|
|
# 15 | 内存模型:Go如何保证并发读写的顺序?
|
|
|
|
|
|
你好,我是鸟窝。
|
|
|
|
|
|
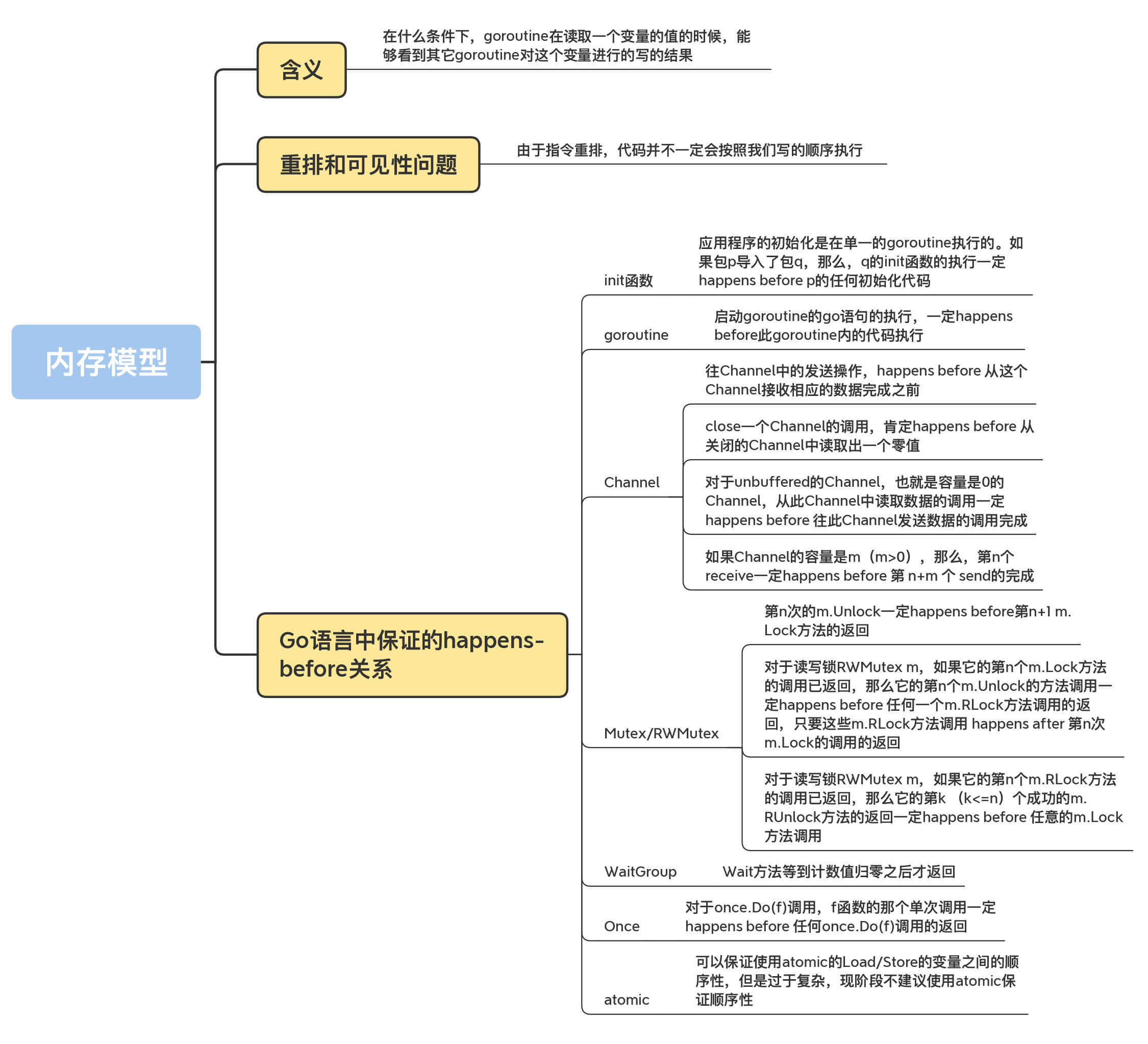
Go官方文档里专门介绍了Go的[内存模型](https://golang.org/ref/mem),你不要误解这里的内存模型的含义,它并不是指Go对象的内存分配、内存回收和内存整理的规范,它描述的是并发环境中多goroutine读相同变量的时候,变量的可见性条件。具体点说,就是指,在什么条件下,goroutine在读取一个变量的值的时候,能够看到其它goroutine对这个变量进行的写的结果。
|
|
|
|
|
|
由于CPU指令重排和多级Cache的存在,保证多核访问同一个变量这件事儿变得非常复杂。毕竟,不同CPU架构(x86/amd64、ARM、Power等)的处理方式也不一样,再加上编译器的优化也可能对指令进行重排,所以编程语言需要一个规范,来明确多线程同时访问同一个变量的可见性和顺序( Russ Cox在麻省理工学院 [6.824 分布式系统Distributed Systems课程](https://pdos.csail.mit.edu/6.824/) 的一课,专门介绍了相关的[知识](http://nil.csail.mit.edu/6.824/2016/notes/gomem.pdf))。在编程语言中,这个规范被叫做内存模型。
|
|
|
|
|
|
除了Go,Java、C++、C、C#、Rust等编程语言也有内存模型。为什么这些编程语言都要定义内存模型呢?在我看来,主要是两个目的。
|
|
|
|
|
|
* 向广大的程序员提供一种保证,以便他们在做设计和开发程序时,面对同一个数据同时被多个goroutine访问的情况,可以做一些串行化访问的控制,比如使用Channel或者sync包和sync/atomic包中的并发原语。
|
|
|
* 允许编译器和硬件对程序做一些优化。这一点其实主要是为编译器开发者提供的保证,这样可以方便他们对Go的编译器做优化。
|
|
|
|
|
|
既然内存模型这么重要,今天,我们就来花一节课的时间学习一下。
|
|
|
|
|
|
首先,我们要先弄明白重排和可见性的问题,因为它们影响着程序实际执行的顺序关系。
|
|
|
|
|
|
# 重排和可见性的问题
|
|
|
|
|
|
**由于指令重排,代码并不一定会按照你写的顺序执行**。
|
|
|
|
|
|
举个例子,当两个goroutine同时对一个数据进行读写时,假设goroutine g1对这个变量进行写操作w,goroutine g2同时对这个变量进行读操作r,那么,如果g2在执行读操作r的时候,已经看到了g1写操作w的结果,那么,也不意味着g2能看到在w之前的其它的写操作。这是一个反直观的结果,不过的确可能会存在。
|
|
|
|
|
|
接下来,我再举几个具体的例子,带你来感受一下,重排以及多核CPU并发执行导致程序的运行和代码的书写顺序不一样的情况。
|
|
|
|
|
|
先看第一个例子,代码如下:
|
|
|
|
|
|
```
|
|
|
var a, b int
|
|
|
|
|
|
func f() {
|
|
|
a = 1 // w之前的写操作
|
|
|
b = 2 // 写操作w
|
|
|
}
|
|
|
|
|
|
func g() {
|
|
|
print(b) // 读操作r
|
|
|
print(a) // ???
|
|
|
}
|
|
|
|
|
|
func main() {
|
|
|
go f() //g1
|
|
|
g() //g2
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
可以看到,第9行是要打印b的值。需要注意的是,即使这里打印出的值是2,但是依然可能在打印a的值时,打印出初始值0,而不是1。这是因为,程序运行的时候,不能保证g2看到的a和b的赋值有先后关系。
|
|
|
|
|
|
再来看一个类似的例子。
|
|
|
|
|
|
```
|
|
|
var a string
|
|
|
var done bool
|
|
|
|
|
|
func setup() {
|
|
|
a = "hello, world"
|
|
|
done = true
|
|
|
}
|
|
|
|
|
|
func main() {
|
|
|
go setup()
|
|
|
for !done {
|
|
|
}
|
|
|
print(a)
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
在这段代码中,主goroutine main即使观察到done变成true了,最后读取到的a的值仍然可能为空。
|
|
|
|
|
|
更糟糕的情况是,main根本就观察不到另一个goroutine对done的写操作,这就会导致main程序一直被hang住。甚至可能还会出现**半初始化**的情况,比如:
|
|
|
|
|
|
```
|
|
|
type T struct {
|
|
|
msg string
|
|
|
}
|
|
|
|
|
|
var g *T
|
|
|
|
|
|
func setup() {
|
|
|
t := new(T)
|
|
|
t.msg = "hello, world"
|
|
|
g = t
|
|
|
}
|
|
|
|
|
|
func main() {
|
|
|
go setup()
|
|
|
for g == nil {
|
|
|
}
|
|
|
print(g.msg)
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
即使main goroutine观察到g不为nil,也可能打印出空的msg(第17行)。
|
|
|
|
|
|
看到这里,你可能要说了,我都运行这个程序几百万次了,怎么也没有观察到这种现象?我可以这么告诉你,能不能观察到和提供保证(guarantee)是两码事儿。由于CPU架构和Go编译器的不同,即使你运行程序时没有遇到这些现象,也不代表Go可以100%保证不会出现这些问题。
|
|
|
|
|
|
刚刚说了,程序在运行的时候,两个操作的顺序可能不会得到保证,那该怎么办呢?接下来,我要带你了解一下Go内存模型中很重要的一个概念:happens-before,这是用来描述两个时间的顺序关系的。如果某些操作能提供happens-before关系,那么,我们就可以100%保证它们之间的顺序。
|
|
|
|
|
|
# happens-before
|
|
|
|
|
|
在一个goroutine内部,程序的执行顺序和它们的代码指定的顺序是一样的,即使编译器或者CPU重排了读写顺序,从行为上来看,也和代码指定的顺序一样。
|
|
|
|
|
|
这是一个非常重要的保证,我们一定要记住。
|
|
|
|
|
|
我们来看一个例子。在下面的代码中,即使编译器或者CPU对a、b、c的初始化进行了重排,但是打印结果依然能保证是1、2、3,而不会出现1、0、0或1、0、1等情况。
|
|
|
|
|
|
```
|
|
|
func foo() {
|
|
|
var a = 1
|
|
|
var b = 2
|
|
|
var c = 3
|
|
|
|
|
|
println(a)
|
|
|
println(b)
|
|
|
println(c)
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
但是,对于另一个goroutine来说,重排却会产生非常大的影响。**因为Go只保证goroutine内部重排对读写的顺序没有影响**,比如刚刚我们在讲“可见性”问题时提到的三个例子,那该怎么办呢?这就要用到happens-before关系了。
|
|
|
|
|
|
如果两个action(read 或者 write)有明确的happens-before关系,你就可以确定它们之间的执行顺序(或者是行为表现上的顺序)。
|
|
|
|
|
|
Go内存模型通过happens-before定义两个事件(读、写action)的顺序:如果事件e1 happens before 事件e2,那么,我们就可以说事件e2在事件e1之后发生(happens after)。如果e1 不是happens before e2, 同时也不happens after e2,那么,我们就可以说事件e1和e2是同时发生的。
|
|
|
|
|
|
如果要保证对“变量**v**的读操作**r**”能够观察到一个对“变量**v**的写操作**w**”,并且**r**只能观察到**w**对变量**v**的写,没有其它对v的写操作,也就是说,我们要保证**r**绝对能观察到**w**操作的结果,那么就需要同时满足两个条件:
|
|
|
|
|
|
1. w happens before r;
|
|
|
2. 其它对v的写操作(w2、w3、w4, ......) 要么happens before w,要么happens after r,绝对不会和w、r同时发生,或者是在它们之间发生。
|
|
|
|
|
|
你可能会说,这是很显然的事情啊,但我要和你说的是,这是一个非常严格、严谨的数学定义。
|
|
|
|
|
|
对于单个的goroutine来说,它有一个特殊的happens-before关系,Go内存模型中是这么讲的:
|
|
|
|
|
|
> Within a single goroutine, the happens-before order is the order expressed by the program.
|
|
|
|
|
|
我来解释下这句话。它的意思是,在单个的goroutine内部, happens-before的关系和代码编写的顺序是一致的。
|
|
|
|
|
|
其实,在这一章的开头我已经用橙色把这句话标注出来了。我再具体解释下。
|
|
|
|
|
|
在goroutine内部对一个局部变量v的读,一定能观察到最近一次对这个局部变量v的写。如果要保证多个goroutine之间对一个共享变量的读写顺序,在Go语言中,可以使用并发原语为读写操作建立happens-before关系,这样就可以保证顺序了。
|
|
|
|
|
|
说到这儿,我想先给你补充三个Go语言中和内存模型有关的小知识,掌握了这些,你就能更好地理解下面的内容。
|
|
|
|
|
|
1. 在Go语言中,对变量进行零值的初始化就是一个写操作。
|
|
|
2. 如果对超过机器word(64bit、32bit或者其它)大小的值进行读写,那么,就可以看作是对拆成word大小的几个读写无序进行。
|
|
|
3. Go并不提供直接的CPU屏障(CPU fence)来提示编译器或者CPU保证顺序性,而是使用不同架构的内存屏障指令来实现统一的并发原语。
|
|
|
|
|
|
接下来,我就带你学习下Go语言中提供的happens-before关系保证。
|
|
|
|
|
|
# Go语言中保证的happens-before关系
|
|
|
|
|
|
除了单个goroutine内部提供的happens-before保证,Go语言中还提供了一些其它的happens-before关系的保证,下面我来一个一个介绍下。
|
|
|
|
|
|
## init函数
|
|
|
|
|
|
应用程序的初始化是在单一的goroutine执行的。如果包p导入了包q,那么,q的init函数的执行一定 happens before p的任何初始化代码。
|
|
|
|
|
|
这里有一个特殊情况需要你记住:**main函数一定在导入的包的init函数之后执行**。
|
|
|
|
|
|
包级别的变量在同一个文件中是按照声明顺序逐个初始化的,除非初始化它的时候依赖其它的变量。同一个包下的多个文件,会按照文件名的排列顺序进行初始化。这个顺序被定义在[Go语言规范](https://golang.org/ref/spec#Program_initialization_and_execution)中,而不是Go的内存模型规范中。你可以看看下面的例子中各个变量的值:
|
|
|
|
|
|
```
|
|
|
var (
|
|
|
a = c + b // == 9
|
|
|
b = f() // == 4
|
|
|
c = f() // == 5
|
|
|
d = 3 // == 5 全部初始化完成后
|
|
|
)
|
|
|
|
|
|
func f() int {
|
|
|
d++
|
|
|
return d
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
具体怎么对这些变量进行初始化呢?Go采用的是依赖分析技术。不过,依赖分析技术保证的顺序只是针对同一包下的变量,而且,只有引用关系是本包变量、函数和非接口的方法,才能保证它们的顺序性。
|
|
|
|
|
|
同一个包下可以有多个init函数,甚至一个文件中也可以包含多个相同签名的init函数。
|
|
|
|
|
|
刚刚讲的这些都是不同包的init函数执行顺序,下面我举一个具体的例子,把这些内容串起来,你一看就明白了。
|
|
|
|
|
|
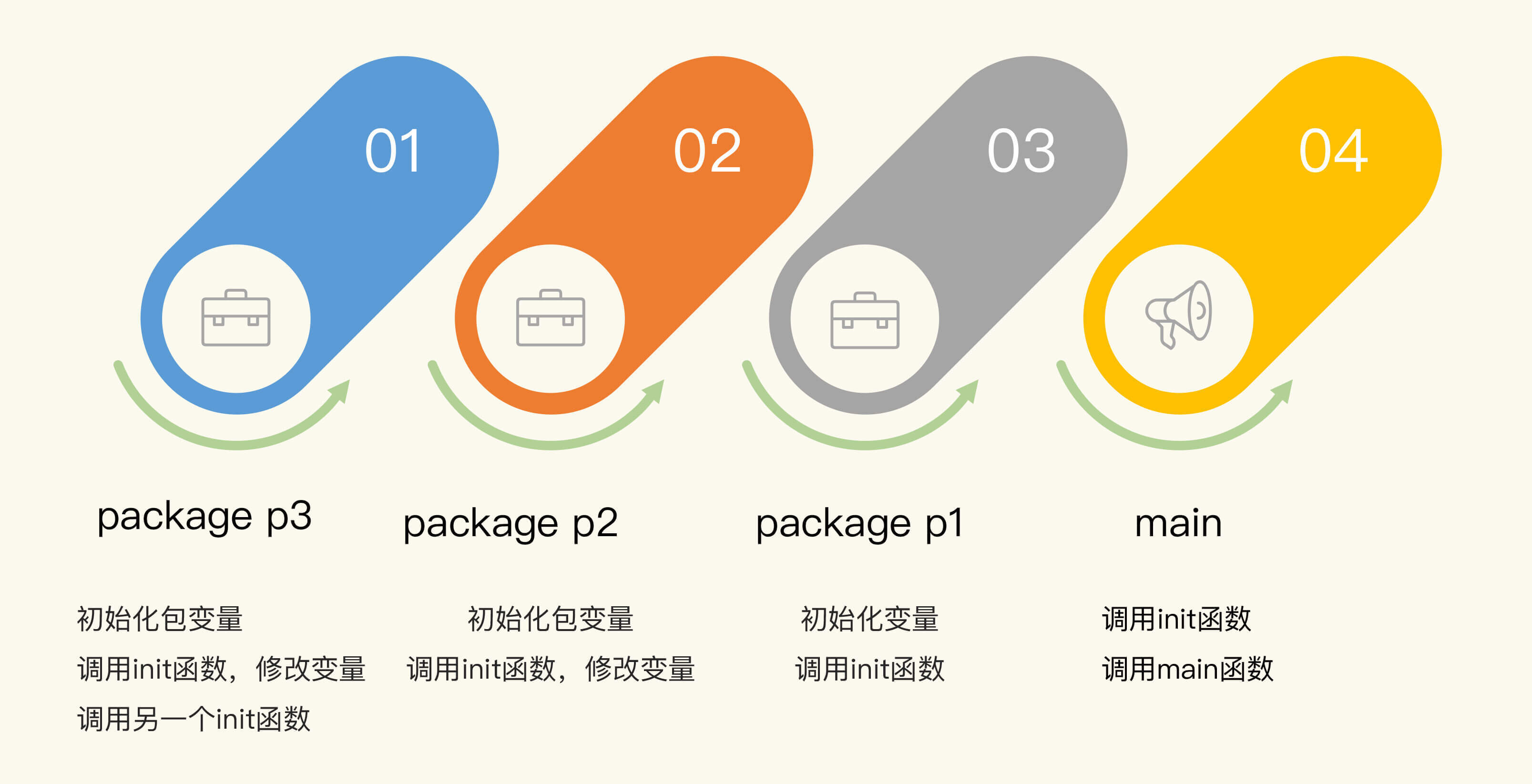
这个例子是一个**main**程序,它依赖包p1,包p1依赖包p2,包p2依赖p3。
|
|
|
|
|
|
|
|
|
|
|
|
为了追踪初始化过程,并输出有意义的日志,我定义了一个辅助方法,打印出日志并返回一个用来初始化的整数值:
|
|
|
|
|
|
```
|
|
|
func Trace(t string, v int) int {
|
|
|
fmt.Println(t, ":", v)
|
|
|
return v
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
包**p3**包含两个文件,分别定义了一个init函数。第一个文件中定义了两个变量,这两个变量的值还会在init函数中进行修改。
|
|
|
|
|
|
我们来分别看下包p3的这两个文件:
|
|
|
|
|
|
```
|
|
|
// lib1.go in p3
|
|
|
|
|
|
var V1_p3 = trace.Trace("init v1_p3", 3)
|
|
|
var V2_p3 = trace.Trace("init v2_p3", 3)
|
|
|
|
|
|
|
|
|
func init() {
|
|
|
fmt.Println("init func in p3")
|
|
|
V1_p3 = 300
|
|
|
V2_p3 = 300
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
```
|
|
|
// lib2.go in p3
|
|
|
|
|
|
func init() {
|
|
|
fmt.Println("another init func in p3")
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
下面再来看看包p2。包p2定义了变量和init函数。第一个变量初始化为2,并在init函数中更改为200。第二个变量是复制的p3.V2\_p3。
|
|
|
|
|
|
```
|
|
|
var V1_p2 = trace.Trace("init v1_p2", 2)
|
|
|
var V2_p2 = trace.Trace("init v2_p2", p3.V2_p3)
|
|
|
|
|
|
func init() {
|
|
|
fmt.Println("init func in p2")
|
|
|
V1_p2 = 200
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
包**p1**定义了变量和init函数。它的两个变量的值是复制的p2对应的两个变量值。
|
|
|
|
|
|
```
|
|
|
var V1_p1 = trace.Trace("init v1_p1", p2.V1_p2)
|
|
|
var V2_p1 = trace.Trace("init v2_p1", p2.V2_p2)
|
|
|
|
|
|
func init() {
|
|
|
fmt.Println("init func in p1")
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
**main**定义了init函数和main函数。
|
|
|
|
|
|
```
|
|
|
func init() {
|
|
|
fmt.Println("init func in main")
|
|
|
}
|
|
|
|
|
|
|
|
|
func main() {
|
|
|
fmt.Println("V1_p1:", p1.V1_p1)
|
|
|
fmt.Println("V2_p1:", p1.V2_p1)
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
运行main函数会依次输出p3、p2、p1、main的初始化变量时的日志(变量初始化时的日志和init函数调用时的日志):
|
|
|
|
|
|
```
|
|
|
// 包p3的变量初始化
|
|
|
init v1_p3 : 3
|
|
|
init v2_p3 : 3
|
|
|
// p3的init函数
|
|
|
init func in p3
|
|
|
// p3的另一个init函数
|
|
|
another init func in p3
|
|
|
|
|
|
// 包p2的变量初始化
|
|
|
init v1_p2 : 2
|
|
|
init v2_p2 : 300
|
|
|
// 包p2的init函数
|
|
|
init func in p2
|
|
|
|
|
|
// 包p1的变量初始化
|
|
|
init v1_p1 : 200
|
|
|
init v2_p1 : 300
|
|
|
// 包p1的init函数
|
|
|
init func in p1
|
|
|
|
|
|
// 包main的init函数
|
|
|
init func in main
|
|
|
// main函数
|
|
|
V1_p1: 200
|
|
|
V2_p1: 300
|
|
|
|
|
|
```
|
|
|
|
|
|
下面,我们再来看看goroutine对happens-before关系的保证情况。
|
|
|
|
|
|
## goroutine
|
|
|
|
|
|
首先,我们需要明确一个规则:**启动goroutine的go语句的执行,一定happens before此goroutine内的代码执行。**
|
|
|
|
|
|
根据这个规则,我们就可以知道,如果go语句传入的参数是一个函数执行的结果,那么,这个函数一定先于goroutine内部的代码被执行。
|
|
|
|
|
|
我们来看一个例子。在下面的代码中,第8行a的赋值和第9行的go语句是在同一个goroutine中执行的,所以,在主goroutine看来,第8行肯定happens before 第9行,又由于刚才的保证,第9行子goroutine的启动happens before 第4行的变量输出,那么,我们就可以推断出,第8行happens before 第4行。也就是说,在第4行打印a的值的时候,肯定会打印出“hello world”。
|
|
|
|
|
|
```
|
|
|
var a string
|
|
|
|
|
|
func f() {
|
|
|
print(a)
|
|
|
}
|
|
|
|
|
|
func hello() {
|
|
|
a = "hello, world"
|
|
|
go f()
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
刚刚说的是启动goroutine的情况,goroutine退出的时候,是没有任何happens-before保证的。所以,如果你想观察某个goroutine的执行效果,你需要使用同步机制建立happens-before关系,比如Mutex或者Channel。接下来,我会讲Channel的happens-before的关系保证。
|
|
|
|
|
|
## Channel
|
|
|
|
|
|
Channel是goroutine同步交流的主要方法。往一个Channel中发送一条数据,通常对应着另一个goroutine从这个Channel中接收一条数据。
|
|
|
|
|
|
通用的Channel happens-before关系保证有4条规则,我分别来介绍下。
|
|
|
|
|
|
**第1条规则是**,往Channel中的发送操作,happens before 从该Channel接收相应数据的动作完成之前,即第n个send一定happens before第n个receive的完成。
|
|
|
|
|
|
```
|
|
|
var ch = make(chan struct{}, 10) // buffered或者unbuffered
|
|
|
var s string
|
|
|
|
|
|
func f() {
|
|
|
s = "hello, world"
|
|
|
ch <- struct{}{}
|
|
|
}
|
|
|
|
|
|
func main() {
|
|
|
go f()
|
|
|
<-ch
|
|
|
print(s)
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
在这个例子中,s的初始化(第5行)happens before 往ch中发送数据, 往ch发送数据 happens before从ch中读取出一条数据(第11行),第12行打印s的值 happens after第11行,所以,打印的结果肯定是初始化后的s的值“hello world”。
|
|
|
|
|
|
**第2条规则是**,close一个Channel的调用,肯定happens before 从关闭的Channel中读取出一个零值。
|
|
|
|
|
|
还是拿刚刚的这个例子来说,如果你把第6行替换成 close(ch),也能保证同样的执行顺序。因为第11行从关闭的ch中读取出零值后,第6行肯定被调用了。
|
|
|
|
|
|
**第3条规则是**,对于unbuffered的Channel,也就是容量是0的Channel,从此Channel中读取数据的调用一定happens before 往此Channel发送数据的调用完成。
|
|
|
|
|
|
所以,在上面的这个例子中呢,如果想保持同样的执行顺序,也可以写成这样:
|
|
|
|
|
|
```
|
|
|
var ch = make(chan int)
|
|
|
var s string
|
|
|
|
|
|
func f() {
|
|
|
s = "hello, world"
|
|
|
<-ch
|
|
|
}
|
|
|
|
|
|
func main() {
|
|
|
go f()
|
|
|
ch <- struct{}{}
|
|
|
print(s)
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
如果第11行发送语句执行成功(完毕),那么根据这个规则,第6行(接收)的调用肯定发生了(执行完成不完成不重要,重要的是这一句“肯定执行了”),那么s也肯定初始化了,所以一定会打印出“hello world”。
|
|
|
|
|
|
这一条比较晦涩,但是,因为Channel是unbuffered的Channel,所以这个规则也成立。
|
|
|
|
|
|
**第4条规则是**,如果Channel的容量是m(m>0),那么,第n个receive一定happens before 第 n+m 个 send的完成。
|
|
|
|
|
|
前一条规则是针对unbuffered channel的,这里给出了更广泛的针对buffered channel的保证。利用这个规则,我们可以实现信号量(Semaphore)的并发原语。Channel的容量相当于可用的资源,发送一条数据相当于请求信号量,接收一条数据相当于释放信号。关于信号量这个并发原语,我会在下一讲专门给你介绍一下,这里你只需要知道它可以控制多个资源的并发访问,就可以了。
|
|
|
|
|
|
## Mutex/RWMutex
|
|
|
|
|
|
对于互斥锁Mutex m或者读写锁RWMutex m,有3条happens-before关系的保证。
|
|
|
|
|
|
1. 第n次的m.Unlock一定happens before第n+1 m.Lock方法的返回;
|
|
|
2. 对于读写锁RWMutex m,如果它的第n个m.Lock方法的调用已返回,那么它的第n个m.Unlock的方法调用一定happens before 任何一个m.RLock方法调用的返回,只要这些m.RLock方法调用 happens after 第n次m.Lock的调用的返回。这就可以保证,只有释放了持有的写锁,那些等待的读请求才能请求到读锁。
|
|
|
3. 对于读写锁RWMutex m,如果它的第n个m.RLock方法的调用已返回,那么它的第k (k<=n)个成功的m.RUnlock方法的返回一定happens before 任意的m.RUnlockLock方法调用,只要这些m.Lock方法调用happens after第n次m.RLock。
|
|
|
|
|
|
读写锁的保证有点绕,我再带你看看官方的描述:
|
|
|
|
|
|
> 对于读写锁l的 l.RLock方法调用,如果存在一个**n**,这次的l.RLock调用 happens after 第n次的l.Unlock,那么,和这个RLock相对应的l.RUnlock一定happens before 第n+1次l.Lock。意思是,读写锁的Lock必须等待既有的读锁释放后才能获取到。
|
|
|
|
|
|
我再举个例子。在下面的代码中,第6行第一次的Unlock一定happens before第二次的Lock(第12行),所以这也能保证正确地打印出“hello world”。
|
|
|
|
|
|
```
|
|
|
var mu sync.Mutex
|
|
|
var s string
|
|
|
|
|
|
func foo() {
|
|
|
s = "hello, world"
|
|
|
mu.Unlock()
|
|
|
}
|
|
|
|
|
|
func main() {
|
|
|
mu.Lock()
|
|
|
go foo()
|
|
|
mu.Lock()
|
|
|
print(s)
|
|
|
|
|
|
```
|
|
|
|
|
|
## WaitGroup
|
|
|
|
|
|
接下来是WaitGroup的保证。
|
|
|
|
|
|
对于一个WaitGroup实例wg,在某个时刻t0时,它的计数值已经不是零了,假如t0时刻之后调用了一系列的wg.Add(n)或者wg.Done(),并且只有最后一次调用wg的计数值变为了0,那么,可以保证这些wg.Add或者wg.Done()一定 happens before t0时刻之后调用的wg.Wait方法的返回。
|
|
|
|
|
|
这个保证的通俗说法,就是**Wait方法等到计数值归零之后才返回**。
|
|
|
|
|
|
## Once
|
|
|
|
|
|
我们在[第8讲](https://time.geekbang.org/column/article/301113)学过Once了,相信你已经很熟悉它的功能了。它提供的保证是:**对于once.Do(f)调用,f函数的那个单次调用一定happens before 任何once.Do(f)调用的返回**。换句话说,就是函数f一定会在Do方法返回之前执行。
|
|
|
|
|
|
还是以hello world的例子为例,这次我们使用Once并发原语实现,可以看下下面的代码:
|
|
|
|
|
|
```
|
|
|
var s string
|
|
|
var once sync.Once
|
|
|
|
|
|
func foo() {
|
|
|
s = "hello, world"
|
|
|
}
|
|
|
|
|
|
func twoprint() {
|
|
|
once.Do(foo)
|
|
|
print(s)
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
第5行的执行一定happens before第9行的返回,所以执行到第10行的时候,sd已经初始化了,所以会正确地打印“hello world”。
|
|
|
|
|
|
最后,我再来说说atomic的保证。
|
|
|
|
|
|
## atomic
|
|
|
|
|
|
其实,Go内存模型的官方文档并没有明确给出atomic的保证,有一个相关的issue [go# 5045](https://github.com/golang/go/issues/5045)记录了相关的讨论。光看issue号,就知道这个讨论由来已久了。Russ Cox想让atomic有一个弱保证,这样可以为以后留下充足的可扩展空间,所以,Go内存模型规范上并没有严格的定义。
|
|
|
|
|
|
对于Go 1.15的官方实现来说,可以保证使用atomic的Load/Store的变量之间的顺序性。
|
|
|
|
|
|
在下面的例子中,打印出的a的结果总是1,但是官方并没有做任何文档上的说明和保证。
|
|
|
|
|
|
依照Ian Lance Taylor的说法,Go核心开发组的成员几乎没有关注这个方向上的研究,因为这个问题太复杂,有很多问题需要去研究,所以,现阶段还是不要使用atomic来保证顺序性。
|
|
|
|
|
|
```
|
|
|
func main() {
|
|
|
var a, b int32 = 0, 0
|
|
|
|
|
|
go func() {
|
|
|
atomic.StoreInt32(&a, 1)
|
|
|
atomic.StoreInt32(&b, 1)
|
|
|
}()
|
|
|
|
|
|
for atomic.LoadInt32(&b) == 0{
|
|
|
runtime.Gosched()
|
|
|
}
|
|
|
fmt.Println(atomic.LoadInt32(&a))
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
# 总结
|
|
|
|
|
|
Go的内存模型规范中,一开始有这么一段话:
|
|
|
|
|
|
> If you must read the rest of this document to understand the behavior of your program, you are being too clever.
|
|
|
|
|
|
> Don't be clever.
|
|
|
|
|
|
我来说说我对这句话的理解:你通过学习这节课来理解你的程序的行为是聪明的,但是,不要自作聪明。
|
|
|
|
|
|
谨慎地使用这些保证,能够让你的程序按照设想的happens-before关系执行,但是不要以为完全理解这些概念和保证,就可以随意地制造所谓的各种技巧,否则就很容易掉进“坑”里,而且会给代码埋下了很多的“定时炸弹”。
|
|
|
|
|
|
比如,Go里面已经有值得信赖的互斥锁了,如果没有额外的需求,就不要使用Channel创造出自己的互斥锁。
|
|
|
|
|
|
当然,我也不希望你畏手畏脚地把思想局限住,我还是建议你去做一些有意义的尝试,比如使用Channel实现信号量等扩展并发原语。
|
|
|
|
|
|
|
|
|
|
|
|
# 思考题
|
|
|
|
|
|
我们知道,Channel可以实现互斥锁,那么,我想请你思考一下,它是如何利用happens-before关系保证锁的请求和释放的呢?
|
|
|
|
|
|
欢迎在留言区写下你的思考和答案,我们一起交流讨论。如果你觉得有所收获,也欢迎你把今天的内容分享给你的朋友或同事。
|
|
|
|