19 KiB
18 | 图像分类(下):如何构建一个图像分类模型?
你好,我是方远。欢迎来到第18节课的学习。
我相信经过上节课的学习,你已经了解了图像分类的原理,还初步认识了一些经典的卷积神经网络。
正所谓“纸上得来终觉浅,绝知此事要躬行”,今天就让我们把上节课的理论知识应用起来,一起从数据的准备、模型训练以及模型评估,从头至尾一起来完成一个完整的图像分类项目实践。
课程代码你可以从这里下载。
问题回顾
我们先来回顾一下问题背景,我们要解决的问题是,在众多图片中自动识别出极客时间Logo的图片。想要实现自动识别,首先需要分析数据集里的图片是啥样子的。
那我们先来看一张包含极客时间Logo的图片,如下所示。

你可以看到,Logo占整张图片的比例还是比较小的,所以说,如果这个项目是真实存在的,目标检测其实更加合适。不过,我们可以将问题稍微修改一下,修改成自动识别极客时间宣传海报,这其实就很适合图像分类任务了。
数据准备
相比目标检测与图像分割来说,图像分类的数据准备还是比较简单的。在图像分类中,我们只需要将每个类别的图片放到指定的文件夹里就行了。
下图是我的图片组织方式,文件夹就是图片所属的类别。
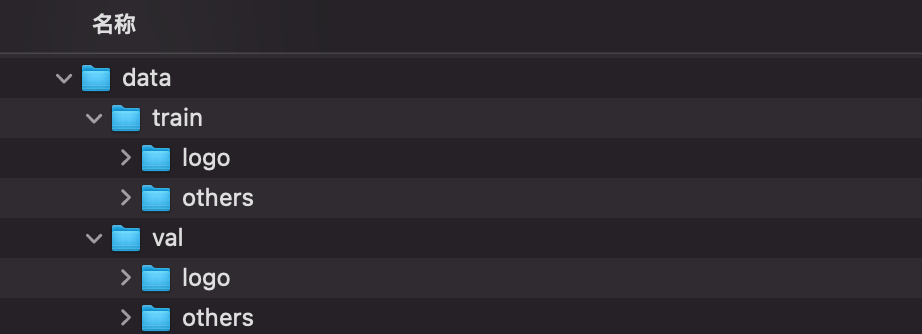
logo文件夹中存放的是10张极客时间海报的图片。

而others中,理论上应该是各种其它类型的图片,但这里为了简化问题,我这个文件夹中存放的都是小猫的图片。

模型训练
好啦,数据准备就绪,我们现在进入模型训练阶段。
今天我想向你介绍一个在最近2年非常受欢迎的一个网络——EfficientNet。它为我们提供了B0~B7,一共8个不同版本的模型,这8个版本有着不同的参数量,在同等参数量的模型中,它的精度都是首屈一指的。因此,这8个版本的模型可以解决你的大多数问题。
EfficientNet
我先给你解读一下EfficientNet的这篇论文,这里我着重分享论文的核心思路还有我的理解,学有余力的同学可以在课后自行阅读原文。
EfficientNet一共有B0到B7,8个模型,参数量由少到多,精度也越来越高,具体你可以看看后面的评价指标。
在之前的那些网络,要么从网络的深度出发,要么从网络的宽度出发来优化网络的性能,但从来没有人将这些方向结合在一起考虑。而EfficientNet就做了这样的尝试,它探索了网络深度、网络宽度、图像分辨率之间的最优组合。
EfficientNet利用一种复合的缩放手段,对网络的深度depth、宽度width和分辨率resolution同时进行缩放(按照一定的缩放规律),来达到精度和运算复杂度FLOPS的权衡。
但即使只探索这三个维度,搜索空间仍然很大,所以作者规定只在B0(作者提出的EfficientNet的一个Baseline)上进行放大。
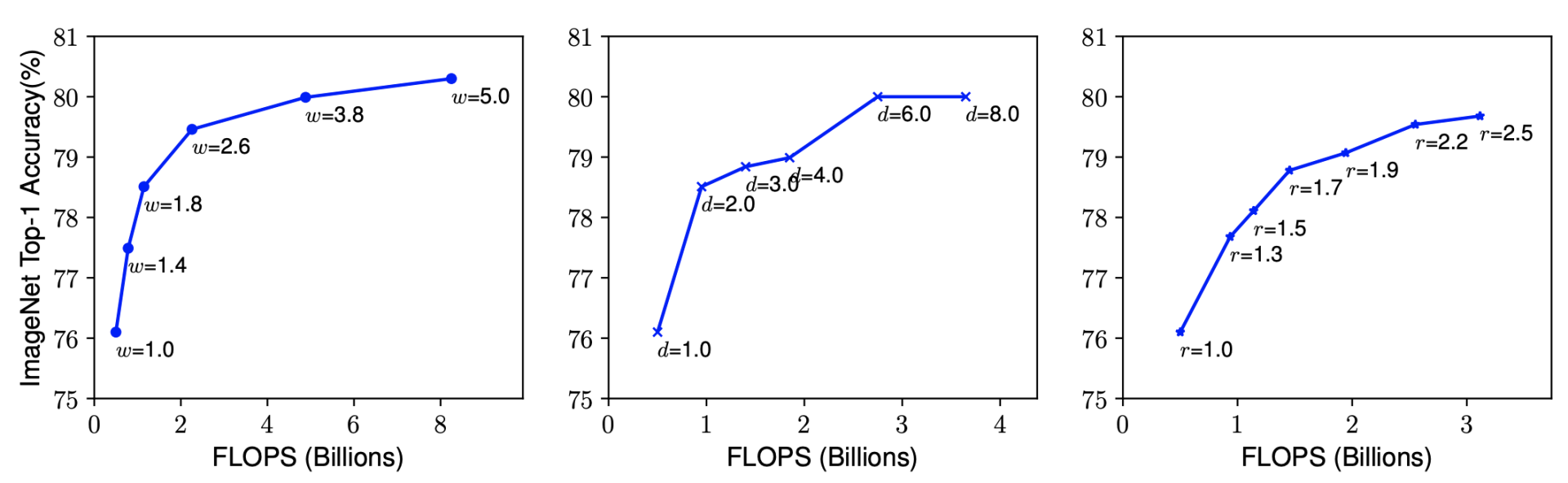
首先,作者比较了单独放大这三个维度中的任意一个维度效果如何。得出结论是放大网络深度或网络宽度或图像分辨率,均可提升模型精度,但是越放大,精度增加越缓慢,如下图所示:
然后,作者做了第二个实验,尝试在不同的r(分辨率),d(深度)组合下变动w(宽度),得到下图:
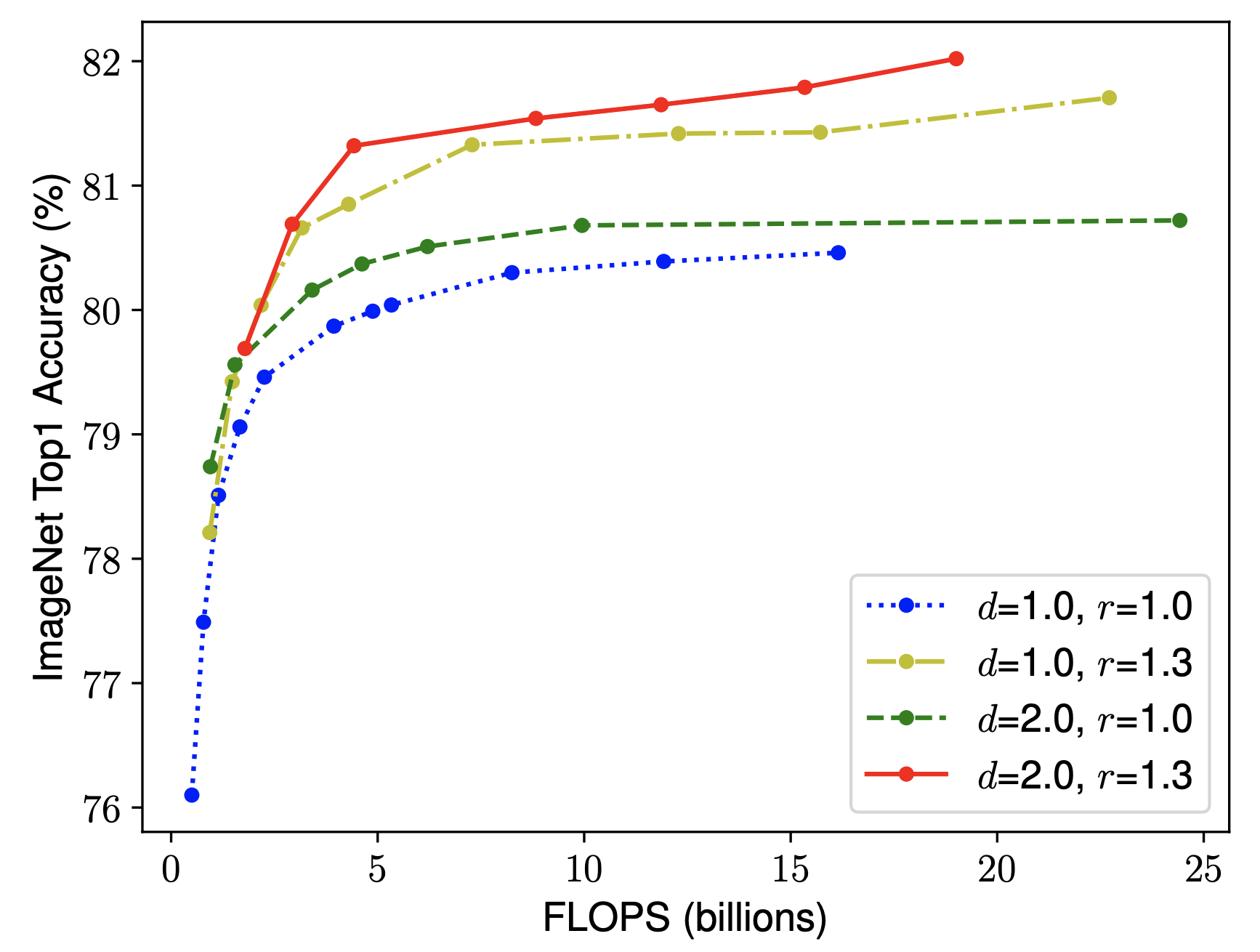
结论是,得到更高的精度以及效率的关键是平衡网络宽度,网络深度,图像分辨率三个维度的缩放倍率(d, r, w)。
因此,作者提出了混合维度放大法,该方法使用一个$\phi$(混合稀疏)来决定三个维度的放大倍率。
深度depth:d = \\alpha ^{\\phi}
宽度width:w = \\beta ^{\\phi}
分辨率resolution: r = \\gamma ^{\\phi}
s.t. \\space \\alpha\\cdot\\beta^2\\cdot\\gamma^2 \\approx2 \\space \\space \\alpha \\geq1,\\beta \\geq1,\\gamma \\geq1第一步,固定$\phi$为1,也就是计算量为2倍,使用网格搜索,得到了最佳的组合,也就是$\alpha=1.2, \beta = 1.1, \gamma = 1.15$。
第二步,固定$\alpha=1.2, \beta = 1.1, \gamma = 1.15$,使用不同的混合稀疏$\phi$,得到了B1~B7。
整体评估效果如下图所示:
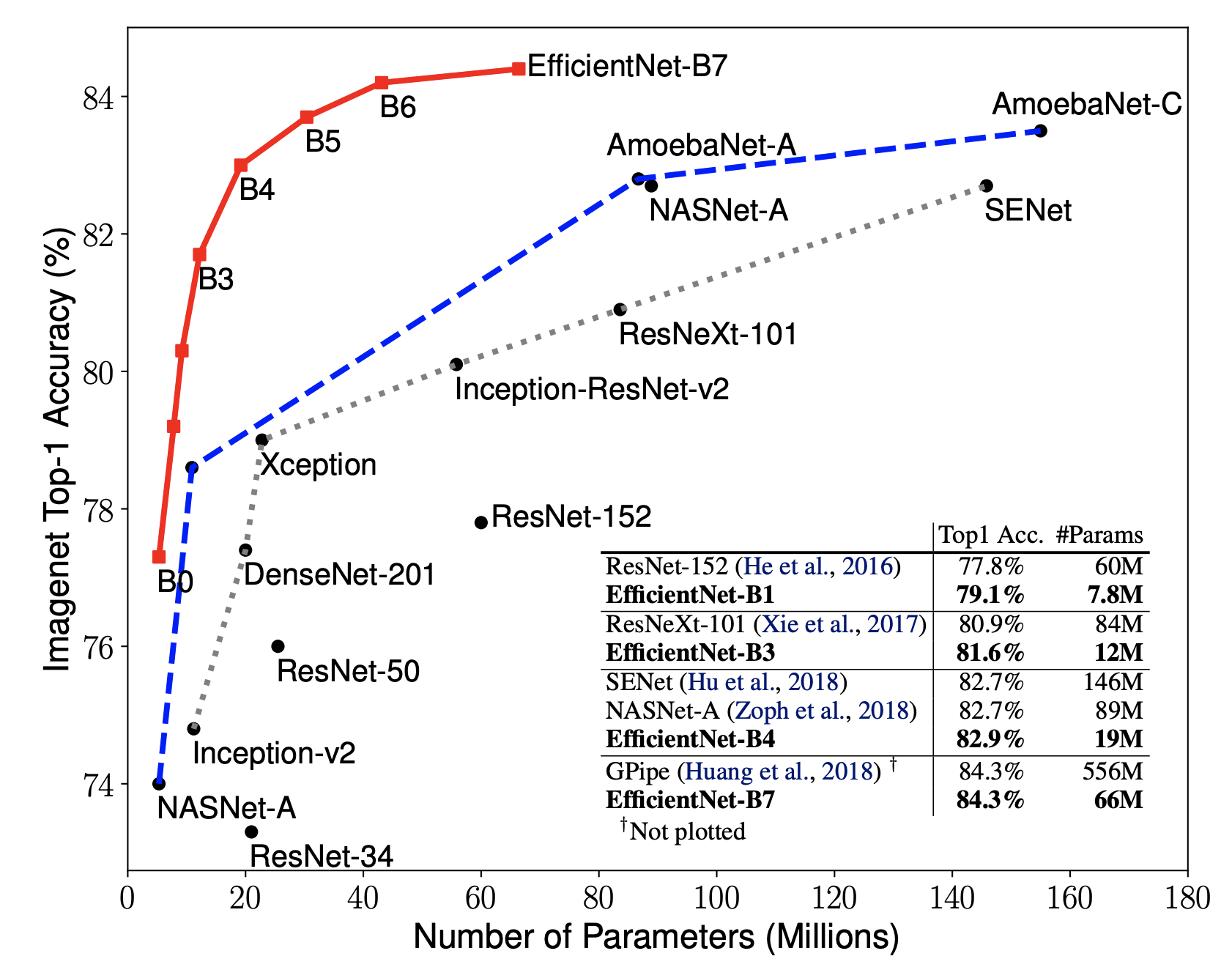
从评估结果上可以看到,EfficientNet的各个版本均超过了之前的一些经典卷积神经网络。
EfficientNet v2也已经被提出来了,有时间的话你可以自己去看看。
我们不妨借助一下EfficientNet的GitHub,它里面有训练ImageNet的demo(demo/imagenet/main.py),接下来我们一起看看它的核心代码,然后精简一下代码,把它运行起来(Torchvision也提供了EfficientNet的模型,课后你也可以自己试一试)。
这里我们再回顾一下,之前说的机器学习3件套:
1.数据处理
2.模型训练(构建模型、损失函数与优化方法)
3.模型评估
接下来我们就挨个看看这些步骤。你需要先把https://github.com/lukemelas/EfficientNet-PyTorch给克隆下来,我们只使用efficientnet_pytorch中的内容,它包含着模型的网络结构。
之后我们来创建一个叫做geektime的项目文件夹,然后把efficientnet_pytorch放进去。
在开始之前,我先把程序需要的参数给你列一下,在下面的讲解中,我们就直接使用这些参数了。当你在实现今天代码的时候,需要将这些参数补充到代码中(可以使用argparsem模块)。
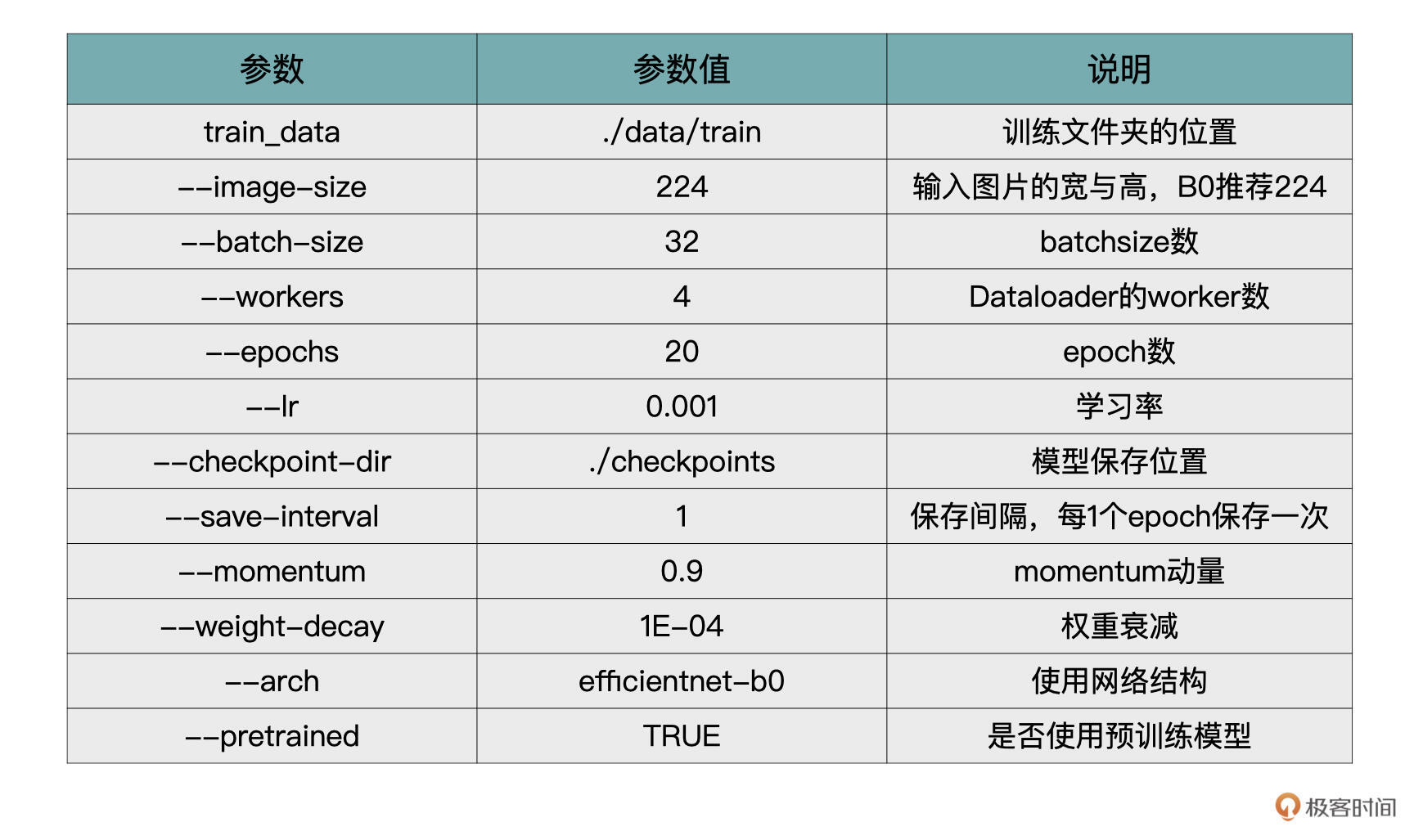
好,下面让我们正式开始动手。
加载数据
首先是数据加载的环节,我们创建一个dataset.py文件,用来存储与数据有关的内容。dataset.py如下(我省略了模块的引入)。
# 作者给出的标准化方法
def _norm_advprop(img):
return img * 2.0 - 1.0
def build_transform(dest_image_size):
normalize = transforms.Lambda(_norm_advprop)
if not isinstance(dest_image_size, tuple):
dest_image_size = (dest_image_size, dest_image_size)
else:
dest_image_size = dest_image_size
transform = transforms.Compose([
transforms.RandomResizedCrop(dest_image_size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize
])
return transform
def build_data_set(dest_image_size, data):
transform = build_transform(dest_image_size)
dataset=datasets.ImageFolder(data, transform=transform, target_transform=None)
return dataset
这部分代码完成的工作是,通过build_data_set构建数据集。这里我们使用了torchvision.datasets.ImageFolder来创建Dataset。ImageFolder能将按文件夹形式的组织数据生成到一个Dataset。
在这个例子中,我传入的训练集路径为’./data/train’,你可以看看开篇的截图。
ImageFolder会自动的将同一文件夹内的数据打上一个标签,也就是说logo文件夹的数据,ImageFolder会认为是来自同一类别,others文件夹的数据,ImageFolder会认为是来自另外一个类别。
我们这个精简版只构建了训练集的Dataset,当你看Efficient官方代码的时候,在验证集的构建过程中,你需要留意一下验证集的transforms。
我认为,这里这么做是有点问题的,原因是Resize中size参数如果是个tuple类型,则直接按照size的尺寸进行resize。如果是一个int的时候,如果图片的height大于width,则按照(size * height/width, size)进行resize。
在作者的原始程序中,imag_size是个int,而不是tuple。所以按照这种先resize再crop的方式处理一下,对长宽比比较大的图片来说,效果不是很好。
让我们实际验证一下这个想法,我将开篇的例子(也就是那张海报图)的image_size设定为224后,用上述的方式进行处理后,获得下图。

你看,是不是缺少了很多信息?
所以,如果在我们的例子中使用作者的程序,就需要做一下修改。把这里的代码逻辑修改为如果image_size不是tuple,先将image_size转换为tuple,并且也不需要crop了。代码如下所示:
if not isinstance(image_size, tuple):
image_size = (image_size, image_size)
else:
image_size = image_size
transform = transforms.Compose([
transforms.Resize(image_size, interpolation=Image.BICUBIC),
transforms.ToTensor(),
normalize,
])
训练的主程序我们定义在main.py中,在main.py中的main()中,进行数据的加载,如下所示。
然后,我们通过for循环一个一个Epoch的调用train方法进行训练就可以了。
# 省略了一些模块的引入
from efficientnet import EfficientNet
from dataset import build_data_set
def main():
# part1: 模型加载 (稍后补充)
# part2: 损失函数、优化方法(稍后补充)
train_dataset = build_data_set(args.image_size, args.train_data)
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=args.batch_size,
shuffle=True,
num_workers=args.workers,
)
for epoch in range(args.epochs):
# 调用train函数进行训练,稍后补充
train(train_loader, model, criterion, optimizer, epoch, args)
# 模型保存
if epoch % args.save_interval == 0:
if not os.path.exists(args.checkpoint_dir):
os.mkdir(args.checkpoint_dir)
torch.save(model.state_dict(), os.path.join(args.checkpoint_dir,
'checkpoint.pth.tar.epoch_%s' % epoch))
创建模型
接下来,我们来看看如何创建模型,这一步我们直接使用作者给出的Efficient模型。在上面代码注释中的part1部分,用下述代码即可加载EfficientNet模型。
args.classes_num = 2
if args.pretrained:
model = EfficientNet.from_pretrained(args.arch, num_classes=args.classes_num,
advprop=args.advprop)
print("=> using pre-trained model '{}'".format(args.arch))
else:
print("=> creating model '{}'".format(args.arch))
model = EfficientNet.from_name(args.arch, override_params={'num_classes': args.classes_num})
# 有GPU的话,加上cuda()
#mode.cuda()
这段代码是说,如果pretrained model参数为True,则自动下载并加载pretrained model后进行训练,否则是使用随机数初始化网络。
from_pretrained与from_name中,都需要修改一下num_classes,将EfficientNet的全连接层修改我们项目对应的类别数,这里的args.classes_num为2(logo类与others类)。
模型微调
模型微调在第8节课和第14节课时说过,这个概念比较重要,我们一起再复习一下。
Pretrained model一般是在ImageNet(也有可能是COCO或VOC,都是公开数据集)上训练过的模型,我们可以直接把它在ImageNet上训练好的模型参数直接拿过来,在其基础上训练我们自己的模型,这就是模型微调。
所以说,如果有Pretrained model,我们一定会使用Pretrained model进行训练,收敛速度会快。
使用Pretrained model的时候要注意一点,在ImageNet上训练后的全连接层一共有1000个节点,所以使用Pretrained model的时候只使用全连接层以外的参数。
在上述代码的EfficientNet.from_pretrained中,会通调用load_pretrained_weights函数,调用之前num_classes已经被修改为2(logo与others),所以说传入load_pretrained_weights的load_fc参数为False,也就是说不会加载全连接层的参数。load_pretrained_weights的调用如下所示:
load_pretrained_weights(model, model_name, load_fc=(num_classes == 1000), advprop=advprop)
load_pretrained_weights函数中包含下面这段代码,就像刚才所说,如果不加载全连接层,则删除_fc的weight与bias:
if load_fc:
ret = model.load_state_dict(state_dict, strict=False)
assert not ret.missing_keys, 'Missing keys when loading pretrained weights: {}'.format(ret.missing_keys)
else:
state_dict.pop('_fc.weight')
state_dict.pop('_fc.bias')
ret = model.load_state_dict(state_dict, strict=False)
设定损失函数与优化方法
最后要做的就是设定损失函数与优化方法了,我们将下面的代码补充到part2部分:
criterion = nn.CrossEntropyLoss() # 有GPU的话加上.cuda()
optimizer = torch.optim.SGD(model.parameters(), args.lr,
momentum=args.momentum,
weight_decay=args.weight_decay)
到这里,我们就完成训练的所有准备了,只要再补充好train函数就可以了,代码如下。下面的代码的原理我们在第13节课中已经讲过了,记不清的可以去回顾一下。
def train(train_loader, model, criterion, optimizer, epoch, args):
# switch to train mode
model.train()
for i, (images, target) in enumerate(train_loader):
# compute output
output = model(images)
loss = criterion(output, target)
print('Epoch ', epoch, loss)
# compute gradient and do SGD step
optimizer.zero_grad()
loss.backward()
optimizer.step()
不过在我的程序里,保存了若干个Epoch的模型,我们应该怎么选择呢?这就要说到模型的评估环节。
模型评估
对于分类模型的评估来说,有很多评价指标,例如准确率、精确率、召回率、F1-Score等。其中,我认为最直观、最有说服力的就是精确率与召回率,这也是我在项目中观察的主要是指标。下面我们依次来看看。
混淆矩阵
在讲解精确率与召回率之前,我们先看看混淆矩阵这个概念。其实精确率与召回率就是通过它计算出来的。下表就是一个混淆矩阵,正例就是logo类,负例就是others类。
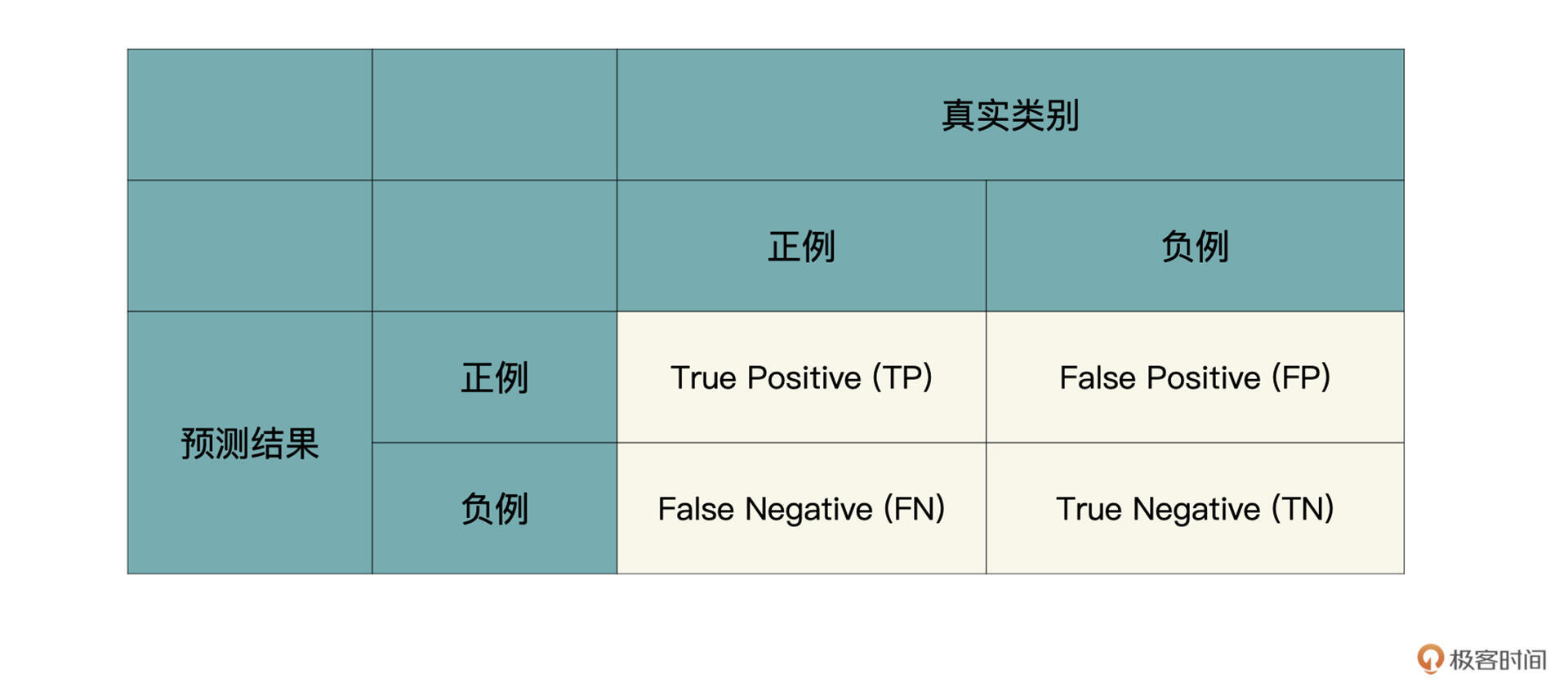
根据预测结果和真实类别的组合,一共有四种情况:
1.TP是说真实类别为Logo,模型也预测为Logo;
2.FP是说真实类别为Others,但模型预测为Logo;
3.FN是说真实类别为Logo,但模型预测为Others;
4.TN是说真实类别为Others,模型也预测为Others;
精确率的计算方法为:
precision = \\frac{TP}{ (TP + FP)}召回率的计算方式为:
recall = \\frac{TP}{(TP + FN)}精确率与召回率分别衡量了模型的不同表现,精确率说的是,如果模型认为一张图片是Logo类,那有多大概率是Logo类。而召回率衡量的是,在整个验证集中,模型能找到多少Logo图片。
那问题来了,怎样根据这两个指标来选择模型呢?业务需求不同,我们侧重的指标就不一样。
比如在我们的这个项目中,如果老板允许一部分Logo图片没有被识别,但是模型必须非常准,模型说一张图片是Logo类,那图片真实类别就有非常大的概率是Logo类图片,那应该侧重的就是精确率;如果老板希望把线上Logo类尽可能地识别出来,允许一部分图片被误识别,那应该侧重的就是召回率。
在计算精确率与召回率的时候,给你分享一下我的经验。在实际项目中,我习惯把模型对每张图片的预测结果保存到一个txt中,这样可以比较直观地筛选一些模型的badcase,并且验证集如果非常大,又需要调整的时候,直接更改txt就可以了,不需要再次让模型预测整个验证集。
下面是txt文件的一部分,分别记录了logo类的概率、others类的概率、真实类别是否为logo、真实类别是否为others、预测类别是否为logo、预测类别是否为ohters、图片名。
14.jpeg是开篇例子的那张图片,模型认为它是Logo的概率是0.58476,others类的概率是0.41524。
...
0.64460 0.35540 1 0 1 0 ./data/val/logo/13.jpeg
0.58476 0.41524 1 0 1 0 ./data/val/logo/14.jpeg
...
下图是我训练了10个Epoch的B0模型,在验证集(这里我用训练集充当了一下验证集)上的评价效果。
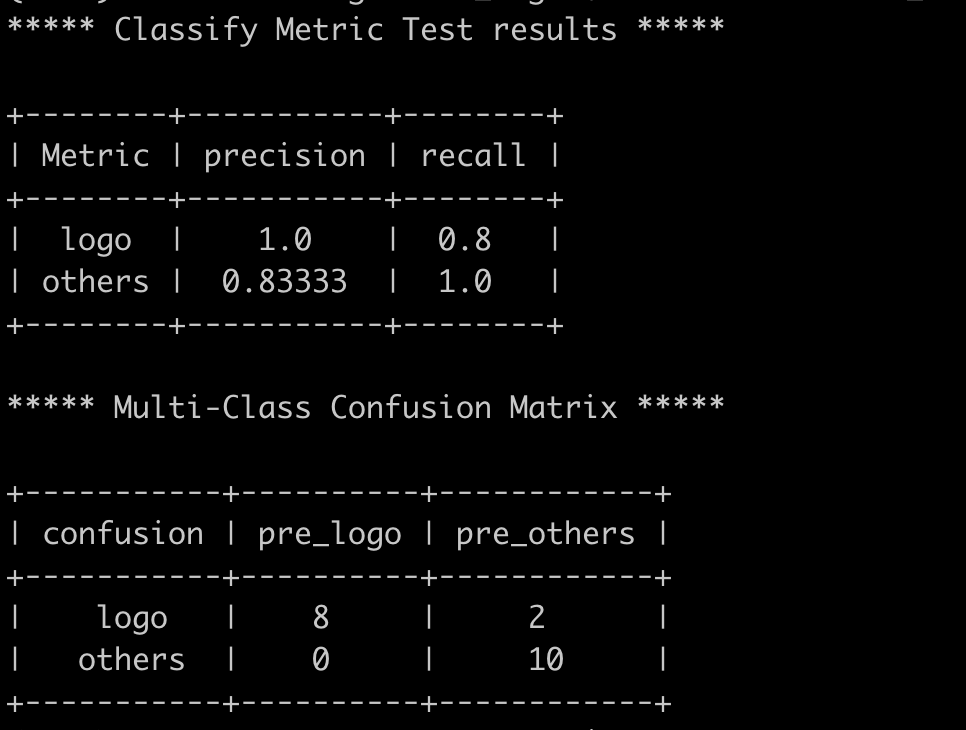
通过混淆矩阵可以看到,整个验证集一共有8+0张图片被预测为logo类,所以logo类的精确率为8 / (8 + 0 ) = 1;logo类一共有8+2张图片,有两张预测错了,所以召回率为8 / (8 +2) = 0.8。
others类别的计算类似,你可以自己算算看。
小结
恭喜你,完成了今天的学习任务。今天我们一起完成了一个图像分类项目的实践。虽然项目规模较小,但是在真实项目中的每一个环节都包含在内了,可以说是麻雀虽小,五脏俱全。
下面我们回顾一下每个环节上的关键要点和实操经验。
数据准备其实是最关键的一步,数据的质量直接决定了模型好坏。所以,在开始训练之前你应该对你的数据集有十足的了解才可以。例如,验证集还是否可以反映出训练集、数据中有没有脏数据、数据分布有没有偏等等。
完成数据准备之后就到了模型训练,图像分类任务其实基本上都是采用主流的卷积神经网络了,很少对模型结构做一些更改。
最后的模型评估环节要侧重业务场景,看业务上需要高精确还是高召回,然后再对你的模型做调整。
思考题
老板希望你的模型能尽可能的把线上所有极客时间的海报都找到,允许一些误召回。训练模型的时候你应该侧重精确率还是召回率?
推荐你动手实现一下今天的Demo,也欢迎你把这节课分享给更多的同事、朋友,跟他一起学习进步。