22 KiB
15 | Nginx的499状态码是怎么回事?
你好,我是胜辉。
“实战一:TCP真实案例解密篇”刚刚结束。在过去的十几讲里,我们全面回顾了TCP的各种技术细节,从握手到挥手,从重传等容错机制,到传输速度等效率机制,应该说也是对我们的TCP知识做了一个全面的“体检”。如果你发现自己对TCP的掌握还有不少漏洞,也别着急,可以回头复习一下相应部分的内容,或者在留言区提问,我会给你解答。
从这节课开始,我们要进入网络排查的“实战二:应用层真实案例解密篇”了。今天要给你讲解的是一个关于Nginx的排查案例。
Nginx的499状态码是怎么回事?
你肯定听说过Nginx,或者经常用到它。作为一个高性能的HTTP和反向代理服务器,Nginx不管是用来搭建Web Server,还是用作负载均衡都很合适,并且它可供配置的日志字段也很丰富,从各类HTTP头部到内部的性能数据都有。
不过,你在日常维护Nginx时有没有遇到过这种情况:**在Nginx的访问日志中,存在499状态码的日志。**但是常见的4xx家族的状态码只有400、401、403、404等,这个499并未在HTTP的RFC文档中定义,是不是很奇怪?
这个499错误日志,在流量较大的场景下,特别是面向Internet的Web站点场景下还是很常见的 。但如果你遇到过,第一感觉可能会是一头雾水,不知道499这个状态码具体是用来干啥的,因为确实跟其他的400系列状态码太不同了。
我在公有云的时候,做过的一个案例正好是关于Nginx的499日志。当时一位客户向我反馈:他们的Nginx服务器会连续几天记录较多的499错误日志,之后几天可能趋零,然后再回升,整体状况起伏不定。
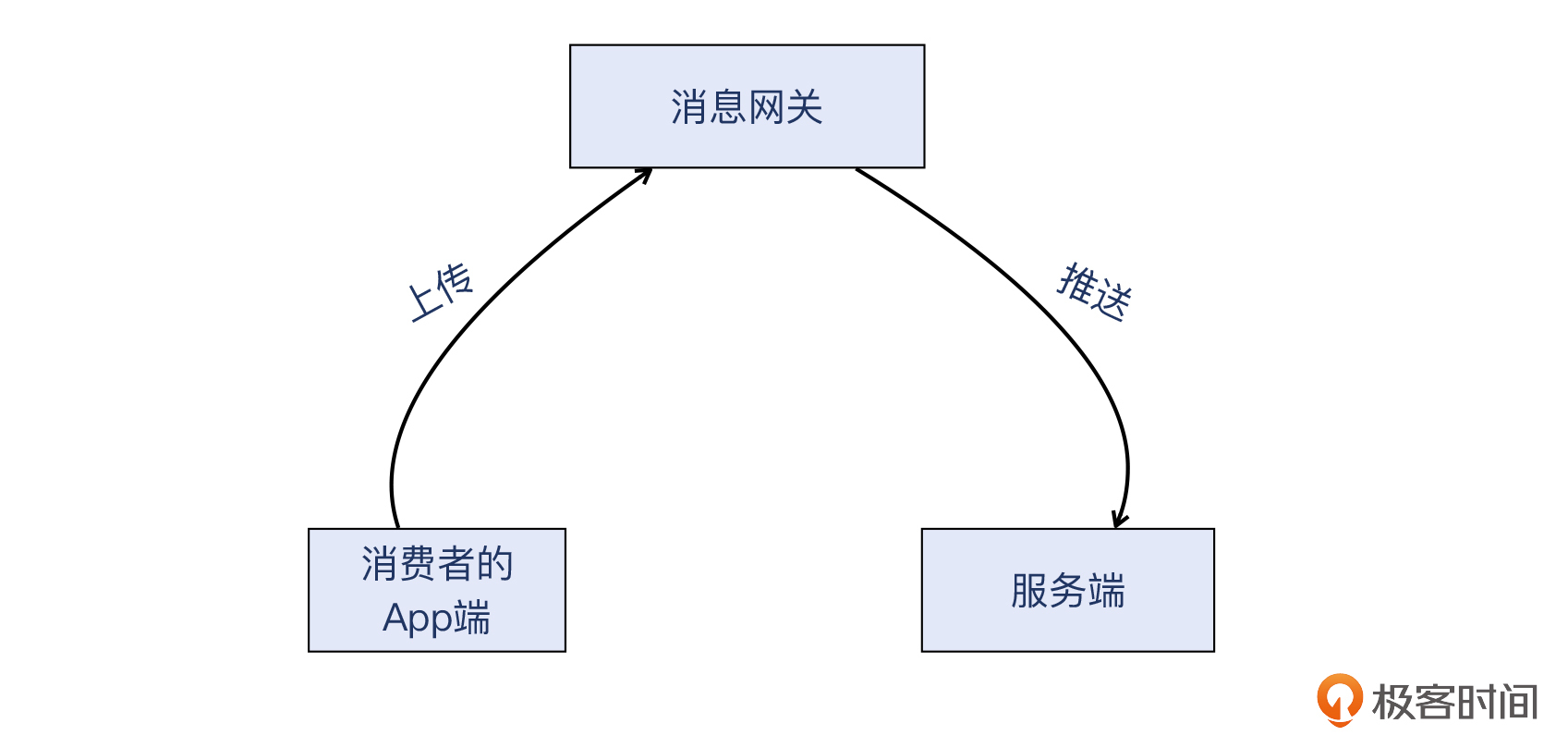
这个客户经营的是To C的电子产品,跟手机端App协同工作。这个App会定时把消息上传到微信消息网关,后者再把这些消息推送到该客户的服务端(在公有云上)做业务处理,整体的消息量约每日三十万条。那么,对消息网关来说,这个服务端就是一个Web回调接口。下面是架构简图:
他们给我提供了499日志趋势图:
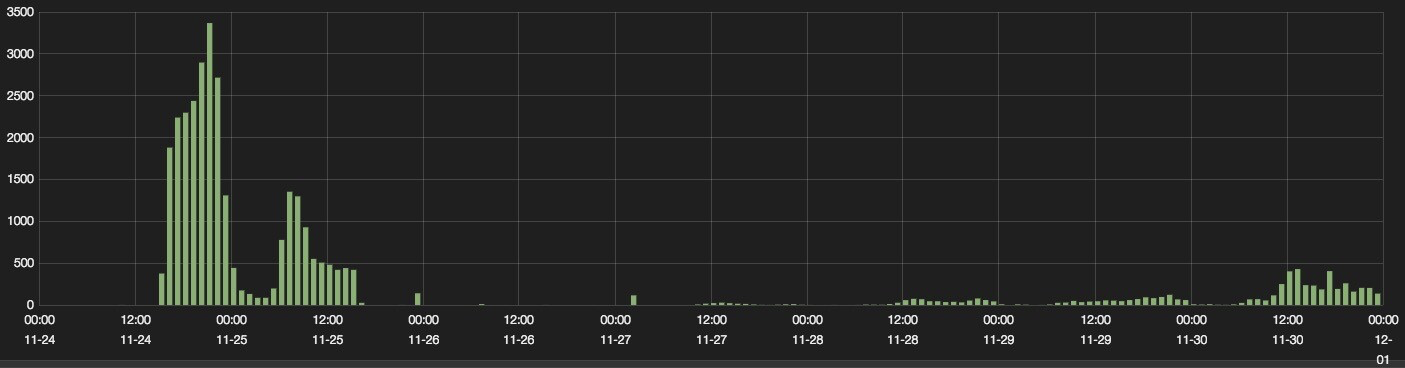
由于大量499日志的存在,客户非常担心业务已经受到影响,比如他们的终端消费者是否经常上传数据失败?是否已经严重影响了消费者的体验?所以,我们需要搞清楚499错误日志的含义。
那么,499这个状态码本身能帮到我们什么呢?我们可以查一下它在Nginx里的官方定义:
NGX_HTTP_CLIENT_CLOSED_REQUEST | 499
可是,什么叫client closed request(客户端关闭了请求)呢?好像说了跟没说也没太大区别。我们知道499是客户端关闭请求引起的,那又是什么原因,引起了“客户端关闭了请求”呢?关于这个问题,Nginx的文档并没有提及。
有一句话叫做“解决问题的办法,可能不在问题自身所处的这个层面”。**应用层日志,其实记录的依然是表象。**更深层次的原因,很可能在更底层,比如在传输层或者网络层。
所以,搞清楚499这个状态码是什么意思,对于我们来说,不仅是理解这个499码的底层含义,而且通过这种排查,我们还能掌握一套对HTTP返回码进行网络分析的方法。这种方法,对于维护好Nginx以及其他Web服务,都是很有帮助的。
那么接下来,我们就根据这个案例,一起探讨下如何用抓包分析,来拆解HTTP返回码的真正含义。
锚定到网络层
如前面所说,我是选择用抓包分析这个方法来展开排查的。之所以采用这个方法,是因为我前面也说过,从软件文档已经无法查清楚问题根因了,所以需要下沉到网络层排查。如果你在处理应用层故障,比如HTTP异常返回码(4xx和5xx系列)场景中,也遇到了在应用层找不到答案的情况,你就可以考虑采用抓包分析的方法。
补充:下文中的“客户端”都指微信消息网关,“服务端”指这个客户在公有云的服务器。
这样,我在服务端使用tcpdump工具做了抓包,然后用Wireshark打开抓包文件展开分析。从抓包文件中,我一般会寻找一些比较可疑的报文。正好,这次抓包里有不少RST报文,于是我过滤出了一个典型的带RST报文的TCP流,请看下图:

补充:抓包示例文件已经上传至Gitee,建议用Wireshark打开文件,结合文稿一起学习。
相信你也一眼就看到了那个结尾处的RST。但问题是,这个TCP流一定跟499日志有关系吗?
得益于TCP/IP的精妙的分层设计,应用层只需要通过系统调用,就可以像使用文件IO那样使用网络IO,具体的网络细节都由内核处理了。可是由此也带来了一个问题:以应用层的视角,是无法“看到”具体的网络报文的。
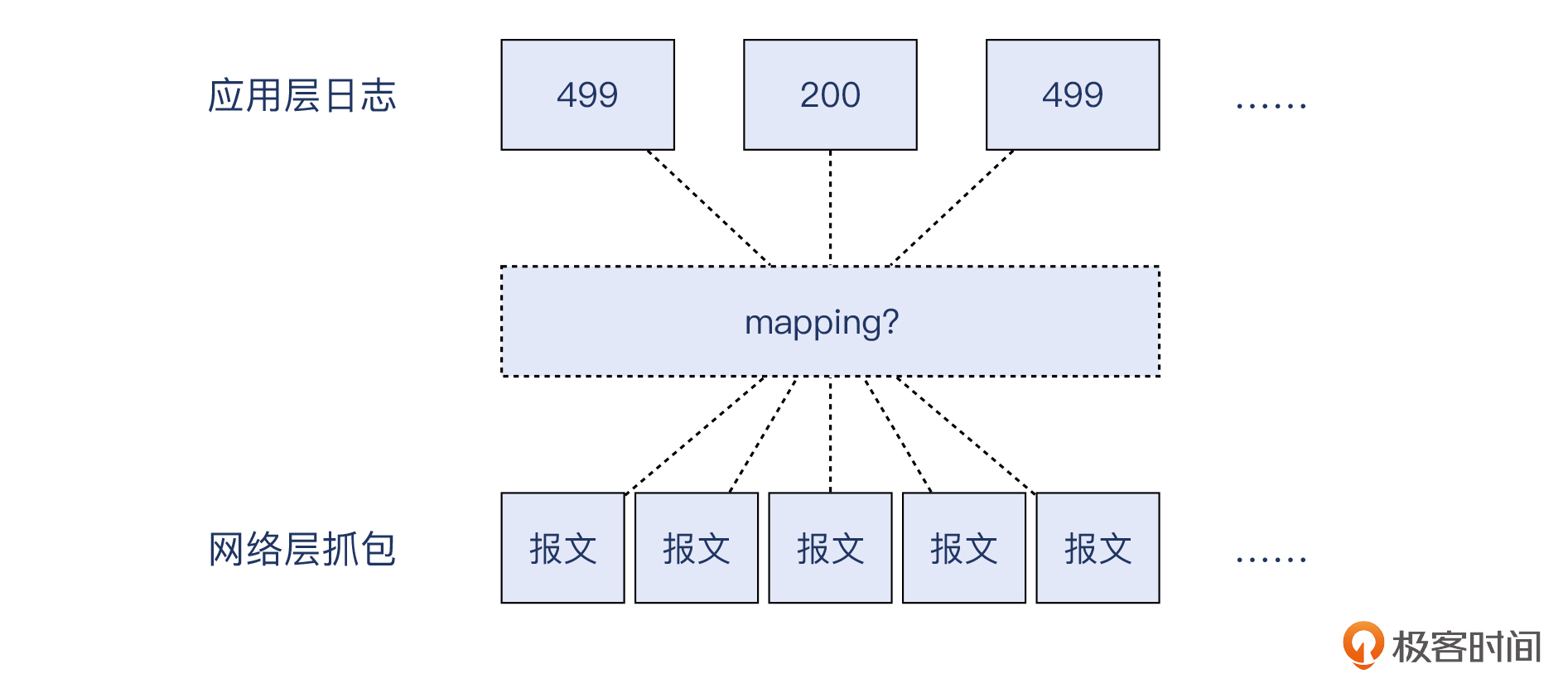
我们需要根据一些关键信息来确定应用层日志跟网络报文的对应关系。比如在这里,我可以确认上面这个带有RST的TCP流,就是日志中记录的一条499日志记录。这是如何做到的呢?
就是因为以下三点。
- 客户端IP:日志中的remote IP跟抓包文件里面的IP符合。
- 时间戳:日志的时间戳也跟这个TCP流的时间吻合。
- 应用层请求:日志里的HTTP URL路径和这个TCP流里的URL相同。
补充:如果你对第4讲有印象,应该记得当时也是用类似的方式找到了应用日志跟报文的对应关系。
实际上,在真实的抓包分析场景中,“如何把应用层问题跟网络层抓包关联起来”,始终是一个关键环节。同时,这也是比较令人困扰的关键技术障碍,很多人就是在这一关前败下阵来,导致没有办法真正彻底地查到根因。所以这里的方法可以作为给你的参考,当你以后再处理这种关键环节的时候,也可以根据上面提到的三个维度的信息,即IP、时间戳、应用层请求(包括URL和header),来达到“把应用层问题锚定到网络层数据包”的目的。
好,既然确定这个流就是代表了一次499事件,那么我们就需要好好分析一下这些报文里面的文章了。
TCP流的解读
这里,你可以先注意一下我在下图的这个TCP流示意图中,标记出的红框部分,在后续的分析过程中,我会重点分析这几个部分。
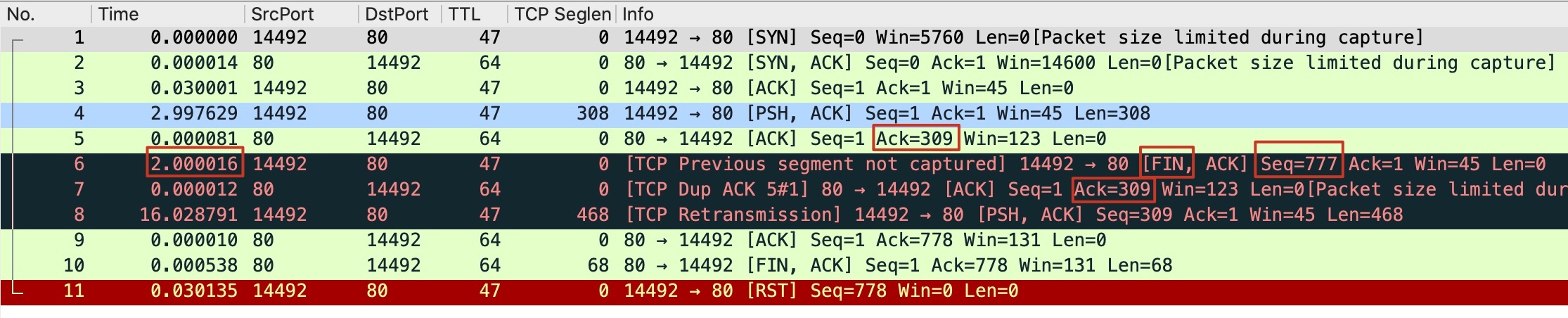
首先是报文1~3,表示TCP握手成功。
然后是报文4(客户端发出),表示客户端(消息网关)向服务器发送报文,这个报文里只包含HTTP header,其声明该请求为POST方法,但不含POST body。这其实是正常的,因为HTTP协议就是这样规定的,数据的先后顺序是:先header(包含method、URL、headers),后body。所以,既然方法(method)和URL单独位于一个报文里面了,那么按顺序来说,body就是在后续的报文里面。
接下来是报文5(服务端发出),它是一个确认报文。它的意思是:我(服务端)确认收到了你(客户端)发过来的报文4。
紧接着是报文6(客户端发出),此时距离上一个报文的时间是2秒。这个报文被Wireshark标记为了红色,注释为TCP Previous segment not captured,意思是它之前的TCP报文段没有被抓到。
什么叫做“之前的TCP报文”呢?其实就是按TCP序列号顺序,排在当前报文之前的报文。我对这个6号报文标注了3处红框,它们都有很重要的含义。这里我们先关注下右边一个红框圈出来的FIN标志位,这说明,这是一个客户端主动关闭连接的报文。
我们可以把到目前为止的报文情况,用下面这个示意图来表示:
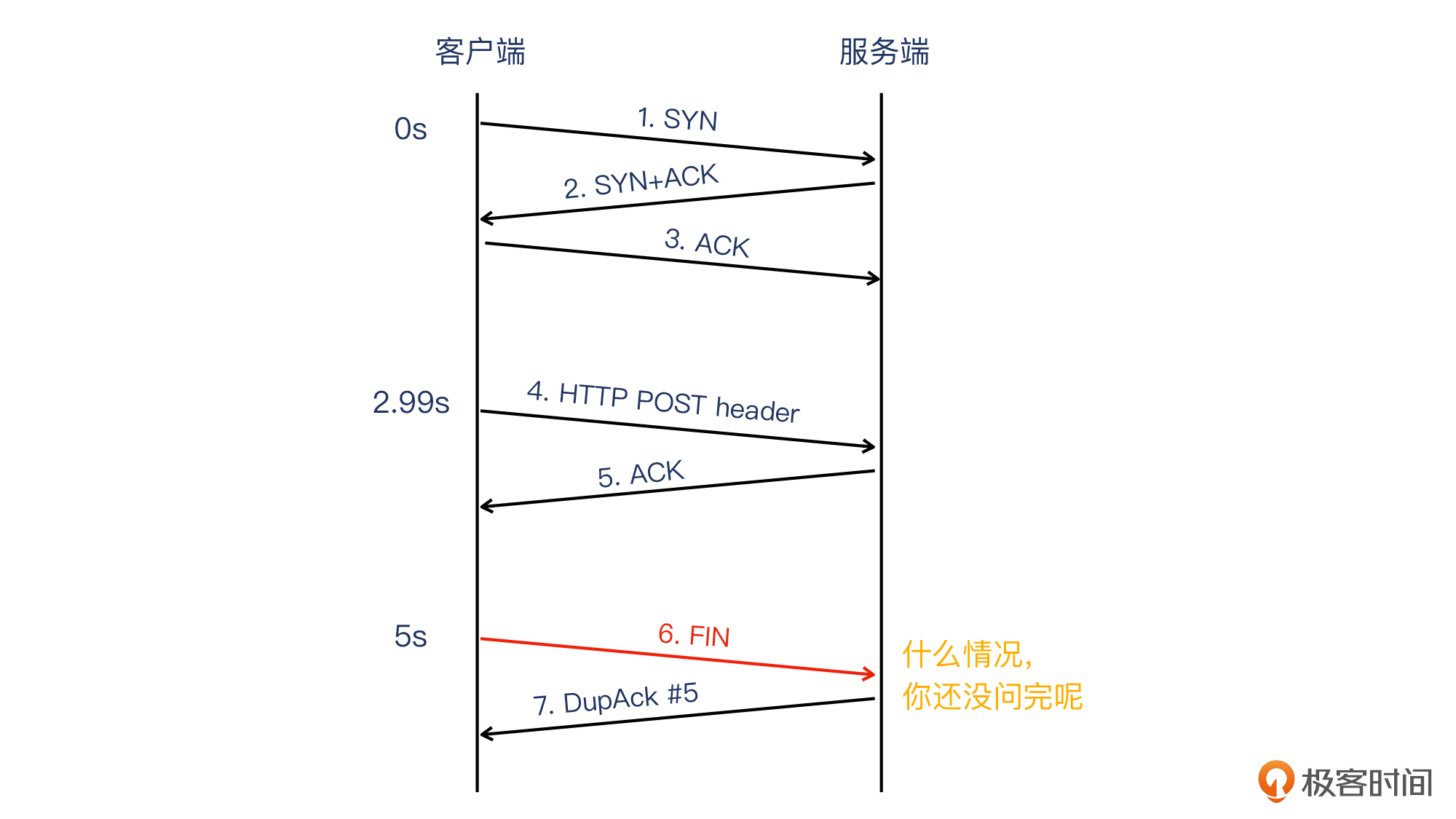
你看这里是不是很奇怪?明明HTTP POST请求的body(也称为HTTP载荷)部分还没发过来,这个客户端就嚷嚷着要关闭连接了?这就好比有个朋友跟你说:“我有个事情要你帮忙,嗯,拜拜~”,你刚听到上半句他的求助意向,还没听到这个忙具体是什么,他就跟你说再见了。惊不惊喜,意不意外?你可能暂时看不出这里究竟出了什么问题,不过没关系,先放一放。
我们继续看报文7(服务端发出)。服务器收到了FIN+ACK报文(6号报文),但发现序列号并不是它期待的309,而是777,于是服务器TCP协议栈判断:有一个长度为777-309=468的TCP段(TCP segment)丢失了。
按TCP的约定,这时候服务端只可以确认其收到的字节的最后位置,在这里,就是上一次(报文5)的ACK位置。形式上,报文7就成了一个DupAck(重复确认)。
当客户端收到DupAck的时候,它就需要长一个心眼了:“情况有点微妙,如果凑满3个DupAck可能有丢包啊”。
补充:如果凑满3个DupAck就重传的机制,被称为快速重传机制,我们在第12讲我们有深入学习过。
为了帮助理解,这里我再展示下报文4的TCP信息:
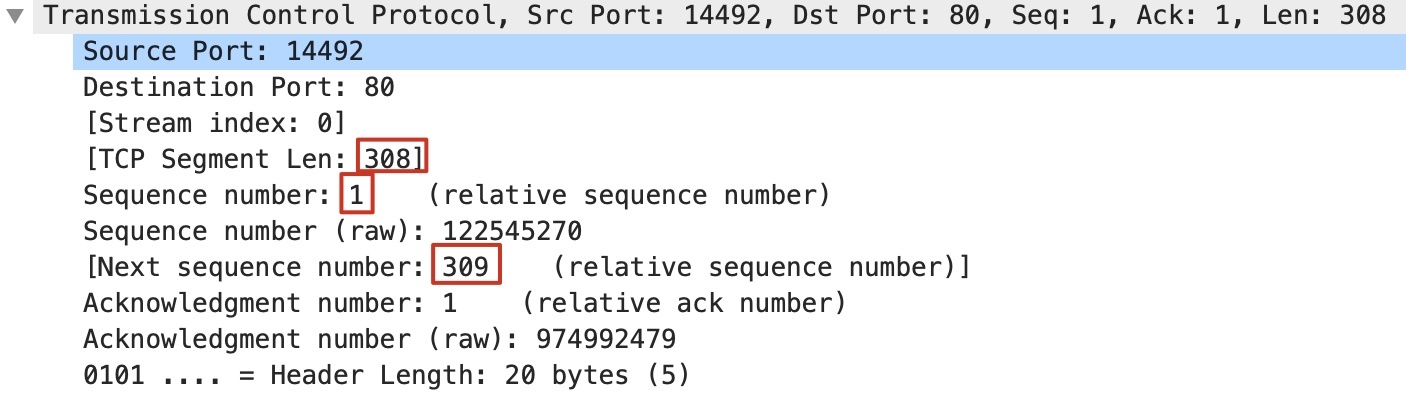
那么,按TCP的设计,客户端将要发送的下一个报文的序列号(309)= 本次序列号(1) + 本次数据长度(308),也就是图中的Next sequence number。
我们再来看报文8(客户端发出),过了16秒之久,客户端重传了这个报文,包含POST body的数据,长度为 468 字节。你看,这是不是就跟前面说的777-309=468对应起来了。
可能你在这里又有点困惑了,明明这个468字节的报文是第一次出现,怎么就算重传了呢?
其实是因为,这个抓包文件是在服务端生成的,所以它的视角,是无法看到多次传送同样这个报文的现象的。但我判断,在客户端抓包的话,一定可以看到这个468字节的报文被试图传送了多次。
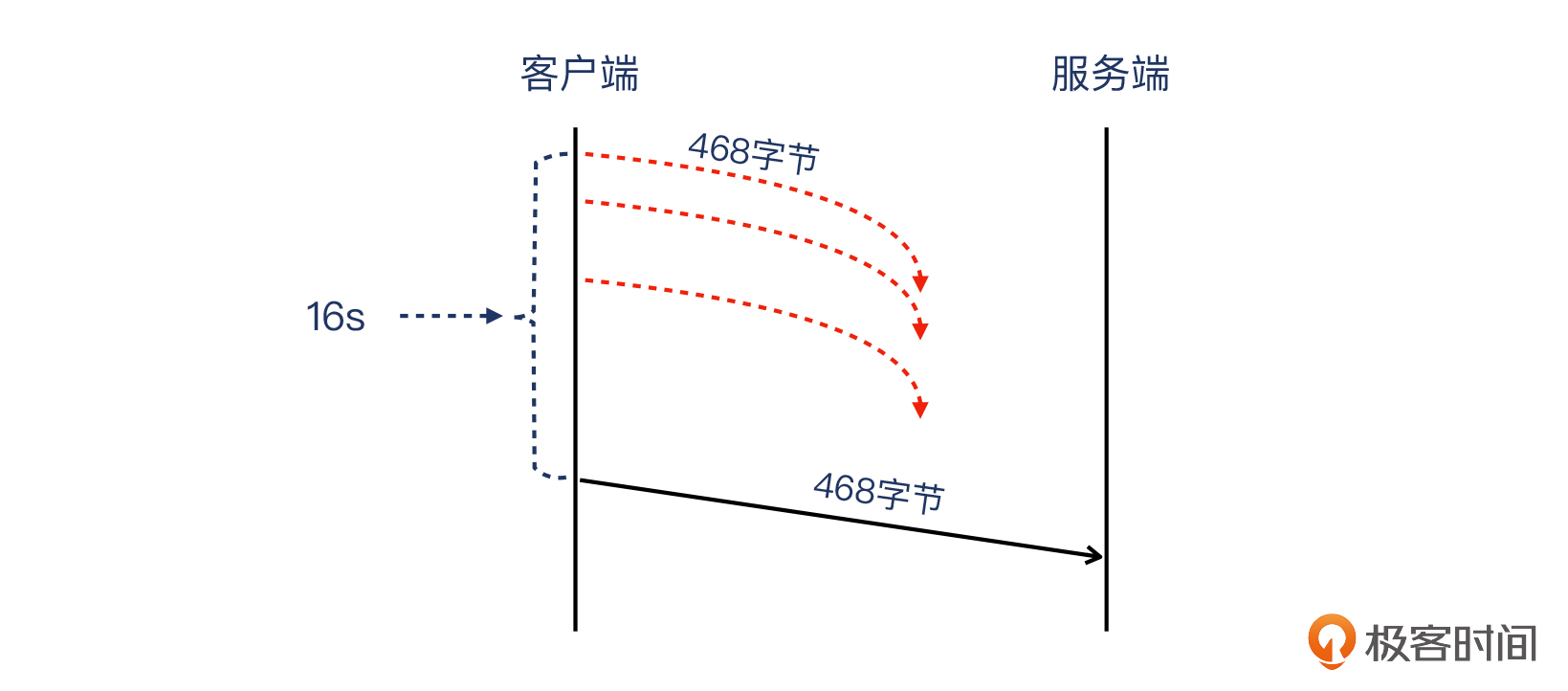
我们就以服务端视角来判断,一开始这个报文应该是走丢了,没有达到服务端,所以没有在这个服务端抓包文件里现身。又因为过了16秒之久才到达,很可能不是单纯一次重传,而是多次重传后才最终到达的。因此从这一点上讲,确实属于重传。
我们继续分析。接下来就是报文9,服务端对这个POST body的数据包回复了确认报文。
最后是报文10,服务端发送了HTTP 400的响应报文给消息网关。这个信息并没有被Wireshark直接按HTTP格式进行展示,但是因为HTTP是文本编码的,所以我们可以鼠标选中Transmission Control Protcol部分,在底下的文本栏直接看到HTTP 400这段文本:
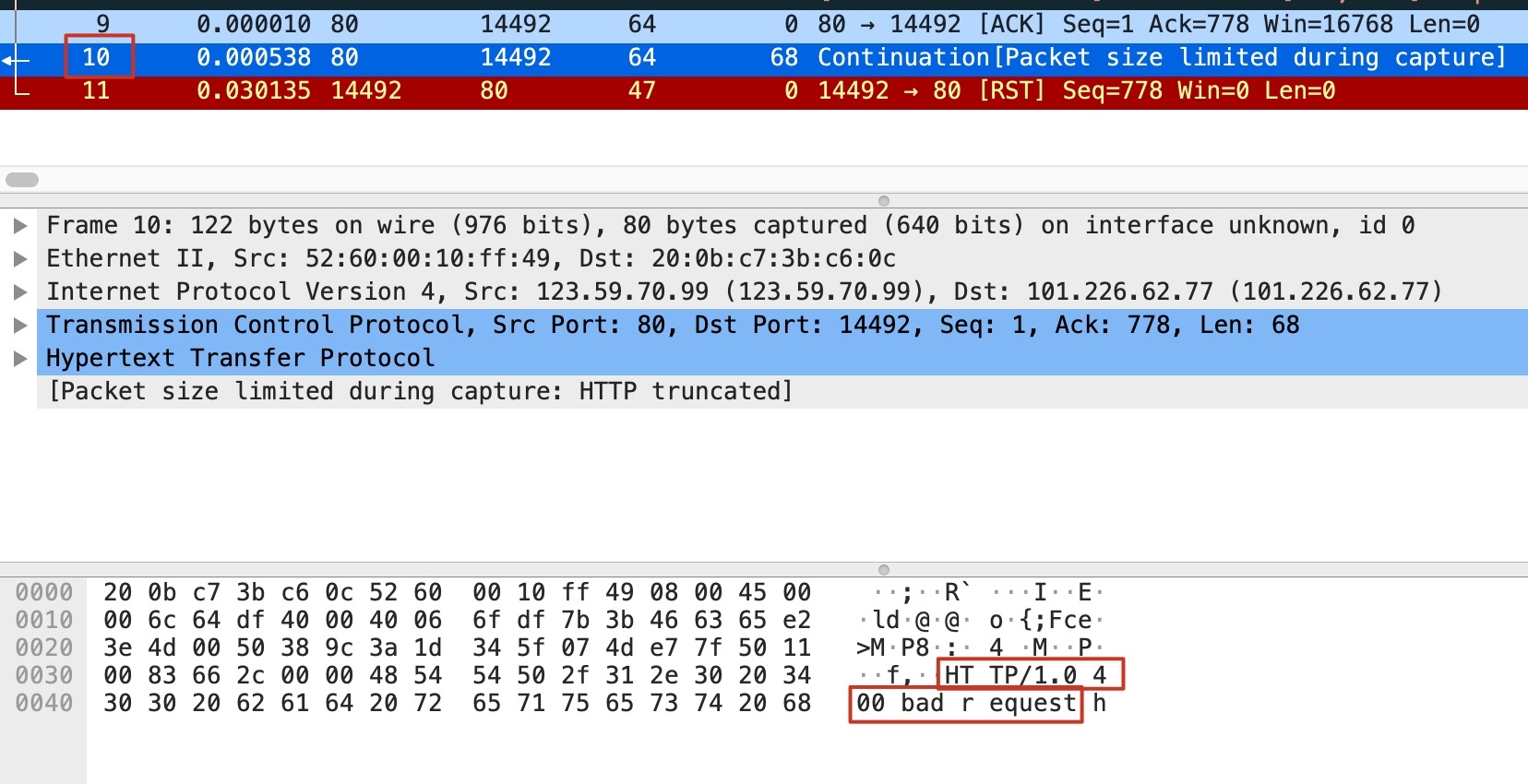
有趣的是,这个 HTTP 400报文也是带FIN标志位的,也就是服务端操作系统“图省事”了,把应用层的应答数据(HTTP 400),跟操作系统对TCP连接关闭的控制报文(这个FIN),合并在同一个报文里面了。也就是我们在第3讲提到的搭顺风车(Piggybacking),提升了网络利用效率。
这个阶段的报文图示如下:
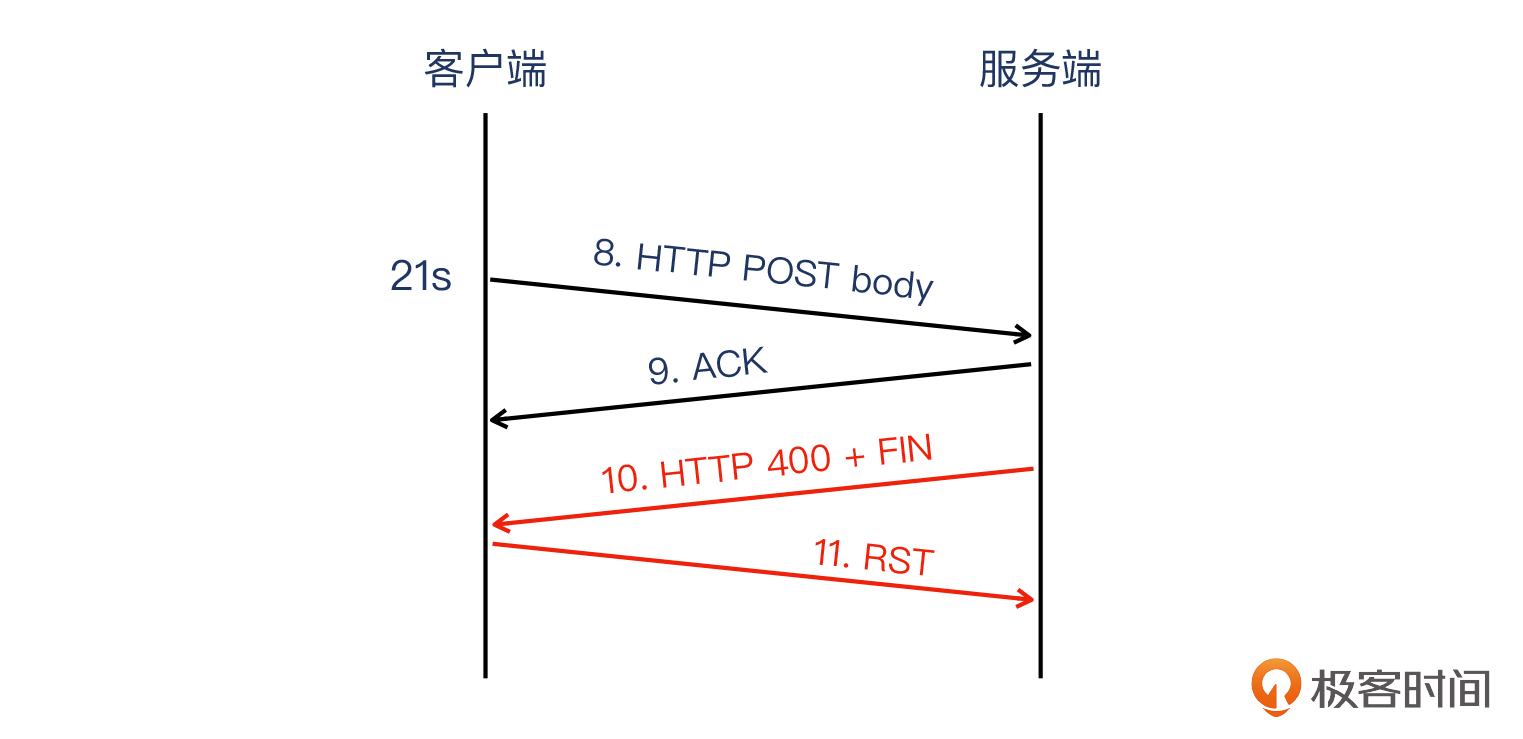
那么,从这些报文的顺序来看,我们会发现它确实是有问题的。特别是有以下几个疑点:
- 服务端先收到了HTTP header报文,随后并没有收到期望的HTTP body报文,而是收到了FIN报文,即客户端试图关闭连接。这个行为十分古怪,要知道HTTP请求还没发送到服务端,服务端回复HTTP响应更是无从谈起,这个时候客户端发送FIN就不符合常理了(即前面说的朋友求帮忙的类比)。
- 服务端回复了HTTP 400,并且也发送FIN关闭了这个连接。
- 客户端回复RST彻底关闭这个连接。
而把上面这几条信息综合起来看,你有没有发现一个重要的线索?**客户端先发送了FIN,之后才发送POST body。**现在让我们把全部过程拼接起来,看一下全景图:
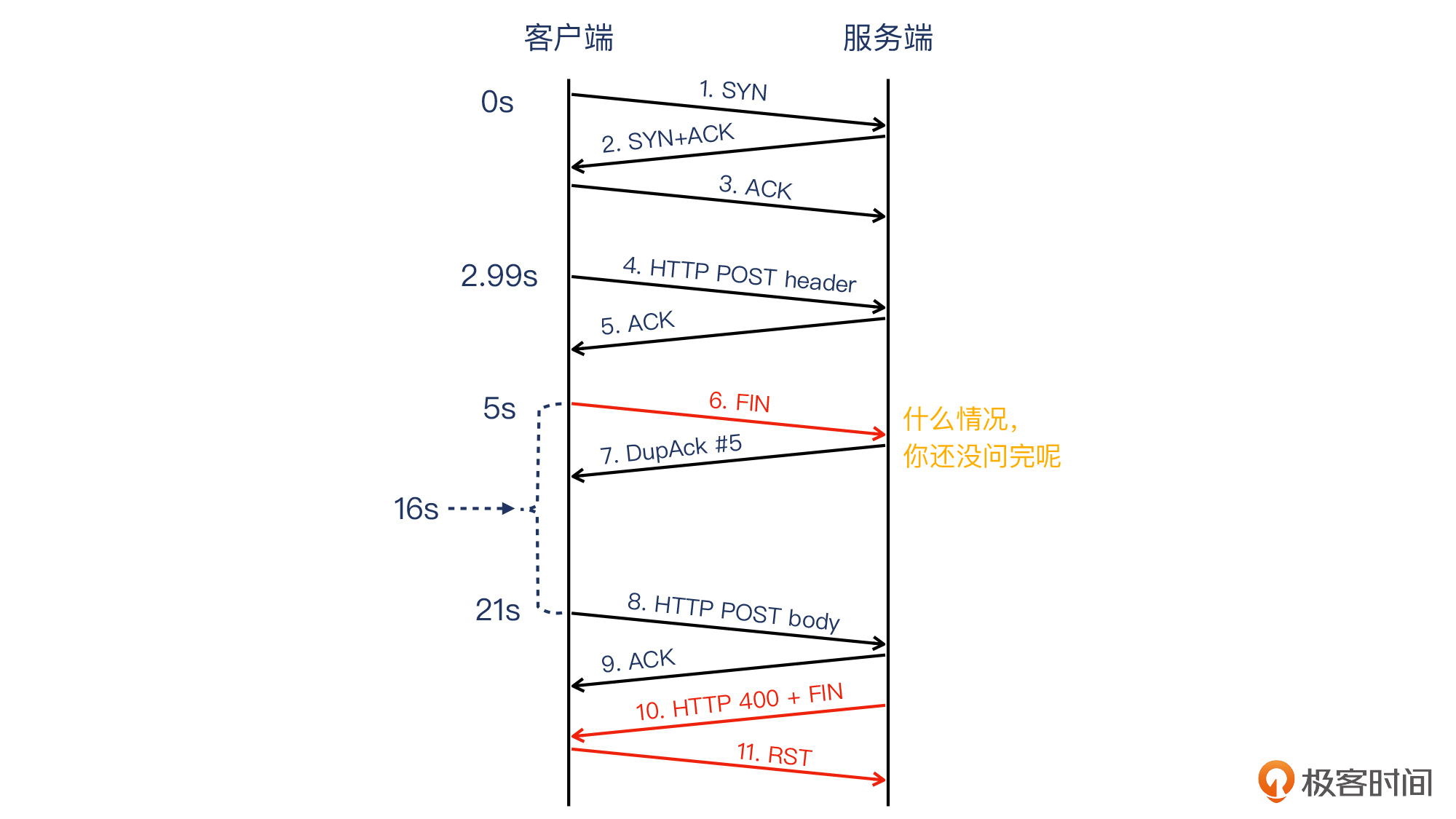
这么古怪的行为,可以描述为“服务端还没回复数据而客户端已经要关闭连接”。按照499的官方定义,这种行为就被Nginx判定为了499状态。对内表现为记录499日志,对外表现为回复HTTP 400给消息网关。
所以,在服务端的Nginx日志中,就留下了大量的499日志条目;而在消息网关那头,如果它也做Web日志的话,相信就不是499日志,而是400的报错了。
那么到这里,问题是水落石出了吗?其实不是。
从现象到本质
我们还需要搞清楚最底层的疑问:为什么客户端先发送FIN,然后才发送POST body?
我们回到Wireshark窗口,再次关注下6号报文:

它离上一个报文相差了2秒,而我们知道这个信息,是因为Wireshark很友好地显示了报文之间的间隔时长。
我们再往前看4号报文:

离3号报文相差了2.997秒,几乎就是3秒整了。那么加起来,6号报文离TCP握手完成,正好隔了 5秒整。
一般出现这种整数,就越发可疑了,因为如果是系统或者网络的错乱导致的行为,其时间分布上应该是随机的,不可能卡在整数时间上。就我的经验来看,这往往跟某种人为的设置有关系。
所以,经过我的提醒,客户自己仔细查看了微信网关的使用文档,果然发现了它确实有5秒超时的设置。也就是说,如果一个HTTP事务(在这个例子里是HTTP POST事务)无法在5秒内完成,就关闭这个连接。
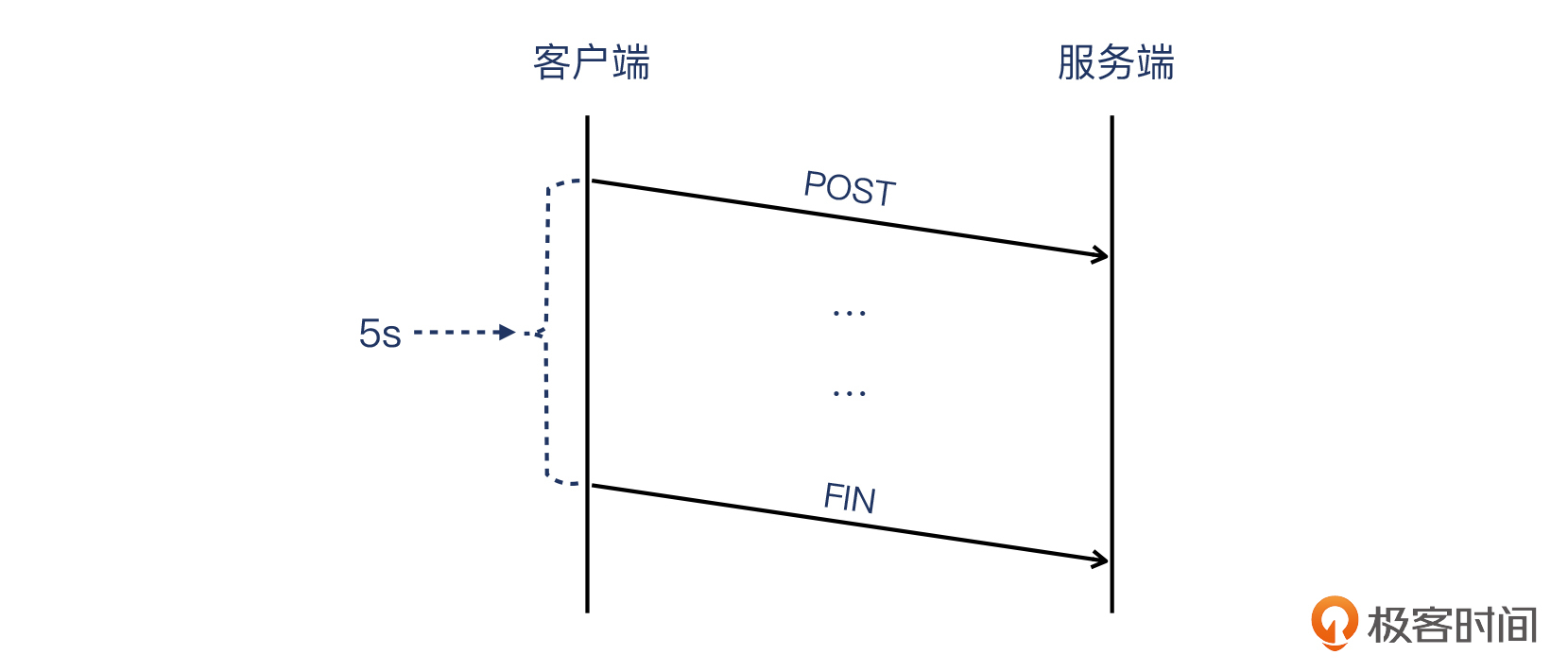
这个“无法完成”,在这个抓包里面体现为:HTTP header报文发过去了,但HTTP body报文没有一起过去(网络原因导致)。而由于初始阶段报文少,无法凑齐3个DupAck,所以快速重传没有被启动,只好依赖超时重传(关于超时重传的知识在第12讲也有详细的介绍),而且这多次超时重传也失败了,服务端只好持续等待这个丢失的报文。5秒钟过后,客户端(微信消息网关)没有收到服务端的响应,就主动关闭了这次连接(可以下次再试,这次就不继续干等了)。
也就是说,这个场景里的Nginx 499错误日志的产生,主要是由于两个因素造成的:
- “消息网关—>服务器”方向上的一个TCP包丢失(案例里是HTTP POST body报文),引起服务端空闲等待;
- 消息网关有一个5秒超时的设置,即连接达到5秒时,消息网关就发送FIN关闭连接。
所以到这里,想必你也明白了这里的逻辑链条,也就是:
- 要解决499报错的问题,就需要解决5秒超时的问题;
- 要解决5秒超时的问题,就需要解决丢包问题;
- 要解决丢包的问题,就需要改善网络链路质量。
最根本的解决方案,就是如何确保客户端到服务端的网络连接可靠稳定,使得类似的报文延迟的现象降到最低。只要不丢包不延迟,HTTP事务就能在5秒内完成,消息网关就不会启动5秒超时断开连接的机制。
这样,我们跟客户还有网关的工程师一起配合,确实发现网关到我们公有云的一条链路有问题。更换为另外一条链路后,丢包率大幅降低,问题得到了极大改善。虽然还是有极小比例的错误日志(大约万分之一),但是这对于客户来说,完全在可接受范围之内了。
另外,因为丢包的存在,客户端的FIN报文跟HTTP POST body报文一样,也可能会丢失。不过,无论这个FIN是否被服务端及时收到,这次HTTP事务本身也已经在客户端被记为失败了,也就是不改变这件事的结果。
你可能会问了:链路丢包这种问题应该挺明显的,为什么没有在第一时间发现呢?
这其实是多种因素导致的:
- 我们虽然对主要链路的整体状况有细致的监控,但这里的网关到客户的公有云服务属于“点到点”的链接,本身也属于客户自身的业务,公有云难以对这种情况做监控,理想情况是客户自己来实现监控。
- 客户的消息量很大,哪怕整体失败比例不高,但乘以绝对的消息量,产生的错误的绝对数也就比较可观了。
至于Nginx为什么要“创造”499这个独有的状态码的原因,其实在 Nginx源码的注释部分里,已经写得非常清楚了。它并非标新立异,而确实是为了弥补标准HTTP协议的不足。相关代码如下:
/*
* HTTP does not define the code for the case when a client closed
* the connection while we are processing its request so we introduce
* own code to log such situation when a client has closed the connection
* before we even try to send the HTTP header to it
*/
#define NGX_HTTP_CLIENT_CLOSED_REQUEST 499
翻译过来就是:HTTP并没有对服务端还在处理请求的时候客户端就关闭连接的情况,做一个状态码的定义。所以我们定义了自己的状态码(499),以记录这种“还没来得及发送返回,客户端就关闭了连接”的情形。
小结
现在,我们就清楚在这个例子里,造成499状态码的根因了。不过基于普适性的应用需求,我想把这个案例再延伸拓展一下,希望可以帮助你了解到更多的知识,并且在理解了这些知识点之后,你能够有效应用在类似的HTTP异常码的故障排查里。
首先,我们要知道,Nginx 499是Nginx自身定义的状态码,并非任何RFC中定义的HTTP状态码。它表示的是“Nginx收到完整的HTTP request前(或者已经接收到完整的request但还没来得及发送HTTP response前),客户端试图关闭TCP连接”这种反常情况。
第二,超时时间跟499报错数量也有直接关系。如果我们有办法延长消息网关的超时时间,比如从5秒改为50秒,那么客户端就有比较充足的时间去等待丢失的报文被成功重传,从而在50秒内完成HTTP事务,499日志也会少很多。
第三,我们要关注网络延迟对通信的影响。比如客户端发出的两个报文(报文3和报文4)间隔了3秒钟,这在网络通信中是个非常大的延迟。而造成这么大延迟的原因,会有两种可能:一是消息网关端本身是在握手后隔了3秒才发送了这个报文,属于应用层问题;二是消息网关在握手后立刻发送了这个报文,但在公网上丢失了,微信消息网关就根据“超时重传”的机制重新发了这个报文,并于3秒后到达。这属于网络链路问题。
由于上面的抓包是在服务端做的,所以未到达服务器的包自然也不可能抓到,也就是无法确定是具体哪一种原因(客户端应用层问题或网络链路问题)导致,但这并不影响结论。
最后一点,就是我们要清楚,公网上丢包现象不可能完全消失。千分之一左右的公网丢包率属于正常范围。由于客户发送量比较大(这是主要原因),加上微信消息网关设置的5秒超时相对比较短(这是次要原因),这两个因素一结合,问题就会在这个案例中被集中暴露出来。
那么,像上面第二点说的那样,设置更长的超时阈值(比如50秒)能解决问题吗?相信出错率会降低不少,但是这样新的问题也来了:
- 消息网关会有更多的资源消耗(内存、TCP源端口、计算能力等);
- 消息网关处理事务的平均耗时会增加。
所以,选择5秒应该是一个做过权衡后的适中的方案。
而从排查的方法论上来说,对于更广泛的应用层报错日志的排查,我的推荐是这样的:
- 首先查看应用文档,初步确定问题性质,大体确定排查方向。
- **通过对比应用日志和抓取的报文,在传输层和网络层寻找可疑报文。**在这一步,可以采用以下的比对策略来找到可疑报文:
- 日志中的IP跟报文中的IP对应;
- 日志和报文的时间戳对应;
- 应用层请求信息和报文信息对应。
- 结合协议规范和报文现象,推导出根因。
思考题
给你留两个思考题,欢迎在留言区分享你的答案和思考,我们一起交流讨论。
- 第7个报文是DupAck,为什么没有触发快速重传呢?
- 消息网关那头的应用日志应该不是499,那会是什么样的日志呢?
欢迎你把今天的内容分享给更多的朋友,我们一起成长。