16 KiB
06 | 分片机制:为什么说Range是更好的分片策略?
你好,我是王磊,你也可以叫我Ivan。
在这一讲的开头,我想请你思考一个问题,你觉得在大规模的业务应用下,单体数据库遇到的主要问题是什么?对,首先就是写入性能不足,这个我们在第4讲也说过,另外还有存储方面的限制。而分片就是解决性能和存储这两个问题的关键设计,甚至不仅是分布式数据库,在所有分布式存储系统中,分片这种设计都是广泛存在的。
所以今天,就让我们好好了解一下,分片到底是怎么回事儿。
什么是分片
分片在不同系统中有各自的别名,Spanner和YugabyteDB中被称为Tablet,在HBase和TiDB中被称为Region,在CockraochDB中被称为Range。无论叫什么,概念都是一样的,分片是一种水平切分数据表的方式,它是数据记录的集合,也是数据表的组成单位。
分布式数据库的分片与单体数据库的分区非常相似,区别在于:分区虽然可以将数据表按照策略切分成多个数据文件,但这些文件仍然存储在单节点上;而分片则可以进一步根据特定规则将切分好的文件分布到多个节点上,从而实现更强大的存储和计算能力。
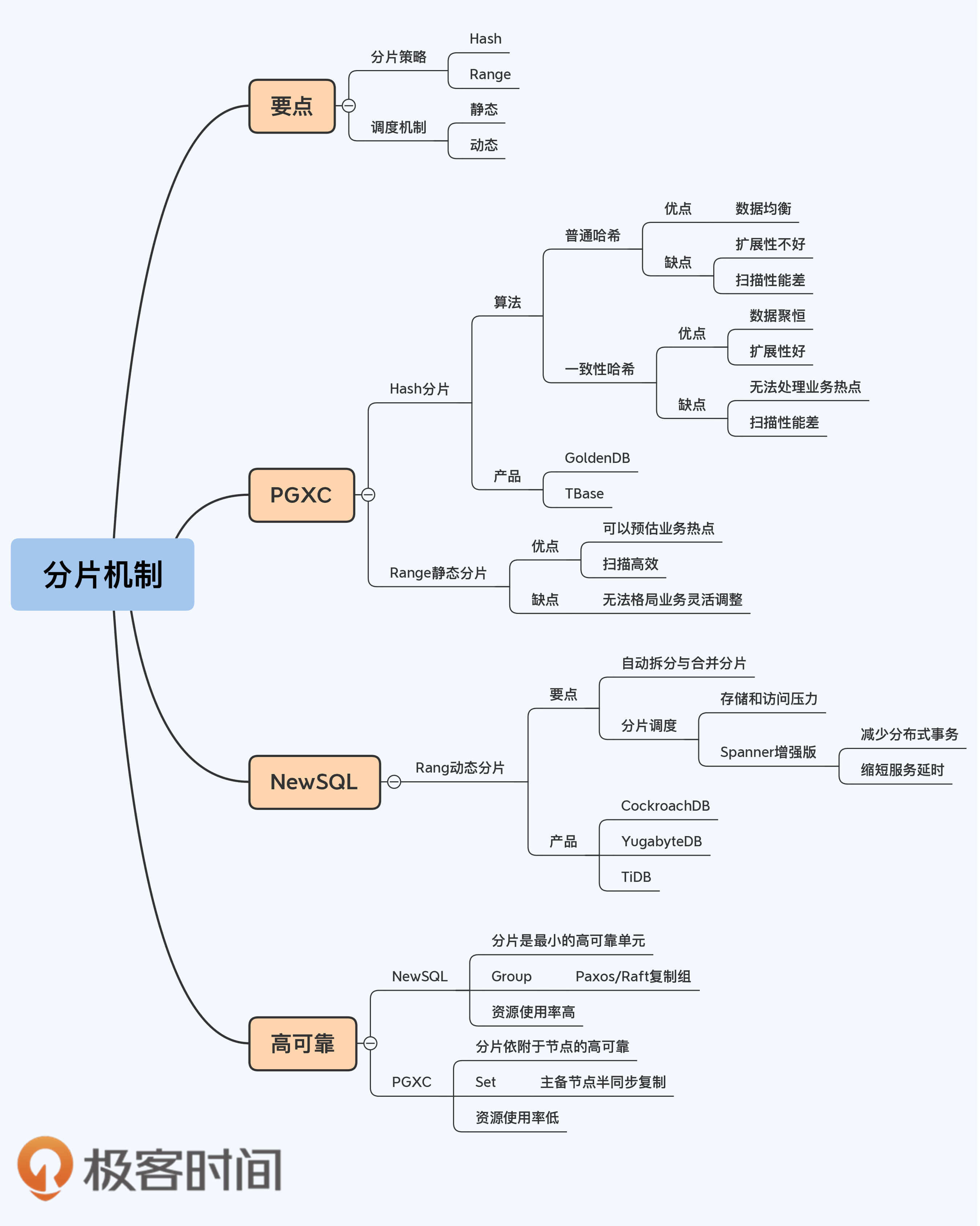
分片机制通常有两点值得关注:
- 分片策略
主要有Hash(哈希)和Range(范围)两种。你可能还听到过Key和List,其实Key和List可以看作是Hash和Range的特殊情况,因为机制类似,我们这里就不再细分了。
- 分片的调度机制
分为静态与动态两种。静态意味着分片在节点上的分布基本是固定的,即使移动也需要人工的介入;动态则是指通过调度管理器基于算法在各节点之间自动地移动分片。
我把分片机制的两个要点与第5讲提到的两种架构风格对应了一下,放到下面的表格中,希望能给你带来更直观的感受。
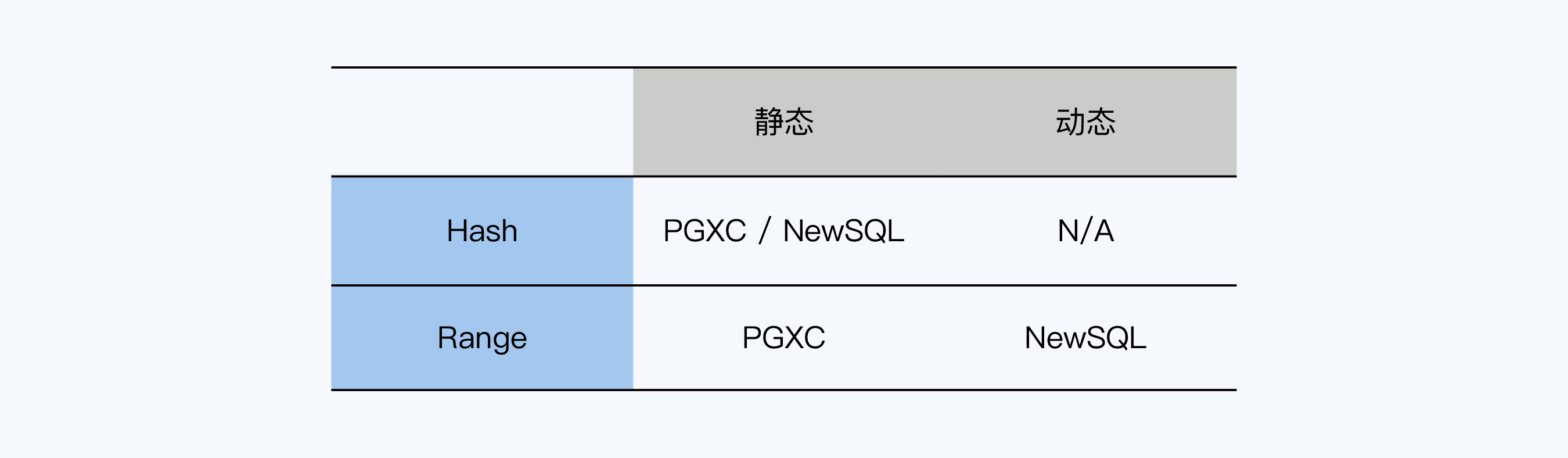
从表格中可以看出,PGXC只支持静态的Hash分片和Range分片,实现机制较为简单,所以,我就从这里开始展开吧。
PGXC
Hash分片
Hash分片,就是按照数据记录中指定关键字的Hash值将数据记录映射到不同的分片中。我画了一张图来表示Hash分片的过程。
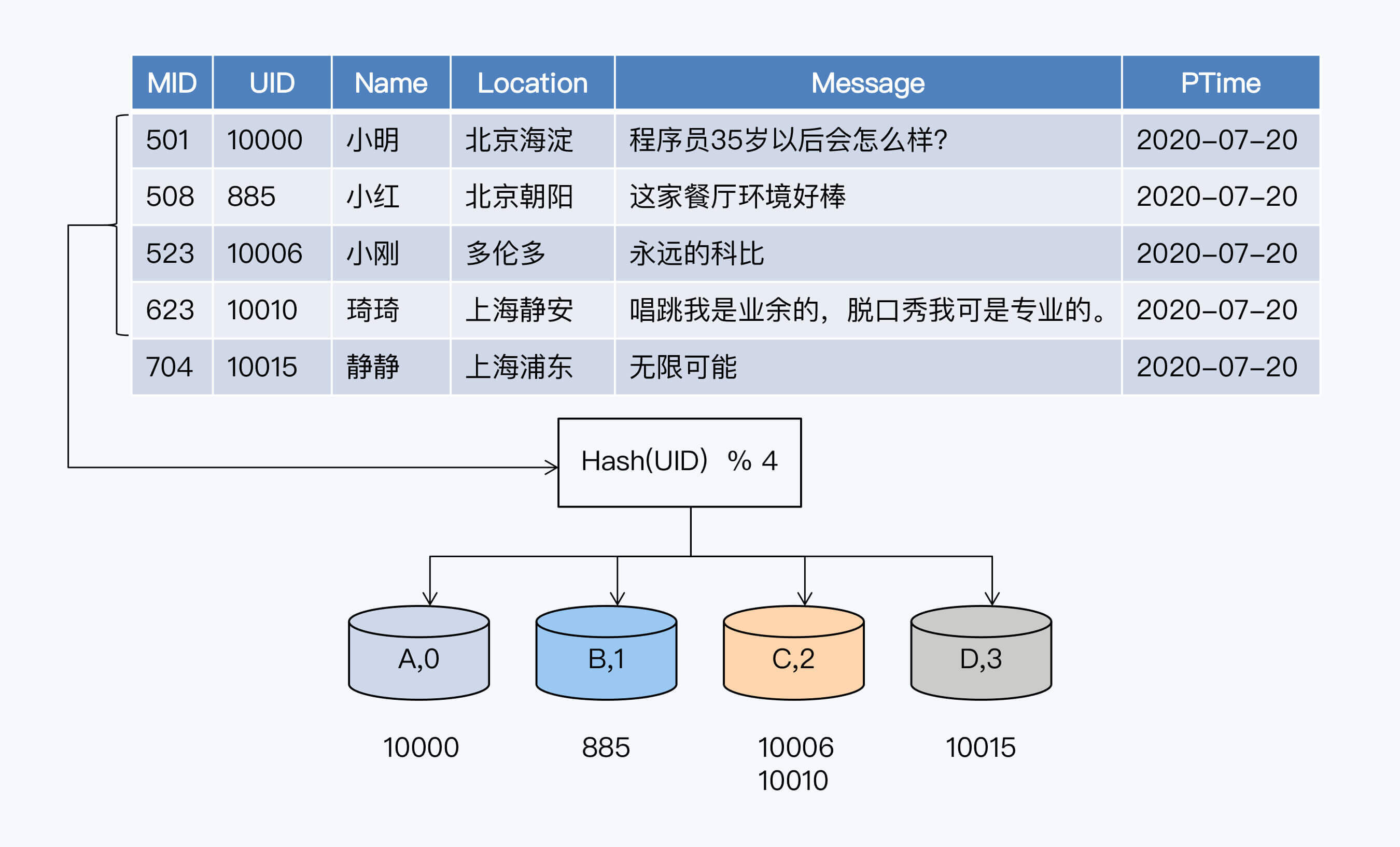
图中的表格部分显示了一个社交网站的记录表,包括主键、用户ID、分享内容和分享时间等字段。假设以用户ID作为关键字进行分片,系统会通过一个Hash函数计算用户ID的Hash值而后取模,分配到对应的分片。模为4的原因是系统一共有四个节点,每个节点作为一个分片。
因为Hash计算会过滤掉数据原有的业务特性,所以可以保证数据非常均匀地分布到多个分片上,这是Hash分片最大的优势,而且它的实现也很简洁。但示例中采用的分片方法直接用节点数作为模,如果系统节点数量变动,模也随之改变,数据就要重新Hash计算,从而带来大规模的数据迁移。显然,这种方式对于扩展性是非常不友好的。
那接下来的问题就是,我们需要找一个方法提升系统的扩展性。你可能猜到了,这就是一致性Hash,该算法首次提出是在论文“Consistent Hashing and Random Trees : Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web”当中。
要在工业实践中应用一致性Hash算法,首先会引入虚拟节点,每个虚拟节点就是一个分片。为了便于说明,我们在这个案例中将分片数量设定为16。但实际上,因为分片数量决定了集群的最大规模,所以它通常会远大于初始集群节点数。
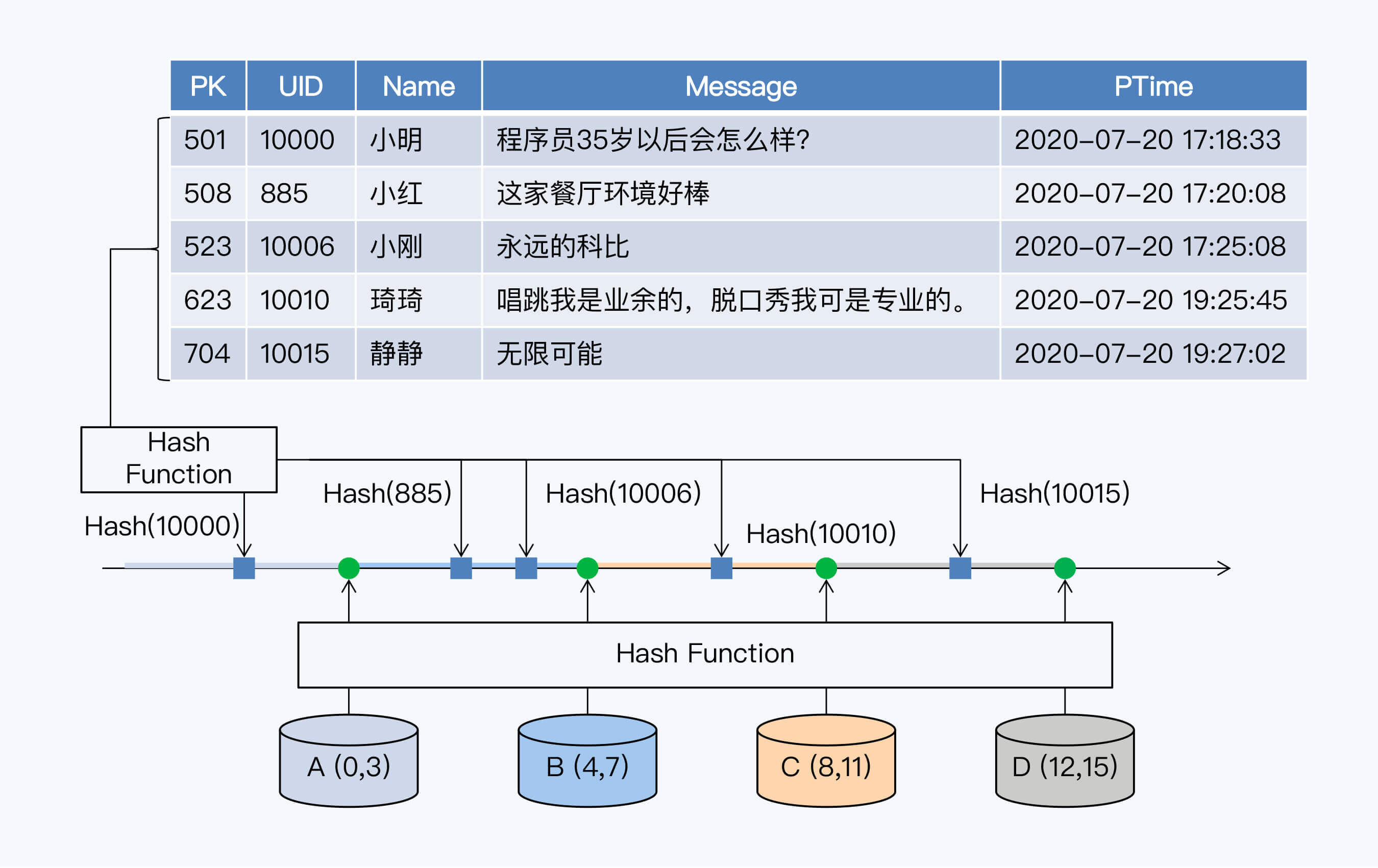
16个分片构成了整个Hash空间,数据记录的主键和节点都要通过Hash函数映射到这个空间。这个Hash空间是一个Hash环。我们换一种方式画图,可以看得更清楚些。
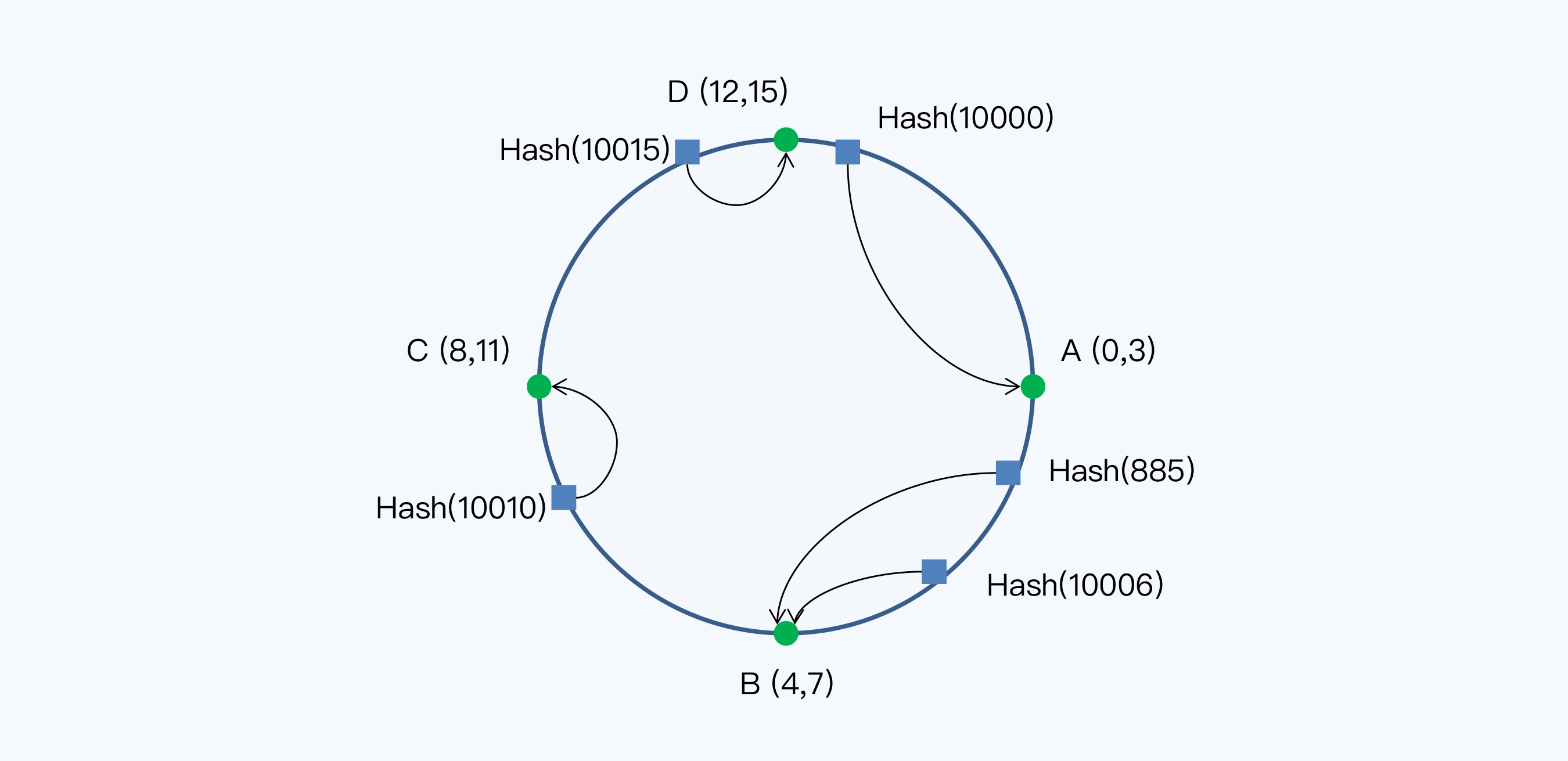
节点和数据都通过Hash函数映射到Hash环上,数据按照顺时针找到最近的节点。
当我们新增一台服务器,即节点E时,受影响的数据仅仅是新服务器到其环空间中前一台服务器(即沿着逆时针方向的第一台服务器)之间数据。结合我们的示例,只有小红分享的消息从节点B被移动到节点E,其他节点的数据保持不变。此后,节点B只存储Hash值6和7的消息,节点E存储Hash值4和5的消息。
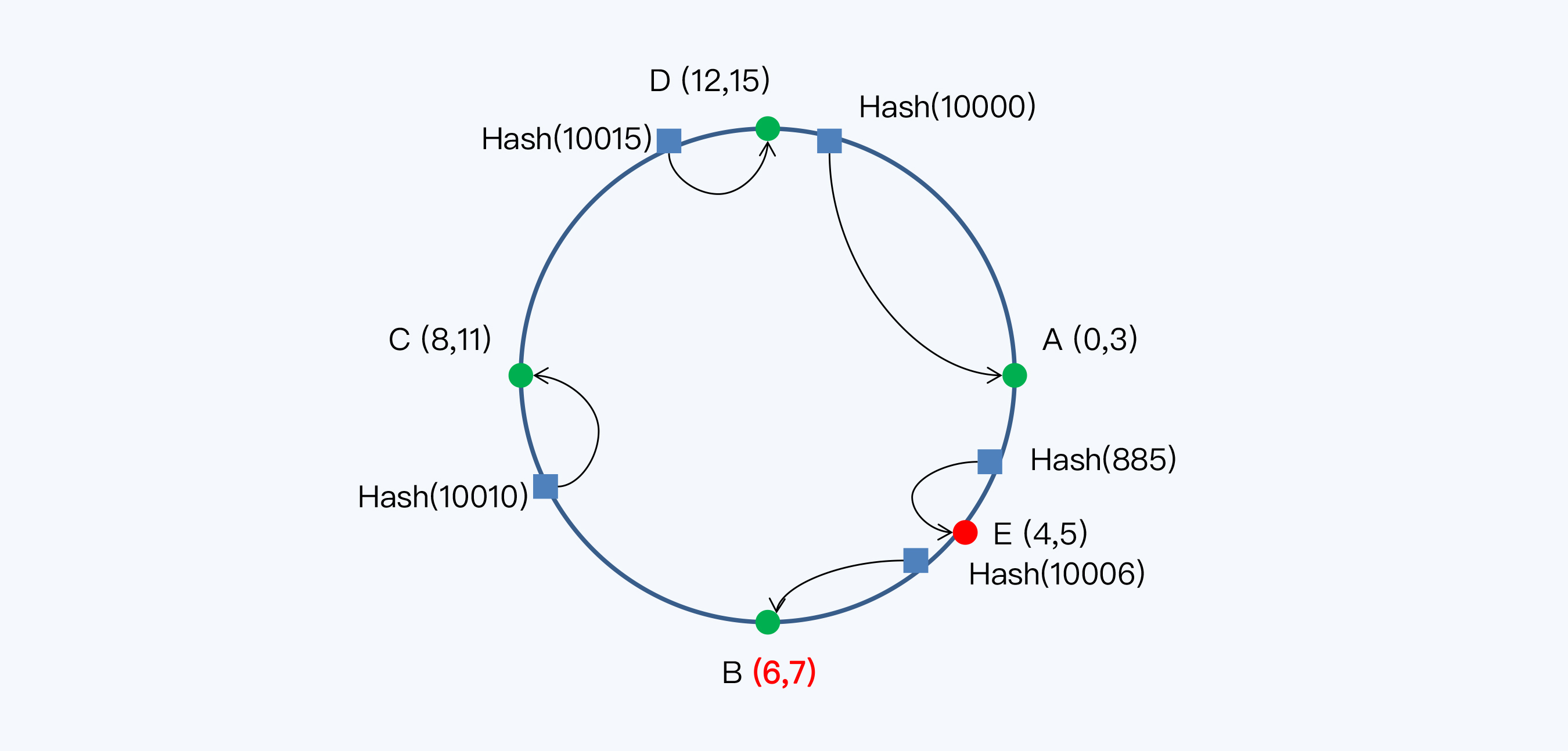
Hash函数的优点是数据可以较为均匀地分配到各节点,并发写入性能更好。
本质上,Hash分片是一种静态分片方式,必须在设计之初约定分片的最大规模。同时,因为Hash函数已经过滤掉了业务属性,也很难解决访问业务热点问题。所谓业务热点,就是由于局部的业务活跃度较高,形成系统访问上的热点。这种情况普遍存在于各类应用中,比如电商网站的某个商品卖得比较好,或者外卖网站的某个饭店接单比较多,或者某个银行网点的客户业务量比较大等等。
Range静态分片
与Hash分片不同,Range分片的特点恰恰是能够加入对于业务的预估。例如,我们用“Location”作为关键字进行分片时,不是以统一的行政级别为标准。因为注册地在北京、上海的用户更多,所以这两个区域可以按照区县设置分片,而海外用户较少,可以按国家设置为分片。这样,分片间的数据更加平衡。

但是,这种方式依然是静态的,如果海外业务迅速增长,服务海外用户的分片将承担更大的压力,可能导致性能下降,用户体验不佳。
相对Hash分片,Range分片的适用范围更加广泛。其中一个非常重要的原因是,Range分片可以更高效地扫描数据记录,而Hash分片由于数据被打散,扫描操作的I/O开销更大。但是,PGXC的Range分片受限于单体数据库的实现机制,很难随数据变动和负载变化而调整。
虽然有些PGXC同时支持两种分片方式,但Hash分片仍是主流,比如GoldenDB默认使用Hash分片,而TBase仅支持Hash分片。
NewSQL
总体上,NewSQL也是支持Hash和Range两种分片方式的。具体就产品来说,CockroachDB和YugabyteDB同时支持两种方式,TiDB仅支持Range分片。
NewSQL数据库的Hash分片也是静态的,所以与PGXC差别不大,这里就不再赘述了。接下来,我们重点学习下Range动态分片。
Range动态分片
NewSQL的Range分片,多数是用主键作为关键字来分片的,当然主键可以是系统自动生成的,也可以是用户指定的。既然提供了用户指定主键的方式,那么理论上可以通过设定主键的产生规则,控制数据流向哪个分片。但是,主键必须保证唯一性,甚至是单调递增的,导致这种控制就会比较复杂,使用成本较高。所以,我们基本可以认为,分片是一个系统自动处理的过程,用户是感知不到的。这样做的好处显然是提升了系统的易用性。
我们将NewSQL的Range分片称为动态分片,主要有两个原因:
- 分片可以自动完成分裂与合并
当单个分片的数据量超过设定值时,分片可以一分为二,这样就可以保证每个分片的数据量较为均衡。多个数据量较少的分片,会在一定的周期内被合并为一个分片。
还是回到我们社交网站这个例子,根据消息的数量来自动分片,我们可以得到R1、R2、R3三个分片。

分片也会被均衡地调度到各个节点上,节点间的数据量也保持总体平衡。
- 可以根据访问压力调度分片
我们看到系统之所以尽量维持分片之间,以及节点间的数据量均衡,存储的原因外,还可以更大概率地将访问压力分散到各个节点上。但是,有少量的数据可能会成为访问热点,就是上面提到的业务热点,从而打破这种均衡。比如,琦琦和静静都是娱乐明星,有很多粉丝关注她们分享的内容,其访问量远超过普通人。这时候,系统会根据负载情况,将R2和R3分别调度到不同的节点,来均衡访问压力。
存储均衡和访问压力均衡,是NewSQL分片调度机制普遍具备的两项能力。此外,还有两项能力在Spanner论文中被提及,但在其他产品中没有看到工程化实现。
第一是减少分布式事务。
对分布式数据库来说,有一个不争的事实,那就是分布式事务的开销永远不会小于单节点本地事务的开销。因此,所有分布式数据库都试图通过减少分布式事务来提升性能。
Spanner在Tablet,也就是Range分片,之下增加了目录(Directory),作为数据调度的最小单位,它的调度范围是可以跨Tablet的。通过调度Directory可以将频繁参与同样事务的数据,转移到同一个Tablet下,从而将分布式事务转换为本地事务。
第二是缩短服务延时。
对于全球化部署的分布式数据库,数据可能存储在相距很远的多个数据中心,如果用户需要访问远端机房的数据,操作延时就比较长,这受制于数据传输速度。而Spanner可以将Directory调度到靠近用户的数据中心,缩短数据传输时间。当然,这里的调度对象都是数据的主副本,跨中心的数据副本仍然存在,负责保证系统整体的高可靠性。
Directory虽然带来新的特性,但显然也削弱了分片的原有功能,分片内的记录不再连续,扫描要付出更大成本。而减少分布式事务和靠近客户端位置这本身就是不能兼顾的,再加上存储和访问压力,分片调度机制要在四个目标间进行更复杂的权衡。
Spanner的这种设计能达到什么样的实际效果呢?我们现在还需要继续等待和观察。
分片与高可靠的关系
高可靠是分布式数据库的重要特性,分片是数据记录的最小组织单位,也必须是高可靠的。
NewSQL与PGXC的区别在于,对于NewSQL来说,分片是高可靠的最小单元;而对于PGXC,分片的高可靠要依附于节点的高可靠。
NewSQL的实现方式是复制组(Group)。在产品层面,通常由一个主副本和若干个副本组成,通过Raft或Paxos等共识算法完成数据同步,称为Raft Group或Paxos Group,所以我们简称这种方式为Group。因为不相关的数据记录会被并发操作,所以同一时刻有多个Group在工作。因此,NewSQL通常支持Multi Raft Group或者Multi Paxos Group。这里,我们先忽略Multi Paxos的另一个意思。
每个Group是独立运行的,只是共享相同的网络和节点资源,所以不同复制组的主副本是可以分布在不同节点的。
PGXC的最小高可靠单元由一个主节点和多个备节点组成,我们借用TDSQL中的术语,将其称为Set。一个PGXC是由多个Set组成。Set的主备节点间复制,多数采用半同步复制,平衡可靠性和性能。这意味着,所有分片的主副本必须运行在Set的主节点上。
从架构设计角度看,Group比Set更具优势,原因主要有两个方面。首先,Group的高可靠单元更小,出现故障时影响的范围就更小,系统整体的可靠性就更高。其次,在主机房范围内,Group的主副本可以在所有节点上运行,资源可以得到最大化使用,而Set模式下,占大多数的备节点是不提供有效服务的,资源白白浪费掉。
小结
好吧,今天的内容就到这里了,我们一起回顾下这节课的重点。
- 分片是分布式数据库的关键设计,以此实现多节点的存储和访问能力。
- 分片机制的两个要点是分片策略和调度机制,分片策略包括Hash和Range两种,调度机制则分为静态和动态。
- PGXC使用单体数据库作为数据节点,往往只实现了静态分片。它的分片策略支持Hash和Range两种,其中Hash一般是指一致性Hash,可以最大程度规避节点扩缩带来的影响。Hash分片写性能出众,但查询性能差,Range则相反。
- NewSQL的默认分片策略通常是Range分片。分片调度机制为了实现存储平衡和访问压力平衡的目标,会将分片动态调度到各个节点。Spanner的设计又将在分片下拓展了Directory,通过对Directory的调度实现减少分布式事务和缩短延时的目标,但在其他分布式数据库中尚未看到对应的实现。
- NewSQL架构下,分片采用Paxos或Raft算法可以构成复制组,这种复制机制相比PGXC的主备节点复制,提供了更高的可靠性,资源使用也更加高效。
到这里你应该已经大体了解了分布式数据库分片机制。我们说Range是更好的分片策略,就是因为Range分片有条件做到更好的动态调度,只有动态了,才能自适应各种业务场景下的数据变化,平衡存储、访问压力、分布式事务和访问链路延时等多方面的诉求。从我个人的观点来说,NewSQL的Range分片方式更加优雅,随着单体数据库底层数据同步机制的改进,未来PGXC可能也会向这种方式靠拢。
如果你想更深入地了解Range分片机制,可以研究下BigTable的论文。同时,因为HBase是业界公认的BigTable开源实现,所以你在它的官方文档也能找到很多有用的内容。
思考题
Range分片的优势是动态调度,这就是说分片存储在哪个节点上是不断变化的。这时,客户端首先要知道分片的位置,就要先访问分片的元数据。你觉得这些元数据应该如何存储呢?是存储在某个中心点,还是分散在所有节点上呢?如果有多个副本,又该如何同步呢?
如果你想到了答案,又或者是触发了你对相关问题的思考,都可以在评论区和我聊聊,我会在答疑篇更系统地回复这个问题。如果你身边的朋友也对数据的分片机制,这个话题感兴趣,你也可以把今天这一讲分享给他,我们一起讨论。
学习资料
David Karge et al.: Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web
Fay Chang et al.: Bigtable: A Distributed Storage System for Structured Data
HBase: Apache HBase ™ Reference Guide
James C. Corbett et al.: Spanner: Google’s Globally-Distributed Database