497 lines
22 KiB
Markdown
497 lines
22 KiB
Markdown
# 45 | 发送网络包(上):如何表达我们想让合作伙伴做什么?
|
||
|
||
上一节,我们通过socket函数、bind函数、listen函数、accept函数以及connect函数,在内核建立好了数据结构,并完成了TCP连接建立的三次握手过程。
|
||
|
||
这一节,我们接着来分析,发送一个网络包的过程。
|
||
|
||
## 解析socket的Write操作
|
||
|
||
socket对于用户来讲,是一个文件一样的存在,拥有一个文件描述符。因而对于网络包的发送,我们可以使用对于socket文件的写入系统调用,也就是write系统调用。
|
||
|
||
write系统调用对于一个文件描述符的操作,大致过程都是类似的。在文件系统那一节,我们已经详细解析过,这里不再多说。对于每一个打开的文件都有一个struct file结构,write系统调用会最终调用stuct file结构指向的file\_operations操作。
|
||
|
||
对于socket来讲,它的file\_operations定义如下:
|
||
|
||
```
|
||
static const struct file_operations socket_file_ops = {
|
||
.owner = THIS_MODULE,
|
||
.llseek = no_llseek,
|
||
.read_iter = sock_read_iter,
|
||
.write_iter = sock_write_iter,
|
||
.poll = sock_poll,
|
||
.unlocked_ioctl = sock_ioctl,
|
||
.mmap = sock_mmap,
|
||
.release = sock_close,
|
||
.fasync = sock_fasync,
|
||
.sendpage = sock_sendpage,
|
||
.splice_write = generic_splice_sendpage,
|
||
.splice_read = sock_splice_read,
|
||
};
|
||
|
||
```
|
||
|
||
按照文件系统的写入流程,调用的是sock\_write\_iter。
|
||
|
||
```
|
||
static ssize_t sock_write_iter(struct kiocb *iocb, struct iov_iter *from)
|
||
{
|
||
struct file *file = iocb->ki_filp;
|
||
struct socket *sock = file->private_data;
|
||
struct msghdr msg = {.msg_iter = *from,
|
||
.msg_iocb = iocb};
|
||
ssize_t res;
|
||
......
|
||
res = sock_sendmsg(sock, &msg);
|
||
*from = msg.msg_iter;
|
||
return res;
|
||
}
|
||
|
||
```
|
||
|
||
在sock\_write\_iter中,我们通过VFS中的struct file,将创建好的socket结构拿出来,然后调用sock\_sendmsg。而sock\_sendmsg会调用sock\_sendmsg\_nosec。
|
||
|
||
```
|
||
static inline int sock_sendmsg_nosec(struct socket *sock, struct msghdr *msg)
|
||
{
|
||
int ret = sock->ops->sendmsg(sock, msg, msg_data_left(msg));
|
||
......
|
||
}
|
||
|
||
```
|
||
|
||
这里调用了socket的ops的sendmsg,我们在上一节已经遇到它好几次了。根据inet\_stream\_ops的定义,我们这里调用的是inet\_sendmsg。
|
||
|
||
```
|
||
int inet_sendmsg(struct socket *sock, struct msghdr *msg, size_t size)
|
||
{
|
||
struct sock *sk = sock->sk;
|
||
......
|
||
return sk->sk_prot->sendmsg(sk, msg, size);
|
||
}
|
||
|
||
```
|
||
|
||
这里面,从socket结构中,我们可以得到更底层的sock结构,然后调用sk\_prot的sendmsg方法。这个我们同样在上一节遇到好几次了。
|
||
|
||
## 解析tcp\_sendmsg函数
|
||
|
||
根据tcp\_prot的定义,我们调用的是tcp\_sendmsg。
|
||
|
||
```
|
||
int tcp_sendmsg(struct sock *sk, struct msghdr *msg, size_t size)
|
||
{
|
||
struct tcp_sock *tp = tcp_sk(sk);
|
||
struct sk_buff *skb;
|
||
int flags, err, copied = 0;
|
||
int mss_now = 0, size_goal, copied_syn = 0;
|
||
long timeo;
|
||
......
|
||
/* Ok commence sending. */
|
||
copied = 0;
|
||
restart:
|
||
mss_now = tcp_send_mss(sk, &size_goal, flags);
|
||
|
||
while (msg_data_left(msg)) {
|
||
int copy = 0;
|
||
int max = size_goal;
|
||
|
||
skb = tcp_write_queue_tail(sk);
|
||
if (tcp_send_head(sk)) {
|
||
if (skb->ip_summed == CHECKSUM_NONE)
|
||
max = mss_now;
|
||
copy = max - skb->len;
|
||
}
|
||
|
||
if (copy <= 0 || !tcp_skb_can_collapse_to(skb)) {
|
||
bool first_skb;
|
||
|
||
new_segment:
|
||
/* Allocate new segment. If the interface is SG,
|
||
* allocate skb fitting to single page.
|
||
*/
|
||
if (!sk_stream_memory_free(sk))
|
||
goto wait_for_sndbuf;
|
||
......
|
||
first_skb = skb_queue_empty(&sk->sk_write_queue);
|
||
skb = sk_stream_alloc_skb(sk,
|
||
select_size(sk, sg, first_skb),
|
||
sk->sk_allocation,
|
||
first_skb);
|
||
......
|
||
skb_entail(sk, skb);
|
||
copy = size_goal;
|
||
max = size_goal;
|
||
......
|
||
}
|
||
|
||
/* Try to append data to the end of skb. */
|
||
if (copy > msg_data_left(msg))
|
||
copy = msg_data_left(msg);
|
||
|
||
/* Where to copy to? */
|
||
if (skb_availroom(skb) > 0) {
|
||
/* We have some space in skb head. Superb! */
|
||
copy = min_t(int, copy, skb_availroom(skb));
|
||
err = skb_add_data_nocache(sk, skb, &msg->msg_iter, copy);
|
||
......
|
||
} else {
|
||
bool merge = true;
|
||
int i = skb_shinfo(skb)->nr_frags;
|
||
struct page_frag *pfrag = sk_page_frag(sk);
|
||
......
|
||
copy = min_t(int, copy, pfrag->size - pfrag->offset);
|
||
......
|
||
err = skb_copy_to_page_nocache(sk, &msg->msg_iter, skb,
|
||
pfrag->page,
|
||
pfrag->offset,
|
||
copy);
|
||
......
|
||
pfrag->offset += copy;
|
||
}
|
||
|
||
......
|
||
tp->write_seq += copy;
|
||
TCP_SKB_CB(skb)->end_seq += copy;
|
||
tcp_skb_pcount_set(skb, 0);
|
||
|
||
copied += copy;
|
||
if (!msg_data_left(msg)) {
|
||
if (unlikely(flags & MSG_EOR))
|
||
TCP_SKB_CB(skb)->eor = 1;
|
||
goto out;
|
||
}
|
||
|
||
if (skb->len < max || (flags & MSG_OOB) || unlikely(tp->repair))
|
||
continue;
|
||
|
||
if (forced_push(tp)) {
|
||
tcp_mark_push(tp, skb);
|
||
__tcp_push_pending_frames(sk, mss_now, TCP_NAGLE_PUSH);
|
||
} else if (skb == tcp_send_head(sk))
|
||
tcp_push_one(sk, mss_now);
|
||
continue;
|
||
......
|
||
}
|
||
......
|
||
}
|
||
|
||
```
|
||
|
||
tcp\_sendmsg的实现还是很复杂的,这里面做了这样几件事情。
|
||
|
||
msg是用户要写入的数据,这个数据要拷贝到内核协议栈里面去发送;在内核协议栈里面,网络包的数据都是由struct sk\_buff维护的,因而第一件事情就是找到一个空闲的内存空间,将用户要写入的数据,拷贝到struct sk\_buff的管辖范围内。而第二件事情就是发送struct sk\_buff。
|
||
|
||
在tcp\_sendmsg中,我们首先通过强制类型转换,将sock结构转换为struct tcp\_sock,这个是维护TCP连接状态的重要数据结构。
|
||
|
||
接下来是tcp\_sendmsg的第一件事情,把数据拷贝到struct sk\_buff。
|
||
|
||
我们先声明一个变量copied,初始化为0,这表示拷贝了多少数据。紧接着是一个循环,while (msg\_data\_left(msg)),也即如果用户的数据没有发送完毕,就一直循环。循环里声明了一个copy变量,表示这次拷贝的数值,在循环的最后有copied += copy,将每次拷贝的数量都加起来。
|
||
|
||
我们这里只需要看一次循环做了哪些事情。
|
||
|
||
**第一步**,tcp\_write\_queue\_tail从TCP写入队列sk\_write\_queue中拿出最后一个struct sk\_buff,在这个写入队列中排满了要发送的struct sk\_buff,为什么要拿最后一个呢?这里面只有最后一个,可能会因为上次用户给的数据太少,而没有填满。
|
||
|
||
**第二步**,tcp\_send\_mss会计算MSS,也即Max Segment Size。这是什么呢?这个意思是说,我们在网络上传输的网络包的大小是有限制的,而这个限制在最底层开始就有。
|
||
|
||
**MTU**(Maximum Transmission Unit,最大传输单元)是二层的一个定义。以以太网为例,MTU为1500个Byte,前面有6个Byte的目标MAC地址,6个Byte的源MAC地址,2个Byte的类型,后面有4个Byte的CRC校验,共1518个Byte。
|
||
|
||
在IP层,一个IP数据报在以太网中传输,如果它的长度大于该MTU值,就要进行分片传输。
|
||
|
||
在TCP层有个**MSS**(Maximum Segment Size,最大分段大小),等于MTU减去IP头,再减去TCP头。也就是,在不分片的情况下,TCP里面放的最大内容。
|
||
|
||
在这里,max是struct sk\_buff的最大数据长度,skb->len是当前已经占用的skb的数据长度,相减得到当前skb的剩余数据空间。
|
||
|
||
**第三步**,如果copy小于0,说明最后一个struct sk\_buff已经没地方存放了,需要调用sk\_stream\_alloc\_skb,重新分配struct sk\_buff,然后调用skb\_entail,将新分配的sk\_buff放到队列尾部。
|
||
|
||
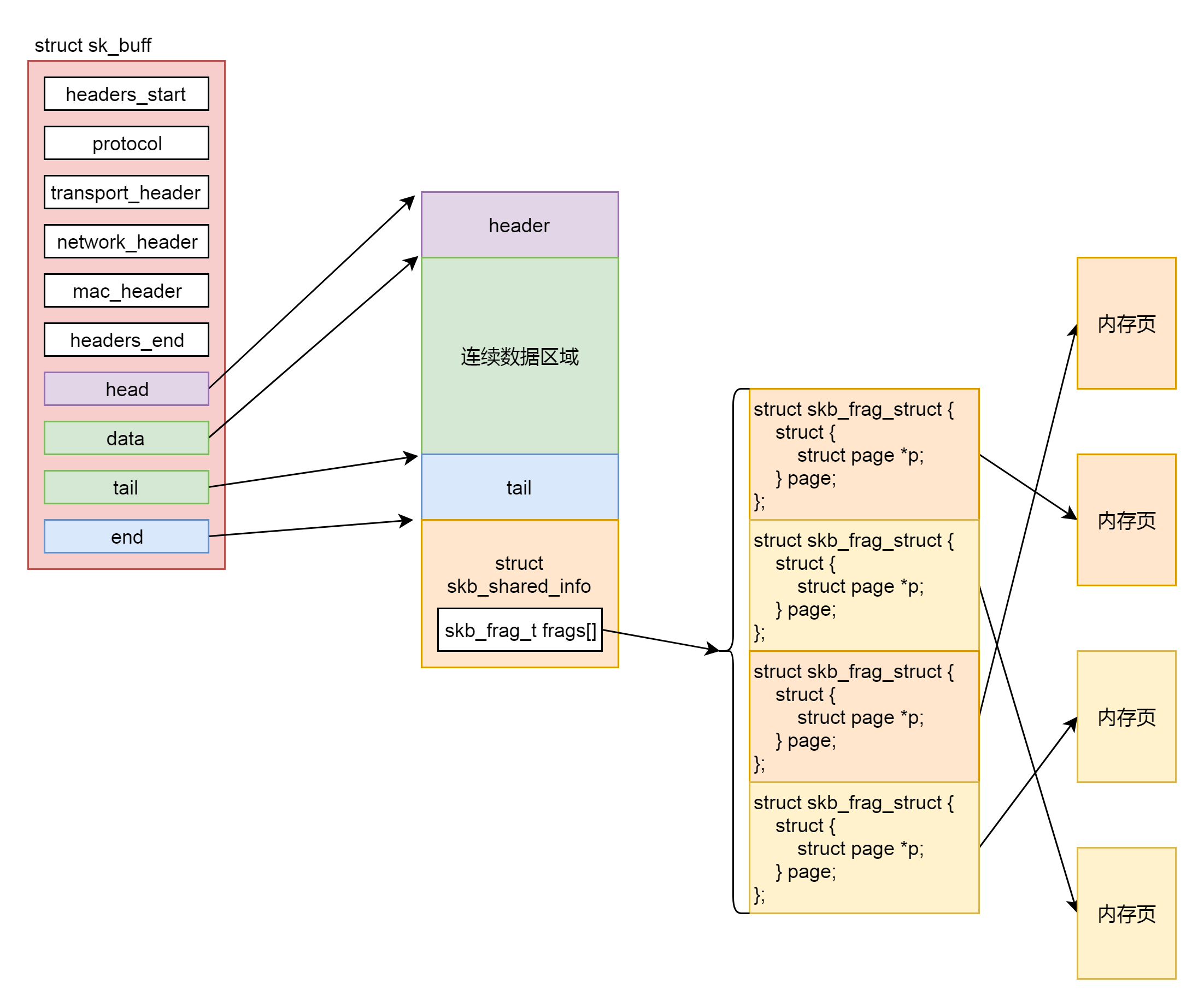
struct sk\_buff是存储网络包的重要的数据结构,在应用层数据包叫data,在TCP层我们称为segment,在IP层我们叫packet,在数据链路层称为frame。在struct sk\_buff,首先是一个链表,将struct sk\_buff结构串起来。
|
||
|
||
接下来,我们从headers\_start开始,到headers\_end结束,里面都是各层次的头的位置。这里面有二层的mac\_header、三层的network\_header和四层的transport\_header。
|
||
|
||
```
|
||
struct sk_buff {
|
||
union {
|
||
struct {
|
||
/* These two members must be first. */
|
||
struct sk_buff *next;
|
||
struct sk_buff *prev;
|
||
......
|
||
};
|
||
struct rb_node rbnode; /* used in netem & tcp stack */
|
||
};
|
||
......
|
||
/* private: */
|
||
__u32 headers_start[0];
|
||
/* public: */
|
||
......
|
||
__u32 priority;
|
||
int skb_iif;
|
||
__u32 hash;
|
||
__be16 vlan_proto;
|
||
__u16 vlan_tci;
|
||
......
|
||
union {
|
||
__u32 mark;
|
||
__u32 reserved_tailroom;
|
||
};
|
||
|
||
union {
|
||
__be16 inner_protocol;
|
||
__u8 inner_ipproto;
|
||
};
|
||
|
||
__u16 inner_transport_header;
|
||
__u16 inner_network_header;
|
||
__u16 inner_mac_header;
|
||
|
||
__be16 protocol;
|
||
__u16 transport_header;
|
||
__u16 network_header;
|
||
__u16 mac_header;
|
||
|
||
/* private: */
|
||
__u32 headers_end[0];
|
||
/* public: */
|
||
|
||
/* These elements must be at the end, see alloc_skb() for details. */
|
||
sk_buff_data_t tail;
|
||
sk_buff_data_t end;
|
||
unsigned char *head,
|
||
*data;
|
||
unsigned int truesize;
|
||
refcount_t users;
|
||
};
|
||
|
||
```
|
||
|
||
最后几项, head指向分配的内存块起始地址。data这个指针指向的位置是可变的。它有可能随着报文所处的层次而变动。当接收报文时,从网卡驱动开始,通过协议栈层层往上传送数据报,通过增加 skb->data 的值,来逐步剥离协议首部。而要发送报文时,各协议会创建 sk\_buff{},在经过各下层协议时,通过减少 skb->data的值来增加协议首部。tail指向数据的结尾,end指向分配的内存块的结束地址。
|
||
|
||
要分配这样一个结构,sk\_stream\_alloc\_skb会最终调用到\_\_alloc\_skb。在这个函数里面,除了分配一个sk\_buff结构之外,还要分配sk\_buff指向的数据区域。这段数据区域分为下面这几个部分。
|
||
|
||
第一部分是连续的数据区域。紧接着是第二部分,一个struct skb\_shared\_info结构。这个结构是对于网络包发送过程的一个优化,因为传输层之上就是应用层了。按照TCP的定义,应用层感受不到下面的网络层的IP包是一个个独立的包的存在的。反正就是一个流,往里写就是了,可能一下子写多了,超过了一个IP包的承载能力,就会出现上面MSS的定义,拆分成一个个的Segment放在一个个的IP包里面,也可能一次写一点,一次写一点,这样数据是分散的,在IP层还要通过内存拷贝合成一个IP包。
|
||
|
||
为了减少内存拷贝的代价,有的网络设备支持**分散聚合**(Scatter/Gather)I/O,顾名思义,就是IP层没必要通过内存拷贝进行聚合,让散的数据零散的放在原处,在设备层进行聚合。如果使用这种模式,网络包的数据就不会放在连续的数据区域,而是放在struct skb\_shared\_info结构里面指向的离散数据,skb\_shared\_info的成员变量skb\_frag\_t frags\[MAX\_SKB\_FRAGS\],会指向一个数组的页面,就不能保证连续了。
|
||
|
||
|
||
|
||
于是我们就有了**第四步**。在注释/\* Where to copy to? \*/后面有个if-else分支。if分支就是skb\_add\_data\_nocache将数据拷贝到连续的数据区域。else分支就是skb\_copy\_to\_page\_nocache将数据拷贝到struct skb\_shared\_info结构指向的不需要连续的页面区域。
|
||
|
||
**第五步**,就是要发生网络包了。第一种情况是积累的数据报数目太多了,因而我们需要通过调用\_\_tcp\_push\_pending\_frames发送网络包。第二种情况是,这是第一个网络包,需要马上发送,调用tcp\_push\_one。无论\_\_tcp\_push\_pending\_frames还是tcp\_push\_one,都会调用tcp\_write\_xmit发送网络包。
|
||
|
||
至此,tcp\_sendmsg解析完了。
|
||
|
||
## 解析tcp\_write\_xmit函数
|
||
|
||
接下来我们来看,tcp\_write\_xmit是如何发送网络包的。
|
||
|
||
```
|
||
static bool tcp_write_xmit(struct sock *sk, unsigned int mss_now, int nonagle, int push_one, gfp_t gfp)
|
||
{
|
||
struct tcp_sock *tp = tcp_sk(sk);
|
||
struct sk_buff *skb;
|
||
unsigned int tso_segs, sent_pkts;
|
||
int cwnd_quota;
|
||
......
|
||
max_segs = tcp_tso_segs(sk, mss_now);
|
||
while ((skb = tcp_send_head(sk))) {
|
||
unsigned int limit;
|
||
......
|
||
tso_segs = tcp_init_tso_segs(skb, mss_now);
|
||
......
|
||
cwnd_quota = tcp_cwnd_test(tp, skb);
|
||
......
|
||
if (unlikely(!tcp_snd_wnd_test(tp, skb, mss_now))) {
|
||
is_rwnd_limited = true;
|
||
break;
|
||
}
|
||
......
|
||
limit = mss_now;
|
||
if (tso_segs > 1 && !tcp_urg_mode(tp))
|
||
limit = tcp_mss_split_point(sk, skb, mss_now, min_t(unsigned int, cwnd_quota, max_segs), nonagle);
|
||
|
||
if (skb->len > limit &&
|
||
unlikely(tso_fragment(sk, skb, limit, mss_now, gfp)))
|
||
break;
|
||
......
|
||
if (unlikely(tcp_transmit_skb(sk, skb, 1, gfp)))
|
||
break;
|
||
|
||
repair:
|
||
/* Advance the send_head. This one is sent out.
|
||
* This call will increment packets_out.
|
||
*/
|
||
tcp_event_new_data_sent(sk, skb);
|
||
|
||
tcp_minshall_update(tp, mss_now, skb);
|
||
sent_pkts += tcp_skb_pcount(skb);
|
||
|
||
if (push_one)
|
||
break;
|
||
}
|
||
......
|
||
}
|
||
|
||
```
|
||
|
||
这里面主要的逻辑是一个循环,用来处理发送队列,只要队列不空,就会发送。
|
||
|
||
在一个循环中,涉及TCP层的很多传输算法,我们来一一解析。
|
||
|
||
第一个概念是**TSO**(TCP Segmentation Offload)。如果发送的网络包非常大,就像上面说的一样,要进行分段。分段这个事情可以由协议栈代码在内核做,但是缺点是比较费CPU,另一种方式是延迟到硬件网卡去做,需要网卡支持对大数据包进行自动分段,可以降低CPU负载。
|
||
|
||
在代码中,tcp\_init\_tso\_segs会调用tcp\_set\_skb\_tso\_segs。这里面有这样的语句:DIV\_ROUND\_UP(skb->len, mss\_now)。也就是sk\_buff的长度除以mss\_now,应该分成几个段。如果算出来要分成多个段,接下来就是要看,是在这里(协议栈的代码里面)分好,还是等待到了底层网卡再分。
|
||
|
||
于是,调用函数tcp\_mss\_split\_point,开始计算切分的limit。这里面会计算max\_len = mss\_now \* max\_segs,根据现在不切分来计算limit,所以下一步的判断中,大部分情况下tso\_fragment不会被调用,等待到了底层网卡来切分。
|
||
|
||
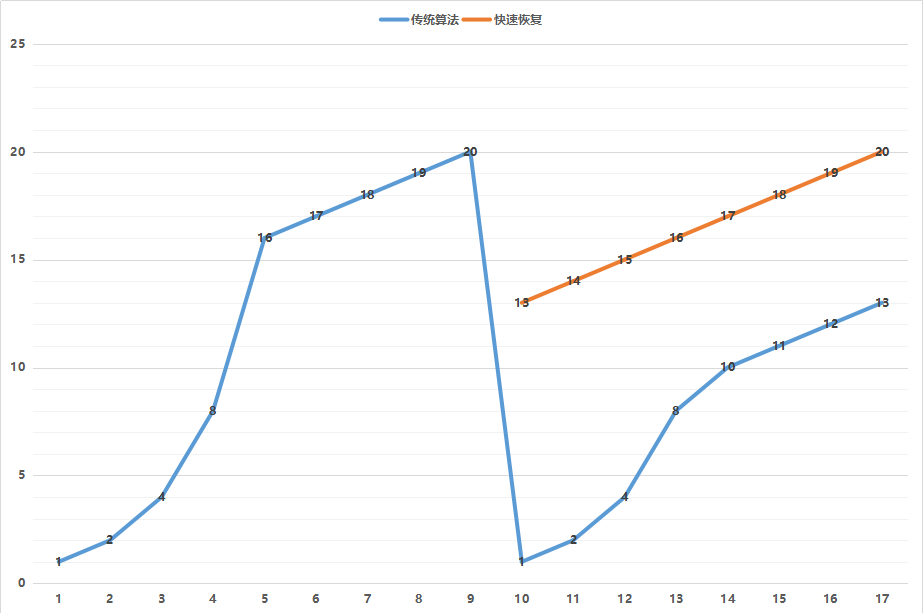
第二个概念是**拥塞窗口**的概念(cwnd,congestion window),也就是说为了避免拼命发包,把网络塞满了,定义一个窗口的概念,在这个窗口之内的才能发送,超过这个窗口的就不能发送,来控制发送的频率。
|
||
|
||
那窗口大小是多少呢?就是遵循下面这个著名的拥塞窗口变化图。
|
||
|
||
|
||
|
||
一开始的窗口只有一个mss大小叫作slow start(慢启动)。一开始的增长速度的很快的,翻倍增长。一旦到达一个临界值ssthresh,就变成线性增长,我们就称为**拥塞避免**。什么时候算真正拥塞呢?就是出现了丢包。一旦丢包,一种方法是马上降回到一个mss,然后重复先翻倍再线性对的过程。如果觉得太过激进,也可以有第二种方法,就是降到当前cwnd的一半,然后进行线性增长。
|
||
|
||
在代码中,tcp\_cwnd\_test会将当前的snd\_cwnd,减去已经在窗口里面尚未发送完毕的网络包,那就是剩下的窗口大小cwnd\_quota,也即就能发送这么多了。
|
||
|
||
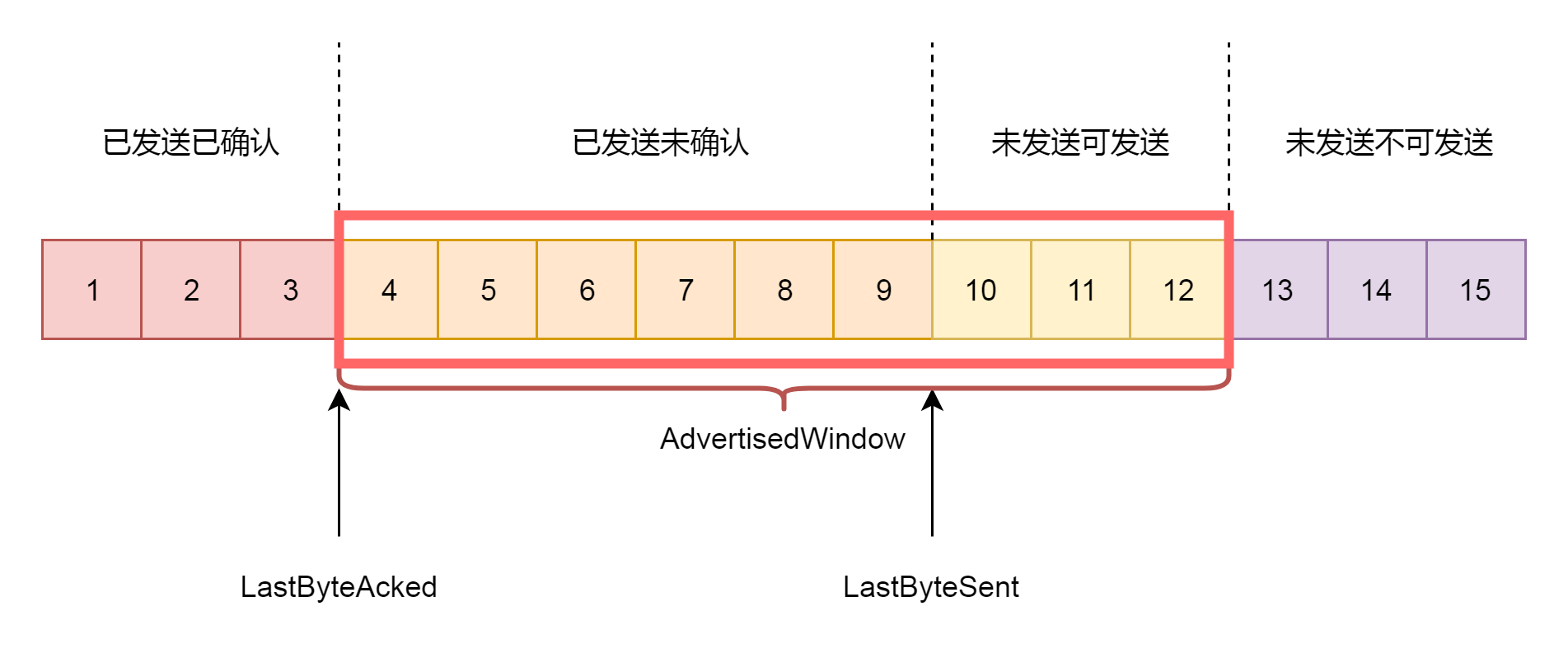
第三个概念就是**接收窗口**rwnd的概念(receive window),也叫滑动窗口。如果说拥塞窗口是为了怕把网络塞满,在出现丢包的时候减少发送速度,那么滑动窗口就是为了怕把接收方塞满,而控制发送速度。
|
||
|
||
|
||
|
||
滑动窗口,其实就是接收方告诉发送方自己的网络包的接收能力,超过这个能力,我就受不了了。因为滑动窗口的存在,将发送方的缓存分成了四个部分。
|
||
|
||
* 第一部分:发送了并且已经确认的。这部分是已经发送完毕的网络包,这部分没有用了,可以回收。
|
||
* 第二部分:发送了但尚未确认的。这部分,发送方要等待,万一发送不成功,还要重新发送,所以不能删除。
|
||
* 第三部分:没有发送,但是已经等待发送的。这部分是接收方空闲的能力,可以马上发送,接收方收得了。
|
||
* 第四部分:没有发送,并且暂时还不会发送的。这部分已经超过了接收方的接收能力,再发送接收方就收不了了。
|
||
|
||
|
||
|
||
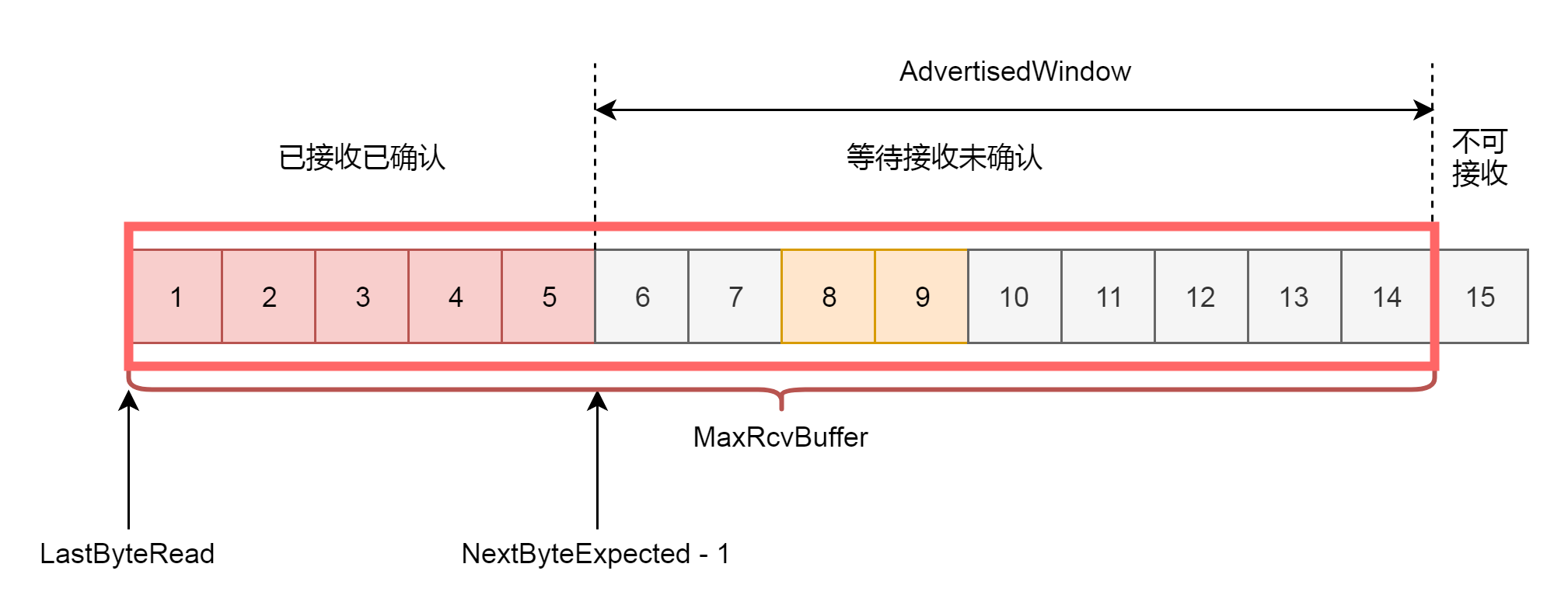
因为滑动窗口的存在,接收方的缓存也要分成了三个部分。
|
||
|
||
* 第一部分:接受并且确认过的任务。这部分完全接收成功了,可以交给应用层了。
|
||
* 第二部分:还没接收,但是马上就能接收的任务。这部分有的网络包到达了,但是还没确认,不算完全完毕,有的还没有到达,那就是接收方能够接受的最大的网络包数量。
|
||
* 第三部分:还没接收,也没法接收的任务。这部分已经超出接收方能力。
|
||
|
||
在网络包的交互过程中,接收方会将第二部分的大小,作为AdvertisedWindow发送给发送方,发送方就可以根据他来调整发送速度了。
|
||
|
||
在tcp\_snd\_wnd\_test函数中,会判断sk\_buff中的end\_seq和tcp\_wnd\_end(tp)之间的关系,也即这个sk\_buff是否在滑动窗口的允许范围之内。如果不在范围内,说明发送要受限制了,我们就要把is\_rwnd\_limited设置为true。
|
||
|
||
接下来,tcp\_mss\_split\_point函数要被调用了。
|
||
|
||
```
|
||
static unsigned int tcp_mss_split_point(const struct sock *sk,
|
||
const struct sk_buff *skb,
|
||
unsigned int mss_now,
|
||
unsigned int max_segs,
|
||
int nonagle)
|
||
{
|
||
const struct tcp_sock *tp = tcp_sk(sk);
|
||
u32 partial, needed, window, max_len;
|
||
|
||
window = tcp_wnd_end(tp) - TCP_SKB_CB(skb)->seq;
|
||
max_len = mss_now * max_segs;
|
||
|
||
if (likely(max_len <= window && skb != tcp_write_queue_tail(sk)))
|
||
return max_len;
|
||
|
||
needed = min(skb->len, window);
|
||
|
||
if (max_len <= needed)
|
||
return max_len;
|
||
......
|
||
return needed;
|
||
}
|
||
|
||
```
|
||
|
||
这里面除了会判断上面讲的,是否会因为超出mss而分段,还会判断另一个条件,就是是否在滑动窗口的运行范围之内,如果小于窗口的大小,也需要分段,也即需要调用tso\_fragment。
|
||
|
||
在一个循环的最后,是调用tcp\_transmit\_skb,真的去发送一个网络包。
|
||
|
||
```
|
||
static int tcp_transmit_skb(struct sock *sk, struct sk_buff *skb, int clone_it,
|
||
gfp_t gfp_mask)
|
||
{
|
||
const struct inet_connection_sock *icsk = inet_csk(sk);
|
||
struct inet_sock *inet;
|
||
struct tcp_sock *tp;
|
||
struct tcp_skb_cb *tcb;
|
||
struct tcphdr *th;
|
||
int err;
|
||
|
||
tp = tcp_sk(sk);
|
||
|
||
skb->skb_mstamp = tp->tcp_mstamp;
|
||
inet = inet_sk(sk);
|
||
tcb = TCP_SKB_CB(skb);
|
||
memset(&opts, 0, sizeof(opts));
|
||
|
||
tcp_header_size = tcp_options_size + sizeof(struct tcphdr);
|
||
skb_push(skb, tcp_header_size);
|
||
|
||
/* Build TCP header and checksum it. */
|
||
th = (struct tcphdr *)skb->data;
|
||
th->source = inet->inet_sport;
|
||
th->dest = inet->inet_dport;
|
||
th->seq = htonl(tcb->seq);
|
||
th->ack_seq = htonl(tp->rcv_nxt);
|
||
*(((__be16 *)th) + 6) = htons(((tcp_header_size >> 2) << 12) |
|
||
tcb->tcp_flags);
|
||
|
||
th->check = 0;
|
||
th->urg_ptr = 0;
|
||
......
|
||
tcp_options_write((__be32 *)(th + 1), tp, &opts);
|
||
th->window = htons(min(tp->rcv_wnd, 65535U));
|
||
......
|
||
err = icsk->icsk_af_ops->queue_xmit(sk, skb, &inet->cork.fl);
|
||
......
|
||
}
|
||
|
||
```
|
||
|
||
tcp\_transmit\_skb这个函数比较长,主要做了两件事情,第一件事情就是填充TCP头,如果我们对着TCP头的格式。
|
||
|
||
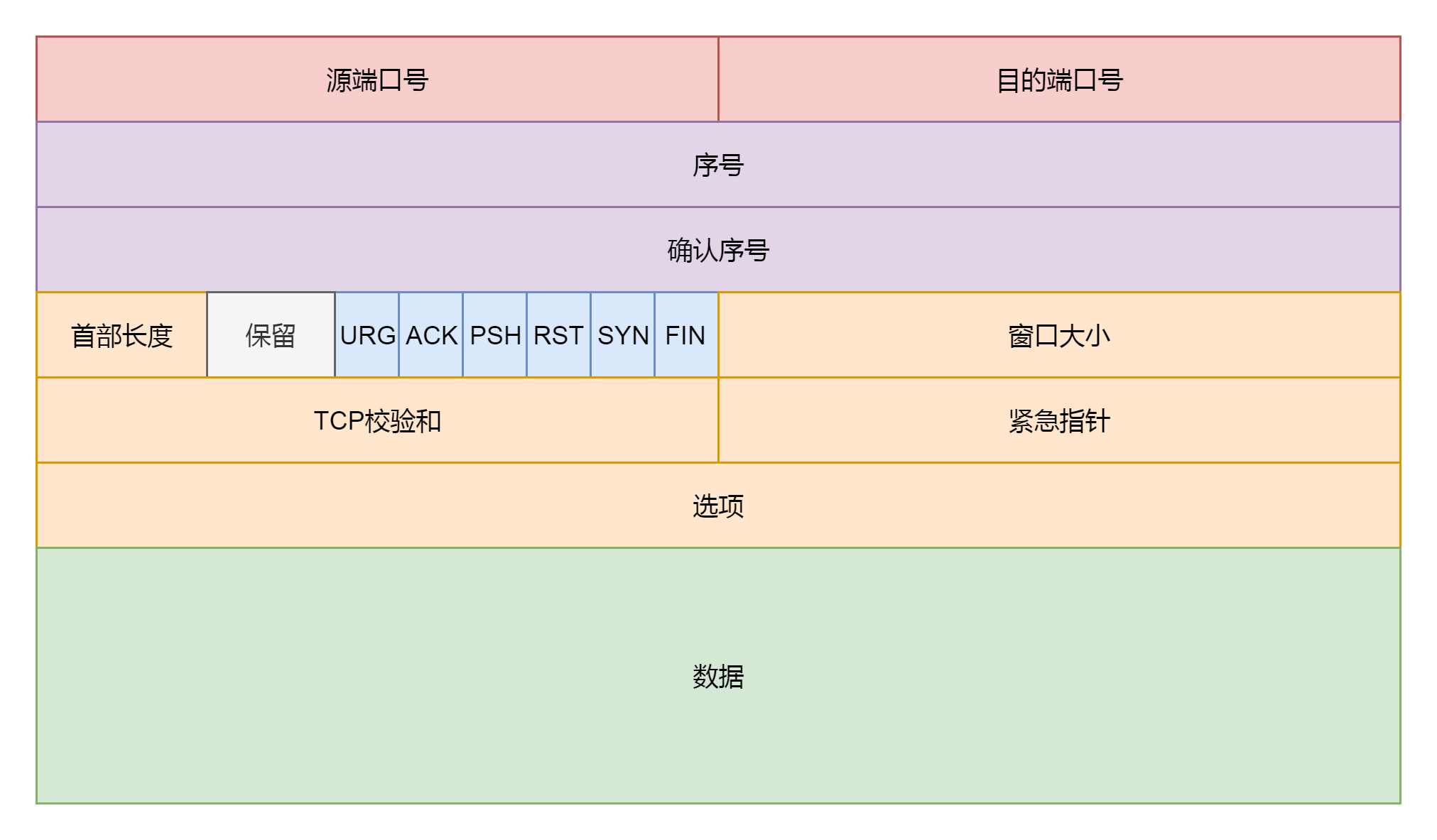
|
||
|
||
这里面有源端口,设置为inet\_sport,有目标端口,设置为inet\_dport;有序列号,设置为tcb->seq;有确认序列号,设置为tp->rcv\_nxt。我们把所有的flags设置为tcb->tcp\_flags。设置选项为opts。设置窗口大小为tp->rcv\_wnd。
|
||
|
||
全部设置完毕之后,就会调用icsk\_af\_ops的queue\_xmit方法,icsk\_af\_ops指向ipv4\_specific,也即调用的是ip\_queue\_xmit函数。
|
||
|
||
```
|
||
const struct inet_connection_sock_af_ops ipv4_specific = {
|
||
.queue_xmit = ip_queue_xmit,
|
||
.send_check = tcp_v4_send_check,
|
||
.rebuild_header = inet_sk_rebuild_header,
|
||
.sk_rx_dst_set = inet_sk_rx_dst_set,
|
||
.conn_request = tcp_v4_conn_request,
|
||
.syn_recv_sock = tcp_v4_syn_recv_sock,
|
||
.net_header_len = sizeof(struct iphdr),
|
||
.setsockopt = ip_setsockopt,
|
||
.getsockopt = ip_getsockopt,
|
||
.addr2sockaddr = inet_csk_addr2sockaddr,
|
||
.sockaddr_len = sizeof(struct sockaddr_in),
|
||
.mtu_reduced = tcp_v4_mtu_reduced,
|
||
};
|
||
|
||
```
|
||
|
||
## 总结时刻
|
||
|
||
这一节,我们解析了发送一个网络包的一部分过程,如下图所示。
|
||
|
||
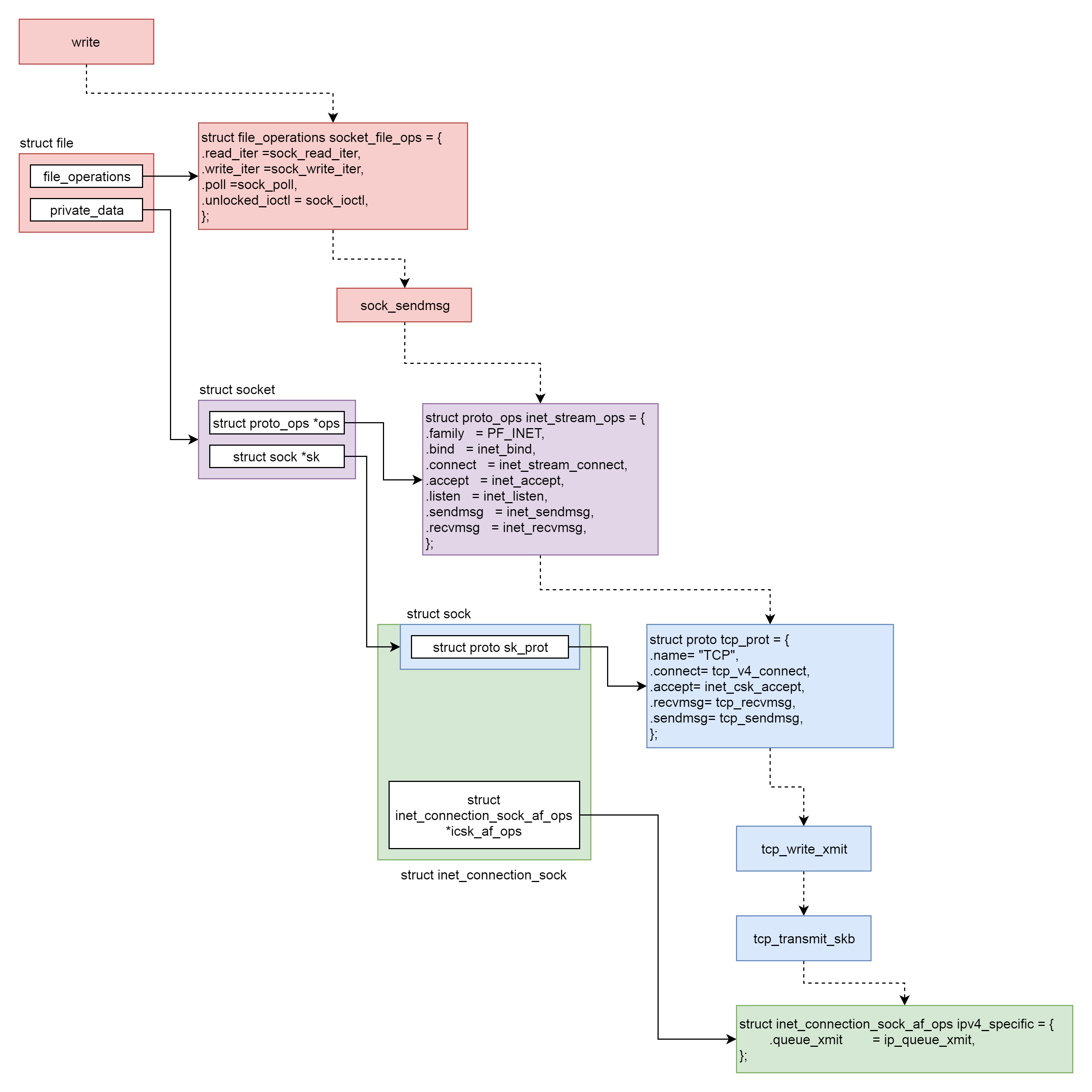
|
||
|
||
这个过程分成几个层次。
|
||
|
||
* VFS层:write系统调用找到struct file,根据里面的file\_operations的定义,调用sock\_write\_iter函数。sock\_write\_iter函数调用sock\_sendmsg函数。
|
||
* Socket层:从struct file里面的private\_data得到struct socket,根据里面ops的定义,调用inet\_sendmsg函数。
|
||
* Sock层:从struct socket里面的sk得到struct sock,根据里面sk\_prot的定义,调用tcp\_sendmsg函数。
|
||
* TCP层:tcp\_sendmsg函数会调用tcp\_write\_xmit函数,tcp\_write\_xmit函数会调用tcp\_transmit\_skb,在这里实现了TCP层面向连接的逻辑。
|
||
* IP层:扩展struct sock,得到struct inet\_connection\_sock,根据里面icsk\_af\_ops的定义,调用ip\_queue\_xmit函数。
|
||
|
||
## 课堂练习
|
||
|
||
如果你对TCP协议的结构不太熟悉,可以使用tcpdump命令截取一个TCP的包,看看里面的结构。
|
||
|
||
欢迎留言和我分享你的疑惑和见解 ,也欢迎可以收藏本节内容,反复研读。你也可以把今天的内容分享给你的朋友,和他一起学习和进步。
|
||
|