19 KiB
11 | 为什么说Shuffle是一时无两的性能杀手?
你好,我是吴磊。
一提到Shuffle,你能想到什么?我想很多人的第一反应都是应用中最顽固、最难解决的性能瓶颈。
在之前的课程中,我们也不止一次地提到Shuffle,尤其是在开发原则那一讲,我还建议你遵循“能省则省、能拖则拖”的原则,在应用中尽量去避免Shuffle,如果受业务逻辑所限确实不能避免,就尽可能地把Shuffle往后拖。
那么,为什么我们一谈Shuffle就色变,提到它就避之唯恐不及呢?今天这一讲,我就通过实现一个仙女散花游戏的过程,来和你深入探讨Shuffle是如何工作的,说说它为什么是分布式应用一时无两的性能杀手。毕竟,只有了解Shuffle的工作原理,我们才能更好地避免它。
如何理解Shuffle?
假设,你的老板今天给你安排一个开发任务,让你用Spark去实现一个游戏需求。这个实现需求来自一个小故事:仙女散花。
很久以前,燕山脚下有个小村庄,村子里有所“七色光”小学,方圆百里的孩子都来这里上学。这一天,一年级2班的黄老师和班里的五个孩子正在做一个游戏,叫做“仙女散花”。
黄老师的背包里装满了五种不同颜色的花朵,五种颜色分别是红、橙、黄、紫、青。她把背包里的花朵随机地分发给五个小同学:小红、橙橙、黄小乙、阿紫和小青。花朵发完之后,每个同学分到的花朵数量差不多,颜色各有不同。
接着,黄老师开始宣布游戏规则:“你们要一起协作,在最短的时间内,把花朵按照颜色收集在一起。游戏完成的标志是,课桌上有5堆花朵,每堆花朵的颜色都是一样的。”

大家跃跃欲试,黄小乙说:“先别急,我们来制定个策略。先在前面摆上5张课桌,然后每个人需要做两件事情,先把自己手里的花朵按照颜色归类分为5堆,再把分好颜色的花朵,分别放到相应的课桌上!”于是,几个小同学按照黄小乙说的策略,不一会儿就完成了游戏。
事实上,仙女散花的游戏过程和Shuffle的工作流程大同小异。当然,Shuffle过程中涉及的步骤和环节,要比“仙女散花”复杂一些。
Shuffle的本意是“洗牌”,在分布式计算环境中,它有两个阶段。一般来说,前一个阶段叫做“Map阶段”,后一个阶段叫做“Reduce阶段”。当然,也有人把它们叫做Shuffle Write阶段和Shuffle Read阶段。

在仙女散花的游戏中,从老师分发花朵,到5个小同学把花朵按照颜色归类,对应的是Shuffle的Map阶段,而大家把归类的花朵分发到相应的课桌,这个过程类似于Shuffle的Reduce阶段。
接下来,我们就借助这个故事来深入探讨Shuffle的两个阶段:Map阶段和Reduce阶段。
自2.0版本之后,Spark将Shuffle操作统一交由Sort shuffle manager来管理。因此,今天这一讲,我们专注于Sort shuffle manager实现的Shuffle分发过程。
Map阶段是如何输出中间文件的?
以终为始、以结果为导向的学习往往效率更高,在深入探讨Map阶段如何生产数据之前,我们不妨先来明确:Map阶段的输出到底是什么?
之前我们也说过,Map阶段最终生产的数据会以中间文件的形式物化到磁盘中,这些中间文件就存储在spark.local.dir设置的文件目录里。中间文件包含两种类型:一类是后缀为data的数据文件,存储的内容是Map阶段生产的待分发数据;另一类是后缀为index的索引文件,它记录的是数据文件中不同分区的偏移地址。这里的分区是指Reduce阶段的分区,因此,分区数量与Reduce阶段的并行度保持一致。

这样一来,我们就可以把问题进一步聚焦在,Spark在Map阶段是如何生产这些中间文件的。不过,我们首先需要明确的是,Map阶段每一个Task的执行流程都是一样的,每个Task最终都会生成一个数据文件和一个索引文件。**因此,中间文件的数量与Map阶段的并行度保持一致。**换句话说,有多少个Task,Map阶段就会生产相应数量的数据文件和索引文件。
接下来,我带你用Spark来实现“仙女散花”的游戏,咱们一边做游戏,一边来分析Map阶段的中间文件是如何产生的。
用groupByKey实现“仙女散花”
在“仙女散花”的游戏中,黄老师要求大家把同一种花色的花朵收集到一起。那么,在Spark的分布式开发框架内,与这个游戏最相仿的计算过程非groupByKey莫属,所以我们不妨用groupByKey来实现游戏。
首先是flowers.txt文件:
黄色花朵
紫色花朵
红色花朵
橙色花朵
青色花朵
黄色花朵
紫色花朵
橙色花朵
青色花朵
......
其次是同学小A接到需求后,用groupByKey实现“仙女散花”游戏的代码:
val flowers = spark.sparkContext.textFile("flowers.txt")
//黄老师给5个小同学分发花朵
val flowersForKids = flowers.coalesce(5)
val flowersKV = flowersForKids.map((_, 1))
//黄小乙的两个步骤:大家先各自按颜色归类,然后再把归类后的花朵放到相应的课桌上
flowersKV.groupByKey.collect
我们可以看到,代码步骤与游戏过程基本上一一对应。但是,读取完花朵文件之后,由于groupByKey是pairRDD算子,需要消费(Key,Value)形式的数据,因此我们需要对原始花朵数据做一次转换。以数据分区0为例,数据的转换过程如下图所示,你不妨把数据分区0理解为是黄老师分发给小红的花朵。

基于pairRDD的Key,也就是花朵的颜色,Map Task就可以计算每条数据记录在Reduce阶段的目标分区,目标分区也就是游戏中的课桌。在黄小乙制定的策略中,哪种花放到哪张桌子是大家事先商定好的,但在Spark中,每条数据记录应该分发到哪个目标分区,是由Key的哈希值决定的。
目标分区计算好之后,Map Task会把每条数据记录和它的目标分区,放到一个特殊的数据结构里,这个数据结构叫做“PartitionedPairBuffer”,它本质上就是一种数组形式的缓存结构。它是怎么存储数据记录的呢?
每条数据记录都会占用数组中相邻的两个元素空间,第一个元素是(目标分区,Key),第二个元素是Value。假设PartitionedPairBuffer的大小是4,也就是最多只能存储4条数据记录。那么,如果我们还以数据分区0为例,小红的前4枚花朵在PartitionedPairBuffer中的存储状态就会如下所示。

对我们来说,最理想的情况当然是PartitionedPairBuffer足够大,大到足以容纳Map Task所需处理的所有数据。不过,现实总是很骨感,每个Task分到的内存空间是有限的,PartitionedPairBuffer自然也不能保证能容纳分区中的所有数据。因此,Spark需要一种计算机制,来保障在数据总量超出可用内存的情况下,依然能够完成计算。这种机制就是:排序、溢出、归并。
就拿大小为4的PartitionedPairBuffer来说,数据分区0里面有16朵花,对应着16条数据记录,它们至少要分4批才能依次完成处理。在处理下一批数据之前,Map Task得先把PartitionedPairBuffer中已有的数据腾挪出去,腾挪的方式简单粗暴,Map Task直接把数据溢出到磁盘中的临时文件。
不过,在溢出之前,对于PartitionedPairBuffer中已有的数据,Map Task会先按照数据记录的第一个元素,也就是目标分区 + Key进行排序。也就是说,尽管数据暂时溢出到了磁盘,但是临时文件中的数据也是有序的。
就这样,PartitionedPairBuffer腾挪了一次又一次,数据分区0里面的花朵处理了一批又一批,直到所有的花朵都被处理完。分区0有16朵花,PartitionedPairBuffer的大小是4,因此,PartitionedPairBuffer总共被腾挪了3次,生成了3个临时文件,每个临时文件中包含4条数据记录。16条数据,有12条分散在3个文件中,还有4条缓存在PartitionedPairBuffer里。
到此为止,我们离Map阶段生产的、用于在网络中分发数据的中间文件仅有一步之遥了。还记得吗?Map阶段生产的中间文件有两类,一类是数据文件,另一类是索引文件。分散在3个临时文件和PartitionedPairBuffer里的数据记录,就是生成这两类文件的输入源。最终,Map Task用归并排序的算法,将4个输入源中的数据写入到数据文件和索引文件中去,如下图所示。

好了,到目前为止,我们用groupByKey实现了“仙女散花”的游戏,详细讲解了Map阶段生产中间文件的过程。虽然Map阶段的计算步骤很多,但其中最主要的环节可以归结为4步:
1. 对于分片中的数据记录,逐一计算其目标分区,并将其填充到PartitionedPairBuffer;
2. PartitionedPairBuffer填满后,如果分片中还有未处理的数据记录,就对Buffer中的数据记录按(目标分区ID,Key)进行排序,将所有数据溢出到临时文件,同时清空缓存;
3. 重复步骤1、2,直到分片中所有的数据记录都被处理;
4. 对所有临时文件和PartitionedPairBuffer归并排序,最终生成数据文件和索引文件。
不难发现,仙女散花其实就是个分组、收集的游戏。应该说,用Spark来实现分组、收集类的游戏还是比较简单的,那么,如果把仙女散花变成是“分组、统计”的游戏,我们该怎么做呢?
“仙女散花”游戏升级
5个小同学完成游戏之后,离下课时间还早。因此,黄老师调整了游戏规则:“你们五个人还是一起协作,这次要在最短的时间内,统计不同花色花朵的数量。”
小红迫不及待地说:“很简单!还是按照刚才的策略,先把花朵分好堆,然后我们五个人分别去课桌上数数就好啦!”

黄小乙皱了皱眉,说道:“别急,新的游戏规则也是有时间限制的,我想了一个和你差不多的办法,一共分三步:第一步,每个人把手里不同花色花朵的数量先算出来;第二步,我们只需要把花朵的数量写到相应的桌子上;第三步,我们分别对五张课桌上的数字求和。这样就能完成得更快了”

用reduceByKey实现升级后的仙女散花
如果我们想用Spark来实现升级后的游戏,该怎么办呢?其实很简单,只要把groupByKey换成reduceByKey就好了。
val flowers = spark.sparkContext.textFile("flowers.txt")
//黄老师给5个小同学分发花朵
val flowersForKids = flowers.coalesce(5)
val flowersKV = flowersForKids.map((_, 1))
//黄小乙的两个步骤:大家先各自按颜色计数,然后再按照课桌统一计数
flowersKV.reduceByKey(_ + _).collect
接下来,我们来分析一下reduceByKey的Map阶段计算,相比groupByKey有何不同。就Map端的计算步骤来说,reduceByKey与刚刚讲的groupByKey一样,都是先填充内存数据结构,然后排序溢出,最后归并排序。
区别在于,在计算的过程中,reduceByKey采用一种叫做PartitionedAppendOnlyMap的数据结构来填充数据记录。这个数据结构是一种Map,而Map的Value值是可累加、可更新的。因此,PartitionedAppendOnlyMap非常适合聚合类的计算场景,如计数、求和、均值计算、极值计算等等。

在上图中,4个KV对的Value值,是扫描到数据分区0当中青色花朵之前的状态。在PartitionedAppendOnlyMap中,由于Value是可累加、可更新的,因此这种数据结构可以容纳的花朵数量一定比4大。因此,相比PartitionedPairBuffer,PartitionedAppendOnlyMap的存储效率要高得多,溢出数据到磁盘文件的频率也要低得多。
以此类推,最终合并的数据文件也会小很多。依靠高效的内存数据结构、更少的磁盘文件、更小的文件尺寸,我们就能大幅降低了Shuffle过程中的磁盘和网络开销。
事实上,相比groupByKey、collect_list这些收集类算子,聚合类算子(reduceByKey、aggregateByKey等)在执行性能上更占优势。**因此,我们要避免在聚合类的计算需求中,引入收集类的算子。**虽然这种做法不妨碍业务逻辑实现,但在性能调优上可以说是大忌。
Reduce阶段是如何进行数据分发的?
最后,我们再来说说Reduce阶段,在“仙女散花”的游戏里,每个人把自己的花朵归好类之后,主动地把不同颜色的花朵放到相应的课桌上,这个过程实际上就是Shuffle过程中的数据分发。不过,与课桌被动地接收花朵不同的是,Shuffle在Reduce阶段是主动地从Map端的中间文件中拉取数据。

刚刚讲过,每个Map Task都会生成如上图所示的中间文件,文件中的分区数与Reduce阶段的并行度一致。换句话说,每个Map Task生成的数据文件,都包含所有Reduce Task所需的部分数据。因此,任何一个Reduce Task要想完成计算,必须先从所有Map Task的中间文件里去拉取属于自己的那部分数据。索引文件正是用于帮助判定哪部分数据属于哪个Reduce Task。
Reduce Task通过网络拉取中间文件的过程,实际上就是不同Stages之间数据分发的过程。在“仙女散花”的游戏中,5个孩子与5张课桌之间,需要往返25人次。如果让100个孩子把100种颜色的花朵,分别收集到100张课桌上,那么这100个孩子与100张课桌之间,就需要10000人次的往返!显然,Shuffle中数据分发的网络开销,会随着Map Task与Reduce Task的线性增长,呈指数级爆炸。
Reduce Task将拉取到的数据块填充到读缓冲区,然后按照任务的计算逻辑不停地消费、处理缓冲区中的数据记录,如下图所示。

我们可以看到,Reduce阶段用圆圈标记的1、2、3、4与Map阶段的四个步骤一模一样。没错,因即是果、果即是因,当我们说某个Stage是Map阶段或是Reduce阶段的时候,我们的出发点或者说锚点就是Shuffle。对于上图的Shuffle 0来说,Stage 0是Map阶段,Stage 1是Reduce阶段。但是,对于后面的Shuffle 1来说,Stage 1就变成了Map 阶段。因此你看,当我们把视角拉宽,Map和Reduce这两个看似对立的东西,其实有很多地方都是相通的。
性能杀手
想必经过上面两个阶段的分析,你已经对Shuffle为何会成为性能瓶颈,有了比较直观的感受。这里,我再带你总结一下。
首先,对于Shuffle来说,它需要消耗所有的硬件资源:
-
无论是PartitionedPairBuffer、PartitionedAppendOnlyMap这些内存数据结构,还是读写缓冲区,都会消耗宝贵的内存资源;
-
由于内存空间有限,因此溢出的临时文件会引入大量磁盘I/O,而且,Map阶段输出的中间文件也会消耗磁盘;
-
呈指数级增长的跨节点数据分发,带来的网络开销更是不容小觑。
**其次,Shuffle消耗的不同硬件资源之间很难达到平衡。**磁盘和网络的消耗是Shuffle中必需的环节。但是,磁盘与网络的处理延迟相比CPU和内存要相差好几个数量级。以下表为例,如果以CPU L1缓存的处理延迟为基准,把单位从纳秒校准到秒,我们就会惊讶地发现,当CPU、内存以秒为单位处理数据时,磁盘和网络的处理延迟是以天、月为单位的!
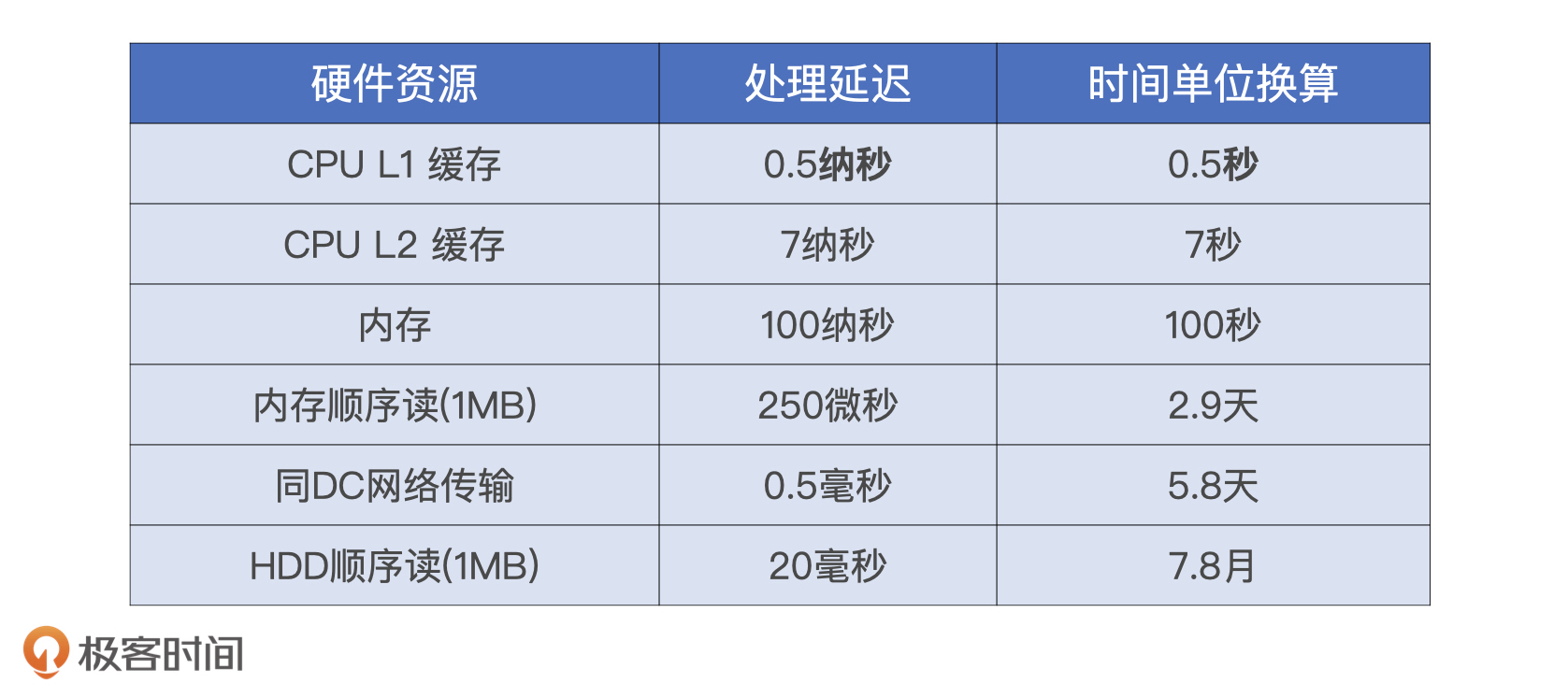
正是基于Shuffle的这些特点,我们才会“谈虎色变”,一提到Shuffle就避之唯恐不及,强调能省则省、能拖则拖。
小结
这一讲,我借助实现仙女散花这个游戏的需求,带你直观地认识Shuffle的计算过程。Shuffle有两个计算阶段,Map阶段和Reduce阶段。我们要重点掌握Map阶段的计算流程,我把它总结为4步:
- 对于分片中的数据记录,逐一计算其目标分区,然后填充内存数据结构(PartitionedPairBuffer或PartitionedAppendOnlyMap);
- 当数据结构填满后,如果分片中还有未处理的数据记录,就对结构中的数据记录按(目标分区ID,Key)排序,将所有数据溢出到临时文件,同时清空数据结构;
- 重复前2个步骤,直到分片中所有的数据记录都被处理;
- 对所有临时文件和内存数据结构中剩余的数据记录做归并排序,最终生成数据文件和索引文件。
在Reduce阶段我们要注意,Reduce Task通过网络拉取中间文件的过程,实际上就是不同Stages之间数据分发的过程。并且,Shuffle中数据分发的网络开销,会随着Map Task与Reduce Task的线性增长,呈指数级爆炸。
最后,从硬件资源的角度来看,Shuffle对每一种硬件资源都非常地渴求,尤其是内存、磁盘和网络。由于不同硬件资源之间的处理延迟差异巨大,我们很难在Shuffle过程中平衡CPU、内存、磁盘和网络之间的计算开销。因此,对于Shuffle我们避之唯恐不及,要能省则省、能拖则拖。
每日一练
- 以小红分到的花朵(数据分区0)为例,你能推导出reduceByKey中Map阶段的每个环节吗?(提示:PartitionedAppendOnlyMap需要多少次溢出到磁盘临时文件?每一个临时文件中的内容是什么?最终生成的中间文件,内容分别是什么?和groupByKey生成的中间文件一样吗?)
- Map阶段和Reduce阶段有不少环节都涉及数据缓存、数据存储,结合上一讲介绍的Spark配置项,你能把相关的配置项对号入座吗?
期待在留言区看到你的思考和讨论,我们下一讲见!