|
|
# 22|设计实战(二): 一个全周期自动化测试Pipeline的设计
|
|
|
|
|
|
你好,我是柳胜。
|
|
|
|
|
|
说起交付流水线,你可能立马想到的是Jenkins或CloudBees这些工具,它们实现了从Code Build到最终部署到Production环境的全过程。
|
|
|
|
|
|
但Jenkins只是工具,一个Pipeline到底需要多少个Job,每个Job都是什么样的,这些问题Jenkins是回答不了的,需要使用工具的工程师去思考去设计。在实践中,通常是DevOps工程师来做这个设计。
|
|
|
|
|
|
既然我们学习了微测试Job模型,也知道了它能帮助我们去做自动化测试设计,那用这个模型,能不能帮我们做Pipeline设计呢?**其实,Pipeline本质上也是一个自动化测试方案,只不过它解决的场景是把软件从代码端到生产端的自动化。**
|
|
|
|
|
|
掌握设计思维是测试工程师向测试架构师的必由之路,假设今天你需要设计一个Pipeline,把一个Example Service的代码,最终部署成为生产环境的一个服务进程。完成这个工作,你不仅能弄明白CICD的原理和实现,而且对自动化测试Job怎么集成到CICD,也将了如指掌。
|
|
|
|
|
|
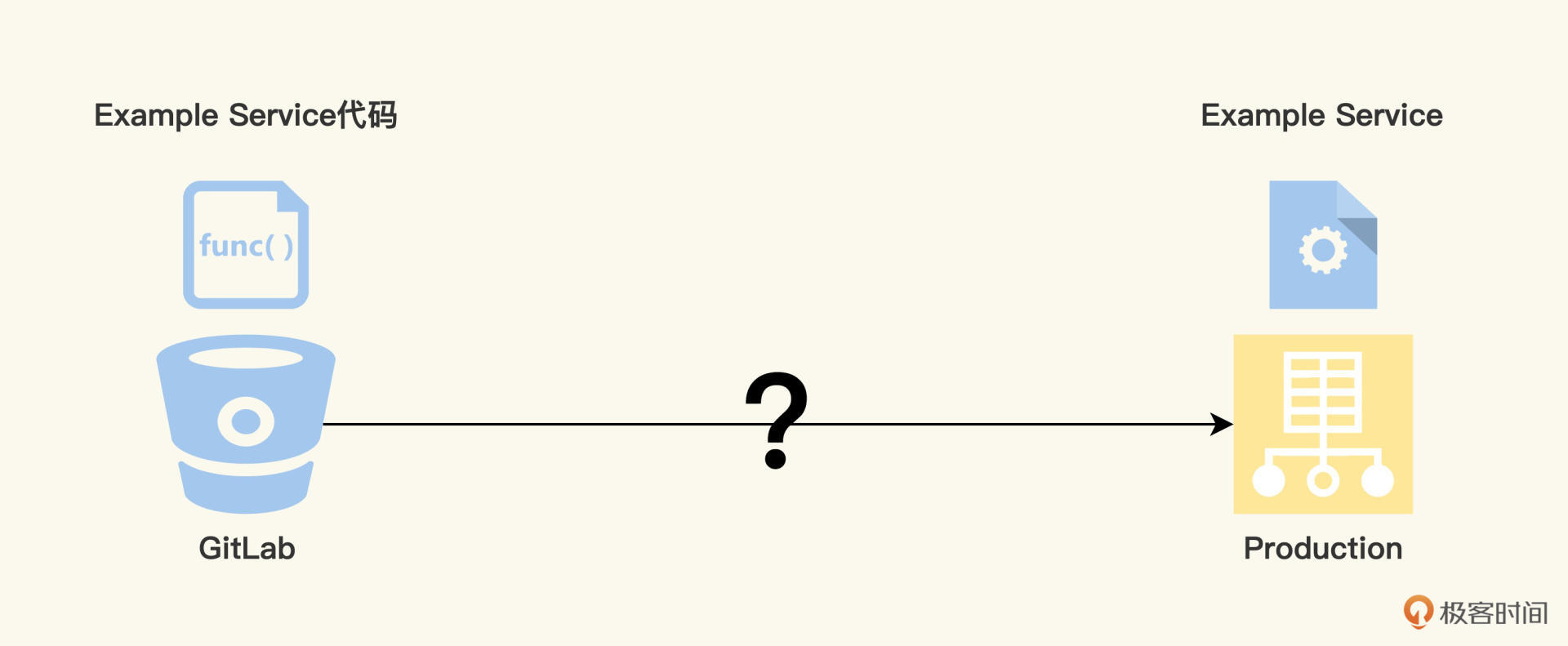
|
|
|
|
|
|
## Example Service的Pipeline的目标
|
|
|
|
|
|
还是按照Job模型的设计原则,先理出Pipleline的第一个根Job。
|
|
|
|
|
|
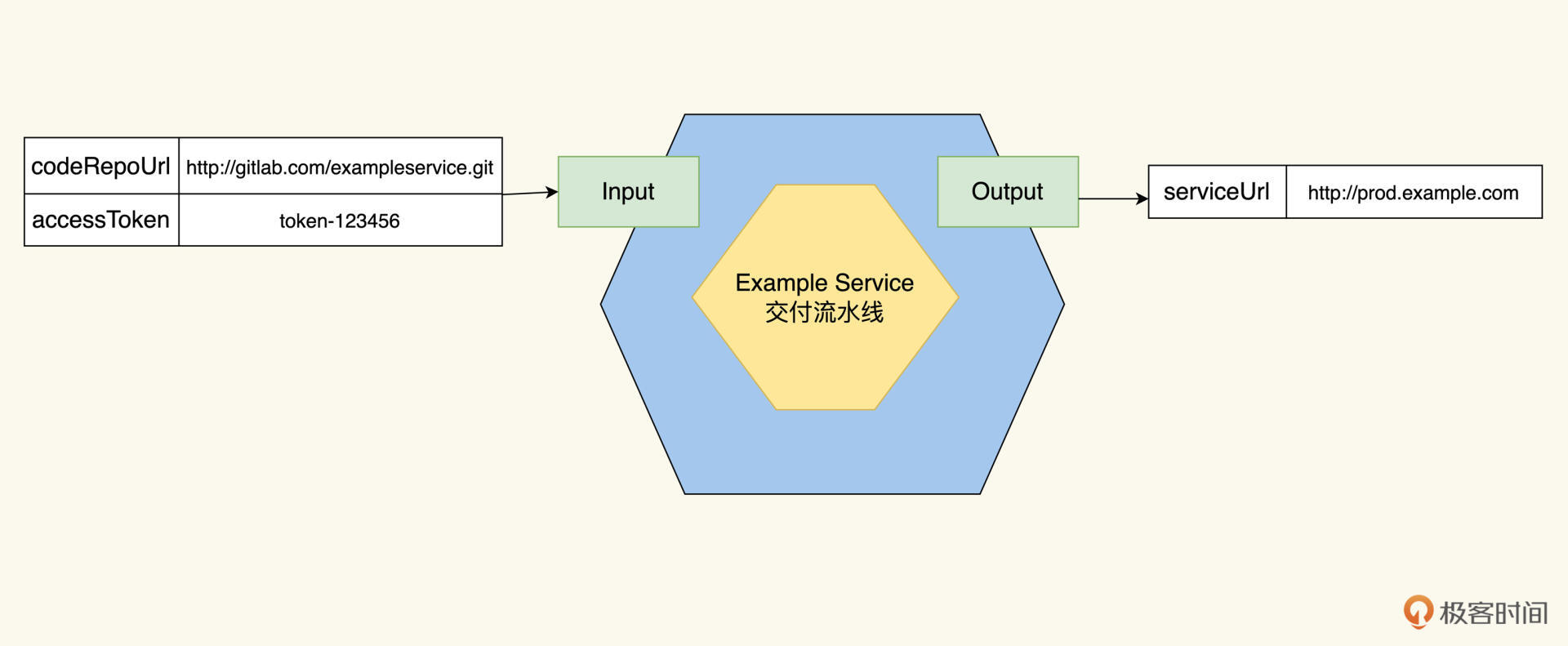
Pipeline的起点在哪里呢?很显然,它从一个GitLab的repo开始,准确来说,要能访问Example Service的代码。怎么能访问代码呢?我们需要知道两个信息,代码仓库的URL地址和访问的token。
|
|
|
|
|
|
1.GitLab的代码仓库地址:[http://gitlab.example.com/sheng/exampleservice.git](http://81.70.254.64/yuzi/dockerbase.git)
|
|
|
|
|
|
2.访问token:token-123456
|
|
|
|
|
|
Pipeline的终点到哪里呢?很简单,最后Example Service能够在生产环境运行起来,运行起来的标志,就是Example Service的工作URL:[http://prod.example.com](http://prod.example.com)
|
|
|
|
|
|
|
|
|
|
|
|
## 划分Pipeline的阶段
|
|
|
|
|
|
这个从代码转成生产环境服务的过程,至少要完成两次转换。
|
|
|
|
|
|
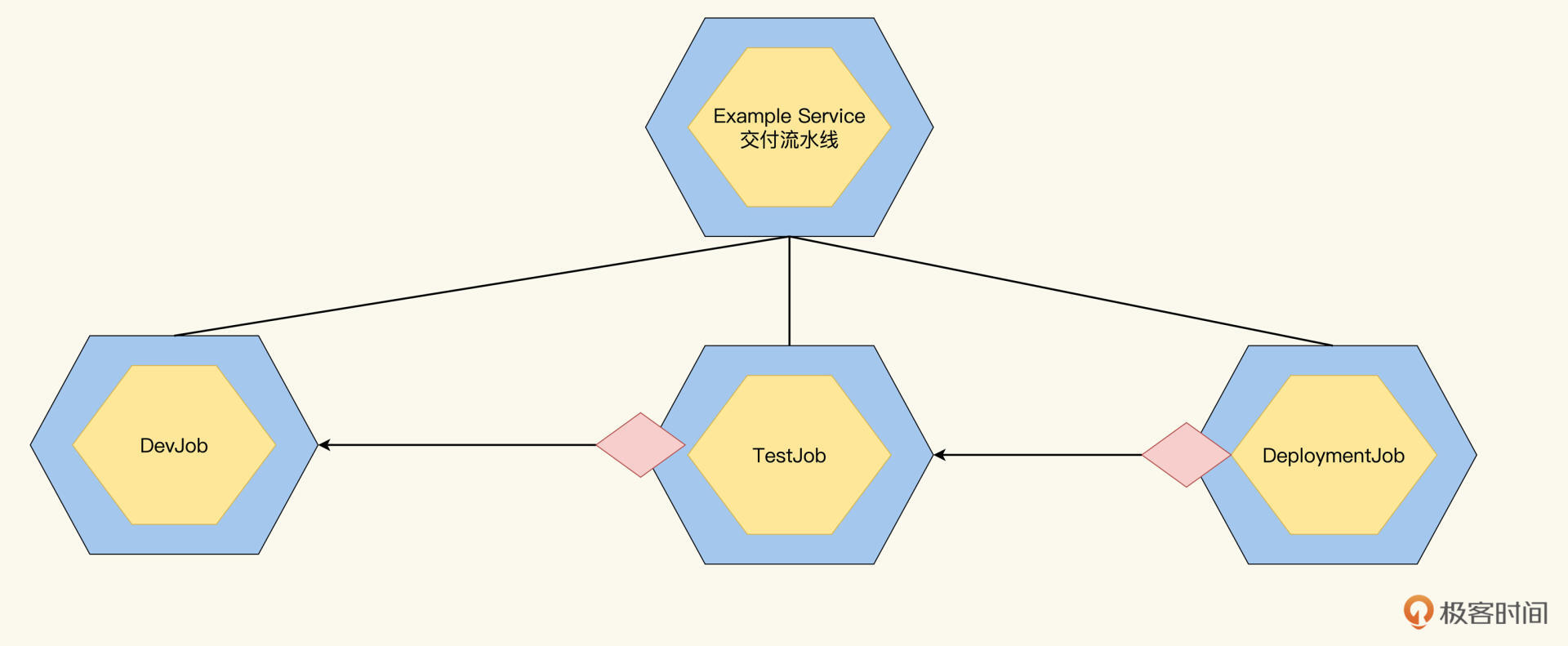
第一次转换是**把代码转成可部署包**,第二次是**把可部署包转换成运行态服务**。为了把好验证关的大门,我们还要在这两次转换中间再加入一个测试任务,那么Pipeline就可以分解成3个子Job,分别是开发Job、测试Job、部署Job,它们依次完成,全部运行通过,最后才能部署到生产环境。如下图:
|
|
|
|
|
|
|
|
|
|
|
|
这三个Job,我们依次来看一下它们都需要干什么活。
|
|
|
|
|
|
首先,我们来看看DevJob。开发阶段测试Job,作为整个Pipleline的初始Job,Pipeline的Input就是DevJob的Input。
|
|
|
|
|
|
1.GitLab的代码仓库地址:[http://gitlab.example.com/sheng/exampleservice.git](http://81.70.254.64/yuzi/dockerbase.git)
|
|
|
2.访问token: token-123456
|
|
|
|
|
|
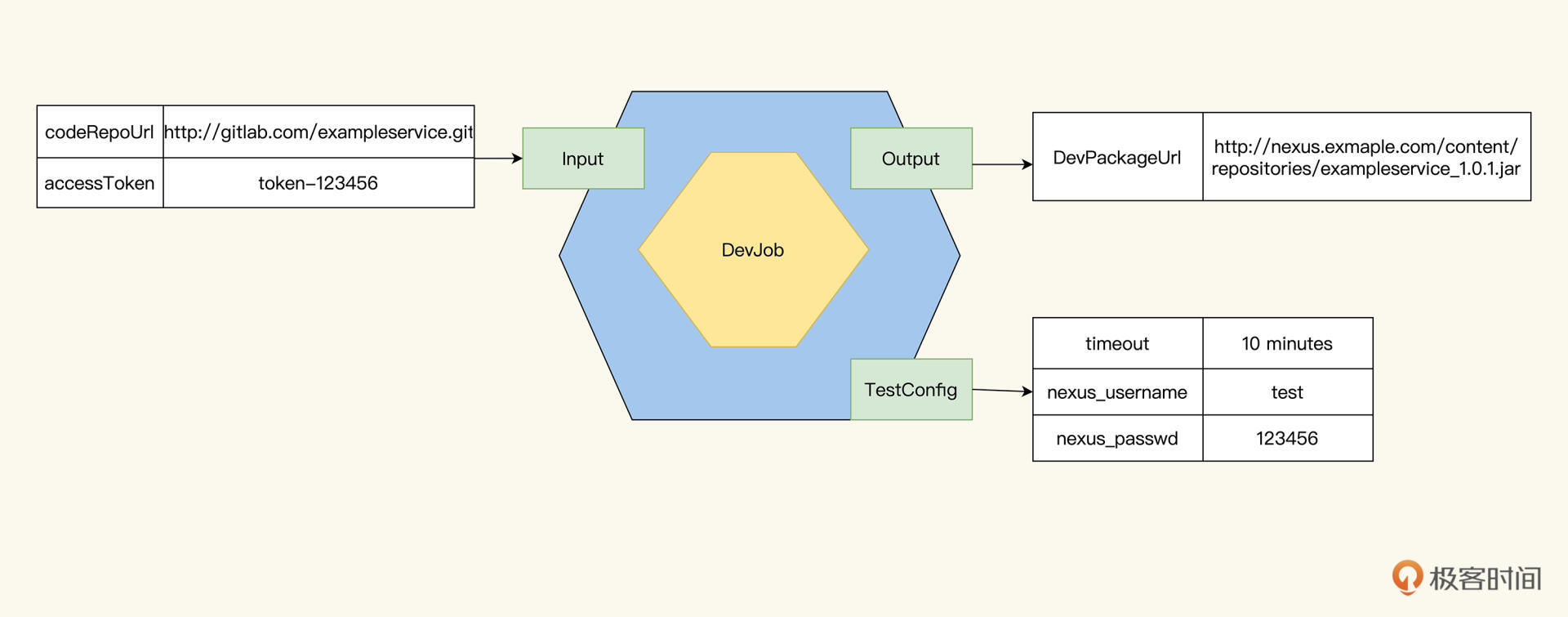
DevJob要做什么呢?它前面连接了代码库,后面要对接集成测试,它的主要职责就是把代码变成可部署的Package。
|
|
|
|
|
|
Input有了,DevJob要输出什么呢?我们要知道,DevJob的输出会作为下一阶段Job的输入,设计DevJob的输出就跟接口设计一样,不同的接口都能让系统工作,但我们要选择最合适那一种。
|
|
|
|
|
|
比如,我们可以让DevJob输出一个Example Package的仓库地址,代表Package已经打好了,并上传到了仓库,或者我们输出单元测试报告;甚至,DevJob也可以什么都不输出,让下一个TestJob自己去按照双方约定好的Ftp服务器上去取包。
|
|
|
|
|
|
哪种方案更合适呢?
|
|
|
|
|
|
这里你要考虑两点:第一,我的输出别人是否用得到?像单元测试报告这种信息,是我DevJob内部的工作产物,别人不会感兴趣。按照面向对象设计原则,这些细节应该隐藏在DevJob内,不向外公布。
|
|
|
|
|
|
第二,我的输出是不是信息显式而充分的?像多个Job都遵循一个约定,去指定的FTP服务器上去取放Package,这个信息交互就是隐式的,没有在接口上体现出来。这样是有隐患的,如果之后各个Job变更重构的时候,就会出问题。
|
|
|
|
|
|
根据这个原则,我们让DevJob输出一个Example Package的仓库地址
|
|
|
|
|
|
DevPackageURL: [http://nexus.exmaple.com/content/repositories/exampleservice\_1.0.1.jar](http://nexus.exmaple.com/content/repositories/exampleservice.jar)
|
|
|
|
|
|
如果DevJob输出了这个URL,就代表DevJob已经运行通过,把代码变成了Package,而且把Package放到了组件管理平台Nexus上去,别人就可以用了。
|
|
|
|
|
|
你可能会问,拿到了Package URL还需要Nexus的用户名密码才能访问。那下一个Job从哪里获知用户名和密码呢?这时,就可以用到我们Job测试模型的TestConfig属性了。直接把用户名、密码放在TestConfig就可以了。
|
|
|
|
|
|
|
|
|
|
|
|
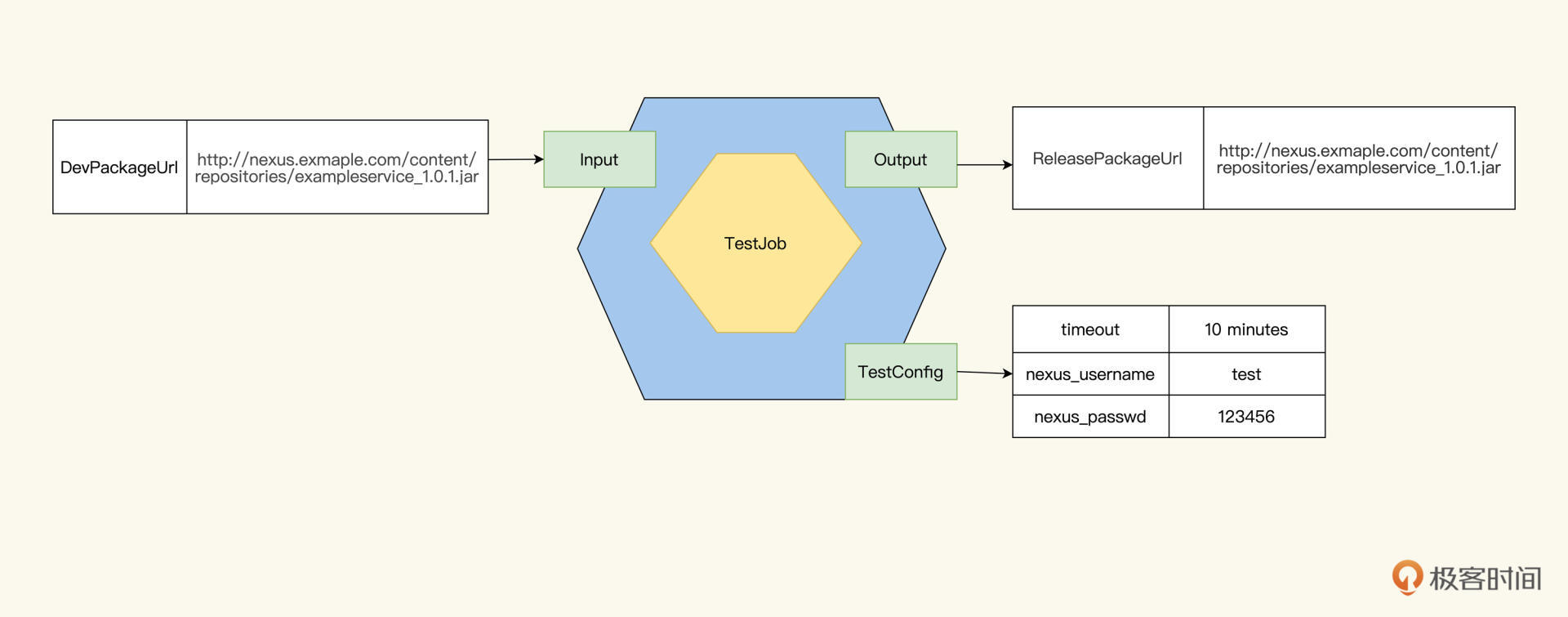
同样的思路,我们也能整理出TestJob的Input是DevPackageUrl,Output是ReleasePackageUrl:
|
|
|
|
|
|
|
|
|
|
|
|
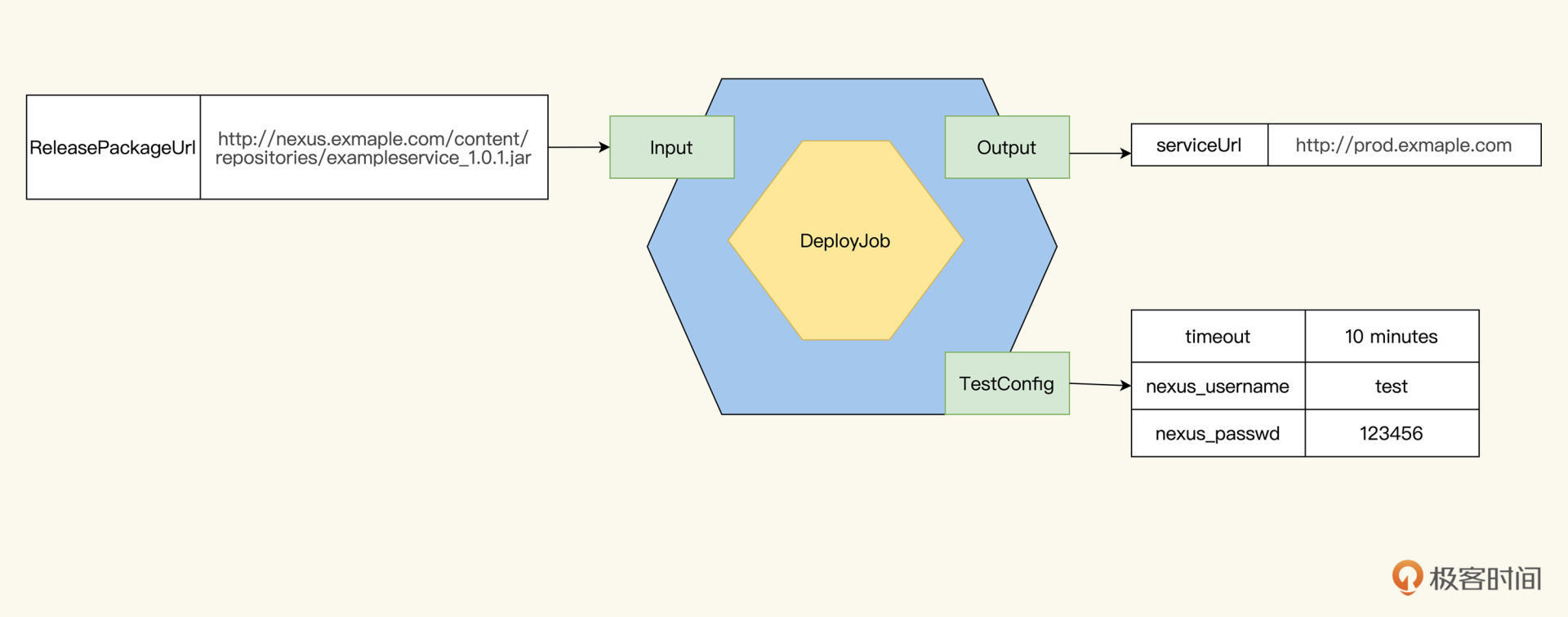
DeployJob的Input是ReleasePackageUrl,作为Pipeline最末一个Job,Pipeline的输出就是DeployJob的输出:
|
|
|
|
|
|
|
|
|
|
|
|
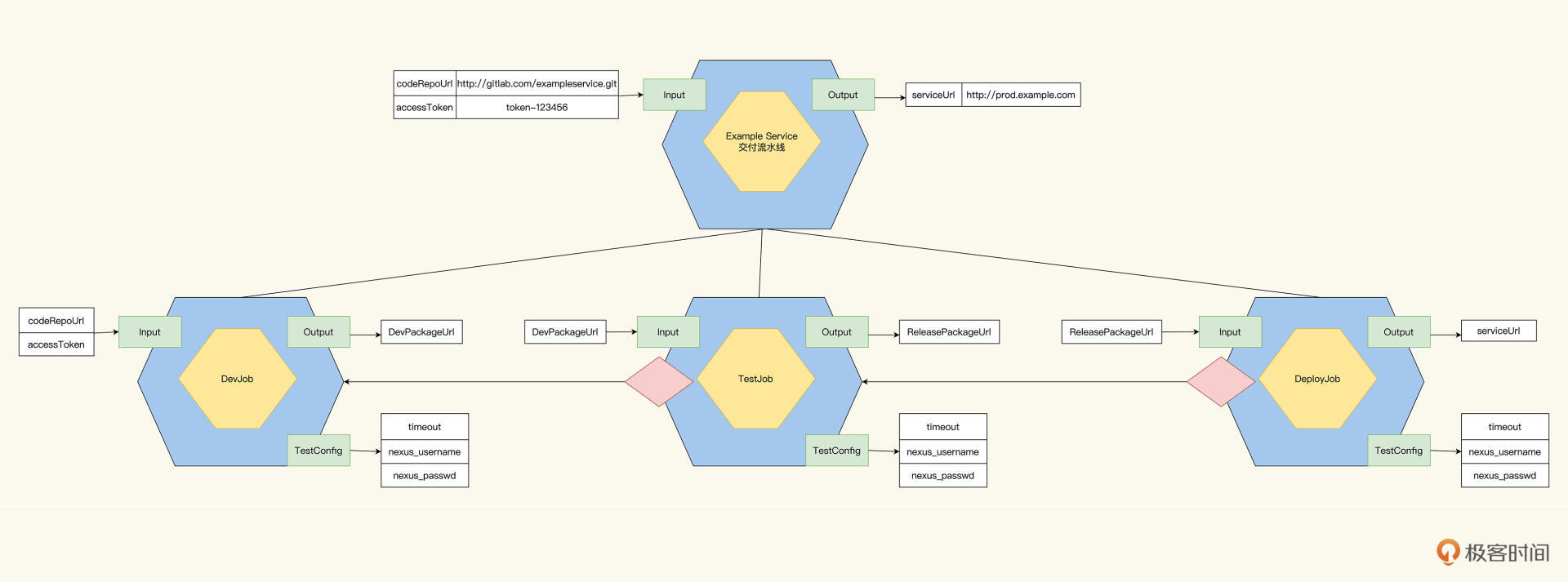
推演到现在,整个Job树就成了后面这样:
|
|
|
|
|
|
|
|
|
|
|
|
我们把Pipeline拆分成Dev、Test和Deploy三个Job后,就可以把它们分别指派给开发人员、测试人员、运维人员,由他们来推进下一阶段的设计了。至此,概要设计告一段落。
|
|
|
|
|
|
## 各阶段Job的详细设计
|
|
|
|
|
|
我们在上面的设计中规划了3个阶段,明确了作为Pipeline job的第一级子Job:DevJob、TestJob、DeployJob。但每个阶段要做什么具体任务,还需要进一步详细设计。
|
|
|
|
|
|
### DevJob
|
|
|
|
|
|
我们先看DevJob,它的Output是一个可执行包。
|
|
|
|
|
|
怎么完成从代码到可执行包的转换呢?当然要进行构建,也就是Build。
|
|
|
|
|
|
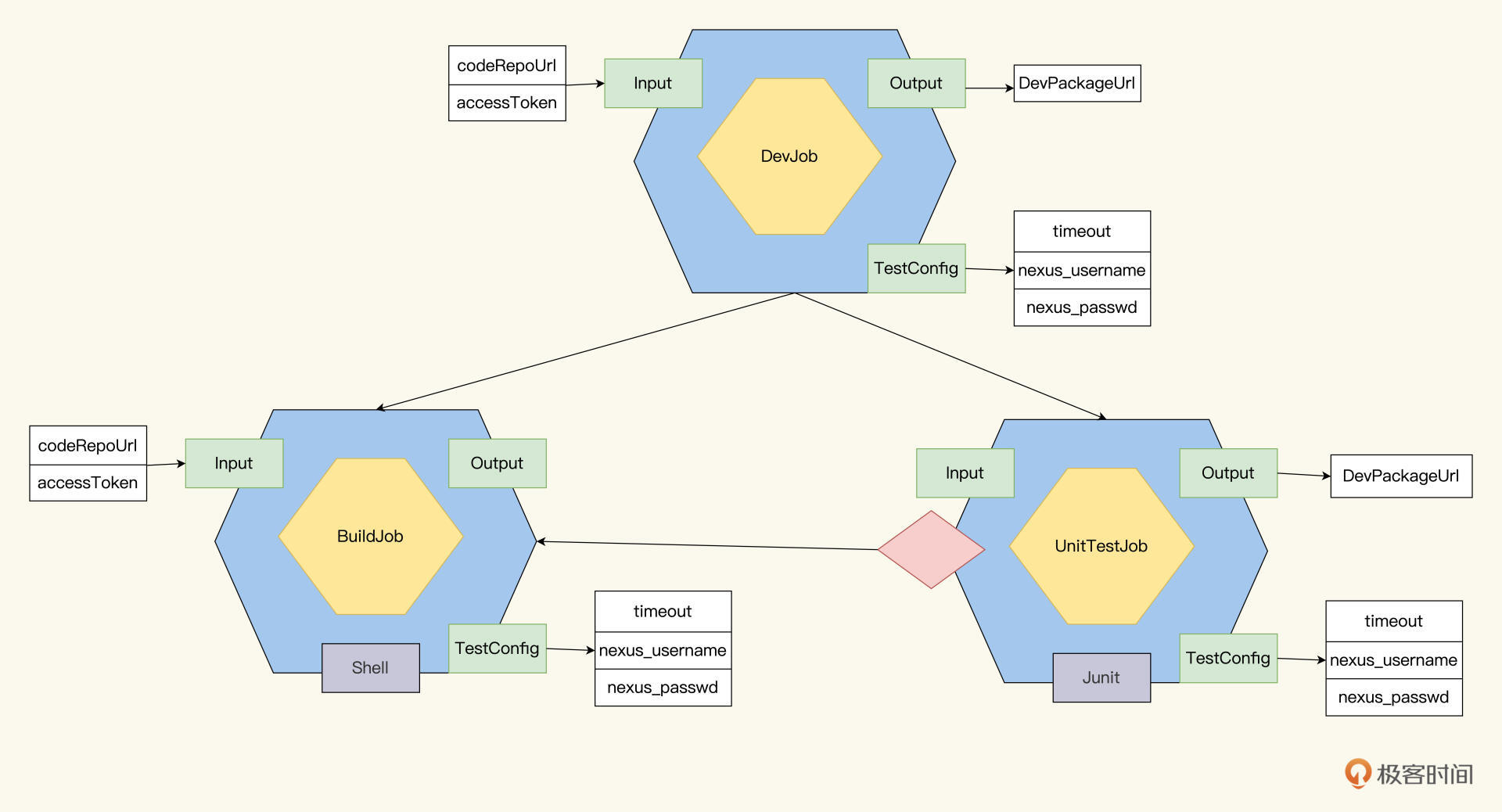
BuildJob的模型很容易梳理,它的Input是codeRepoUrl,而Output是DevPackageUrl。BuildJob从代码库里抓取代码,构建,然后打包生成Package,上传到对象仓库,就完成了。
|
|
|
|
|
|
但build通过了后,是不是可以直接产生DevPackage呢?这里我分享一个“保险”措施,为了保证质量,我们可以在build之后,加上一个测试任务,也就是单元测试UnitTestJob。单元测试通过之后,再输出DevPackage。
|
|
|
|
|
|
UnitTestJob就是运行单元测试,单元测试成功还是失败,就是UnitTestJob的结果。所以,UnitTestJob的Job模型里,只设置一个Dependency就好了,指向BuildJob。BuildJob成功之后,才能运行UnitTestJob。这里的UnitTestJob,我们选用Junit开发框架就能实现。
|
|
|
|
|
|
现在DevJob被细分成了两个子Job:BuildJob和UnitTestJob。
|
|
|
|
|
|
按照Job模型的规则,子Job都运行成功,父Job才能成功。所以,BuildJob和UnitTestJob运行成功,DevJob才算成功,而DevJob成功了,后面的TestJob才能触发运行。
|
|
|
|
|
|
|
|
|
|
|
|
### TestJob
|
|
|
|
|
|
经过第二模块里策略篇的学习,我们知道了测试的策略有单元测试、接口测试和系统测试。单元测试一般是开发人员来做,已经包含在DevJob里了。而接口测试和系统测试,就需要放在TestJob里。
|
|
|
|
|
|
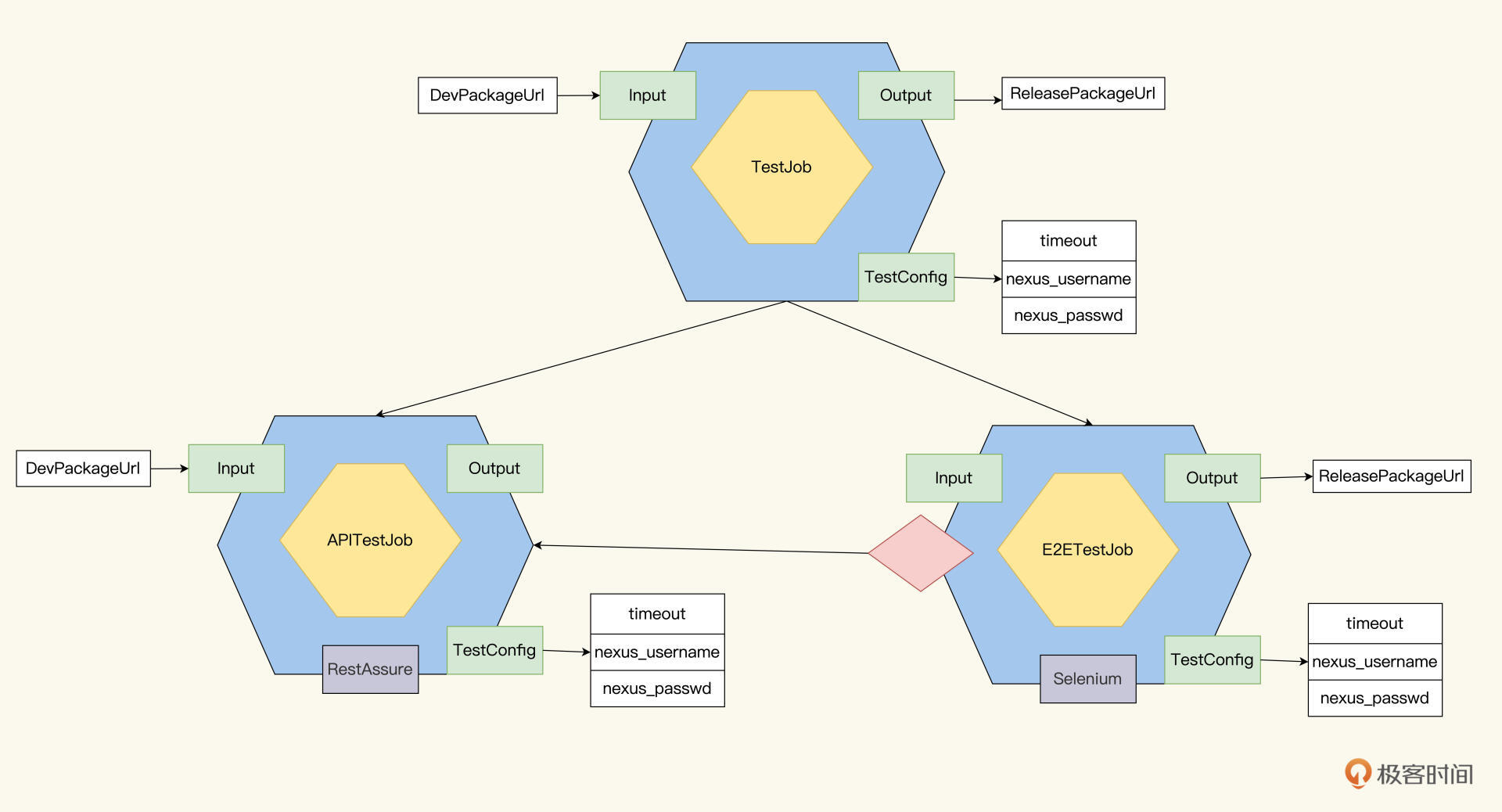
先来看APITestJob的模型。APITestJob作为TestJob的第一个子Job,APITestJob的Input就是它的父Job TestJob的Input,也就是DevPackageUrl。有了这个信息,APITestJob就可以开发实现了,它的自动化工具可以选用RestAssure。
|
|
|
|
|
|
然后是E2ETestJob的模型,它的Dependency是APITestJob,而Output是ReleasePackageUrl。至于E2ETestJob的自动化技术,我们可以选用Selenium。
|
|
|
|
|
|
现在,可以把TestJob分解成了2个子Job,APTestJob和E2ETestJob,Job树如下:
|
|
|
|
|
|
|
|
|
|
|
|
### DeploymentJob
|
|
|
|
|
|
又下一城,咱们一鼓作气,继续来看DeploymentJob。
|
|
|
|
|
|
当Pipeline移动到DeploymentJob的时候,它会检查前置依赖TestJob的状态,只有成功了,DeploymentJob才会运行。在运行的时候,DeploymentJob会从Input获得一个ReleasePackageUrl,然后经过一系列部署操作,把Package部署到生产环境里开始运行,输出一个serviceUrl。
|
|
|
|
|
|
为了完成这个过程,简单的做法是,DeploymentJob不需要再细分子Job,你可以直接把它当作一个可执行Job,用部署脚本来实现。
|
|
|
|
|
|
## 转成自动化测试开发计划
|
|
|
|
|
|
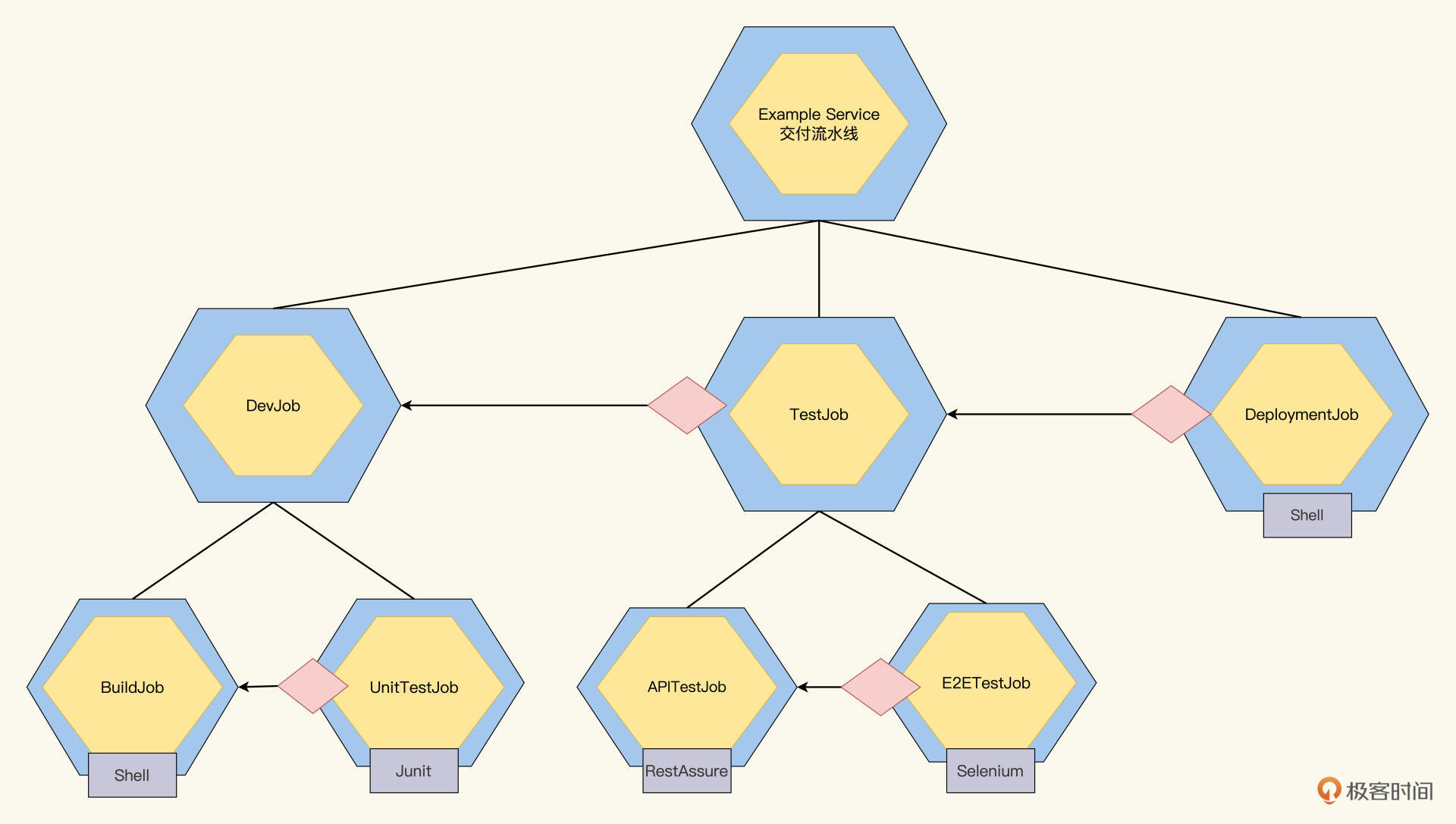
搞定上面的设计后,现在Job树变成了这样:
|
|
|
|
|
|
|
|
|
|
|
|
现在每一个叶子结点,就是可执行的Job,需要自动化实现。
|
|
|
|
|
|
|
|
|
|
|
|
## 变更和扩展
|
|
|
|
|
|
在Pipeline搭建起来后,我们还要持续维护。这里有两种情形,一种是新增Job,还有一种是扩展Job。
|
|
|
|
|
|
先看新增Job的场景,我给你举个例子。比如开发人员有一天要引入Sonar,做代码质量检测,那我们该怎么做呢?
|
|
|
|
|
|
动手前,我们还是先分析一下。Sonar扫描,也是基于代码CodeRepoUrl,这个和DevJob的Input一致。这样,我们可以建立一个SonarJob,作为DevJob的子Job,可以复用DevJob的Input。
|
|
|
|
|
|
那SonarJob和BuildJob,还有UnitTestJob是什么关系呢?这就看我们想怎么定义它们的依赖关系了。也就是谁在前端,谁在末端。
|
|
|
|
|
|
一般来说,代码扫描,应该发生在代码变更的最早时刻。一旦有代码提交,就首先检查代码的质量,如果代码质量不符合预定标准,就终止Pipeline。实践里这样选择,是为了优先保证代码的质量。
|
|
|
|
|
|
基于这样的目标,我们就把SonarJob添加到DevJob下的第一个子Job,让BuildJob依赖SonarJob,而UnitTestJob保持不变,还是依赖BuildJob。
|
|
|
|
|
|
另外还有一种情形,就是某一个Job当时设计实现比较简单,后来需要扩展。比如DeploymentJob,刚开始我们用一段Shell脚本就可以轻松执行它。但随着Deployment要求提高,我们需要在Deployment结束后,还要执行测试任务,验证质量,然后再发布serviceUrl。面对这种情况,我们该怎么办?
|
|
|
|
|
|
其实这个场景,就跟开发一样,一旦代码规模扩大了,就需要分拆模块了。
|
|
|
|
|
|
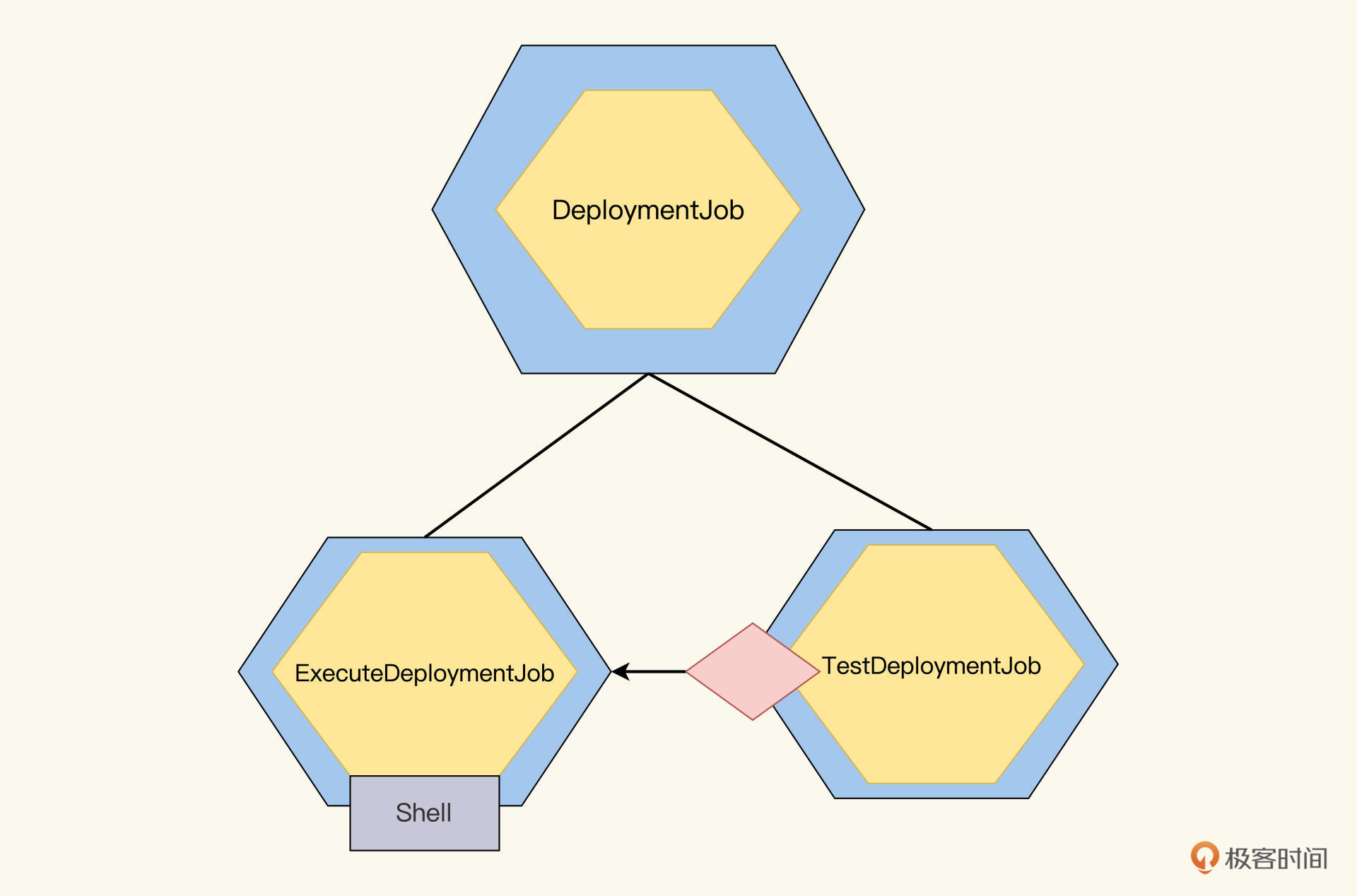
在我们的Job树里,原先的DeploymentJob需要分拆了,拆分成ExecuteDeployment和TestDeployment,让TestDeployment依赖于ExecuteDeployment。之前的DeploymentJob变成一个抽象Job,它的脚本实现挪到ExecuteDeploymentJob里,在新TestDeployment里,加上测试任务即可。如下图:
|
|
|
|
|
|
|
|
|
|
|
|
## 小结
|
|
|
|
|
|
为了检验咱们的Job模型威力几何,今天我们再次锻炼设计思维,进行了部署Pipeline的设计。经过案例演练,你现在是不是对Job模型更加熟悉了呢?
|
|
|
|
|
|
咱们回顾一下关键流程。概要设计里,我们完成了抽象Job的定义,对应着Pipeline划分的三大阶段:开发阶段、测试阶段和部署阶段,然后逐层细化,一直到实例Job。而在详细设计里,我们不仅要确定实例Job的接口,而且还要确定它们的自动化测试实现技术。
|
|
|
|
|
|
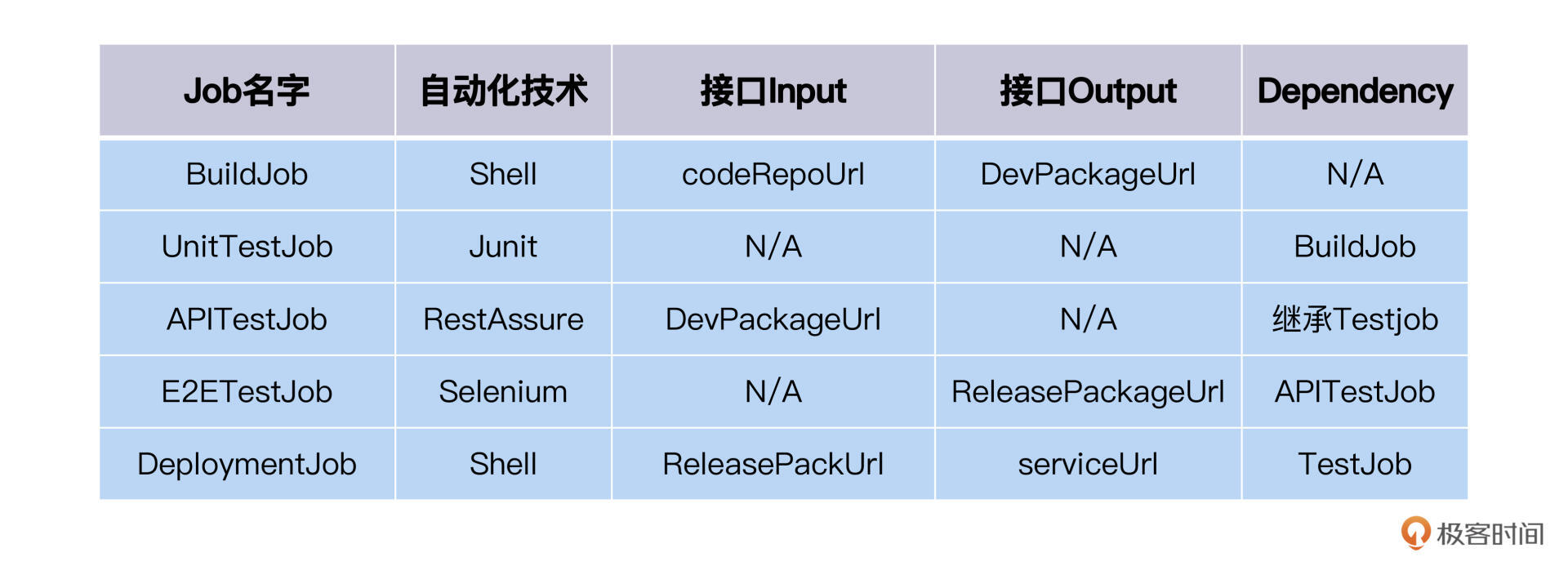
做完设计,每一个叶子节点的Job都是要去开发实现的自动化测试任务。我们就可以整理出一个自动化测试开发任务列表了。
|
|
|
|
|
|
后面是Job树叶子工作表,供你复习回顾。
|
|
|
|
|
|

|
|
|
|
|
|
一个优秀模型,不光着眼于眼前的需求,还具备应对未来变化的能力。除了概要设计和详细设计,我们还推演了未来的应变策略。
|
|
|
|
|
|
当规模扩大时,原先的可执行Job的逻辑变得复杂的时候,我们依然可以根据Job模型,把可执行Job再进行分解成多个子Job。需要注意的是,我们遵循的原则是只有叶子结点Job才是可执行Job,不再进行分解的Job,而一旦Job下挂了子Job,那这个Job就变成了抽象Job,只负责接口的定义。
|
|
|
|
|
|
今天讲了Pipeline设计,也是对前面Job设计内容的复习巩固。接下来,我们就要进阶到另外一个难度级别的设计了,不仅有多端协作,还有分布式事务,这种场景怎么设计?我们下讲见。
|
|
|
|
|
|
## 思考题
|
|
|
|
|
|
你负责或者参与的Pipeline原先是怎么设计的?看完这一讲,你想到怎么优化它了么?
|
|
|
|
|
|
欢迎你在留言区跟我交流互动。如果觉得这一讲对你有启发,也推荐你把它分享给更多朋友、同事。
|
|
|
|