|
|
# 25|找准方向:如何建立有效的测试度量体系?
|
|
|
|
|
|
你好,我是柳胜。
|
|
|
|
|
|
提到数据度量、数据驱动这些词,我们并不陌生。无论是管理领域用来追踪业绩的KPI、OKR,还是商业中用数据来做最优决策的Business Intelligence,都用到了数据驱动的方法。
|
|
|
|
|
|
而在我们IT领域,管理大师彼得·格鲁克就曾说过:“You can’t improve what you cannot measure”,意思是如果你不能度量一件事情,你就不知道怎么去优化改进它。
|
|
|
|
|
|
既然数据驱动方法论已经深入人心,自动化测试领域也自然不会错过它。我们遇到的很多困境,其根源都要归结到数据不可见上,或者数据虽然可见,我们却不知道如何科学利用。比如常见的困难就有:管理者对自动化测试没什么信心,所以投入并不稳定;测试设计者也不清楚拿到了资源,自动化测试应该投入到哪个领域,分别投入多少才合适。
|
|
|
|
|
|
所以,在度量篇我们的目标就是把数据度量方法用起来,这样才能真正通过数据驱动测试的改进和提升。
|
|
|
|
|
|
前面Job模型的学习中,我们通常都是自顶向下,按照现状、目的、任务拆解,一直细化到实现层面。这节课思路也一样,自动化测试数据度量的关键问题如下:
|
|
|
|
|
|
1.为什么需要数据度量?
|
|
|
2.围绕目标,怎么建立有效的测试度量体系?
|
|
|
3.测试度量指标设计要遵循哪些原则?
|
|
|
|
|
|
解决了这几个问题,度量活动的整体脉络就有了,实际工作里才能有的放矢。
|
|
|
|
|
|
## 为什么需要数据度量?
|
|
|
|
|
|
在我看来,数据度量是自动化测试走向成熟阶段的标志。想要弄清楚为什么要花费时间精力,来做数据度量这件事,我们不妨追本溯源,从自动化测试的发展阶段说起。
|
|
|
|
|
|
如果你的团队自动化测试刚开始起步,有几个繁琐易错的测试场景需要自动化,比如,要测试在不同平台下安装软件客户端,要生成测试数据。
|
|
|
|
|
|
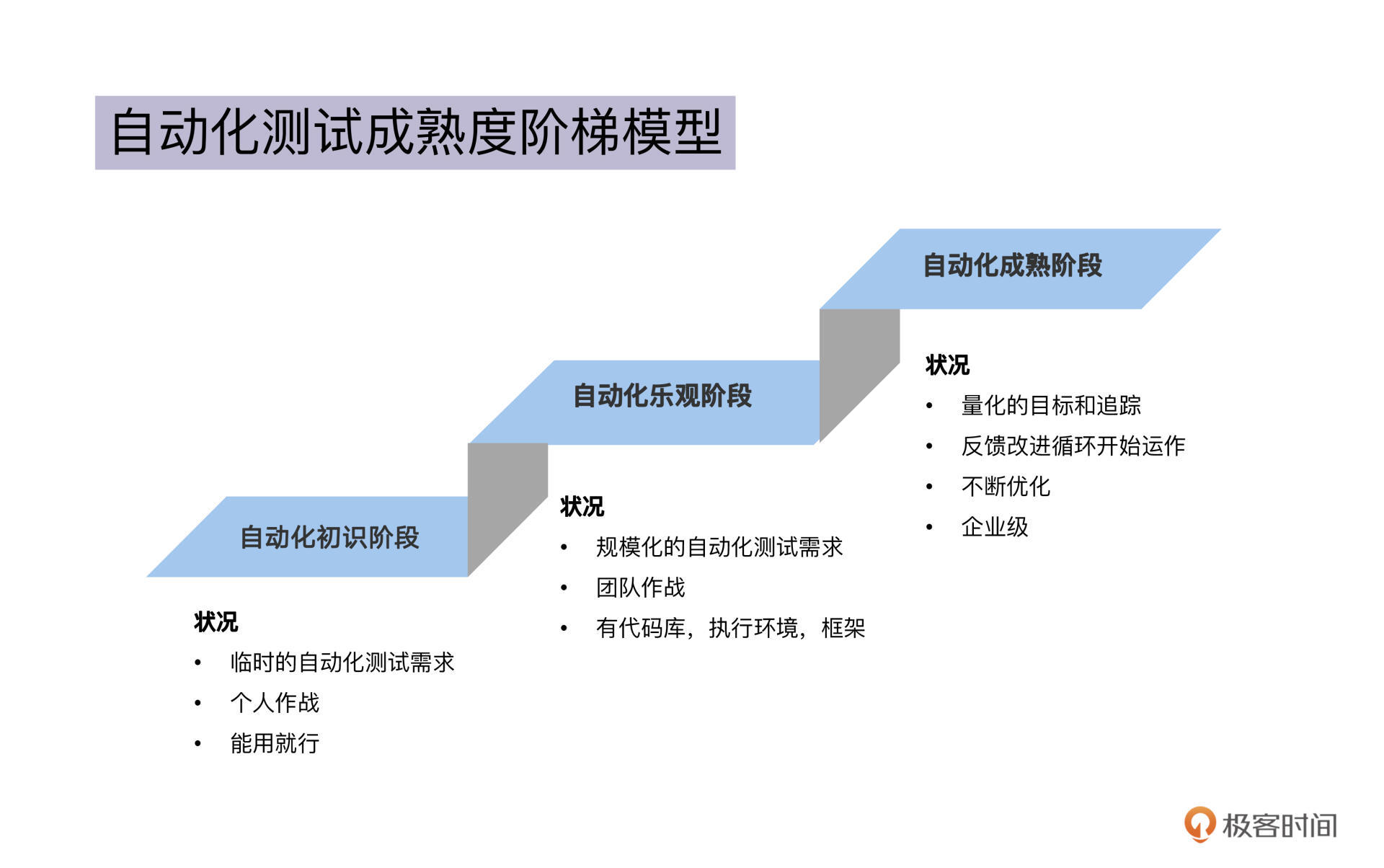
这时,你发愁的是,怎么帮助团队掌握如何使用工具,把手工案例转化成自动化测试案例。我管这个阶段叫做“**自动化初识阶段**”。
|
|
|
|
|
|
这个阶段的特点是这样的:自动化测试的需求是偶发的、临时起意的,一两个人负责自动化测试的实施,选型工具也没啥策略,开发出来的测试脚本能跑起来就行。
|
|
|
|
|
|
而随着产品规模扩大,测试案例越来越多,对自动化测试的需求也会增加,不再局限于一两个特定场景,开始建立冒烟测试自动化集合,多个团队小组都开始实施自动化测试。
|
|
|
|
|
|
到了这个时候,你会看到不同的测试需求,也看到了更多的自动化测试工具和框架,相应也会涉及到工具选型、自动化测试环境搭建的工作。我管这个阶段叫做“**自动化乐观阶段**”。
|
|
|
|
|
|
面对自动化测试的投入增大,领导的殷切期望,团队的学习热情,你可能心里会生出一点担忧“我们这样投入,自动化测试能带来质量提升么,能节约成本么”。
|
|
|
|
|
|
为了控制成本,你开始关注团队间工具能否通用、代码能否复用。不过,还是不清楚自动化测试做到什么程度才合适。
|
|
|
|
|
|
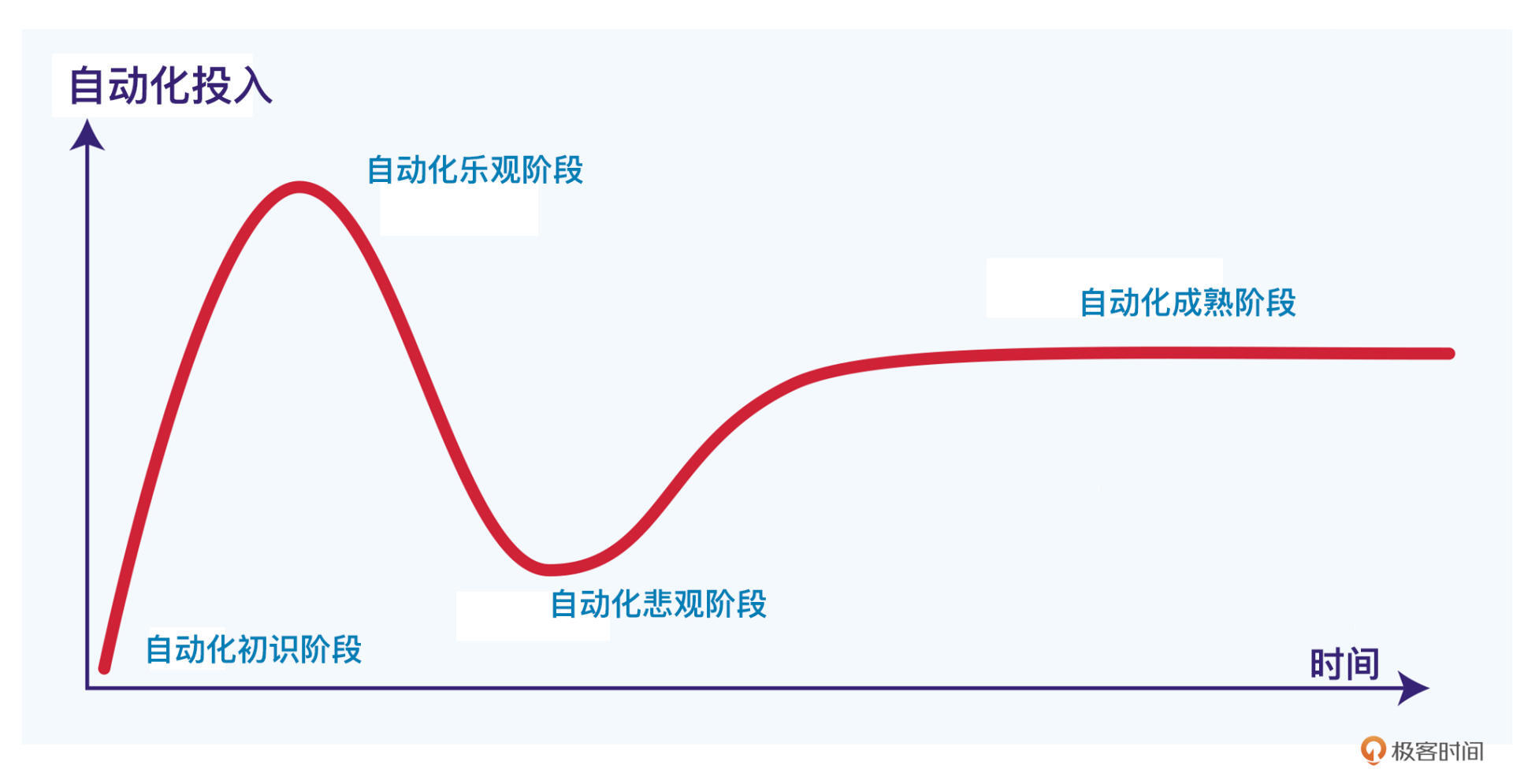
我再次引用加特纳技术成熟度曲线,它会告诉我们在自动化测试乐观阶段之后,会发生什么。
|
|
|
|
|
|
|
|
|
|
|
|
自动化测试乐观阶段的特点是,团队热情高,投入大,甚至有的测试组织都提出100%自动化的目标。但理想和现实总会有差距,当自动化实际的产出,没有达到对自动化测试预期的时候,我们就很容易进入到“自动化测试悲观阶段”,觉得自动化测试是糊弄人的,华而不实,还不如用一个自动化测试工程师的成本,去多招两个手工测试的人手。
|
|
|
|
|
|
这种认知的反差并不稀奇,往往就发生在同一个人身上,同一个测试组织里。前面乐观情绪有多高,后面悲观情绪就有多低落。
|
|
|
|
|
|
结合上面的曲线图,经历了乐观阶段和悲观阶段,我们怎么走向“自动化测试的成熟”阶段呢?这是一个很关键的门槛,推开了这扇大门,就进入到一个新的世界,对自动化测试的认识成熟理性,实践稳步提升,进入到一个正反馈的循环中。
|
|
|
|
|
|
其实,开启这扇大门的钥匙就是数据驱动。当乐观和悲观都解决不了问题的时候,数据才能让我们认清现实,从而找到解决问题之道。
|
|
|
|
|
|
|
|
|
|
|
|
## 度量什么?
|
|
|
|
|
|
确立了数据度量的必要性,接下来就到了细化方向、建立指标的环节。
|
|
|
|
|
|
度量什么?这是一个好问题。建立一个度量指标,相当于在团队立了flag,如果这个flag立得不对,就会误导团队。
|
|
|
|
|
|
我也见过有些团队上来就立“军令状”,发誓单元测试覆盖率要达到80%,然后一顿操作猛如虎,开发测试全员加班加点,心中叫苦。也许后面覆盖率确实达到了定下的指标,但单元测试自上线起,从未捕捉到回归Bug,软件交付质量也不见提升。
|
|
|
|
|
|
可见度量flag的建立是一个技术活,最终要看指标对软件质量的提升有没有帮助。如果制定得不合理,就会竹篮打水一场空。怎么合理设立度量指标呢?我们需要先拆解软件质量包括哪些方面。
|
|
|
|
|
|
### 交付质量度量
|
|
|
|
|
|
软件质量体系,可以分为交付质量和内建质量。交付质量是结果,内建质量是过程。做好过程是为了得到好的结果。像我们前面做好设计,写好代码与测试案例,科学实施自动化测试,它们都是内建质量活动,最终都是为了提升交付质量。
|
|
|
|
|
|
所以,我们首先要把交付质量的度量先定下来,就相当于抛出一个锚,而内建度量就可以向它看齐了。
|
|
|
|
|
|
对于交付质量,我们最常用的度量指标就是生产环境Bug数量。这个也很简单直观,把软件交付给用户之后,用户发现的bug越多,说明质量越差,能做到0Bug,那说明质量最好。
|
|
|
|
|
|
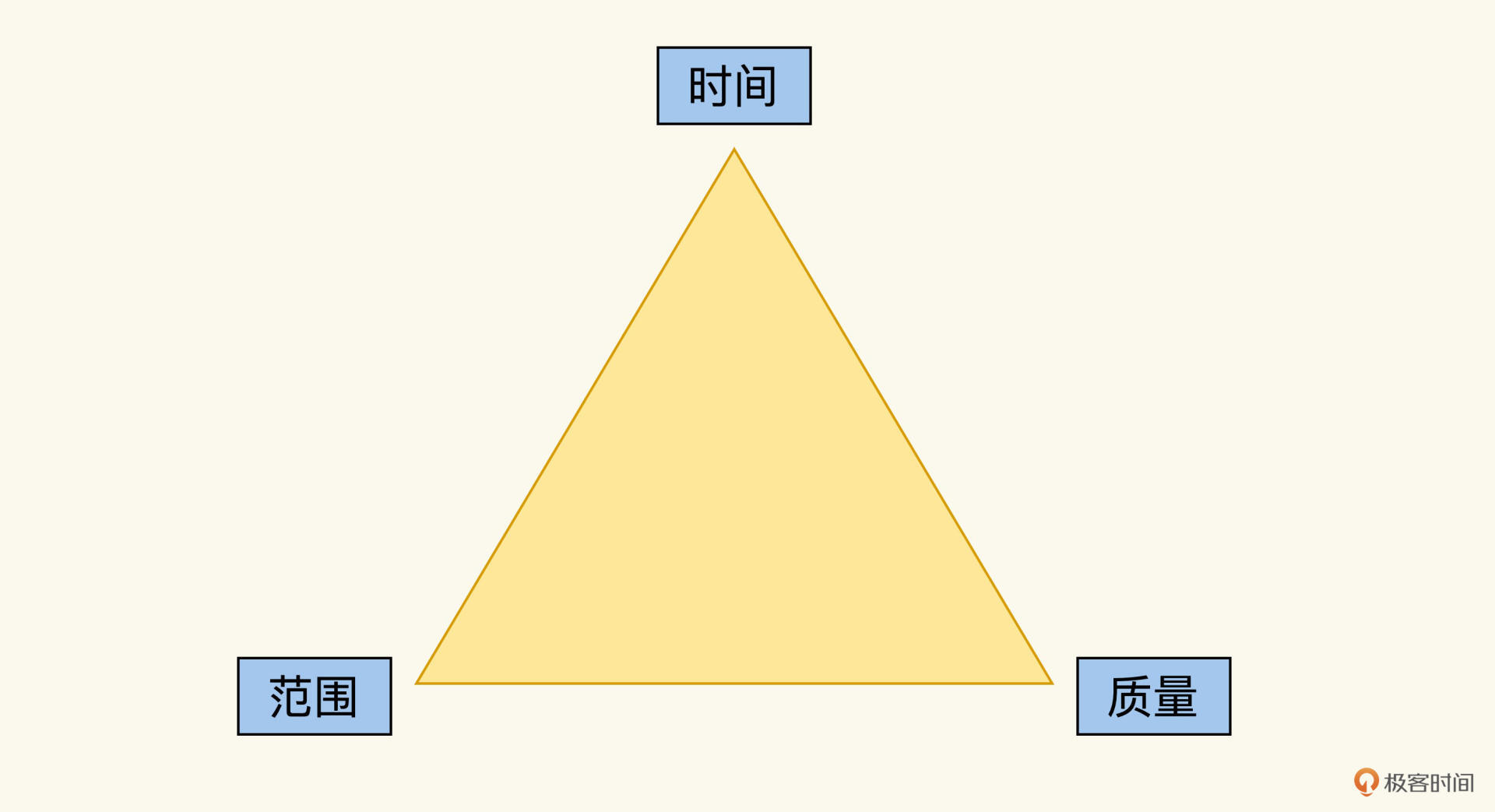
但生产环境的Bug数量,跟发布多少功能以及发布速度都有关系。我用一个质量三角图来说明这三者之间的关系:
|
|
|
|
|
|
|
|
|
|
|
|
这三个因素中有一个因素发生变化,就会影响其他两个因素。比如,老板有一天说,为了抢占市场,我们这个产品要提前10天发布,这时三角形的时间发生了变化,那就要影响三角形的其它两边,要么缩小功能的范围,要么就要接受Bug增多的质量风险。
|
|
|
|
|
|
而我们交付质量的目标是在不损失其他两个因素的情况下,来提升质量。所以,我们在度量交付质量的时候,这三个因素都需要观测。我们后面就可以用这三个指标来代表交付质量。
|
|
|
|
|
|
1.交付速度,是版本迭代的速度,我们可以用发布的周期来度量。
|
|
|
|
|
|
2.交付范围,是新功能的规模,可以用新增代码行数来度量。
|
|
|
|
|
|
3.质量,用生产环境发现的Bug数量来度量。
|
|
|
|
|
|
从交付质量的这三个度量指标中,我们可以看到,自动化测试是能够提升这三个指标的。自动化测试的程度高,覆盖的功能越广,可以大面积回归,质量就能得到保证。而自动化测试执行速度也快,这样交付时间也会缩短。
|
|
|
|
|
|
交付质量的度量指标确定了后,相当于目标确定了。我们下面来看一下内建质量该怎么度量。
|
|
|
|
|
|
### 内建质量度量
|
|
|
|
|
|
交付质量是果,内建质量是因。而且是多因一果。软件研发又是一个复杂的活动,里面任何一个环节没做好,都有可能影响最终质量。
|
|
|
|
|
|
俄国文豪托尔斯泰曾经说过一句流传很广的话“幸福的家庭是相似的,不幸的家庭各有各的不幸”,换到软件质量领域也一样。你可以想想木桶理论。木桶是由多个木板组合而成的,木桶能装多少水,通常取决于短板。因为只要有一个短板,木桶的水就会流出来。
|
|
|
|
|
|
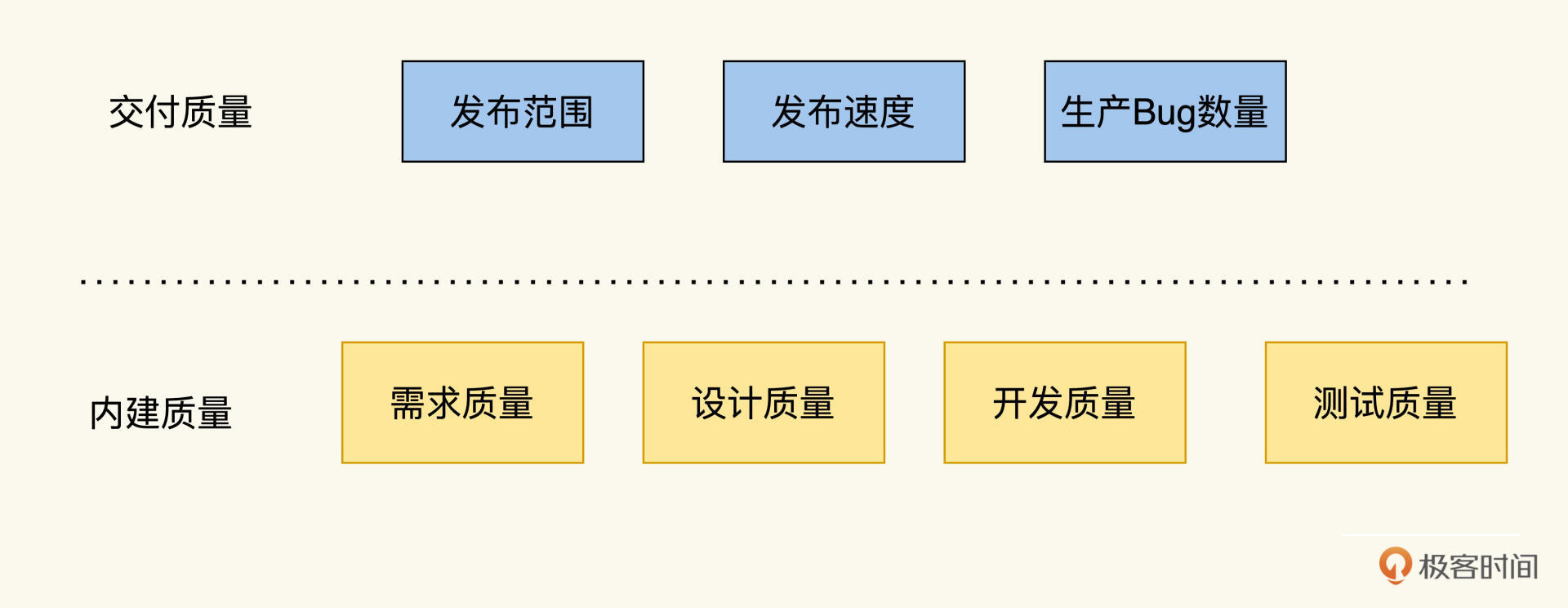
内建质量活动就相当于这些木桶板,内建质量的提升,就是要找出那块短板,把它加长。但内建质量的木板是很多的,大方面有人员、流程、技术栈,细节上有代码的实现,以及配置文件的读写等等。在这么多木板中,你怎么找出这块短板呢?
|
|
|
|
|
|
学过Job模型后,你应该掌握了一个把复杂问题简单化的解决思路。那就是先做划分,再定位实现。
|
|
|
|
|
|
|
|
|
|
|
|
内建质量可以划分成四个维度:需求质量、设计质量、开发质量和测试质量。每个维度展开以后,都是一组度量指标。
|
|
|
|
|
|
我们今天以测试质量为例,来研究一下这个领域的度量指标的设定。掌握这个思路,其他领域你也能触类旁通。
|
|
|
|
|
|
## 测试活动的度量
|
|
|
|
|
|
在设计测试活动度量之前,让我们以终为始,先想清楚,测试活动的结果输出是什么?什么样的输出能够促进交付质量的提升?换句话说就是,我们怎么评价一个测试活动是“很棒”的,还是“很差劲”的呢?
|
|
|
|
|
|
你可能想到,交付质量里有一个指标“生产环境发现的Bug数量”,把这个指标作为测试有效性的评价指标不就可以了么?
|
|
|
|
|
|
如果这样想,其实你就进入了一个“测试组织对最终质量负责”的思维误区。因为Bug的绝对数量增加,因素也很多。
|
|
|
|
|
|
比如,在这个Release 项目新加的功能多,开发代码变动大,引发Bug就多,这不是测试团队能控制的,既然不能控制,当然就没办法对它的结果负责,你也不能用它来驱动测试活动的提升。
|
|
|
|
|
|
怎么评价测试的有效性呢?这时我想提醒你,注意度量设计的一个原则,**尽量不要以绝对数字来判断好和坏**。
|
|
|
|
|
|
可是不用绝对数字,应该用什么呢?结合我的实践经验,为了衡量测试活动的有效性,可以设定以下指标,你可以做个参考:
|
|
|
|
|
|
* Bug泄漏率=生产环境的Bug数量/Bug总数量
|
|
|
* 冒烟测试Bug泄漏率=生产环境的关键Bug/关键Bug总数量
|
|
|
* 测试需求覆盖率=被测试的需求条数/总需求条数
|
|
|
* 测试执行效率=自动化测试的案例/总共测试案例
|
|
|
|
|
|
这几个指标都有一个共同的特点,它们都是用两个数字的比率来做度量,而不是用一个绝对数字。数字的比率可以消除绝对数字的笼统性,比如,影响Bug总数的因素很多,所以你很难用Bug总数来说事,但是把Bug归因到各个过程所占的比例,像是需求Bug比、设计Bug比、代码Bug比等等,就能说明一些问题了。
|
|
|
|
|
|
这个思路,不光用数字的比率,我们也可以用数字的差做度量,这种度量方法我会在第二十七讲里详细展开。
|
|
|
|
|
|
另外,上面的这四个指标之间也是有逻辑关系的,它评价测试的效果,也是从测试的范围(测试需求覆盖率),时间(执行效率),质量(Bug泄漏率),这三点支撑的一个度量体系。
|
|
|
|
|
|
**避免指标单一化**,其实也是一个度量设计的原则,也就是说,不要从单一指标来评价。尤其有的组织习惯于把指标和绩效挂钩,可是实际上往往事与愿违,容易引发执行者不假思索地机械化工作,甚至弄虚作假。
|
|
|
|
|
|
自动化测试作为测试活动下面的一个子活动,我们该怎么度量呢?随着度量指标从上到下的细化,越细化,目标就越具体,也更加问题导向,便于落地。
|
|
|
|
|
|
到这里,测试活动的度量框架我们就建立了。度量篇的后面几节课,我会从单元测试度量设计,自动化测试度量设计,自动化测试关键问题可信性度量几个方面深入解析,带你系统掌握自动化测试的度量思路与方法。
|
|
|
|
|
|
## 小结
|
|
|
|
|
|
现在来回顾一下今天学习的内容,学完了正文,开篇的三大问题想必你也找到了答案。
|
|
|
|
|
|
第一个问题就是为什么要做度量?当团队和产品的规模和复杂度都在增大的时候,我们很难对它有清楚的把握,如果不加以梳理,就会走向混乱的败局。
|
|
|
|
|
|
怎么理呢?方法就是数据度量。只有由数据得来的信息,才能支撑下一步的行动,确保我们的决策有助于优化、提升产品,而不是做无用功、甚至越改越糟。
|
|
|
|
|
|
每个行业领域都服从这样的规律,自动化测试也不例外,要想从自动化测试盲目乐观和盲目悲观中走向成熟,那就要掌握数据驱动这个方法论。
|
|
|
|
|
|
为了更好地让你理解质量度量体系。我把它从头展开,从交付质量到内建质量,然后从内建质量再分解到各个活动中去。每一层级是上一级的实现,又是下一级的目标。这跟Job模型的思维非常相似。我把这个度量体系画出来,就是这个样子:
|
|
|
|
|
|
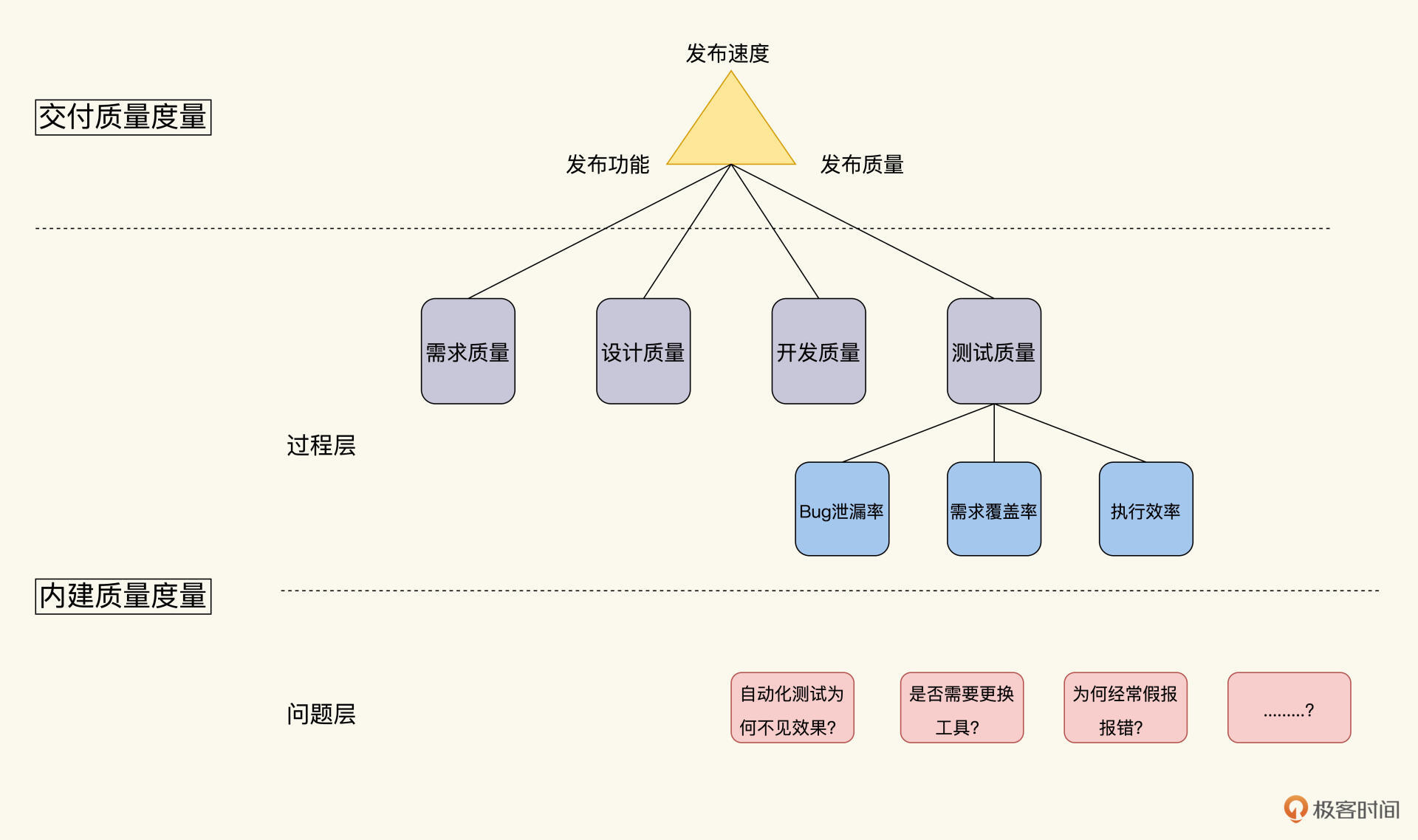
|
|
|
|
|
|
这里质量体系我们之所以用树形结构表达,是为了强调上下级的关系。根结点是交付质量,只要这个总目标不变,内建质量的度量点你可以根据组织和项目情况,灵活变化。
|
|
|
|
|
|
那怎么衡量你的度量是有效的呢?只要每一层的度量指标,都能促进上一层度量目标的积极变化就行。否则,就需要更改或寻找新的度量。
|
|
|
|
|
|
另外,在质量度量体系分解的过程中,需要遵循两个度量指标的设计原则:**第一,避免绝对数字**;**第二,避免单一**。这都来自于我和团队的实践经验,希望也能帮助你排忧解难。在后续的章节中,我还会陆续提到其它原则,到最后一讲,我还会为你再总结一下。
|
|
|
|
|
|
下一讲,我们要从单元测试的实际场景,去发现怎么定义合理的指标,敬请期待。
|
|
|
|
|
|
## 思考题
|
|
|
|
|
|
在你的组织中,有没有量化的指标?能否分享一下,你觉得好用的指标,或者不好用的指标呢?
|
|
|
|
|
|
欢迎你在留言区跟我交流互动。如果觉得今天讲的方法对你有启发,也推荐你分享给更多朋友、同事。
|
|
|
|