|
|
# 11 | 架构现代化 :在气泡上下文中打造你的新城区
|
|
|
|
|
|
你好,我是姚琪琳。
|
|
|
|
|
|
前面三节课,我们学习了代码现代化的多种模式。从这节课开始,我们继续学习如何实现架构现代化。
|
|
|
|
|
|
需要说明的是,这四个现代化并不是层层递进的关系,而是既可以同时进行,也可以颠倒顺序。
|
|
|
|
|
|
比如,你既可以先重构代码,再拆分架构,也可以先拆分架构,再重构代码。同时,也可以重组团队结构,专门拉出一个平台团队去搭建DevOps平台。
|
|
|
|
|
|
我在第二节课和你探讨架构现代化时,曾经用“建设新城区”和“改造老城区”做了一个类比,今天我们就来详细讲讲在“建设新城区”时,都有哪些模式。
|
|
|
|
|
|
## 绞杀植物模式
|
|
|
|
|
|
我选择把绞杀植物模式作为架构现代化的第一个模式,因为它的思想影响了很多其他模式,包括气泡上下文、扩张-收缩、修缮者等等。
|
|
|
|
|
|
[绞杀植物模式](https://martinfowler.com/bliki/StranglerFigApplication.html)**(Strangler Fig)**,这是Martin Fowler在2004年左右提出的,它是一种用新系统替换旧系统的模式。我们在[第七节课](https://time.geekbang.org/column/article/511924)学习的遗留系统现代化的五种策略,其中就有Rebuild/Replace策略,绞杀植物模式就是针对这种策略的。
|
|
|
|
|
|
很多团队在选择了Rebuild/Replace策略后,往往希望一股脑地构建出新的系统或服务,然后直接替换,而忽略了增量演进这个原则。这样做的后果就是,新构建的系统或服务,与原系统有很大差异,甚至根本不可用。
|
|
|
|
|
|
绞杀植物模式描述了绞杀植物是如何工作的。像榕树、无花果树这类绞杀植物,会从宿主植物的头部播种,慢慢向下生长,直到插入土中,长出自己的根。几年甚至几十年过后,这些绞杀植物最终会杀死自己的宿主,占据宿主原来的位置,完成“谋权篡位”。
|
|
|
|
|
|

|
|
|
|
|
|
我们在替换一个软件系统时也是一样,应该在旧系统旁边搭建一个新系统,让它缓慢增长,与旧系统同时存在,逐步地“绞杀”旧系统。这个“逐步”的意思,其实就是**增量演进**。“同时存在”指的是**并行运行**。
|
|
|
|
|
|
我们在[第六节课](https://time.geekbang.org/column/article/510594)我们讲过一个例子,演示如何用绞杀植物模式来增量演进和并行运行,你可以去复习一下。
|
|
|
|
|
|
绞杀植物模式不但可以用来替换旧系统,也可以替换一个服务或模块,或者像我们例子中介绍的那样,用独立的服务来替换单体中的模块。
|
|
|
|
|
|
我的前同事乔梁,在他的著作《持续交付2.0》里总结了这种模式的利弊。它有三个优势:第一,不会遗漏原有需求;第二,可以稳定地提供价值,频繁地交付版本,更好地监控其改造进展。第三,避免“闭门造车”。
|
|
|
|
|
|
劣势主要来自迭代的风险和成本,绞杀的时间跨度会很大,存在一定风险,而且还会产生一定的迭代成本。
|
|
|
|
|
|
总之,绞杀植物模式的这种新旧共存、并行运行、小步快跑、逐步替换的思想,你在之后的很多模式里还会找到相似的影子。
|
|
|
|
|
|
如果拿城市建设来打比方的话,绞杀植物模式就类似于城市迁址。我们在搭建好新址的基础设施(代码库、运行环境、脚手架、配置等)后,就可以把居民(代码)迁移到新址中。但这个过程也应该是逐步进行的,如果一股脑全部搬迁过去,可能就会造成混乱。
|
|
|
|
|
|
就像明成祖迁都北平,建紫禁城建了三年,迁都仅用了几个月,结果诸事不利,差点被儿子迁回南京。倘若一部分一部分地迁移居民,让先去的那些人逐渐处理掉那些混乱,等全部搬过去之后,就会好很多吧。
|
|
|
|
|
|
## 气泡上下文
|
|
|
|
|
|
逐步替换的下一招就是气泡上下文,我还是先和你聊聊它从何而来。
|
|
|
|
|
|
领域驱动设计的创造者Eric Evans在2013年发表了[一篇文章](https://www.domainlanguage.com/wp-content/uploads/2016/04/GettingStartedWithDDDWhenSurroundedByLegacySystemsV1.pdf),介绍了如何在遗留系统中应用DDD。
|
|
|
|
|
|
多年来,在落地DDD战术设计的时候,人们往往倾向于选择一个“干净”的**限界上下文(Bounded Context)**。然而在遗留系统中,这种“干净”的上下文可遇不可求,这就导致在遗留系统中应用DDD十分困难。人们只能在Rebuild/Replace的时候,在新的系统中应用DDD战术设计。
|
|
|
|
|
|
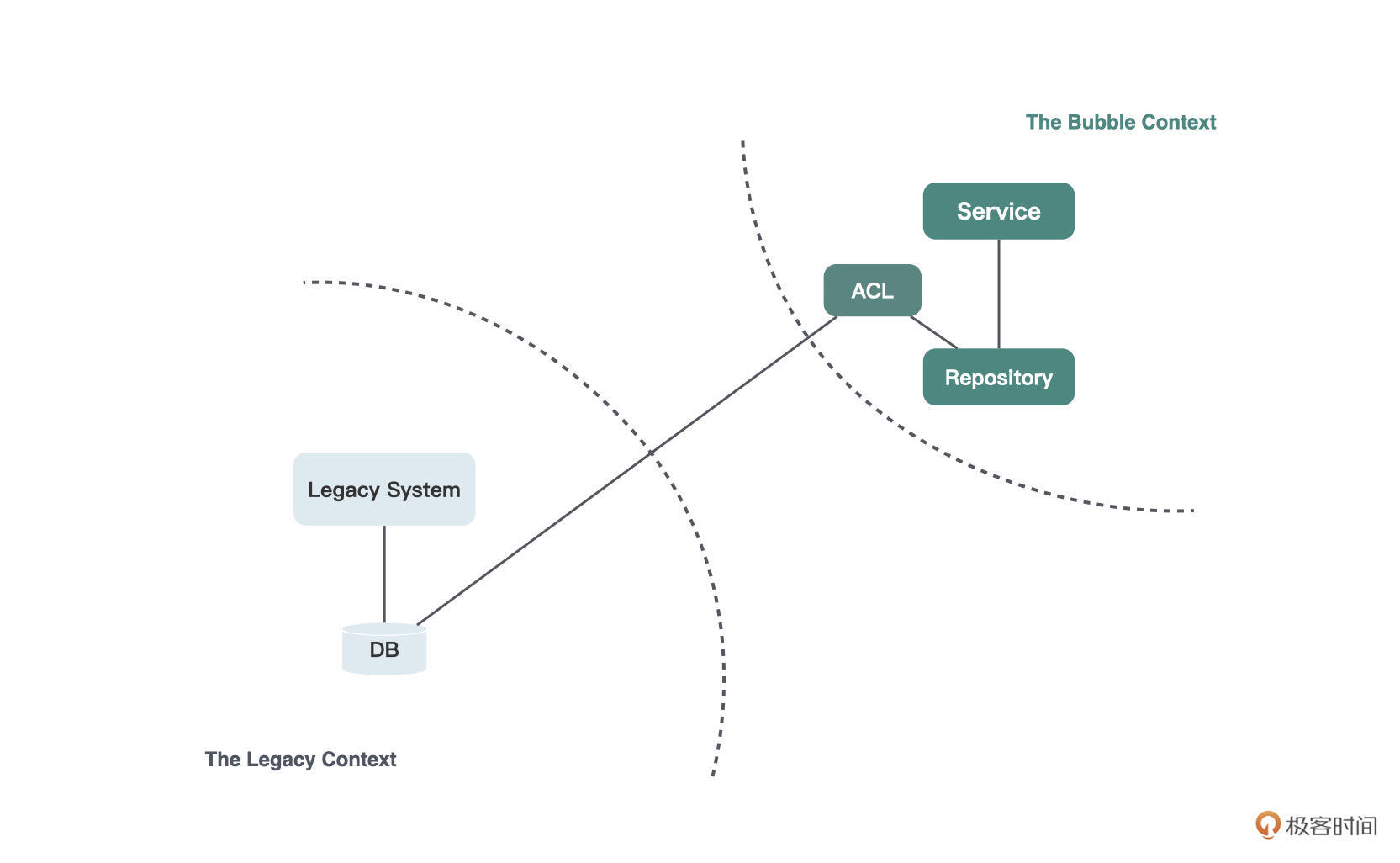
为了能够在遗留系统中使用DDD,Eric在文章中提出了四种模式,其中第一种就是**气泡上下文(Bubble Context)模式**。这里的气泡,指的是用**防腐层(Anticorruption Layer)**隔离开的一个小的**限界上下文**,这个上下文用于特殊的开发目的,并且不打算长期使用。它就像是一个悬浮在遗留系统之上的气泡一样,十分“干净”,却一捅就破。
|
|
|
|
|
|
什么是防腐层呢?它是Eric在《领域驱动设计》一书中提出的模式,顾名思义是为了隔离不同上下文之间模型不匹配的问题,避免一个上下文中的模型渗透到另一个上下文中。
|
|
|
|
|
|
当你遇到一个新的需求时,可以评估这个需求,如果它适合的话,可以不在遗留系统中开发这个需求,而是将它放到气泡上下文中,在一个全新的环境内开发这个需求。由于防腐层隔离了遗留系统,因此你可以在气泡中相对自由地进行领域建模,而不必受到遗留系统的限制。
|
|
|
|
|
|
|
|
|
|
|
|
然而,Eric的气泡上下文是没有自己的数据库的,只能访问遗留系统中的数据库。为此,它提出了**基于防腐层的仓库(ACL-backed Repository)模式**,即在仓库中调用防腐层,由防腐层去直接访问遗留系统数据库。
|
|
|
|
|
|
我们上节课学过,仓库模式用起来就像是内存中的集合,所以会让人觉得,气泡上下文中真的有自己的数据一样。这样一来,气泡上下文中的开发者就可以专注于业务逻辑开发,而不必关心数据从哪儿来,大大降低了认知负载。
|
|
|
|
|
|
当然,如果你不想让领域层中的仓库依赖防腐层,就可以将仓库的接口定义在领域层,将仓库的实现类定义在防腐层,以实现依赖倒置。
|
|
|
|
|
|
就像一些新企业建厂办公(DDD落地),老城区的空间不够或者条件不适合。那么就会建立一个新城区(气泡上下文),按照更适合这些企业需求的方式规划和布局(应用DDD的各种战术模式)。当新城区需要供电供水供暖(数据)时,就拉一条新的管线(基于防腐层的仓库)从老城区来获取这些资源。
|
|
|
|
|
|
## 自治气泡
|
|
|
|
|
|
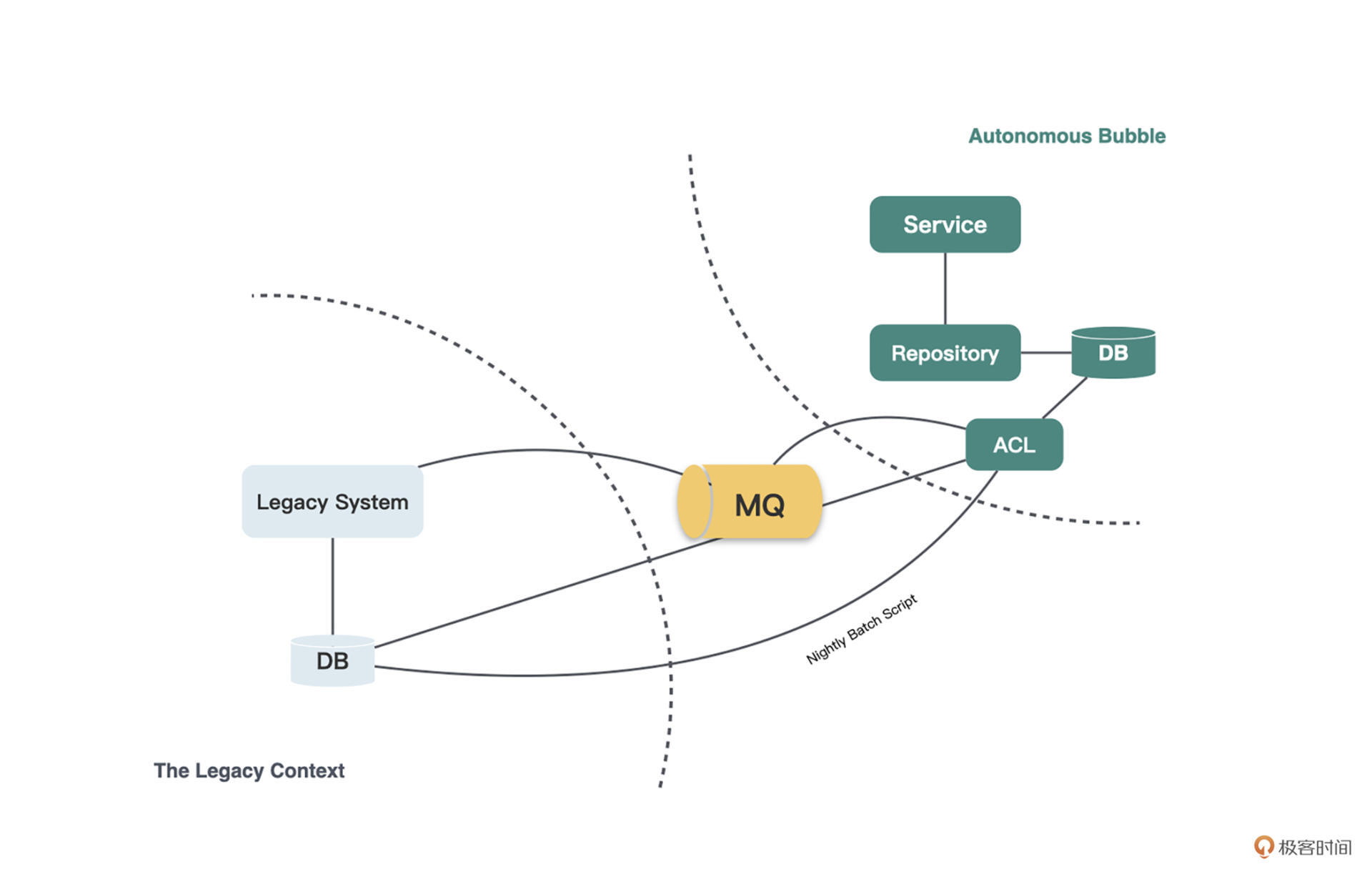
显然,这样的方式是不可能长久的。新需求中必然有需要建新表的时候,如果仍然建立在遗留系统中,就会让遗留系统更加混乱。就像新城区的人多了,却还要跑到老城区的医院和学校去,这就太麻烦了。因此,Eric提出了第二种模式:**自治气泡(Autonomous Bubble)**。
|
|
|
|
|
|
顾名思义,自治气泡就是**能够自治的气泡,它有自己的数据库,与遗留系统是弱耦合的**。它不再直接访问遗留系统的数据和服务,而是通过**同步防腐层(Synchronizing ACL)**,将遗留系统中的数据同步到自治气泡中。同步的方式可以是轻量级的每日同步脚本,也可以是消息或领域事件。
|
|
|
|
|
|
|
|
|
|
|
|
这就像是新城区中建好了水电气厂,也建好了医院、学校等其他基础设施(数据库),但是工厂的员工、医院的医生、学校的老师(数据)仍然住在老城区,他们需要每天辛苦地通勤到新城区工作(同步数据)。
|
|
|
|
|
|
你会发现,这种自治气泡非常接近于微服务架构中的一个服务,都有独立的数据库,能够独立演进,与其他服务通过事件等机制进行弱耦合地通信。只不过在微服务架构中,还可以通过API来访问其他服务。而在原始的自治气泡模式中,是彻底隔断了API调用这种方式的。
|
|
|
|
|
|
### 变动数据捕获
|
|
|
|
|
|
要想在自治气泡中同步数据,Eric给出的原始方案是用定期脚本或领域事件。其实还有一种方式是**变动数据捕获(Change Data Capture)模式**,简称CDC。它能识别和跟踪数据库中的数据变动,并捕获这种变动,完成一系列后续处理,比如:将变动内容发布到一个事件总线中,再由气泡上下文去消费这个事件,从而同步数据;或者干脆直接连接其他数据库进行同步。
|
|
|
|
|
|
一般来说,有两种捕获变动数据的方法。
|
|
|
|
|
|
一种是使用**数据库触发器**。大多数关系型数据库都支持触发器,尤其是Oracle这类数据库,还能在触发器中调用外部服务,做起同步来尤其简单。
|
|
|
|
|
|
但我要提醒你,使用触发器一定要慎重,如果一个系统有一两个触发器还不算大问题,但有些系统(尤其是遗留系统)就是构建在大量的触发器之上的。这简直就是灾难,因为它们很难管理,你根本不知道一个数据变化会触发哪些行为,以至于无法搞清楚系统是如何工作的。基于大量数据库触发器的系统,认知负载太高了。
|
|
|
|
|
|
另一种捕获数据的方式是使用一个单独的工具,来**轮询数据库的事务日志**。由于日志本身包含了数据的变动,你根本不需要去解析。工具本身也运行在单独的进程中,也不用担心和数据库产生耦合和竞争。轮询事务日志的做法,可以称得上是最整洁的CDC方案。
|
|
|
|
|
|
在将单体应用拆分为微服务的时候,CDC是一个经常会使用到的模式。但在微服务架构下,它就有点不合时宜了。因为它把服务内部的数据泄露到了事件总线中,破坏了封装。更好的方式还是应该让服务来发布领域事件(Domain Event)到事件总线中,其他服务来消费领域事件,而不是变动的数据。比如一个订单开始配送了,应该由物流服务发布一个“订单已配送”事件,而不是由CDC来发布一个订单表中,一行数据的变化情况。
|
|
|
|
|
|
### 事件拦截
|
|
|
|
|
|
如果你的遗留系统是**事件驱动的架构(Event-Driven Architecture)**,那么恭喜你,你的自治气泡上下文甚至整个架构现代化的工作都轻松了不少。你可以使用**事件拦截(Event Interception)模式**来取代CDC,实现气泡中的数据同步。
|
|
|
|
|
|
Martin Fowler早在2004年就[提出了这种模式](https://www.martinfowler.com/bliki/EventInterception.html),作为构建绞杀植物应用的一种落地方案。你可以拦截一些系统中已有的事件,为它们编写新的监听程序,来进行数据的同步或开始连带的业务处理。必要的时候也可以在遗留系统中补充一些缺失的事件。
|
|
|
|
|
|
### 遗留系统封装API
|
|
|
|
|
|
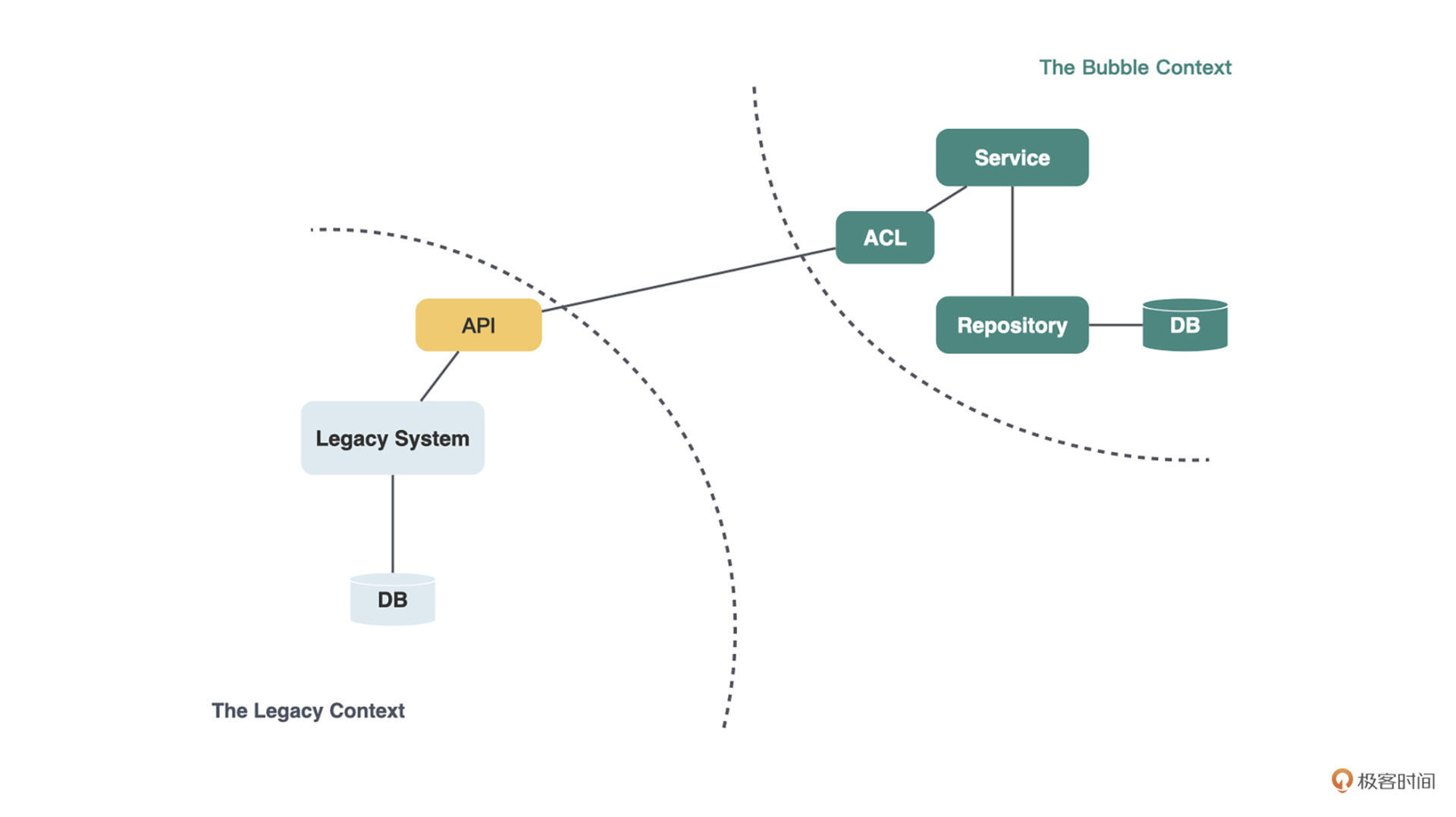
无论是在气泡上下文中使用基于防腐层的仓库,还是在自治气泡中使用同步防腐层,其实都很别扭。如果你的遗留系统是一个Web系统,可以方便地添加API,最简洁的方式是**将遗留系统封装为若干个API**,对外提供业务能力,供各个气泡上下文访问。
|
|
|
|
|
|
但你仍然需要在气泡上下文中提供一个防腐层,只不过这个防腐层不再直连遗留系统的数据库,而是去访问遗留系统封装的API。
|
|
|
|
|
|
|
|
|
|
|
|
在封装API时,强烈建议你新写API,不要复用那些老的API。一方面老API是为特定的页面而编写的,很难被其他气泡复用。另一方面,即使能复用,老页面与气泡的需求变化方向和速率也是不同的,很可能出现为了满足老页面的需求变化而改了API,结果气泡上下文中的功能被破坏了。
|
|
|
|
|
|
如果你的遗留系统不是基于Web的,就会稍微麻烦一些了。如果还想应用这种模式,可以新建立一个服务,直连遗留系统数据库,对外提供各种API。但这会造成大量的代码和业务的重复,你需要仔细斟酌。
|
|
|
|
|
|
在应用了**遗留系统封装API模式**后,自治气泡就更像是一个微服务了。它有自己的数据库,对于依赖的数据通过API来访问。当然如果遗留系统本身是基于事件的,你还可以充分利用事件机制,来实现服务之间的松耦合。
|
|
|
|
|
|
这就像是新城区建设得差不多了,有了自己的水电气厂和医院学校,甚至连工人医生和老师(数据)都住在新城区了(独立的数据库),但对于某些特殊场景,如高端的商场、电影院等,你仍然需要时不时去一趟老城区(调用API)。
|
|
|
|
|
|
## 小结
|
|
|
|
|
|
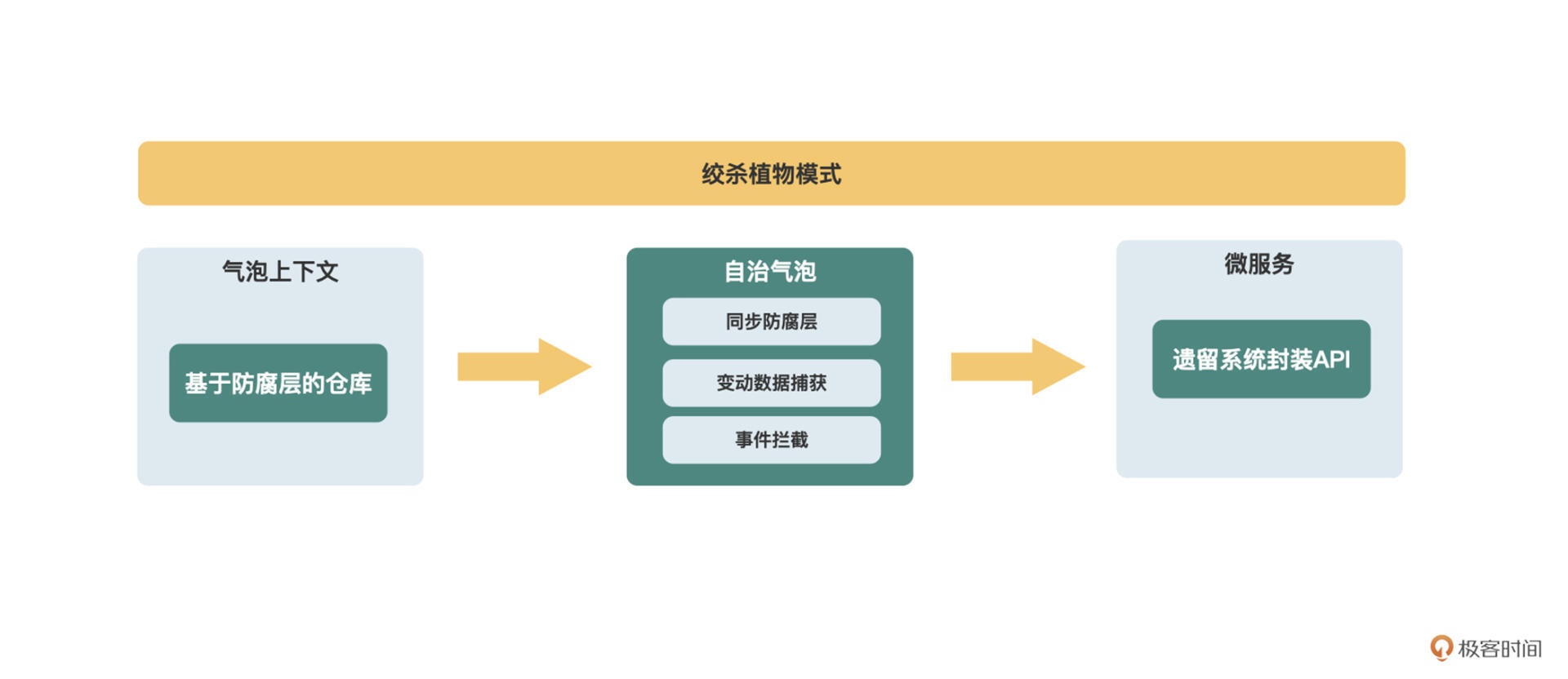
总结一下今天的内容。我们从Martin Fowler“灵光一现”发明的绞杀植物模式出发,接着学习了Eric Evans发明的气泡上下文和自治气泡模式,以及在气泡中可以使用的数据同步和访问方式,包括变动数据捕获、事件拦截和遗留系统封装API。
|
|
|
|
|
|
|
|
|
|
|
|
从气泡上下文,到自治气泡,再到微服务,这其实描述了一个新需求落地成微服务的演进路线。一步到位地去开发一个微服务,认知负载偏高,而且你可能也并不需要。我们按需演进地去开发,认知负载就会低得多,也更容易得到一个刚刚好的架构。
|
|
|
|
|
|
有很多新需求都可以通过气泡上下文来构建,比如报表、问卷、评分等。在着手开发类似这样的需求前,作为架构师,你应该思考一下:是否仍然在遗留系统中进行开发,是否可以新建一个服务来开发。
|
|
|
|
|
|
这样可以和遗留系统划清界限、保持隔离。新的服务可以更好地规划和设计,遗留系统也没有变得更糟。这有点类似我们在代码现代化中介绍的新生和外覆方法,它们自己是可测的,同时也没有影响到旧方法。
|
|
|
|
|
|
气泡上下文一开始可能不需要自己的数据库,只需要从遗留系统中获取数据即可。慢慢地随着需求的迭代,开始有了自己的数据,就可以用自治气泡的方式让它拥有自己的数据库,并通过变动数据捕获或事件拦截的方式来同步遗留系统中的数据,或通过API来访问遗留系统的功能。
|
|
|
|
|
|
我曾经在项目中使用过很多次气泡上下文模式,当时并不知道这是一种模式,只是想把这种看似与遗留系统不太相干的需求放在外面,不要再和遗留系统纠缠在一起了。没想到用起来效果还真的挺不错。
|
|
|
|
|
|
无论是绞杀植物还是气泡,以及之前课程里提到的接缝、工厂、仓库,包括新老城区建设等等,其实都是一种隐喻。隐喻不但有助于我们理解概念,还能激发我们在看似不相关的场景中,发现相似点的这种概念性思维(Conceptual Thinking)。
|
|
|
|
|
|
最后请允许我感叹一句,像Martin Fowler这种看到绞杀植物绞杀了宿主的现象,从而联想到遗留系统也应该以这样的方式进行替换,真的是把概念性思维发挥到了极致啊。
|
|
|
|
|
|
[下一节课](https://time.geekbang.org/column/article/515274),我们继续新城区的建设,来学习如何从一个遗留系统的大泥球单体架构,一步步演进到微服务。
|
|
|
|
|
|
## 思考题
|
|
|
|
|
|
感谢你学完了今天的内容,今天的作业请你分享一下,你的项目中是否有意无意使用过气泡上下文来开发新的需求呢?如果有,你们如何处理数据问题呢?
|
|
|
|
|
|
期待你的分享。 如果你觉得这节课对你有帮助,别忘了分享给你的同事和朋友,我们一起打造新城区。
|
|
|
|