我们可以通过反编译看下具体字节码的实现,运行以下反编译命令,就可以输出我们想要的字节码:
|
||
|
||
```
|
||
javac -encoding UTF-8 SyncTest.java //先运行编译class文件命令
|
||
|
||
```
|
||
|
||
```
|
||
javap -v SyncTest.class //再通过javap打印出字节文件
|
||
|
||
```
|
||
|
||
通过输出的字节码,你会发现:Synchronized在修饰同步代码块时,是由 monitorenter和monitorexit指令来实现同步的。进入monitorenter 指令后,线程将持有Monitor对象,退出monitorenter指令后,线程将释放该Monitor对象。
|
||
|
||
```
|
||
public void method2();
|
||
descriptor: ()V
|
||
flags: ACC_PUBLIC
|
||
Code:
|
||
stack=2, locals=4, args_size=1
|
||
0: new #2
|
||
3: dup
|
||
4: invokespecial #1
|
||
7: astore_1
|
||
8: aload_1
|
||
9: dup
|
||
10: astore_2
|
||
11: monitorenter //monitorenter 指令
|
||
12: aload_2
|
||
13: monitorexit //monitorexit 指令
|
||
14: goto 22
|
||
17: astore_3
|
||
18: aload_2
|
||
19: monitorexit
|
||
20: aload_3
|
||
21: athrow
|
||
22: return
|
||
Exception table:
|
||
from to target type
|
||
12 14 17 any
|
||
17 20 17 any
|
||
LineNumberTable:
|
||
line 18: 0
|
||
line 19: 8
|
||
line 21: 12
|
||
line 22: 22
|
||
StackMapTable: number_of_entries = 2
|
||
frame_type = 255 /* full_frame */
|
||
offset_delta = 17
|
||
locals = [ class com/demo/io/SyncTest, class java/lang/Object, class java/lang/Object ]
|
||
stack = [ class java/lang/Throwable ]
|
||
frame_type = 250 /* chop */
|
||
offset_delta = 4
|
||
|
||
```
|
||
|
||
再来看以下同步方法的字节码,你会发现:当Synchronized修饰同步方法时,并没有发现monitorenter和monitorexit指令,而是出现了一个ACC\_SYNCHRONIZED标志。
|
||
|
||
这是因为JVM使用了ACC\_SYNCHRONIZED访问标志来区分一个方法是否是同步方法。当方法调用时,调用指令将会检查该方法是否被设置ACC\_SYNCHRONIZED访问标志。如果设置了该标志,执行线程将先持有Monitor对象,然后再执行方法。在该方法运行期间,其它线程将无法获取到该Mointor对象,当方法执行完成后,再释放该Monitor对象。
|
||
|
||
```
|
||
public synchronized void method1();
|
||
descriptor: ()V
|
||
flags: ACC_PUBLIC, ACC_SYNCHRONIZED // ACC_SYNCHRONIZED 标志
|
||
Code:
|
||
stack=0, locals=1, args_size=1
|
||
0: return
|
||
LineNumberTable:
|
||
line 8: 0
|
||
|
||
|
||
```
|
||
|
||
通过以上的源码,我们再来看看Synchronized修饰方法是怎么实现锁原理的。
|
||
|
||
JVM中的同步是基于进入和退出管程(Monitor)对象实现的。每个对象实例都会有一个Monitor,Monitor可以和对象一起创建、销毁。Monitor是由ObjectMonitor实现,而ObjectMonitor是由C++的ObjectMonitor.hpp文件实现,如下所示:
|
||
|
||
```
|
||
ObjectMonitor() {
|
||
_header = NULL;
|
||
_count = 0; //记录个数
|
||
_waiters = 0,
|
||
_recursions = 0;
|
||
_object = NULL;
|
||
_owner = NULL;
|
||
_WaitSet = NULL; //处于wait状态的线程,会被加入到_WaitSet
|
||
_WaitSetLock = 0 ;
|
||
_Responsible = NULL ;
|
||
_succ = NULL ;
|
||
_cxq = NULL ;
|
||
FreeNext = NULL ;
|
||
_EntryList = NULL ; //处于等待锁block状态的线程,会被加入到该列表
|
||
_SpinFreq = 0 ;
|
||
_SpinClock = 0 ;
|
||
OwnerIsThread = 0 ;
|
||
}
|
||
|
||
```
|
||
|
||
当多个线程同时访问一段同步代码时,多个线程会先被存放在ContentionList和\_EntryList 集合中,处于block状态的线程,都会被加入到该列表。接下来当线程获取到对象的Monitor时,Monitor是依靠底层操作系统的Mutex Lock来实现互斥的,线程申请Mutex成功,则持有该Mutex,其它线程将无法获取到该Mutex,竞争失败的线程会再次进入ContentionList被挂起。
|
||
|
||
如果线程调用wait() 方法,就会释放当前持有的Mutex,并且该线程会进入WaitSet集合中,等待下一次被唤醒。如果当前线程顺利执行完方法,也将释放Mutex。
|
||
|
||
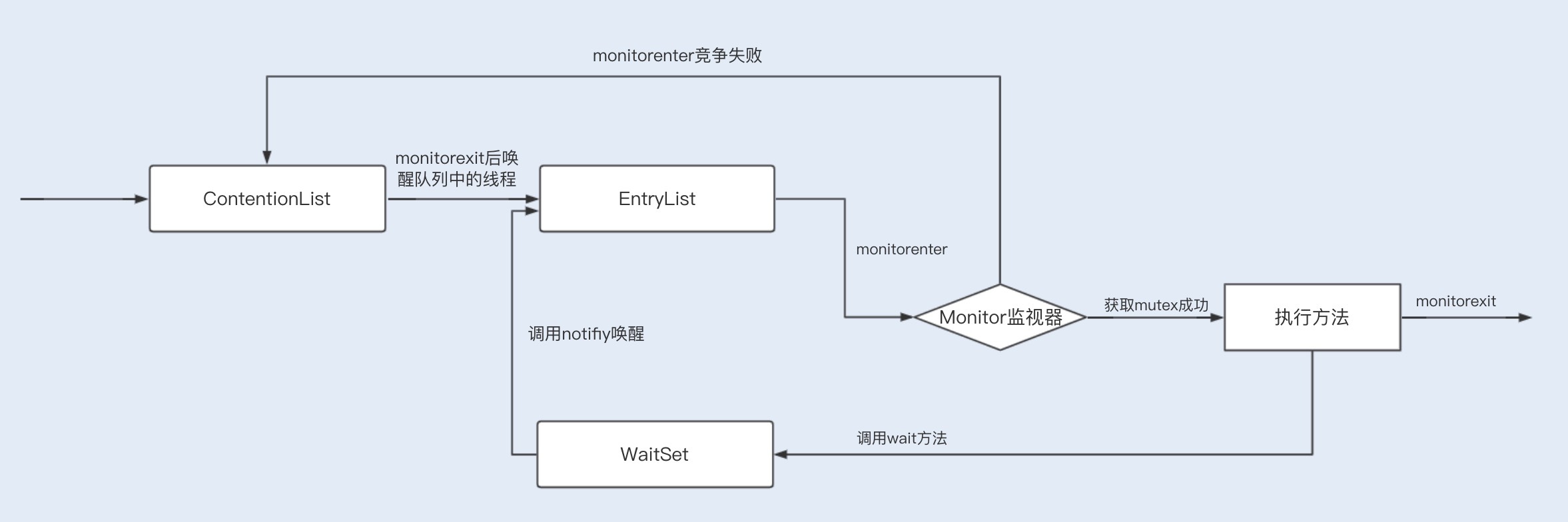
|
||
|
||
看完上面的讲解,相信你对同步锁的实现原理已经有个深入的了解了。总结来说就是,同步锁在这种实现方式中,因Monitor是依赖于底层的操作系统实现,存在用户态与内核态之间的切换,所以增加了性能开销。
|
||
|
||
## 锁升级优化
|
||
|
||
为了提升性能,JDK1.6引入了偏向锁、轻量级锁、重量级锁概念,来减少锁竞争带来的上下文切换,而正是新增的Java对象头实现了锁升级功能。
|
||
|
||
当Java对象被Synchronized关键字修饰成为同步锁后,围绕这个锁的一系列升级操作都将和Java对象头有关。
|
||
|
||
### Java对象头
|
||
|
||
在JDK1.6 JVM中,对象实例在堆内存中被分为了三个部分:对象头、实例数据和对齐填充。其中Java对象头由Mark Word、指向类的指针以及数组长度三部分组成。
|
||
|
||
Mark Word记录了对象和锁有关的信息。Mark Word在64位JVM中的长度是64bit,我们可以一起看下64位JVM的存储结构是怎么样的。如下图所示:
|
||
|
||
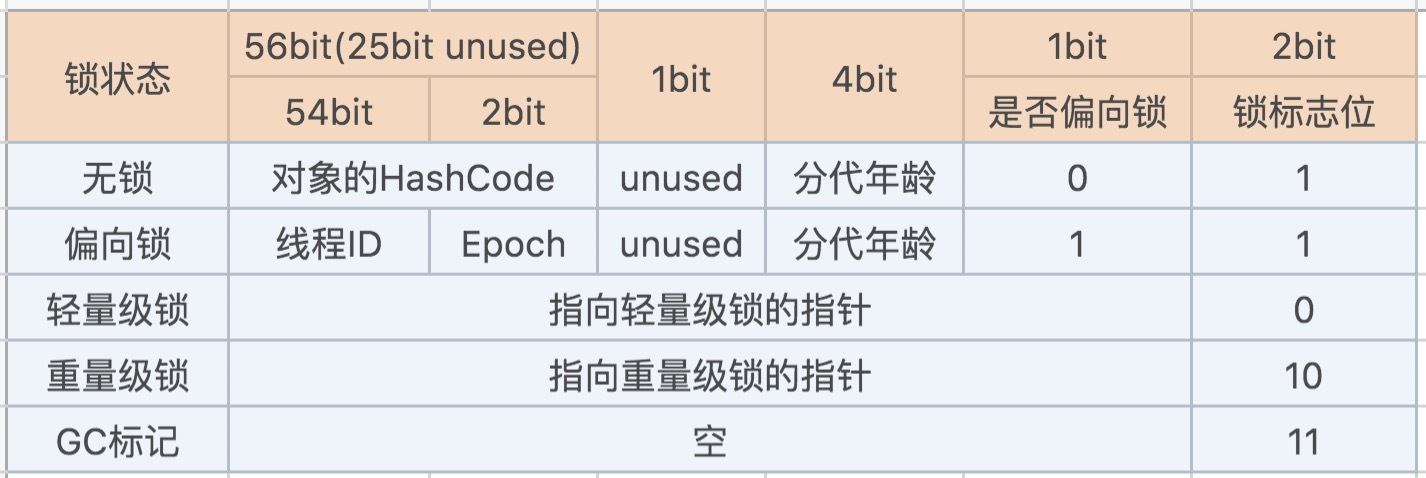
|
||
|
||
锁升级功能主要依赖于Mark Word中的锁标志位和释放偏向锁标志位,Synchronized同步锁就是从偏向锁开始的,随着竞争越来越激烈,偏向锁升级到轻量级锁,最终升级到重量级锁。下面我们就沿着这条优化路径去看下具体的内容。
|
||
|
||
### 1.偏向锁
|
||
|
||
偏向锁主要用来优化同一线程多次申请同一个锁的竞争。在某些情况下,大部分时间是同一个线程竞争锁资源,例如,在创建一个线程并在线程中执行循环监听的场景下,或单线程操作一个线程安全集合时,同一线程每次都需要获取和释放锁,每次操作都会发生用户态与内核态的切换。
|
||
|
||
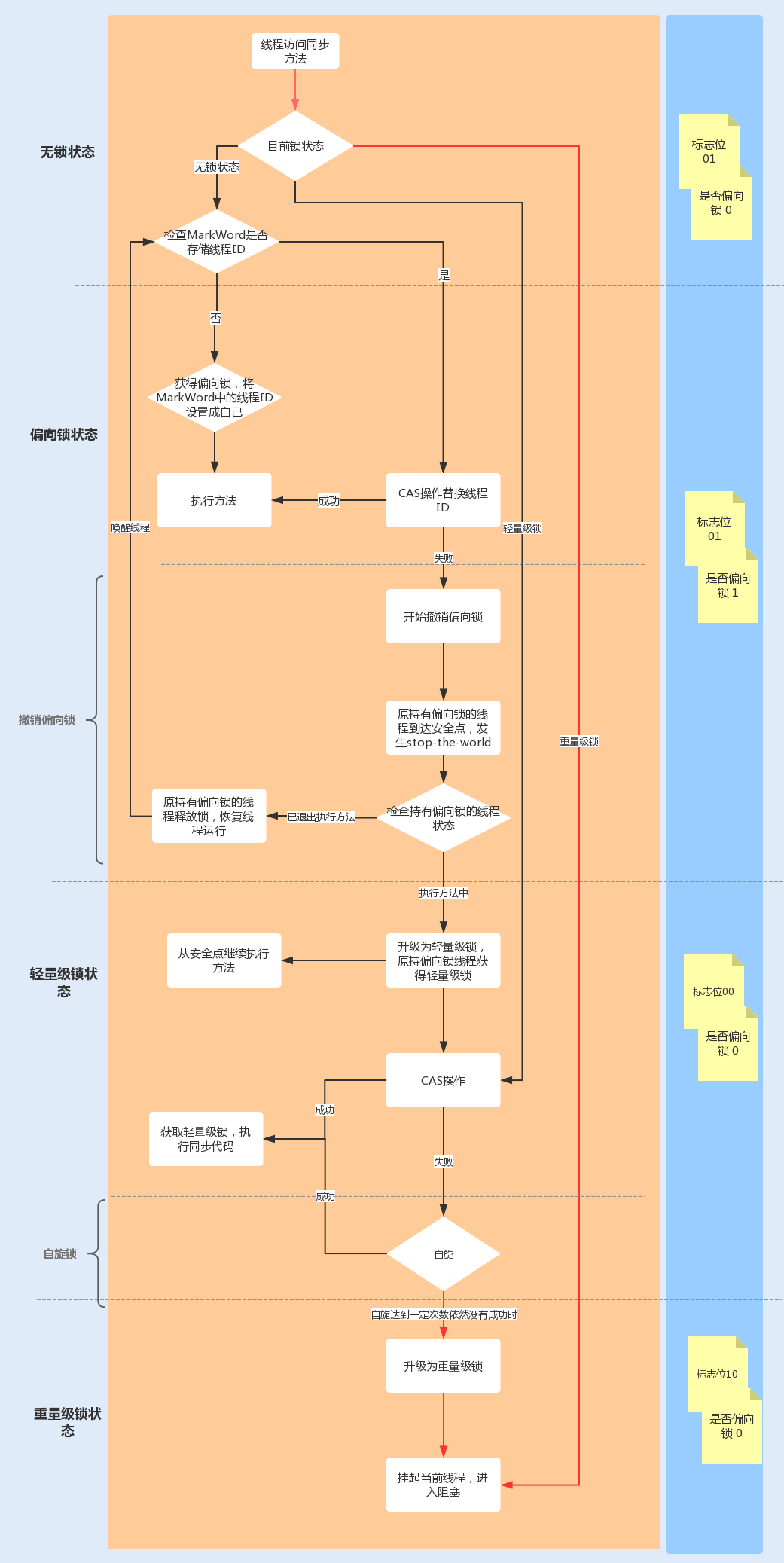
偏向锁的作用就是,当一个线程再次访问这个同步代码或方法时,该线程只需去对象头的Mark Word中去判断一下是否有偏向锁指向它的ID,无需再进入Monitor去竞争对象了。**当对象被当做同步锁并有一个线程抢到了锁时,锁标志位还是01,“是否偏向锁”标志位设置为1,并且记录抢到锁的线程ID,表示进入偏向锁状态。**
|
||
|
||
一旦出现其它线程竞争锁资源时,偏向锁就会被撤销。偏向锁的撤销需要等待全局安全点,暂停持有该锁的线程,同时检查该线程是否还在执行该方法,如果是,则升级锁,反之则被其它线程抢占。
|
||
|
||
**下图中红线流程部分为偏向锁获取和撤销流程:**
|
||
|
||
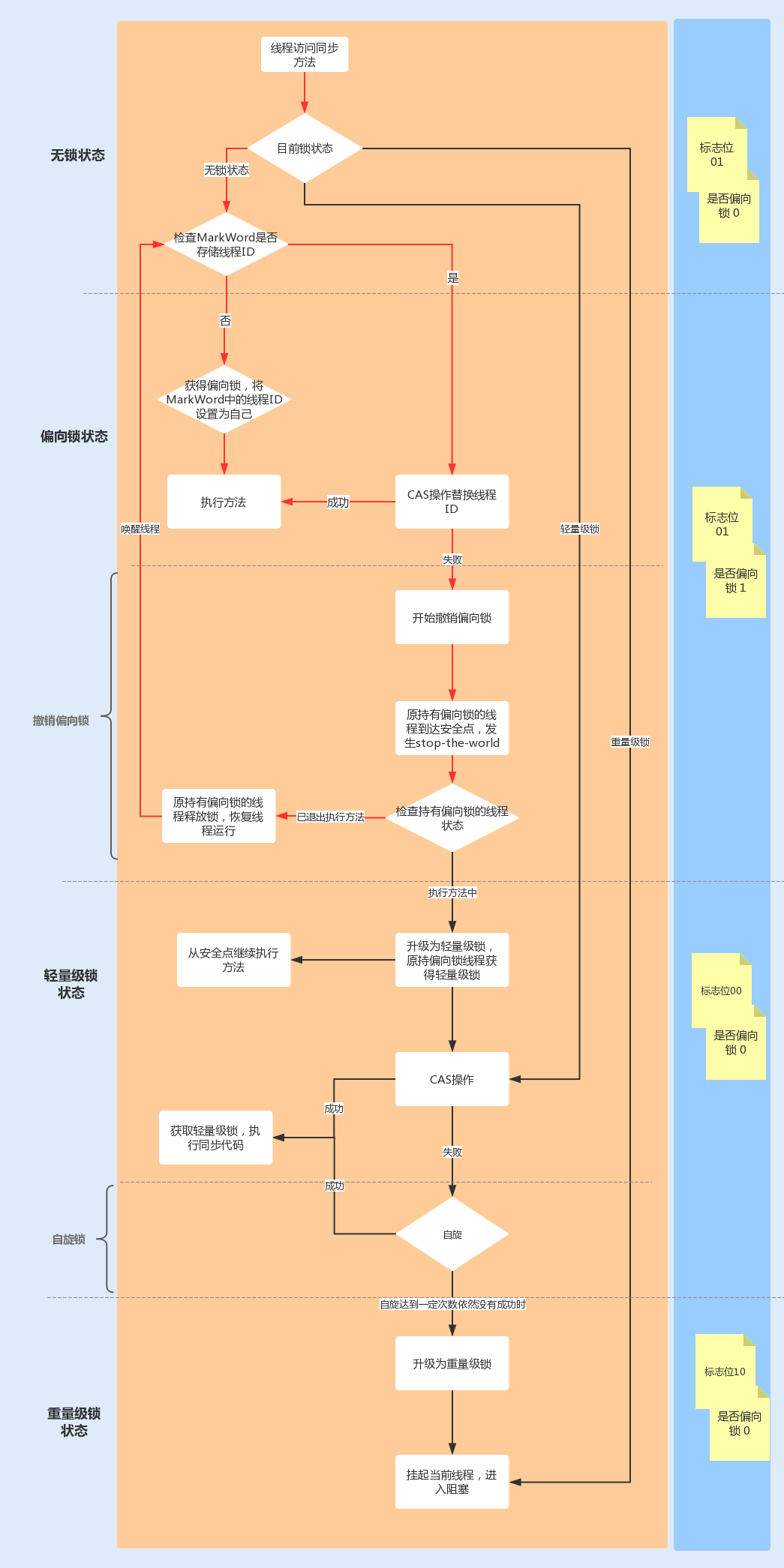
|
||
|
||
因此,在高并发场景下,当大量线程同时竞争同一个锁资源时,偏向锁就会被撤销,发生stop the word后, 开启偏向锁无疑会带来更大的性能开销,这时我们可以通过添加JVM参数关闭偏向锁来调优系统性能,示例代码如下:
|
||
|
||
```
|
||
-XX:-UseBiasedLocking //关闭偏向锁(默认打开)
|
||
|
||
```
|
||
|
||
或
|
||
|
||
```
|
||
-XX:+UseHeavyMonitors //设置重量级锁
|
||
|
||
```
|
||
|
||
### 2.轻量级锁
|
||
|
||
当有另外一个线程竞争获取这个锁时,由于该锁已经是偏向锁,当发现对象头Mark Word中的线程ID不是自己的线程ID,就会进行CAS操作获取锁,如果获取成功,直接替换Mark Word中的线程ID为自己的ID,该锁会保持偏向锁状态;如果获取锁失败,代表当前锁有一定的竞争,偏向锁将升级为轻量级锁。
|
||
|
||
轻量级锁适用于线程交替执行同步块的场景,绝大部分的锁在整个同步周期内都不存在长时间的竞争。
|
||
|
||
**下图中红线流程部分为升级轻量级锁及操作流程:**
|
||
|
||
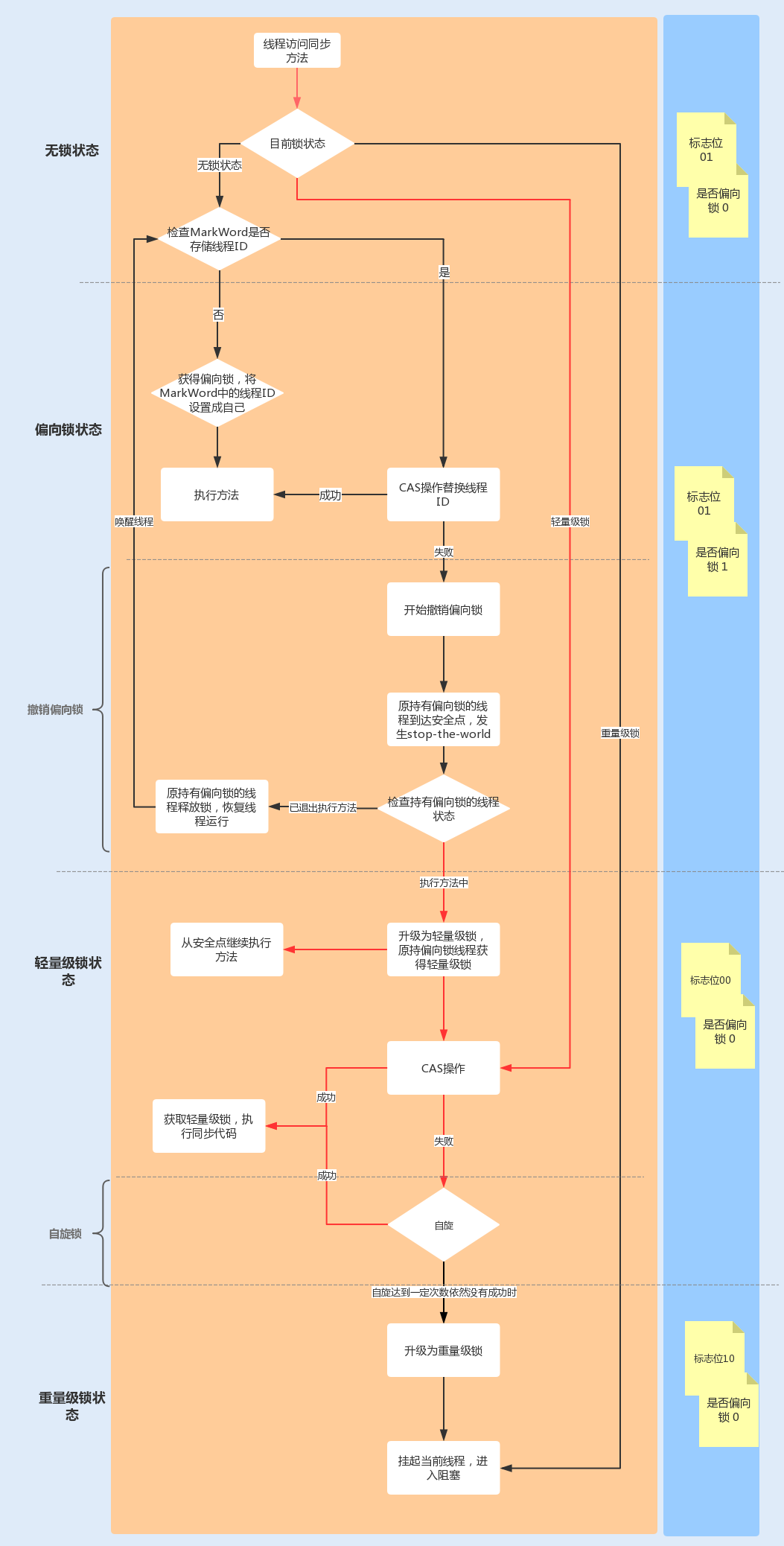
|
||
|
||
### 3.自旋锁与重量级锁
|
||
|
||
轻量级锁CAS抢锁失败,线程将会被挂起进入阻塞状态。如果正在持有锁的线程在很短的时间内释放资源,那么进入阻塞状态的线程无疑又要申请锁资源。
|
||
|
||
JVM提供了一种自旋锁,可以通过自旋方式不断尝试获取锁,从而避免线程被挂起阻塞。这是基于大多数情况下,线程持有锁的时间都不会太长,毕竟线程被挂起阻塞可能会得不偿失。
|
||
|
||
从JDK1.7开始,自旋锁默认启用,自旋次数由JVM设置决定,这里我不建议设置的重试次数过多,因为CAS重试操作意味着长时间地占用CPU。
|
||
|
||
自旋锁重试之后如果抢锁依然失败,同步锁就会升级至重量级锁,锁标志位改为10。在这个状态下,未抢到锁的线程都会进入Monitor,之后会被阻塞在\_WaitSet队列中。
|
||
|
||
**下图中红线流程部分为自旋后升级为重量级锁的流程:**
|
||
|
||
|
||
|
||
在锁竞争不激烈且锁占用时间非常短的场景下,自旋锁可以提高系统性能。一旦锁竞争激烈或锁占用的时间过长,自旋锁将会导致大量的线程一直处于CAS重试状态,占用CPU资源,反而会增加系统性能开销。所以自旋锁和重量级锁的使用都要结合实际场景。
|
||
|
||
在高负载、高并发的场景下,我们可以通过设置JVM参数来关闭自旋锁,优化系统性能,示例代码如下:
|
||
|
||
```
|
||
-XX:-UseSpinning //参数关闭自旋锁优化(默认打开)
|
||
-XX:PreBlockSpin //参数修改默认的自旋次数。JDK1.7后,去掉此参数,由jvm控制
|
||
|
||
```
|
||
|
||
## 动态编译实现锁消除/锁粗化
|
||
|
||
除了锁升级优化,Java还使用了编译器对锁进行优化。JIT 编译器在动态编译同步块的时候,借助了一种被称为逃逸分析的技术,来判断同步块使用的锁对象是否只能够被一个线程访问,而没有被发布到其它线程。
|
||
|
||
确认是的话,那么 JIT 编译器在编译这个同步块的时候不会生成 synchronized 所表示的锁的申请与释放的机器码,即消除了锁的使用。在 Java7 之后的版本就不需要手动配置了,该操作可以自动实现。
|
||
|
||
锁粗化同理,就是在 JIT 编译器动态编译时,如果发现几个相邻的同步块使用的是同一个锁实例,那么 JIT 编译器将会把这几个同步块合并为一个大的同步块,从而避免一个线程“反复申请、释放同一个锁”所带来的性能开销。
|
||
|
||
## 减小锁粒度
|
||
|
||
除了锁内部优化和编译器优化之外,我们还可以通过代码层来实现锁优化,减小锁粒度就是一种惯用的方法。
|
||
|
||
当我们的锁对象是一个数组或队列时,集中竞争一个对象的话会非常激烈,锁也会升级为重量级锁。我们可以考虑将一个数组和队列对象拆成多个小对象,来降低锁竞争,提升并行度。
|
||
|
||
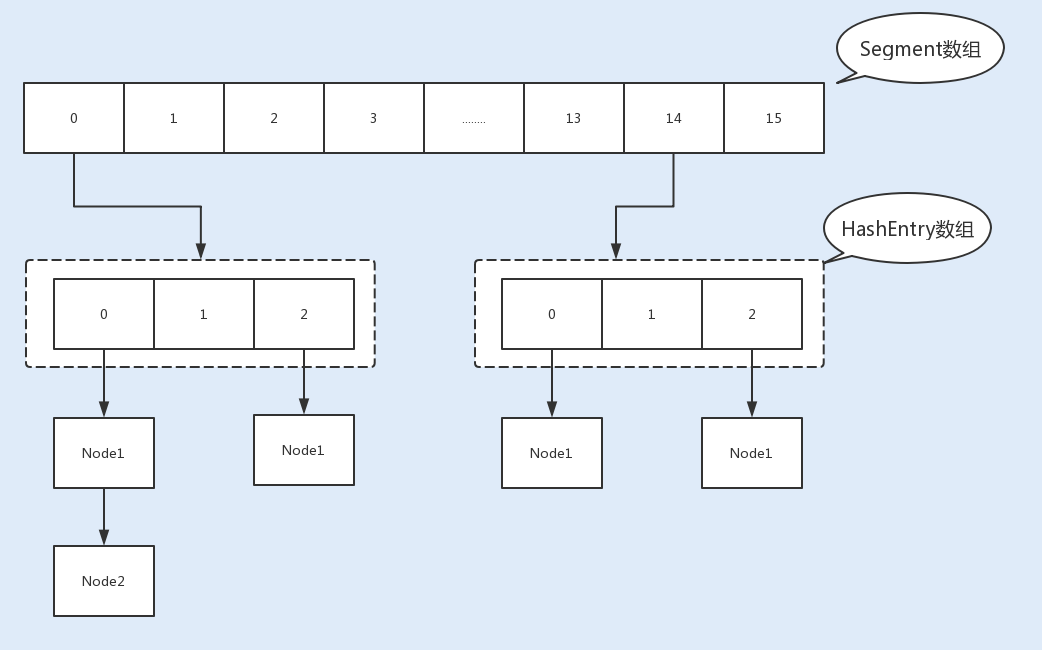
最经典的减小锁粒度的案例就是JDK1.8之前实现的ConcurrentHashMap版本。我们知道,HashTable是基于一个数组+链表实现的,所以在并发读写操作集合时,存在激烈的锁资源竞争,也因此性能会存在瓶颈。而ConcurrentHashMap就很很巧妙地使用了分段锁Segment来降低锁资源竞争,如下图所示:
|
||
|
||
|
||
|
||
## 总结
|
||
|
||
JVM在JDK1.6中引入了分级锁机制来优化Synchronized,当一个线程获取锁时,首先对象锁将成为一个偏向锁,这样做是为了优化同一线程重复获取导致的用户态与内核态的切换问题;其次如果有多个线程竞争锁资源,锁将会升级为轻量级锁,它适用于在短时间内持有锁,且分锁有交替切换的场景;轻量级锁还使用了自旋锁来避免线程用户态与内核态的频繁切换,大大地提高了系统性能;但如果锁竞争太激烈了,那么同步锁将会升级为重量级锁。
|
||
|
||
减少锁竞争,是优化Synchronized同步锁的关键。我们应该尽量使Synchronized同步锁处于轻量级锁或偏向锁,这样才能提高Synchronized同步锁的性能;通过减小锁粒度来降低锁竞争也是一种最常用的优化方法;另外我们还可以通过减少锁的持有时间来提高Synchronized同步锁在自旋时获取锁资源的成功率,避免Synchronized同步锁升级为重量级锁。
|
||
|
||
这一讲我们重点了解了Synchronized同步锁优化,这里由于字数限制,也为了你能更好地理解内容,目录中12讲的内容我拆成了两讲,在下一讲中,我会重点讲解Lock同步锁的优化方法。
|
||
|
||
## 思考题
|
||
|
||
请问以下Synchronized同步锁对普通方法和静态方法的修饰有什么区别?
|
||
|
||
```
|
||
// 修饰普通方法
|
||
public synchronized void method1() {
|
||
// code
|
||
}
|
||
|
||
// 修饰静态方法
|
||
public synchronized static void method2() {
|
||
// code
|
||
}
|
||
|
||
```
|
||
|
||
期待在留言区看到你的答案。也欢迎你点击“请朋友读”,把今天的内容分享给身边的朋友,邀请他一起学习。
|
||
|
||

|
||
|