|
|
# 02 | 一篇文章带你快速搞定Kafka术语
|
|
|
|
|
|
你好,我是胡夕。今天我们正式开启Apache Kafka学习之旅。
|
|
|
|
|
|
在Kafka的世界中有很多概念和术语是需要你提前理解并熟练掌握的,这对于后面你深入学习Kafka各种功能和特性将大有裨益。下面我来盘点一下Kafka的各种术语。
|
|
|
|
|
|
在专栏的第一期我说过Kafka属于分布式的消息引擎系统,它的主要功能是提供一套完备的消息发布与订阅解决方案。在Kafka中,发布订阅的对象是主题(Topic),你可以为每个业务、每个应用甚至是每类数据都创建专属的主题。
|
|
|
|
|
|
向主题发布消息的客户端应用程序称为生产者(Producer),生产者程序通常持续不断地向一个或多个主题发送消息,而订阅这些主题消息的客户端应用程序就被称为消费者(Consumer)。和生产者类似,消费者也能够同时订阅多个主题的消息。我们把生产者和消费者统称为客户端(Clients)。你可以同时运行多个生产者和消费者实例,这些实例会不断地向Kafka集群中的多个主题生产和消费消息。
|
|
|
|
|
|
有客户端自然也就有服务器端。Kafka的服务器端由被称为Broker的服务进程构成,即一个Kafka集群由多个Broker组成,Broker负责接收和处理客户端发送过来的请求,以及对消息进行持久化。虽然多个Broker进程能够运行在同一台机器上,但更常见的做法是将不同的Broker分散运行在不同的机器上,这样如果集群中某一台机器宕机,即使在它上面运行的所有Broker进程都挂掉了,其他机器上的Broker也依然能够对外提供服务。这其实就是Kafka提供高可用的手段之一。
|
|
|
|
|
|
实现高可用的另一个手段就是备份机制(Replication)。备份的思想很简单,就是把相同的数据拷贝到多台机器上,而这些相同的数据拷贝在Kafka中被称为副本(Replica)。好吧,其实在整个分布式系统里好像都叫这个名字。副本的数量是可以配置的,这些副本保存着相同的数据,但却有不同的角色和作用。Kafka定义了两类副本:领导者副本(Leader Replica)和追随者副本(Follower Replica)。前者对外提供服务,这里的对外指的是与客户端程序进行交互;而后者只是被动地追随领导者副本而已,不能与外界进行交互。当然了,你可能知道在很多其他系统中追随者副本是可以对外提供服务的,比如MySQL的从库是可以处理读操作的,但是在Kafka中追随者副本不会对外提供服务。对了,一个有意思的事情是现在已经不提倡使用Master-Slave来指代这种主从关系了,毕竟Slave有奴隶的意思,在美国这种严禁种族歧视的国度,这种表述有点政治不正确了,所以目前大部分的系统都改成Leader-Follower了。
|
|
|
|
|
|
副本的工作机制也很简单:生产者总是向领导者副本写消息;而消费者总是从领导者副本读消息。至于追随者副本,它只做一件事:向领导者副本发送请求,请求领导者把最新生产的消息发给它,这样它能保持与领导者的同步。
|
|
|
|
|
|
虽然有了副本机制可以保证数据的持久化或消息不丢失,但没有解决伸缩性的问题。伸缩性即所谓的Scalability,是分布式系统中非常重要且必须要谨慎对待的问题。什么是伸缩性呢?我们拿副本来说,虽然现在有了领导者副本和追随者副本,但倘若领导者副本积累了太多的数据以至于单台Broker机器都无法容纳了,此时应该怎么办呢?一个很自然的想法就是,能否把数据分割成多份保存在不同的Broker上?如果你就是这么想的,那么恭喜你,Kafka就是这么设计的。
|
|
|
|
|
|
这种机制就是所谓的分区(Partitioning)。如果你了解其他分布式系统,你可能听说过分片、分区域等提法,比如MongoDB和Elasticsearch中的Sharding、HBase中的Region,其实它们都是相同的原理,只是Partitioning是最标准的名称。
|
|
|
|
|
|
Kafka中的分区机制指的是将每个主题划分成多个分区(Partition),每个分区是一组有序的消息日志。生产者生产的每条消息只会被发送到一个分区中,也就是说如果向一个双分区的主题发送一条消息,这条消息要么在分区0中,要么在分区1中。如你所见,Kafka的分区编号是从0开始的,如果Topic有100个分区,那么它们的分区号就是从0到99。
|
|
|
|
|
|
讲到这里,你可能有这样的疑问:刚才提到的副本如何与这里的分区联系在一起呢?实际上,副本是在分区这个层级定义的。每个分区下可以配置若干个副本,其中只能有1个领导者副本和N-1个追随者副本。生产者向分区写入消息,每条消息在分区中的位置信息由一个叫位移(Offset)的数据来表征。分区位移总是从0开始,假设一个生产者向一个空分区写入了10条消息,那么这10条消息的位移依次是0、1、2、......、9。
|
|
|
|
|
|
至此我们能够完整地串联起Kafka的三层消息架构:
|
|
|
|
|
|
* 第一层是主题层,每个主题可以配置M个分区,而每个分区又可以配置N个副本。
|
|
|
* 第二层是分区层,每个分区的N个副本中只能有一个充当领导者角色,对外提供服务;其他N-1个副本是追随者副本,只是提供数据冗余之用。
|
|
|
* 第三层是消息层,分区中包含若干条消息,每条消息的位移从0开始,依次递增。
|
|
|
* 最后,客户端程序只能与分区的领导者副本进行交互。
|
|
|
|
|
|
讲完了消息层次,我们来说说Kafka Broker是如何持久化数据的。总的来说,Kafka使用消息日志(Log)来保存数据,一个日志就是磁盘上一个只能追加写(Append-only)消息的物理文件。因为只能追加写入,故避免了缓慢的随机I/O操作,改为性能较好的顺序I/O写操作,这也是实现Kafka高吞吐量特性的一个重要手段。不过如果你不停地向一个日志写入消息,最终也会耗尽所有的磁盘空间,因此Kafka必然要定期地删除消息以回收磁盘。怎么删除呢?简单来说就是通过日志段(Log Segment)机制。在Kafka底层,一个日志又进一步细分成多个日志段,消息被追加写到当前最新的日志段中,当写满了一个日志段后,Kafka会自动切分出一个新的日志段,并将老的日志段封存起来。Kafka在后台还有定时任务会定期地检查老的日志段是否能够被删除,从而实现回收磁盘空间的目的。
|
|
|
|
|
|
这里再重点说说消费者。在专栏的第一期中我提到过两种消息模型,即点对点模型(Peer to Peer,P2P)和发布订阅模型。这里面的点对点指的是同一条消息只能被下游的一个消费者消费,其他消费者则不能染指。在Kafka中实现这种P2P模型的方法就是引入了消费者组(Consumer Group)。所谓的消费者组,指的是多个消费者实例共同组成一个组来消费一组主题。这组主题中的每个分区都只会被组内的一个消费者实例消费,其他消费者实例不能消费它。为什么要引入消费者组呢?主要是为了提升消费者端的吞吐量。多个消费者实例同时消费,加速整个消费端的吞吐量(TPS)。我会在专栏的后面详细介绍消费者组机制,所以现在你只需要了解消费者组是做什么的即可。另外这里的消费者实例可以是运行消费者应用的进程,也可以是一个线程,它们都称为一个消费者实例(Consumer Instance)。
|
|
|
|
|
|
消费者组里面的所有消费者实例不仅“瓜分”订阅主题的数据,而且更酷的是它们还能彼此协助。假设组内某个实例挂掉了,Kafka能够自动检测到,然后把这个Failed实例之前负责的分区转移给其他活着的消费者。这个过程就是Kafka中大名鼎鼎的“重平衡”(Rebalance)。嗯,其实既是大名鼎鼎,也是臭名昭著,因为由重平衡引发的消费者问题比比皆是。事实上,目前很多重平衡的Bug社区都无力解决。
|
|
|
|
|
|
每个消费者在消费消息的过程中必然需要有个字段记录它当前消费到了分区的哪个位置上,这个字段就是消费者位移(Consumer Offset)。注意,这和上面所说的位移完全不是一个概念。上面的“位移”表征的是分区内的消息位置,它是不变的,即一旦消息被成功写入到一个分区上,它的位移值就是固定的了。而消费者位移则不同,它可能是随时变化的,毕竟它是消费者消费进度的指示器嘛。另外每个消费者有着自己的消费者位移,因此一定要区分这两类位移的区别。我个人把消息在分区中的位移称为分区位移,而把消费者端的位移称为消费者位移。
|
|
|
|
|
|
## 小结
|
|
|
|
|
|
我来总结一下今天提到的所有名词术语:
|
|
|
|
|
|
* 消息:Record。Kafka是消息引擎嘛,这里的消息就是指Kafka处理的主要对象。
|
|
|
* 主题:Topic。主题是承载消息的逻辑容器,在实际使用中多用来区分具体的业务。
|
|
|
* 分区:Partition。一个有序不变的消息序列。每个主题下可以有多个分区。
|
|
|
* 消息位移:Offset。表示分区中每条消息的位置信息,是一个单调递增且不变的值。
|
|
|
* 副本:Replica。Kafka中同一条消息能够被拷贝到多个地方以提供数据冗余,这些地方就是所谓的副本。副本还分为领导者副本和追随者副本,各自有不同的角色划分。副本是在分区层级下的,即每个分区可配置多个副本实现高可用。
|
|
|
* 生产者:Producer。向主题发布新消息的应用程序。
|
|
|
* 消费者:Consumer。从主题订阅新消息的应用程序。
|
|
|
* 消费者位移:Consumer Offset。表征消费者消费进度,每个消费者都有自己的消费者位移。
|
|
|
* 消费者组:Consumer Group。多个消费者实例共同组成的一个组,同时消费多个分区以实现高吞吐。
|
|
|
* 重平衡:Rebalance。消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance是Kafka消费者端实现高可用的重要手段。
|
|
|
|
|
|
最后我用一张图来展示上面提到的这些概念,希望这张图能够帮助你形象化地理解所有这些概念:
|
|
|
|
|
|
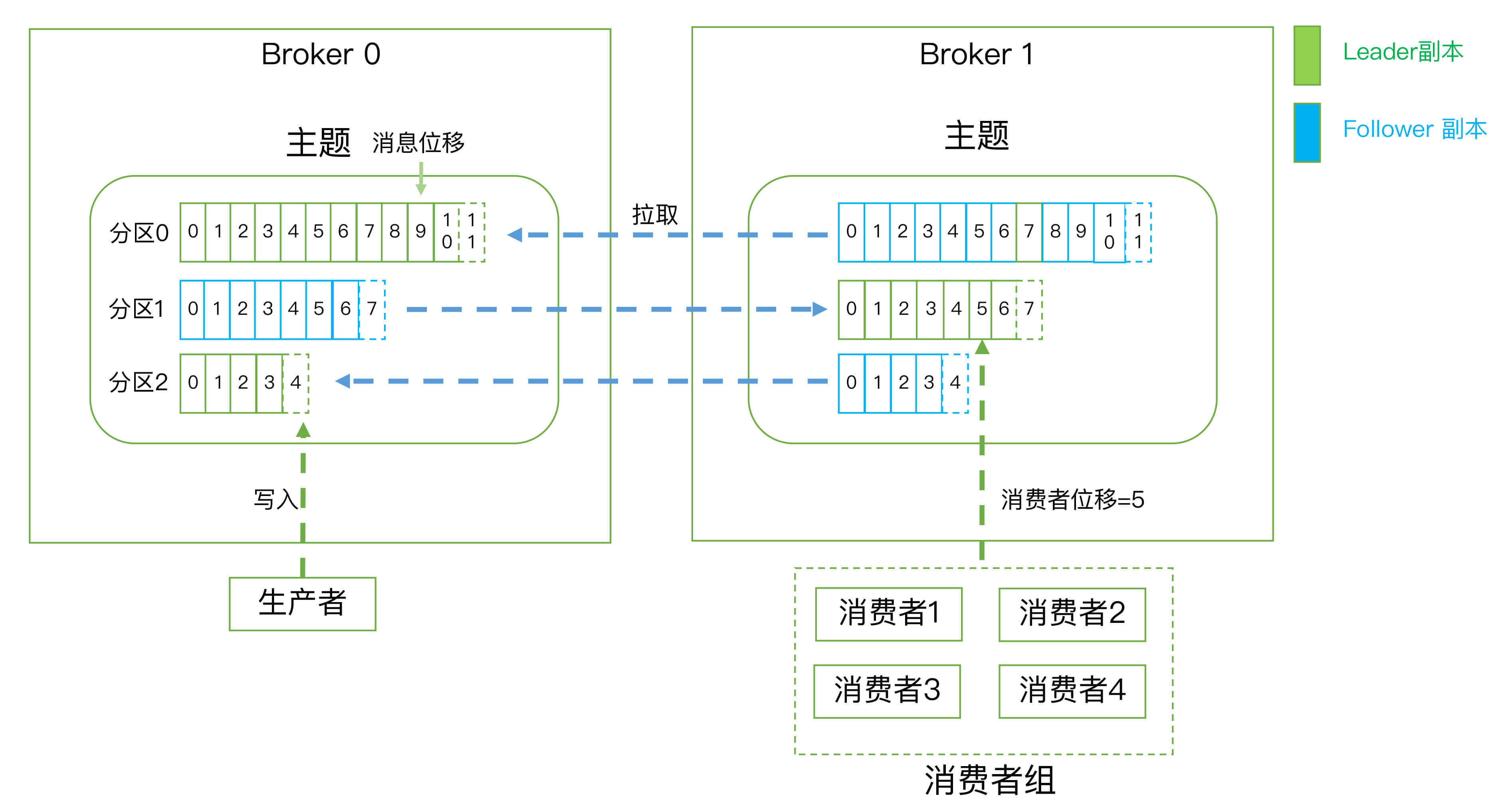
|
|
|
|
|
|
## 开放讨论
|
|
|
|
|
|
请思考一下为什么Kafka不像MySQL那样允许追随者副本对外提供读服务?
|
|
|
|
|
|
欢迎写下你的思考和答案,我们一起讨论。如果你觉得有所收获,也欢迎把文章分享给你的朋友。
|
|
|
|