21 KiB
21 | UI 优化(下):如何优化 UI 渲染?
孔子曰:“温故而知新”,在学习如何优化UI渲染之前,我们先来回顾一下在“卡顿优化”中学到的知识。关于卡顿优化,我们学习了4种本地排查卡顿的工具,以及多种线上监控卡顿、帧率的方法。为什么要回顾卡顿优化呢?那是因为UI渲染也会造成卡顿,并且肯定会有同学疑惑卡顿优化和UI优化的区别是什么。
在Android系统的VSYNC信号到达时,如果UI线程被某个耗时任务堵塞,长时间无法对UI进行渲染,这时就会出现卡顿。但是这种情形并不是我们今天讨论的重点,UI优化要解决的核心是由于渲染性能本身造成用户感知的卡顿,它可以认为是卡顿优化的一个子集。
从设计师和产品的角度,他们希望应用可以用丰富的图形元素、更炫酷的动画来实现流畅的用户体验。但是Android系统很有可能无法及时完成这些复杂的界面渲染操作,这个时候就会出现掉帧。也正因如此我才希望做UI优化,因为我们有更高的要求,希望它能达到流畅画面所需要的60 fps。这里需要说的是,即使40 fps用户可能不会感到明显的卡顿,但我们也仍需要去做进一步的优化。
那么接下来我们就来看看,如何让我们的UI渲染达到60 fps?有哪些方法可以帮助我们优化UI渲染性能?
UI渲染测量
通过上一期的学习,你应该已经掌握了一些UI测试和问题定位的工具。
-
测试工具:Profile GPU Rendering和Show GPU Overdraw,具体的使用方法你可以参考《检查GPU渲染速度和绘制过度》。
-
问题定位工具:Systrace和Tracer for OpenGL ES,具体使用方法可以参考《Slow rendering》。
在Android Studio 3.1之后,Android推荐使用Graphics API Debugger(GAPID)来替代Tracer for OpenGL ES工具。GAPID可以说是升级版,它不仅可以跨平台,而且功能更加强大,支持Vulkan与回放。
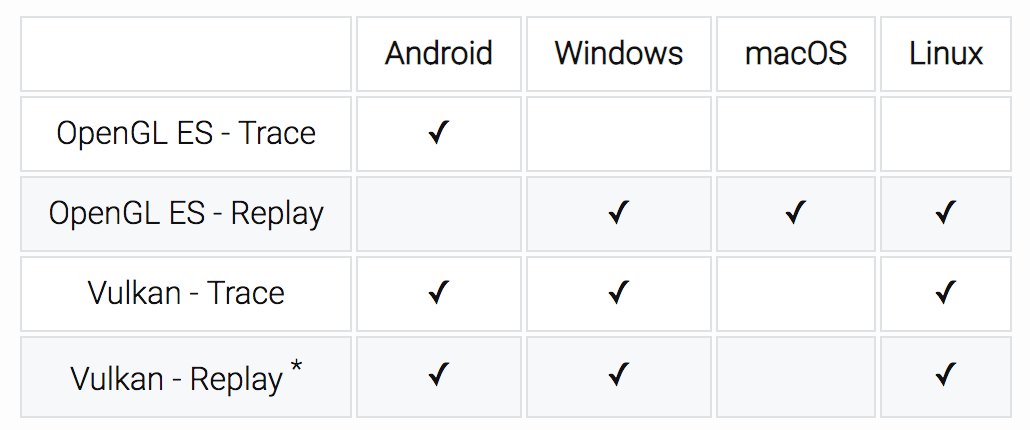
通过上面的几个工具,我们可以初步判断应用UI渲染的性能是否达标,例如是否经常出现掉帧、掉帧主要发生在渲染的哪一个阶段、是否存在Overdraw等。
虽然这些图形化界面工具非常好用,但是它们难以用在自动化测试场景中,那有哪些测量方法可以用于自动化测量UI渲染性能呢?
1. gfxinfo
gfxinfo可以输出包含各阶段发生的动画以及帧相关的性能信息,具体命令如下:
adb shell dumpsys gfxinfo 包名
除了渲染的性能之外,gfxinfo还可以拿到渲染相关的内存和View hierarchy信息。在Android 6.0之后,gxfinfo命令新增了framestats参数,可以拿到最近120帧每个绘制阶段的耗时信息。
adb shell dumpsys gfxinfo 包名 framestats
通过这个命令我们可以实现自动化统计应用的帧率,更进一步还可以实现自定义的“Profile GPU Rendering”工具,在出现掉帧的时候,自动统计分析是哪个阶段的耗时增长最快,同时给出相应的建议。

2. SurfaceFlinger
除了耗时,我们还比较关心渲染使用的内存。上一期我讲过,在Android 4.1以后每个Surface都会有三个Graphic Buffer,那如何查看Graphic Buffer占用的内存,系统是怎么样管理这部分的内存的呢?
你可以通过下面的命令拿到系统SurfaceFlinger相关的信息:
adb shell dumpsys SurfaceFlinger
下面以今日头条为例,应用使用了三个Graphic Buffer缓冲区,当前用在显示的第二个Graphic Buffer,大小是1080 x 1920。现在我们也可以更好地理解三缓冲机制,你可以看到这三个Graphic Buffer的确是在交替使用。
+ Layer 0x793c9d0c00 (com.ss.***。news/com.**.MainActivity)
//序号 //状态 //对象 //大小
>[02:0x794080f600] state=ACQUIRED, 0x794081bba0 [1080x1920:1088, 1]
[00:0x793e76ca00] state=FREE , 0x793c8a2640 [1080x1920:1088, 1]
[01:0x793e76c800] state=FREE , 0x793c9ebf60 [1080x1920:1088, 1]
继续往下看,你可以看到这三个Buffer分别占用的内存:
Allocated buffers:
0x793c8a2640: 8160.00 KiB | 1080 (1088) x 1920 | 1 | 0x20000900
0x793c9ebf60: 8160.00 KiB | 1080 (1088) x 1920 | 1 | 0x20000900
0x794081bba0: 8160.00 KiB | 1080 (1088) x 1920 | 1 | 0x20000900
这部分的内存其实真的不小,特别是现在手机的分辨率越来越大,而且还很多情况应用会有其他的Surface存在,例如使用了SurfaceView或者TextureView等。
那系统是怎么样管理这部分内存的呢?当应用退到后台的时候,系统会将这些内存回收,也就不会再把它们计算到应用的内存占用中。
+ Layer 0x793c9d0c00 (com.ss.***。news/com.**.MainActivity)
[00:0x0] state=FREE
[01:0x0] state=FREE
[02:0x0] state=FREE
那么如何快速地判别UI实现是否符合设计稿?如何更高效地实现UI自动化测试?这些问题你可以先思考一下,我们将在后面“高效测试”中再详细展开。
UI优化的常用手段
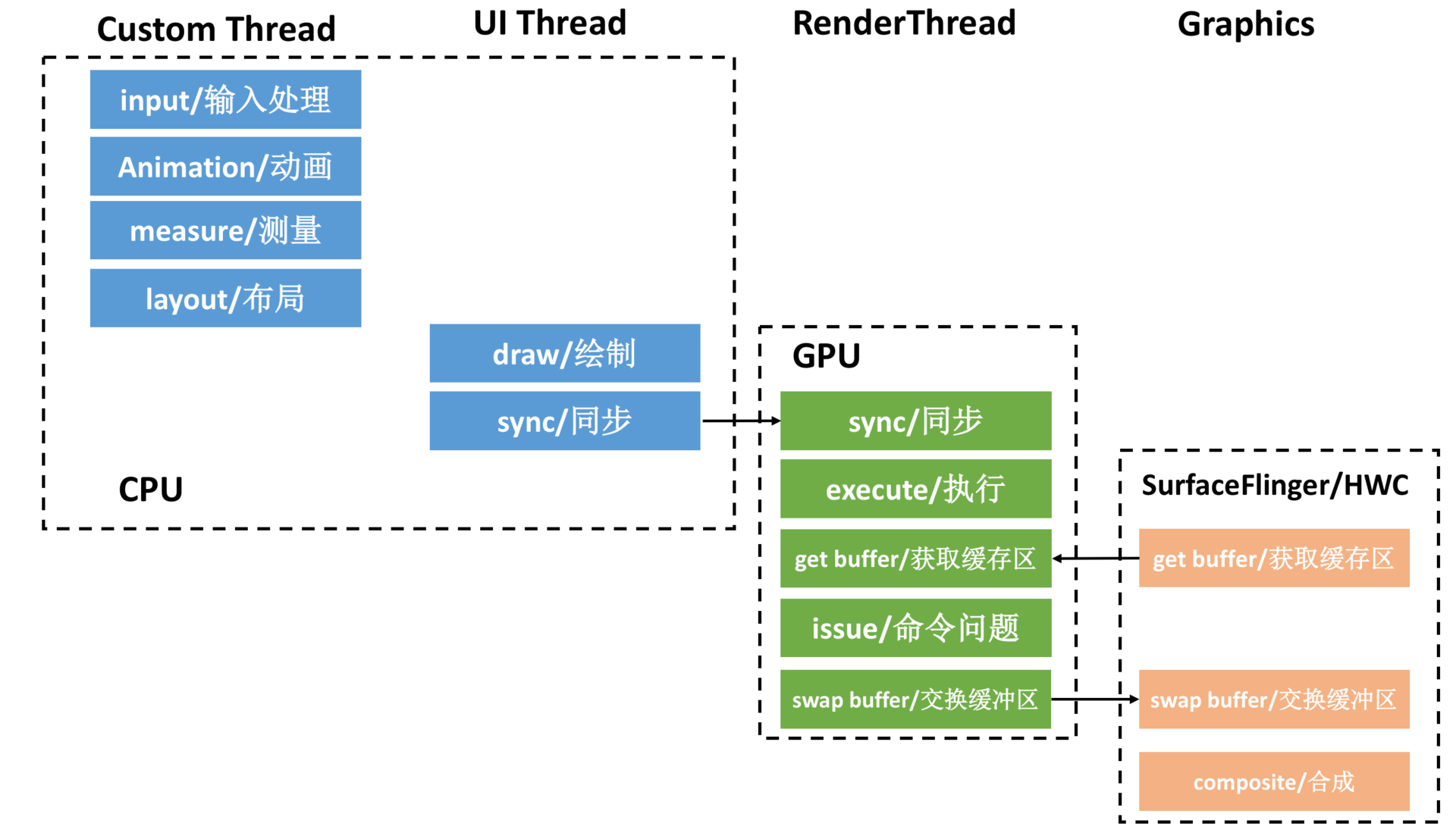
让我们再重温一下UI渲染的阶段流程图,我们的目标是实现60 fps,这意味着渲染的所有操作都必须在16 ms(= 1000 ms/60 fps)内完成。
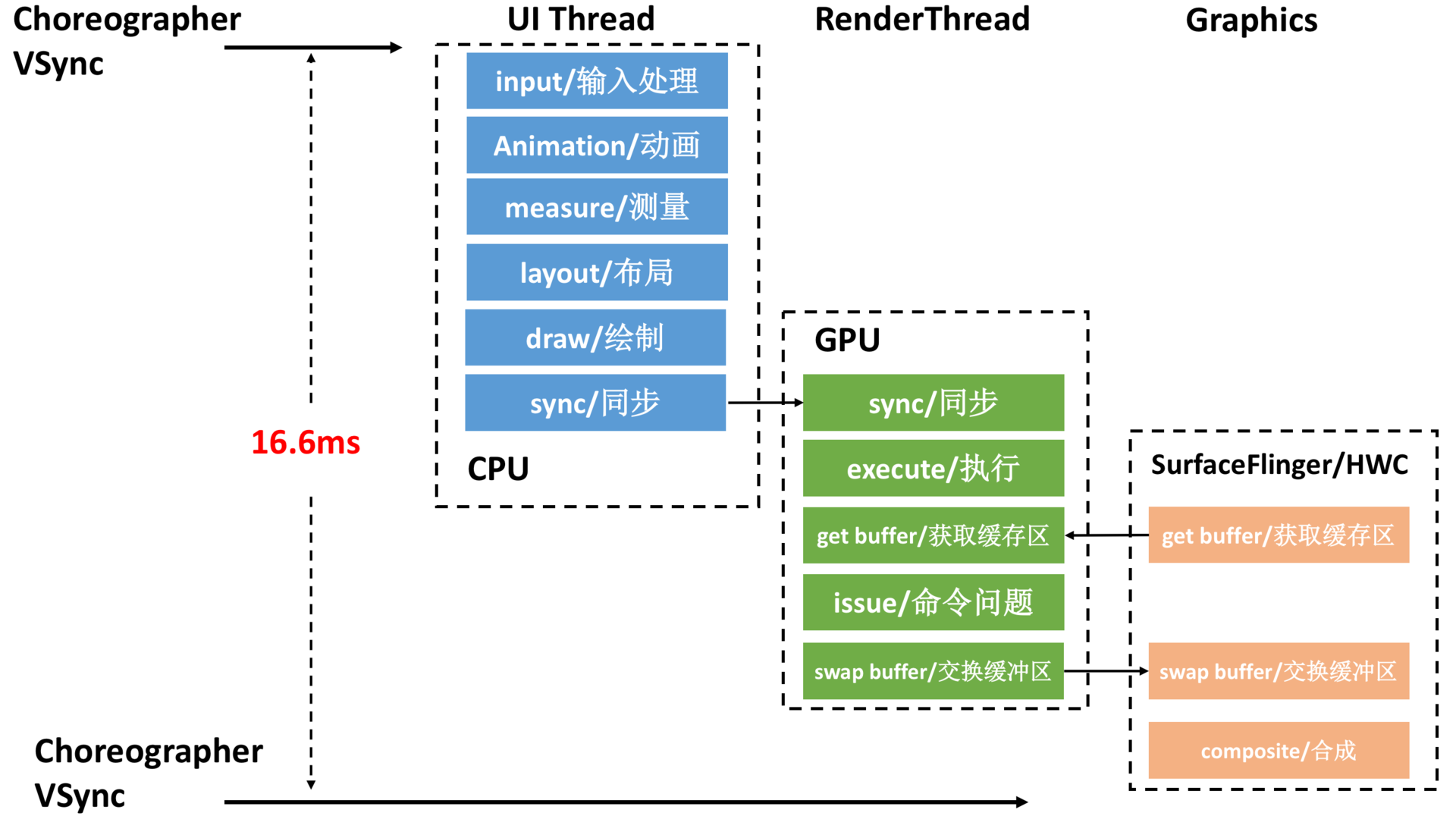
所谓的UI优化,就是拆解渲染的各个阶段的耗时,找到瓶颈的地方,再加以优化。接下来我们一起来看看UI优化的一些常用的手段。
1. 尽量使用硬件加速
通过上一期学习,相信你也发自内心地认同硬件加速绘制的性能是远远高于软件绘制的。所以说UI优化的第一个手段就是保证渲染尽量使用硬件加速。
有哪些情况我们不能使用硬件加速呢?之所以不能使用硬件加速,是因为硬件加速不能支持所有的Canvas API,具体API兼容列表可以见drawing-support文档。如果使用了不支持的API,系统就需要通过CPU软件模拟绘制,这也是渐变、磨砂、圆角等效果渲染性能比较低的原因。
SVG也是一个非常典型的例子,SVG有很多指令硬件加速都不支持。但我们可以用一个取巧的方法,提前将这些SVG转换成Bitmap缓存起来,这样系统就可以更好地使用硬件加速绘制。同理,对于其他圆角、渐变等场景,我们也可以改为Bitmap实现。
这种取巧方法实现的关键在于如何提前生成Bitmap,以及Bitmap的内存需要如何管理。你可以参考一下市面常用的图片库实现。
2. Create View优化
观察渲染的流水线时,有没有同学发现缺少一个非常重要的环节,那就是View创建的耗时。请不要忘记,View的创建也是在UI线程里,对于一些非常复杂的界面,这部分的耗时不容忽视。
在优化之前我们先来分解一下View创建的耗时,可能会包括各种XML的随机读的I/O时间、解析XML的时间、生成对象的时间(Framework会大量使用到反射)。
相应的,我们来看看这个阶段有哪些优化方式。
使用代码创建
使用XML进行UI编写可以说是十分方便,可以在Android Studio中实时预览到界面。如果我们要对一个界面进行极致优化,就可以使用代码进行编写界面。
但是这种方式对开发效率来说简直是灾难,因此我们可以使用一些开源的XML转换为Java代码的工具,例如X2C。但坦白说,还是有不少情况是不支持直接转换的。
所以我们需要兼容性能与开发效率,我建议只在对性能要求非常高,但修改又不非常频繁的场景才使用这个方式。
异步创建
那我们能不能在线程提前创建View,实现UI的预加载吗?尝试过的同学都会发现系统会抛出下面这个异常:
java.lang.RuntimeException: Can't create handler inside thread that has not called Looper.prepare()
at android.os.Handler.<init>(Handler.java:121)
事实上,我们可以通过又一个非常取巧的方式来实现。在使用线程创建UI的时候,先把线程的Looper的MessageQueue替换成UI线程Looper的Queue。
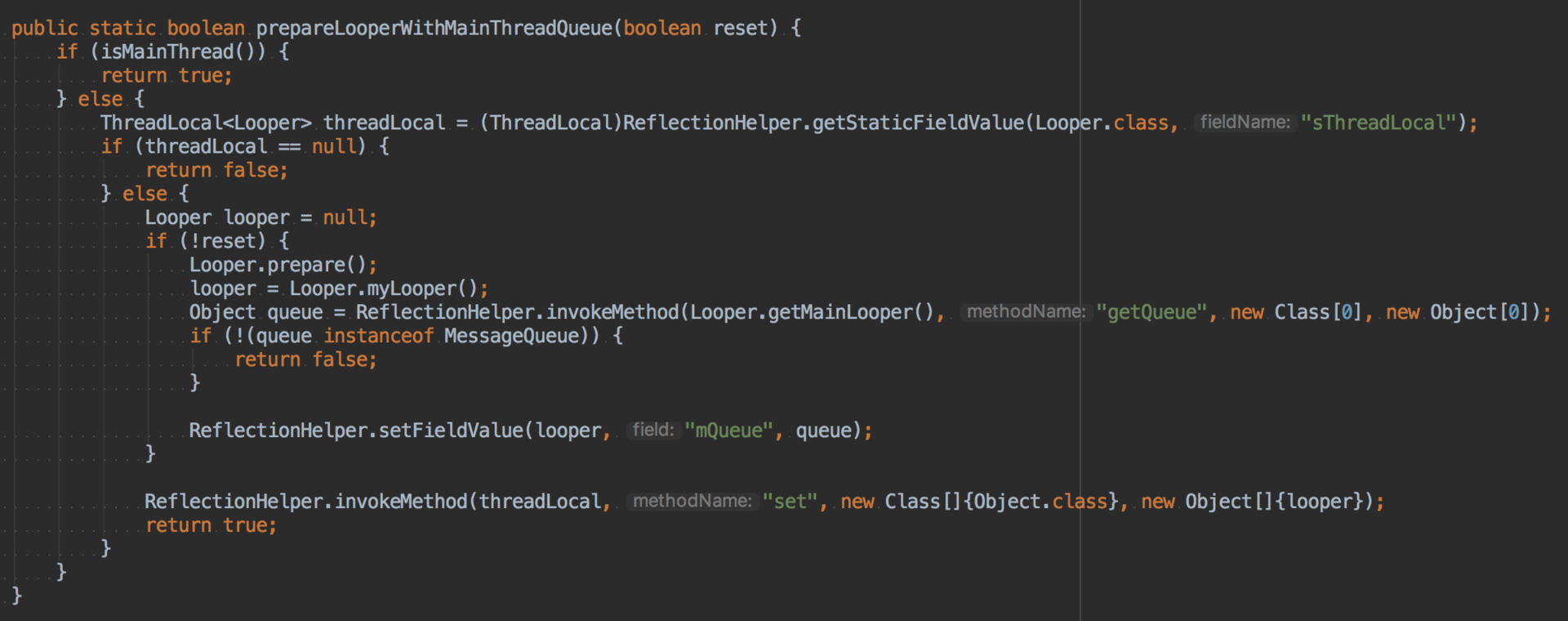
不过需要注意的是,在创建完View后我们需要把线程的Looper恢复成原来的。
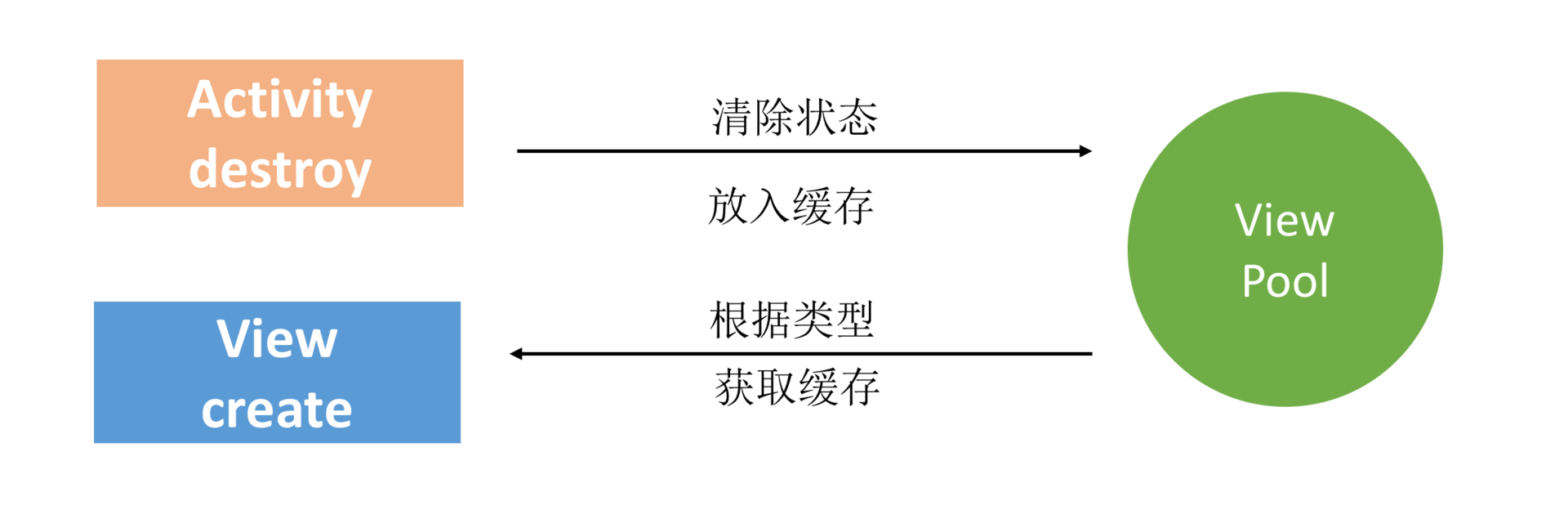
View重用
正常来说,View会随着Activity的销毁而同时销毁。ListView、RecycleView通过View的缓存与重用大大地提升渲染性能。因此我们可以参考它们的思想,实现一套可以在不同Activity或者Fragment使用的View缓存机制。
但是这里需要保证所有进入缓存池的View都已经“净身出户”,不会保留之前的状态。微信曾经就因为这个缓存,导致出现不同的用户聊天记录错乱。
3. measure/layout优化
渲染流程中measure和layout也是需要CPU在主线程执行的,对于这块内容网上有很多优化的文章,一般的常规方法有:
-
减少UI布局层次。例如尽量扁平化,使用
<ViewStub><Merge>等优化。 -
优化layout的开销。尽量不使用RelativeLayout或者基于weighted LinearLayout,它们layout的开销非常巨大。这里我推荐使用ConstraintLayout替代RelativeLayout或者weighted LinearLayout。
-
背景优化。尽量不要重复去设置背景,这里需要注意的是主题背景(theme), theme默认会是一个纯色背景,如果我们自定义了界面的背景,那么主题的背景我们来说是无用的。但是由于主题背景是设置在DecorView中,所以这里会带来重复绘制,也会带来绘制性能损耗。
对于measure和layout,我们能不能像Create View一样实现线程的预布局呢?这样可以大大地提升首次显示的性能。
Textview是系统控件中非常强大也非常重要的一个控件,强大的背后就代表着需要做很多计算。在2018年的Google I/O大会,发布了PrecomputedText并已经集成在Jetpack中,它给我们提供了接口,可以异步进行measure和layout,不必在主线程中执行。
UI优化的进阶手段
那对于其他的控件我们是不是也可以采用相同的方式?接下来我们一起来看看近两年新框架的做法,我来介绍一下Facebook的一个开源库Litho以及Google开源的Flutter。
1. Litho:异步布局
Litho是Facebook开源的声明式Android UI渲染框架,它是基于另外一个Facebook开源的布局引擎Yoga开发的。
Litho本身非常强大,内部做了很多非常不错的优化。下面我来简单介绍一下它是如何优化UI的。
异步布局
一般来说的Android所有的控件绘制都要遵守measure -> layout -> draw的流水线,并且这些都发生在主线程中。
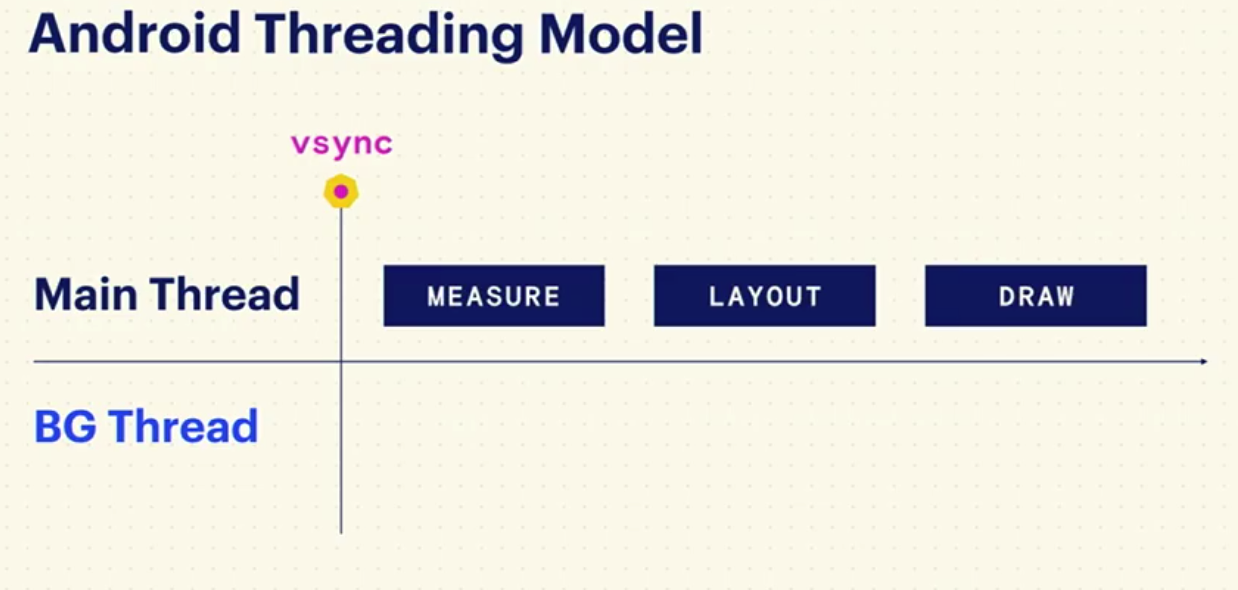
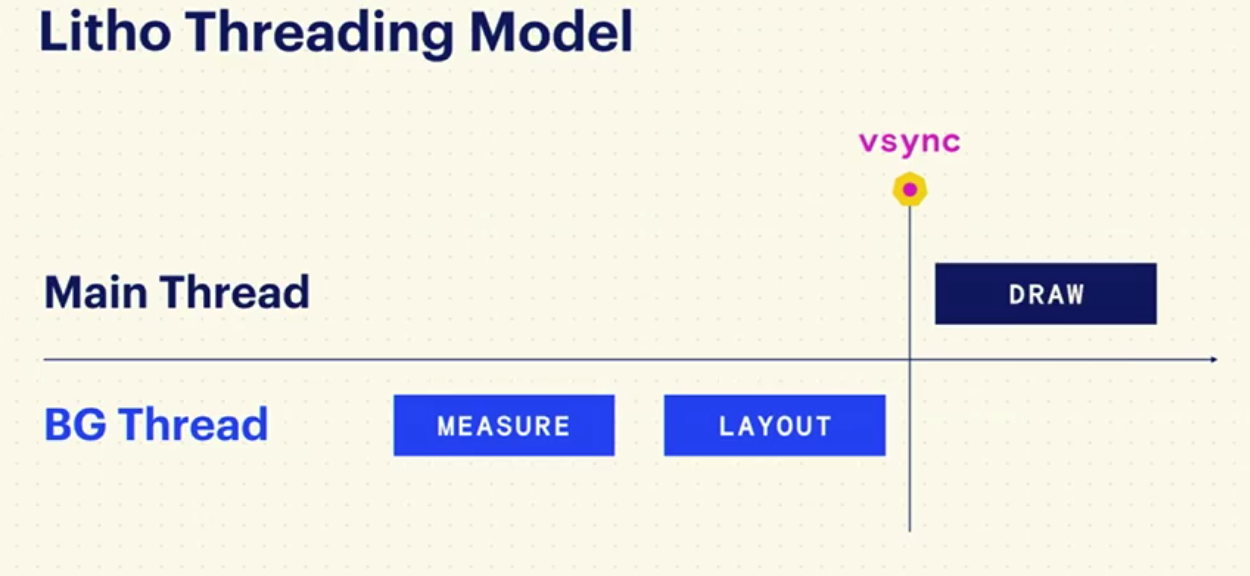
Litho如我前面提到的PrecomputedText一样,把measure和layout都放到了后台线程,只留下了必须要在主线程完成的draw,这大大降低了UI线程的负载。它的渲染流水线如下:
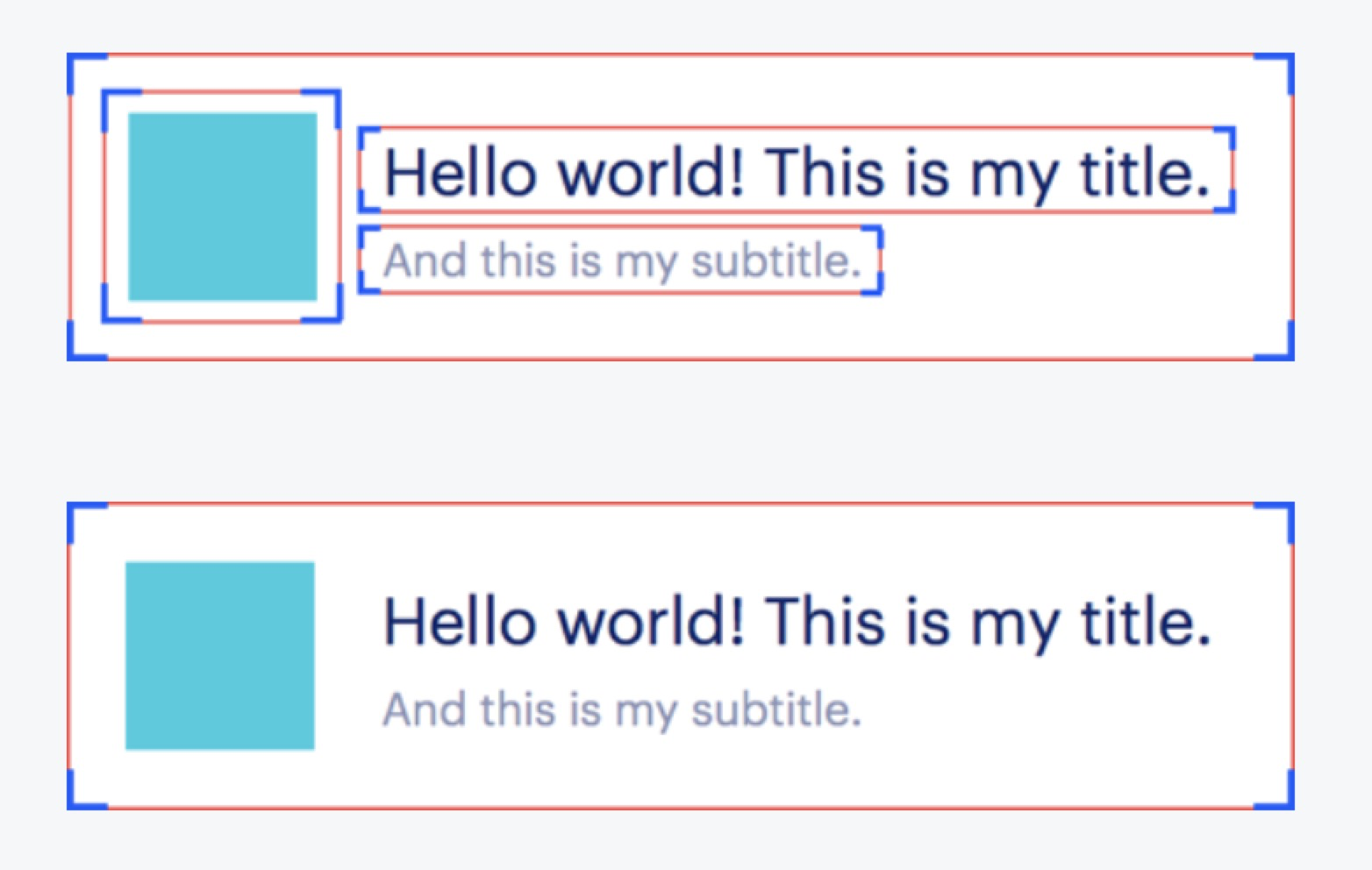
界面扁平化
前面也提到过,降低UI的层级是一个非常通用的优化方法。你肯定会想,有没有一种方法可以直接降低UI的层级,而不通过代码的改变呢?Litho就给了我们一种方案,由于Litho使用了自有的布局引擎(Yoga),在布局阶段就可以检测不必要的层级、减少ViewGroups,来实现UI扁平化。比如下面这样图,上半部分是我们一般编写这个界面的方法,下半部分是Litho编写的界面,可以看到只有一层层级。
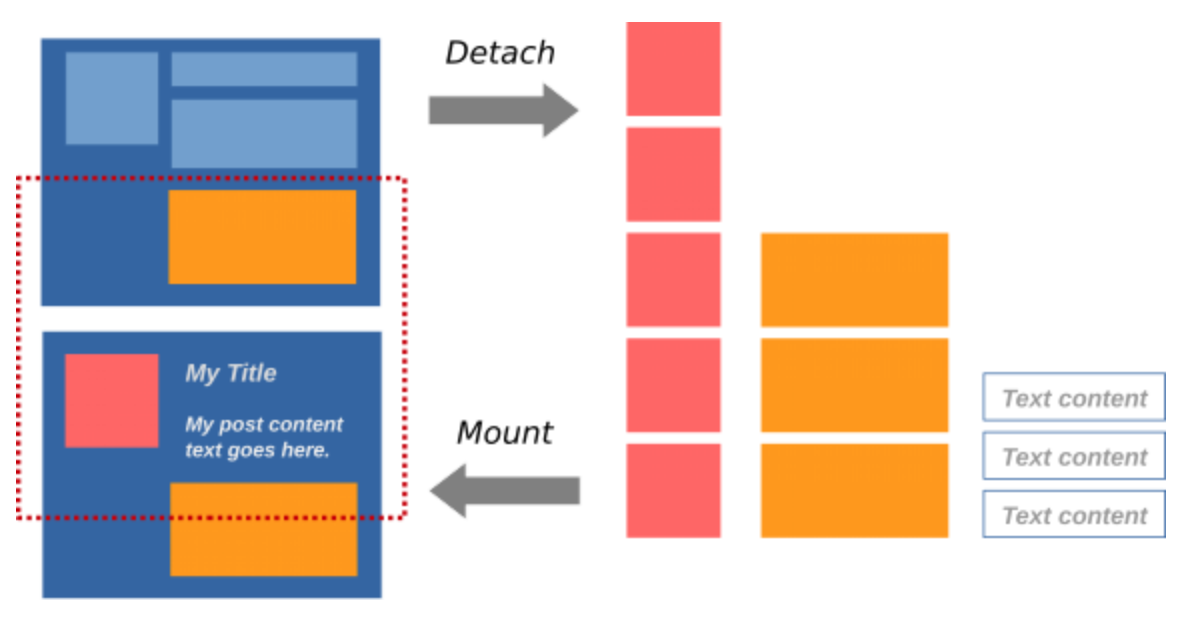
优化RecyclerView
Litho还优化了RecyclerView中UI组件的缓存和回收方法。原生的RecyclerView或者ListView是按照viewType来进行缓存和回收,但如果一个RecyclerView/ListView中出现viewType过多,会使缓存形同虚设。但Litho是按照text、image和video独立回收的,这可以提高缓存命中率、降低内存使用率、提高滚动帧率。
Litho虽然强大,但也有自己的缺点。它为了实现measure/layout异步化,使用了类似react单向数据流设计,这一定程度上加大了UI开发的复杂性。并且Litho的UI代码是使用Java/Kotlin来进行编写,无法做到在AS中预览。
如果你没有计划完全迁移到Litho,我建议可以优先使用Litho中的RecyclerCollectionComponent和Sections来优化自己的RecyelerView的性能。
2. Flutter:自己的布局 + 渲染引擎
如下图所示,Litho虽然通过使用自己的布局引擎Yoga,一定程度上突破了系统的一些限制,但是在draw之后依然走的系统的渲染机制。
那我们能不能再往底层深入,把系统的渲染也同时接管过来?Flutter正是这样的框架,它也是最近十分火爆的一个新框架,这里我也简单介绍一下。
Flutter是Google推出并开源的移动应用开发框架,开发者可以通过Dart语言开发App,一套代码同时运行在iOS和Android平台。
我们先整体看一下Flutter的架构,在Android上Flutter完全没有基于系统的渲染引擎,而是把Skia引擎直接集成进了App中,这使得Flutter App就像一个游戏App。并且直接使用了Dart虚拟机,可以说是一套跳脱出Android的方案,所以Flutter也可以很容易实现跨平台。

开发Flutter应用总的来说简化了线程模型,框架给我们抽象出各司其职的Runner,包括UI、GPU、I/O、Platform Runner。Android平台上面每一个引擎实例启动的时候会为UI Runner、GPU Runner、I/O Runner各自创建一个新的线程,所有Engine实例共享同一个Platform Runner和线程。
由于本期我们主要讨论UI渲染相关的内容,我来着重分析一下Flutter的渲染步骤,相关的具体知识你可以阅读《Flutter原理与实践》。
-
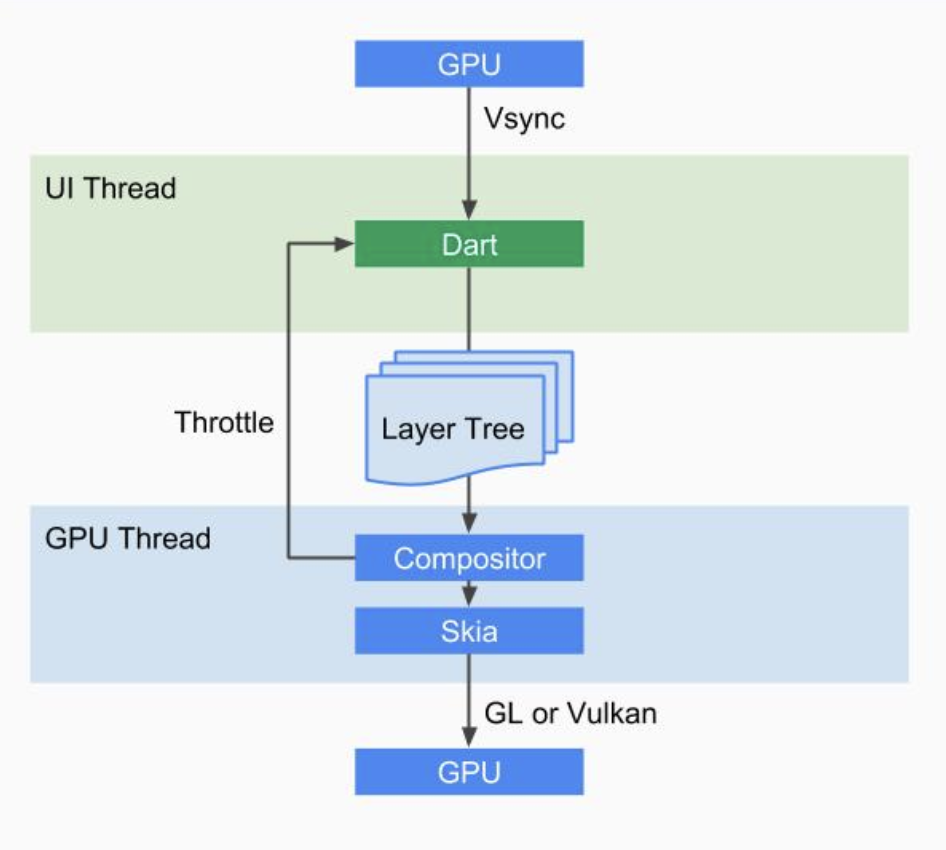
首先UI Runner会执行root isolate(可以简单理解为main函数。需要简单解释一下isolate的概念,isolate是Dart虚拟机中一种执行并发代码实现,Dart虚拟机实现了Actor的并发模型,与大名鼎鼎的Erlang使用了类似的并发模型。如果不太了解Actor的同学,可以简单认为isolate就是Dart虚拟机的“线程”,Root isolate会通知引擎有帧要渲染)。
-
Flutter引擎得到通知后,会告知系统我们要同步VSYNC。
-
得到GPU的VSYNC信号后,对UI Widgets进行Layout并生成一个Layer Tree。
-
然后Layer Tree会交给GPU Runner进行合成和栅格化。
-
GPU Runner使用Skia库绘制相关图形。
Flutter也采用了类似Litho、React属性不可变,单向数据流的方案。这已经成为现代UI渲染引擎的标配。这样做的好处是可以将视图与数据分离。
总体来说Flutter吸取和各个优秀前端框架的精华,还“加持”了强大的Dart虚拟机和Skia渲染引擎,可以说是一个非常优秀的框架,闲鱼、今日头条等很多应用部分功能已经使用Flutter开发。结合Google最新的Fuchsia操作系统,它会不会是一个颠覆Android的开发框架?我们在专栏后面会单独详细讨论Flutter。
3. RenderThread与RenderScript
在Android 5.0,系统增加了RenderThread,对于ViewPropertyAnimator和CircularReveal动画,我们可以使用RenderThead实现动画的异步渲染。当主线程阻塞的时候,普通动画会出现明显的丢帧卡顿,而使用RenderThread渲染的动画即使阻塞了主线程仍不受影响。
现在越来越多的应用会使用一些高级图片或者视频编辑功能,例如图片的高斯模糊、放大、锐化等。拿日常我们使用最多的“扫一扫”这个场景来看,这里涉及大量的图片变换操作,例如缩放、裁剪、二值化以及降噪等。
图片的变换涉及大量的计算任务,而根据我们上一期的学习,这个时候使用GPU是更好的选择。那如何进一步压榨系统GPU的性能呢?
我们可以通过RenderScript,它是Android操作系统上的一套API。它基于异构计算思想,专门用于密集型计算。RenderScript提供了三个基本工具:一个硬件无关的通用计算API;一个类似于CUDA、OpenCL和GLSL的计算API;一个类C99的脚本语言。允许开发者以较少的代码实现功能复杂且性能优越的应用程序。
如何将它们应用到我们的项目中?你可以参考下面的一些实践方案:
总结
回顾一下UI优化的所有手段,我们会发现它存在这样一个脉络:
1. 在系统的框架下优化。布局优化、使用代码创建、View缓存等都是这个思路,我们希望减少甚至省下渲染流水线里某个阶段的耗时。
2. 利用系统新的特性。使用硬件加速、RenderThread、RenderScript都是这个思路,通过系统一些新的特性,最大限度压榨出性能。
3. 突破系统的限制。由于Android系统碎片化非常严重,很多好的特性可能低版本系统并不支持。而且系统需要支持所有的场景,在一些特定场景下它无法实现最优解。这个时候,我们希望可以突破系统的条条框框,例如Litho突破了布局,Flutter则更进一步,把渲染也接管过来了。
回顾一下过去所有的UI优化,第一阶段的优化我们在系统的束缚下也可以达到非常不错的效果。不过越到后面越容易出现瓶颈,这个时候我们就需要进一步往底层走,可以对整个架构有更大的掌控力,需要造自己的“轮子”。
对于UI优化的另一个思考是效率,目前Android Studio对设计并不友好,例如不支持Sketch插件和AE插件。Lottie是一个非常好的案例,它很大提升了开发人员写动画的效率。
“设计师和产品,你们长大了,要学会自己写UI了”。在未来,我们希望UI界面与适配可以实现自动化,或者干脆把它交还给设计师和产品。
课后作业
在你平时的工作中,做过哪些UI优化的工作,有没有什么“大招”跟其他同学分享?对于Litho, Flutter,你又有什么看法?欢迎留言跟我和其他同学一起讨论。
今天还有两个课后小作业,尝试使用Litho和Flutter这两个框架。
1.使用Litho实现一个信息流界面。
2.使用Flutter写一个Hello World,分析安装包的体积。
欢迎你点击“请朋友读”,把今天的内容分享给好友,邀请他一起学习。最后别忘了在评论区提交今天的作业,我也为认真完成作业的同学准备了丰厚的“学习加油礼包”,期待与你一起切磋进步哦。