12 KiB
协议专栏特别福利 | 答疑解惑第四期
你好,我是刘超。
第四期答疑涵盖第14讲至第21讲的内容。我依旧对课后思考题和留言中比较有代表性的问题作出回答。你可以点击文章名,回到对应的章节复习,也可以继续在留言区写下你的疑问,我会持续不断地解答。希望对你有帮助。
《第14讲 | HTTP协议:看个新闻原来这么麻烦》
课后思考题
QUIC是一个精巧的协议,所以它肯定不止今天我提到的四种机制,你知道还有哪些吗?
云学讲了一个QUIC的特性。

QUIC还有其他特性,一个是快速建立连接。这个我放在下面HTTPS的时候一起说。另一个是拥塞控制,QUIC协议当前默认使用了TCP协议的CUBIC(拥塞控制算法)。
你还记得TCP的拥塞控制算法吗?每当收到一个ACK的时候,就需要调整拥塞窗口的大小。但是这也造成了一个后果,那就是RTT比较小的,窗口增长快。
然而这并不符合当前网络的真实状况,因为当前的网络带宽比较大,但是由于遍布全球,RTT也比较长,因而基于RTT的窗口调整策略,不仅不公平,而且由于窗口增加慢,有时候带宽没满,数据就发送完了,因而巨大的带宽都浪费掉了。
CUBIC进行了不同的设计,它的窗口增长函数仅仅取决于连续两次拥塞事件的时间间隔值,窗口增长完全独立于网络的时延RTT。
CUBIC的窗口大小以及变化过程如图所示。
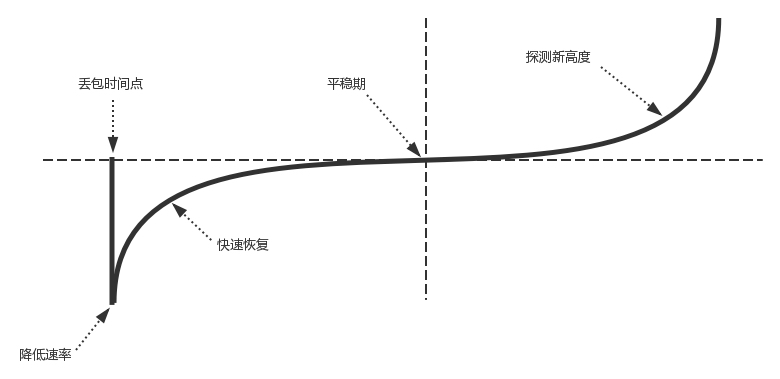
当出现丢包事件时,CUBIC会记录这时的拥塞窗口大小,把它作为Wmax。接着,CUBIC会通过某个因子执行拥塞窗口的乘法减小,然后,沿着立方函数进行窗口的恢复。
从图中可以看出,一开始恢复的速度是比较快的,后来便从快速恢复阶段进入拥塞避免阶段,也即当窗口接近Wmax的时候,增加速度变慢;立方函数在Wmax处达到稳定点,增长速度为零,之后,在平稳期慢慢增长,沿着立方函数的开始探索新的最大窗口。
留言问题
HTTP的keepalive模式是什么样?

在没有keepalive模式下,每个HTTP请求都要建立一个TCP连接,并且使用一次之后就断开这个TCP连接。
使用keepalive之后,在一次TCP连接中可以持续发送多份数据而不会断开连接,可以减少TCP连接建立次数,减少TIME_WAIT状态连接。
然而,长时间的TCP连接容易导致系统资源无效占用,因而需要设置正确的keepalive timeout时间。当一个HTTP产生的TCP连接在传送完最后一个响应后,还需要等待keepalive timeout秒后,才能关闭这个连接。如果这个期间又有新的请求过来,可以复用TCP连接。
《第15讲 | HTTPS协议:点外卖的过程原来这么复杂》
课后思考题
HTTPS 协议比较复杂,沟通过程太繁复,这样会导致效率问题,那你知道有哪些手段可以解决这些问题吗?
通过HTTPS访问的确复杂,至少经历四个阶段:DNS查询、TCP连接建立、TLS连接建立,最后才是HTTP发送数据。我们可以一项一项来优化这个过程。
首先如果使用基于UDP的QUIC,可以省略掉TCP的三次握手。至于TLS的建立,如果按文章中基于TLS 1.2的,双方要交换key,经过两个来回,也即两个RTT,才能完成握手。但是咱们讲IPSec的时候,讲过通过共享密钥、DH算法进行握手的场景。
在TLS 1.3中,握手过程中移除了ServerKeyExchange和ClientKeyExchange,DH参数可以通过key_share进行传输。这样只要一个来回,就可以搞定RTT了。
对于QUIC来讲,也可以这样做。当客户端首次发起QUIC连接时,会发送一个client hello消息,服务器会回复一个消息,里面包括server config,类似于TLS1.3中的key_share交换。当客户端获取到server config以后,就可以直接计算出密钥,发送应用数据了。
留言问题
1.HTTPS的双向认证流程是什么样的?
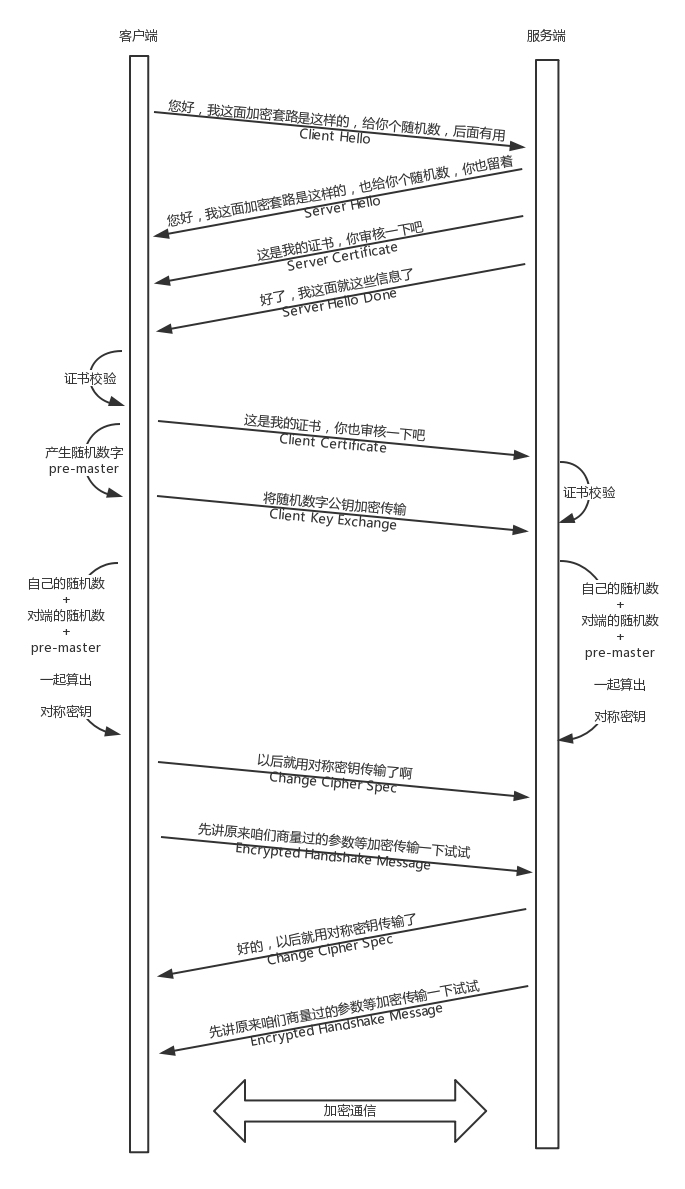
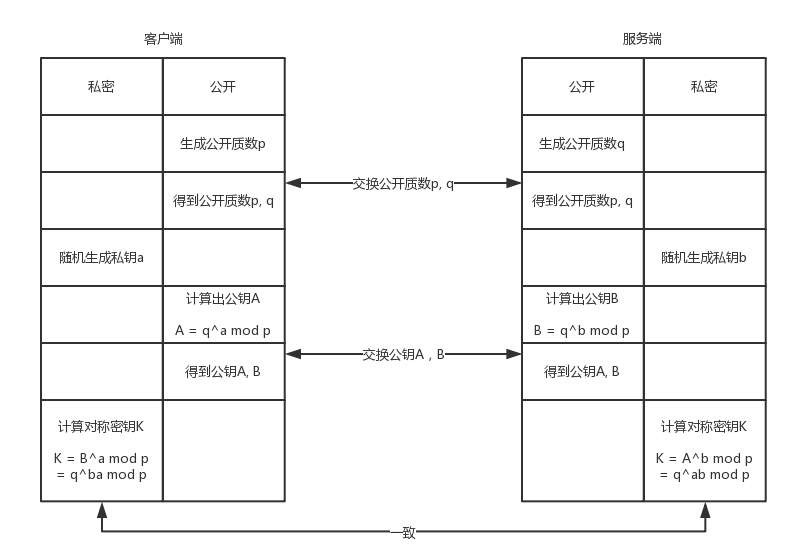
2.随机数和premaster的含义是什么?
《第16讲 | 流媒体协议:如何在直播里看到美女帅哥?》
课后思考题
你觉得基于 RTMP 的视频流传输的机制存在什么问题?如何进行优化?
Jason的回答很对。

Jealone的回答更加具体。

当前有基于自研UDP协议传输的,也有基于QUIC协议传输的。
留言问题
RTMP建立连接的序列是什么样的?

的确,这个图我画错了,我重新画了一个。
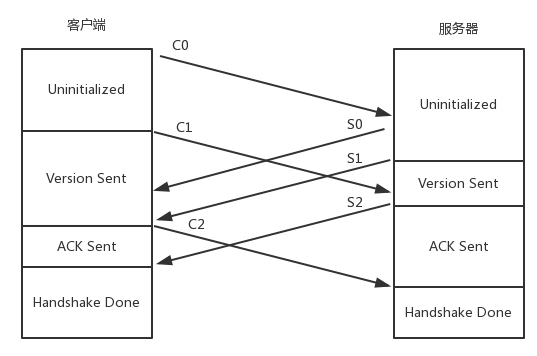
不过文章中这部分的文字描述是没问题的。
客户端发送C0、C1、 C2,服务器发送S0、 S1、 S2。
首先,客户端发送C0表明自己的版本号,不必等对方的回复,然后发送C1表明自己的时间戳。
服务器只有在收到C0的时候,才能返回S0,表明自己的版本号。如果版本不匹配,可以断开连接。
服务器发送完S0后,也不用等什么,就直接发送自己的时间戳S1。客户端收到S1的时候,发一个知道了对方时间戳的ACK C2。同理服务器收到C1的时候,发一个知道了对方时间戳的ACK S2。
于是,握手完成。
《第17讲 | P2P协议:我下小电影,99%急死你》
课后思考题
除了这种去中心化分布式哈希的算法,你还能想到其他的应用场景吗?

留言问题
99%卡住的原因是什么?

《第18讲 | DNS协议:网络世界的地址簿》
课后思考题
全局负载均衡使用过程中,常常遇到失灵的情况,你知道具体有哪些情况吗?对应应该怎么来解决呢?

留言问题
如果权威DNS连不上,怎么办?

一般情况下,DNS是基于UDP协议的。在应用层设置一个超时器,如果UDP发出没有回应,则会进行重试。
DNS服务器一般也是高可用的,很少情况下会挂。即便挂了,也会很快切换,重试一般就会成功。
对于客户端来讲,为了DNS解析能够成功,也会配置多个DNS服务器,当一个不成功的时候,可以选择另一个来尝试。
《第19讲 | HttpDNS:网络世界的地址簿也会指错路》
课后思考题
使用 HttpDNS,需要向 HttpDNS 服务器请求解析域名,可是客户端怎么知道 HttpDNS 服务器的地址或者域名呢?

《第20讲 | CDN:你去小卖部取过快递么?》
课后思考题
这一节讲了CDN使用DNS进行全局负载均衡的例子,CDN如何使用HttpDNS呢?

《第21讲 | 数据中心:我是开发商,自己拿地盖别墅》
课后思考题
对于数据中心来讲,高可用是非常重要的,每个设备都要考虑高可用,那跨机房的高可用,你知道应该怎么做吗?
其实跨机房的高可用分两个级别,分别是同城双活和异地灾备。
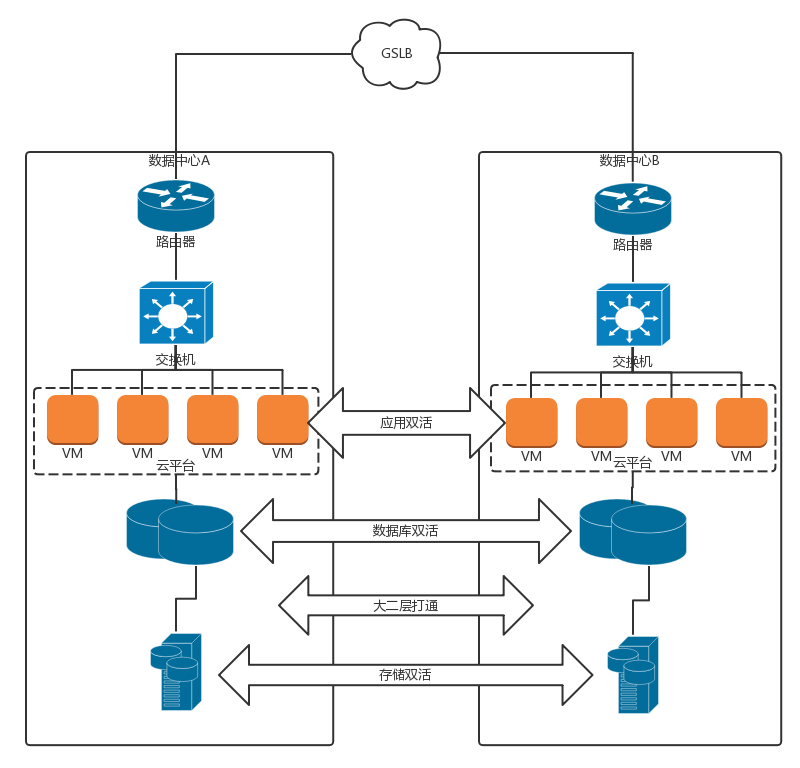
同城双活,就是在同一个城市,距离大概30km到100km的两个数据中心之间,通过高速专线互联的方式,让两个数据中心形成一个大二层网络。
同城双活最重要的是,数据如何从一个数据中心同步到另一个数据中心,并且在一个数据中心故障的时候,实现存储设备的切换,保证状态能够快速切换到另一个数据中心。在高速光纤互联情况下,主流的存储厂商都可以做到在一定距离之内的两台存储设备的近实时同步。数据双活是一切双活的基础。
基于双数据中心的数据同步,可以形成一个统一的存储池,从而数据库层在共享存储池的情况下可以近实时地切换,例如Oracle RAC。
虚拟机在统一的存储池的情况下,也可以实现跨机房的HA,在一个机房切换到另一个机房。
SLB负载均衡实现同一机房的各个虚拟机之间的负载均衡。GSLB可以实现跨机房的负载均衡,实现外部访问的切换。
如果在两个数据中心距离很近,并且大二层可通的情况下,也可以使用VRRP协议,通过VIP方式进行外部访问的切换。
下面我们说异地灾备。
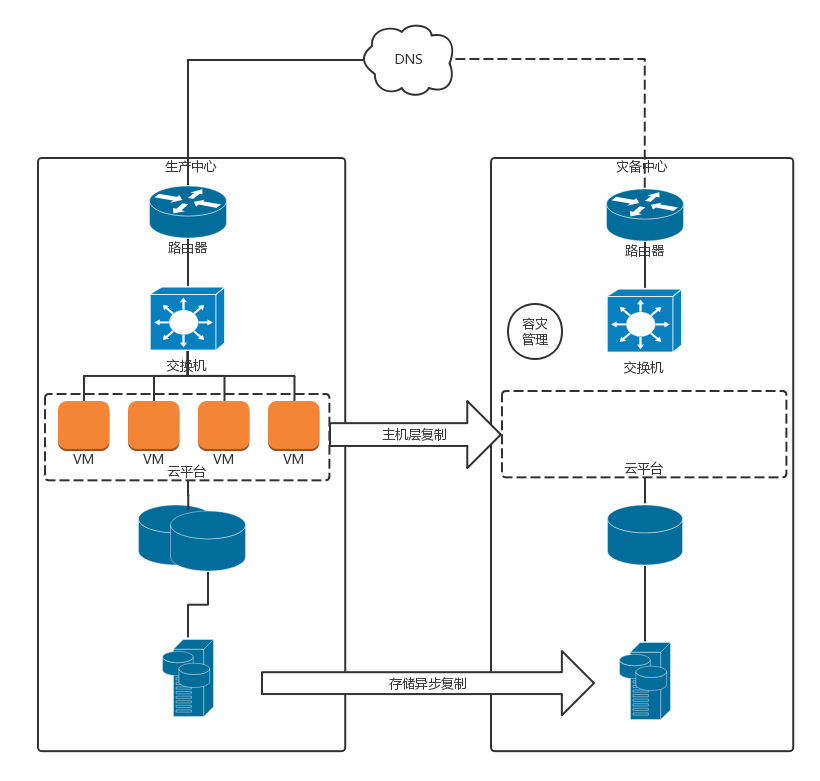
异地灾备的第一大问题还是数据的问题,也即生产数据中心的数据如何备份到容灾数据中心。由于异地距离比较远,不可能像双活一样采取近同步的方式,只能通过异步的方式进行同步。可以预见的问题是,容灾切换的时候,数据会丢失一部分。
由于容灾数据中心平时是不用的,不是所有的业务都会进行容灾,否则成本太高。
对于数据的问题,我比较建议从业务层面进行容灾。由于数据同步会比较慢,可以根据业务需求高优先级同步重要的数据,因而容灾的层次越高越好。
例如,有的用户完全不想操心,直接使用存储层面的异步复制。对于存储设备来讲,它是无法区分放在存储上的虚拟机,哪台是重要的,哪台是不重要的,只会完全根据块进行复制,很可能就会先复制了不重要的虚拟机。
如果用户想对虚拟机做区分,则可以使用虚拟机层面的异步复制。用户知道哪些虚拟机更重要一些,哪些虚拟机不重要,则可以先同步重要的虚拟机。
对业务来讲,如果用户可以根据业务层情况,在更细的粒度上区分数据是否重要。重要的数据,例如交易数据,需要优先同步;不重要的数据,例如日志数据,就不需要优先同步。
在有异地容灾的情况下,可以平时进行容灾演练,看容灾数据中心是否能够真正起作用,别容灾了半天,最后用的时候掉链子。
感谢第14讲至第21讲中对内容有深度思考和提出问题的同学。我会为你们送上奖励礼券和知识图谱。(稍后运营同学会发送短信通知。)
欢迎你继续提问!
