19 KiB
30 | 文件缓存:常用文档应该放在触手可得的地方
上一节,我们讲了文件系统的挂载和文件的打开,并通过打开文件的过程,构建了一个文件管理的整套数据结构体系。其实到这里,我们还没有对文件进行读写,还属于对于元数据的操作。那这一节,我们就重点关注读写。
系统调用层和虚拟文件系统层
文件系统的读写,其实就是调用系统函数read和write。由于读和写的很多逻辑是相似的,这里我们一起来看一下这个过程。
下面的代码就是read和write的系统调用,在内核里面的定义。
SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count)
{
struct fd f = fdget_pos(fd);
......
loff_t pos = file_pos_read(f.file);
ret = vfs_read(f.file, buf, count, &pos);
......
}
SYSCALL_DEFINE3(write, unsigned int, fd, const char __user *, buf,
size_t, count)
{
struct fd f = fdget_pos(fd);
......
loff_t pos = file_pos_read(f.file);
ret = vfs_write(f.file, buf, count, &pos);
......
}
对于read来讲,里面调用vfs_read->__vfs_read。对于write来讲,里面调用vfs_write->__vfs_write。
下面是__vfs_read和__vfs_write的代码。
ssize_t __vfs_read(struct file *file, char __user *buf, size_t count,
loff_t *pos)
{
if (file->f_op->read)
return file->f_op->read(file, buf, count, pos);
else if (file->f_op->read_iter)
return new_sync_read(file, buf, count, pos);
else
return -EINVAL;
}
ssize_t __vfs_write(struct file *file, const char __user *p, size_t count,
loff_t *pos)
{
if (file->f_op->write)
return file->f_op->write(file, p, count, pos);
else if (file->f_op->write_iter)
return new_sync_write(file, p, count, pos);
else
return -EINVAL;
}
上一节,我们讲了,每一个打开的文件,都有一个struct file结构。这里面有一个struct file_operations f_op,用于定义对这个文件做的操作。__vfs_read会调用相应文件系统的file_operations里面的read操作,__vfs_write会调用相应文件系统file_operations里的write操作。
ext4文件系统层
对于ext4文件系统来讲,内核定义了一个ext4_file_operations。
const struct file_operations ext4_file_operations = {
......
.read_iter = ext4_file_read_iter,
.write_iter = ext4_file_write_iter,
......
}
由于ext4没有定义read和write函数,于是会调用ext4_file_read_iter和ext4_file_write_iter。
ext4_file_read_iter会调用generic_file_read_iter,ext4_file_write_iter会调用__generic_file_write_iter。
ssize_t
generic_file_read_iter(struct kiocb *iocb, struct iov_iter *iter)
{
......
if (iocb->ki_flags & IOCB_DIRECT) {
......
struct address_space *mapping = file->f_mapping;
......
retval = mapping->a_ops->direct_IO(iocb, iter);
}
......
retval = generic_file_buffered_read(iocb, iter, retval);
}
ssize_t __generic_file_write_iter(struct kiocb *iocb, struct iov_iter *from)
{
......
if (iocb->ki_flags & IOCB_DIRECT) {
......
written = generic_file_direct_write(iocb, from);
......
} else {
......
written = generic_perform_write(file, from, iocb->ki_pos);
......
}
}
generic_file_read_iter和__generic_file_write_iter有相似的逻辑,就是要区分是否用缓存。
缓存其实就是内存中的一块空间。因为内存比硬盘快得多,Linux为了改进性能,有时候会选择不直接操作硬盘,而是读写都在内存中,然后批量读取或者写入硬盘。一旦能够命中内存,读写效率就会大幅度提高。
因此,根据是否使用内存做缓存,我们可以把文件的I/O操作分为两种类型。
第一种类型是缓存I/O。大多数文件系统的默认I/O操作都是缓存I/O。对于读操作来讲,操作系统会先检查,内核的缓冲区有没有需要的数据。如果已经缓存了,那就直接从缓存中返回;否则从磁盘中读取,然后缓存在操作系统的缓存中。对于写操作来讲,操作系统会先将数据从用户空间复制到内核空间的缓存中。这时对用户程序来说,写操作就已经完成。至于什么时候再写到磁盘中由操作系统决定,除非显式地调用了sync同步命令。
第二种类型是直接IO,就是应用程序直接访问磁盘数据,而不经过内核缓冲区,从而减少了在内核缓存和用户程序之间数据复制。
如果在读的逻辑generic_file_read_iter里面,发现设置了IOCB_DIRECT,则会调用address_space的direct_IO的函数,将数据直接读取硬盘。我们在mmap映射文件到内存的时候讲过address_space,它主要用于在内存映射的时候将文件和内存页产生关联。
同样,对于缓存来讲,也需要文件和内存页进行关联,这就要用到address_space。address_space的相关操作定义在struct address_space_operations结构中。对于ext4文件系统来讲, address_space的操作定义在ext4_aops,direct_IO对应的函数是ext4_direct_IO。
static const struct address_space_operations ext4_aops = {
......
.direct_IO = ext4_direct_IO,
......
};
如果在写的逻辑__generic_file_write_iter里面,发现设置了IOCB_DIRECT,则调用generic_file_direct_write,里面同样会调用address_space的direct_IO的函数,将数据直接写入硬盘。
ext4_direct_IO最终会调用到__blockdev_direct_IO->do_blockdev_direct_IO,这就跨过了缓存层,到了通用块层,最终到了文件系统的设备驱动层。由于文件系统是块设备,所以这个调用的是blockdev相关的函数,有关块设备驱动程序的原理我们下一章详细讲,这一节我们就讲到文件系统到块设备的分界线部分。
/*
* This is a library function for use by filesystem drivers.
*/
static inline ssize_t
do_blockdev_direct_IO(struct kiocb *iocb, struct inode *inode,
struct block_device *bdev, struct iov_iter *iter,
get_block_t get_block, dio_iodone_t end_io,
dio_submit_t submit_io, int flags)
{......}
接下来,我们重点看带缓存的部分如果进行读写。
带缓存的写入操作
我们先来看带缓存写入的函数generic_perform_write。
ssize_t generic_perform_write(struct file *file,
struct iov_iter *i, loff_t pos)
{
struct address_space *mapping = file->f_mapping;
const struct address_space_operations *a_ops = mapping->a_ops;
do {
struct page *page;
unsigned long offset; /* Offset into pagecache page */
unsigned long bytes; /* Bytes to write to page */
status = a_ops->write_begin(file, mapping, pos, bytes, flags,
&page, &fsdata);
copied = iov_iter_copy_from_user_atomic(page, i, offset, bytes);
flush_dcache_page(page);
status = a_ops->write_end(file, mapping, pos, bytes, copied,
page, fsdata);
pos += copied;
written += copied;
balance_dirty_pages_ratelimited(mapping);
} while (iov_iter_count(i));
}
这个函数里,是一个while循环。我们需要找出这次写入影响的所有的页,然后依次写入。对于每一个循环,主要做四件事情:
- 对于每一页,先调用address_space的write_begin做一些准备;
- 调用iov_iter_copy_from_user_atomic,将写入的内容从用户态拷贝到内核态的页中;
- 调用address_space的write_end完成写操作;
- 调用balance_dirty_pages_ratelimited,看脏页是否太多,需要写回硬盘。所谓脏页,就是写入到缓存,但是还没有写入到硬盘的页面。
我们依次来看这四个步骤。
static const struct address_space_operations ext4_aops = {
......
.write_begin = ext4_write_begin,
.write_end = ext4_write_end,
......
}
第一步,对于ext4来讲,调用的是ext4_write_begin。
ext4是一种日志文件系统,是为了防止突然断电的时候的数据丢失,引入了日志**(Journal)**模式。日志文件系统比非日志文件系统多了一个Journal区域。文件在ext4中分两部分存储,一部分是文件的元数据,另一部分是数据。元数据和数据的操作日志Journal也是分开管理的。你可以在挂载ext4的时候,选择Journal模式。这种模式在将数据写入文件系统前,必须等待元数据和数据的日志已经落盘才能发挥作用。这样性能比较差,但是最安全。
另一种模式是order模式。这个模式不记录数据的日志,只记录元数据的日志,但是在写元数据的日志前,必须先确保数据已经落盘。这个折中,是默认模式。
还有一种模式是writeback,不记录数据的日志,仅记录元数据的日志,并且不保证数据比元数据先落盘。这个性能最好,但是最不安全。
在ext4_write_begin,我们能看到对于ext4_journal_start的调用,就是在做日志相关的工作。
在ext4_write_begin中,还做了另外一件重要的事情,就是调用grab_cache_page_write_begin,来得到应该写入的缓存页。
struct page *grab_cache_page_write_begin(struct address_space *mapping,
pgoff_t index, unsigned flags)
{
struct page *page;
int fgp_flags = FGP_LOCK|FGP_WRITE|FGP_CREAT;
page = pagecache_get_page(mapping, index, fgp_flags,
mapping_gfp_mask(mapping));
if (page)
wait_for_stable_page(page);
return page;
}
在内核中,缓存以页为单位放在内存里面,那我们如何知道,一个文件的哪些数据已经被放到缓存中了呢?每一个打开的文件都有一个struct file结构,每个struct file结构都有一个struct address_space用于关联文件和内存,就是在这个结构里面,有一棵树,用于保存所有与这个文件相关的的缓存页。
我们查找的时候,往往需要根据文件中的偏移量找出相应的页面,而基数树radix tree这种数据结构能够快速根据一个长整型查找到其相应的对象,因而这里缓存页就放在radix基数树里面。
struct address_space {
struct inode *host; /* owner: inode, block_device */
struct radix_tree_root page_tree; /* radix tree of all pages */
spinlock_t tree_lock; /* and lock protecting it */
......
}
pagecache_get_page就是根据pgoff_t index这个长整型,在这棵树里面查找缓存页,如果找不到就会创建一个缓存页。
第二步,调用iov_iter_copy_from_user_atomic。先将分配好的页面调用kmap_atomic映射到内核里面的一个虚拟地址,然后将用户态的数据拷贝到内核态的页面的虚拟地址中,调用kunmap_atomic把内核里面的映射删除。
size_t iov_iter_copy_from_user_atomic(struct page *page,
struct iov_iter *i, unsigned long offset, size_t bytes)
{
char *kaddr = kmap_atomic(page), *p = kaddr + offset;
iterate_all_kinds(i, bytes, v,
copyin((p += v.iov_len) - v.iov_len, v.iov_base, v.iov_len),
memcpy_from_page((p += v.bv_len) - v.bv_len, v.bv_page,
v.bv_offset, v.bv_len),
memcpy((p += v.iov_len) - v.iov_len, v.iov_base, v.iov_len)
)
kunmap_atomic(kaddr);
return bytes;
}
第三步,调用ext4_write_end完成写入。这里面会调用ext4_journal_stop完成日志的写入,会调用block_write_end->__block_commit_write->mark_buffer_dirty,将修改过的缓存标记为脏页。可以看出,其实所谓的完成写入,并没有真正写入硬盘,仅仅是写入缓存后,标记为脏页。
但是这里有一个问题,数据很危险,一旦宕机就没有了,所以需要一种机制,将写入的页面真正写到硬盘中,我们称为回写(Write Back)。
第四步,调用 balance_dirty_pages_ratelimited,是回写脏页的一个很好的时机。
/**
* balance_dirty_pages_ratelimited - balance dirty memory state
* @mapping: address_space which was dirtied
*
* Processes which are dirtying memory should call in here once for each page
* which was newly dirtied. The function will periodically check the system's
* dirty state and will initiate writeback if needed.
*/
void balance_dirty_pages_ratelimited(struct address_space *mapping)
{
struct inode *inode = mapping->host;
struct backing_dev_info *bdi = inode_to_bdi(inode);
struct bdi_writeback *wb = NULL;
int ratelimit;
......
if (unlikely(current->nr_dirtied >= ratelimit))
balance_dirty_pages(mapping, wb, current->nr_dirtied);
......
}
在balance_dirty_pages_ratelimited里面,发现脏页的数目超过了规定的数目,就调用balance_dirty_pages->wb_start_background_writeback,启动一个背后线程开始回写。
void wb_start_background_writeback(struct bdi_writeback *wb)
{
/*
* We just wake up the flusher thread. It will perform background
* writeback as soon as there is no other work to do.
*/
wb_wakeup(wb);
}
static void wb_wakeup(struct bdi_writeback *wb)
{
spin_lock_bh(&wb->work_lock);
if (test_bit(WB_registered, &wb->state))
mod_delayed_work(bdi_wq, &wb->dwork, 0);
spin_unlock_bh(&wb->work_lock);
}
(_tflags) | TIMER_IRQSAFE); \
} while (0)
/* bdi_wq serves all asynchronous writeback tasks */
struct workqueue_struct *bdi_wq;
/**
* mod_delayed_work - modify delay of or queue a delayed work
* @wq: workqueue to use
* @dwork: work to queue
* @delay: number of jiffies to wait before queueing
*
* mod_delayed_work_on() on local CPU.
*/
static inline bool mod_delayed_work(struct workqueue_struct *wq,
struct delayed_work *dwork,
unsigned long delay)
{....
通过上面的代码,我们可以看出,bdi_wq是一个全局变量,所有回写的任务都挂在这个队列上。mod_delayed_work函数负责将一个回写任务bdi_writeback挂在这个队列上。bdi_writeback有个成员变量struct delayed_work dwork,bdi_writeback就是以delayed_work的身份挂到队列上的,并且把delay设置为0,意思就是一刻不等,马上执行。
那具体这个任务由谁来执行呢?这里的bdi的意思是backing device info,用于描述后端存储相关的信息。每个块设备都会有这样一个结构,并且在初始化块设备的时候,调用bdi_init初始化这个结构,在初始化bdi的时候,也会调用wb_init初始化bdi_writeback。
static int wb_init(struct bdi_writeback *wb, struct backing_dev_info *bdi,
int blkcg_id, gfp_t gfp)
{
wb->bdi = bdi;
wb->last_old_flush = jiffies;
INIT_LIST_HEAD(&wb->b_dirty);
INIT_LIST_HEAD(&wb->b_io);
INIT_LIST_HEAD(&wb->b_more_io);
INIT_LIST_HEAD(&wb->b_dirty_time);
wb->bw_time_stamp = jiffies;
wb->balanced_dirty_ratelimit = INIT_BW;
wb->dirty_ratelimit = INIT_BW;
wb->write_bandwidth = INIT_BW;
wb->avg_write_bandwidth = INIT_BW;
spin_lock_init(&wb->work_lock);
INIT_LIST_HEAD(&wb->work_list);
INIT_DELAYED_WORK(&wb->dwork, wb_workfn);
wb->dirty_sleep = jiffies;
......
}
#define __INIT_DELAYED_WORK(_work, _func, _tflags) \
do { \
INIT_WORK(&(_work)->work, (_func)); \
__setup_timer(&(_work)->timer, delayed_work_timer_fn, \
(unsigned long)(_work), \
这里面最重要的是INIT_DELAYED_WORK。其实就是初始化一个timer,也即定时器,到时候我们就执行wb_workfn这个函数。
接下来的调用链为:wb_workfn->wb_do_writeback->wb_writeback->writeback_sb_inodes->__writeback_single_inode->do_writepages,写入页面到硬盘。
在调用write的最后,当发现缓存的数据太多的时候,会触发回写,这仅仅是回写的一种场景。另外还有几种场景也会触发回写:
- 用户主动调用sync,将缓存刷到硬盘上去,最终会调用wakeup_flusher_threads,同步脏页;
- 当内存十分紧张,以至于无法分配页面的时候,会调用free_more_memory,最终会调用wakeup_flusher_threads,释放脏页;
- 脏页已经更新了较长时间,时间上超过了timer,需要及时回写,保持内存和磁盘上数据一致性。
带缓存的读操作
带缓存的写分析完了,接下来,我们看带缓存的读,对应的是函数generic_file_buffered_read。
static ssize_t generic_file_buffered_read(struct kiocb *iocb,
struct iov_iter *iter, ssize_t written)
{
struct file *filp = iocb->ki_filp;
struct address_space *mapping = filp->f_mapping;
struct inode *inode = mapping->host;
for (;;) {
struct page *page;
pgoff_t end_index;
loff_t isize;
page = find_get_page(mapping, index);
if (!page) {
if (iocb->ki_flags & IOCB_NOWAIT)
goto would_block;
page_cache_sync_readahead(mapping,
ra, filp,
index, last_index - index);
page = find_get_page(mapping, index);
if (unlikely(page == NULL))
goto no_cached_page;
}
if (PageReadahead(page)) {
page_cache_async_readahead(mapping,
ra, filp, page,
index, last_index - index);
}
/*
* Ok, we have the page, and it's up-to-date, so
* now we can copy it to user space...
*/
ret = copy_page_to_iter(page, offset, nr, iter);
}
}
读取比写入总体而言简单一些,主要涉及预读的问题。
在generic_file_buffered_read函数中,我们需要先找到page cache里面是否有缓存页。如果没有找到,不但读取这一页,还要进行预读,这需要在page_cache_sync_readahead函数中实现。预读完了以后,再试一把查找缓存页,应该能找到了。
如果第一次找缓存页就找到了,我们还是要判断,是不是应该继续预读;如果需要,就调用page_cache_async_readahead发起一个异步预读。
最后,copy_page_to_iter会将内容从内核缓存页拷贝到用户内存空间。
总结时刻
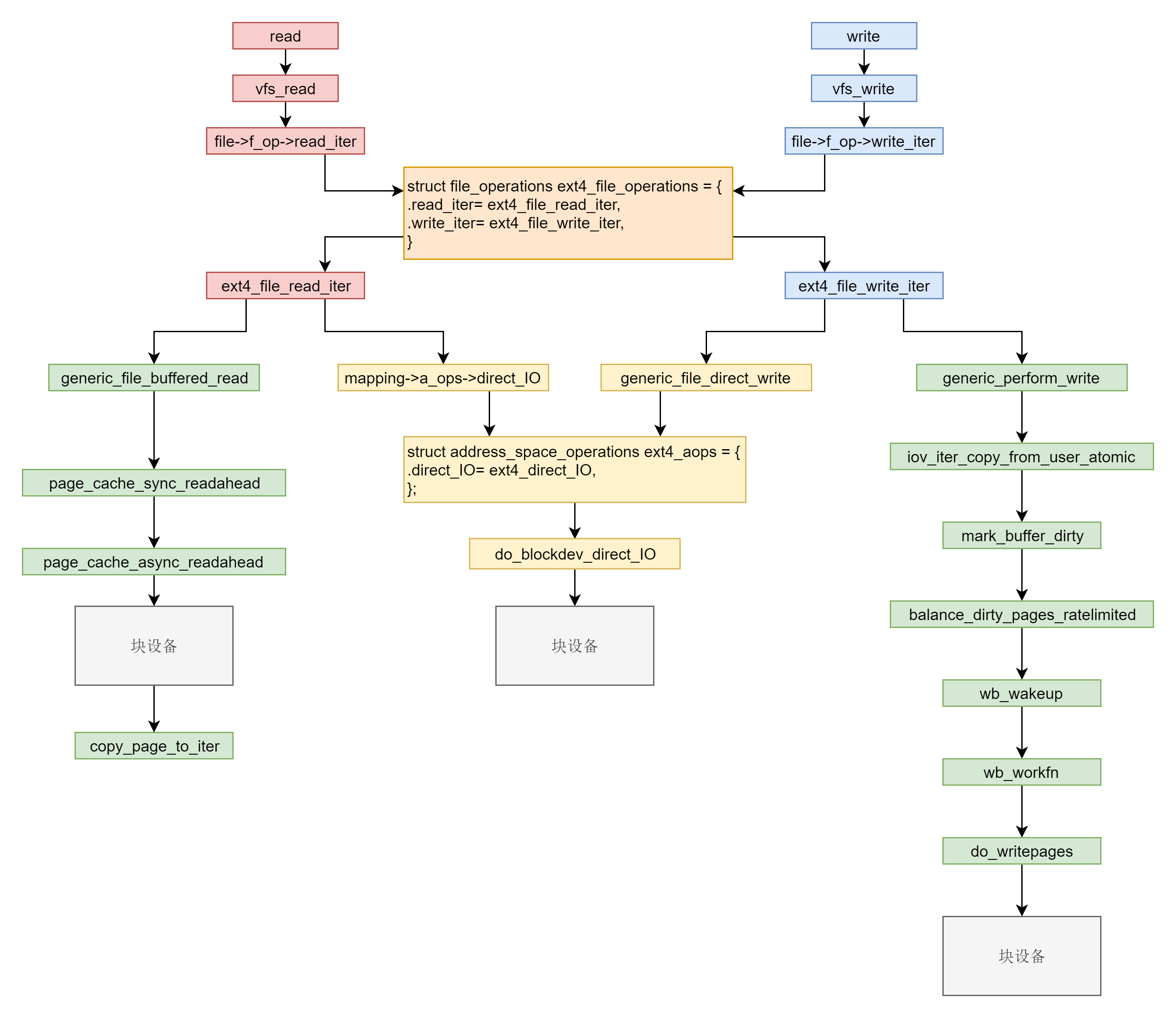
这一节对于读取和写入的分析就到这里了。我们发现这个过程还是很复杂的,我这里画了一张调用图,你可以看到调用过程。
在系统调用层我们需要仔细学习read和write。在VFS层调用的是vfs_read和vfs_write并且调用file_operation。在ext4层调用的是ext4_file_read_iter和ext4_file_write_iter。
接下来就是分叉。你需要知道缓存I/O和直接I/O。直接I/O读写的流程是一样的,调用ext4_direct_IO,再往下就调用块设备层了。缓存I/O读写的流程不一样。对于读,从块设备读取到缓存中,然后从缓存中拷贝到用户态。对于写,从用户态拷贝到缓存,设置缓存页为脏,然后启动一个线程写入块设备。
课堂练习
你知道如何查询和清除文件系统缓存吗?
欢迎留言和我分享你的疑惑和见解 ,也欢迎可以收藏本节内容,反复研读。你也可以把今天的内容分享给你的朋友,和他一起学习和进步。
