452 lines
26 KiB
Markdown
452 lines
26 KiB
Markdown
# 22 | 为什么压力测试TPS总是上不去?
|
||
|
||
你好,我是胜辉。
|
||
|
||
在上一讲里,我们排查了一个跟操作系统紧密相关的性能问题。我们结合top和strace这两个工具,抓住了关键点,从而解决了问题。性能问题,确实也是我们日常技术工作中的一个重要话题。在出现性能问题以后,我们要有能力搞定它;而在出现性能问题之前,最好能提前预见到它。而要“预见”性能瓶颈,最好的方法就是做**压力测试**。
|
||
|
||
但是,我们在做压力测试的过程中也时常出现预料不到的情况。比如在离预期的瓶颈值还很远的时候,系统就出现了各种意外,影响到压力测试的继续进行。
|
||
|
||
那么在这节课里,我们会回顾几个典型的压力测试场景中的网络问题,一起来学习其中的关键要点。同时,我们还会学习一系列跟网络性能相关的压测工具和检测工具,这样以后你遇到类似的问题时,就有所准备了。
|
||
|
||
## 压测要做什么?
|
||
|
||
压力测试的诉求实际上多种多样,不过大体上可以分为这几种。
|
||
|
||
**应用的承受能力**:这主要在第七层应用层,比如发起了压测,把服务端的CPU打到95%甚至100%,观察这时候的请求的TPS、请求耗时、并发量等等。而这些对于不同的业务场景,又会有不同的侧重点。比如:
|
||
|
||
* 对于时间敏感型业务来说,请求耗时(Latency)这个指标就是关键了。
|
||
* 对于经常做秒杀的电商来说,并发处理量TPS(Transaction Per Second)就是一个核心关注点了。
|
||
|
||
**LB的连接处理能力**:这主要在第四层TCP,看LB能最大支持的TCP并发连接数。这时候,发起压测的客户端一般会指定比较大的并发数,这样就可以发起尽量多的TCP连接。
|
||
|
||
**网络的承受能力**:这可能主要在第三层IP层了,比如测试上行和下行带宽能否跑满、是否有丢包和额外的延迟,等等。特别是对于一些流量比较大的场景,很可能服务端计算能力都还在,但带宽已经不够用了,所以我们要提前发现这些隐患。
|
||
|
||
## 案例1:压测TPS上不去
|
||
|
||
我们有个客户是传统企业转型做电商,有一次准备搞大促。为了确保大促顺利,他们要提前对网站进行压测。
|
||
|
||
客户用的压测工具比较简单,是Apache ab。ab是Apache Benchmark的缩写,它的用途就是对HTTP服务端发起测试,以获得性能指标(Benchmark)。ab本身不是独立安装的,而是在apache2-utils工具包里,所以你可以这样来安装它:
|
||
|
||
```bash
|
||
apt install apache2-utils
|
||
|
||
```
|
||
|
||
ab是一个轻量级的工具,因为相对其他重量级的工具比如LoadRunner或者JMeter来说,ab只要一行命令就可以发起压测了,是不是很省事?比如你可以这样:
|
||
|
||
```bash
|
||
ab -c 100 -n 10000 目标URL
|
||
|
||
```
|
||
|
||
通过上面的命令,你就用-c 100这个参数,让ab发起了100个并发的请求,而-n 10000指定了总共发送的请求量。
|
||
|
||
> 补充:这里有一个小的注意点。如果目标URL只是站点名本身,还是需要在结尾处加上“`>/`”,要不然ab会报这个错误:`ab: invalid URL`
|
||
|
||
比如我用下面这条ab命令,对一个著名网站发起“压测”,当然我的参数选择的很小,只有10个并发,一共100次请求,尽量避免打扰到这个网站。我们可以看一下输出:
|
||
|
||
```bash
|
||
$ ab -c 10 -n 100 https://www.baidu.com/abc
|
||
This is ApacheBench, Version 2.3 <$Revision: 1843412 $>
|
||
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
|
||
Licensed to The Apache Software Foundation, http://www.apache.org/
|
||
|
||
Benchmarking www.baidu.com (be patient).....done
|
||
|
||
|
||
Server Software: Apache
|
||
Server Hostname: www.baidu.com
|
||
Server Port: 443
|
||
SSL/TLS Protocol: TLSv1.2,ECDHE-RSA-AES128-GCM-SHA256,2048,128
|
||
Server Temp Key: ECDH P-256 256 bits
|
||
TLS Server Name: www.baidu.com
|
||
|
||
Document Path: /abc
|
||
Document Length: 201 bytes
|
||
|
||
Concurrency Level: 10
|
||
Time taken for tests: 9.091 seconds
|
||
Complete requests: 100
|
||
Failed requests: 0
|
||
Non-2xx responses: 100
|
||
Total transferred: 34600 bytes
|
||
HTML transferred: 20100 bytes
|
||
Requests per second: 11.00 [#/sec] (mean)
|
||
Time per request: 909.051 [ms] (mean)
|
||
Time per request: 90.905 [ms] (mean, across all concurrent requests)
|
||
Transfer rate: 3.72 [Kbytes/sec] received
|
||
|
||
Connection Times (ms)
|
||
min mean[+/-sd] median max
|
||
Connect: 141 799 429.9 738 4645
|
||
Processing: 19 67 102.0 23 416
|
||
Waiting: 17 67 101.8 23 416
|
||
Total: 162 866 439.7 796 4666
|
||
|
||
Percentage of the requests served within a certain time (ms)
|
||
50% 796
|
||
66% 877
|
||
75% 944
|
||
80% 1035
|
||
90% 1093
|
||
95% 1339
|
||
98% 1530
|
||
99% 4666
|
||
100% 4666 (longest request)
|
||
|
||
```
|
||
|
||
结尾部分的多个Percentage,确切地说就是Percentile,也就是百分位。比如50% 796这一行的意思是:第50个请求(因为总数是100个)的耗时小于等于796毫秒,另外50个请求大于796毫秒。那么我们也可以知道,耗时最长的那个就是排最后一名的4666,它的耗时是4666毫秒。
|
||
|
||
这次,客户用ab时指定的具体参数是这样的:
|
||
|
||
```bash
|
||
ab -k -c 500 -n 100000 http://site.name.com/path
|
||
|
||
```
|
||
|
||
也就是并发数为500,总次数为10万,而-k参数是启用长连接。然后就是查看以下两个主要指标:
|
||
|
||
* ab这个客户端的耗时分布,也就是前面刚介绍过的各个百分位的耗时数值。
|
||
* 服务端的性能指标,也就是在这个压力下面,服务端的CPU、内存、网络丢包率等的统计数值。
|
||
|
||
|
||
|
||
压测过程中,客户发现测试端的带宽用到400Mbps后,TPS就上不去了,无论把并发量或者总量的数值进行怎样的调整,TPS都会维持在一个稳定的数值。
|
||
|
||
```bash
|
||
Transfer rate: 52087.82 [Kbytes/sec] received
|
||
|
||
```
|
||
|
||
那究竟是不是购买的服务端主机的性能不够的原因呢?要知道,客户端和服务端都是1Gbps的网卡,客户是想压满100%的带宽,现在只用到了40%的带宽,TPS就上不去了。
|
||
|
||
为什么会这样呢?
|
||
|
||
我们就跟客户配合,一边做ab压测,一边做了4秒钟的tcpdump抓包,这对采样分析来说也够用了。然后打开抓包文件,查看专家信息(Expert Information),如下:
|
||
|
||
> 补充:抓包示例文件已经上传至[Gitee](https://gitee.com/steelvictor/network-analysis/tree/master/22),建议结合抓包文件和文稿一起学习。
|
||
|
||

|
||
|
||
这次我就不做标记了,你自己先找找看,能否找到一些问题?
|
||
|
||
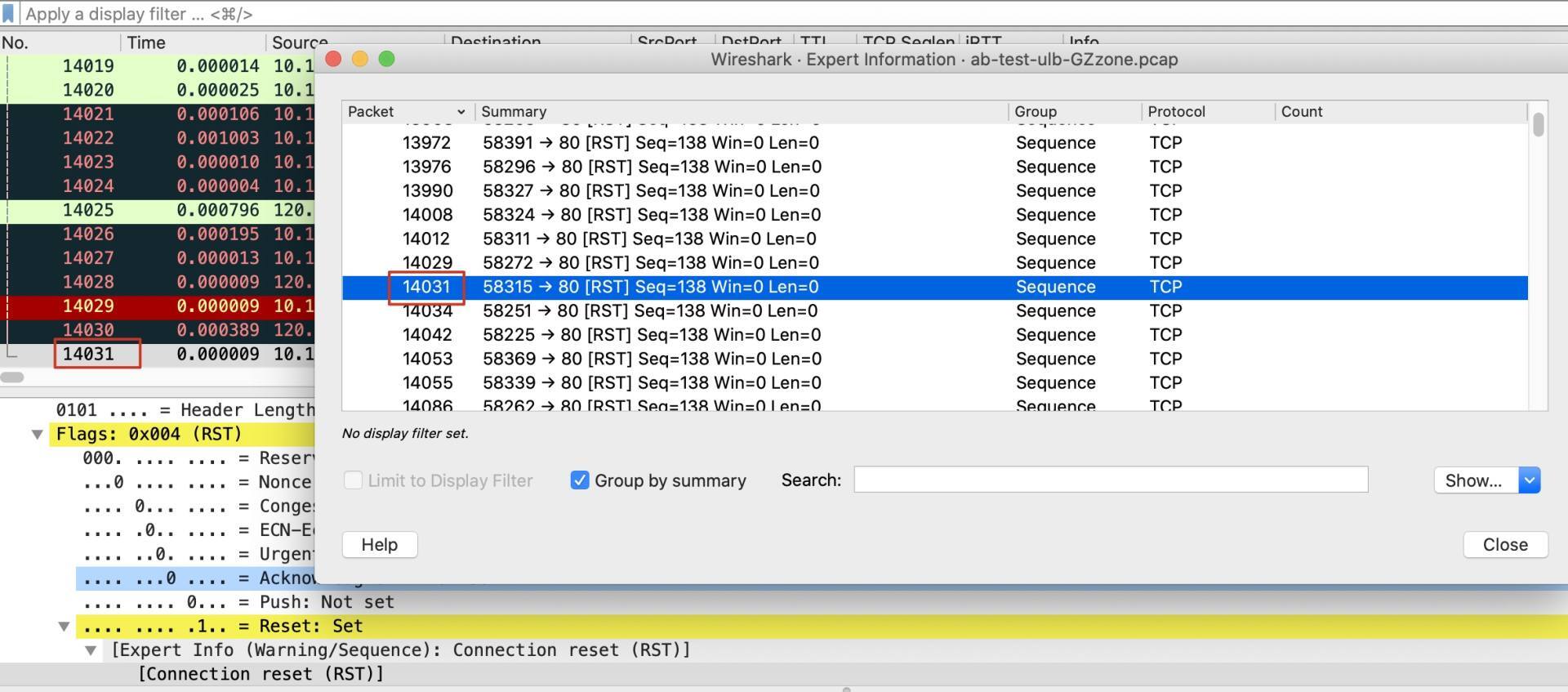
你有没有发现,GET有1603次(倒数第三行),而RST有1982次(第三行),比GET这种HTTP请求的次数还更多。也就是说,平摊的话,每次GET请求对应了一次以上的RST。这个现象会不会跟TPS上不去的问题有关系呢?
|
||
|
||
我们选一个RST来看一下情况。比如14031号报文:
|
||
|
||
|
||
|
||
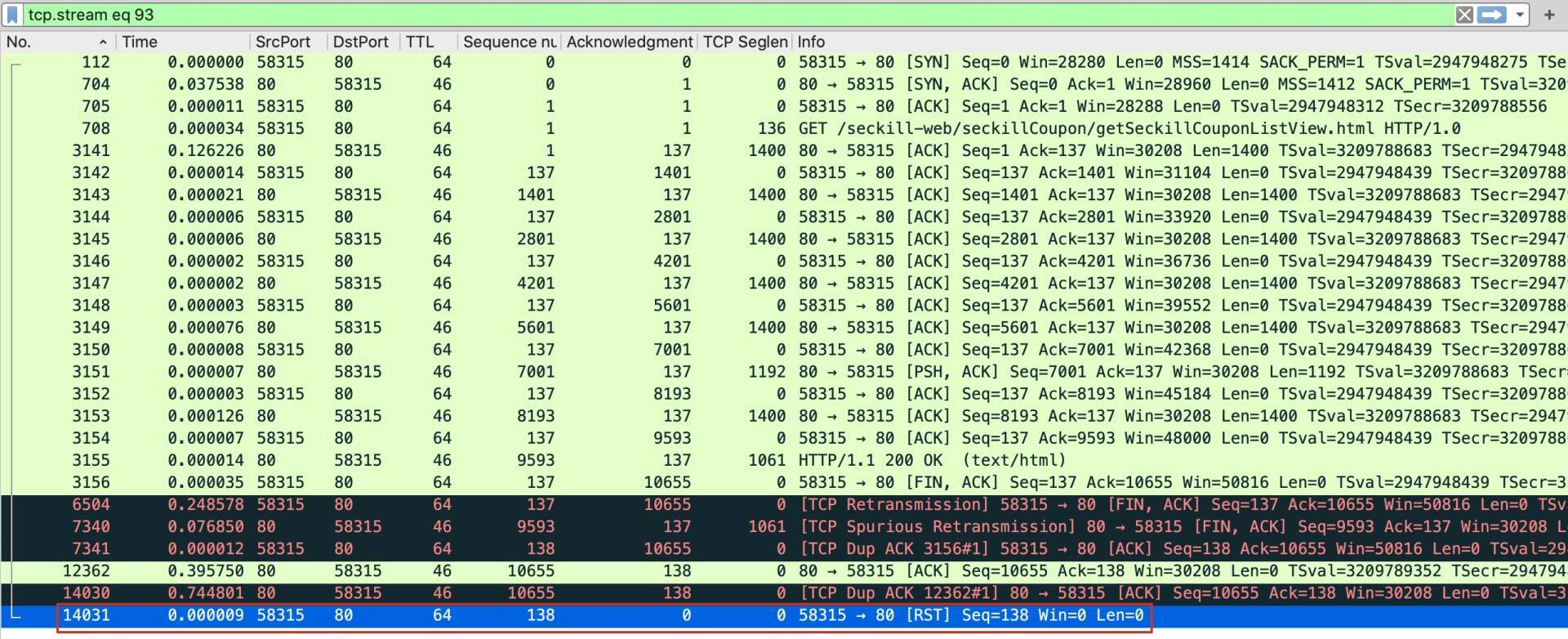
然后Follow -> TCP Stream,就来到了这条TCP流:
|
||
|
||
|
||
|
||
在这里,你有没有发现两个重传报文?一个是6504号报文,一个是7340号报文。我们再进一步看一下这两个的重传的原因是什么。一般来说,判断一个报文是否是重传,最方便的就是借助Wireshark本身提供的提示,Wireshark说是Retransmission,那就是了。
|
||
|
||
那么假设世界上还没有Wireshark,你又**如何判断一个报文是否是重传呢?**其实可以根据两个关键信息:**序列号、载荷长度**。
|
||
|
||
我在之前的课程里提到过,序列号本身反映的就是字节位置,载荷的长度就表示这段报文的实际字节长度,这两个信息就确定了信息的**起点和终点**,也就是决定了一个报文是否是之前报文的重传。
|
||
|
||
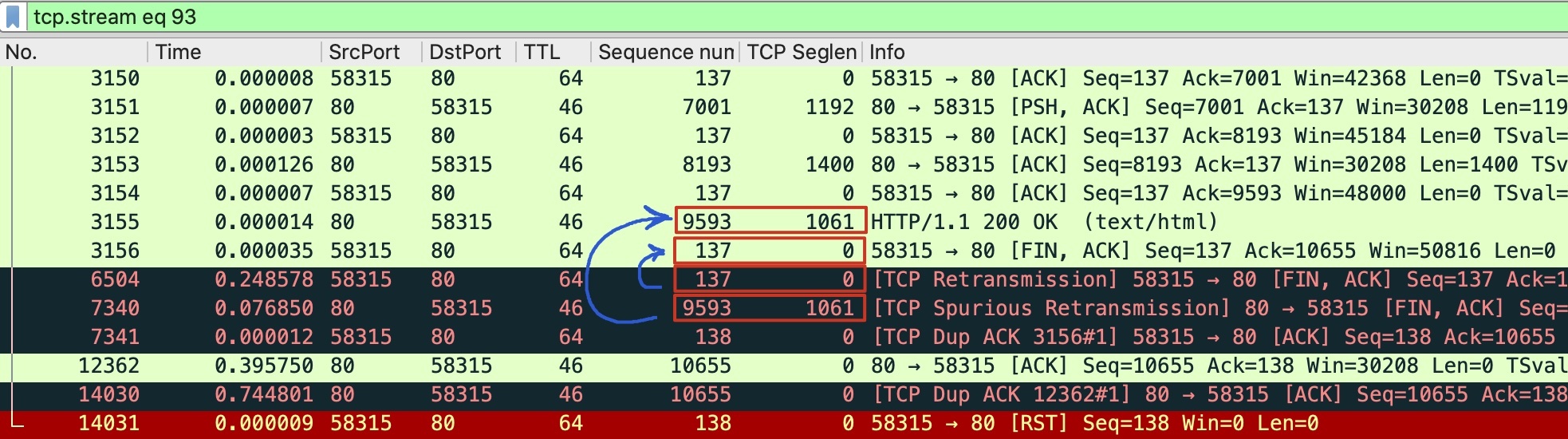
在上面的截图里,我们根据序列号(Sequence Number列)和载荷长度(TCP Seglen列),判断出下面两次重传:
|
||
|
||
|
||
|
||
可见,7340是3155报文的重传,因为它们的序列号都是9593,载荷长度都是1061。同样的道理,6504和3156也是一对重传关系。
|
||
|
||
当然,我们也可以直接在Wireshark里选中7340号报文,它的基础报文也就是3155的**前面会出现一个小圆点**,就像下图这样:
|
||
|
||

|
||
|
||
总之,我们确认TCP传输中是有丢包和重传现象的,我们可以回头从专家信息那里得到证实,这里显示有184个Suprious重传和2274个(超时)重传。
|
||
|
||

|
||
|
||
> 补充:而出现RST的原因,是客户端在已经没有了这个TCP连接的情况下,收到了服务端的ACK报文。从现象来看,客户端应该是做了TIME\_WAIT优化的设置,我们后面的实验里也会带到。
|
||
|
||
考虑到这是在压测场景中出现的丢包现象,我们根据经验,想到了**网卡包量**的问题。
|
||
|
||
一般说到网络性能,我们会讨论的就是带宽、时延、网速等等这些指标。实际上,另外一个性能指标常常在达到带宽极限之前就已经触顶了,它就是包量。
|
||
|
||
**包量是对PPS(Packet Per Second)的简称,一般用来衡量一台主机的网络处理能力。**那么,这次是不是触及了服务端主机的包量上限了呢?我们又如何检查包量指标呢?
|
||
|
||
我们需要用的工具是sar。
|
||
|
||
### 性能工具sar
|
||
|
||
sar是sysstat工具集的一部分。这个工具集包含了一些很有用的工具,除了sar,还有mpstat、iostat等等。如果你平时经常做操作系统维护方面的工作,应该对它们比较熟悉了。这些工具还有一个共同的特点,运行的时候一般都是加上“间隔 次数”这样的参数的。也就是下面这样:
|
||
|
||
```bash
|
||
sar -n DEV 1 10 #查看网卡性能
|
||
iostat 1 10 #查看IO性能
|
||
mpstat 2 5 #查看CPU性能
|
||
|
||
```
|
||
|
||
这些工具会按指定的时间间隔,运行指定的次数后再退出。这样我们就可以观察到这段时间内的多次输出了,很适合通过这种多次的观察,得到比较准确的性能数据趋势。
|
||
|
||
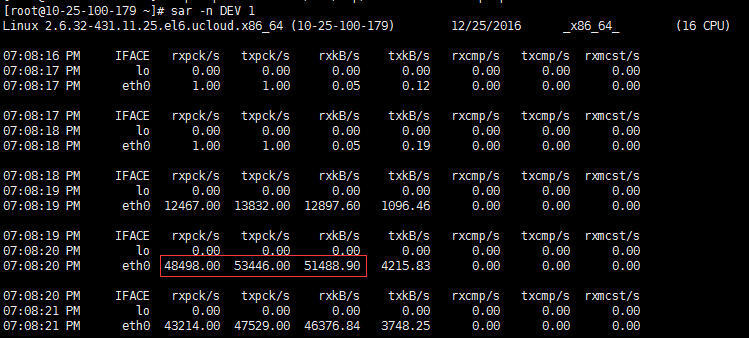
这次我们也在被压测的服务端云主机上运行了 `sar -n DEV`,得到了以下的性能数据:
|
||
|
||
|
||
|
||
前面说的包量,就是体现在两个pck/s指标中,一个是 **rxpck/s**,就是接收方向的包量;一个是 **txpck/s**,就是发送方向的包量。显然,图中的数值已经在5万左右,这个正是当时我们云主机性能的上限。难怪服务端已经无法提供更高的TPS了,因为网络包的处理都来不及做了。
|
||
|
||
那你可能会问了:“网络包也有大有小,这个包量指标说的是大包还是小包呢?”
|
||
|
||
其实,一般的包量测试,不是随便什么大小的报文都可以测试,而是普遍使用64字节长度的IP报文。另外,我们也要认识到,包的大小对包量性能的影响也不是很大。这是因为,对于网络处理来说,主要的开销在包的头部的处理上,而载荷本身的处理是很快的。
|
||
|
||
那么,对于客户遇到的这种包量达到上限的情况,我们可以选择的应对办法是这样的:
|
||
|
||
* 选择更高网络性能的主机,比如硬件的RSS、软件的RPS等特性,都会大幅提升包量处理性能。
|
||
* 对服务集群进行水平扩展,也就是在LB后面增加服务器,这样VIP作为一个整体提供的包,处理能力也就提升了。
|
||
|
||
## 案例2:LoadRunner压测发现部分失败
|
||
|
||
这是另外一个客户,他们没有用ab这样的简单工具,而是用了LoadRunner这样一个企业级的测试软件。LoadRunner的厉害之处在于,不仅可以发起巨大的请求量,而且可以模拟用户的复杂行为,比如登录、浏览、加入购物车等等。这一系列事务有前后状态关系,这就不是简单的ab可以做到的了。
|
||
|
||
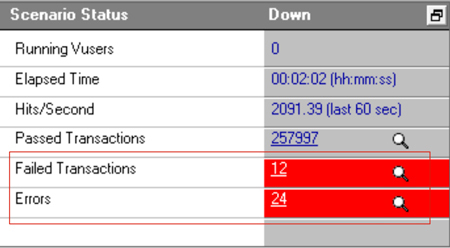
但是测试结果中的小几十个Failed和Error引起了客户的疑虑。他们怀疑:是不是我们公有云的机器或者网络质量不行,所以才导致了这些失败呢?
|
||
|
||
|
||
|
||
我们就尝试复现这个压测场景,同时也对测试机上的TCP资源情况做检查,其中最主要的就是源端口了。
|
||
|
||
为什么会想到这个呢?因为压测发起的请求,都是依托于TCP连接的。我们在[第1讲](https://time.geekbang.org/column/article/477510)里就提到过:**TCP连接是基于五元组的**。那么对于客户端来说,源IP、目的IP、目的端口、协议,这四个元素都不会变化,**唯一会变的就是自己的源端口**了。那么我们来看看,当时测试机的源端口情况。
|
||
|
||
这是一台Window机器,跟Linux类似,我们执行这条命令:
|
||
|
||
```bash
|
||
netstat -ant
|
||
|
||
```
|
||
|
||
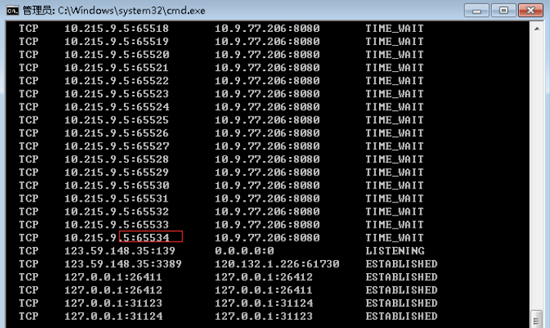
输出如下图:
|
||
|
||
|
||
|
||
原来,确实有大量的TCP连接都在TIME\_WAIT状态,尤其是源端口已经用到了**65534**。所以可以肯定,这次压测中出现失败的原因,就在于源端口耗尽。
|
||
|
||
那要如何处理呢?显然我们也变不出更多的端口来。这个时候,我们可以**调整压测软件的设置,比如从短连接改成长连接**。这样就可以避免源端口耗尽的情况,因为所有的请求是在长连接里完成的,只要连接池本身设置合理,源端口就不会被用完。
|
||
|
||
## 案例3:压测报cannot assign requested address错误
|
||
|
||
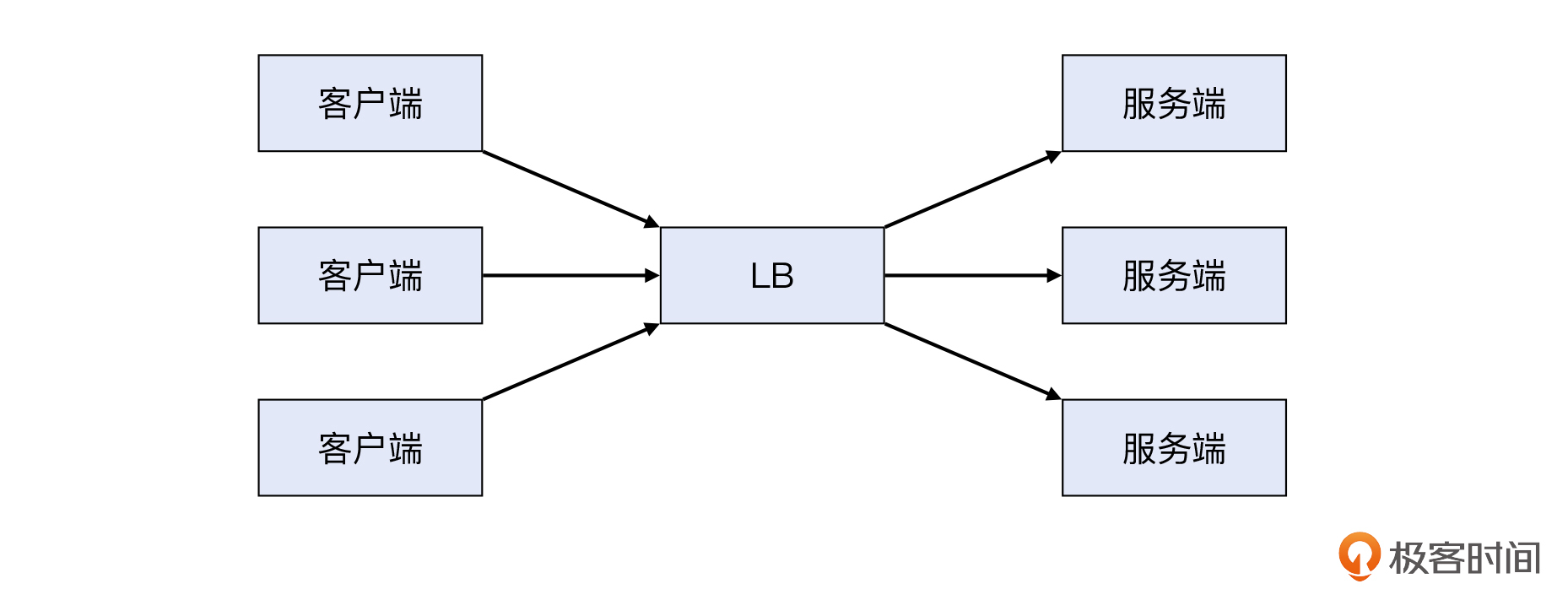
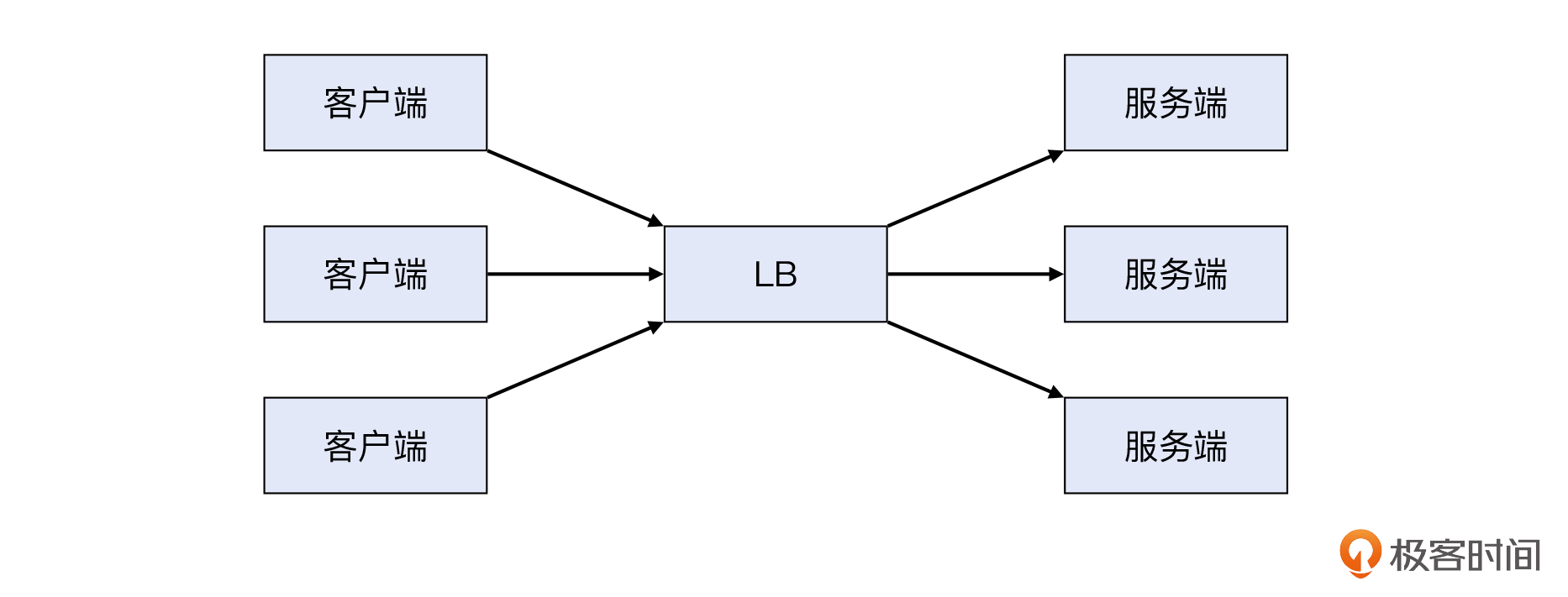
我们内部有一个团队在做业务压力测试,结果遇到了一个奇怪的报错:cannot assign requested address。这次的场景是这样的:这个团队从多台客户端机器向LB上的一个VIP,发送大量的请求,而LB的后面就是很多的服务器。
|
||
|
||
|
||
|
||
但是,还没等到这些服务器的负载跑起来,客户端那边提前报错了。这是一个Go语言的程序,具体的报错信息如下:
|
||
|
||
```plain
|
||
https://test.vip/a": dial tcp 10.123.123.12:443: connect: cannot assign requested address
|
||
http post Post \"https://test.vip/b": dial tcp 10.123.123.12:443: connect: cannot assign requested address retry 1 times
|
||
|
||
```
|
||
|
||
于是他们就怀疑:既然报错是连接出错,那是不是LB有什么问题呢?比如,是否LB本身处理能力不够,不能服务这么大量的连接请求?否则为什么客户端会报connect的错误呢?要知道,用来发起TCP连接的系统调用(syscall)就是connect。
|
||
|
||
确实,这个报错信息“dial tcp 10.123.123.12:443: connect: cannot assign requested address”说得不太清楚。表面上看,就是客户端往10.123.123.12:443这个VIP发起连接请求(用connect)然后遇到了报错,也难怪测试团队会找到我们来查看LB的问题。
|
||
|
||
我们检查了LB,发现一切正常。于是把排查方向换到客户端。在这次测试中,有一个参数是关于HTTP Keep-alive的。如果你对课程前面的内容还有印象的话,应该还记得我们在第7讲“[保活机制](https://time.geekbang.org/column/article/482610)”里,深入讨论过这个问题。
|
||
|
||
简单来说,这次的测试配置里,HTTP Keep-alive没有打开,导致这些TCP连接被视作短连接来处理了,也就是一次HTTP请求和响应完成后,这条连接就关闭了。由于发起关闭的是客户端自己,于是这条连接也就进入了TIME\_WAIT状态。
|
||
|
||
而要查看TIME\_WAIT状态的连接数量,我们可以用 **netstat命令**,配合管道和awk来完成统计。比如,这次我在一台客户端机器上执行了下面的命令:
|
||
|
||
```bash
|
||
$ netstat -ant |awk '{++a[$6]} END{for (i in a) print i, a[i]}'
|
||
TIME_WAIT 28231
|
||
|
||
```
|
||
|
||
或者用下面的 **ss命令**会更快:
|
||
|
||
```bash
|
||
ss -ant | awk '{++s[$1]}END{for(k in s) print k,s[k]}'
|
||
TIME-WAIT 28231
|
||
|
||
```
|
||
|
||
可见,处于TIME\_WAIT状态的连接数接近3万个,差不多就是Linux的本地动态端口的范围了。我们随后检查这台Linux机器的本地源端口范围,执行了下面的命令:
|
||
|
||
```plain
|
||
$ cat /proc/sys/net/ipv4/ip_local_port_range
|
||
32768 60999
|
||
|
||
```
|
||
|
||
于是发现它的下限是32768,上限是60999,范围正好就是28231,跟TIME\_WAIT的数量一致,显然也是一次源端口耗尽导致的压测问题。
|
||
|
||
当然,用sysctl也一样可以查看这个范围:
|
||
|
||
```bash
|
||
sysctl net.ipv4.ip_local_port_range
|
||
|
||
```
|
||
|
||
不过你可能会问:“难道压测中的网络排查,除了包量和源端口,就没有别的问题了吗?”
|
||
|
||
我们来看一个不一样的案例。
|
||
|
||
## 案例4:压测遇到connection reset by peer
|
||
|
||
这次的场景是一个应用团队用netty http client去调用一个VIP做压测。具体来说是9台客户端机器,向同一个LB VIP发起大量的请求。
|
||
|
||
|
||
|
||
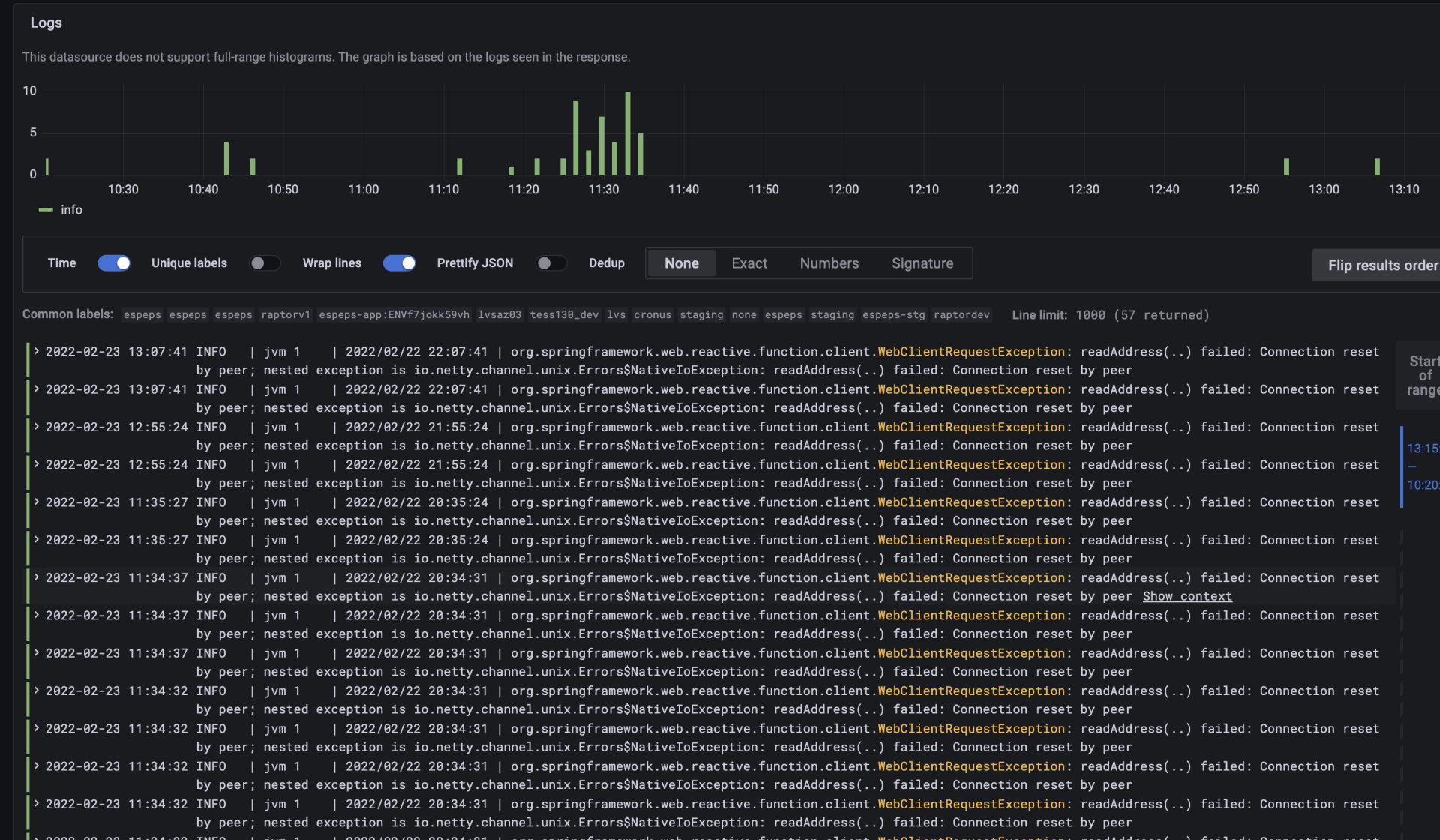
结果遇到了connection reset by peer。蹊跷的是,这个报错是零零星星出现的。而像之前的例子,如果真的源端口用尽了,那么接下来一段时间内,这些请求都会因为本地没有源端口可用而宣告失败,也就是报错会是大面积出现,而不会零星出现。
|
||
|
||
|
||
|
||
从图上看,报错数量不超过50个,主要集中在11点20分到11点35分这个时间段,这正是压测的时段。因为报错只有50来个,这相比于这次压测发起的成千上万的请求来说,是很小的比例了。
|
||
|
||
> 补充:Y轴就是报错的个数,最高值是10,我们把几个柱体的高度加起来,就是报错的总数量了。
|
||
|
||
我们了解到,压测期间每个客户端的请求频率是700TPS,所以9台客户端一共会发起6300TPS的请求量。这个问题诡异的地方就是,大部分的请求都能得到正确及时的回复,但是隔了两三分钟,就会出现几次这种connection reset by peer的问题。
|
||
|
||
那我们需要理解一下,**为什么会reset**。
|
||
|
||
我们在做网络排查的时候,如果在Wireshark里看到TCP RST,往往会觉得它不是一个好的征兆。确实,有时候是RST引起了故障,有时候又是网络故障迫使TCP用RST来结束连接。无论RST是因还是果,它总是跟问题本身逃不脱关系。
|
||
|
||
那干脆在TCP里取消RST,是不是很多问题就会被解决呢?当然不是,RST在TCP里面是一个非常必要的组成部分。没有RST,其实就没有“坏”的结束,也就没有“好”的开始。
|
||
|
||
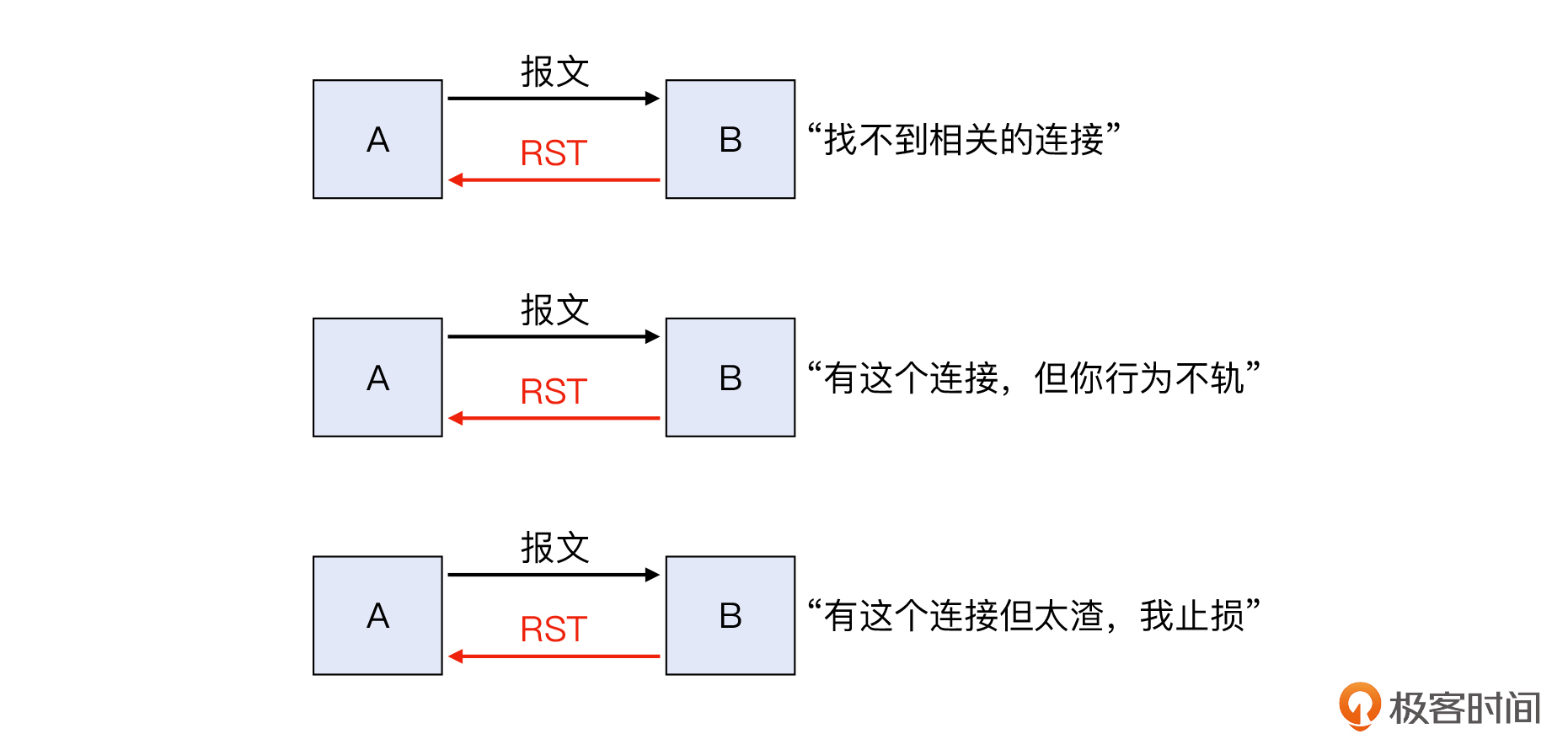
大体上,TCP RST的原因可以分为这么几个大类:
|
||
|
||
* 找不到相关连接,那么接收端可以放心地直接发送RST。
|
||
* 找到了相关连接,但收到的报文不符合TCP规范,那么接收端也可以发送RST。
|
||
* 找到了相关连接,但传输状况恶劣,内核选择及时“止损”,发送RST。
|
||
|
||
|
||
|
||
而这次案例里面的情况,就符合第一种。这是因为:
|
||
|
||
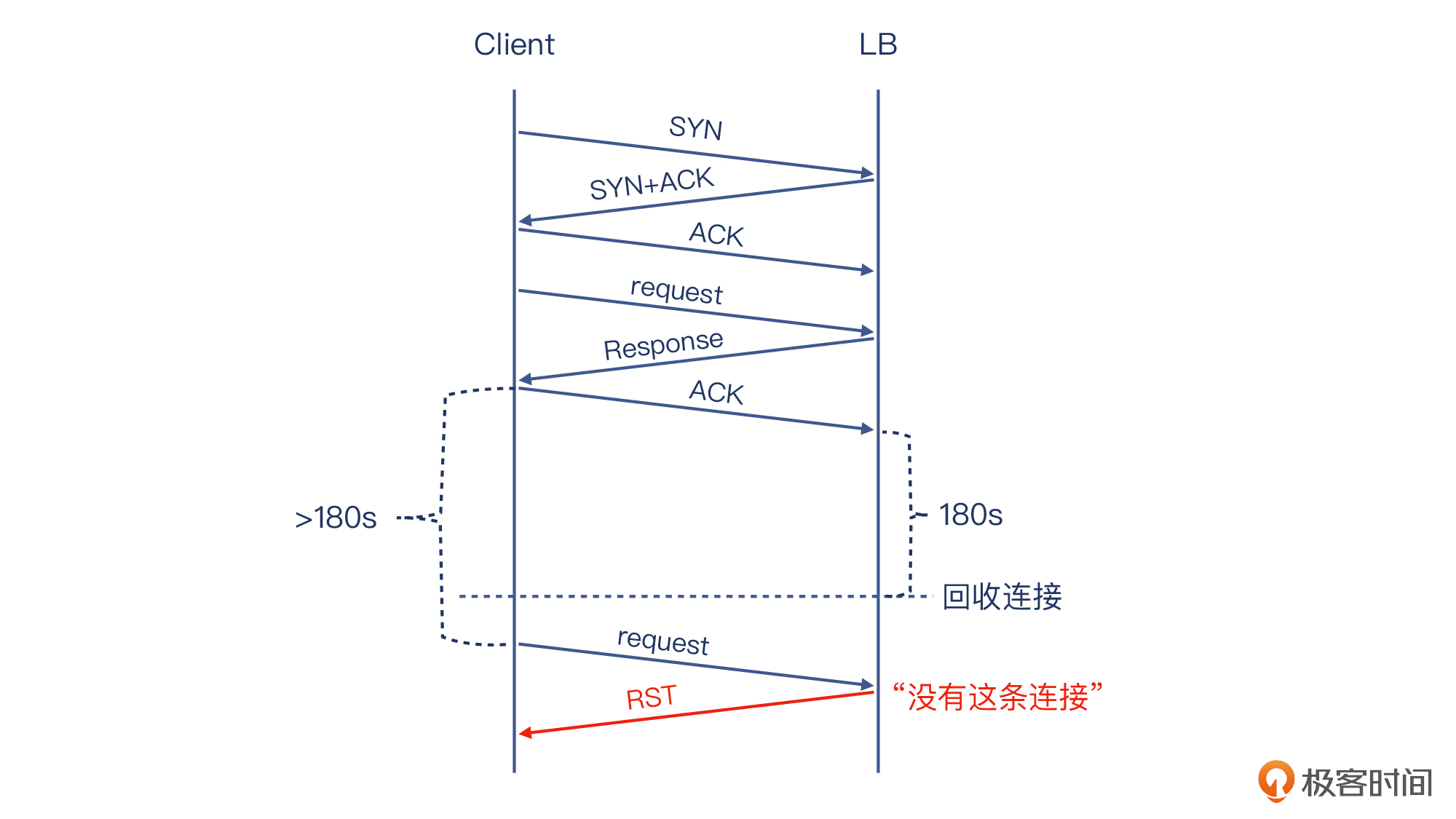
* 我们的LB上的VIP有一个idle timeout的设置,如果客户端在一定时限内不发任何报文,那么这条连接将被回收。这个时限是180秒,而且回收时不向客户端发送FIN或者RST报文。
|
||
* 这次的压测客户端框架里,有一个设置值也是关于idle timeout的。不过这个值设置的是360秒。
|
||
|
||
你有没有发现问题?这两个idle timeout值一边大一边小,配合不当,就会出现下面这样的问题:
|
||
|
||
|
||
|
||
某条TCP连接中完成一次HTTP请求和响应之后,连接没有被关闭。过了180秒,LB这一侧的连接被回收了,但客户端那边还没到360秒,所以还认为这条连接是活着的,于是在180秒之后发起了一次请求。报文到达LB,后者在连接表里没有查到这条连接,于是回复了RST。
|
||
|
||
根因清楚了,解决起来异常简单:把客户端的Idle timeout参数,从原先的360秒,改成比LB的180秒更低的值就好了。这次改到了120秒,RST就完全消失了。
|
||
|
||
你看,虽然在案例2里,我们知道了压测最好使用长连接,这样可以避免源端口耗尽的问题。但是不等于你设置了长连接就一劳永逸了,还需要考虑idle timeout的问题。这次压测的关键在于:要确保长连接本身是真正有效的,你需要**确保客户端的idle timeout小于服务端的idle timeout,这样才能避免连接失效导致的RST**。
|
||
|
||
> 补充:这个库是Ractor-Netty,idle timeout对应的是[evictInBackground](https://projectreactor.io/docs/netty/release/api/reactor/netty/resources/ConnectionProvider.ConnectionPoolSpec.html#evictInBackground-java.time.Duration-) + [maxLifeTime](https://projectreactor.io/docs/netty/release/api/reactor/netty/resources/ConnectionProvider.ConnectionPoolSpec.html#maxLifeTime-java.time.Duration-)。
|
||
|
||
## 实验
|
||
|
||
回顾完这些压测案例,你可能会发现其实难度并不太大,是不是也跃跃欲试了呢?接下来,我们就用ab来做个小实验,这次还捎带一个小任务:**控制TIME\_WAIT状态的连接的数量**。
|
||
|
||
在案例2和3里面,源端口耗尽的问题,本质是TIME\_WAIT需要停留2MSL的时长。要解决TIME\_WAIT连接过多的问题,方法有很多。这次我们只实验其中的一种方法,就是修改 `net.ipv4.tcp_max_tw_buckets` 这个内核参数。
|
||
|
||
它的默认值为16384,改为更小的值后,超过这个数值的TIME\_WAIT连接会被清除,这样,TIME\_WAIT连接数就被控制住了。
|
||
|
||
这个实验在本地就可以完成,比如在你的笔记本上安装VirtualBox,然后在这个虚拟机里面完成实验。
|
||
|
||
步骤一:安装Nginx和Apache ab。
|
||
|
||
```bash
|
||
apt install nginx
|
||
apt install apache2-utils
|
||
|
||
```
|
||
|
||
步骤二:启动ab测试,执行下面的命令。
|
||
|
||
```bash
|
||
ab -c 500 -n 10000 http://localhost/
|
||
|
||
```
|
||
|
||
步骤三:观察TCP连接的各种状态的统计数。
|
||
|
||
```bash
|
||
ss -ant | awk '{++s[$1]}END{for(k in s) print k,s[k]}'
|
||
|
||
```
|
||
|
||
此时你应该会看到1万多个TIME\_WAIT的连接,然后等待2分钟后继续步骤四。
|
||
|
||
步骤四:修改内核参数 `tcp_max_tw_buckets` 为100。
|
||
|
||
```bash
|
||
sysctl net.ipv4.tcp_max_tw_buckets=100
|
||
|
||
```
|
||
|
||
步骤五:再次ab测试。
|
||
|
||
```bash
|
||
ab -c 500 -n 10000 http://localhost/
|
||
|
||
```
|
||
|
||
步骤六:再次观察TCP连接的各种状态的统计数。
|
||
|
||
```bash
|
||
ss -ant | awk '{++s[$1]}END{for(k in s) print k,s[k]}'
|
||
|
||
```
|
||
|
||
此时TIME\_WAIT应该只有100了。
|
||
|
||
当然,TIME\_WAIT本身被设计出来是有原因的,建议你在改动它之前,把自己的场景想清楚,然后再改不迟。
|
||
|
||
## 小结
|
||
|
||
这节课,我们回顾了几个典型的压力测试场景中的网络问题,你需要重点掌握以下这些知识点。
|
||
|
||
**关于压测指标和工具。**轻量级的工具是ab,它十分方便,而且也可以发起大量的请求,在简单的压测场景下很有用。比如下面的命令:
|
||
|
||
```bash
|
||
ab -k -c 100 -n 10000 目标URL
|
||
|
||
```
|
||
|
||
重量级工具是LoadRunner和JMeter,它们可以实现复杂的交互行为,也提供更加详细的报告。
|
||
|
||
在网络性能领域,**包量是对PPS的简称,一般用来衡量一台主机的网络处理能力。**而评估包量的工具是sar,我们可以运行下面的命令获取到实时的包量值:
|
||
|
||
```bash
|
||
sar -n DEV 1 10
|
||
|
||
```
|
||
|
||
**关于TCP的知识。**这节课里我们也再次温习了TCP相关的知识,包括:
|
||
|
||
* 判断一个报文是否是之前报文的重传,可以根据两个关键信息:**序列号、载荷长度**。这两个值分别相同的多个报文,互相就是重传关系了。
|
||
* 压测数据起不来的一个常见原因是**源端口耗尽**,要验证这一点,可以执行以下命令,来查看TIME\_WAIT或者ESTABLISHED状态的连接数是否到达了上限:
|
||
|
||
```bash
|
||
ss -ant | awk '{++s[$1]}END{for(k in s) print k,s[k]}'
|
||
|
||
```
|
||
|
||
或者:
|
||
|
||
```bash
|
||
netstat -ant |awk '{++a[$6]} END{for (i in a) print i, a[i]}'
|
||
|
||
```
|
||
|
||
* 而连接数到达上限值的问题,往往跟可用的**本地源端口范围**有关。要查看端口范围,我们可以执行这条命令:
|
||
|
||
```bash
|
||
sysctl net.ipv4.ip_local_port_range
|
||
|
||
```
|
||
|
||
* 压测中遇到RST的原因,可能跟两端的idle timeout不合理有关,建议把客户端的idle timeout设置为比服务端idle timeout更低的值。
|
||
|
||
## 思考题
|
||
|
||
最后还是再给你留两道思考题:
|
||
|
||
* 测试HTTP性能经常用ab,那测试带宽本身,一般用什么工具呢?
|
||
* 要把TIME\_WAIT停留的时间2MSL改小,你知道用什么方法吗?
|
||
|
||
欢迎在留言区分享你的答案,也欢迎你把今天的内容分享给更多的朋友。
|
||
|
||
## 附录
|
||
|
||
抓包示例文件:[https://gitee.com/steelvictor/network-analysis/tree/master/22](https://gitee.com/steelvictor/network-analysis/tree/master/22)
|
||
|