127 lines
16 KiB
Markdown
127 lines
16 KiB
Markdown
# 03|以降低认知负载为前提:为什么遗留系统这么难搞?
|
||
|
||
你好,我是姚琪琳。
|
||
|
||
前两节课,我们分别介绍了为什么要对遗留系统进行现代化,以及遗留系统现代化的四个方向和三个原则。从这节课开始,我们将逐一讲解这三个原则。今天先来看看第一个原则:以降低认知负载为前提。
|
||
|
||
你可能会问,认知负载对改造遗留系统有什么帮助呢?别着急,学完这节课的内容,你自然就明白了。
|
||
|
||
## 怎样理解认知负载?
|
||
|
||
作为开发人员,不管是不是工作在遗留系统上,我想你都一定面临过来自业务方或项目经理的灵魂拷问:为什么这个需求这么简单,不过是多一项在下拉菜单,你们却开发这么长时间,要我做绝对不超过半天!言语中透露出一丝对于你工作能力的质疑,或是上班摸鱼的揣度。
|
||
|
||
然而实际情况真的如此吗?你恨不得翻出代码逐行展示给他看。来来来,你以为只是下拉框多了一项,实际上前后端都要加上;后端还要改五个服务,有两个我本地从未部署;搭环境调服务就用了一天,改代码修bug又是两天半;别问我为什么修了两天bug,因为实际上服务要改六个;我已经连续加班三个晚上,你要觉得你行下次你上……
|
||
|
||
玩笑归玩笑,但类似的battle我相信每个同学都经历过。你在面对这样的质疑时,内心肯定是很委屈的。但是你是否思考过这里面的真正原因?
|
||
|
||
你可能会说,是架构不合理,新增一个下拉项要改五六个服务;是DevOps工具不好用或根本没有,在本地部署新服务搭环境要很长时间;是系统知识严重缺失,不知道要改哪些地方以至于漏掉了一个服务……
|
||
|
||
虽然这些问题确实增加了工作难度,但是对于项目上的老人不是这样啊,他们改起来仍然游刃有余,没部署过的服务也能轻松调通。你可能会辩驳,这是系统太复杂,对新人不友好,而老人都已经熟悉了。
|
||
|
||
是的,没错,你说对了。但这里面有个更专业的术语,叫做认知负载。认知负载(Cognitive Load)是认知心理学家John Sweller在上世纪80年代所创建的理论,是指从事一件工作所要使用的脑力劳动的总和。简单来说,就是你可以用认知负载衡量你牺牲了多少脑细胞。
|
||
|
||
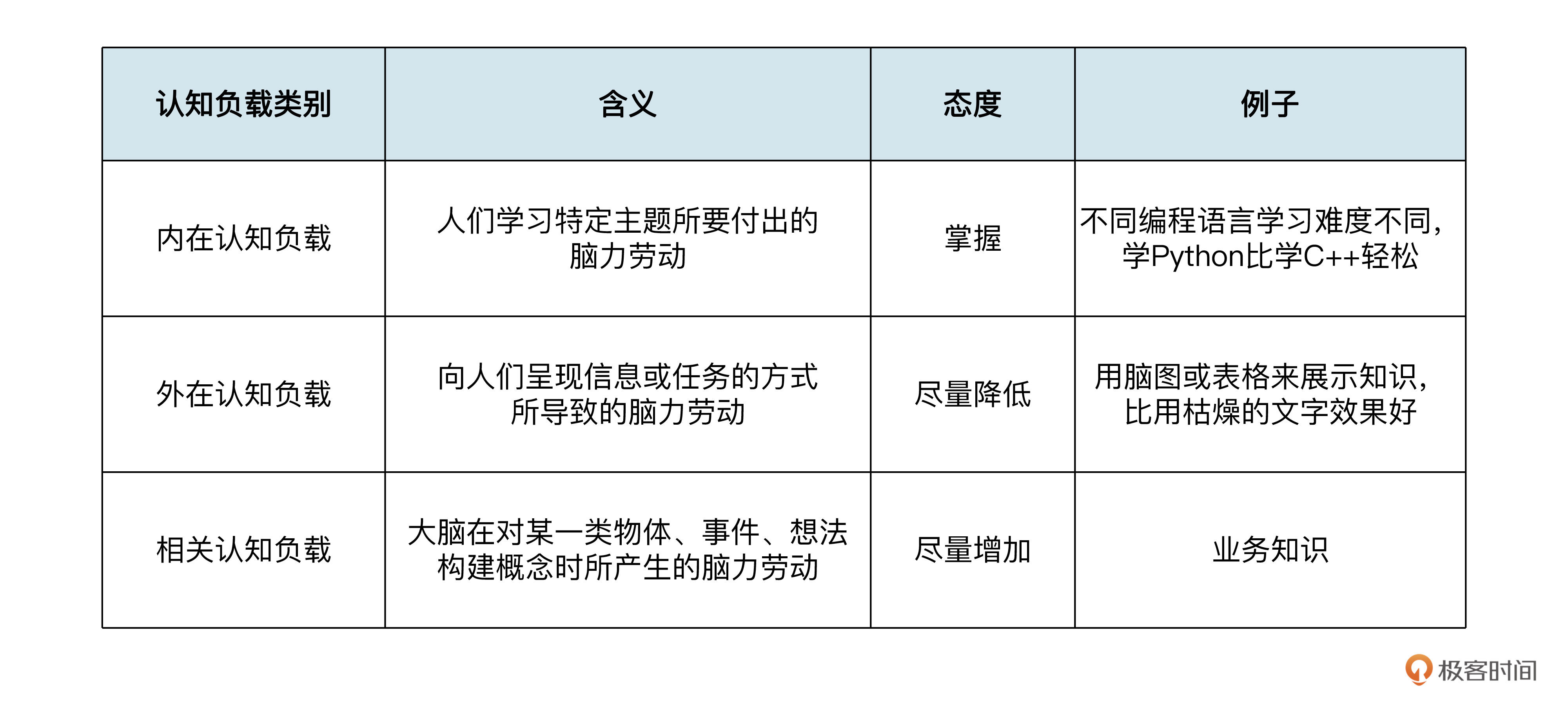
认知负载一共分为三种类型,内在认知负载、外在认知负载和相关认知负载。对于它们的定义和对比,我汇总了一张表。
|
||
|
||
|
||
|
||
从表中我们可以看到,内在认知负载是你掌握一门技能所必须要付出的努力,虽然不同的技能难度不同,但只要选择了一个,它的大小就固定了,掌握得不够必然就无法胜任工作。外在认知负载是信息的呈现方式,是我们着重要降低的,信息的呈现自然应该越简单越好。而相关认知负载是在构建概念时要了解的知识,是要尽可能增加的,因为这些知识越多越有利于我们的工作。
|
||
|
||
也就是说,**我们要完成一项工作,就要在内在认知负载一定的前提下,尽量减少外在认知负载,增加相关认知负载**。以软件开发为例,要完成这项工作,就要在掌握开发技能的前提下,尽量简化与开发需求本身无关的细节,而去了解尽可能多的业务知识。
|
||
|
||
看到这里,你就能充分理解为啥架构不合理、DevOps工具不好用以及系统知识匮乏,都会导致你改个“芝麻大”的需求都要加班加点,没错,罪魁祸首就是外在认知负载。
|
||
|
||
结合前面的例子,我们逐一分析:一个小需求都要改很多地方,说明模块划分时,可能一起发生变化的部分没有内聚在一起,而是分离到了不同模块和层级,架构向开发者呈现系统的方式过于复杂,增加了外在认知负载;DevOps工具不好用,意味着工具向开发者呈现的部署任务方式太复杂;同理,没人能把一个需求要改哪些地方都说清楚,说明系统知识早已藏身代码深处,不陪葬一把头发深入研究代码,别想拿到这些知识。
|
||
|
||
而项目里的“老人们”早已经消化掉了这些外在认知负载。我相信他们在刚加入项目时,也一定经历过你的这些崩溃时刻。
|
||
|
||
还有一点就是,有些时候一些知识或实践,看上去在当下增加了外在认知负载,但实际上长远来看,是可以大大降低外在认知负载的。
|
||
|
||
比如测试驱动开发,一开始上手的时候,绝大多数开发人员可能都不会写代码了,软件开发的外在认知负载一下子大了很多。但如果你把它当做一项技能(也就是内在认知负载)去不断学习、刻意练习的话,熟能生巧之后,就会大大降低写代码的整体认知负载,而且还提升了软件的质量(因为有很多自动化测试),降低了业务知识获取的难度(测试可以看成是有效的文档)。
|
||
|
||
## 遗留系统中的认知负载
|
||
|
||
那么遗留系统中的外在认知负载都有哪些呢?第一节课我们介绍过遗留系统的特点,代码质量差、架构不合理、测试不充分、DevOps水平低,其实都会导致外在认知负载增加。
|
||
|
||
**不过,遗留系统最大的认知负载其实是无处可寻的业务知识。**我们第一节课介绍过,遗留系统中的蕴含着丰富的业务资产,但由于种种原因,导致这个资产并不那么容易获得。
|
||
|
||
遗留系统在构建的时候,往往会有成百上千页的需求、设计文档,这些的确能准确描述当时的系统状态。然而随着时间的更迭、需求的演化,当前的系统已经和构建时不可同日而语,且不同阶段的文档往往无法很好地保留下来,这就造成了业务知识的缺失。
|
||
|
||
即使所有文档都保存完好,也很难有人能完完整整地阅读下来。而且,也没有人能保证系统的实现和文档的描述是完全吻合的。
|
||
|
||
你可能会问,不是还有人吗?去问问需求人员或者业务分析人员啊。遗憾的是,对于时间不太长的遗留系统,也许还能找到人,但稍长一点的,可能人影都找不到了。有的离职了,有的升职了,有的可能是第三方供应商开发的,现在已经不合作了。即使有些知识可以在开发人员之间口口相传下来,但是也是严重失真的,没人能确保它的正确性。
|
||
|
||
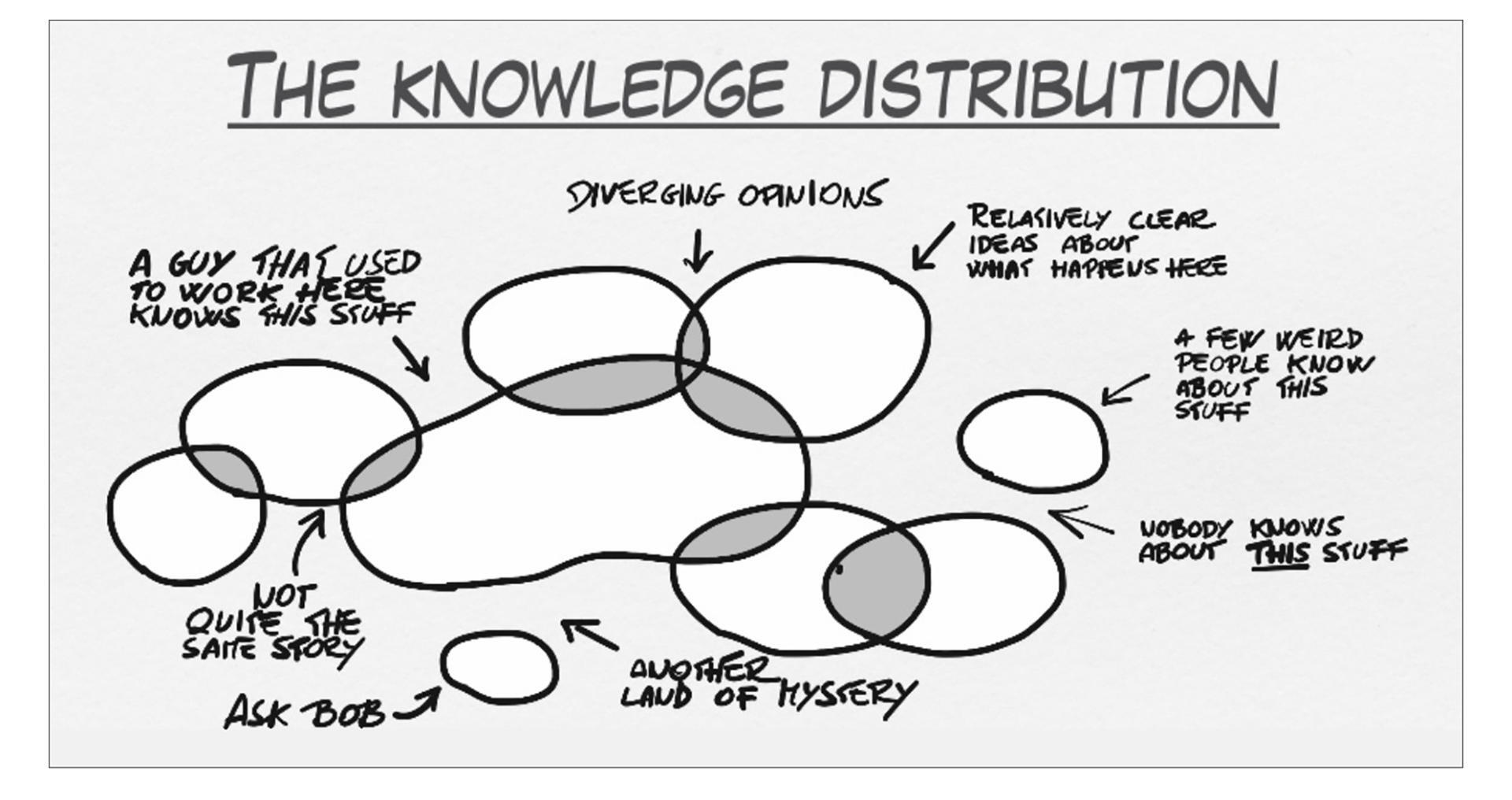
下图是事件风暴的发明者Alberto Brandolini在讲述知识的分布时用到的图,我想它也同样适合描述知识传递过程。结合图片可以看到,有些知识只有曾经工作在它上面的某一个人知道,有些知识得去问Bob,而有些知识就像一个谜。
|
||
|
||
|
||
|
||
如果系统中包含自动化测试,尤其是那种描述一个端到端业务的自动化测试,某种意义上是可以被看作有效文档的。但对于遗留系统来说,这样的测试太罕见了,不提也罢。
|
||
|
||
很明显,想通过历史文档、咨询相关者,以及自动化测试等手段理清业务,都不靠谱。其实,要想捋清一个遗留系统的业务,唯一有效的方式就是“扒代码”。
|
||
|
||
把代码掰开揉碎了仔细阅读,弄清楚每一行的意图,直到搞清楚这一块代码所要表达的业务逻辑。但这种方法同时又是非常低效的,因为遗留系统的代码质量往往惨不忍睹,想靠人工的方式来梳理代码理清业务,是几乎不可能完成的任务。
|
||
|
||
经过这一番描述,你应该弄清楚了遗留系统中业务知识难以获取的原因。因为它们是以“质量很差的代码”这种形式向人呈现出来的,因此有着非常高的外在认知负载。
|
||
|
||
这里你可能会有疑问,前面不是还说业务知识是相关认知负载,需要增加吗?这里为什么又说业务知识是遗留系统最大的认知负载,需要降低呢?其实这里说的,隐藏在遗留系统隐秘角落的业务知识,是指它们呈现的方式不友好,提高了外在认知负载,而这恰恰是我们需要降低的。
|
||
|
||
**遗留系统的第二大认知负载,是同样难以获取的系统知识**。这里的系统知识是指系统的具体实现细节,包括模块的划分、架构的取舍,以及每一个技术决策的原因。这些知识也同样很难有文档可以一窥究竟,更遗憾的是,连代码都无法体现出每一个细节。
|
||
|
||
给我印象深刻的是我曾经治理的一段代码,有一行用Thread.sleep(5000)等待了5秒钟。我问遍团队的每一个人,都不知道这行代码的用意,于是就当做无用代码删掉了。没想到几天之后系统崩溃了,原来这行代码的前面几百行,有一处调用链很深的代码触发了一个后台任务,等待5秒钟的目的就是等这个后台任务跑完,然后后面的代码就可以用这个后台任务所生成的数据了。删掉这行等待代码,后续的代码就失败了。
|
||
|
||
还记得我第一节课的吐槽吗?糟糕的代码各有各的糟糕之处。但这段代码的问题并不在于它有多糟糕,而是在于没有人知道它为什么糟糕。这种代码存在于系统之中,就带来了非常高的外在认知负载。
|
||
|
||
这些高认知负载的系统知识,会导致我们的需求开发走向“魔改”。所谓“魔改”,就是魔幻般地修改,这种情况下,没人能说清楚一个新需求应该改哪里,更没法保证改了这些,是否就覆盖了全部要改的内容。
|
||
|
||
至此,我们已经知道了遗留系统之所以这么“难搞”,就是因为过高的外在认知负载。人们在遗留系统上工作的时候,所付出的脑力劳动比正常系统要多得多,因此只要能大致测试通过,就会凑合着上线,而没有精力去偿还欠下的债务、改善外在认知负载。如此恶性循环,导致遗留系统的外在认知负载越来越高,修改起来越来越难。
|
||
|
||
我们进行遗留系统的整治,其实就是要尽力降低遗留系统的外在认知负载。外在认知负载降低了,开发起来容易了,痛点自然就解决了。
|
||
|
||
## 以降低认知负载为前提
|
||
|
||
**以降低外在认知负载为前提的意思就是,我们进行遗留系统现代化时,所做的任何举措都应该是能够降低外在认知负载的**。
|
||
|
||
现在回顾[第二节课](https://xn--yfr16a528c0pp4fap15gjp7o)的“四化建设”——代码现代化、架构现代化、DevOps现代化和团队结构现代化,你会发现这四大方向其实都有利于降低团队外在认知负载。
|
||
|
||
比如对代码进行重构、改善代码的可读性,可以降低阅读代码的难度,实际上就是降低代码的认知负载;对单体架构进行拆分,分解成多个小的、更加内聚的微服务,每个服务可以独立部署和演进,实际上就是在降低业务和系统的认知负载;还有优化持续集成流水线,让开发人员提交代码之后就不必随时关注后续的步骤,轻装上阵;再比如对团队结构进行优化,让每个团队只关注少量大小适中的业务模块,以降低认知负载。
|
||
|
||
没错,降低认知负载这一原则不光能作为方向指引,落到微观操作层,同样能帮助你科学预判改造过程中的每个决策。
|
||
|
||
比如在进行微服务拆分时,是应该先对代码进行模块化分解,再进而拆分出独立的服务,还是应该直接拆分出服务,再对耦合的部分进行解耦呢?代码分层改造时,是应该改造成分层架构,还是六边形架构或整洁架构呢?优化分支策略时,是应该基于主干开发,还是应该使用特性分支呢?前端应该改造成React还是Vue?改造过程如何回退?
|
||
|
||
在遗留系统现代化的过程中,如果以常规的技术视角去看待上述问题,可能很多类似的技术决策都很难找到具有说服力的依据,最后只好拍拍脑袋,随便决定一个,或者看架构师自己的喜好。实际上只要我们掌握了“降低外在认知负载”这个原则,我们就可以把技术性的问题轻松转换成人的问题,然后去分析看看,到底哪个选项更有利于降低团队的认知负载,更容易被团队所接受,更容易实现。
|
||
|
||
很多时候,遗留系统的现代化项目以失败告终,或举步维艰,都是因为很多决定和举措非但不能降低认知负载,反倒增加了认知负载。以高认知负载的方案去解决高认知负载的问题,最终必将导致项目做不下去,人也疲惫不堪。
|
||
|
||
其实**不止是遗留系统现代化,我们所有的工作都应该尽量去降低外在认知负载,从而简化工作本身**。
|
||
|
||
比如敏捷开发方法就是一套很好的可以降低外在认知负载的方法。几个月甚至几年的交付周期,所承载的内容会让人不堪重负;而只有两周的迭代,则能让人轻装上阵。一份动辄几百页的需求文档,会让人不知所措;而只有一两页的故事卡,则能让人更轻松地聚焦于眼前的工作。
|
||
|
||
领域驱动开发(DDD)也是行之有效的降低外在认知负载的方法论。形成统一语言、拆分限界上下文,都是为了使沟通更加容易、工作更加聚焦。还有目前大厂比较流行的研发工程效能,其本质说白了也是为了降低外在认知负载。
|
||
|
||
从这个角度出发,灵活应用这个原则,以前很多悬而未决的疑难杂症,很多靠“视情况而定”、“具体问题具体分析”等“托词”搪塞过去的问题,是不是一下子就豁然开朗了?
|
||
|
||
## 总结
|
||
|
||
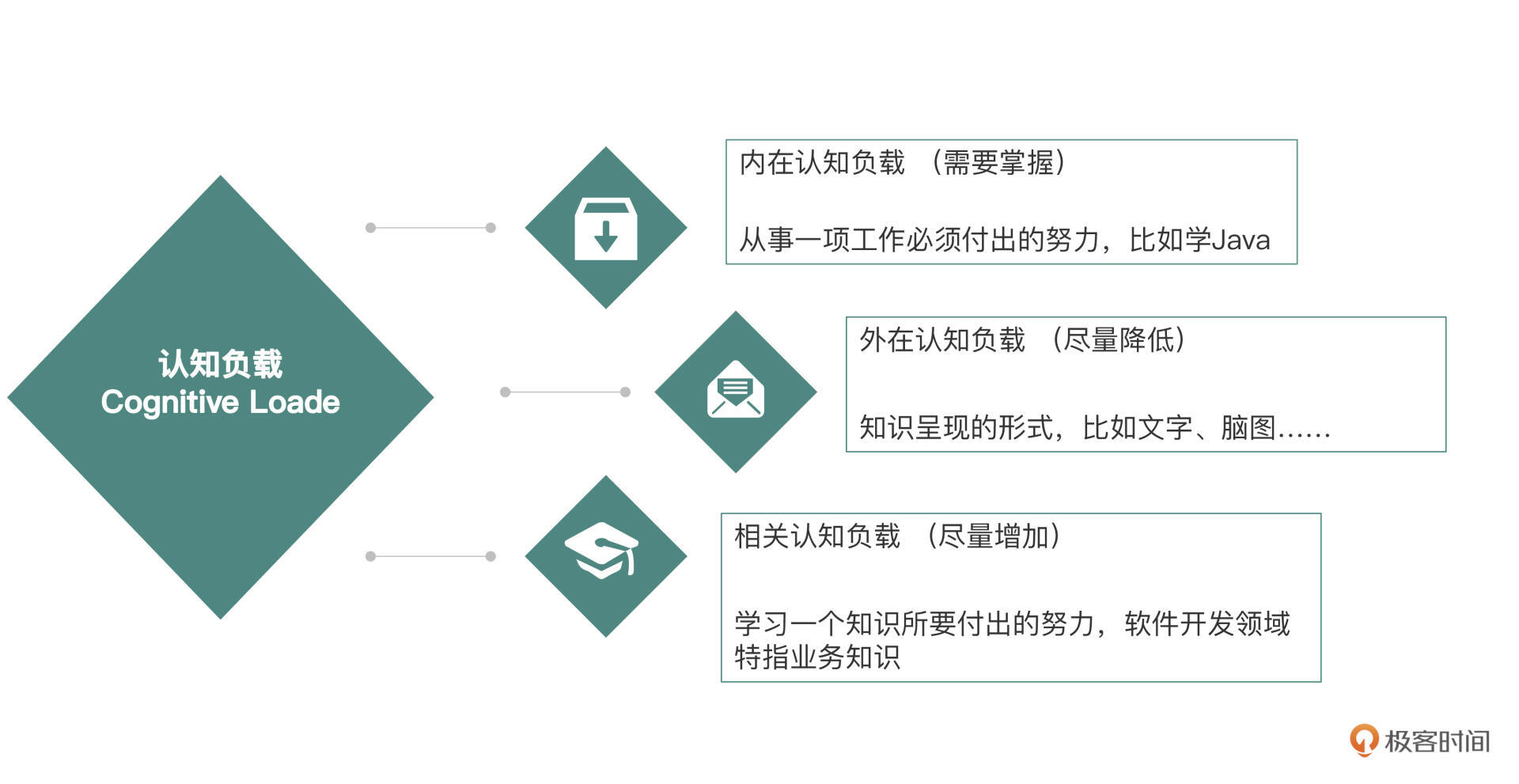
总结一下今天的内容。我们介绍了认知负载的三个分类:内在认知负载、外在认知负载和相关认知负载。我把它们的特点以及和软件开发特别是遗留系统的关系总结一下,方便你复习:
|
||
|
||
* 内在认知负载是指从事一项工作必须付出的努力,比如学习Java知识、前端知识等;
|
||
* 外在认知负载是指知识呈现的形式,代码越糟糕、越难读,外在认知负载越高;
|
||
* 相关认知负载是指人们要学习一个知识所要付出的努力,在软件开发领域就特指业务知识。
|
||
|
||
|
||
其中,外在认知负载是我们最痛恨的,一定要尽可能地降低。我们在做遗留系统现代化的时候,所有的决策在制定之前都要思考一下,是否有利于降低当前的外在认知负载。可以说,将遗留系统的外在认知负载降到最低,遗留系统的现代化工作也就完成了。
|
||
|
||
为了方便后面课程的讲述,我将统一用“认知负载”来代替具体的分类。至于到底是哪一种类型的认知负载,就不是那么特别重要了。你只需要判断一下,**当前这个事物、活动、决策所增加的认知负载是否更有利于我们完成当前和以后的工作**。如果有利(比如学习更多的业务知识),就增加这种认知负载;如果不利(比如读一篇晦涩难懂的需求文档),就减少这种认知负载。
|
||
|
||
[下一节课](https://time.geekbang.org/column/article/508559)我们就来看看在遗留系统中,如何来降低业务知识和系统知识难以获取的认知负载。
|
||
|
||
## 思考题
|
||
|
||
感谢你认真学完了这节课的内容,今天的思考题是两道开放式的问题:
|
||
|
||
1.你项目上的分支策略是什么样的?是基于主干开发,还是特性分支,或者其他分支策略?你认为哪种方式更能降低外在认知负载?
|
||
|
||
2.你项目上的哪些实践是有意无意地降低了外在认知负载的?又有哪些实践增加了外在认知负载?
|
||
|
||
欢迎你在留言区留下你的思考,我们一起交流讨论。也欢迎你把这节课分享给其他工作在遗留系统上的朋友,让我们一起帮助他们走出泥潭。
|
||
|