|
|
# 17 | 别以为“自动挡”就不可能出现OOM
|
|
|
|
|
|
你好,我是朱晔。今天,我要和你分享的主题是,别以为“自动挡”就不可能出现OOM。
|
|
|
|
|
|
这里的“自动挡”,是我对Java自动垃圾收集器的戏称。的确,经过这么多年的发展,Java的垃圾收集器已经非常成熟了。有了自动垃圾收集器,绝大多数情况下我们写程序时可以专注于业务逻辑,无需过多考虑对象的分配和释放,一般也不会出现OOM。
|
|
|
|
|
|
但,内存空间始终是有限的,Java的几大内存区域始终都有OOM的可能。相应地,Java程序的常见OOM类型,可以分为堆内存的OOM、栈OOM、元空间OOM、直接内存OOM等。几乎每一种OOM都可以使用几行代码模拟,市面上也有很多资料在堆、元空间、直接内存中分配超大对象或是无限分配对象,尝试创建无限个线程或是进行方法无限递归调用来模拟。
|
|
|
|
|
|
但值得注意的是,我们的业务代码并不会这么干。所以今天,我会从内存分配意识的角度通过一些案例,展示业务代码中可能导致OOM的一些坑。这些坑,或是因为我们意识不到对象的分配,或是因为不合理的资源使用,或是没有控制缓存的数据量等。
|
|
|
|
|
|
在[第3讲](https://time.geekbang.org/column/article/210337)介绍线程时,我们已经看到了两种OOM的情况,一是因为使用无界队列导致的堆OOM,二是因为使用没有最大线程数量限制的线程池导致无限创建线程的OOM。接下来,我们再一起看看,在写业务代码的过程中,还有哪些意识上的疏忽可能会导致OOM。
|
|
|
|
|
|
## 太多份相同的对象导致OOM
|
|
|
|
|
|
我要分享的第一个案例是这样的。有一个项目在内存中缓存了全量用户数据,在搜索用户时可以直接从缓存中返回用户信息。现在为了改善用户体验,需要实现输入部分用户名自动在下拉框提示补全用户名的功能(也就是所谓的自动完成功能)。
|
|
|
|
|
|
在[第10讲](https://time.geekbang.org/column/article/216778)介绍集合时,我提到对于这种快速检索的需求,最好使用Map来实现,会比直接从List搜索快得多。
|
|
|
|
|
|
为实现这个功能,我们需要一个HashMap来存放这些用户数据,Key是用户姓名索引,Value是索引下对应的用户列表。举一个例子,如果有两个用户aa和ab,那么Key就有三个,分别是a、aa和ab。用户输入字母a时,就能从Value这个List中拿到所有字母a开头的用户,即aa和ab。
|
|
|
|
|
|
在代码中,在数据库中存入1万个测试用户,用户名由a~j这6个字母随机构成,然后把每一个用户名的前1个字母、前2个字母以此类推直到完整用户名作为Key存入缓存中,缓存的Value是一个UserDTO的List,存放的是所有相同的用户名索引,以及对应的用户信息:
|
|
|
|
|
|
```
|
|
|
//自动完成的索引,Key是用户输入的部分用户名,Value是对应的用户数据
|
|
|
private ConcurrentHashMap<String, List<UserDTO>> autoCompleteIndex = new ConcurrentHashMap<>();
|
|
|
|
|
|
@Autowired
|
|
|
private UserRepository userRepository;
|
|
|
|
|
|
@PostConstruct
|
|
|
public void wrong() {
|
|
|
//先保存10000个用户名随机的用户到数据库中
|
|
|
userRepository.saveAll(LongStream.rangeClosed(1, 10000).mapToObj(i -> new UserEntity(i, randomName())).collect(Collectors.toList()));
|
|
|
|
|
|
//从数据库加载所有用户
|
|
|
userRepository.findAll().forEach(userEntity -> {
|
|
|
int len = userEntity.getName().length();
|
|
|
//对于每一个用户,对其用户名的前N位进行索引,N可能是1~6六种长度类型
|
|
|
for (int i = 0; i < len; i++) {
|
|
|
String key = userEntity.getName().substring(0, i + 1);
|
|
|
autoCompleteIndex.computeIfAbsent(key, s -> new ArrayList<>())
|
|
|
.add(new UserDTO(userEntity.getName()));
|
|
|
}
|
|
|
});
|
|
|
log.info("autoCompleteIndex size:{} count:{}", autoCompleteIndex.size(),
|
|
|
autoCompleteIndex.entrySet().stream().map(item -> item.getValue().size()).reduce(0, Integer::sum));
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
对于每一个用户对象UserDTO,除了有用户名,我们还加入了10K左右的数据模拟其用户信息:
|
|
|
|
|
|
```
|
|
|
@Data
|
|
|
public class UserDTO {
|
|
|
private String name;
|
|
|
@EqualsAndHashCode.Exclude
|
|
|
private String payload;
|
|
|
|
|
|
public UserDTO(String name) {
|
|
|
this.name = name;
|
|
|
this.payload = IntStream.rangeClosed(1, 10_000)
|
|
|
.mapToObj(__ -> "a")
|
|
|
.collect(Collectors.joining(""));
|
|
|
}
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
运行程序后,日志输出如下:
|
|
|
|
|
|
```
|
|
|
[11:11:22.982] [main] [INFO ] [.t.c.o.d.UsernameAutoCompleteService:37 ] - autoCompleteIndex size:26838 count:60000
|
|
|
|
|
|
```
|
|
|
|
|
|
可以看到,一共有26838个索引(也就是所有用户名的1位、2位一直到6位有26838个组合),HashMap的Value,也就是List一共有1万个用户\*6=6万个UserDTO对象。
|
|
|
|
|
|
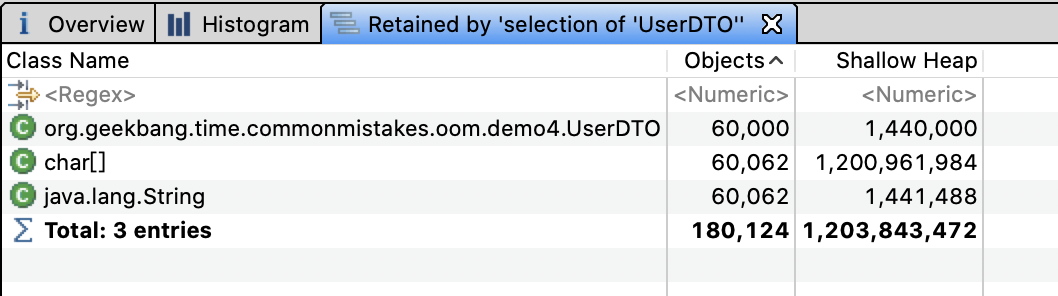
使用内存分析工具MAT打开堆dump发现,6万个UserDTO占用了约1.2GB的内存:
|
|
|
|
|
|
|
|
|
|
|
|
看到这里发现,**虽然真正的用户只有1万个,但因为使用部分用户名作为索引的Key,导致缓存的Key有26838个,缓存的用户信息多达6万个**。如果我们的用户名不是6位而是10位、20位,那么缓存的用户信息可能就是10万、20万个,必然会产生堆OOM。
|
|
|
|
|
|
尝试调大用户名的最大长度,重启程序可以看到类似如下的错误:
|
|
|
|
|
|
```
|
|
|
[17:30:29.858] [main] [ERROR] [ringframework.boot.SpringApplication:826 ] - Application run failed
|
|
|
org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'usernameAutoCompleteService': Invocation of init method failed; nested exception is java.lang.OutOfMemoryError: Java heap space
|
|
|
|
|
|
```
|
|
|
|
|
|
我们可能会想当然地认为,数据库中有1万个用户,内存中也应该只有1万个UserDTO对象,但实现的时候每次都会new出来UserDTO加入缓存,当然在内存中都是新对象。在实际的项目中,用户信息的缓存可能是随着用户输入增量缓存的,而不是像这个案例一样在程序初始化的时候全量缓存,所以问题暴露得不会这么早。
|
|
|
|
|
|
知道原因后,解决起来就比较简单了。把所有UserDTO先加入HashSet中,因为UserDTO以name来标识唯一性,所以重复用户名会被过滤掉,最终加入HashSet的UserDTO就不足1万个。
|
|
|
|
|
|
有了HashSet来缓存所有可能的UserDTO信息,我们再构建自动完成索引autoCompleteIndex这个HashMap时,就可以直接从HashSet获取所有用户信息来构建了。这样一来,同一个用户名前缀的不同组合(比如用户名为abc的用户,a、ab和abc三个Key)关联到UserDTO是同一份:
|
|
|
|
|
|
```
|
|
|
@PostConstruct
|
|
|
public void right() {
|
|
|
...
|
|
|
|
|
|
HashSet<UserDTO> cache = userRepository.findAll().stream()
|
|
|
.map(item -> new UserDTO(item.getName()))
|
|
|
.collect(Collectors.toCollection(HashSet::new));
|
|
|
|
|
|
|
|
|
cache.stream().forEach(userDTO -> {
|
|
|
int len = userDTO.getName().length();
|
|
|
for (int i = 0; i < len; i++) {
|
|
|
String key = userDTO.getName().substring(0, i + 1);
|
|
|
autoCompleteIndex.computeIfAbsent(key, s -> new ArrayList<>())
|
|
|
.add(userDTO);
|
|
|
}
|
|
|
});
|
|
|
...
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
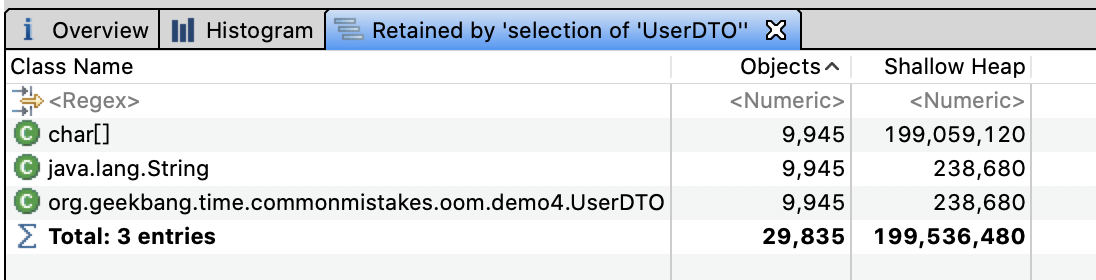
再次分析堆内存,可以看到UserDTO只有9945份,总共占用的内存不到200M。这才是我们真正想要的结果。
|
|
|
|
|
|
|
|
|
|
|
|
修复后的程序,不仅相同的UserDTO只有一份,总副本数变为了原来的六分之一;而且因为HashSet的去重特性,双重节约了内存。
|
|
|
|
|
|
值得注意的是,我们虽然清楚数据总量,但却忽略了每一份数据在内存中可能有多份。我之前还遇到一个案例,一个后台程序需要从数据库加载大量信息用于数据导出,这些数据在数据库中占用100M内存,但是1GB的JVM堆却无法完成导出操作。
|
|
|
|
|
|
我来和你分析下原因吧。100M的数据加载到程序内存中,变为Java的数据结构就已经占用了200M堆内存;这些数据经过JDBC、MyBatis等框架其实是加载了2份,然后领域模型、DTO再进行转换可能又加载了2次;最终,占用的内存达到了200M\*4=800M。
|
|
|
|
|
|
所以,**在进行容量评估时,我们不能认为一份数据在程序内存中也是一份**。
|
|
|
|
|
|
## 使用WeakHashMap不等于不会OOM
|
|
|
|
|
|
对于上一节实现快速检索的案例,为了防止缓存中堆积大量数据导致OOM,一些同学可能会想到使用WeakHashMap作为缓存容器。
|
|
|
|
|
|
WeakHashMap的特点是Key在哈希表内部是弱引用的,当没有强引用指向这个Key之后,Entry会被GC,即使我们无限往WeakHashMap加入数据,只要Key不再使用,也就不会OOM。
|
|
|
|
|
|
说到了强引用和弱引用,我先和你回顾下Java中引用类型和垃圾回收的关系:
|
|
|
|
|
|
* 垃圾回收器不会回收有强引用的对象;
|
|
|
* 在内存充足时,垃圾回收器不会回收具有软引用的对象;
|
|
|
* 垃圾回收器只要扫描到了具有弱引用的对象就会回收,WeakHashMap就是利用了这个特点。
|
|
|
|
|
|
不过,我要和你分享的第二个案例,恰巧就是不久前我遇到的一个使用WeakHashMap却最终OOM的案例。我们暂且不论使用WeakHashMap作为缓存是否合适,先分析一下这个OOM问题。
|
|
|
|
|
|
声明一个Key是User类型、Value是UserProfile类型的WeakHashMap,作为用户数据缓存,往其中添加200万个Entry,然后使用ScheduledThreadPoolExecutor发起一个定时任务,每隔1秒输出缓存中的Entry个数:
|
|
|
|
|
|
```
|
|
|
private Map<User, UserProfile> cache = new WeakHashMap<>();
|
|
|
|
|
|
@GetMapping("wrong")
|
|
|
public void wrong() {
|
|
|
String userName = "zhuye";
|
|
|
//间隔1秒定时输出缓存中的条目数
|
|
|
Executors.newSingleThreadScheduledExecutor().scheduleAtFixedRate(
|
|
|
() -> log.info("cache size:{}", cache.size()), 1, 1, TimeUnit.SECONDS);
|
|
|
LongStream.rangeClosed(1, 2000000).forEach(i -> {
|
|
|
User user = new User(userName + i);
|
|
|
cache.put(user, new UserProfile(user, "location" + i));
|
|
|
});
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
执行程序后日志如下:
|
|
|
|
|
|
```
|
|
|
[10:30:28.509] [pool-3-thread-1] [INFO ] [t.c.o.demo3.WeakHashMapOOMController:29 ] - cache size:2000000
|
|
|
[10:30:29.507] [pool-3-thread-1] [INFO ] [t.c.o.demo3.WeakHashMapOOMController:29 ] - cache size:2000000
|
|
|
[10:30:30.509] [pool-3-thread-1] [INFO ] [t.c.o.demo3.WeakHashMapOOMController:29 ] - cache size:2000000
|
|
|
|
|
|
```
|
|
|
|
|
|
可以看到,输出的cache size始终是200万,即使我们通过jvisualvm进行手动GC还是这样。这就说明,这些Entry无法通过GC回收。如果你把200万改为1000万,就可以在日志中看到如下的OOM错误:
|
|
|
|
|
|
```
|
|
|
Exception in thread "http-nio-45678-exec-1" java.lang.OutOfMemoryError: GC overhead limit exceeded
|
|
|
Exception in thread "Catalina-utility-2" java.lang.OutOfMemoryError: GC overhead limit exceeded
|
|
|
|
|
|
```
|
|
|
|
|
|
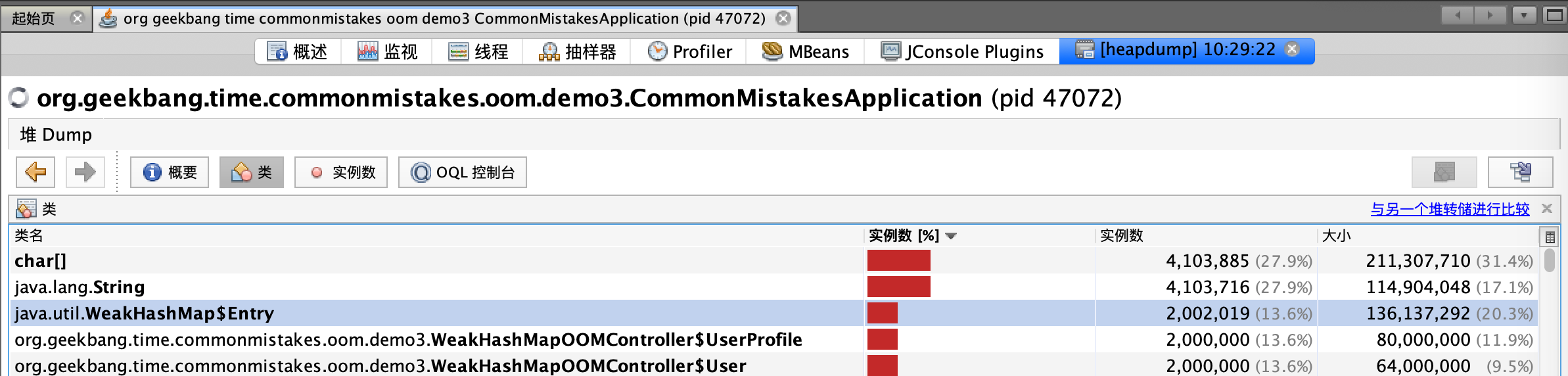
我们来分析一下这个问题。进行堆转储后可以看到,堆内存中有200万个UserProfie和User:
|
|
|
|
|
|
|
|
|
|
|
|
如下是User和UserProfile类的定义,需要注意的是,WeakHashMap的Key是User对象,而其Value是UserProfile对象,持有了User的引用:
|
|
|
|
|
|
```
|
|
|
@Data
|
|
|
@AllArgsConstructor
|
|
|
@NoArgsConstructor
|
|
|
class User {
|
|
|
private String name;
|
|
|
}
|
|
|
|
|
|
|
|
|
@Data
|
|
|
@AllArgsConstructor
|
|
|
@NoArgsConstructor
|
|
|
public class UserProfile {
|
|
|
private User user;
|
|
|
private String location;
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
没错,这就是问题的所在。分析一下WeakHashMap的源码,你会发现WeakHashMap和HashMap的最大区别,是Entry对象的实现。接下来,我们暂且忽略HashMap的实现,来看下Entry对象:
|
|
|
|
|
|
```
|
|
|
private static class Entry<K,V> extends WeakReference<Object> ...
|
|
|
/**
|
|
|
* Creates new entry.
|
|
|
*/
|
|
|
Entry(Object key, V value,
|
|
|
ReferenceQueue<Object> queue,
|
|
|
int hash, Entry<K,V> next) {
|
|
|
super(key, queue);
|
|
|
this.value = value;
|
|
|
this.hash = hash;
|
|
|
this.next = next;
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
Entry对象继承了WeakReference,Entry的构造函数调用了super (key,queue),这是父类的构造函数。其中,key是我们执行put方法时的key;queue是一个ReferenceQueue。如果你了解Java的引用就会知道,被GC的对象会被丢进这个queue里面。
|
|
|
|
|
|
再来看看对象被丢进queue后是如何被销毁的:
|
|
|
|
|
|
```
|
|
|
public V get(Object key) {
|
|
|
Object k = maskNull(key);
|
|
|
int h = hash(k);
|
|
|
Entry<K,V>[] tab = getTable();
|
|
|
int index = indexFor(h, tab.length);
|
|
|
Entry<K,V> e = tab[index];
|
|
|
while (e != null) {
|
|
|
if (e.hash == h && eq(k, e.get()))
|
|
|
return e.value;
|
|
|
e = e.next;
|
|
|
}
|
|
|
return null;
|
|
|
}
|
|
|
|
|
|
private Entry<K,V>[] getTable() {
|
|
|
expungeStaleEntries();
|
|
|
return table;
|
|
|
}
|
|
|
|
|
|
/**
|
|
|
* Expunges stale entries from the table.
|
|
|
*/
|
|
|
private void expungeStaleEntries() {
|
|
|
for (Object x; (x = queue.poll()) != null; ) {
|
|
|
synchronized (queue) {
|
|
|
@SuppressWarnings("unchecked")
|
|
|
Entry<K,V> e = (Entry<K,V>) x;
|
|
|
int i = indexFor(e.hash, table.length);
|
|
|
|
|
|
Entry<K,V> prev = table[i];
|
|
|
Entry<K,V> p = prev;
|
|
|
while (p != null) {
|
|
|
Entry<K,V> next = p.next;
|
|
|
if (p == e) {
|
|
|
if (prev == e)
|
|
|
table[i] = next;
|
|
|
else
|
|
|
prev.next = next;
|
|
|
// Must not null out e.next;
|
|
|
// stale entries may be in use by a HashIterator
|
|
|
e.value = null; // Help GC
|
|
|
size--;
|
|
|
break;
|
|
|
}
|
|
|
prev = p;
|
|
|
`` p = next;
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
从源码中可以看到,每次调用get、put、size等方法时,都会从queue里拿出所有已经被GC掉的key并删除对应的Entry对象。我们再来回顾下这个逻辑:
|
|
|
|
|
|
* put一个对象进Map时,它的key会被封装成弱引用对象;
|
|
|
* 发生GC时,弱引用的key被发现并放入queue;
|
|
|
* 调用get等方法时,扫描queue删除key,以及包含key和value的Entry对象。
|
|
|
|
|
|
**WeakHashMap的Key虽然是弱引用,但是其Value却持有Key中对象的强引用,Value被Entry引用,Entry被WeakHashMap引用,最终导致Key无法回收**。解决方案就是让Value变为弱引用,使用WeakReference来包装UserProfile即可:
|
|
|
|
|
|
```
|
|
|
private Map<User, WeakReference<UserProfile>> cache2 = new WeakHashMap<>();
|
|
|
|
|
|
@GetMapping("right")
|
|
|
public void right() {
|
|
|
String userName = "zhuye";
|
|
|
//间隔1秒定时输出缓存中的条目数
|
|
|
Executors.newSingleThreadScheduledExecutor().scheduleAtFixedRate(
|
|
|
() -> log.info("cache size:{}", cache2.size()), 1, 1, TimeUnit.SECONDS);
|
|
|
LongStream.rangeClosed(1, 2000000).forEach(i -> {
|
|
|
User user = new User(userName + i);
|
|
|
//这次,我们使用弱引用来包装UserProfile
|
|
|
cache2.put(user, new WeakReference(new UserProfile(user, "location" + i)));
|
|
|
});
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
重新运行程序,从日志中观察到cache size不再是固定的200万,而是在不断减少,甚至在手动GC后所有的Entry都被回收了:
|
|
|
|
|
|
```
|
|
|
[10:40:05.792] [pool-3-thread-1] [INFO ] [t.c.o.demo3.WeakHashMapOOMController:40 ] - cache size:1367402
|
|
|
[10:40:05.795] [pool-3-thread-1] [INFO ] [t.c.o.demo3.WeakHashMapOOMController:40 ] - cache size:1367846
|
|
|
[10:40:06.773] [pool-3-thread-1] [INFO ] [t.c.o.demo3.WeakHashMapOOMController:40 ] - cache size:549551
|
|
|
...
|
|
|
[10:40:20.742] [pool-3-thread-1] [INFO ] [t.c.o.demo3.WeakHashMapOOMController:40 ] - cache size:549551
|
|
|
[10:40:22.862] [pool-3-thread-1] [INFO ] [t.c.o.demo3.WeakHashMapOOMController:40 ] - cache size:547937
|
|
|
[10:40:22.865] [pool-3-thread-1] [INFO ] [t.c.o.demo3.WeakHashMapOOMController:40 ] - cache size:542134
|
|
|
[10:40:23.779] [pool-3-thread-1] [INFO ]
|
|
|
//手动进行GC
|
|
|
[t.c.o.demo3.WeakHashMapOOMController:40 ] - cache size:0
|
|
|
|
|
|
```
|
|
|
|
|
|
当然,还有一种办法就是,让Value也就是UserProfile不再引用Key,而是重新new出一个新的User对象赋值给UserProfile:
|
|
|
|
|
|
```
|
|
|
@GetMapping("right2")
|
|
|
public void right2() {
|
|
|
String userName = "zhuye";
|
|
|
...
|
|
|
User user = new User(userName + i);
|
|
|
cache.put(user, new UserProfile(new User(user.getName()), "location" + i));
|
|
|
});
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
此外,Spring提供的[ConcurrentReferenceHashMap](https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/util/ConcurrentReferenceHashMap.html)类可以使用弱引用、软引用做缓存,Key和Value同时被软引用或弱引用包装,也能解决相互引用导致的数据不能释放问题。与WeakHashMap相比,ConcurrentReferenceHashMap不但性能更好,还可以确保线程安全。你可以自己做实验测试下。
|
|
|
|
|
|
## Tomcat参数配置不合理导致OOM
|
|
|
|
|
|
我们再来看看第三个案例。有一次运维同学反馈,有个应用在业务量大的情况下会出现假死,日志中也有大量OOM异常:
|
|
|
|
|
|
```
|
|
|
[13:18:17.597] [http-nio-45678-exec-70] [ERROR] [ache.coyote.http11.Http11NioProtocol:175 ] - Failed to complete processing of a request
|
|
|
java.lang.OutOfMemoryError: Java heap space
|
|
|
|
|
|
```
|
|
|
|
|
|
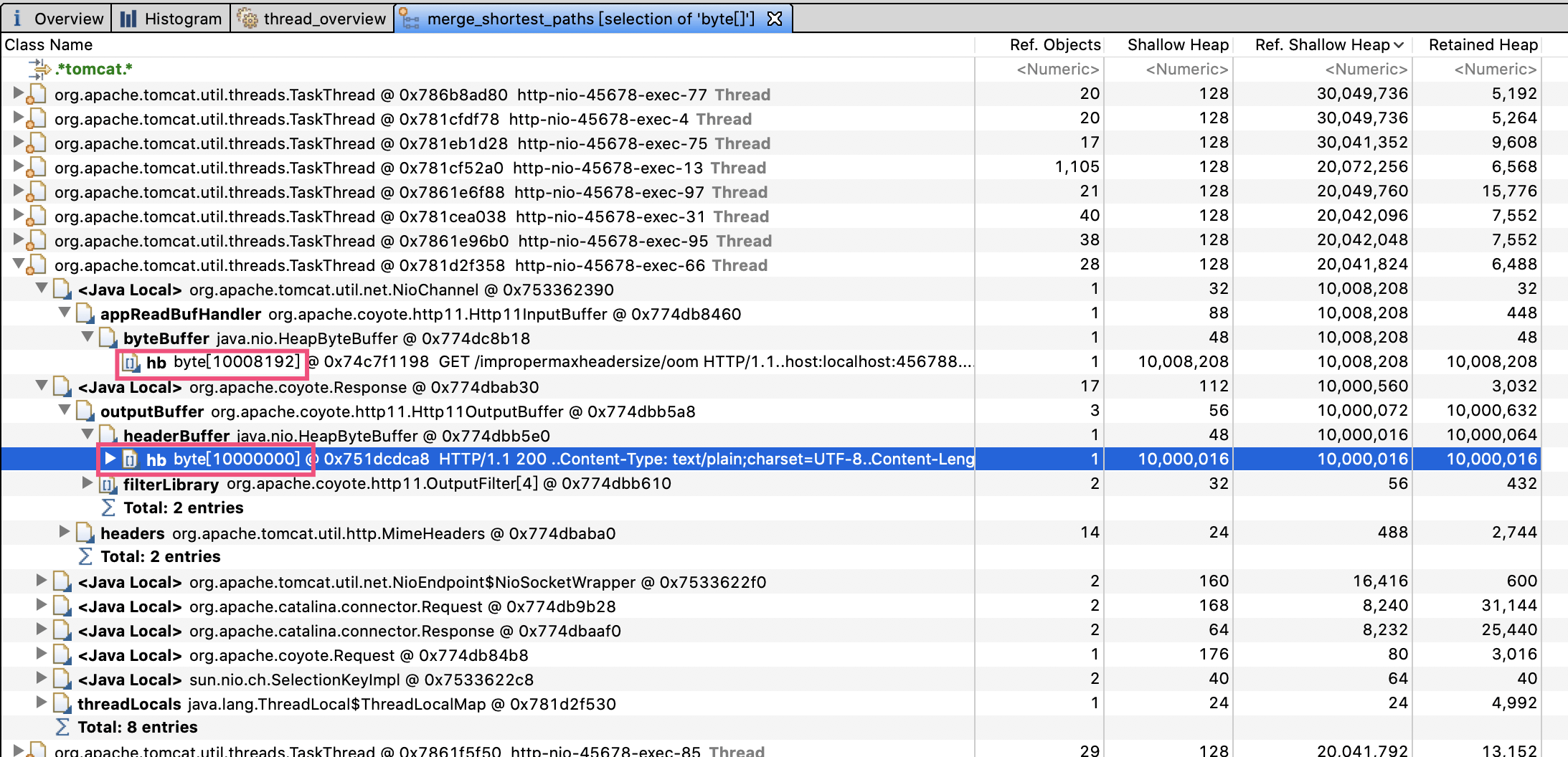
于是,我让运维同学进行生产堆Dump。通过MAT打开dump文件后,我们一眼就看到OOM的原因是,有接近1.7GB的byte数组分配,而JVM进程的最大堆内存我们只配置了2GB:
|
|
|
|
|
|

|
|
|
|
|
|
通过查看引用可以发现,大量引用都是Tomcat的工作线程。大部分工作线程都分配了两个10M左右的数组,100个左右工作线程吃满了内存。第一个红框是Http11InputBuffer,其buffer大小是10008192字节;而第二个红框的Http11OutputBuffer的buffer,正好占用10000000字节:
|
|
|
|
|
|
|
|
|
|
|
|
我们先来看看第一个Http11InputBuffer为什么会占用这么多内存。查看Http11InputBuffer类的init方法注意到,其中一个初始化方法会分配headerBufferSize+readBuffer大小的内存:
|
|
|
|
|
|
```
|
|
|
void init(SocketWrapperBase<?> socketWrapper) {
|
|
|
|
|
|
wrapper = socketWrapper;
|
|
|
wrapper.setAppReadBufHandler(this);
|
|
|
|
|
|
int bufLength = headerBufferSize +
|
|
|
wrapper.getSocketBufferHandler().getReadBuffer().capacity();
|
|
|
if (byteBuffer == null || byteBuffer.capacity() < bufLength) {
|
|
|
byteBuffer = ByteBuffer.allocate(bufLength);
|
|
|
byteBuffer.position(0).limit(0);
|
|
|
}
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
在[Tomcat文档](https://tomcat.apache.org/tomcat-8.0-doc/config/http.html)中有提到,这个Socket的读缓冲,也就是readBuffer默认是8192字节。显然,问题出在了headerBufferSize上:
|
|
|
|
|
|

|
|
|
|
|
|
向上追溯初始化Http11InputBuffer的Http11Processor类,可以看到,传入的headerBufferSize配置的是MaxHttpHeaderSize:
|
|
|
|
|
|
```
|
|
|
inputBuffer = new Http11InputBuffer(request, protocol.getMaxHttpHeaderSize(),
|
|
|
protocol.getRejectIllegalHeaderName(), httpParser);
|
|
|
|
|
|
```
|
|
|
|
|
|
Http11OutputBuffer中的buffer正好占用了10000000字节,这又是为什么?通过Http11OutputBuffer的构造方法,可以看到它是直接根据headerBufferSize分配了固定大小的headerBuffer:
|
|
|
|
|
|
```
|
|
|
protected Http11OutputBuffer(Response response, int headerBufferSize){
|
|
|
...
|
|
|
headerBuffer = ByteBuffer.allocate(headerBufferSize);
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
那么我们就可以想到,一定是应用把Tomcat头相关的参数配置为10000000了,使得每一个请求对于Request和Response都占用了20M内存,最终在并发较多的情况下引起了OOM。
|
|
|
|
|
|
果不其然,查看项目代码发现配置文件中有这样的配置项:
|
|
|
|
|
|
```
|
|
|
server.max-http-header-size=10000000
|
|
|
|
|
|
```
|
|
|
|
|
|
翻看源码提交记录可以看到,当时开发同学遇到了这样的异常:
|
|
|
|
|
|
```
|
|
|
java.lang.IllegalArgumentException: Request header is too large
|
|
|
|
|
|
```
|
|
|
|
|
|
于是他就到网上搜索了一下解决方案,随意将server.max-http-header-size修改为了一个超大值,期望永远不会再出现类似问题。但,没想到这个修改却引起了这么大的问题。把这个参数改为比较合适的20000再进行压测,我们就可以发现应用的各项指标都比较稳定。
|
|
|
|
|
|
这个案例告诉我们,**一定要根据实际需求来修改参数配置,可以考虑预留2到5倍的量。容量类的参数背后往往代表了资源,设置超大的参数就有可能占用不必要的资源,在并发量大的时候因为资源大量分配导致OOM**。
|
|
|
|
|
|
## 重点回顾
|
|
|
|
|
|
今天,我从内存分配意识的角度和你分享了OOM的问题。通常而言,Java程序的OOM有如下几种可能。
|
|
|
|
|
|
一是,我们的程序确实需要超出JVM配置的内存上限的内存。不管是程序实现的不合理,还是因为各种框架对数据的重复处理、加工和转换,相同的数据在内存中不一定只占用一份空间。针对内存量使用超大的业务逻辑,比如缓存逻辑、文件上传下载和导出逻辑,我们在做容量评估时,可能还需要实际做一下Dump,而不是进行简单的假设。
|
|
|
|
|
|
二是,出现内存泄露,其实就是我们认为没有用的对象最终会被GC,但却没有。GC并不会回收强引用对象,我们可能经常在程序中定义一些容器作为缓存,但如果容器中的数据无限增长,要特别小心最终会导致OOM。使用WeakHashMap是解决这个问题的好办法,但值得注意的是,如果强引用的Value有引用Key,也无法回收Entry。
|
|
|
|
|
|
三是,不合理的资源需求配置,在业务量小的时候可能不会出现问题,但业务量一大可能很快就会撑爆内存。比如,随意配置Tomcat的max-http-header-size参数,会导致一个请求使用过多的内存,请求量大的时候出现OOM。在进行参数配置的时候,我们要认识到,很多限制类参数限制的是背后资源的使用,资源始终是有限的,需要根据实际需求来合理设置参数。
|
|
|
|
|
|
最后我想说的是,在出现OOM之后,也不用过于紧张。我们可以根据错误日志中的异常信息,再结合jstat等命令行工具观察内存使用情况,以及程序的GC日志,来大致定位出现OOM的内存区块和类型。其实,我们遇到的90%的OOM都是堆OOM,对JVM进程进行堆内存Dump,或使用jmap命令分析对象内存占用排行,一般都可以很容易定位到问题。
|
|
|
|
|
|
这里,**我建议你为生产系统的程序配置JVM参数启用详细的GC日志,方便观察垃圾收集器的行为,并开启HeapDumpOnOutOfMemoryError,以便在出现OOM时能自动Dump留下第一问题现场**。对于JDK8,你可以这么设置:
|
|
|
|
|
|
```
|
|
|
XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=. -XX:+PrintGCDateStamps -XX:+PrintGCDetails -Xloggc:gc.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=100M
|
|
|
|
|
|
```
|
|
|
|
|
|
今天用到的代码,我都放在了GitHub上,你可以点击[这个链接](https://github.com/JosephZhu1983/java-common-mistakes)查看。
|
|
|
|
|
|
## 思考与讨论
|
|
|
|
|
|
1. Spring的ConcurrentReferenceHashMap,针对Key和Value支持软引用和弱引用两种方式。你觉得哪种方式更适合做缓存呢?
|
|
|
2. 当我们需要动态执行一些表达式时,可以使用Groovy动态语言实现:new出一个GroovyShell类,然后调用evaluate方法动态执行脚本。这种方式的问题是,会重复产生大量的类,增加Metaspace区的GC负担,有可能会引起OOM。你知道如何避免这个问题吗?
|
|
|
|
|
|
针对OOM或内存泄露,你还遇到过什么案例吗?我是朱晔,欢迎在评论区与我留言分享,也欢迎你把今天的内容分享给你的朋友或同事,一起交流。
|
|
|
|