|
|
# 17 | TCP并不总是“可靠”的?
|
|
|
|
|
|
你好,我是盛延敏,这里是网络编程实战第17讲,欢迎回来。
|
|
|
|
|
|
在前面一讲中,我们讲到如何理解TCP数据流的本质,进而引出了报文格式和解析。在这一讲里,我们讨论通过如何增强读写操作,以处理各种“不可靠”的场景。
|
|
|
|
|
|
## TCP是可靠的?
|
|
|
|
|
|
你可能会认为,TCP是一种可靠的协议,这种可靠体现在端到端的通信上。这似乎给我们带来了一种错觉,从发送端来看,应用程序通过调用send函数发送的数据流总能可靠地到达接收端;而从接收端来看,总是可以把对端发送的数据流完整无损地传递给应用程序来处理。
|
|
|
|
|
|
事实上,如果我们对TCP传输环节进行详细的分析,你就会沮丧地发现,上述论断是不正确的。
|
|
|
|
|
|
前面我们已经了解,发送端通过调用send函数之后,数据流并没有马上通过网络传输出去,而是存储在套接字的发送缓冲区中,由网络协议栈决定何时发送、如何发送。当对应的数据发送给接收端,接收端回应ACK,存储在发送缓冲区的这部分数据就可以删除了,但是,发送端并无法获取对应数据流的ACK情况,也就是说,发送端没有办法判断对端的接收方是否已经接收发送的数据流,如果需要知道这部分信息,就必须在应用层自己添加处理逻辑,例如显式的报文确认机制。
|
|
|
|
|
|
从接收端来说,也没有办法保证ACK过的数据部分可以被应用程序处理,因为数据需要接收端程序从接收缓冲区中拷贝,可能出现的状况是,已经ACK的数据保存在接收端缓冲区中,接收端处理程序突然崩溃了,这部分数据就没有办法被应用程序继续处理。
|
|
|
|
|
|
你有没有发现,TCP协议实现并没有提供给上层应用程序过多的异常处理细节,或者说,TCP协议反映链路异常的能力偏弱,这其实是有原因的。要知道,TCP诞生之初,就是为美国国防部服务的,考虑到军事作战的实际需要,TCP不希望暴露更多的异常细节,而是能够以无人值守、自我恢复的方式运作。
|
|
|
|
|
|
TCP连接建立之后,能感知TCP链路的方式是有限的,一种是以read为核心的读操作,另一种是以write为核心的写操作。接下来,我们就看下如何通过读写操作来感知异常情况,以及对应的处理方式。
|
|
|
|
|
|
## 故障模式总结
|
|
|
|
|
|
在实际情景中,我们会碰到各种异常的情况。在这里我把这几种异常情况归结为两大类:
|
|
|
|
|
|
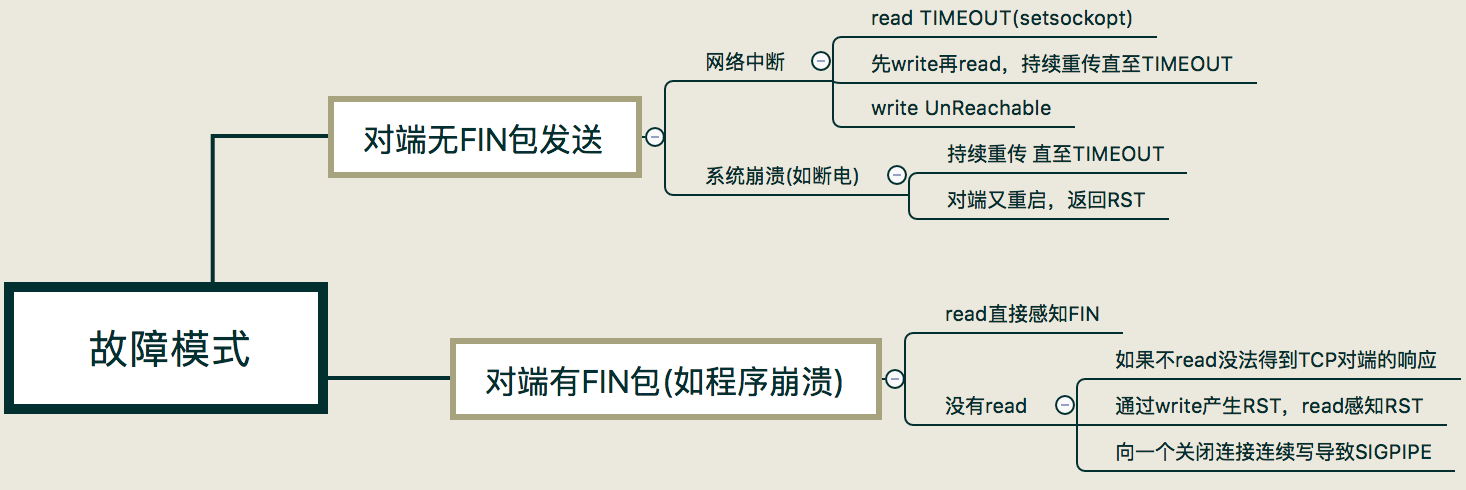
|
|
|
第一类,是对端无FIN包发送出来的情况;第二类是对端有FIN包发送出来。而这两大类情况又可以根据应用程序的场景细分,接下来我们详细讨论。
|
|
|
|
|
|
## 网络中断造成的对端无FIN包
|
|
|
|
|
|
很多原因都会造成网络中断,在这种情况下,TCP程序并不能及时感知到异常信息。除非网络中的其他设备,如路由器发出一条ICMP报文,说明目的网络或主机不可达,这个时候通过read或write调用就会返回Unreachable的错误。
|
|
|
|
|
|
可惜大多数时候并不是如此,在没有ICMP报文的情况下,TCP程序并不能理解感应到连接异常。如果程序是阻塞在read调用上,那么很不幸,程序无法从异常中恢复。这显然是非常不合理的,不过,我们可以通过给read操作设置超时来解决,在接下来的第18讲中,我会讲到具体的方法。
|
|
|
|
|
|
如果程序先调用了write操作发送了一段数据流,接下来阻塞在read调用上,结果会非常不同。Linux系统的TCP协议栈会不断尝试将发送缓冲区的数据发送出去,大概在重传12次、合计时间约为9分钟之后,协议栈会标识该连接异常,这时,阻塞的read调用会返回一条TIMEOUT的错误信息。如果此时程序还执着地往这条连接写数据,写操作会立即失败,返回一个SIGPIPE信号给应用程序。
|
|
|
|
|
|
## 系统崩溃造成的对端无FIN包
|
|
|
|
|
|
当系统突然崩溃,如断电时,网络连接上来不及发出任何东西。这里和通过系统调用杀死应用程序非常不同的是,没有任何FIN包被发送出来。
|
|
|
|
|
|
这种情况和网络中断造成的结果非常类似,在没有ICMP报文的情况下,TCP程序只能通过read和write调用得到网络连接异常的信息,超时错误是一个常见的结果。
|
|
|
|
|
|
不过还有一种情况需要考虑,那就是系统在崩溃之后又重启,当重传的TCP分组到达重启后的系统,由于系统中没有该TCP分组对应的连接数据,系统会返回一个RST重置分节,TCP程序通过read或write调用可以分别对RST进行错误处理。
|
|
|
|
|
|
如果是阻塞的read调用,会立即返回一个错误,错误信息为连接重置(Connection Reset)。
|
|
|
|
|
|
如果是一次write操作,也会立即失败,应用程序会被返回一个SIGPIPE信号。
|
|
|
|
|
|
## 对端有FIN包发出
|
|
|
|
|
|
对端如果有FIN包发出,可能的场景是对端调用了close或shutdown显式地关闭了连接,也可能是对端应用程序崩溃,操作系统内核代为清理所发出的。从应用程序角度上看,无法区分是哪种情形。
|
|
|
|
|
|
阻塞的read操作在完成正常接收的数据读取之后,FIN包会通过返回一个EOF来完成通知,此时,read调用返回值为0。这里强调一点,收到FIN包之后read操作不会立即返回。你可以这样理解,收到FIN包相当于往接收缓冲区里放置了一个EOF符号,之前已经在接收缓冲区的有效数据不会受到影响。
|
|
|
|
|
|
为了展示这些特性,我分别编写了服务器端和客户端程序。
|
|
|
|
|
|
```
|
|
|
//服务端程序
|
|
|
int main(int argc, char **argv) {
|
|
|
int connfd;
|
|
|
char buf[1024];
|
|
|
|
|
|
connfd = tcp_server(SERV_PORT);
|
|
|
|
|
|
for (;;) {
|
|
|
int n = read(connfd, buf, 1024);
|
|
|
if (n < 0) {
|
|
|
error(1, errno, "error read");
|
|
|
} else if (n == 0) {
|
|
|
error(1, 0, "client closed \n");
|
|
|
}
|
|
|
|
|
|
sleep(5);
|
|
|
|
|
|
int write_nc = send(connfd, buf, n, 0);
|
|
|
printf("send bytes: %zu \n", write_nc);
|
|
|
if (write_nc < 0) {
|
|
|
error(1, errno, "error write");
|
|
|
}
|
|
|
}
|
|
|
|
|
|
exit(0);
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
服务端程序是一个简单的应答程序,在收到数据流之后回显给客户端,在此之前,休眠5秒,以便完成后面的实验验证。
|
|
|
|
|
|
客户端程序从标准输入读入,将读入的字符串传输给服务器端:
|
|
|
|
|
|
```
|
|
|
//客户端程序
|
|
|
int main(int argc, char **argv) {
|
|
|
if (argc != 2) {
|
|
|
error(1, 0, "usage: reliable_client01 <IPaddress>");
|
|
|
}
|
|
|
|
|
|
int socket_fd = tcp_client(argv[1], SERV_PORT);
|
|
|
char buf[128];
|
|
|
int len;
|
|
|
int rc;
|
|
|
|
|
|
while (fgets(buf, sizeof(buf), stdin) != NULL) {
|
|
|
len = strlen(buf);
|
|
|
rc = send(socket_fd, buf, len, 0);
|
|
|
if (rc < 0)
|
|
|
error(1, errno, "write failed");
|
|
|
rc = read(socket_fd, buf, sizeof(buf));
|
|
|
if (rc < 0)
|
|
|
error(1, errno, "read failed");
|
|
|
else if (rc == 0)
|
|
|
error(1, 0, "peer connection closed\n");
|
|
|
else
|
|
|
fputs(buf, stdout);
|
|
|
}
|
|
|
exit(0);
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
### read直接感知FIN包
|
|
|
|
|
|
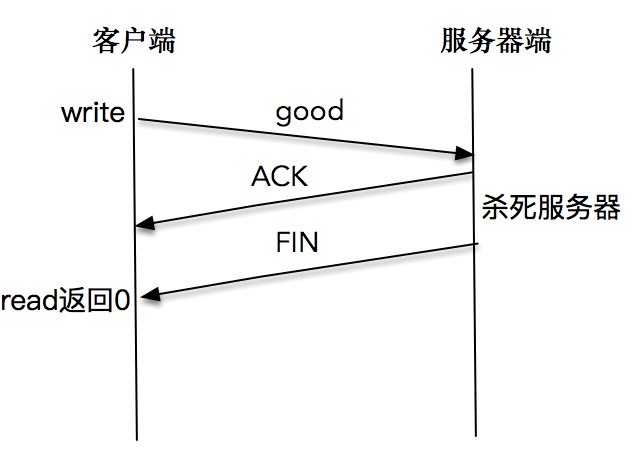
我们依次启动服务器端和客户端程序,在客户端输入good字符之后,迅速结束掉服务器端程序,这里需要赶在服务器端从睡眠中苏醒之前杀死服务器程序。
|
|
|
|
|
|
屏幕上打印出:peer connection closed。客户端程序正常退出。
|
|
|
|
|
|
```
|
|
|
$./reliable_client01 127.0.0.1
|
|
|
$ good
|
|
|
$ peer connection closed
|
|
|
|
|
|
```
|
|
|
|
|
|
这说明客户端程序通过read调用,感知到了服务端发送的FIN包,于是正常退出了客户端程序。
|
|
|
|
|
|
|
|
|
注意如果我们的速度不够快,导致服务器端从睡眠中苏醒,并成功将报文发送出来后,客户端会正常显示,此时我们停留,等待标准输入。如果不继续通过read或write操作对套接字进行读写,是无法感知服务器端已经关闭套接字这个事实的。
|
|
|
|
|
|
### 通过write产生RST,read调用感知RST
|
|
|
|
|
|
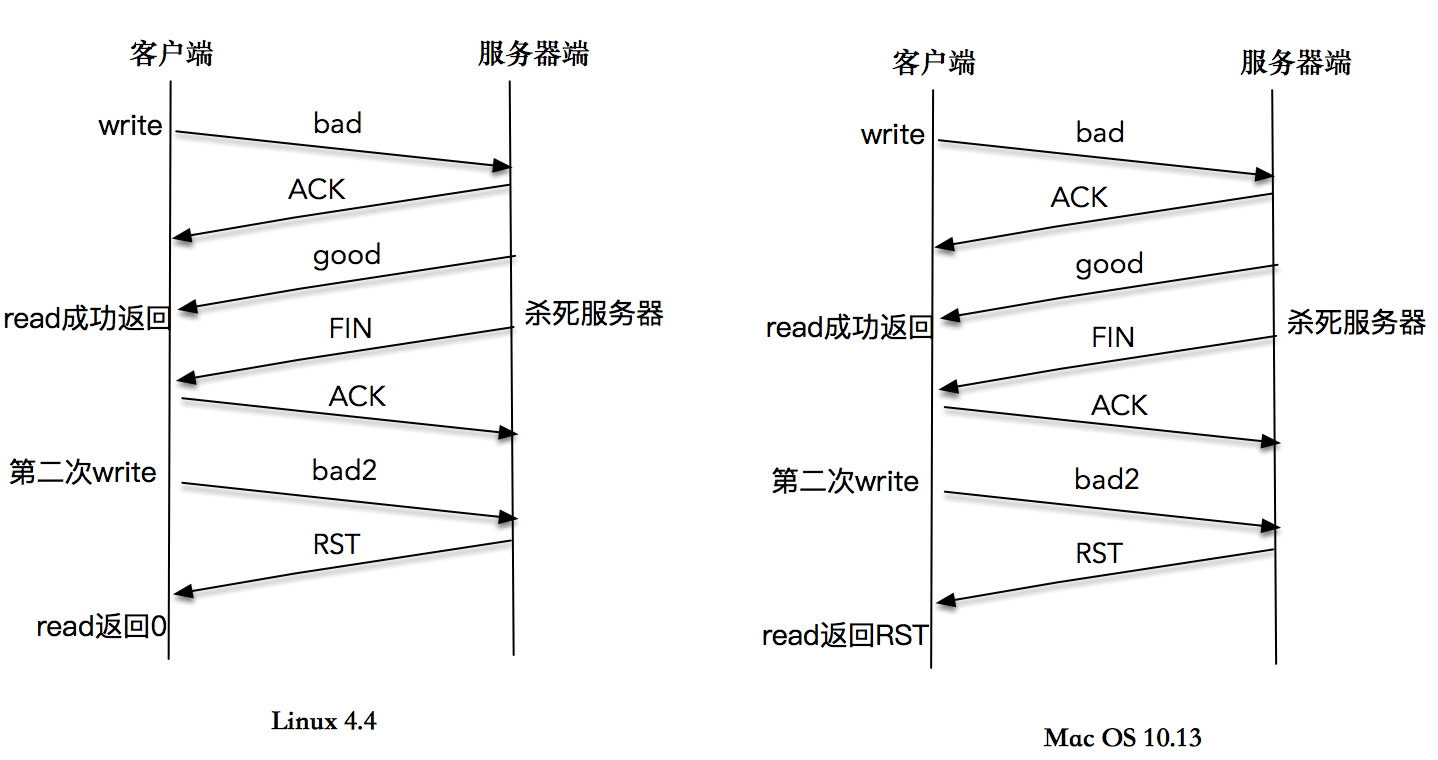
这一次,我们仍然依次启动服务器端和客户端程序,在客户端输入bad字符之后,等待一段时间,直到客户端正确显示了服务端的回应“bad”字符之后,再杀死服务器程序。客户端再次输入bad2,这时屏幕上打印出”peer connection closed“。
|
|
|
|
|
|
这是这个案例的屏幕输出和时序图。
|
|
|
|
|
|
```
|
|
|
$./reliable_client01 127.0.0.1
|
|
|
$bad
|
|
|
$bad
|
|
|
$bad2
|
|
|
$peer connection closed
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
在很多书籍和文章中,对这个程序的解读是,收到FIN包的客户端继续合法地向服务器端发送数据,服务器端在无法定位该TCP连接信息的情况下,发送了RST信息,当程序调用read操作时,内核会将RST错误信息通知给应用程序。这是一个典型的write操作造成异常,再通过read操作来感知异常的样例。
|
|
|
|
|
|
不过,我在Linux 4.4内核上实验这个程序,多次的结果都是,内核正常将EOF信息通知给应用程序,而不是RST错误信息。
|
|
|
|
|
|
我又在Max OS 10.13.6上尝试这个程序,read操作可以返回RST异常信息。输出和时序图也已经给出。
|
|
|
|
|
|
```
|
|
|
$./reliable_client01 127.0.0.1
|
|
|
$bad
|
|
|
$bad
|
|
|
$bad2
|
|
|
$read failed: Connection reset by peer (54)
|
|
|
|
|
|
```
|
|
|
|
|
|
### 向一个已关闭连接连续写,最终导致SIGPIPE
|
|
|
|
|
|
为了模拟这个过程,我对服务器端程序和客户端程序都做了如下修改。
|
|
|
|
|
|
```
|
|
|
nt main(int argc, char **argv) {
|
|
|
int connfd;
|
|
|
char buf[1024];
|
|
|
int time = 0;
|
|
|
|
|
|
connfd = tcp_server(SERV_PORT);
|
|
|
|
|
|
while (1) {
|
|
|
int n = read(connfd, buf, 1024);
|
|
|
if (n < 0) {
|
|
|
error(1, errno, "error read");
|
|
|
} else if (n == 0) {
|
|
|
error(1, 0, "client closed \n");
|
|
|
}
|
|
|
|
|
|
time++;
|
|
|
fprintf(stdout, "1K read for %d \n", time);
|
|
|
usleep(1000);
|
|
|
}
|
|
|
|
|
|
exit(0);
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
服务器端每次读取1K数据后休眠1秒,以模拟处理数据的过程。
|
|
|
|
|
|
客户端程序在第8行注册了SIGPIPE的信号处理程序,在第14-22行客户端程序一直循环发送数据流。
|
|
|
|
|
|
```
|
|
|
int main(int argc, char **argv) {
|
|
|
if (argc != 2) {
|
|
|
error(1, 0, "usage: reliable_client02 <IPaddress>");
|
|
|
}
|
|
|
|
|
|
int socket_fd = tcp_client(argv[1], SERV_PORT);
|
|
|
|
|
|
signal(SIGPIPE, SIG_IGN);
|
|
|
|
|
|
char *msg = "network programming";
|
|
|
ssize_t n_written;
|
|
|
|
|
|
int count = 10000000;
|
|
|
while (count > 0) {
|
|
|
n_written = send(socket_fd, msg, strlen(msg), 0);
|
|
|
fprintf(stdout, "send into buffer %ld \n", n_written);
|
|
|
if (n_written <= 0) {
|
|
|
error(1, errno, "send error");
|
|
|
return -1;
|
|
|
}
|
|
|
count--;
|
|
|
}
|
|
|
return 0;
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
如果在服务端读取数据并处理过程中,突然杀死服务器进程,我们会看到客**户端很快也会退出**,并在屏幕上打印出“Connection reset by peer”的提示。
|
|
|
|
|
|
```
|
|
|
$./reliable_client02 127.0.0.1
|
|
|
$send into buffer 5917291
|
|
|
$send into buffer -1
|
|
|
$send: Connection reset by peer
|
|
|
|
|
|
```
|
|
|
|
|
|
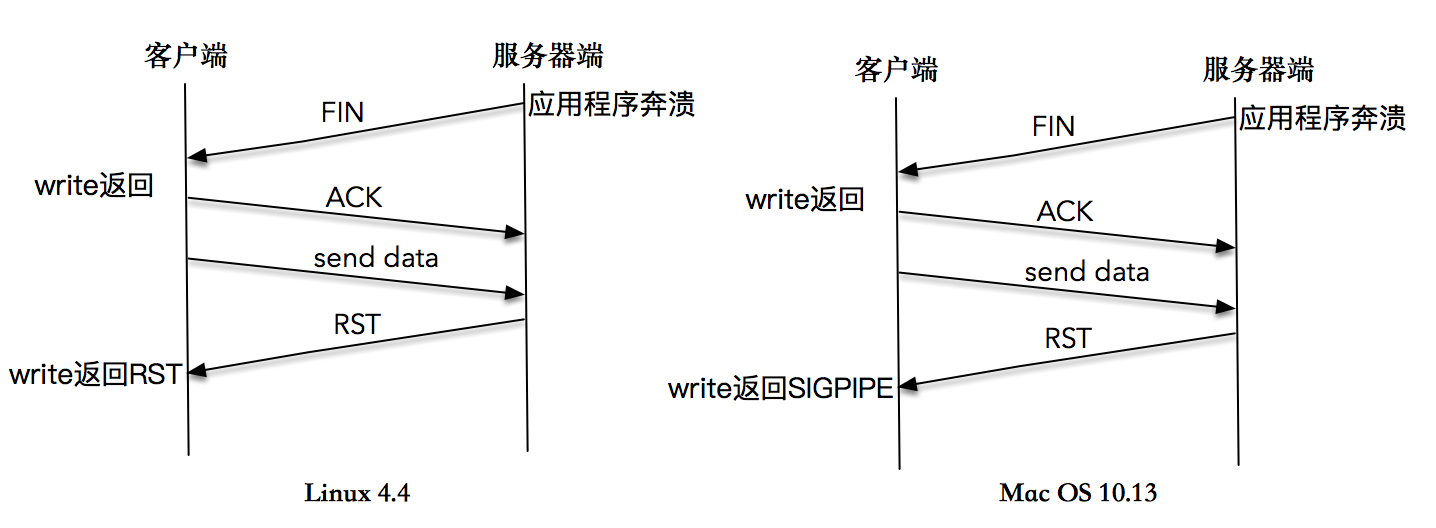
这是因为服务端程序被杀死之后,操作系统内核会做一些清理的事情,为这个套接字发送一个FIN包,但是,客户端在收到FIN包之后,没有read操作,还是会继续往这个套接字写入数据。这是因为根据TCP协议,连接是双向的,收到对方的FIN包只意味着**对方不会再发送任何消息**。 在一个双方正常关闭的流程中,收到FIN包的一端将剩余数据发送给对面(通过一次或多次write),然后关闭套接字。
|
|
|
|
|
|
当数据到达服务器端时,操作系统内核发现这是一个指向关闭的套接字,会再次向客户端发送一个RST包,对于发送端而言如果此时再执行write操作,立即会返回一个RST错误信息。
|
|
|
|
|
|
你可以看到针对这个全过程的一张描述图,你可以参考这张图好好理解一下这个过程。
|
|
|
|
|
|
|
|
|
以上是在Linux 4.4内核上测试的结果。
|
|
|
|
|
|
在很多书籍和文章中,对这个实验的期望结果不是这样的。大部分的教程是这样说的:在第二次write操作时,由于服务器端无法查询到对应的TCP连接信息,于是发送了一个RST包给客户端,客户端第二次操作时,应用程序会收到一个SIGPIPE信号。如果不捕捉这个信号,应用程序会在毫无征兆的情况下直接退出。
|
|
|
|
|
|
我在Max OS 10.13.6上尝试这个程序,得到的结果确实如此。你可以看到屏幕显示和时序图。
|
|
|
|
|
|
```
|
|
|
#send into buffer 19
|
|
|
#send into buffer -1
|
|
|
#send error: Broken pipe (32)
|
|
|
|
|
|
```
|
|
|
|
|
|
这说明,Linux4.4的实现和类BSD的实现已经非常不一样了。限于时间的关系,我没有仔细对比其他版本的Linux,还不清楚是新的内核特性,但有一点是可以肯定的,我们需要记得为SIGPIPE注册处理函数,通过write操作感知RST的错误信息,这样可以保证我们的应用程序在Linux 4.4和Mac OS上都能正常处理异常。
|
|
|
|
|
|
## 总结
|
|
|
|
|
|
在这一讲中,我们意识到TCP并不是那么“可靠”的。我把故障分为两大类,一类是对端无FIN包,需要通过巡检或超时来发现;另一类是对端有FIN包发出,需要通过增强read或write操作的异常处理,帮助我们发现此类异常。
|
|
|
|
|
|
## 思考题
|
|
|
|
|
|
和往常一样,给大家布置两道思考题。
|
|
|
|
|
|
第一道,你不妨在你的Linux系统中重新模拟一下今天文章里的实验,看看运行结果是否和我的一样。欢迎你把内核版本和结果贴在评论里。
|
|
|
|
|
|
第二道题是,如果服务器主机正常关闭,已连接的程序会发生什么呢?
|
|
|
|
|
|
你不妨思考一下这两道题,欢迎你在评论区写下你的模拟结果和思考,我会和你一起交流,也欢迎把这篇文章分享给你的朋友或者同事,一起交流一下。
|
|
|
|