245 lines
19 KiB
Markdown
245 lines
19 KiB
Markdown
# 09 | I/O优化(上):开发工程师必备的I/O优化知识
|
||
|
||
> 250GB容量,512MB DDR4缓存,连续读取不超过550MB/s,连续写入不超过520MB/s。
|
||
|
||
“双十一”在天猫看到一款固态硬盘有上面的这些介绍,这些数字分别代表了什么意思?
|
||
|
||
在专栏前面卡顿和启动优化里,我也经常提到I/O优化。可能很多同学觉得I/O优化不就是不在主线程读写大文件吗,真的只有这么简单吗?那你是否考虑过,从应用程序调用read()方法,内核和硬件会做什么样的处理,整个流程可能会出现什么问题?今天请你带着这些疑问,我们一起来看看I/O优化需要的知识。
|
||
|
||
## I/O的基本知识
|
||
|
||
在工作中,我发现很多工程师对I/O的认识其实比较模糊,认为I/O就是应用程序执行read()、write()这样的一些操作,并不清楚这些操作背后的整个流程是怎样的。
|
||
|
||
|
||
|
||
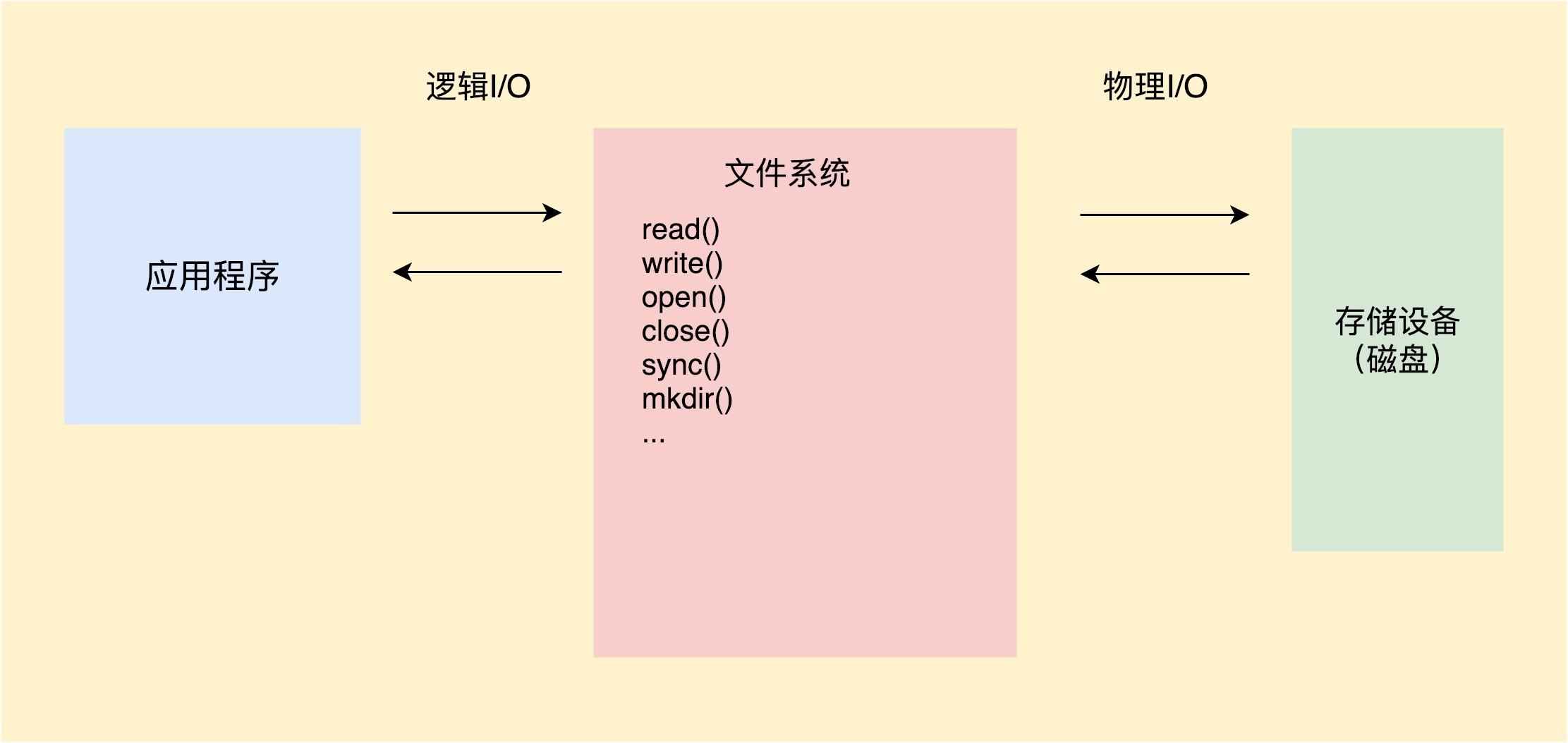
我画了一张简图,你可以看到整个文件I/O操作由应用程序、文件系统和磁盘共同完成。首先应用程序将I/O命令发送给文件系统,然后文件系统会在合适的时机把I/O操作发给磁盘。
|
||
|
||
这就好比CPU、内存、磁盘三个小伙伴一起完成接力跑,最终跑完的时间很大程度上取决于最慢的小伙伴。我们知道,CPU和内存相比磁盘是高速设备,整个流程的瓶颈在于磁盘I/O的性能。所以很多时候,文件系统性能比磁盘性能更加重要,为了降低磁盘对应用程序的影响,文件系统需要通过各种各样的手段进行优化。那么接下来,我们首先来看文件系统。
|
||
|
||
**1\. 文件系统**
|
||
|
||
文件系统,简单来说就是存储和组织数据的方式。比如在iOS 10.3系统以后,苹果使用APFS(Apple File System)替代之前旧的文件系统HFS+。对于Android来说,现在普遍使用的是Linux常用的ext4文件系统。
|
||
|
||
关于文件系统还需要多说两句,华为在EMUI 5.0以后就使用F2FS取代ext4,Google也在最新的旗舰手机Pixel 3使用了F2FS文件系统。Flash-Friendly File System是三星是专门为NAND闪存芯片开发的文件系统,也做了大量针对闪存的优化。根据华为的测试数据,F2FS文件系统在小文件的随机读写方面比ext4更快,例如随机写可以优化60%,不足之处在于可靠性方面出现过一些问题。我想说的是,随着Google、华为的投入和规模化使用,F2FS系统应该是未来Android的主流文件系统。
|
||
|
||
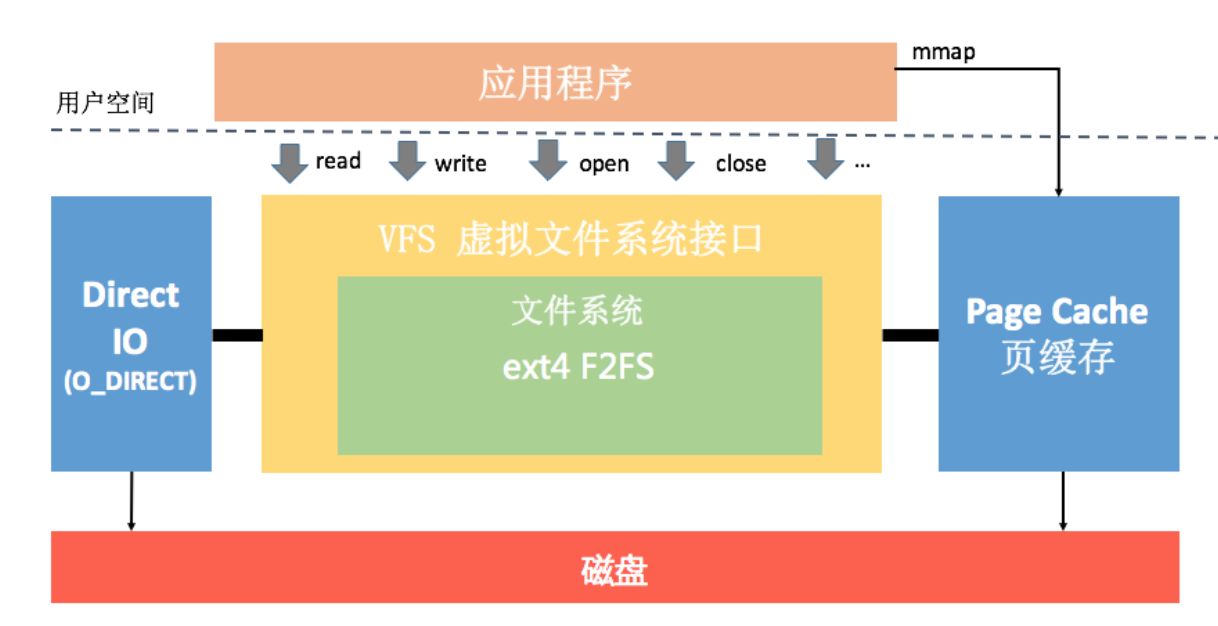
还是回到文件系统的I/O。应用程序调用read()方法,系统会通过中断从用户空间进入内核处理流程,然后经过VFS(Virtual File System,虚拟文件系统)、具体文件系统、页缓存Page Cache。下面是Linux一个通用的I/O架构模型。
|
||
|
||
|
||
|
||
* 虚拟文件系统(VFS)。它主要用于实现屏蔽具体的文件系统,为应用程序的操作提供一个统一的接口。这样保证就算厂商把文件系统从ext4切换到F2FS,应用程序也不用做任何修改。
|
||
|
||
* 文件系统(File System)。ext4、F2FS都是具体文件系统实现,文件元数据如何组织、目录和索引结构如何设计、怎么分配和清理数据,这些都是设计一个文件系统必须要考虑的。**每个文件系统都有适合自己的应用场景,我们不能说F2FS就一定比ext4要好。**F2FS在连续读取大文件上并没有优势,而且会占用更大的空间。只是对一般应用程序来说,随机I/O会更加频繁,特别是在启动的场景。你可以在/proc/filesystems看到系统可以识别的所有文件系统的列表。
|
||
|
||
* 页缓存(Page Cache)。在启动优化中我已经讲过Page Cache这个概念了,在读文件的时候会,先看它是不是已经在Page Cache中,如果命中就不会去读取磁盘。在Linux 2.4.10之前还有一个单独的Buffer Cache,后来它也合并到Page Cache中的Buffer Page了。
|
||
|
||
|
||
具体来说,Page Cache就像是我们经常使用的数据缓存,是文件系统对数据的缓存,目的是提升内存命中率。Buffer Cache就像我们经常使用的BufferInputStream,是磁盘对数据的缓存,目的是合并部分文件系统的I/O请求、降低磁盘I/O的次数。**需要注意的是,它们既会用在读请求中,也会用到写请求中。**
|
||
|
||
通过/proc/meminfo文件可以查看缓存的内存占用情况,当手机内存不足的时候,系统会回收它们的内存,这样整体I/O的性能就会有所降低。
|
||
|
||
```
|
||
MemTotal: 2866492 kB
|
||
MemFree: 72192 kB
|
||
Buffers: 62708 kB // Buffer Cache
|
||
Cached: 652904 kB // Page Cache
|
||
|
||
```
|
||
|
||
**2\. 磁盘**
|
||
|
||
磁盘指的是系统的存储设备,就像小时候我们常听的CD或者电脑使用的机械硬盘,当然还有现在比较流行的SSD固态硬盘。
|
||
|
||
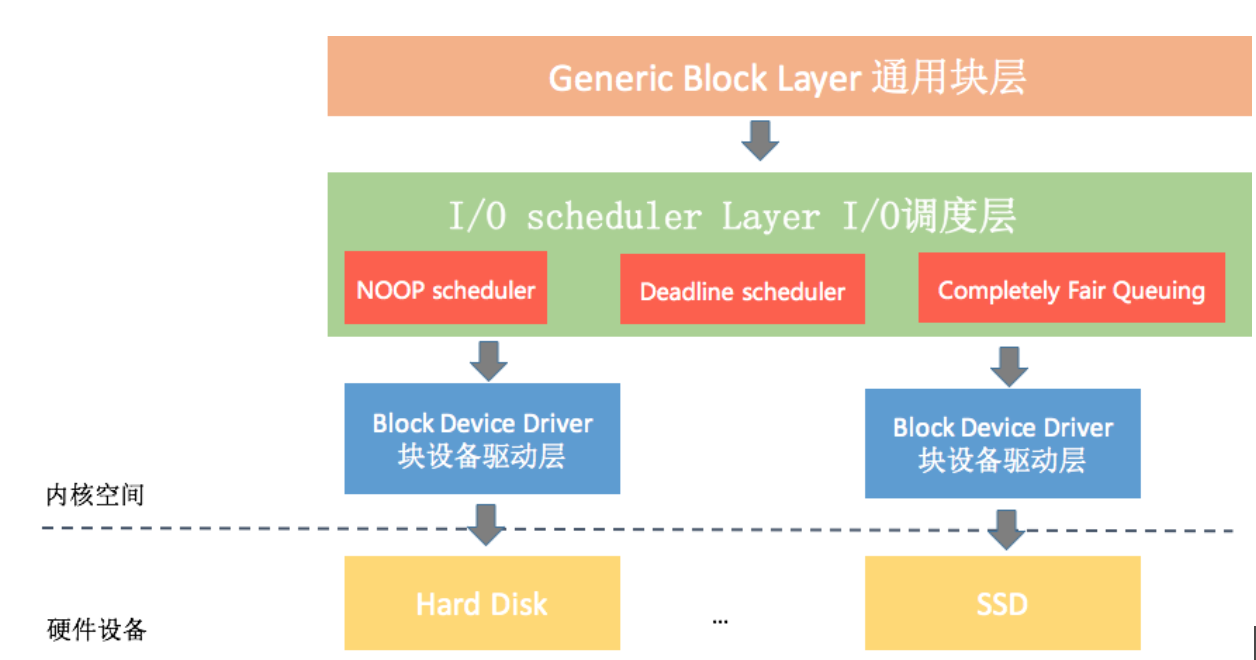
正如我上面所说,如果发现应用程序要read()的数据没有在页缓存中,这时候就需要真正向磁盘发起I/O请求。这个过程要先经过内核的通用块层、I/O调度层、设备驱动层,最后才会交给具体的硬件设备处理。
|
||
|
||
|
||
|
||
* 通用块层。系统中能够随机访问固定大小数据块(block)的设备称为块设备,CD、硬盘和SSD这些都属于块设备。通用块层主要作用是接收上层发出的磁盘请求,并最终发出I/O请求。它跟VFS的作用类似,让上层不需要关心底层硬件设备的具体实现。
|
||
|
||
* I/O调度层。磁盘I/O那么慢,为了降低真正的磁盘I/O,我们不能接收到磁盘请求就立刻交给驱动层处理。所以我们增加了I/O调度层,它会根据设置的调度算法对请求合并和排序。这里比较关键的参数有两个,一个是队列长度,一个是具体的调度算法。我们可以通过下面的文件可以查看对应块设备的队列长度和使用的调度算法。
|
||
|
||
|
||
```
|
||
/sys/block/[disk]/queue/nr_requests // 队列长度,一般是 128。
|
||
/sys/block/[disk]/queue/scheduler // 调度算法
|
||
|
||
```
|
||
|
||
* 块设备驱动层。块设备驱动层根据具体的物理设备,选择对应的驱动程序通过操控硬件设备完成最终的I/O请求。例如光盘是靠激光在表面烧录存储、闪存是靠电子擦写存储数据。
|
||
|
||
## Android I/O
|
||
|
||
前面讲了Linux I/O相关的一些知识,现在我们再来讲讲Android I/O相关的一些知识。
|
||
|
||
**1\. Android闪存**
|
||
|
||
我们先来简单讲讲手机使用的存储设备,手机使用闪存作为存储设备,也就是我们常说的ROM。
|
||
|
||
考虑到体积和功耗,我们肯定不能直接把PC的SSD方案用在手机上面。Android手机前几年通常使用eMMC标准,近年来通常会采用性能更好的UFS 2.0/2.1标准,之前沸沸扬扬的某厂商“闪存门”事件就是因为使用eMMC闪存替换了宣传中的UFS闪存。而苹果依然坚持独立自主的道路,在2015年就在iPhone 6s上就引入了MacBook上备受好评的NVMe协议。
|
||
|
||
最近几年移动硬件的发展非常妖孽,手机存储也朝着体积更小、功耗更低、速度更快、容量更大的方向狂奔。iPhone XS的容量已经达到512GB,连续读取速度可以超过1GB/s,已经比很多的SSD固态硬盘还要快,同时也大大缩小了和内存的速度差距。不过这些都是厂商提供的一些测试数据,特别是对于随机读写的性能相比内存还是差了很多。
|
||
|
||

|
||
|
||
上面的数字好像有点抽象,直白地说闪存的性能会影响我们打开微信、游戏加载以及连续自拍的速度。当然闪存性能不仅仅由硬件决定,它跟采用的标准、文件系统的实现也有很大的关系。
|
||
|
||
**2\. 两个疑问**
|
||
|
||
看到这里可能有些同学会问,知道文件读写的流程、文件系统和磁盘这些基础知识,对我们实际开发有什么作用呢?下面我举两个简单的例子,可能你平时也思考过,不过如果不熟悉I/O的内部机制,你肯定是一知半解。
|
||
|
||
**疑问一:文件为什么会损坏?**
|
||
|
||
先说两个客观数据,微信聊天记录使用的SQLite数据库大概有几万分之一的损坏率,系统SharedPreference如果频繁跨进程读写也会有万分之一的损坏率。
|
||
|
||
在回答文件为什么会损坏前,首先需要先明确一下什么是文件损坏。一个文件的格式或者内容,如果没有按照应用程序写入时的结果都属于文件损坏。它不只是文件格式错误,文件内容丢失可能才是最常出现的,SharedPreference跨进程读写就非常容易出现数据丢失的情况。
|
||
|
||
再来探讨文件为什么会损坏,我们可以从应用程序、文件系统和磁盘三个角度来审视这个问题。
|
||
|
||
* 应用程序。大部分的I/O方法都不是原子操作,文件的跨进程或者多线程写入、使用一个已经关闭的文件描述符fd来操作文件,它们都有可能导致数据被覆盖或者删除。事实上,大部分的文件损坏都是因为应用程序代码设计考虑不当导致的,并不是文件系统或者磁盘的问题。
|
||
|
||
* 文件系统。虽说内核崩溃或者系统突然断电都有可能导致文件系统损坏,不过文件系统也做了很多的保护措施。例如system分区保证只读不可写,增加异常检查和恢复机制,ext4的fsck、f2fs的fsck.f2fs和checkpoint机制等。
|
||
|
||
|
||
在文件系统这一层,更多是因为断电而导致的写入丢失。为了提升I/O性能,文件系统把数据写入到Page Cache中,然后等待合适的时机才会真正的写入磁盘。当然我们也可以通过fsync、msync这些接口强制写入磁盘,在下一其我会详细介绍直接I/O和缓存I/O。
|
||
|
||
* 磁盘。手机上使用的闪存是电子式的存储设备,所以在资料传输过程可能会发生电子遗失等现象导致数据错误。不过闪存也会使用ECC、多级编码等多种方式增加数据的可靠性,一般来说出现这种情况的可能性也比较小。
|
||
|
||
闪存寿命也可能会导致数据错误,由于闪存的内部结构和特征,导致它写过的地址必须擦除才能再次写入,而每个块擦除又有次数限制,次数限制是根据采用的存储颗粒,从十万次到几千都有(SLC>MLC>TLC)。
|
||
|
||
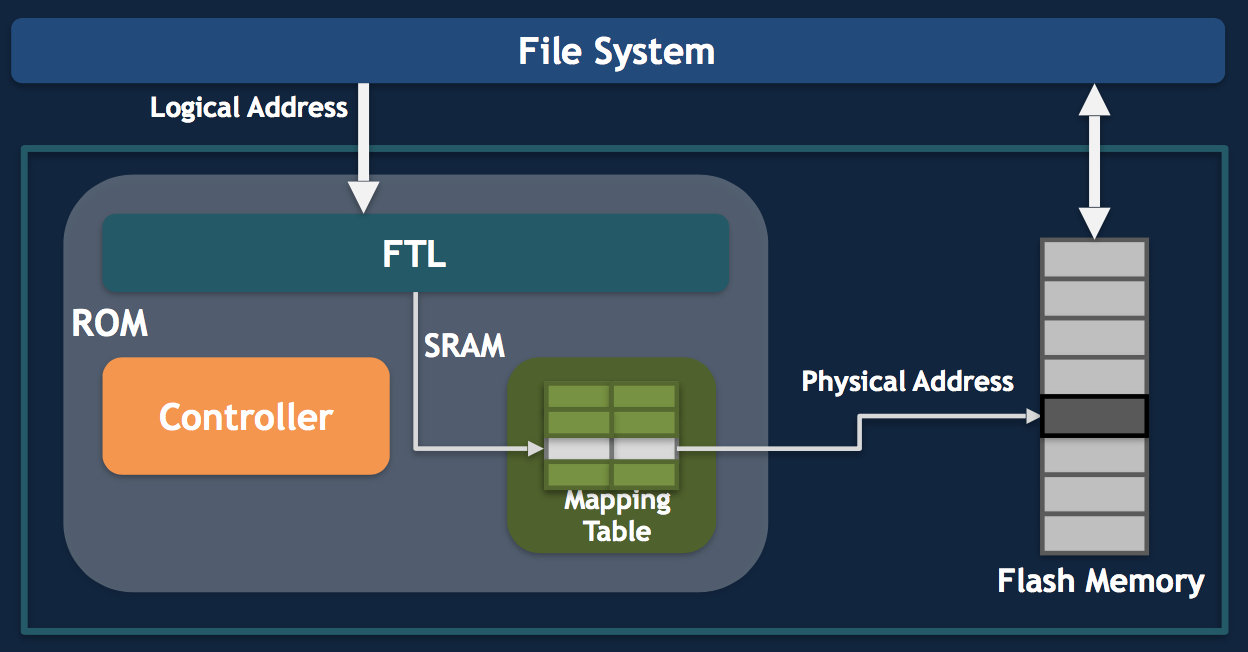
下图是闪存(Flash Memory)的结构图,其中比较重要的是FTL(Flash Translation Layer),它负责物理地址的分配和管理。它需要考虑到每个块的擦除寿命,将擦除次数均衡到所有块上去。当某个块空间不够的时候,它还要通过垃圾回收算法将数据迁移。FTL决定了闪存的使用寿命、性能和可靠性,是闪存技术中最为重要的核心技术之一。
|
||
|
||
|
||
|
||
对于手机来说,假设我们的存储大小是128GB,即使闪存的最大擦除次数只有1000次,那也可以写入128TB,但一般来说比较难达到。
|
||
|
||
**疑问二:I/O有时候为什么会突然很慢?**
|
||
|
||
手机厂商的数据通常都是出厂数据,我们在使用Android手机的时候也会发现,刚买的时候“如丝般顺滑”的手机,在使用一年之后就会变得卡顿无比。
|
||
|
||
这是为什么呢?在一些低端机上面,我发现大量跟I/O相关的卡顿。I/O有时候为什么会突然变慢,可能有下面几个原因。
|
||
|
||
* 内存不足。当手机内存不足的时候,系统会回收Page Cache和Buffer Cache的内存,大部分的写操作会直接落盘,导致性能低下。
|
||
|
||
* 写入放大。上面我说到闪存重复写入需要先进行擦除操作,但这个擦除操作的基本单元是block块,一个page页的写入操作将会引起整个块数据的迁移,这就是典型的写入放大现象。低端机或者使用比较久的设备,由于磁盘碎片多、剩余空间少,非常容易出现写入放大的现象。具体来说,闪存读操作最快,在20us左右。写操作慢于读操作,在200us左右。而擦除操作非常耗时,在1ms左右的数量级。当出现写入放大时,因为涉及移动数据,这个时间会更长。
|
||
|
||
* 由于低端机的CPU和闪存的性能相对也较差,在高负载的情况下容易出现瓶颈。例如eMMC闪存不支持读写并发,当出现写入放大现象时,读操作也会受影响。
|
||
|
||
|
||
系统为了缓解磁盘碎片问题,可以引入fstrim/TRIM机制,在锁屏、充电等一些时机会触发磁盘碎片整理。
|
||
|
||
## I/O的性能评估
|
||
|
||
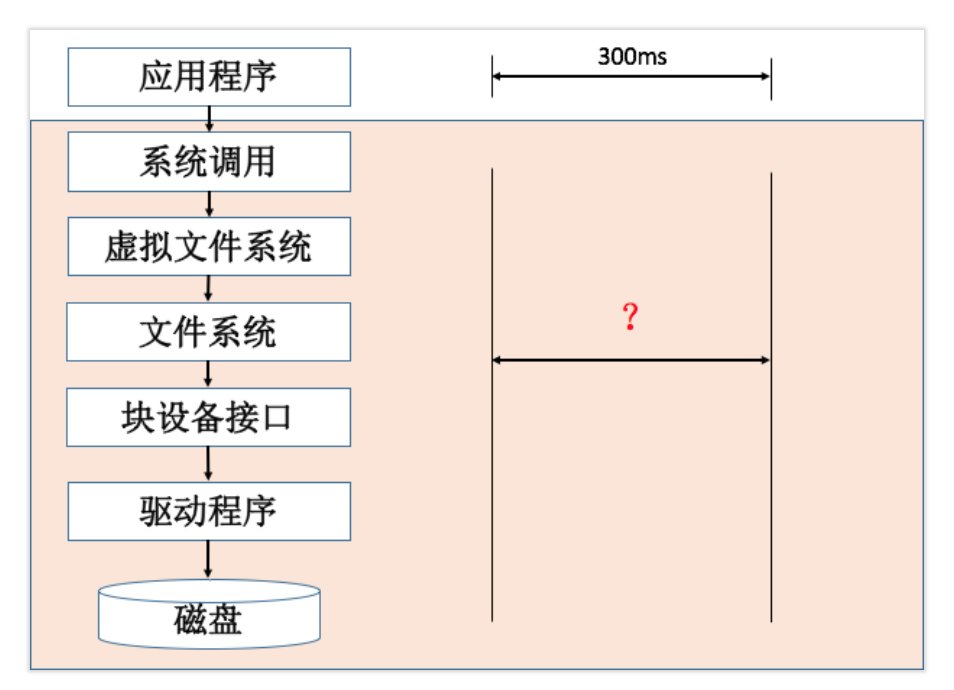
正如下图你所看到的,整个I/O的流程涉及的链路非常长。我们在应用程序中通过打点,发现一个文件读取需要300ms。但是下面每一层可能都有自己的策略和调度算法,因此很难真正的得到每一层的耗时。
|
||
|
||
|
||
|
||
在前面的启动优化内容中,我讲过Facebook和支付宝采用编译单独ROM的方法来评估I/O性能。这是一个比较复杂但是有效的做法,我们可以通过定制源码,选择打开感兴趣的日志来追踪I/O的性能。
|
||
|
||
**1\. I/O性能指标**
|
||
|
||
I/O性能评估中最为核心的指标是吞吐量和IOPS。今天文章开头所说的,“连续读取不超过550MB/s,连续写入不超过520MB/s”,就指的是I/O吞吐量。
|
||
|
||
还有一个比较重要的指标是IOPS,它指的是每秒可以读写的次数。对于随机读写频繁的应用,例如大量的小文件存储,IOPS是关键的衡量指标。
|
||
|
||
**2\. I/O测量**
|
||
|
||
如果不采用定制源码的方式,还有哪些方法可以用来测量I/O的性能呢?
|
||
|
||
**第一种方法:使用proc。**
|
||
|
||
总的来说,I/O性能会跟很多因素有关,是读还是写、是否是连续、I/O大小等。另外一个对I/O性能影响比较大的因素是负载,I/O性能会随着负载的增加而降低,我们可以通过I/O的等待时间和次数来衡量。
|
||
|
||
```
|
||
proc/self/schedstat:
|
||
se.statistics.iowait_count:IO 等待的次数
|
||
se.statistics.iowait_sum: IO 等待的时间
|
||
|
||
```
|
||
|
||
如果是root的机器,我们可以开启内核的I/O监控,将所有block读写dump到日志文件中,这样可以通过dmesg命令来查看。
|
||
|
||
```
|
||
echo 1 > /proc/sys/vm/block_dump
|
||
dmesg -c grep pid
|
||
|
||
.sample.io.test(7540): READ block 29262592 on dm-1 (256 sectors)
|
||
.sample.io.test(7540): READ block 29262848 on dm-1 (256 sectors)
|
||
|
||
```
|
||
|
||
**第二种方法:使用strace。**
|
||
|
||
Linux提供了iostat、iotop等一些相关的命令,不过大部分Anroid设备都不支持。我们可以通过 strace来跟踪I/O相关的系统调用次数和耗时。
|
||
|
||
```
|
||
strace -ttT -f -p [pid]
|
||
|
||
read(53, "*****************"\.\.\., 1024) = 1024 <0.000447>
|
||
read(53, "*****************"\.\.\., 1024) = 1024 <0.000084>
|
||
read(53, "*****************"\.\.\., 1024) = 1024 <0.000059>
|
||
|
||
```
|
||
|
||
通过上面的日志,你可以看到应用程序在读取文件操作符为53的文件,每次读取1024个字节。第一次读取花了447us,后面两次都使用了100us不到。这跟启动优化提到的“数据重排”是一个原因,文件系统每次读取以block为单位,而block的大小一般是4KB,后面两次的读取是从页缓存得到。
|
||
|
||
我们也可以通过strace统计一段时间内所有系统调用的耗时概况。不过strace本身也会消耗不少资源,对执行时间也会产生影响。
|
||
|
||
```
|
||
strace -c -f -p [pid]
|
||
|
||
% time seconds usecs/call calls errors syscall
|
||
------ ----------- ----------- --------- --------- ----------------
|
||
97.56 0.041002 21 1987 read
|
||
1.44 0.000605 55 11 write
|
||
|
||
```
|
||
|
||
从上面的信息你可以看到,读占了97.56%的时间,一共调用了1987次,耗时0.04s,平均每次系统调用21us。同样的道理,**我们也可以计算应用程序某个任务I/O耗时的百分比**。假设一个任务执行了10s,I/O花了9s,那么I/O耗时百分比就是90%。这种情况下,I/O就是我们任务很大的瓶颈,需要去做进一步的优化。
|
||
|
||
**第三种方法:使用vmstat。**
|
||
|
||
vmstat的各个字段说明可以参考[《vmstat监视内存使用情况》](https://linuxtools-rst.readthedocs.io/zh_CN/latest/tool/vmstat.html),其中Memory中的buff和cache,I/O中的bi和bo,System中的cs,以及CPU中的sy和wa,这些字段的数值都与I/O行为有关。
|
||
|
||

|
||
|
||
我们可以配合[dd命令](https://www.cnblogs.com/kongzhongqijing/articles/9049336.html)来配合测试,观察vmstat的输出数据变化。**不过需要注意的是Android里面的dd命令似乎并不支持conv和flag参数。**
|
||
|
||
```
|
||
//清除Buffer和Cache内存缓存
|
||
echo 3 > /proc/sys/vm/drop_caches
|
||
//每隔1秒输出1组vmstat数据
|
||
vmstat 1
|
||
|
||
|
||
//测试写入速度,写入文件/data/data/test,buffer大小为4K,次数为1000次
|
||
dd if=/dev/zero of=/data/data/test bs=4k count=1000
|
||
|
||
```
|
||
|
||
## 总结
|
||
|
||
在性能优化的过程中,我们关注最多的是CPU和内存,I/O也是性能优化中比较重要的一部分。
|
||
|
||
今天我们学习I/O处理的整个流程,它包括应用程序、文件系统和磁盘三个部分。不过I/O这个话题真的很大,在课后需要花更多时间学习课后练习中的一些参考资料。
|
||
|
||
LPDDR5、UFS 3.0很快就要在2019年面世,有些同学会想,随着硬件越来越牛,我们根本就不需要去做优化了。但是一方面考虑到成本的问题,在嵌入式、IoT等一些场景的设备硬件不会太好;另一方面,我们对应用体验的要求也越来越高,沉浸体验(VR)、人工智能(AI)等新功能对硬件的要求也越来越高。所以,应用优化是永恒的,只是在不同的场景下有不同的要求。
|
||
|
||
## 课后练习
|
||
|
||
学习完今天的内容,可能大部分同学会感觉有点陌生、有点茫然。但是没有关系,我们可以在课后补充更多的基础知识,下面的链接是我推荐给你的参考资料。今天的课后作业是,通过今天的学习,在留言区写写你对I/O的理解,以及你都遇到过哪些I/O方面的问题。
|
||
|
||
1.[磁盘I/O那些事](https://tech.meituan.com/about_desk_io.html)
|
||
|
||
2.[Linux 内核的文件 Cache 管理机制介绍](https://www.ibm.com/developerworks/cn/linux/l-cache/index.html)
|
||
|
||
3.[The Linux Kernel/Storage](https://en.wikibooks.org/wiki/The_Linux_Kernel/Storage)
|
||
|
||
4.[选eMMC、UFS还是NVMe? 手机ROM存储传输协议解析](https://www.sohu.com/a/196510603_616364)
|
||
|
||
5.[聊聊Linux IO](http://0xffffff.org/2017/05/01/41-linux-io/)
|
||
|
||
6.[采用NAND Flash设计存储设备的挑战在哪里?](http://blog.51cto.com/alanwu/1425566)
|
||
|
||
“实践出真知”,你也可以尝试使用strace和block\_dump来观察自己应用的I/O情况,不过有些实验会要求有root的机器。
|
||
|
||
欢迎你点击“请朋友读”,把今天的内容分享给好友,邀请他一起学习。最后别忘了在评论区提交今天的作业,我也为认真完成作业的同学准备了丰厚的“学习加油礼包”,期待与你一起切磋进步哦。
|
||
|