20 KiB
20 | UI 优化(上):UI 渲染的几个关键概念
在开始今天的学习前,我祝各位同学新春快乐、工作顺利、身体健康、阖家幸福,绍文给您拜年啦!
每个做UI的Android开发,上辈子都是折翼的天使。
多年来,有那么一群苦逼的Android开发,他们饱受碎片化之苦,面对着各式各样的手机屏幕尺寸和分辨率,还要与“凶残”的产品和UI设计师过招,日复一日、年复一年的做着UI适配和优化工作,蹉跎着青春的岁月。更加不幸的是,最近两年这个趋势似乎还愈演愈烈:刘海屏、全面屏,还有即将推出的柔性折叠屏,UI适配将变得越来越复杂。
UI优化究竟指的是什么呢?我认为所谓的UI优化,应该包含两个方面:一个是效率的提升,我们可以非常高效地把UI的设计图转化成应用界面,并且保证UI界面在不同尺寸和分辨率的手机上都是一致的;另一个是性能的提升,在正确实现复杂、炫酷的UI设计的同时,需要保证用户有流畅的体验。
那如何将我们从无穷无尽的UI适配中拯救出来呢?
UI渲染的背景知识
究竟什么是UI渲染呢?Android的图形渲染框架十分复杂,不同版本的差异也比较大。但是无论怎么样,它们都是为了将我们代码中的View或者元素显示到屏幕中。
而屏幕作为直接面对用户的手机硬件,类似厚度、色彩、功耗等都是厂家非常关注的。从功能机小小的黑白屏,到现在超大的全面屏,我们先来看手机屏幕的发展历程。
1. 屏幕与适配
作为消费者来说,通常会比较关注屏幕的尺寸、分辨率以及厚度这些指标。Android的碎片化问题令人痛心疾首,屏幕的差异正是碎片化问题的“中心”。屏幕的尺寸从3英寸到10英寸,分辨率从320到1920应有尽有,对我们UI适配造成很大困难。
除此之外,材质也是屏幕至关重要的一个评判因素。目前智能手机主流的屏幕可分为两大类:一种是LCD(Liquid Crystal Display),即液晶显示器;另一种是OLED(Organic Light-Emitting Diode的)即有机发光二极管。
最新的旗舰机例如iPhone XS Max和华为Mate 20 Pro使用的都是OLED屏幕。相比LCD屏幕,OLED屏幕在色彩、可弯曲程度、厚度以及耗电都有优势。正因为这些优势,全面屏、曲面屏以及未来的柔性折叠屏,使用的都是OLED材质。关于OLED与LCD的具体差别,你可以参考《OLED和LCD区别》和《手机屏幕的前世今生,可能比你想的还精彩》。今年柔性折叠屏肯定是最大的热点,不过OLED的单价成本要比LCD高很多。
对于屏幕碎片化的问题,Android推荐使用dp作为尺寸单位来适配UI,因此每个Android开发都应该很清楚px、dp、dpi、ppi、density这些概念。

通过dp加上自适应布局可以基本解决屏幕碎片化的问题,也是Android推荐使用的屏幕兼容性适配方案。但是它会存在两个比较大的问题:
-
不一致性。因为dpi与实际ppi的差异性,导致在相同分辨率的手机上,控件的实际大小会有所不同。
-
效率。设计师的设计稿都是以px为单位的,开发人员为了UI适配,需要手动通过百分比估算出dp值。
除了直接dp适配之外,目前业界比较常用的UI适配方法主要有下面几种:
-
限制符适配方案。主要有宽高限定符与smallestWidth限定符适配方案,具体可以参考《Android 目前稳定高效的UI适配方案》《smallestWidth 限定符适配方案》。
-
今日头条适配方案。通过反射修正系统的density值,具体可以参考《一种极低成本的Android屏幕适配方式》《今日头条适配方案》。
2. CPU与GPU
除了屏幕,UI渲染还依赖两个核心的硬件:CPU与GPU。UI组件在绘制到屏幕之前,都需要经过Rasterization(栅格化)操作,而栅格化操作又是一个非常耗时的操作。GPU(Graphic Processing Unit )也就是图形处理器,它主要用于处理图形运算,可以帮助我们加快栅格化操作。
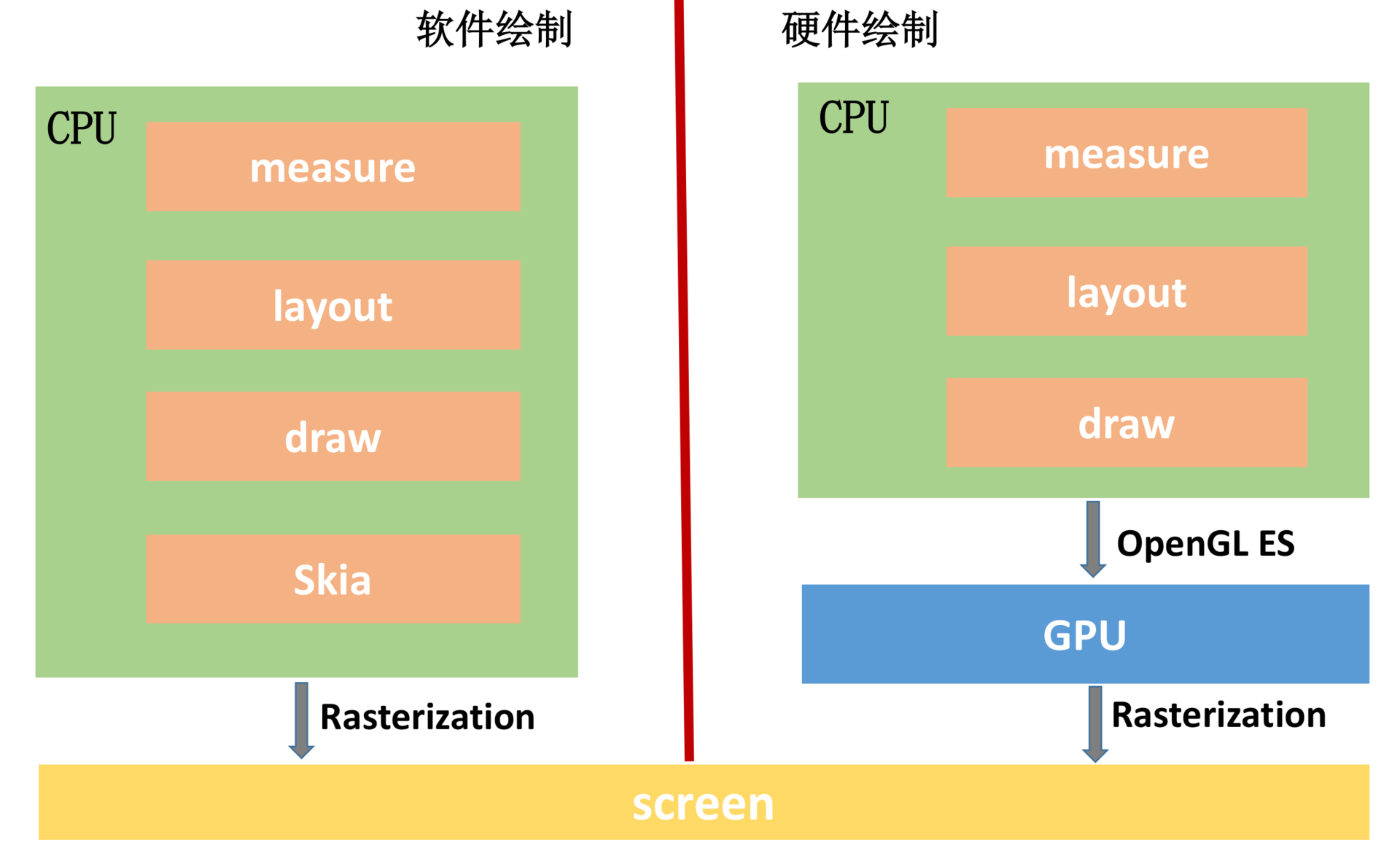
你可以从图上看到,软件绘制使用的是Skia库,它是一款能在低端设备如手机上呈现高质量的2D跨平台图形框架,类似Chrome、Flutter内部使用的都是Skia库。
3. OpenGL与Vulkan
对于硬件绘制,我们通过调用OpenGL ES接口利用GPU完成绘制。OpenGL是一个跨平台的图形API,它为2D/3D图形处理硬件指定了标准软件接口。而OpenGL ES是OpenGL的子集,专为嵌入式设备设计。
在官方硬件加速的文档中,可以看到很多API都有相应的Android API level限制。
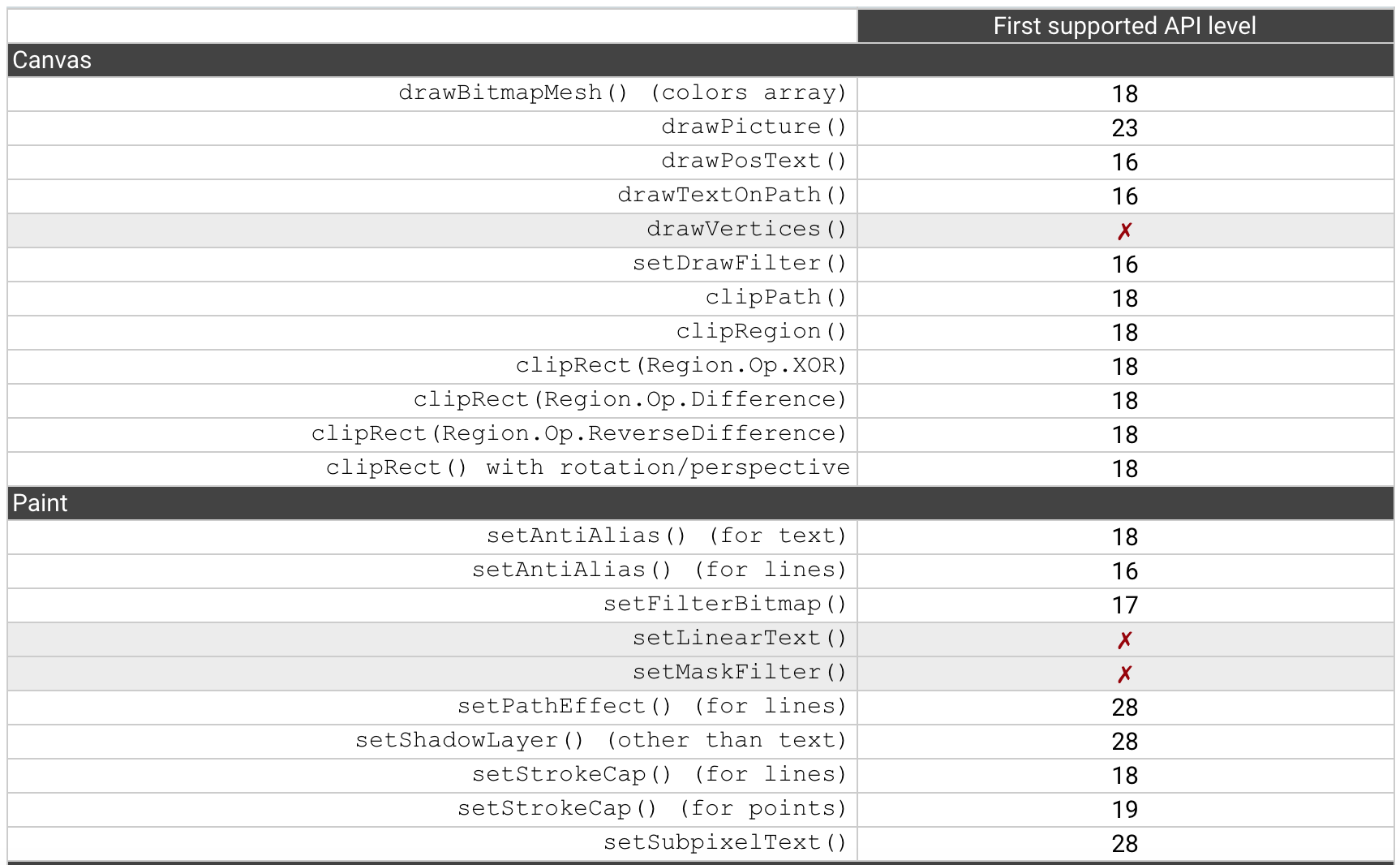
这是为什么呢?其实这主要是受OpenGL ES版本与系统支持的限制,直到最新的Android P,有3个API是仍然没有支持。对于不支持的API,我们需要使用软件绘制模式,渲染的性能将会大大降低。
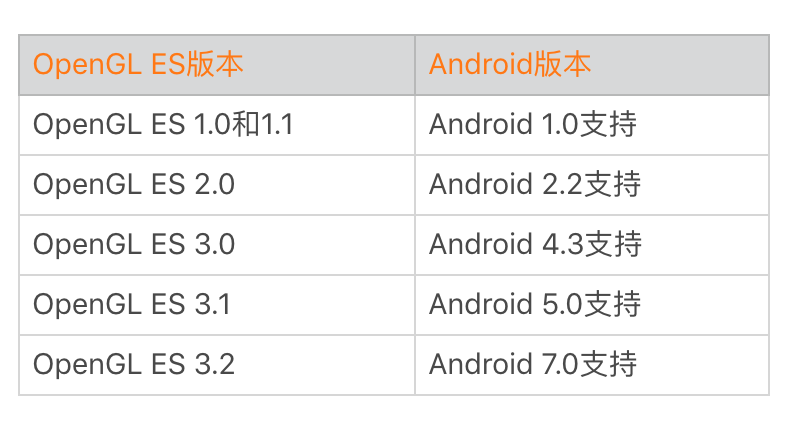
Android 7.0把OpenGL ES升级到最新的3.2版本同时,还添加了对Vulkan的支持。Vulkan是用于高性能3D图形的低开销、跨平台 API。相比OpenGL ES,Vulkan在改善功耗、多核优化提升绘图调用上有着非常明显的优势。
在国内,“王者荣耀”是比较早适配Vulkan的游戏,虽然目前兼容性还有一些问题,但是Vulkan版本的王者荣耀在流畅性和帧数稳定性都有大幅度提升,即使是战况最激烈的团战阶段,也能够稳定保持在55~60帧。
Android渲染的演进
跟耗电一样,Android的UI渲染性能也是Google长期以来非常重视的,基本每次Google I/O都会花很多篇幅讲这一块。每个开发者都希望自己的应用或者游戏可以做到60 fps如丝般顺滑,不过相比iOS系统,Android的渲染性能一直被人诟病。
Android系统为了弥补跟iOS的差距,在每个版本都做了大量的优化。在了解Android的渲染之前,需要先了解一下Android图形系统的整体架构,以及它包含的主要组件。
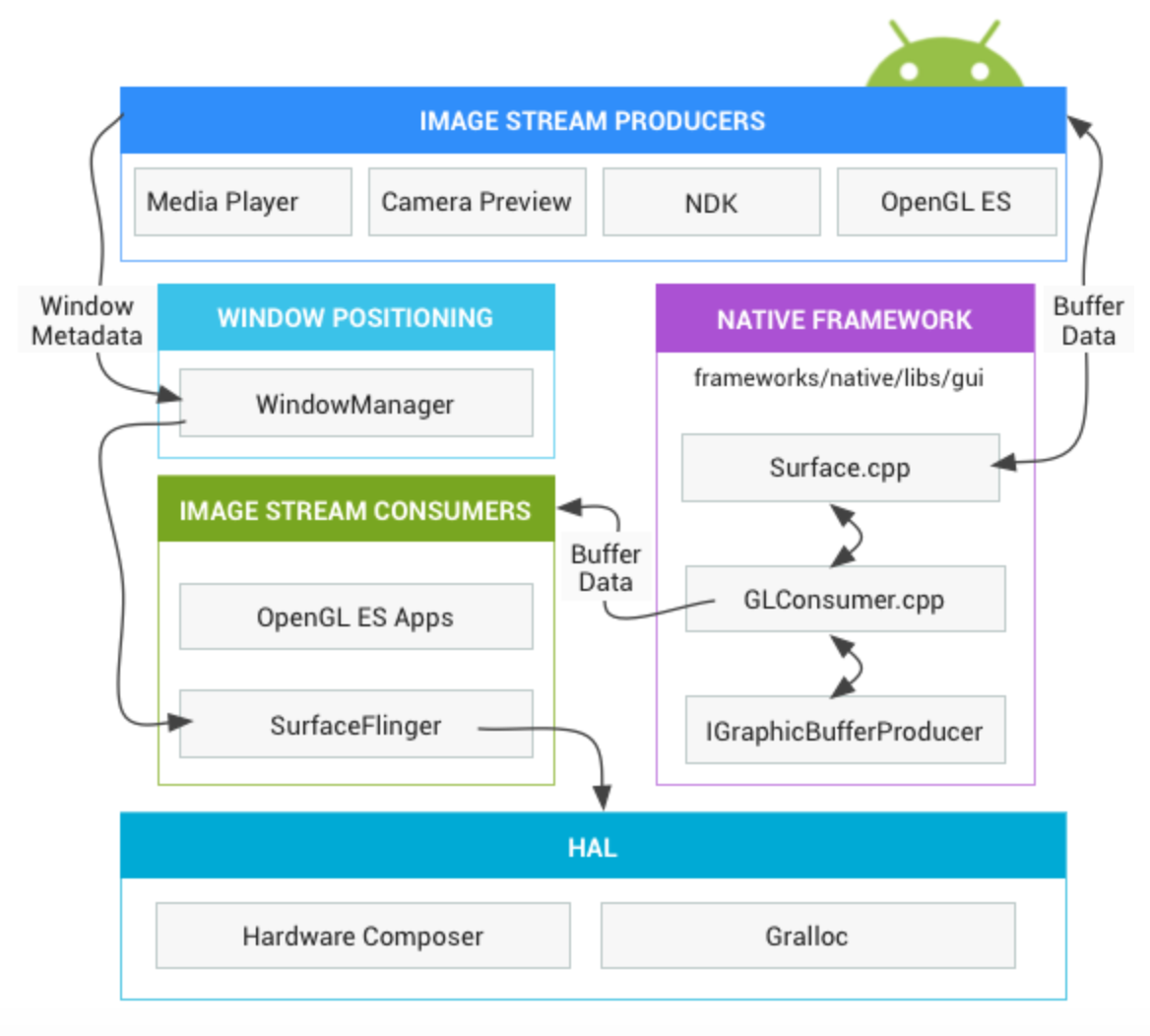
我曾经在一篇文章看过一个生动的比喻,如果把应用程序图形渲染过程当作一次绘画过程,那么绘画过程中Android的各个图形组件的作用是:
-
画笔:Skia或者OpenGL。我们可以用Skia画笔绘制2D图形,也可以用OpenGL来绘制2D/3D图形。正如前面所说,前者使用CPU绘制,后者使用GPU绘制。
-
画纸:Surface。所有的元素都在Surface这张画纸上进行绘制和渲染。在Android中,Window是View的容器,每个窗口都会关联一个Surface。而WindowManager则负责管理这些窗口,并且把它们的数据传递给SurfaceFlinger。
-
画板:Graphic Buffer。Graphic Buffer缓冲用于应用程序图形的绘制,在Android 4.1之前使用的是双缓冲机制;在Android 4.1之后,使用的是三缓冲机制。
-
显示:SurfaceFlinger。它将WindowManager提供的所有Surface,通过硬件合成器Hardware Composer合成并输出到显示屏。
接下来我将通过Android渲染演进分析的方法,帮你进一步加深对Android渲染的理解。
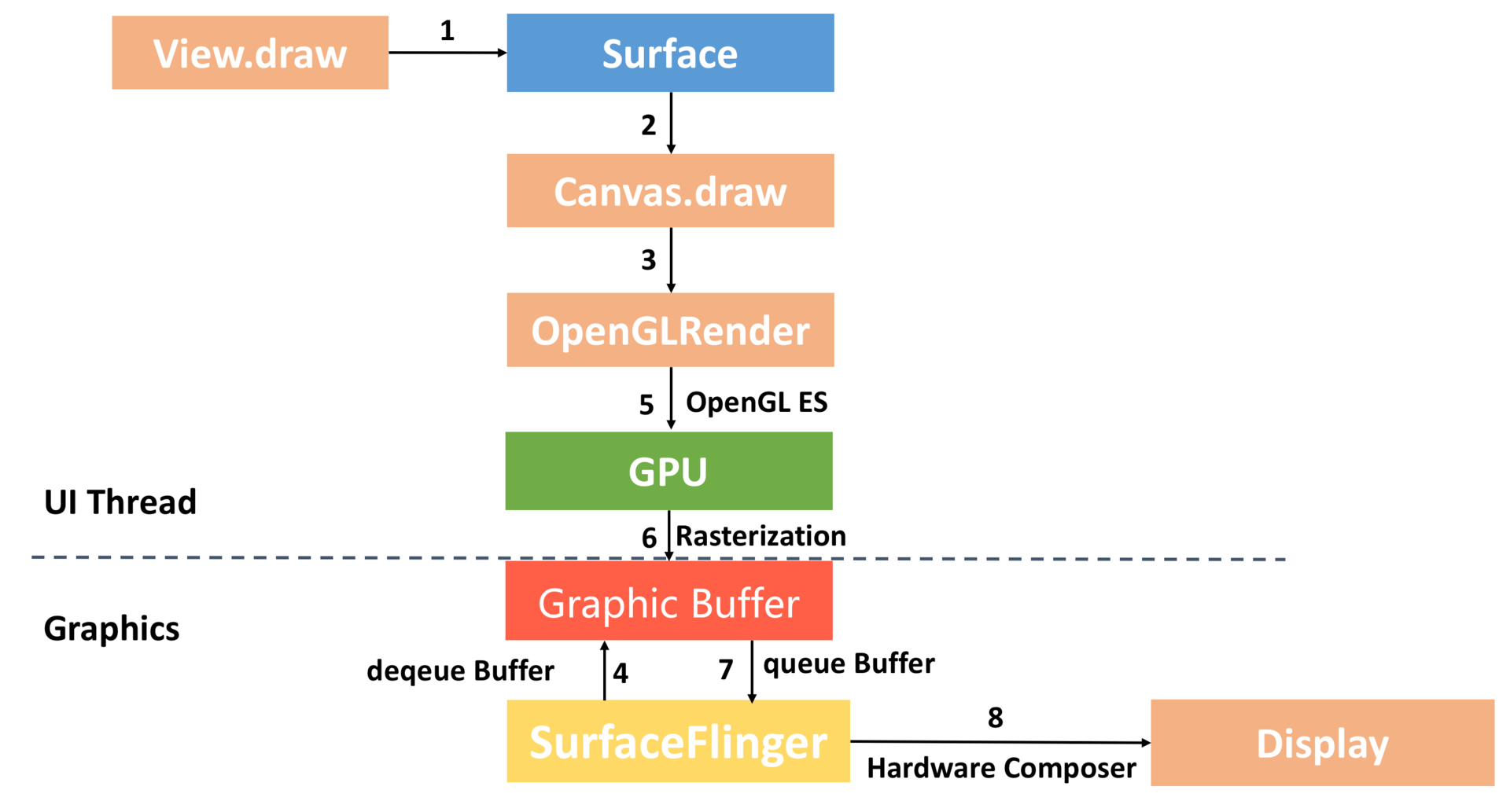
1. Android 4.0:开启硬件加速
在Android 3.0之前,或者没有启用硬件加速时,系统都会使用软件方式来渲染UI。
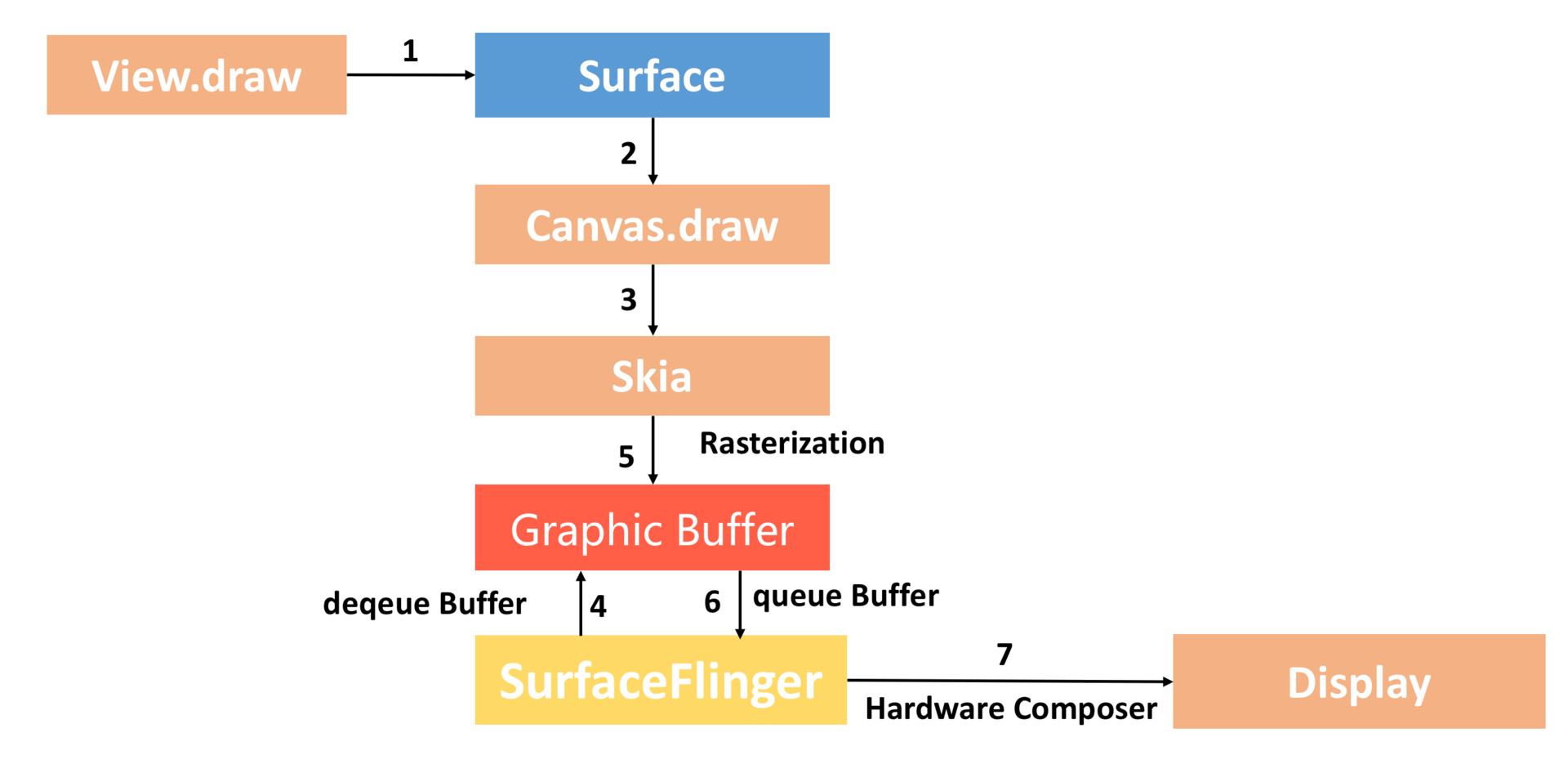
整个流程如上图所示:
-
Surface。每个View都由某一个窗口管理,而每一个窗口都关联有一个Surface。
-
Canvas。通过Surface的lock函数获得一个Canvas,Canvas可以简单理解为Skia底层接口的封装。
-
Graphic Buffer。SurfaceFlinger会帮我们托管一个BufferQueue,我们从BufferQueue中拿到Graphic Buffer,然后通过Canvas以及Skia将绘制内容栅格化到上面。
-
SurfaceFlinger。通过Swap Buffer把Front Graphic Buffer的内容交给SurfaceFinger,最后硬件合成器Hardware Composer合成并输出到显示屏。
整个渲染流程是不是非常简单?但是正如我前面所说,CPU对于图形处理并不是那么高效,这个过程完全没有利用到GPU的高性能。
硬件加速绘制
所以从Androd 3.0开始,Android开始支持硬件加速,到Android 4.0时,默认开启硬件加速。
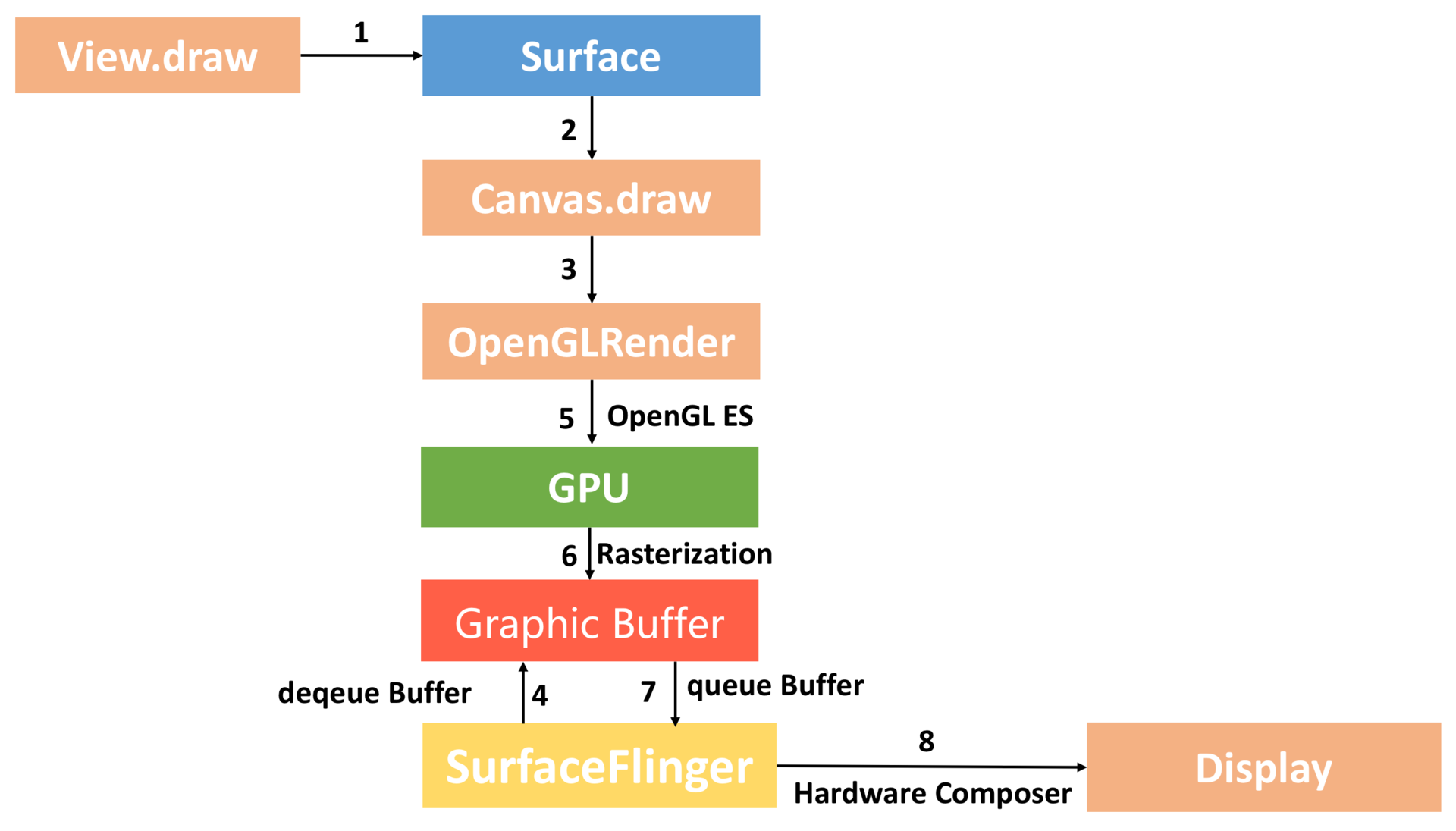
硬件加速绘制与软件绘制整个流程差异非常大,最核心就是我们通过GPU完成Graphic Buffer的内容绘制。此外硬件绘制还引入了一个DisplayList的概念,每个View内部都有一个DisplayList,当某个View需要重绘时,将它标记为Dirty。
当需要重绘时,仅仅只需要重绘一个View的DisplayList,而不是像软件绘制那样需要向上递归。这样可以大大减少绘图的操作数量,因而提高了渲染效率。
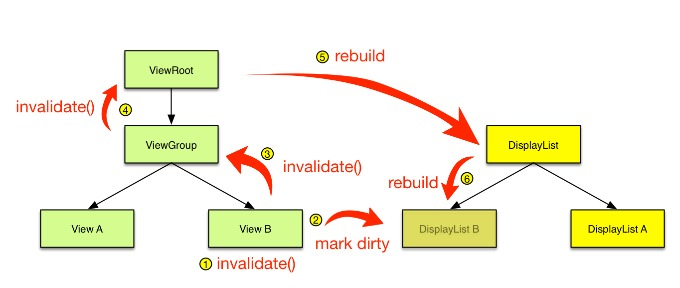
2. Android 4.1:Project Butter
优化是无止境的,Google在2012年的I/O大会上宣布了Project Butter黄油计划,并且在Android 4.1中正式开启了这个机制。
Project Butter主要包含两个组成部分,一个是VSYNC,一个是Triple Buffering。
VSYNC信号
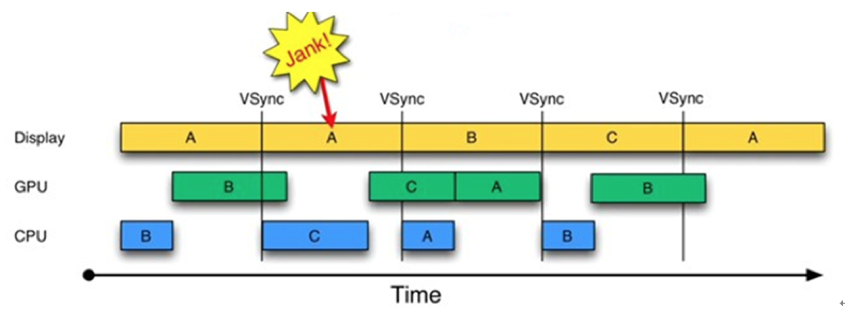
在讲文件I/O跟网络I/O的时候,我讲到过中断的概念。对于Android 4.0,CPU可能会因为在忙别的事情,导致没来得及处理UI绘制。
为解决这个问题,Project Buffer引入了VSYNC,它类似于时钟中断。每收到VSYNC中断,CPU会立即准备Buffer数据,由于大部分显示设备刷新频率都是60Hz(一秒刷新60次),也就是说一帧数据的准备工作都要在16ms内完成。
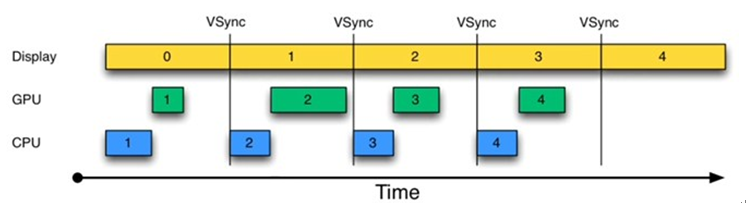
这样应用总是在VSYNC边界上开始绘制,而SurfaceFlinger总是VSYNC边界上进行合成。这样可以消除卡顿,并提升图形的视觉表现。
三缓冲机制Triple Buffering
在Android 4.1之前,Android使用双缓冲机制。怎么理解呢?一般来说,不同的View或者Activity它们都会共用一个Window,也就是共用同一个Surface。
而每个Surface都会有一个BufferQueue缓存队列,但是这个队列会由SurfaceFlinger管理,通过匿名共享内存机制与App应用层交互。
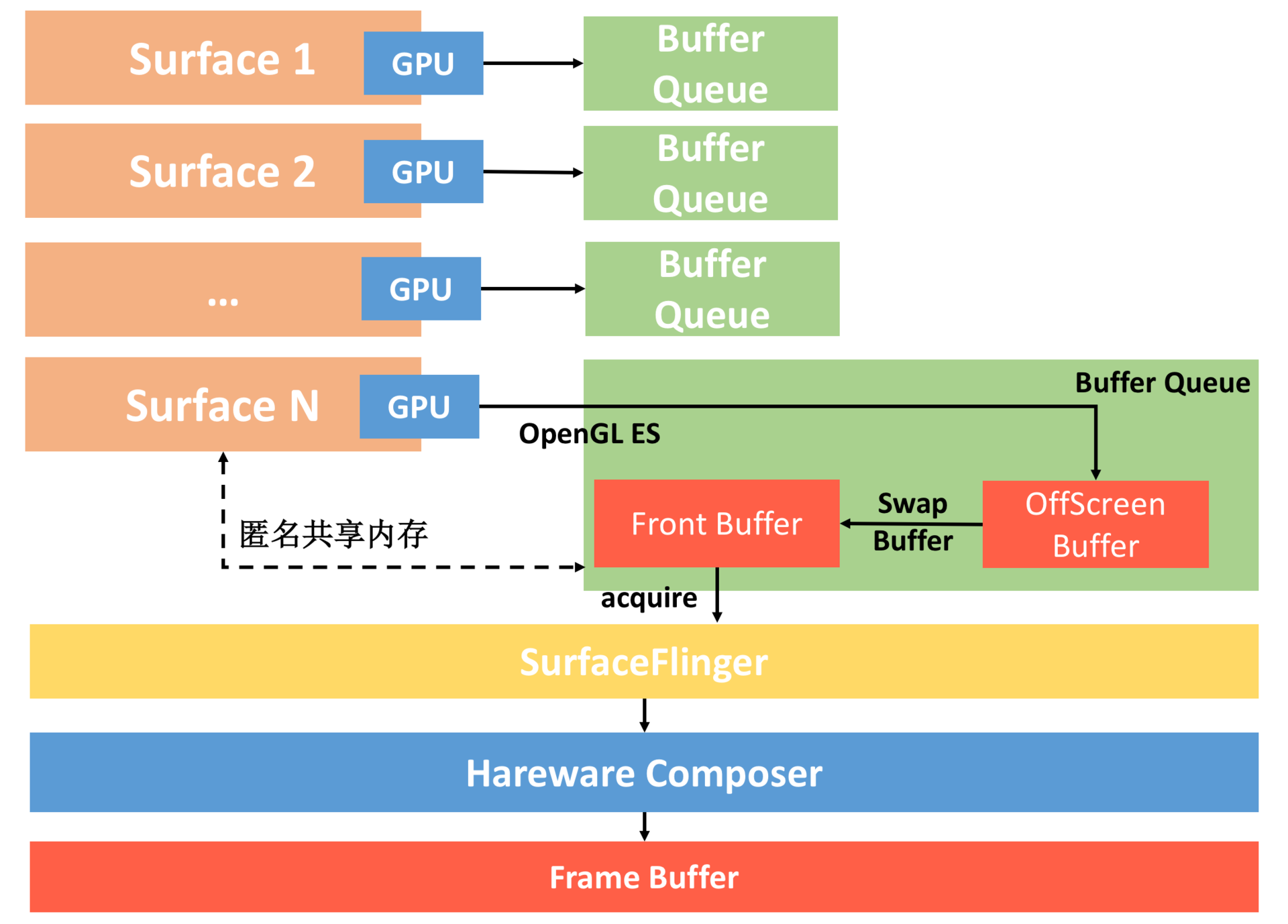
整个流程如下:
-
每个Surface对应的BufferQueue内部都有两个Graphic Buffer ,一个用于绘制一个用于显示。我们会把内容先绘制到离屏缓冲区(OffScreen Buffer),在需要显示时,才把离屏缓冲区的内容通过Swap Buffer复制到Front Graphic Buffer中。
-
这样SurfaceFlinge就拿到了某个Surface最终要显示的内容,但是同一时间我们可能会有多个Surface。这里面可能是不同应用的Surface,也可能是同一个应用里面类似SurefaceView和TextureView,它们都会有自己单独的Surface。
-
这个时候SurfaceFlinger把所有Surface要显示的内容统一交给Hareware Composer,它会根据位置、Z-Order顺序等信息合成为最终屏幕需要显示的内容,而这个内容会交给系统的帧缓冲区Frame Buffer来显示(Frame Buffer是非常底层的,可以理解为屏幕显示的抽象)。
如果你理解了双缓冲机制的原理,那就非常容易理解什么是三缓冲区了。如果只有两个Graphic Buffer缓存区A和B,如果CPU/GPU绘制过程较长,超过了一个VSYNC信号周期,因为缓冲区B中的数据还没有准备完成,所以只能继续展示A缓冲区的内容,这样缓冲区A和B都分别被显示设备和GPU占用,CPU无法准备下一帧的数据。
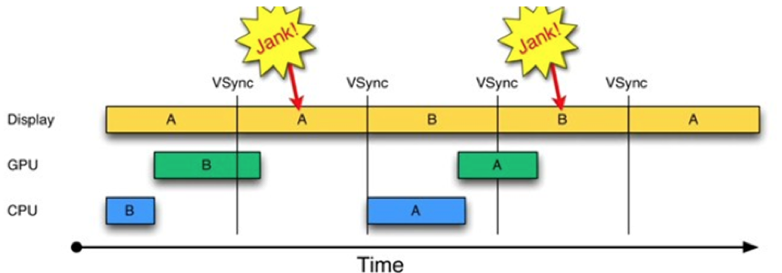
如果再提供一个缓冲区,CPU、GPU和显示设备都能使用各自的缓冲区工作,互不影响。简单来说,三缓冲机制就是在双缓冲机制基础上增加了一个Graphic Buffer缓冲区,这样可以最大限度的利用空闲时间,带来的坏处是多使用的了一个Graphic Buffer所占用的内存。
对于VSYNC信号和Triple Buffering更详细的介绍,可以参考《Android Project Butter分析》。
数据测量
“工欲善其事,必先利其器”,Project Butter在优化UI渲染性能的同时,也希望可以帮助我们更好地排查UI相关的问题。
在Android 4.1,新增了Systrace性能数据采样和分析工具。在卡顿和启动优化中,我们已经使用过Systrace很多次了,也可以用它来检测每一帧的渲染情况。
Tracer for OpenGL ES也是Android 4.1新增加的工具,它可逐帧、逐函数的记录App用OpenGL ES的绘制过程。它提供了每个OpenGL函数调用的消耗时间,所以很多时候用来做性能分析。但因为其强大的记录功能,在分析渲染问题时,当Traceview、Systrace都显得棘手时,还找不到渲染问题所在时,此时这个工具就会派上用场了。
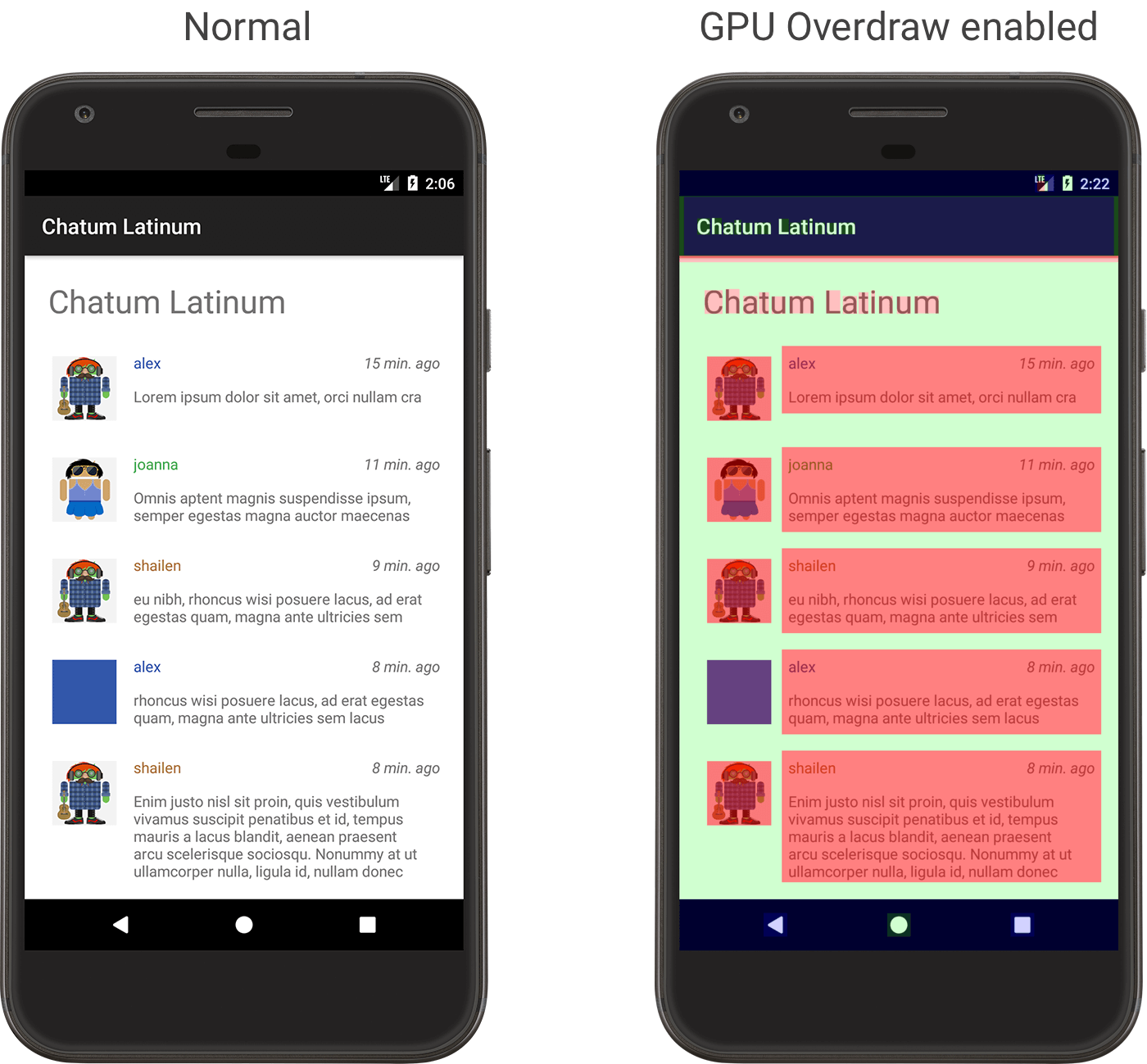
在Android 4.2,系统增加了检测绘制过度工具,具体的使用方法可以参考《检查GPU渲染速度和绘制过度》。
3. Android 5.0:RenderThread
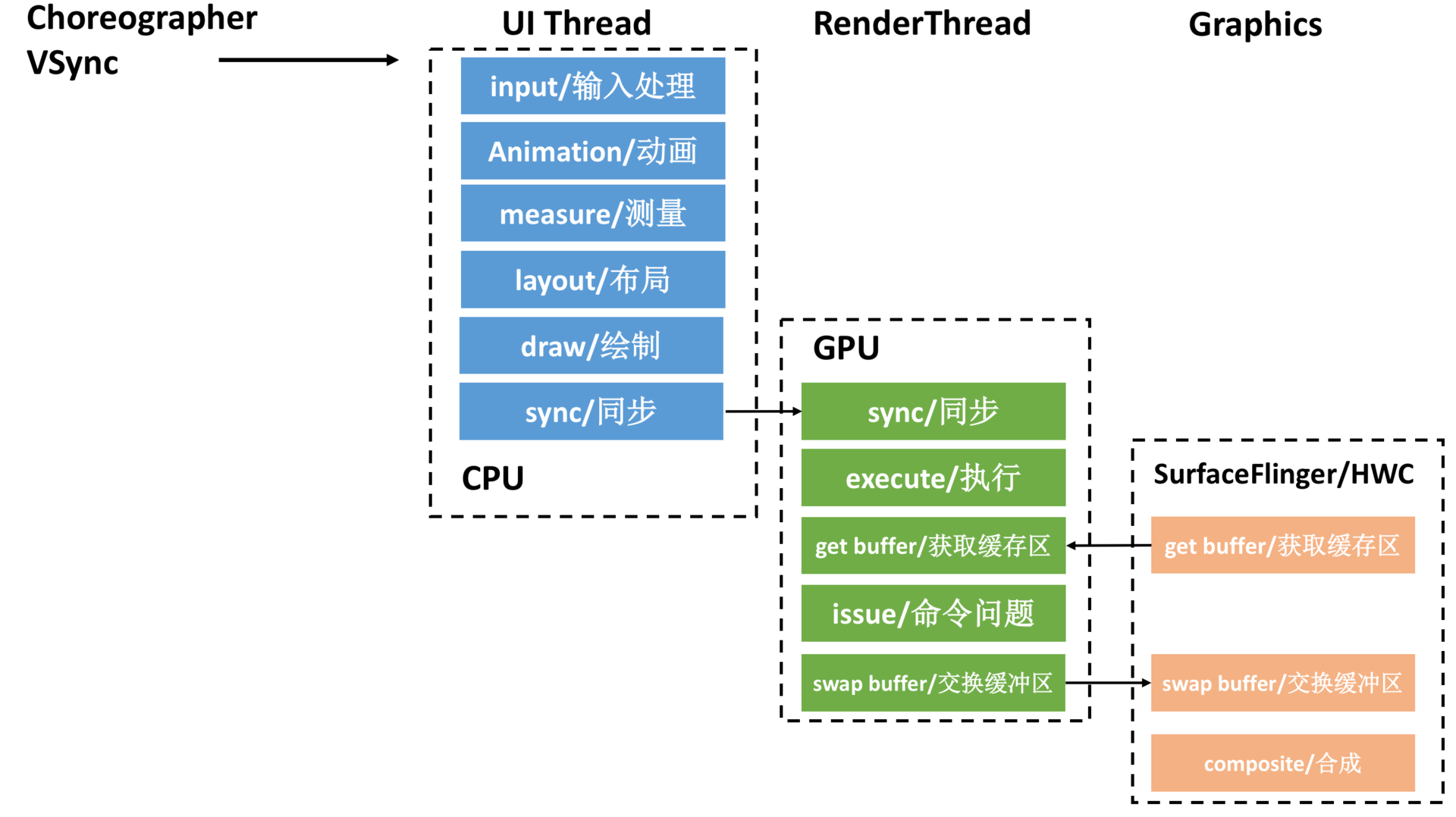
经过Project Butter黄油计划之后,Android的渲染性能有了很大的改善。但是不知道你有没有注意到一个问题,虽然我们利用了GPU的图形高性能运算,但是从计算DisplayList,到通过GPU绘制到Frame Buffer,整个计算和绘制都在UI主线程中完成。
UI主线程“既当爹又当妈”,任务过于繁重。如果整个渲染过程比较耗时,可能造成无法响应用户的操作,进而出现卡顿。GPU对图形的绘制渲染能力更胜一筹,如果使用GPU并在不同线程绘制渲染图形,那么整个流程会更加顺畅。
正因如此,在Android 5.0引入了两个比较大的改变。一个是引入了RenderNode的概念,它对DisplayList及一些View显示属性做了进一步封装。另一个是引入了RenderThread,所有的GL命令执行都放到这个线程上,渲染线程在RenderNode中存有渲染帧的所有信息,可以做一些属性动画,这样即便主线程有耗时操作的时候也可以保证动画流畅。
在官方文档 《检查 GPU 渲染速度和绘制过度》中,我们还可以开启Profile GPU Rendering检查。在Android 6.0之后,会输出下面的计算和绘制每个阶段的耗时:

如果我们把上面的步骤转化线程模型,可以得到下面的流水线模型。CPU将数据同步(sync)给GPU之后,一般不会阻塞等待GPU渲染完毕,而是通知结束后就返回。而RenderThread承担了比较多的绘制工作,分担了主线程很多压力,提高了UI线程的响应速度。
4. 未来
在Android 6.0的时候,Android在gxinfo添加了更详细的信息;在Android 7.0又对HWUI进行了一些重构,而且支持了Vulkan;在Android P支持了Vulkun 1.1。我相信在未来不久的Android Q,更好地支持Vulkan将是一个必然的方向。
总的来说,UI渲染的优化必然会朝着两个方向。一个是进一步压榨硬件的性能,让UI可以更加流畅。一个是改进或者增加更多的分析工具,帮助我们更容易地发现以及定位问题。
总结
今天我们通过Android渲染的演进历程,一步一步加深对Android渲染机制的理解,这对我们UI渲染优化工作会有很大的帮助。
但是凡事都要两面看,硬件加速绘制虽然极大地提高了Android系统显示和刷新的速度,但它也存在那么一些问题。一方面是内存消耗,OpenGL API调用以及Graphic Buffer缓冲区会占用至少几MB的内存,而实际上会占用更多一些。不过最严重的还是兼容性问题,部分绘制函数不支持是其中一部分原因,更可怕的是硬件加速绘制流程本身的Bug。由于Android每个版本对渲染模块都做了一些重构,在某些场景经常会出现一些莫名其妙的问题。
例如每个应用总有那么一些libhwui.so相关的崩溃,曾经这个崩溃占我们总崩溃的20%以上。我们内部花了整整一个多月,通过发了几十个灰度,使用了Inline Hook、GOT Hook等各种手段。最后才定位到问题的原因是系统内部RenderThread与主线程数据同步的Bug,并通过规避的方法得以解决。
课后作业
人们都说iOS系统更加流畅,对于Android的UI渲染你了解多少呢?在日常工作中,你是使用哪种方式做UI适配的,觉得目前在渲染方面最大的痛点是什么?欢迎留言跟我和其他同学一起讨论。
在UI渲染这方面,其实我也并不是非常资深,针对文中所讲的,如果你有更好的思路和想法,一定给我留言,欢迎留下你的想法。
Android渲染架构非常庞大,而且演进得也非常快。如果你还有哪些不理解的地方,可以进一步阅读下面的参考资料:
-
2018 Google I/O:Drawn out: how Android renders
-
官方文档:Android 图形架构
-
浏览器渲染:一颗像素的诞生
欢迎你点击“请朋友读”,把今天的内容分享给好友,邀请他一起学习。最后别忘了在评论区提交今天的作业,我也为认真完成作业的同学准备了丰厚的“学习加油礼包”,期待与你一起切磋进步哦。