12 KiB
08 | 基础设施:全链路压测的环境有什么特点?
你好,我是高楼。
这节课,我们来聊一聊全链路压测的环境特点。
全链路压测在技术市场上叫嚣了好几年了,但是到现在为止还是有很多企业处在懵懂的状态。在开篇词中我们已经提到过,其中一部分原因是会涉及到很高的人工、资金和时间成本。另外,组织协调的问题也不容小觑。但是,为什么会有这么高的成本呢?其实这里的根源,都离不开全链路压测的环境。
全链路压测涉及到的基础设施范围不仅复杂,而且非常庞大。在复杂的网络结构、应用架构中,有数不胜数的可能影响性能的因素。如果只是简单地这么说,你可能不会有特别强烈的感觉。接下来,我们就具体地看一看。
线上环境中复杂的网络结构
下面是一个大企业的双数据中心的拓扑图。
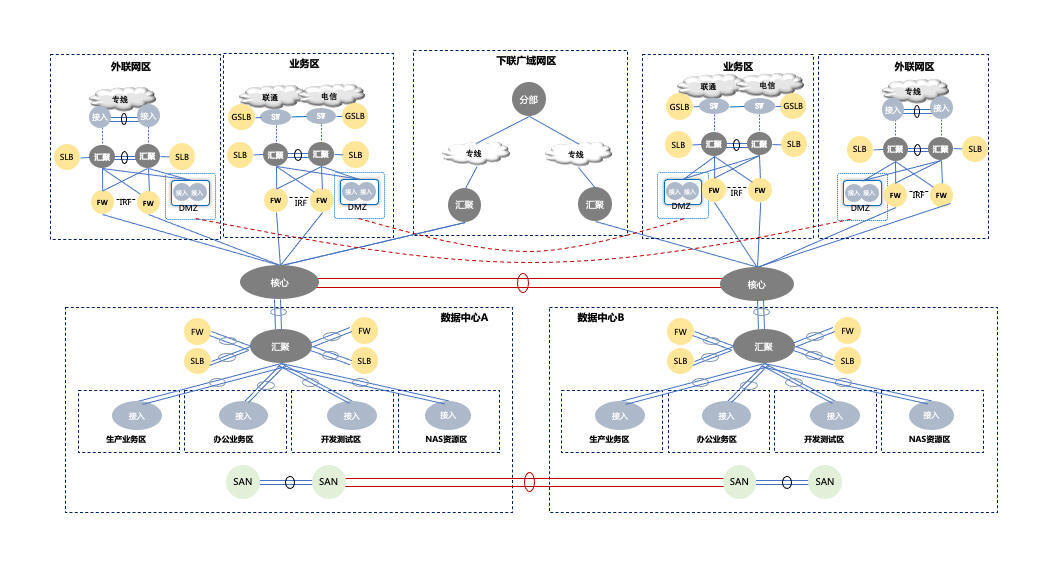
图中所展示的这个网络结构是为了高可用而设计的。因为是双数据中心,所以在这个结构的中心,两个设备虚拟化成了一个设备,汇聚层同理。
在这样的网络里,数据进来之后,会先接入防火墙(FW)、负载均衡(SLB),但它们还没到具体的分区。如果要进入分区,还要接入另一层网络设备,然后才能到达生产业务区、办公业务区、开发测试区、NAS资源区等。
这就完了吗?其实还没有。比方说,生产业务区就还有不同的子分区,你要经过子分区才能到达具体的系统里。
而现在的压测市场,通常都接触不到这么完整的网络架构,很多企业只是在内网的一些服务器上做些压测的操作,大一点的也就是跨几个VLAN(虚拟局域网)了事。还有一些大的企业,据我所知,虽然对外宣传全链路压测做得多么完备,但是在实际执行的过程中,还是分段玩的。
可以看到,两中心的网络结构已经这么复杂了,但这还远不是最复杂的。我们再来看看两地三中心的网络结构是什么样子。
我依旧用拓扑图来展示,为了方便大家理解起见,外网的部分我就不画了。
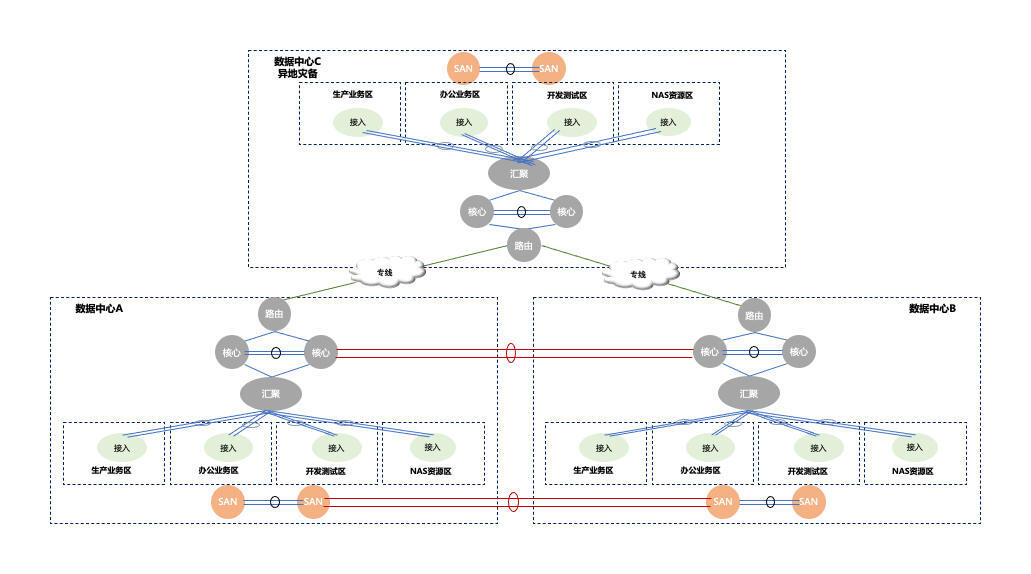
在这种两地三中心的网络架构中,各中心之间是用专线连接的,数据中心A、B会同时提供服务,数据中心C主要是用于异地灾备。
在这个基础上,我们再添加一下网络结构就会成为下面的样子。
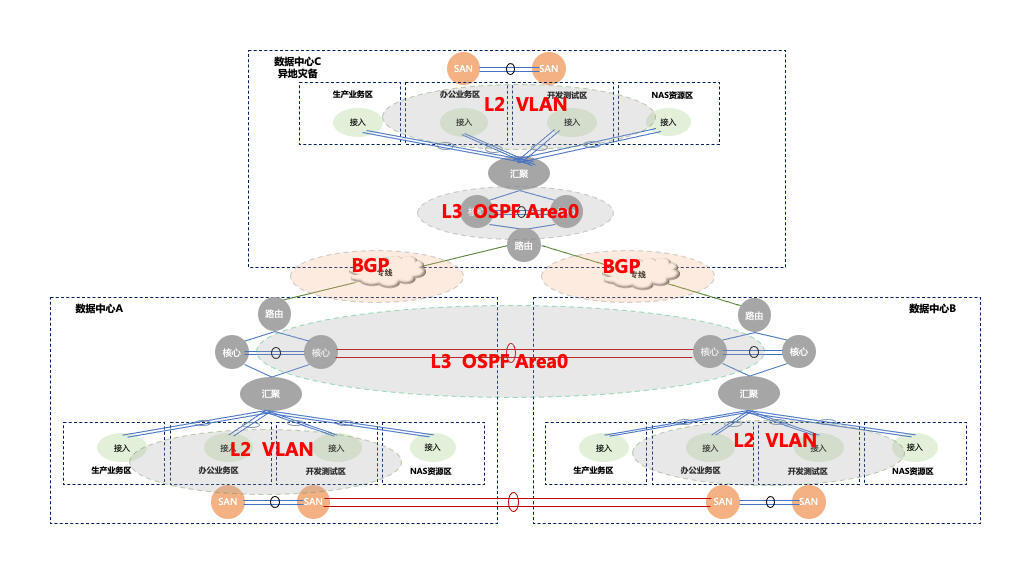
在这个网络结构中,数据中心之间使用的是BGP(Border Gateway Protocol,边界网关协议)协议,数据中心A、B之间使用的是OSPF(Open Shortest Path First、开放式最短路径优先)协议,各分区之间使用的是二层VLAN。
我们不仅要在二层VLAN的网络结构中做压测,数据中心之间的网络也不能忽略。
那再来延伸一下。由于微服务分布式技术的发展,以及云计算基础设施服务的支撑,两地三中心也快成为过去式了,随之而来的是多地多中心的网络结构:
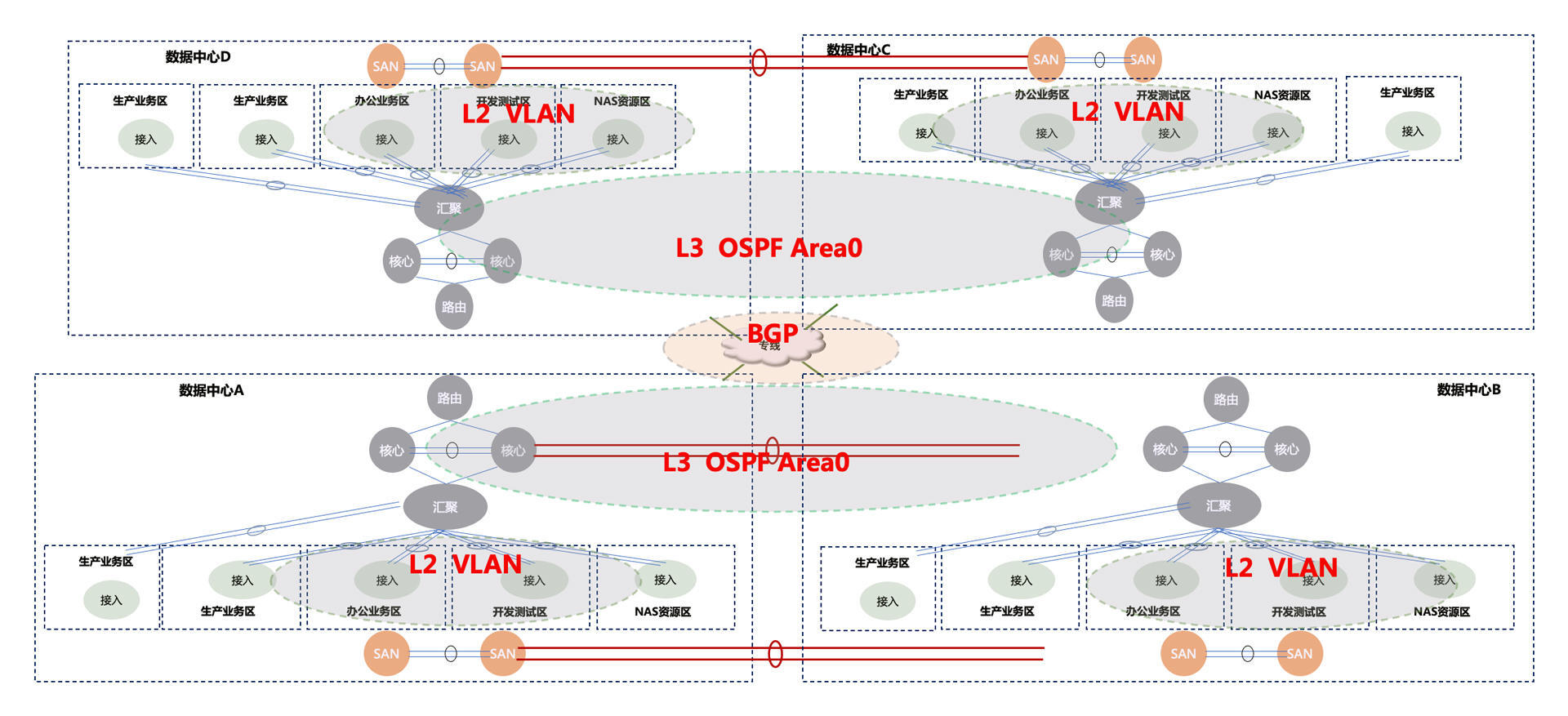
图中有四个中心,对于一些重要的业务来说,四个中心都需要灵活部署的。
你还可以看到,数据中心A、B可以组成一个联邦,数据中心C、D是另一个联邦。每个数据中心都有两个生产业务区,这两个生产数据区之间是可以数据同步的。不过,数据中心A、B和数据中心C、D之间是数据异步的。这些都是为了保证整个企业的业务高可用。
我们把这些数据中心对应到地域上再来看一下。
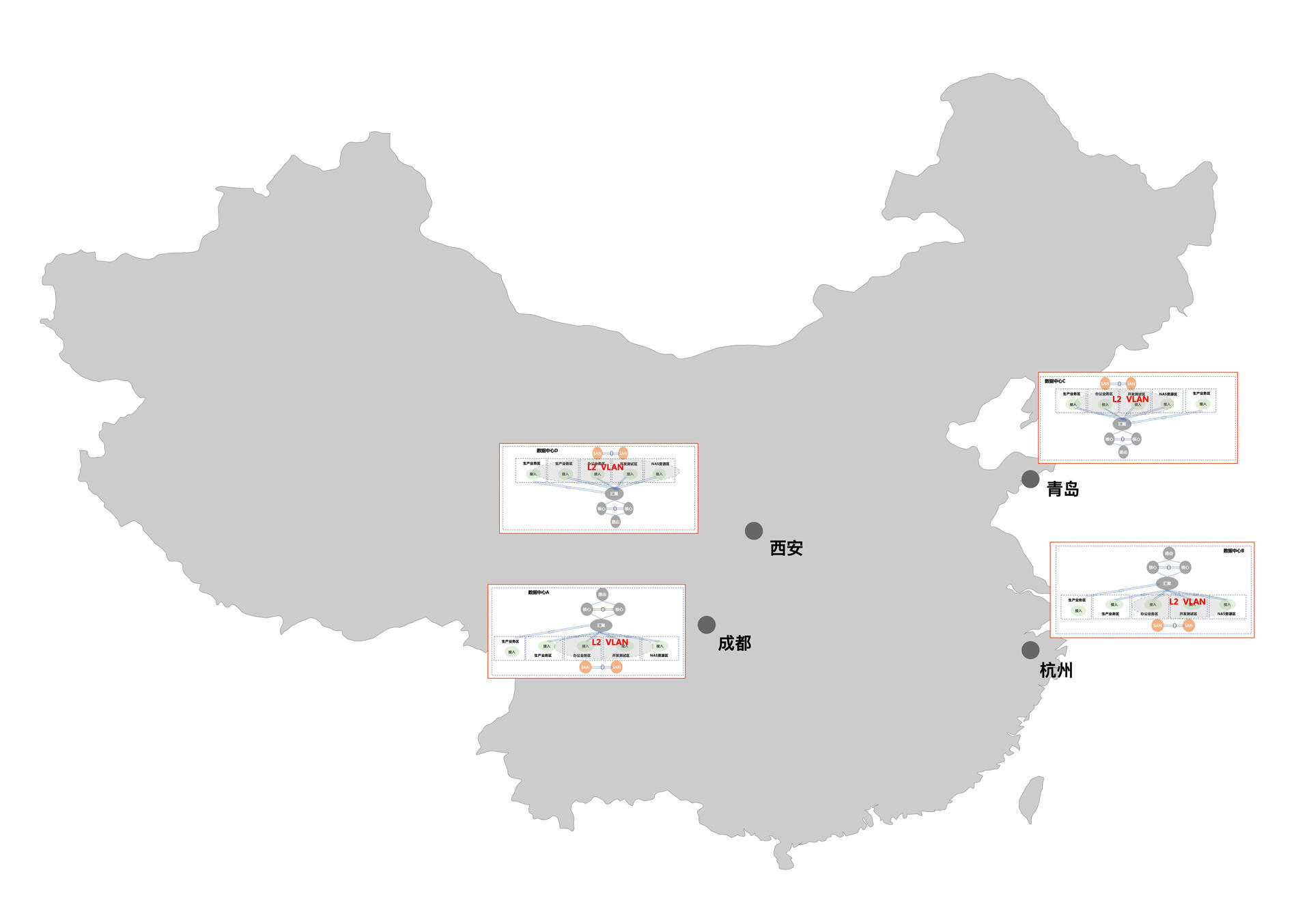
这四个数据中心分布在不同的城市。每个数据中心需要的硬件设备总量完全取决于这个企业的体量,有的几十万台,有的几万台,也有的几千台。
之所以需要这么多设备,是为了满足这么大的容量要求,当然这里也包括了容灾冗余的要求。
如果只是考虑接口级的请求,这个网络结构大概就够了,无非是再加上一些ISP的DNS服务器。但是,我还想再多讲一点,因为对于一些企业来说,还有一个需要关注的大头:CDN。
对于CDN网络架构来说,像上面这样规划显示是过于集中了。如果我们使用CDN架构,它的地域分布应该是这样的:
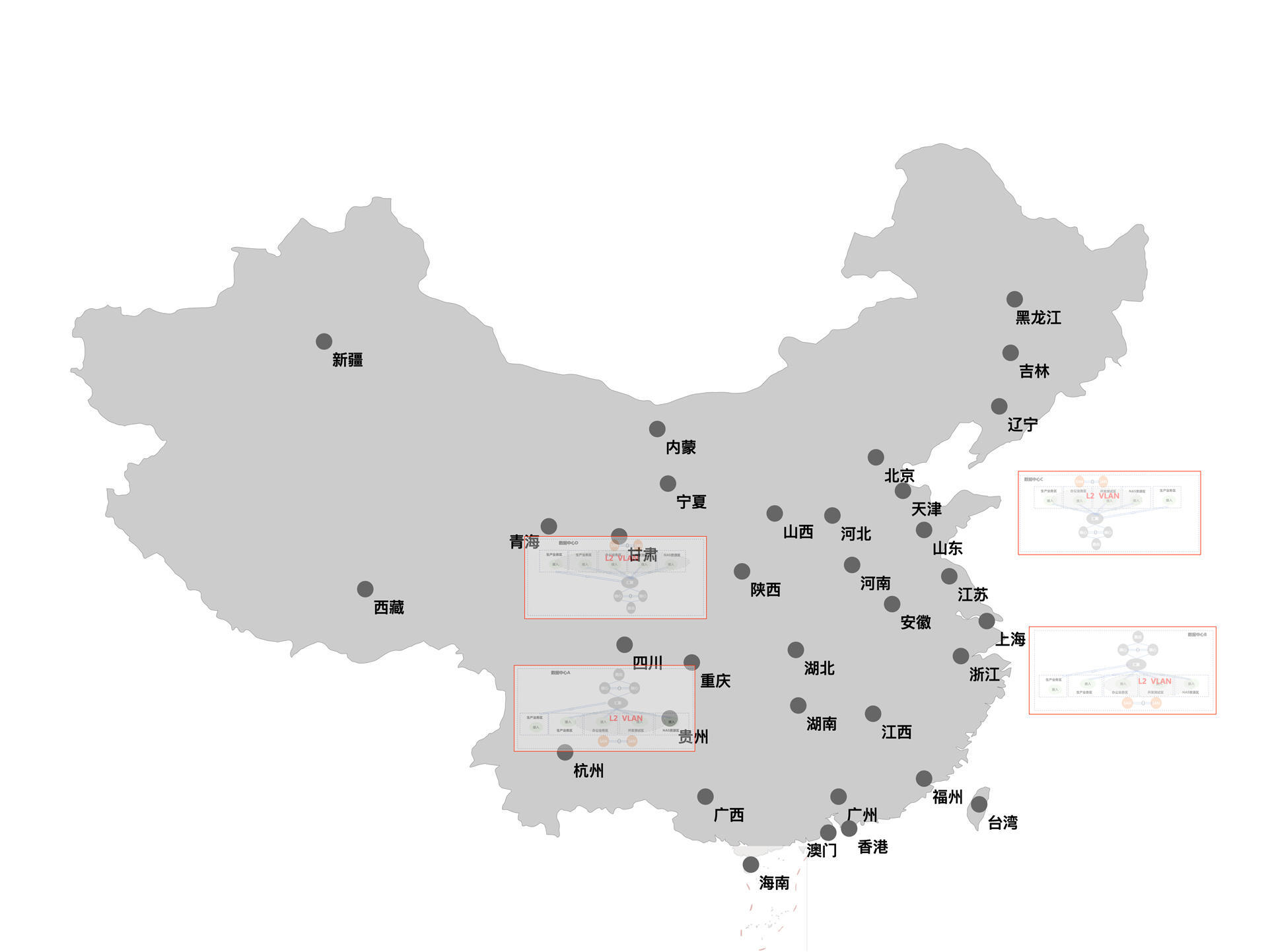
可以看到,针对全国所有的省市,我们都要放CDN的节点。这样,一些静态资源就可以从最近的CDN服务器上获取了,比如电商系统中的商品图片、视频系统中的视频等。这样不仅速度快,也可以节省更多的主干网络资源。
不过,现在各厂商的全链路压测的逻辑中,其实是不包括CDN的部分的,我之所以讲它是希望你可以对线上环境有个更全面的认知。由于做全链路压测的重点在业务系统,而CDN是由独立的系统完成的,并且CDN服务的稳定性由CDN厂商负责,所以CDN没有必要包含在业务系统中,也就没有必要包含在全链路压测中了。
讲到这里估计你已经能够感受到了,真正的线上压测要组织起来,从环境上来讲确实是太复杂了。
线上环境中复杂的应用架构
说了这么多网络结构的问题,我们再来看看应用架构。先来看下我给你画的这张图。
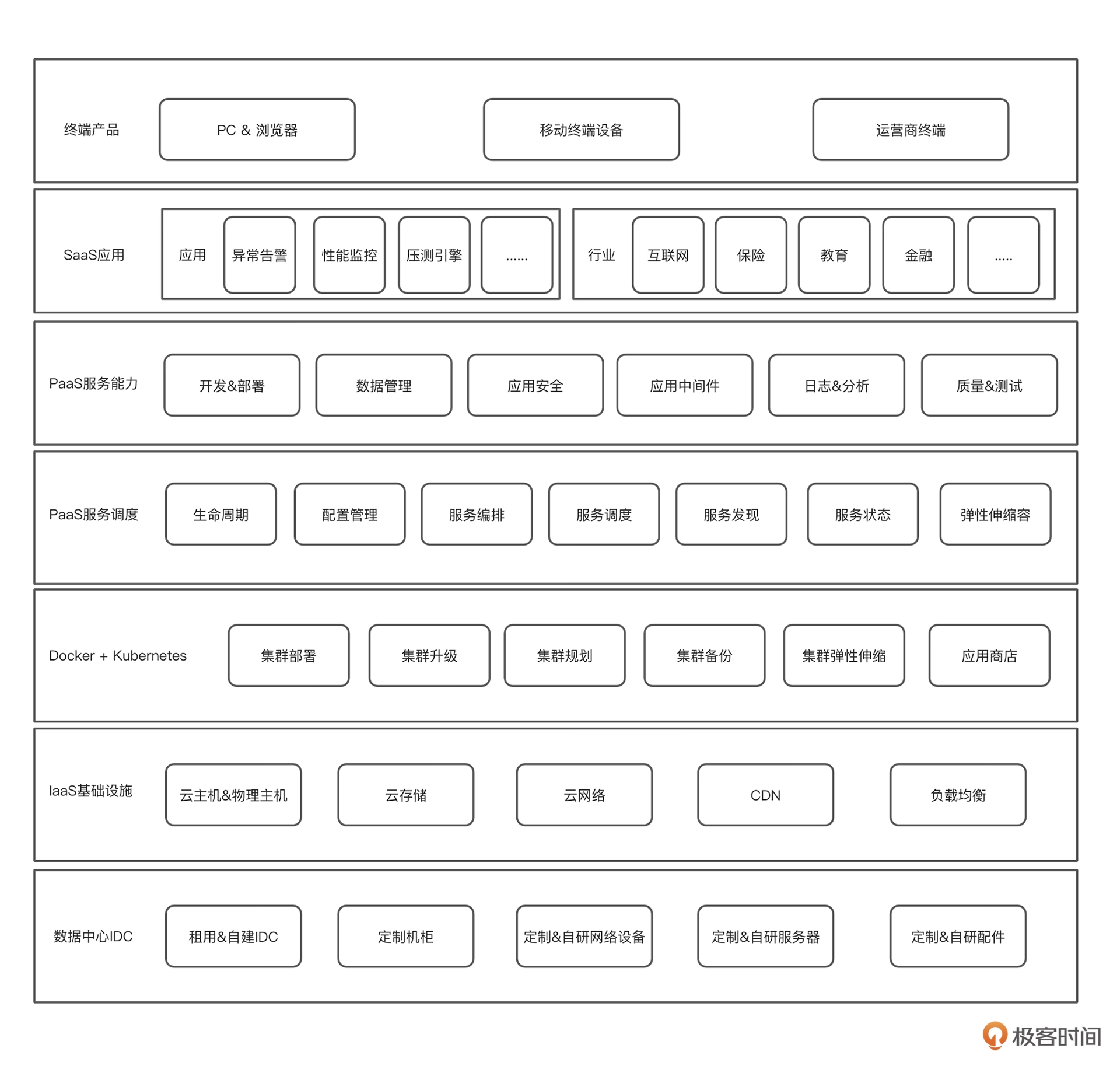
可以看得出,在应用架构方面,一个系统要最终展现到用户面前,还是需要很多技术支撑的。
这些技术大体分为三个层级,也就是 IaaS、PaaS 和 SaaS 。这个层级的划分在不同的企业中并不完全相同,还好无伤大雅,即便划分不同说出来大家也都能理解。
上面这个图可能还是太过笼统了,没有应用、服务细节,看起来还是不太像一个应用系统的架构。我们就再换一个视角,看看一个应用系统架构该有的样子:
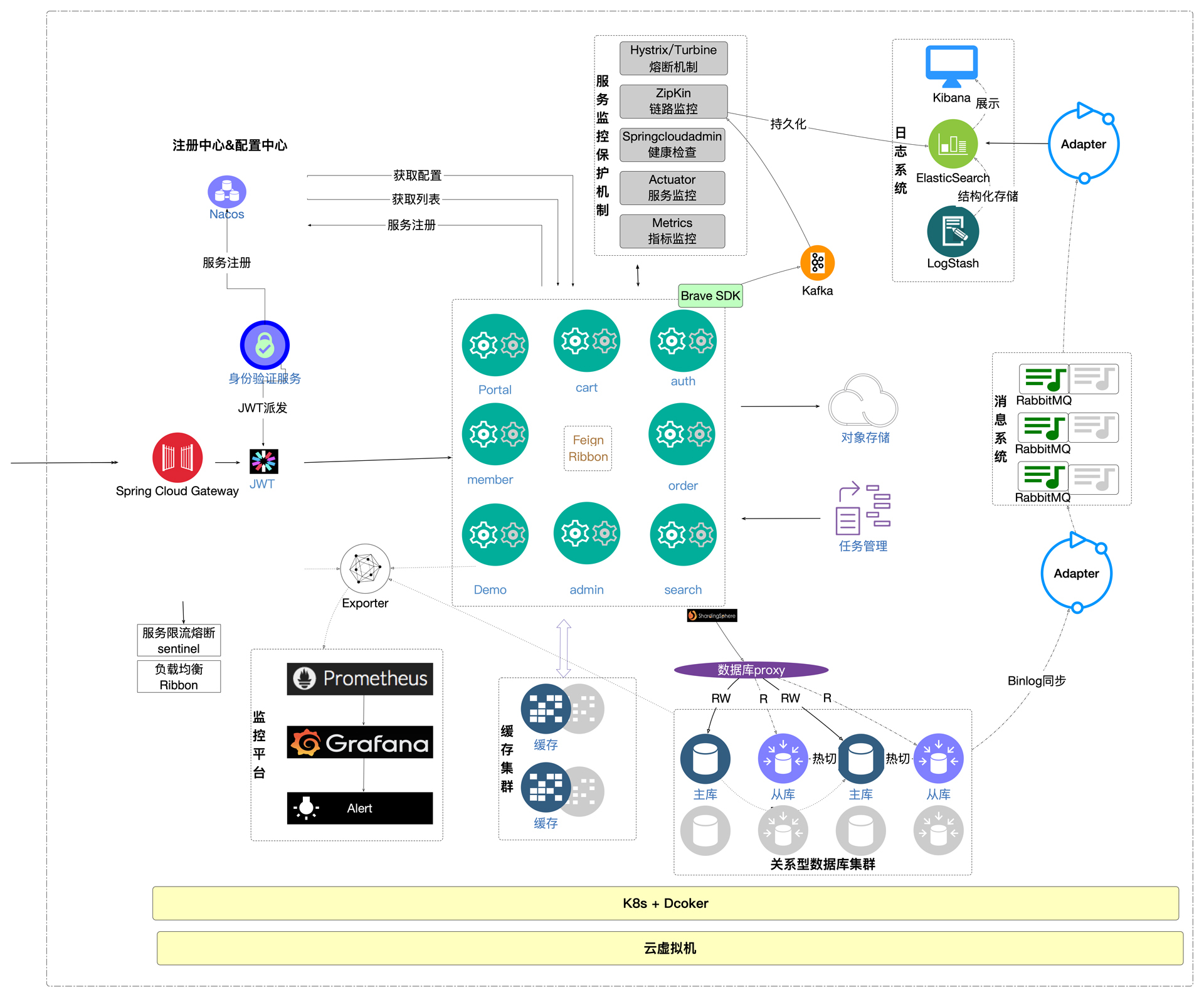
这张图是不是更容易理解了一些?
在这个应用中,用户会从Nginx这样的入口进来(请记住,一个终端用户要想进到这个入口,已经经过了漫长的网络结构),经过网关,然后根据具体的业务访问不同的服务。
这还只是一个系统,而大部分的企业都有很多系统。在我已知的企业级IT架构中,一些大的企业怎么也有几百个系统,一些中小型企业也能达到几十个系统。在这样的量级下,要想把系统完整地搭建起来,可想而知需要多少干体力活的劳工不眠不休地干上几个月。
再加上,企业的整个IT架构也不是一成不变的,每个系统都需要反复的迭代。这就是全链路压测的整体环境为什么那么复杂的另一个原因了。
其实,只是像我们专栏这个项目的量级,搭建的部分最快也得近一个月才能完成。如果再遇到一些鸡毛蒜皮、鸡飞狗跳的技术问题,成本就更加不可控了。
线上性能的影响因素
前面我们了解了网络和应用架构的复杂度,从刚才的分析中我们可以知道,全链路压测出现的前提是,测试环境中构建基础设施和应用资源的成本非常高,所以我们才需要把全链路压测放到线上环境中去执行。
既然要在线上环境中执行,就需要知道影响线上性能的因素有哪些。我们先以应用为核心,对线上资源做个拆解。
基础设施资源方面:
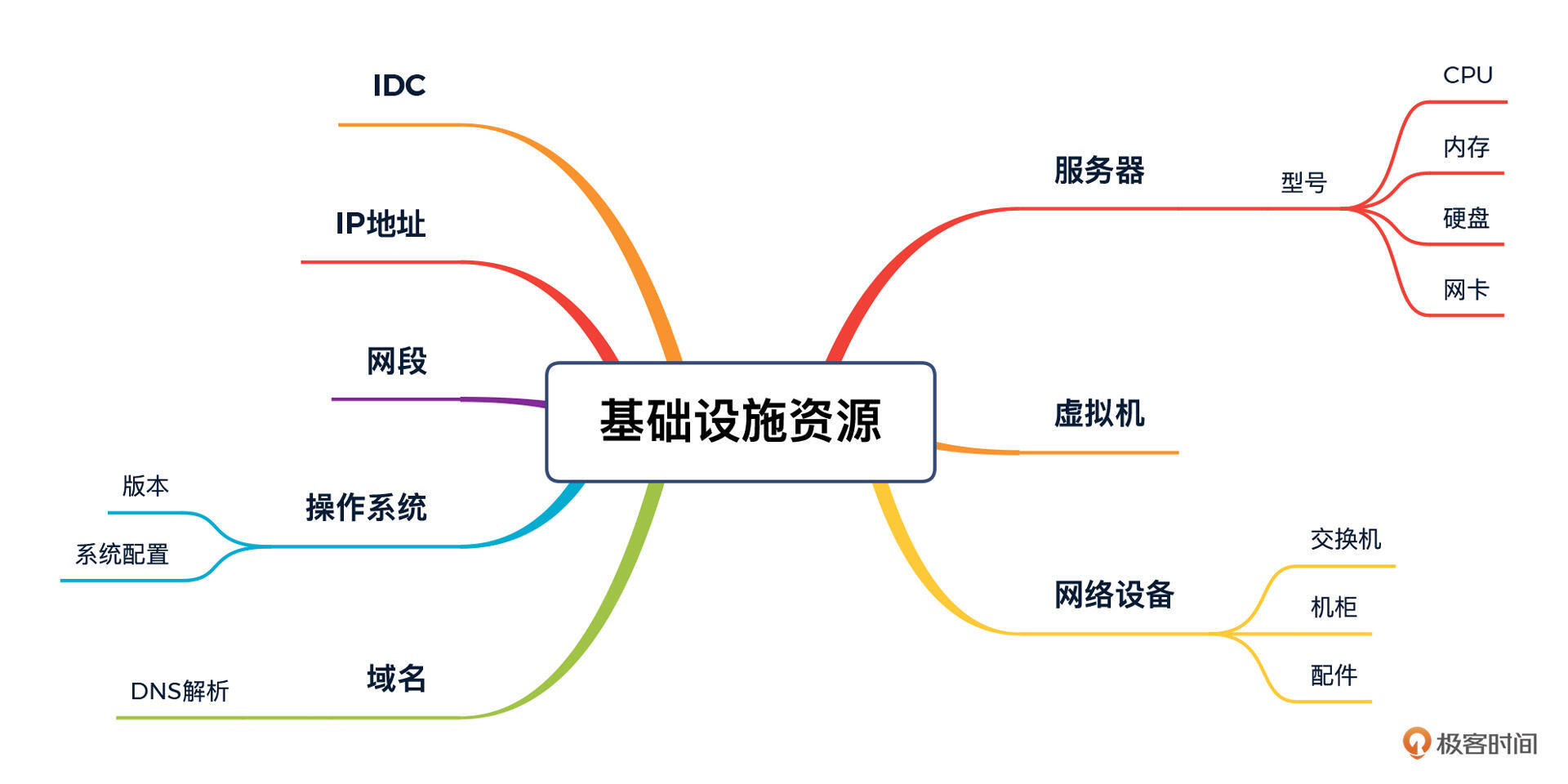
可以看到,从服务器到操作系统、从域名到网络设备、从IDC到机柜等,都属于基础设施资源的范畴。
应用资源方面:
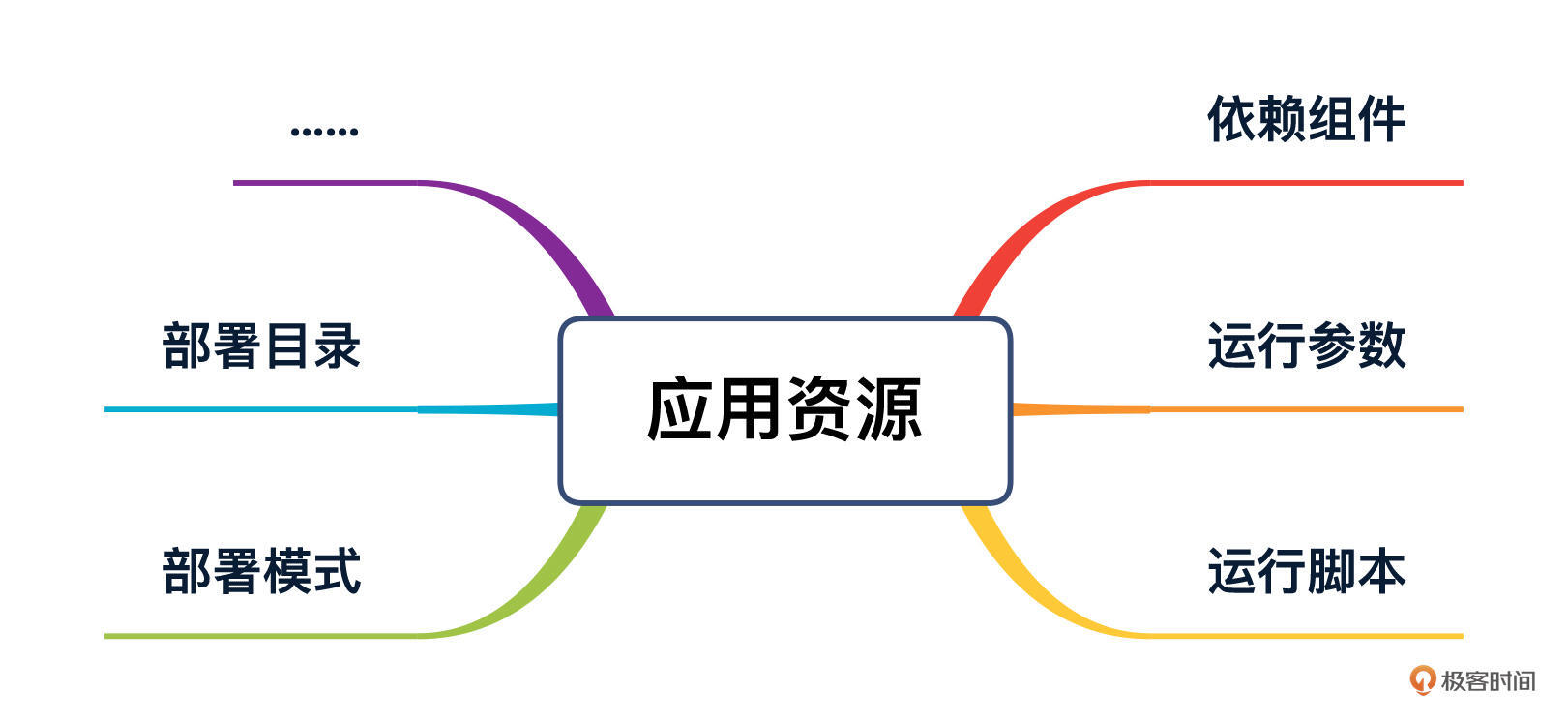
我们知道,很多应用程序的性能问题都可能是第三方依赖引起的,与此同时,应用的运行参数以及部署方式也对性能有着很大的影响。
找齐了这些要素,我们就来总结归纳一下:影响线上性能问题的因素有哪些?
我给你画了张图,你可以参考一下。
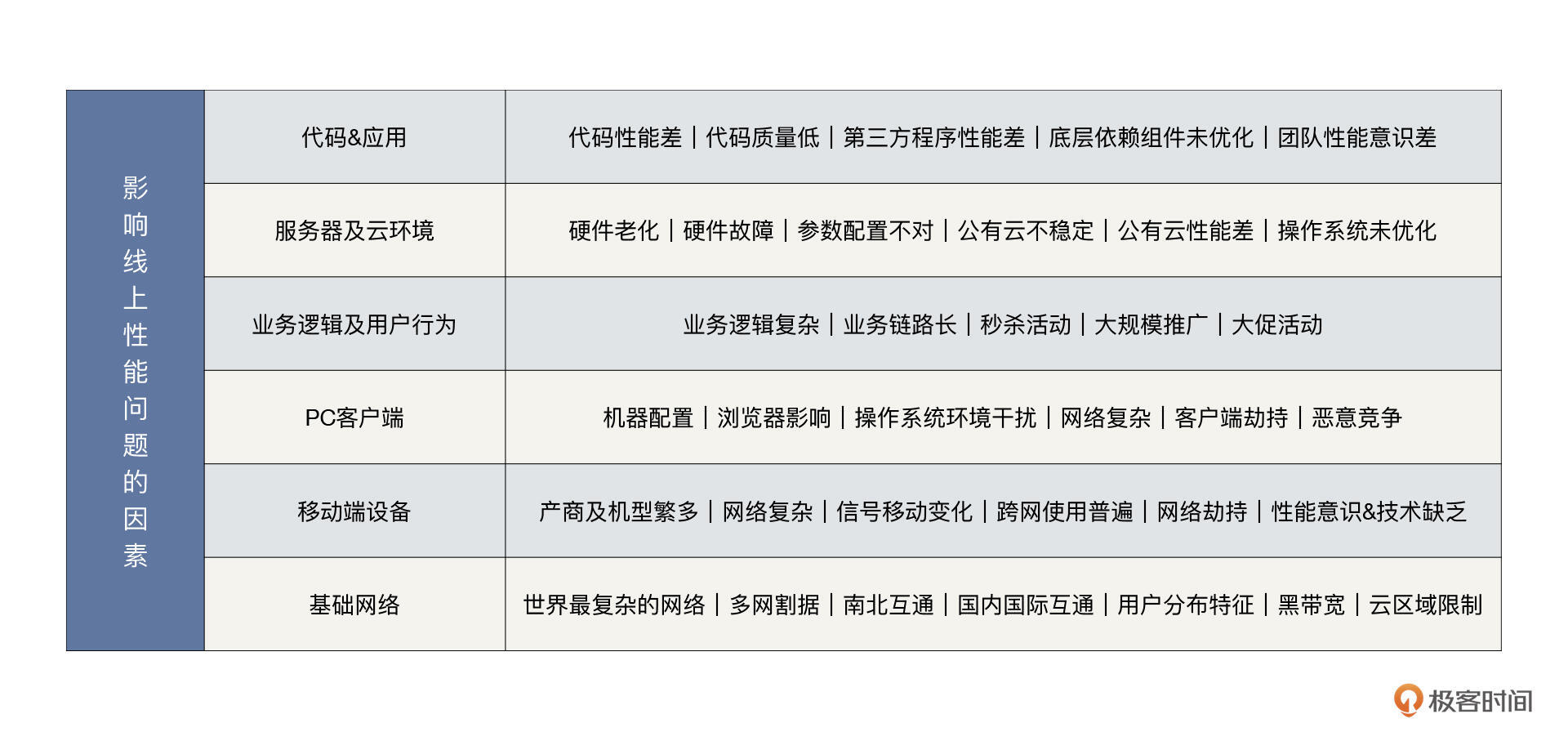
看到这么多影响线上性能的因素,你是不是有点懵?实际上我这里还只列举了我认为最重要的一小部分。那么,是不是所有项目的线上性能都会被这么多因素影响呢?
当然也不是。我这里举的例子只是上了规模的互联网项目,如果你所在的项目只是 ToB 的企业内网项目,系统拓扑肯定是没有这么复杂的。你也可以尝试着按照“横向-纵向”的逻辑把你所在项目的拓扑图画一画。
从以上的描述中就可以看到,虽然我们在线上执行全链路压测是符合压测目标的,但是仍然会有不少需要考虑的因素,这些因素也构成了全链路线上压测的复杂性,当然这些也是我们必须要面对并解决的问题。
全链路压测线下环境亦有挑战
好了,上面我们已经看到了,大型项目的线上环境,在性能方面会面临非常多的挑战。那如果我们知难而退,不做线上压测了,考虑对线上环境做镜像环境、做线下测试,我们又会面临什么挑战呢?
我简要总结了几点:
- 复制线上环境网络环境;
- 复制线上环境基础资源;
- 复制线上环境应用架构;
- 保证网络带宽;
- 准备所有的基础数据;
- …
显然,这对于性能工程师来说,压力太大了。要完成上面这些需求,面临巨大的困难:
- 需要沟通协调几乎所有的相关部门(开发、运维、网络……);
- 成本也是个大问题,一些大的企业通常都是多地多中心的,涉及到公网出入口、各层网络设备、防火墙等等内容,搭建一套一样的环境的成本,纵然是大企业也得掂量掂量。可以想象,如果只是使用一两次,那么就是劳民伤财,成本根本兜不住;如果持续维护,维护成本也同样不可持续。
所以,我们很少看到有企业进行这样的“镜像环境”操作。即便做线下的全链路压测,环境问题依旧很复杂,所以在线上做全链路压测仍然是首选的方案。
总结
好了,这节课就讲到这里,我们总结一下。全链路压测的环境一大特点就是非常复杂,它的复杂性主要体现在以下几个方面:
首先是互联网环境复杂,这不仅仅体现在层级复杂上,而且还具有显著的地域性。
另外,基础设施也是个很大的问题,分布式、云计算、云原生的广泛应用导致现如今的基础设施越来越庞大,其中的人力和时间成本不可低估。
还有,影响线上性能的因素也很多,包括代码、应用、服务器及云环境、业务逻辑及应用行为等等,这都给大型互联网项目在性能方面提出了非常多的挑战。
我们知道,互联网最大的趋势和变化就是海量数据、海量用户导致架构对分布式、云计算、云原生更加依赖,高速发展的独角兽企业会因此遇到很多挑战和困难,但也催生了许多成熟、成功的全链路压测方案。但是,我们还是得着眼实际,打造适合自己项目的特殊的全链路压测。毕竟,技术太过纯粹,适用才是王道。
课后题
学完这节课,请你思考两个问题:
- 除了线下镜像环境,你还知道哪几种搭建环境的方式?
- 在线上做全链路压测的过程中,你遇到过哪些环境问题?
欢迎你在留言区与我交流讨论。当然了,你也可以把这节课分享给你身边的朋友,他们的一些想法或许会让你有更大的收获。我们下节课见!