14 KiB
25|成果验证:如何评价遗留系统现代化项目的成败?
你好,我是姚琪琳。
前面我们用了四节课的时间,解决了在拆分遗留系统时会遇到的种种难题。接下来就到了“提交答卷”的重要时刻,也就是遗留系统现代化的成果验证。
如果团队费时费力做完了改造,就撤出或解散了,没有后续的数据追踪和指标度量,改造成效就无法很好地展示出来。这样,领导和业务方对成效的感知就会很弱,下次可能就不会再投入资源做类似的改造了。
编筐编篓,全在收口,这节课我们就来聊聊成果验证的方法,让你的遗留系统改造项目在掌声中落下帷幕。
功能验证
首先,当一个任务改造完成后,我们需要对它进行功能方面的测试,以确保改造后的功能和改造前的功能是一致的。
这种不改变软件外在行为的“改造”其实就是重构,只不过不是代码级别,而是架构级别的重构。通常,代码级别的重构我们会用单元测试来保证重构的正确性,那对于这种架构级别的重构,应该如何来保证呢?
并行核对
我们前面的课程中一直在说,要基于特性开关做人工的A/B测试。其实A/B测试原本是用于用户体验分析的,收集用户对A、B两个软件版本的真实反馈来进行选择。我们这里将其作为验证重构正确性的工具,算是扩大了它的外延。
其实这种方法有一个专门的名词,叫做并行核对(Parallel Run with Reconciliation)。只不过手工进行的并行核对还是略显麻烦,更好的方式是将该过程自动化。
GitHub在重构自己的遗留代码的时候,为了对比方便,开发了Scientist这个并行核对工具。虽然它本身只支持Ruby,不过也有了多种语言的移植版本。这个工具尤其适合那种使用扩张-收缩模式来进行重构的代码。但它也有相当大的局限,比如不能验证代码的副作用,然而毫无副作用的遗留代码是少之又少的。
要想更好地自动化并行核对,我还是建议自己手动开发一个适合自己遗留系统的工具。我在课程中屡次提到自己开发工具,你可能会望而却步,其实这并没有多难。因为你只需要开发一个能满足自己遗留系统的工具即可,不需要尽善尽美。
除了全自动化的并行核对,你还可以进行一些半自动化的并行核对,下面我们就来看看都有哪些手段。
E2E测试
我们在第八节课中提到过,遗留系统的测试策略应该是个钻石型,其中最上层就是E2E测试。它们可以模拟真实用户的行为,用来验证从页面到数据库的所有环节。
在不少团队中,编写E2E测试是测试人员的工作。因此使用E2E测试进行并行核对的好处是,可以在拆分团队拆分API时,由测试人员并行地去编写E2E测试,这样就节省了大量的时间。
之所以说使用E2E测试进行并行核对是半自动化的,是因为在运行时需要手动调整一下开关。比如测试人员在编写E2E测试时,是基于开关关闭的旧代码来写的。等重构的代码提测之后,测试人员手动打开开关,再次运行测试。如果测试仍然通过,我们就认为重构没有破坏原有的功能。
如果你的遗留系统已经搭建了持续集成流水线,你也可以在重构的代码提交之后,在持续集成流水线中打开开关,并运行E2E测试。
集成测试
然而我们主要想测试的部分是后端代码和数据,而且E2E测试的反馈相对来说还是有些滞后,如果想在开发阶段就能做并行核对,那就需要开发人员在重构阶段编写测试了。
由于我们的增量是一个API,要验证这个API,最直接的方式就是对这个API编写测试。你可以使用Spring Boot等工具来编写针对API的集成测试,对于RESET API来说,还是十分方便的。但我们的案例是普通的Servlet,写起来就有些麻烦了。
这时,我们可以再退一步,放弃测试HTTP相关的内容(因为这一部分本来也不会发生变化),而是直接测试请求所映射的Servlet中的方法。如果这个方法很薄,只是将逻辑委托给了另一个Service,那么直接测试那个Service会更方便。
要想做到并行核对,你需要将测试复制成两份,一份位于单体服务中,用来测试旧的Servlet,一份位于核保服务中,用来测试新的Servlet。这两份测试略微有些不同,因为在核保服务中的测试需要mock掉对于单体服务的依赖。
// 核保服务中的测试
@Test
public void should_approve_underwrite_application_succesfully() {
PolicyServiceProvider policyService = mock(PolicyServiceProvider.class);
when(policyService.approveUnderwriteApplication(1L)).thenReturn(/*...*/);
UnderwriteApplicationService sut = new UnderwriteApplicationService(policyService);
sut.approve(1L);
UnderwriteApplication uw = getUnderwriteApplicationFromDB(1L);
assertEquals("2", uw.getStatus());
verify(policyService).approveUnderwriteApplication(1L);
}
// 单体服务中的测试
@Test
public void should_approve_underwrite_application_succesfully() {
UnderwriteApplicationService sut = new UnderwriteApplicationService(policyService);
sut.approve(1L);
UnderwriteApplication uw = getUnderwriteApplicationFromDB(1L);
assertEquals("2", uw.getStatus());
Policy policy = getPolicyFromDB(1L);
assertEquals(today(), policy.getUnderwriteDate());
}
这种测试的好处是,会连带着测试SQL语句和存储过程,覆盖遗留系统中大多数的业务逻辑。我们在第八节课讲过,要编写这样的数据库集成测试,需要搭建一些基础设施,包括远端的数据库镜像,以及可以从其他环境快速拉取数据的工具。
数据对比
然而,像上面这样只验证数据库中的部分数据(核保申请的状态、保单的核保日期),在遗留系统中可能还不够。
因为遗留系统的数据操作往往十分繁琐,表面上看,我们只是修改了核保申请和保单两张表,但实际上在存储过程中可能涉及了几十张表的修改。要想在每个测试场景中都找出相关的表和修改的字段,对这些字段的值一一对比,工作量十分巨大。
这时你可以考虑直接对比数据库中的数据。比如在开关关闭状态下运行测试,得到当前的数据库快照,接着打开开关,再次运行测试并记录快照,然后比较这两种状态下的数据快照是否完全一致。只有数据库完全一致,才能100%证明重构的正确性。
但是这样全量的数据对比可能会十分耗时,你可以对它进行优化。因为我们的测试其实是白盒的,你可以通过活文档工具快速了解API所涉及的表,然后只去比较这些表的数据。你还可以给出这些表中的主键值,只针对部分行数据做比较,这样能进一步提升执行速度。
但你也会发现,要想提升测试的执行速度,就必须提供更多的数据,而这就会带来额外的工作量。你可以针对你的系统情况,找出一个平衡点。
我的前同事吴雪峰开源了一个针对Oracle的数据库对比工具,感兴趣的同学可以研究一下。
动态开关工具
其实,手写一个开关判断逻辑是很简单的。但除此之外,你还可以选择使用工具。
在动态开关工具中,最流行的恐怕就是Togglz了,它不但提供了多种配置方式,更是允许只匹配指定的用户,这就为灰度发布提供了可能。
最近几年,Feature Toggle as a Service开始流行起来。它们大多数都提供了多语言的支持,并包含友好的用户界面。你可以基于这些服务,很好地管理特性开关。这些服务包括ConfigCat、Flagr、Flagger等。
发布到生产环境
前面我们解决了本地和测试环境的验证问题,当功能测试完成后,就可以发布到生产环境了。这时候为了将发布风险降低到最小,你可以使用蓝绿部署、灰度发布等高频发布技术,缩小发布影响的范围。
如果你的遗留系统还没有这些基础设施,也不必担心,你可以在开关上做一些手脚,仅对配置的用户才生效。比如将测试用户的ID硬编码到开关判断的逻辑中,或者配置在数据库或配置文件里。只有当session中的用户信息和配置的信息匹配时,才将请求转发给核保服务。或者,你也可以直接使用上面提到的Togglz。
这样,你就可以仅对这些测试账号打开开关,由测试人员在生产环境再测试一遍,对产生的数据变化进行对比。测试通过后,再逐步放开用户。由于新旧服务两边都在双写数据,所以你可以放心地控制开关状态。
还有一个可能会影响验证方案的因素,是系统目前的部署状态。比如银行、保险的业务系统,最早可能是分区域部署的,每个省份或地区都会部署相同的、但彼此独立的应用和数据库。这对于跨区域业务来说可能不太友好,但对于遗留系统现代化来说,却歪打正着,是个利好消息。在改造完成后,你可以找一个用户比较少,流量比较少的区域进行验证,以降低风险。
假设验证
当所有API的功能都在生产环境验证成功后,下一步要做的就是验证我们最初的假设是否成立。
在第二十节课我说过,之所以选择核保模块的微服务拆分作为遗留系统现代化试点,是因为业务方更关注核保模块的业务响应力。这个假设可以分解为两个指标,即需求交付前置时间(lead time)和需求吞吐量。
那么我们就有两方面的数据需要收集并对比:
1.服务拆分前后,一个需求从开发接手到上线的时间。
2.服务拆分前后,每个交付周期内可以完成的需求总数。
在收集数据时一定要注意,需求有大有小,有难有易,因此不同的需求之间是很难直接对比的。以前在遗留系统中,对于需求的估算可能更多是靠经验。而现在,你可以参考很多科学的估算方法。比如T-Shirt Size估算法,将需求按大小分为S、M、L、XL等级别,以方便排期。
在度量时,你可以给不同size的需求设置权重,来进行统计。比如一个交付周期内的需求吞吐量可以这么计算:假设S、M、L、XL的权重分别为1、2、3、5(斐波那契数列),将每个需求转换成各自对应的权重(用w表示),并求和。用公式表示就是:
\\sum\_{1}^{n}{w}而需求的交付前置时间可以用单个需求的前置时间除以权重,得到单位权重的前置时间。再将多个需求累加,以排除干扰因素。用公式表示就是:
\\sum\_{1}^{n}{\\frac{t\_{n}}{w}}如果团队使用交付火车这样的交付方式,有着固定交付周期,那么我们也可以用开发前置时间(即需求从开始开发到开发完成的时间)来代替。
在统计数据时,不要忘了将它们可视化出来,比如用下面这种折线图来展示核保服务上线前后的需求吞吐量和前置时间。
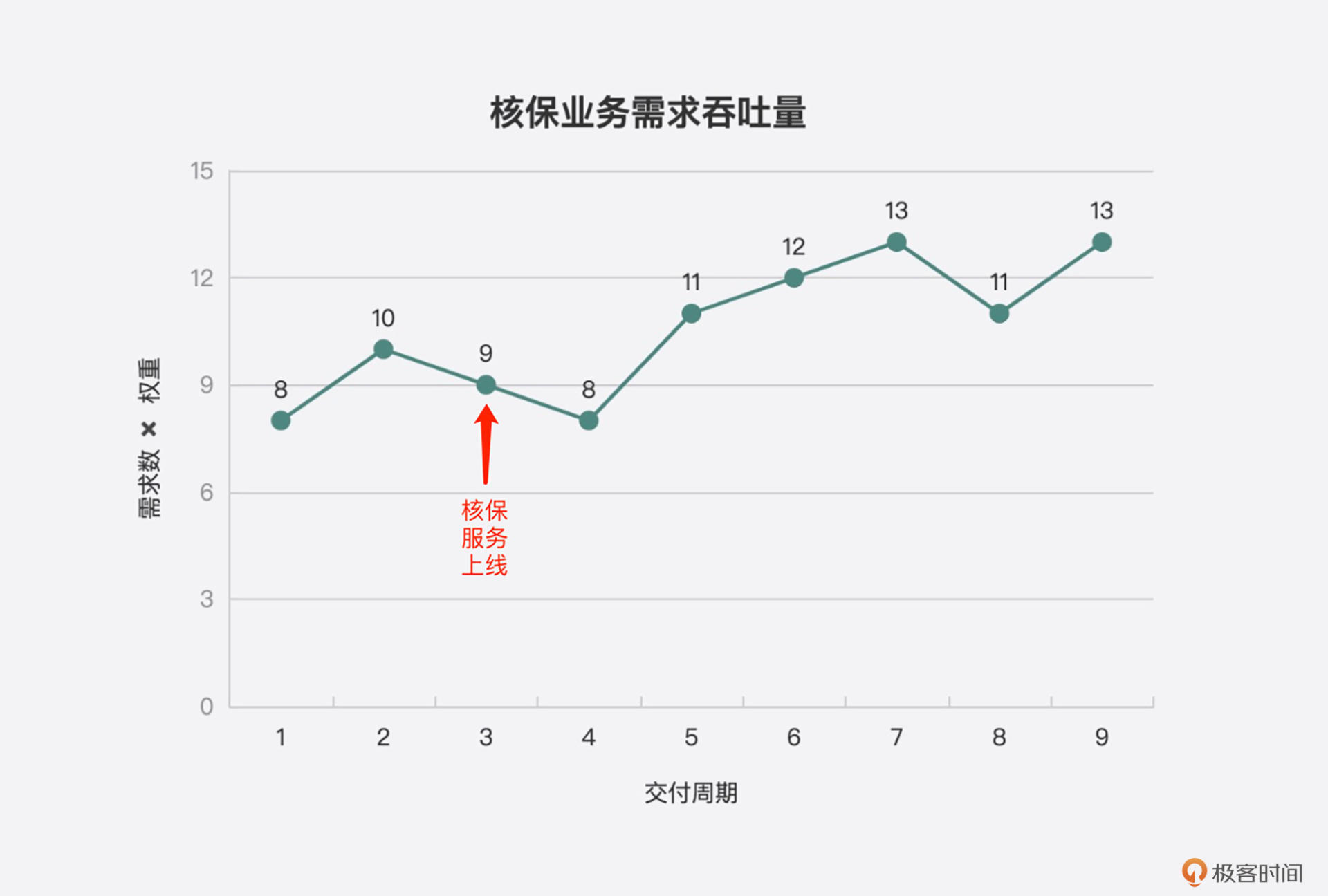
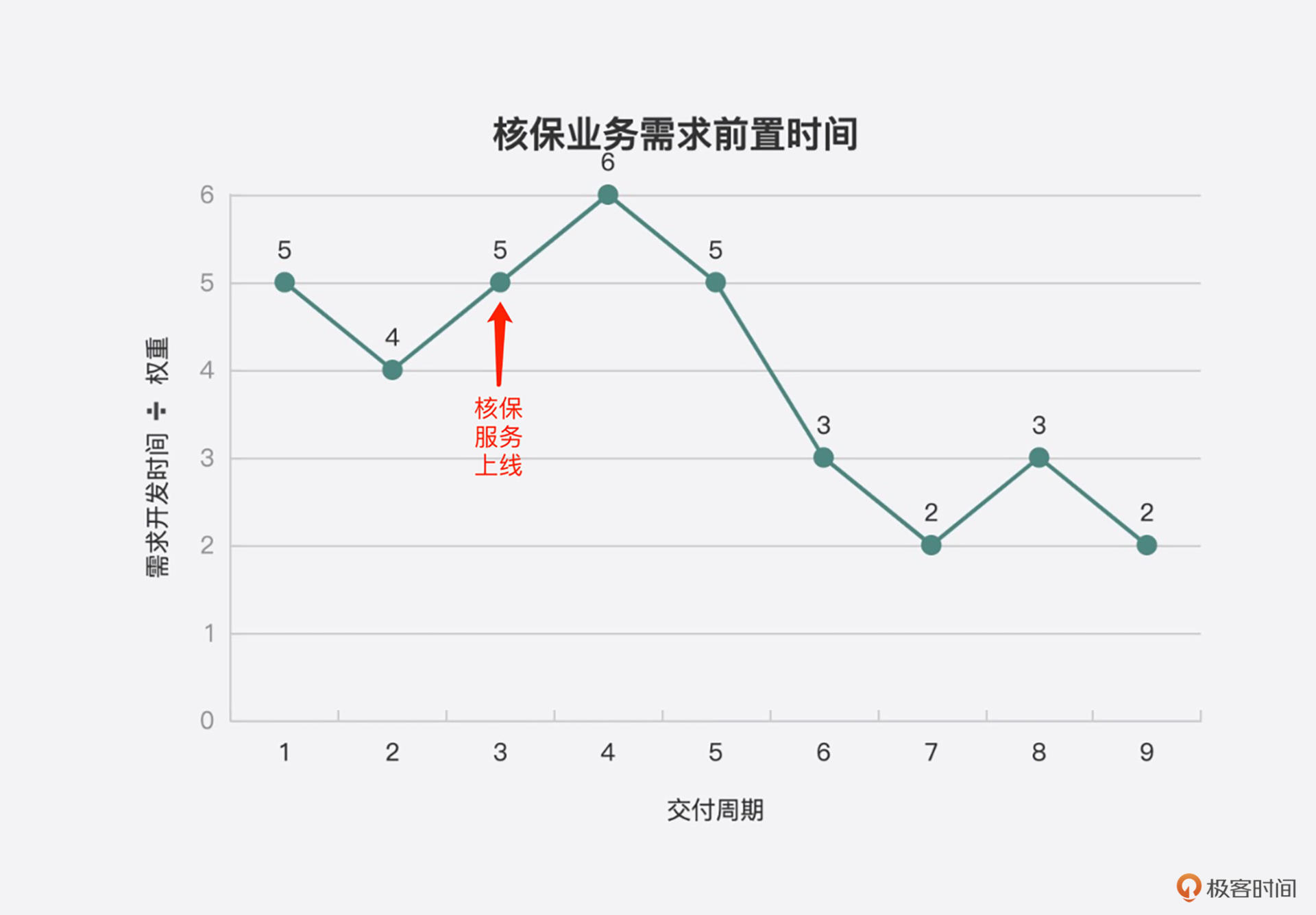
注意,在服务刚上线时,数据可能会变糟,因为可能要修复一些Bug,团队也可能对这种开发方式不太适应。但随着时间变长,因新服务上线造成的Bug越来越少,团队也越来越适应,所有的数据都会慢慢向好的方向发展。
你可以用大屏幕轮播这些图表,或者打印出来贴在墙上。团队成员看到这样的图表会感到自己的努力得到了成效;而业务人员也会很开心,因为他们的投资得到了回报。
小结
又到了总结的时候。今天这节课是我们实战篇的最后一节,我们聊了聊在上线前后如何验证功能,以及在正式交付后如何验证我们最初的假设。
我总结了一幅图,可以帮你加深对这节课的理解。
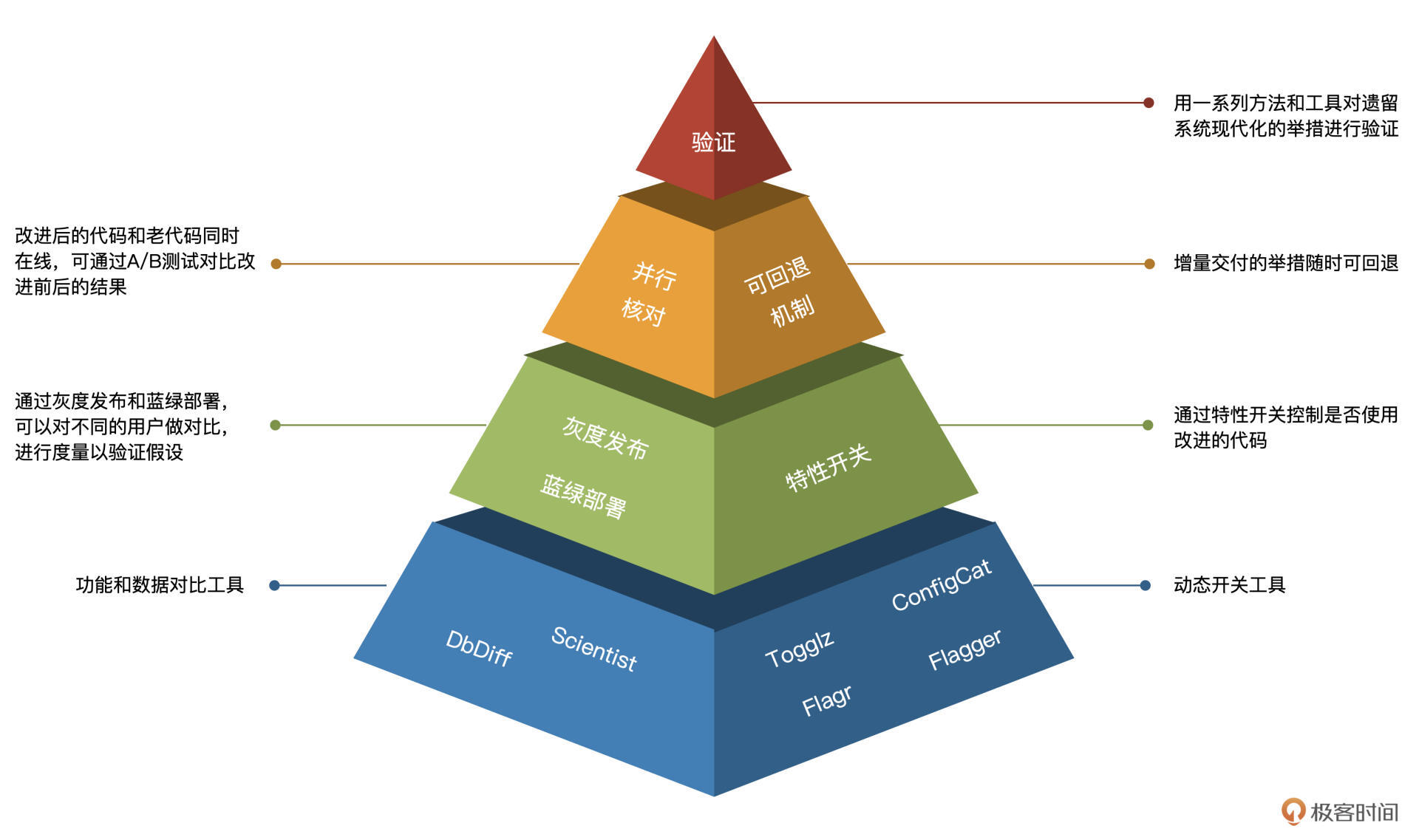
有效的成果验证既能鼓舞团队士气,又能让领导和业务方感受到改造的价值,还能为你后续的改造安排打下良好的试点基础和团队实力。
遗留系统现代化长路漫漫,千万不要因为这些比较容易做却没有做的小事儿,而半途而废啊。
到此为止,我们的遗留系统微服务拆分案例的讲解就告一段落了。你可能感觉自己的项目概况与我所介绍的案例相差甚远,很多实战经验用不上。这其实是很正常的。
实践经验,只是理论知识在落地过程中的“本地化”。任何一套经验,都有它的适用范围,并不是普天下皆准的真理。
在拆分案例讲解中,我力求把分析过程和选型经验融入其中,就是为了让你适应这种现代化理论落地到实践的思维转换。你要做的,是熟练掌握模式篇所介绍的那些模式,并以遗留系统现代化的三大原则作为指导,去完成四个现代化方向上的各种工作。
思考题
感谢你学完了今天的内容,今天的思考题是,你的项目是否做过遗留系统改造的成果度量?如果有的话,能否分享一下你们的经验?
期待你的分享,如果你觉得这节课对你有帮助,别忘了分享给你的同事和朋友,我们一起来检验遗留系统的现代化成果吧。