|
|
# 24 | 物理内存管理(下):会议室管理员如何分配会议室?
|
|
|
|
|
|
前一节,前面我们解析了整页的分配机制。如果遇到小的对象,物理内存是如何分配的呢?这一节,我们一起来看一看。
|
|
|
|
|
|
## 小内存的分配
|
|
|
|
|
|
前面我们讲过,如果遇到小的对象,会使用slub分配器进行分配。那我们就先来解析它的工作原理。
|
|
|
|
|
|
还记得咱们创建进程的时候,会调用dup\_task\_struct,它想要试图复制一个task\_struct对象,需要先调用alloc\_task\_struct\_node,分配一个task\_struct对象。
|
|
|
|
|
|
从这段代码可以看出,它调用了kmem\_cache\_alloc\_node函数,在task\_struct的缓存区域task\_struct\_cachep分配了一块内存。
|
|
|
|
|
|
```
|
|
|
static struct kmem_cache *task_struct_cachep;
|
|
|
|
|
|
task_struct_cachep = kmem_cache_create("task_struct",
|
|
|
arch_task_struct_size, align,
|
|
|
SLAB_PANIC|SLAB_NOTRACK|SLAB_ACCOUNT, NULL);
|
|
|
|
|
|
static inline struct task_struct *alloc_task_struct_node(int node)
|
|
|
{
|
|
|
return kmem_cache_alloc_node(task_struct_cachep, GFP_KERNEL, node);
|
|
|
}
|
|
|
|
|
|
static inline void free_task_struct(struct task_struct *tsk)
|
|
|
{
|
|
|
kmem_cache_free(task_struct_cachep, tsk);
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
在系统初始化的时候,task\_struct\_cachep会被kmem\_cache\_create函数创建。这个函数也比较容易看懂,专门用于分配task\_struct对象的缓存。这个缓存区的名字就叫task\_struct。缓存区中每一块的大小正好等于task\_struct的大小,也即arch\_task\_struct\_size。
|
|
|
|
|
|
有了这个缓存区,每次创建task\_struct的时候,我们不用到内存里面去分配,先在缓存里面看看有没有直接可用的,这就是**kmem\_cache\_alloc\_node**的作用。
|
|
|
|
|
|
当一个进程结束,task\_struct也不用直接被销毁,而是放回到缓存中,这就是**kmem\_cache\_free**的作用。这样,新进程创建的时候,我们就可以直接用现成的缓存中的task\_struct了。
|
|
|
|
|
|
我们来仔细看看,缓存区struct kmem\_cache到底是什么样子。
|
|
|
|
|
|
```
|
|
|
struct kmem_cache {
|
|
|
struct kmem_cache_cpu __percpu *cpu_slab;
|
|
|
/* Used for retriving partial slabs etc */
|
|
|
unsigned long flags;
|
|
|
unsigned long min_partial;
|
|
|
int size; /* The size of an object including meta data */
|
|
|
int object_size; /* The size of an object without meta data */
|
|
|
int offset; /* Free pointer offset. */
|
|
|
#ifdef CONFIG_SLUB_CPU_PARTIAL
|
|
|
int cpu_partial; /* Number of per cpu partial objects to keep around */
|
|
|
#endif
|
|
|
struct kmem_cache_order_objects oo;
|
|
|
/* Allocation and freeing of slabs */
|
|
|
struct kmem_cache_order_objects max;
|
|
|
struct kmem_cache_order_objects min;
|
|
|
gfp_t allocflags; /* gfp flags to use on each alloc */
|
|
|
int refcount; /* Refcount for slab cache destroy */
|
|
|
void (*ctor)(void *);
|
|
|
......
|
|
|
const char *name; /* Name (only for display!) */
|
|
|
struct list_head list; /* List of slab caches */
|
|
|
......
|
|
|
struct kmem_cache_node *node[MAX_NUMNODES];
|
|
|
};
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
在struct kmem\_cache里面,有个变量struct list\_head list,这个结构我们已经看到过多次了。我们可以想象一下,对于操作系统来讲,要创建和管理的缓存绝对不止task\_struct。难道mm\_struct就不需要吗?fs\_struct就不需要吗?都需要。因此,所有的缓存最后都会放在一个链表里面,也就是LIST\_HEAD(slab\_caches)。
|
|
|
|
|
|
对于缓存来讲,其实就是分配了连续几页的大内存块,然后根据缓存对象的大小,切成小内存块。
|
|
|
|
|
|
所以,我们这里有三个kmem\_cache\_order\_objects类型的变量。这里面的order,就是2的order次方个页面的大内存块,objects就是能够存放的缓存对象的数量。
|
|
|
|
|
|
最终,我们将大内存块切分成小内存块,样子就像下面这样。
|
|
|
|
|
|
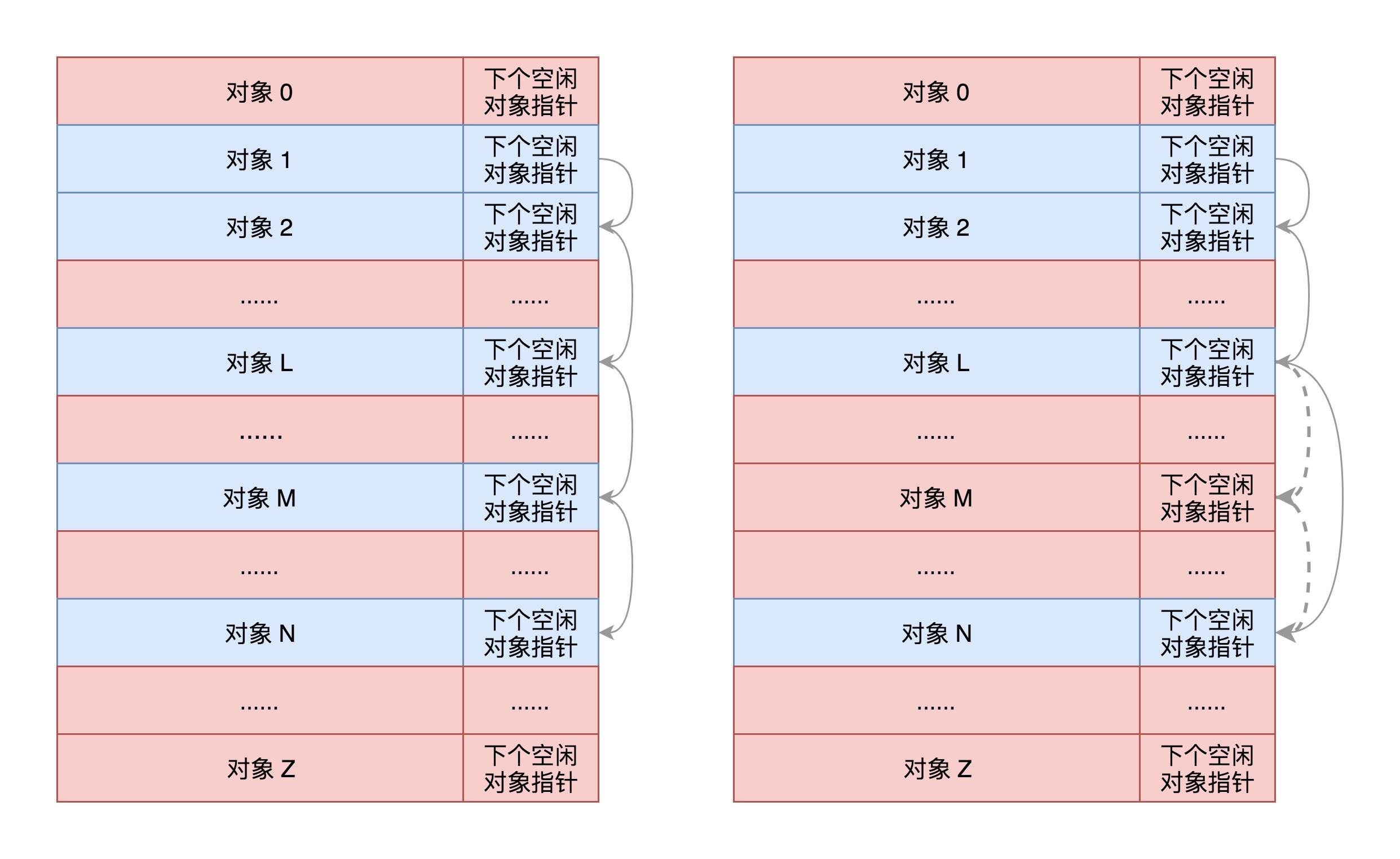
|
|
|
|
|
|
每一项的结构都是缓存对象后面跟一个下一个空闲对象的指针,这样非常方便将所有的空闲对象链成一个链。其实,这就相当于咱们数据结构里面学的,用数组实现一个可随机插入和删除的链表。
|
|
|
|
|
|
所以,这里面就有三个变量:size是包含这个指针的大小,object\_size是纯对象的大小,offset就是把下一个空闲对象的指针存放在这一项里的偏移量。
|
|
|
|
|
|
那这些缓存对象哪些被分配了、哪些在空着,什么情况下整个大内存块都被分配完了,需要向伙伴系统申请几个页形成新的大内存块?这些信息该由谁来维护呢?
|
|
|
|
|
|
接下来就是最重要的两个成员变量出场的时候了。kmem\_cache\_cpu和kmem\_cache\_node,它们都是每个NUMA节点上有一个,我们只需要看一个节点里面的情况。
|
|
|
|
|
|
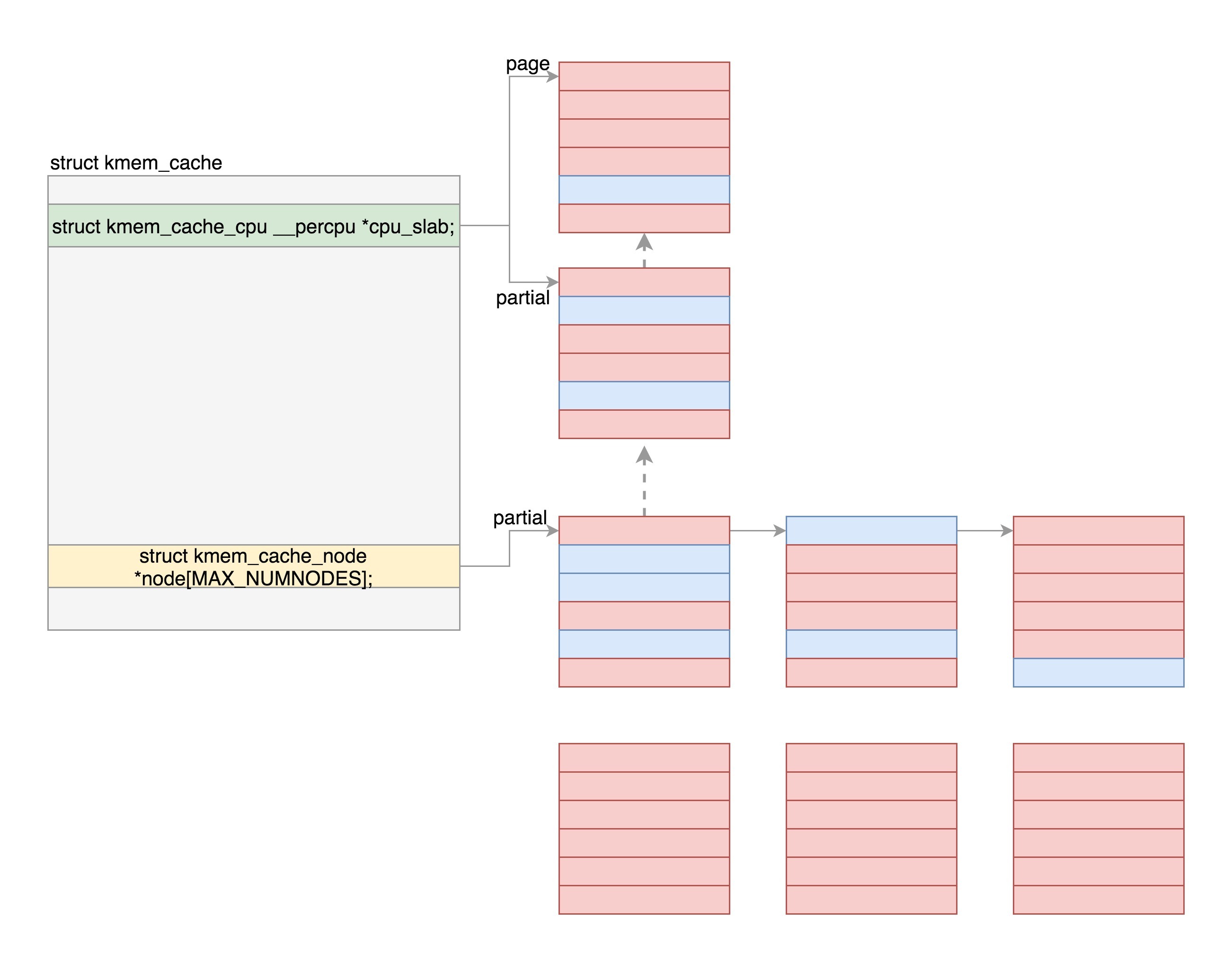
|
|
|
|
|
|
在分配缓存块的时候,要分两种路径,**fast path**和**slow path**,也就是**快速通道**和**普通通道**。其中kmem\_cache\_cpu就是快速通道,kmem\_cache\_node是普通通道。每次分配的时候,要先从kmem\_cache\_cpu进行分配。如果kmem\_cache\_cpu里面没有空闲的块,那就到kmem\_cache\_node中进行分配;如果还是没有空闲的块,才去伙伴系统分配新的页。
|
|
|
|
|
|
我们来看一下,kmem\_cache\_cpu里面是如何存放缓存块的。
|
|
|
|
|
|
```
|
|
|
struct kmem_cache_cpu {
|
|
|
void **freelist; /* Pointer to next available object */
|
|
|
unsigned long tid; /* Globally unique transaction id */
|
|
|
struct page *page; /* The slab from which we are allocating */
|
|
|
#ifdef CONFIG_SLUB_CPU_PARTIAL
|
|
|
struct page *partial; /* Partially allocated frozen slabs */
|
|
|
#endif
|
|
|
......
|
|
|
};
|
|
|
|
|
|
```
|
|
|
|
|
|
在这里,page指向大内存块的第一个页,缓存块就是从里面分配的。freelist指向大内存块里面第一个空闲的项。按照上面说的,这一项会有指针指向下一个空闲的项,最终所有空闲的项会形成一个链表。
|
|
|
|
|
|
partial指向的也是大内存块的第一个页,之所以名字叫partial(部分),就是因为它里面部分被分配出去了,部分是空的。这是一个备用列表,当page满了,就会从这里找。
|
|
|
|
|
|
我们再来看kmem\_cache\_node的定义。
|
|
|
|
|
|
```
|
|
|
struct kmem_cache_node {
|
|
|
spinlock_t list_lock;
|
|
|
......
|
|
|
#ifdef CONFIG_SLUB
|
|
|
unsigned long nr_partial;
|
|
|
struct list_head partial;
|
|
|
......
|
|
|
#endif
|
|
|
};
|
|
|
|
|
|
```
|
|
|
|
|
|
这里面也有一个partial,是一个链表。这个链表里存放的是部分空闲的内存块。这是kmem\_cache\_cpu里面的partial的备用列表,如果那里没有,就到这里来找。
|
|
|
|
|
|
下面我们就来看看这个分配过程。kmem\_cache\_alloc\_node会调用slab\_alloc\_node。你还是先重点看这里面的注释,这里面说的就是快速通道和普通通道的概念。
|
|
|
|
|
|
```
|
|
|
/*
|
|
|
* Inlined fastpath so that allocation functions (kmalloc, kmem_cache_alloc)
|
|
|
* have the fastpath folded into their functions. So no function call
|
|
|
* overhead for requests that can be satisfied on the fastpath.
|
|
|
*
|
|
|
* The fastpath works by first checking if the lockless freelist can be used.
|
|
|
* If not then __slab_alloc is called for slow processing.
|
|
|
*
|
|
|
* Otherwise we can simply pick the next object from the lockless free list.
|
|
|
*/
|
|
|
static __always_inline void *slab_alloc_node(struct kmem_cache *s,
|
|
|
gfp_t gfpflags, int node, unsigned long addr)
|
|
|
{
|
|
|
void *object;
|
|
|
struct kmem_cache_cpu *c;
|
|
|
struct page *page;
|
|
|
unsigned long tid;
|
|
|
......
|
|
|
tid = this_cpu_read(s->cpu_slab->tid);
|
|
|
c = raw_cpu_ptr(s->cpu_slab);
|
|
|
......
|
|
|
object = c->freelist;
|
|
|
page = c->page;
|
|
|
if (unlikely(!object || !node_match(page, node))) {
|
|
|
object = __slab_alloc(s, gfpflags, node, addr, c);
|
|
|
stat(s, ALLOC_SLOWPATH);
|
|
|
}
|
|
|
......
|
|
|
return object;
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
快速通道很简单,取出cpu\_slab也即kmem\_cache\_cpu的freelist,这就是第一个空闲的项,可以直接返回了。如果没有空闲的了,则只好进入普通通道,调用\_\_slab\_alloc。
|
|
|
|
|
|
```
|
|
|
static void *___slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node,
|
|
|
unsigned long addr, struct kmem_cache_cpu *c)
|
|
|
{
|
|
|
void *freelist;
|
|
|
struct page *page;
|
|
|
......
|
|
|
redo:
|
|
|
......
|
|
|
/* must check again c->freelist in case of cpu migration or IRQ */
|
|
|
freelist = c->freelist;
|
|
|
if (freelist)
|
|
|
goto load_freelist;
|
|
|
|
|
|
|
|
|
freelist = get_freelist(s, page);
|
|
|
|
|
|
|
|
|
if (!freelist) {
|
|
|
c->page = NULL;
|
|
|
stat(s, DEACTIVATE_BYPASS);
|
|
|
goto new_slab;
|
|
|
}
|
|
|
|
|
|
|
|
|
load_freelist:
|
|
|
c->freelist = get_freepointer(s, freelist);
|
|
|
c->tid = next_tid(c->tid);
|
|
|
return freelist;
|
|
|
|
|
|
|
|
|
new_slab:
|
|
|
|
|
|
|
|
|
if (slub_percpu_partial(c)) {
|
|
|
page = c->page = slub_percpu_partial(c);
|
|
|
slub_set_percpu_partial(c, page);
|
|
|
stat(s, CPU_PARTIAL_ALLOC);
|
|
|
goto redo;
|
|
|
}
|
|
|
|
|
|
|
|
|
freelist = new_slab_objects(s, gfpflags, node, &c);
|
|
|
......
|
|
|
return freeli
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
在这里,我们首先再次尝试一下kmem\_cache\_cpu的freelist。为什么呢?万一当前进程被中断,等回来的时候,别人已经释放了一些缓存,说不定又有空间了呢。如果找到了,就跳到load\_freelist,在这里将freelist指向下一个空闲项,返回就可以了。
|
|
|
|
|
|
如果freelist还是没有,则跳到new\_slab里面去。这里面我们先去kmem\_cache\_cpu的partial里面看。如果partial不是空的,那就将kmem\_cache\_cpu的page,也就是快速通道的那一大块内存,替换为partial里面的大块内存。然后redo,重新试下。这次应该就可以成功了。
|
|
|
|
|
|
如果真的还不行,那就要到new\_slab\_objects了。
|
|
|
|
|
|
```
|
|
|
static inline void *new_slab_objects(struct kmem_cache *s, gfp_t flags,
|
|
|
int node, struct kmem_cache_cpu **pc)
|
|
|
{
|
|
|
void *freelist;
|
|
|
struct kmem_cache_cpu *c = *pc;
|
|
|
struct page *page;
|
|
|
|
|
|
|
|
|
freelist = get_partial(s, flags, node, c);
|
|
|
|
|
|
|
|
|
if (freelist)
|
|
|
return freelist;
|
|
|
|
|
|
|
|
|
page = new_slab(s, flags, node);
|
|
|
if (page) {
|
|
|
c = raw_cpu_ptr(s->cpu_slab);
|
|
|
if (c->page)
|
|
|
flush_slab(s, c);
|
|
|
|
|
|
|
|
|
freelist = page->freelist;
|
|
|
page->freelist = NULL;
|
|
|
|
|
|
|
|
|
stat(s, ALLOC_SLAB);
|
|
|
c->page = page;
|
|
|
*pc = c;
|
|
|
} else
|
|
|
freelist = NULL;
|
|
|
|
|
|
|
|
|
return freelis
|
|
|
|
|
|
```
|
|
|
|
|
|
在这里面,get\_partial会根据node id,找到相应的kmem\_cache\_node,然后调用get\_partial\_node,开始在这个节点进行分配。
|
|
|
|
|
|
```
|
|
|
/*
|
|
|
* Try to allocate a partial slab from a specific node.
|
|
|
*/
|
|
|
static void *get_partial_node(struct kmem_cache *s, struct kmem_cache_node *n,
|
|
|
struct kmem_cache_cpu *c, gfp_t flags)
|
|
|
{
|
|
|
struct page *page, *page2;
|
|
|
void *object = NULL;
|
|
|
int available = 0;
|
|
|
int objects;
|
|
|
......
|
|
|
list_for_each_entry_safe(page, page2, &n->partial, lru) {
|
|
|
void *t;
|
|
|
|
|
|
|
|
|
t = acquire_slab(s, n, page, object == NULL, &objects);
|
|
|
if (!t)
|
|
|
break;
|
|
|
|
|
|
|
|
|
available += objects;
|
|
|
if (!object) {
|
|
|
c->page = page;
|
|
|
stat(s, ALLOC_FROM_PARTIAL);
|
|
|
object = t;
|
|
|
} else {
|
|
|
put_cpu_partial(s, page, 0);
|
|
|
stat(s, CPU_PARTIAL_NODE);
|
|
|
}
|
|
|
if (!kmem_cache_has_cpu_partial(s)
|
|
|
|| available > slub_cpu_partial(s) / 2)
|
|
|
break;
|
|
|
}
|
|
|
......
|
|
|
return object;
|
|
|
|
|
|
```
|
|
|
|
|
|
acquire\_slab会从kmem\_cache\_node的partial链表中拿下一大块内存来,并且将freelist,也就是第一块空闲的缓存块,赋值给t。并且当第一轮循环的时候,将kmem\_cache\_cpu的page指向取下来的这一大块内存,返回的object就是这块内存里面的第一个缓存块t。如果kmem\_cache\_cpu也有一个partial,就会进行第二轮,再次取下一大块内存来,这次调用put\_cpu\_partial,放到kmem\_cache\_cpu的partial里面。
|
|
|
|
|
|
如果kmem\_cache\_node里面也没有空闲的内存,这就说明原来分配的页里面都放满了,就要回到new\_slab\_objects函数,里面new\_slab函数会调用allocate\_slab。
|
|
|
|
|
|
```
|
|
|
static struct page *allocate_slab(struct kmem_cache *s, gfp_t flags, int node)
|
|
|
{
|
|
|
struct page *page;
|
|
|
struct kmem_cache_order_objects oo = s->oo;
|
|
|
gfp_t alloc_gfp;
|
|
|
void *start, *p;
|
|
|
int idx, order;
|
|
|
bool shuffle;
|
|
|
|
|
|
|
|
|
flags &= gfp_allowed_mask;
|
|
|
......
|
|
|
page = alloc_slab_page(s, alloc_gfp, node, oo);
|
|
|
if (unlikely(!page)) {
|
|
|
oo = s->min;
|
|
|
alloc_gfp = flags;
|
|
|
/*
|
|
|
* Allocation may have failed due to fragmentation.
|
|
|
* Try a lower order alloc if possible
|
|
|
*/
|
|
|
page = alloc_slab_page(s, alloc_gfp, node, oo);
|
|
|
if (unlikely(!page))
|
|
|
goto out;
|
|
|
stat(s, ORDER_FALLBACK);
|
|
|
}
|
|
|
......
|
|
|
return page;
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
在这里,我们看到了alloc\_slab\_page分配页面。分配的时候,要按kmem\_cache\_order\_objects里面的order来。如果第一次分配不成功,说明内存已经很紧张了,那就换成min版本的kmem\_cache\_order\_objects。
|
|
|
|
|
|
好了,这个复杂的层层分配机制,我们就讲到这里,你理解到这里也就够用了。
|
|
|
|
|
|
## 页面换出
|
|
|
|
|
|
另一个物理内存管理必须要处理的事情就是,页面换出。每个进程都有自己的虚拟地址空间,无论是32位还是64位,虚拟地址空间都非常大,物理内存不可能有这么多的空间放得下。所以,一般情况下,页面只有在被使用的时候,才会放在物理内存中。如果过了一段时间不被使用,即便用户进程并没有释放它,物理内存管理也有责任做一定的干预。例如,将这些物理内存中的页面换出到硬盘上去;将空出的物理内存,交给活跃的进程去使用。
|
|
|
|
|
|
什么情况下会触发页面换出呢?
|
|
|
|
|
|
可以想象,最常见的情况就是,分配内存的时候,发现没有地方了,就试图回收一下。例如,咱们解析申请一个页面的时候,会调用get\_page\_from\_freelist,接下来的调用链为get\_page\_from\_freelist->node\_reclaim->\_\_node\_reclaim->shrink\_node,通过这个调用链可以看出,页面换出也是以内存节点为单位的。
|
|
|
|
|
|
当然还有一种情况,就是作为内存管理系统应该主动去做的,而不能等真的出了事儿再做,这就是内核线程**kswapd**。这个内核线程,在系统初始化的时候就被创建。这样它会进入一个无限循环,直到系统停止。在这个循环中,如果内存使用没有那么紧张,那它就可以放心睡大觉;如果内存紧张了,就需要去检查一下内存,看看是否需要换出一些内存页。
|
|
|
|
|
|
```
|
|
|
/*
|
|
|
* The background pageout daemon, started as a kernel thread
|
|
|
* from the init process.
|
|
|
*
|
|
|
* This basically trickles out pages so that we have _some_
|
|
|
* free memory available even if there is no other activity
|
|
|
* that frees anything up. This is needed for things like routing
|
|
|
* etc, where we otherwise might have all activity going on in
|
|
|
* asynchronous contexts that cannot page things out.
|
|
|
*
|
|
|
* If there are applications that are active memory-allocators
|
|
|
* (most normal use), this basically shouldn't matter.
|
|
|
*/
|
|
|
static int kswapd(void *p)
|
|
|
{
|
|
|
unsigned int alloc_order, reclaim_order;
|
|
|
unsigned int classzone_idx = MAX_NR_ZONES - 1;
|
|
|
pg_data_t *pgdat = (pg_data_t*)p;
|
|
|
struct task_struct *tsk = current;
|
|
|
|
|
|
|
|
|
for ( ; ; ) {
|
|
|
......
|
|
|
kswapd_try_to_sleep(pgdat, alloc_order, reclaim_order,
|
|
|
classzone_idx);
|
|
|
......
|
|
|
reclaim_order = balance_pgdat(pgdat, alloc_order, classzone_idx);
|
|
|
......
|
|
|
}
|
|
|
}
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
这里的调用链是balance\_pgdat->kswapd\_shrink\_node->shrink\_node,是以内存节点为单位的,最后也是调用shrink\_node。
|
|
|
|
|
|
shrink\_node会调用shrink\_node\_memcg。这里面有一个循环处理页面的列表,看这个函数的注释,其实和上面我们想表达的内存换出是一样的。
|
|
|
|
|
|
```
|
|
|
/*
|
|
|
* This is a basic per-node page freer. Used by both kswapd and direct reclaim.
|
|
|
*/
|
|
|
static void shrink_node_memcg(struct pglist_data *pgdat, struct mem_cgroup *memcg,
|
|
|
struct scan_control *sc, unsigned long *lru_pages)
|
|
|
{
|
|
|
......
|
|
|
unsigned long nr[NR_LRU_LISTS];
|
|
|
enum lru_list lru;
|
|
|
......
|
|
|
while (nr[LRU_INACTIVE_ANON] || nr[LRU_ACTIVE_FILE] ||
|
|
|
nr[LRU_INACTIVE_FILE]) {
|
|
|
unsigned long nr_anon, nr_file, percentage;
|
|
|
unsigned long nr_scanned;
|
|
|
|
|
|
|
|
|
for_each_evictable_lru(lru) {
|
|
|
if (nr[lru]) {
|
|
|
nr_to_scan = min(nr[lru], SWAP_CLUSTER_MAX);
|
|
|
nr[lru] -= nr_to_scan;
|
|
|
|
|
|
|
|
|
nr_reclaimed += shrink_list(lru, nr_to_scan,
|
|
|
lruvec, memcg, sc);
|
|
|
}
|
|
|
}
|
|
|
......
|
|
|
}
|
|
|
......
|
|
|
|
|
|
```
|
|
|
|
|
|
这里面有个lru列表。从下面的定义,我们可以想象,所有的页面都被挂在LRU列表中。LRU是Least Recent Use,也就是最近最少使用。也就是说,这个列表里面会按照活跃程度进行排序,这样就容易把不怎么用的内存页拿出来做处理。
|
|
|
|
|
|
内存页总共分两类,一类是**匿名页**,和虚拟地址空间进行关联;一类是**内存映射**,不但和虚拟地址空间关联,还和文件管理关联。
|
|
|
|
|
|
它们每一类都有两个列表,一个是active,一个是inactive。顾名思义,active就是比较活跃的,inactive就是不怎么活跃的。这两个里面的页会变化,过一段时间,活跃的可能变为不活跃,不活跃的可能变为活跃。如果要换出内存,那就是从不活跃的列表中找出最不活跃的,换出到硬盘上。
|
|
|
|
|
|
```
|
|
|
enum lru_list {
|
|
|
LRU_INACTIVE_ANON = LRU_BASE,
|
|
|
LRU_ACTIVE_ANON = LRU_BASE + LRU_ACTIVE,
|
|
|
LRU_INACTIVE_FILE = LRU_BASE + LRU_FILE,
|
|
|
LRU_ACTIVE_FILE = LRU_BASE + LRU_FILE + LRU_ACTIVE,
|
|
|
LRU_UNEVICTABLE,
|
|
|
NR_LRU_LISTS
|
|
|
};
|
|
|
|
|
|
|
|
|
#define for_each_evictable_lru(lru) for (lru = 0; lru <= LRU_ACTIVE_FILE; lru++)
|
|
|
|
|
|
|
|
|
static unsigned long shrink_list(enum lru_list lru, unsigned long nr_to_scan,
|
|
|
struct lruvec *lruvec, struct mem_cgroup *memcg,
|
|
|
struct scan_control *sc)
|
|
|
{
|
|
|
if (is_active_lru(lru)) {
|
|
|
if (inactive_list_is_low(lruvec, is_file_lru(lru),
|
|
|
memcg, sc, true))
|
|
|
shrink_active_list(nr_to_scan, lruvec, sc, lru);
|
|
|
return 0;
|
|
|
}
|
|
|
|
|
|
|
|
|
return shrink_inactive_list(nr_to_scan, lruvec, sc, lru);
|
|
|
|
|
|
```
|
|
|
|
|
|
从上面的代码可以看出,shrink\_list会先缩减活跃页面列表,再压缩不活跃的页面列表。对于不活跃列表的缩减,shrink\_inactive\_list就需要对页面进行回收;对于匿名页来讲,需要分配swap,将内存页写入文件系统;对于内存映射关联了文件的,我们需要将在内存中对于文件的修改写回到文件中。
|
|
|
|
|
|
## 总结时刻
|
|
|
|
|
|
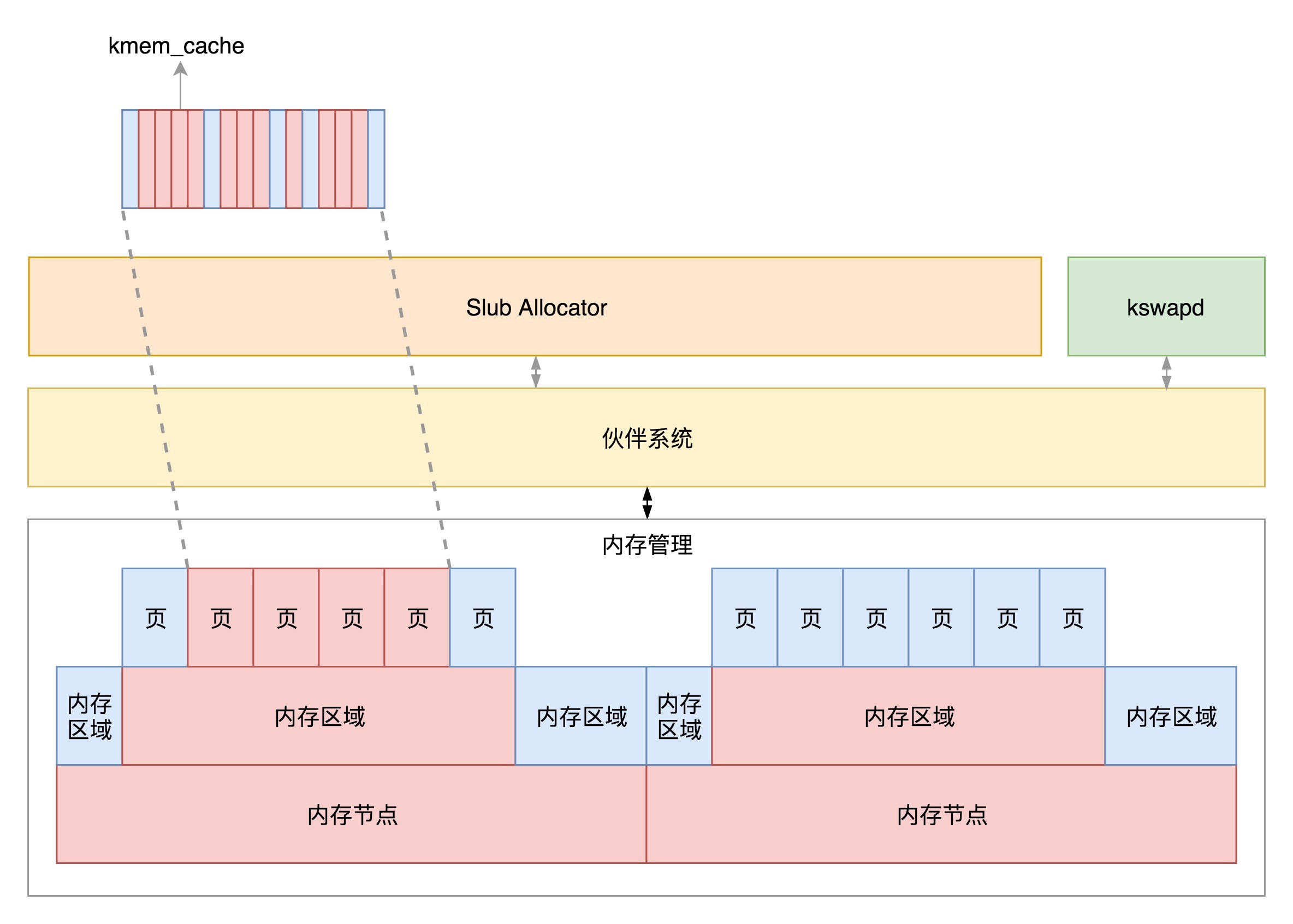
好了,对于物理内存的管理就讲到这里了,我们来总结一下。对于物理内存来讲,从下层到上层的关系及分配模式如下:
|
|
|
|
|
|
* 物理内存分NUMA节点,分别进行管理;
|
|
|
|
|
|
* 每个NUMA节点分成多个内存区域;
|
|
|
|
|
|
* 每个内存区域分成多个物理页面;
|
|
|
|
|
|
* 伙伴系统将多个连续的页面作为一个大的内存块分配给上层;
|
|
|
|
|
|
* kswapd负责物理页面的换入换出;
|
|
|
|
|
|
* Slub Allocator将从伙伴系统申请的大内存块切成小块,分配给其他系统。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
## 课堂练习
|
|
|
|
|
|
内存的换入和换出涉及swap分区,那你知道如何检查当前swap分区情况,如何启用和关闭swap区域,如何调整swappiness吗?
|
|
|
|
|
|
欢迎留言和我分享你的疑惑和见解,也欢迎你收藏本节内容,反复研读。你也可以把今天的内容分享给你的朋友,和他一起学习、进步。
|
|
|
|
|
|

|
|
|
|