14 KiB
06 | 数据库检索:如何使用B+树对海量磁盘数据建立索引?
你好,我是陈东。
在基础篇中,我们学习了许多和检索相关的数据结构和技术。但是在大规模的数据环境下,这些技术的应用往往会遇到一些问题,比如说,无法将数据全部加载进内存。再比如说,无法支持索引的高效实时更新。而且,对于复杂的系统和业务场景,我们往往需要对基础的检索技术进行组合和升级。这就需要我们对实际的业务问题和解决方案十分了解。
所以,从这一讲开始,我会和你一起探讨实际工作中的系统和业务问题,分享给你一些工业界中常见的解决方案,帮助你积累对应的行业经验,让你能够解决工作中的检索难题。
在工业界中,我们经常会遇到的一个问题,许多系统要处理的数据量非常庞大,数据无法全部存储在内存中,需要借助磁盘完成存储和检索。我们熟悉的关系型数据库,比如MySQL和Oracle,就是这样的典型系统。
数据库中支持多种索引方式,比如,哈希索引、全文索引和B+树索引,其中B+树索引是使用最频繁的类型。因此,今天我们就一起来聊一聊磁盘上的数据检索有什么特点,以及为什么B+树能对磁盘上的大规模数据进行高效索引。
磁盘和内存中数据的读写效率有什么不同?
首先,我们来探讨一下,存储在内存中和磁盘中的数据,在检索效率方面有什么不同。
内存是半导体元件。对于内存而言,只要给出了内存地址,我们就可以直接访问该地址取出数据。这个过程具有高效的随机访问特性,因此内存也叫随机访问存储器(Random Access Memory,即RAM)。内存的访问速度很快,但是价格相对较昂贵,因此一般的计算机内存空间都相对较小。
而磁盘是机械器件。磁盘访问数据时,需要等磁盘盘片旋转到磁头下,才能读取相应的数据。尽管磁盘的旋转速度很快,但是和内存的随机访问相比,性能差距非常大。到底有多大呢?一般来说,如果是随机读写,会有10万到100万倍左右的差距。但如果是顺序访问大批量数据的话,磁盘的性能和内存就是一个数量级的。为什么会这样呢?这和磁盘的读写原理有关。那具体是怎么回事呢?
磁盘的最小读写单位是扇区,较早期的磁盘一个扇区是512字节。随着磁盘技术的发展,目前常见的磁盘扇区是4K个字节。操作系统一次会读写多个扇区,所以操作系统的最小读写单位是块(Block),也叫作簇(Cluster)。当我们要从磁盘中读取一个数据时,操作系统会一次性将整个块都读出来。因此,对于大批量的顺序读写来说,磁盘的效率会比随机读写高许多。
现在你已经了解磁盘的特点了,那我们就可以来看一下,如果使用之前学过的检索技术来检索磁盘中的数据,检索效率会是怎样的呢?
假设有一个有序数组存储在硬盘中,如果它足够大,那么它会存储在多个块中。当我们要对这个数组使用二分查找时,需要先找到中间元素所在的块,将这个块从磁盘中读到内存里,然后在内存中进行二分查找。如果下一步要读的元素在其他块中,则需要再将相应块从磁盘中读入内存。直到查询结束,这个过程可能会多次访问磁盘。我们可以看到,这样的检索性能非常低。
由于磁盘相对于内存而言访问速度实在太慢,因此,对于磁盘上数据的高效检索,我们有一个极其重要的原则:对磁盘的访问次数要尽可能的少!
那问题来了,我们应该如何减少磁盘的访问次数呢?将索引和数据分离就是一种常见的设计思路。
如何将索引和数据分离?
我们以查询用户信息为例。我们知道,一个系统中的用户信息非常多,除了有唯一标识的ID以外,还有名字、邮箱、手机、兴趣爱好以及文章列表等各种信息。一个保存了所有用户信息的数组往往非常大,无法全部放在内存中,因此我们会将它存储在磁盘中。
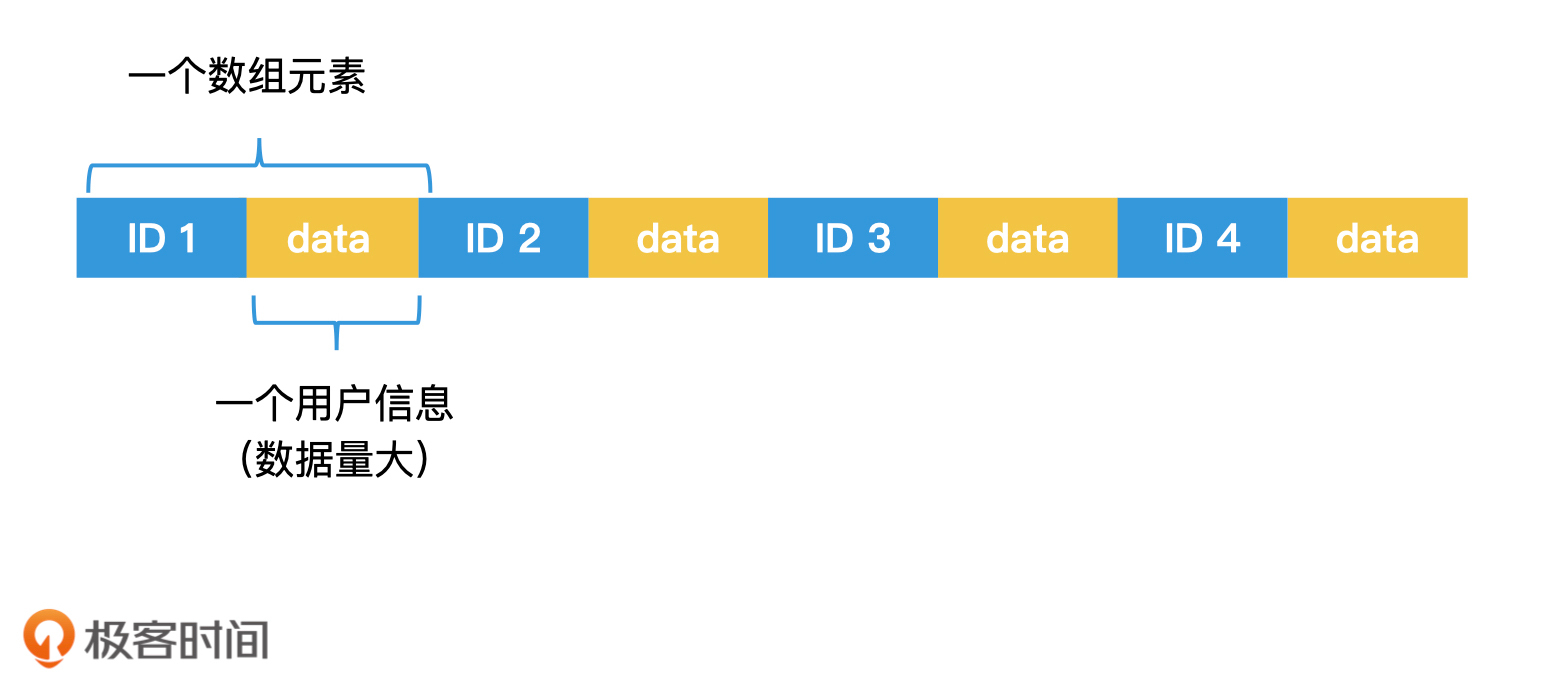
常规数组存储
当我们以用户的ID进行检索时,这个检索过程其实并不需要读取存储用户的具体信息。因此,我们可以生成一个只用于检索的有序索引数组。数组中的每个元素存两个值,一个是用户ID,另一个是这个用户信息在磁盘上的位置,那么这个数组的空间就会很小,也就可以放入内存中了。这种用有序数组做索引的方法,叫作线性索引(Linear Index)。
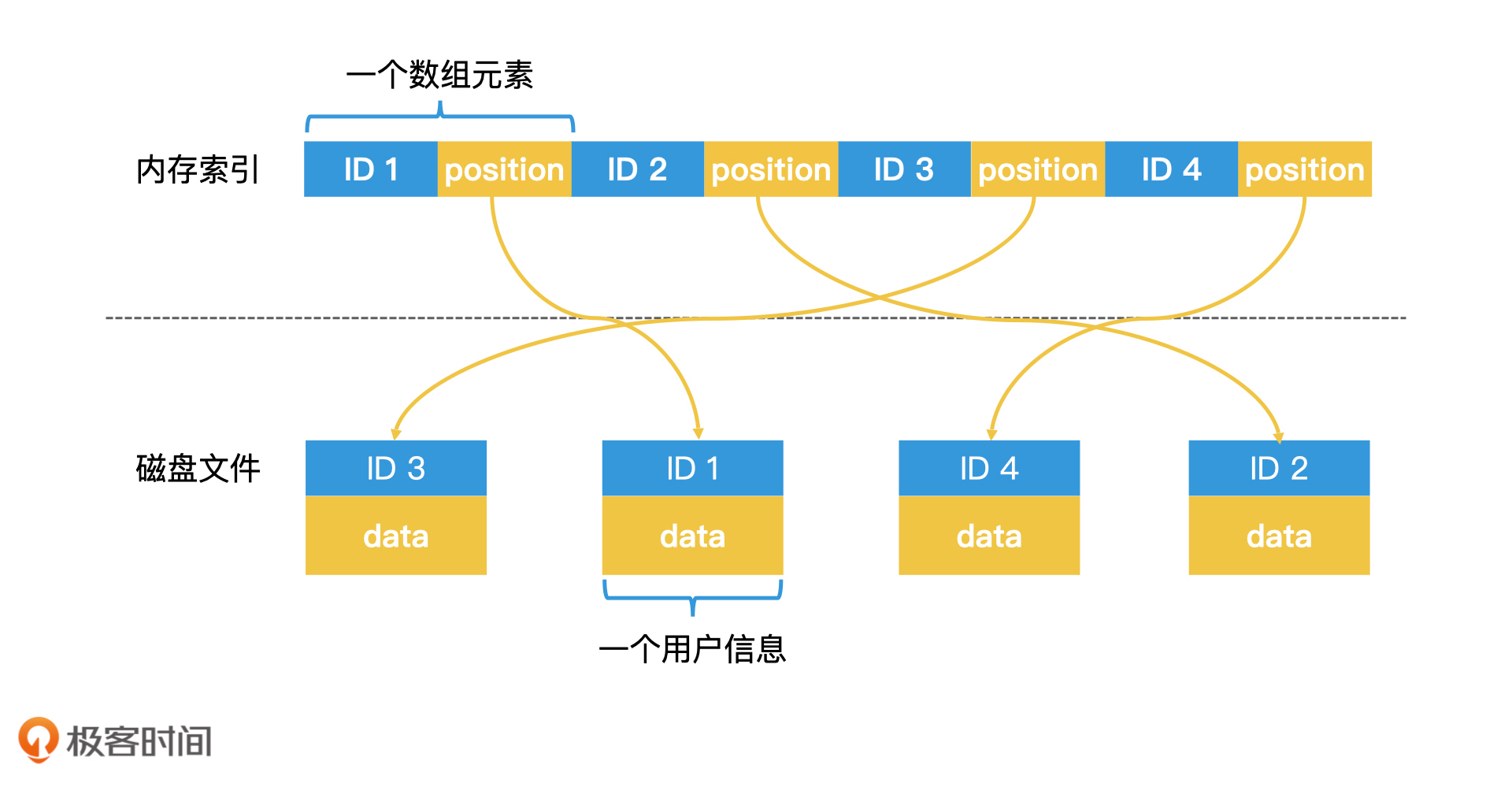
索引与数据分离:线性索引
在数据频繁变化的场景中,有序数组并不是一个最好的选择,二叉检索树或者哈希表往往更有普适性。但是,哈希表由于缺乏范围检索的能力,在一些场合也不适用。因此,二叉检索树这种树形结构是许多常见检索系统的实施方案。那么,上图中的线性索引结构,就变成下图这个样子。
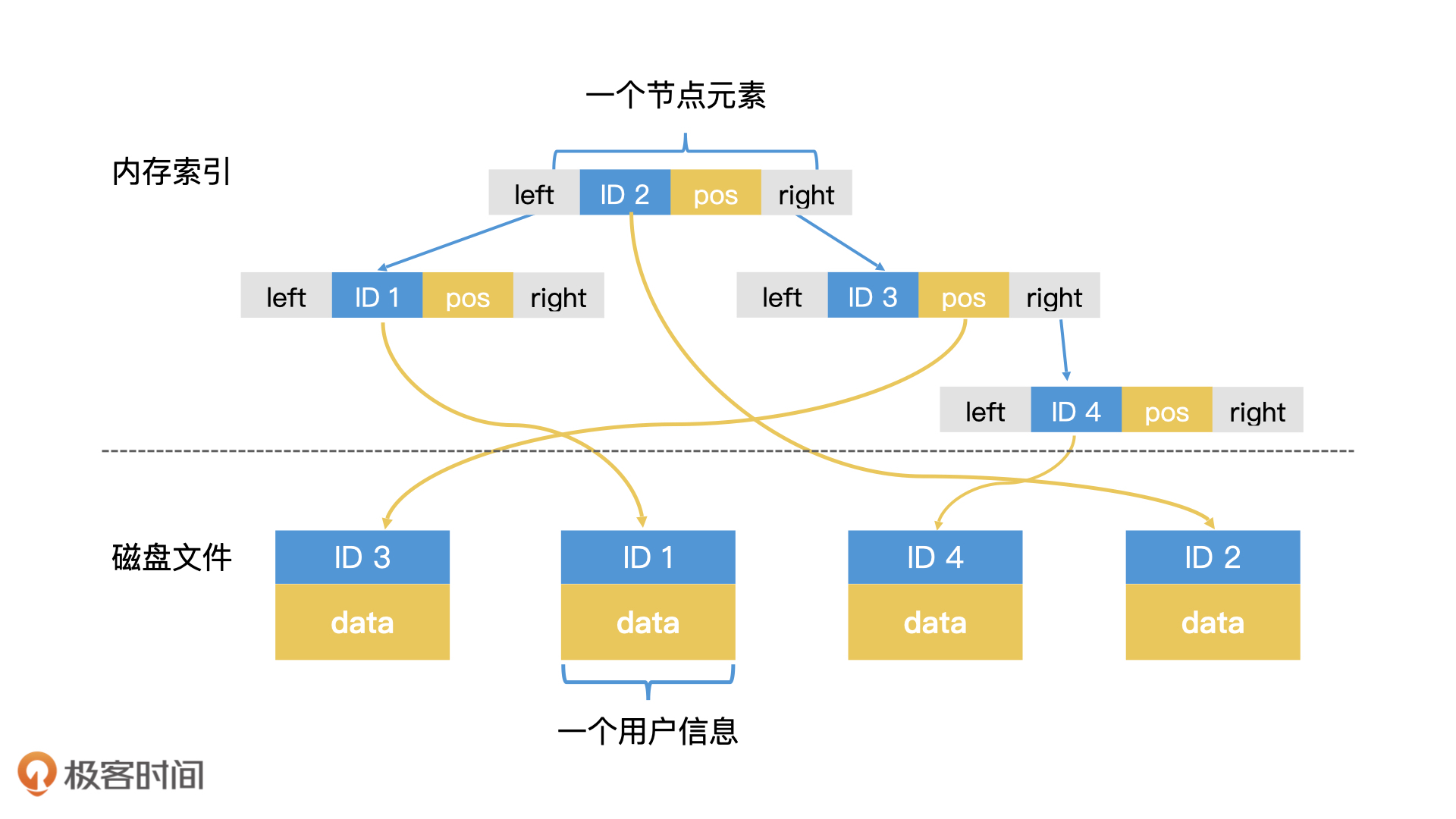
索引与数据分离:树形索引
尽管二叉检索树可以解决数据动态修改的问题,但在索引数据很大的情况下,依然会有数据无法完全加载到内存中。这种情况我们应该怎么办呢?
一个很自然的思路,就是将索引数据也存在磁盘中。那如果是树形索引,我们应该将哪些节点存入磁盘,又要如何从磁盘中读出这些数据进行检索呢?你可以先想一想,然后我们一起来看看业界常用的解决方案B+树是怎么做的。
如何理解B+树的数据结构?
B+树是检索技术中非常重要的一个部分。这是为什么呢?因为B+树给出了将树形索引的所有节点都存在磁盘上的高效检索方案,使得索引技术摆脱了内存空间的限制,得到了广泛的应用。
前面我们讲了,操作系统对磁盘数据的访问是以块为单位的。因此,如果我们想将树型索引的一个节点从磁盘中读出,即使该节点的数据量很小(比如说只有几个字节),但磁盘依然会将整个块的数据全部读出来,而不是只读这一小部分数据,这会让有效读取效率很低。B+树的一个关键设计,就是让一个节点的大小等于一个块的大小。节点内存储的数据,不是一个元素,而是一个可以装m个元素的有序数组。这样一来,我们就可以将磁盘一次读取的数据全部利用起来,使得读取效率最大化。
B+树还有另一个设计,就是将所有的节点分为内部节点和叶子节点。尽管内部节点和叶子节点的数据结构是一样的,但存储的内容是不同的。
内部节点仅存储key和维持树形结构的指针,并不存储key对应的数据(无论是具体数据还是文件位置信息)。这样内部节点就能存储更多的索引数据,我们也就可以使用最少的内部节点,将所有数据组织起来了。而叶子节点仅存储key和对应数据,不存储维持树形结构的指针。通过这样的设计,B+树就能做到节点的空间利用率最大化。
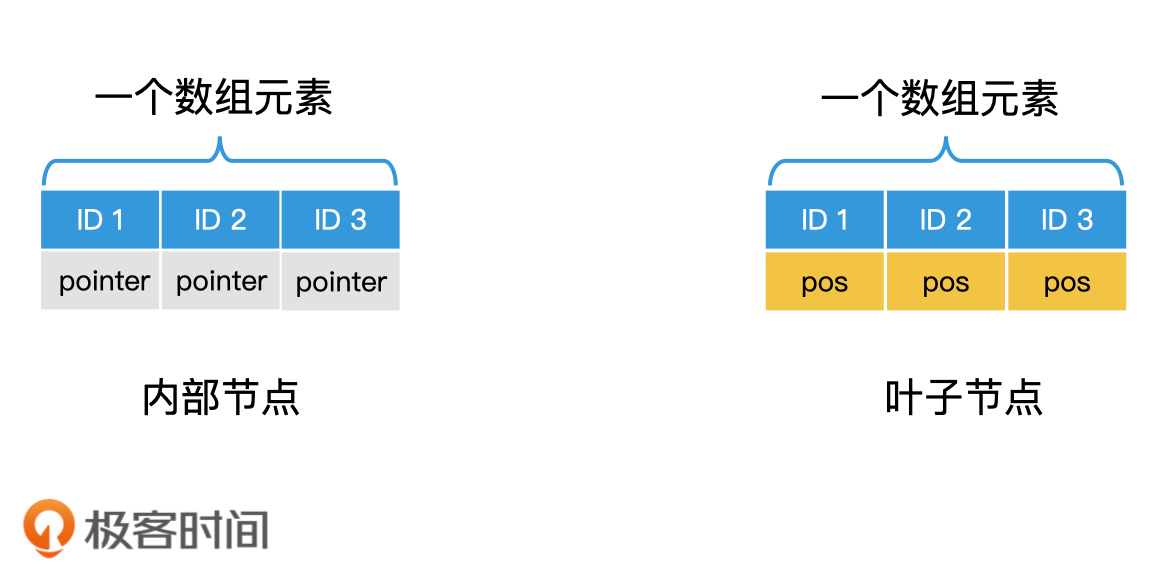
B+树的内部节点和叶子节点
此外,B+树还将同一层的所有节点串成了有序的双向链表,这样一来,B+树就同时具备了良好的范围查询能力和灵活调整的能力了。
因此,B+树是一棵完全平衡的m阶多叉树。所谓的m阶,指的是每个节点最多有m个子节点,并且每个节点里都存了一个紧凑的可包含m个元素的数组。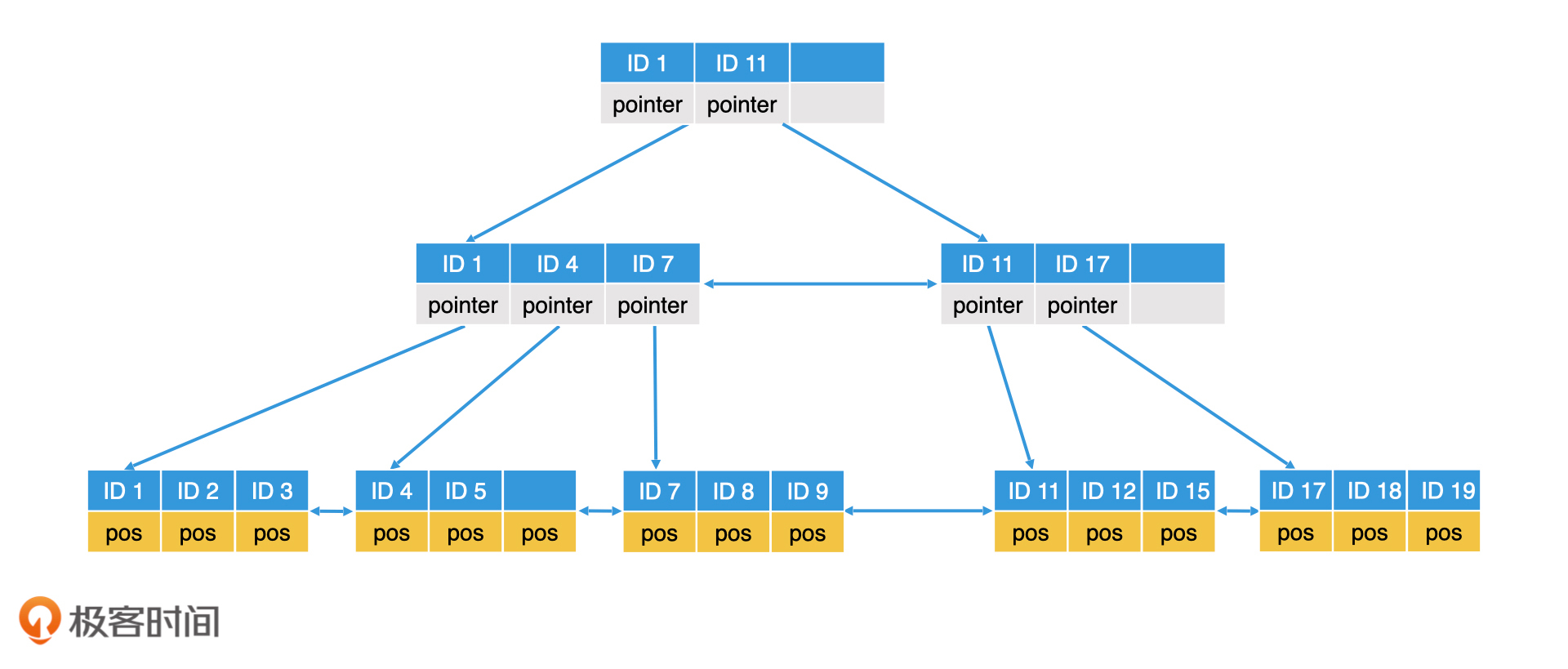
B+树的整体结构
B+树是如何检索的?
这样的结构,使得B+树可以作为一个完整的文件全部存储在磁盘中。当从根节点开始查询时,通过一次磁盘访问,我们就能将文件中的根节点这个数据块读出,然后在根节点的有序数组中进行二分查找。
具体的查找过程是这样的:我们先确认要寻找的查询值,位于数组中哪两个相邻元素中间,然后我们将第一个元素对应的指针读出,获得下一个block的位置。读出下一个block的节点数据后,我们再对它进行同样处理。这样,B+树会逐层访问内部节点,直到读出叶子节点。对于叶子节点中的数组,直接使用二分查找算法,我们就可以判断查找的元素是否存在。如果存在,我们就可以得到该查询值对应的存储数据。如果这个数据是详细信息的位置指针,那我们还需要再访问磁盘一次,将详细信息读出。
我们前面说了,B+树是一棵完全平衡的m阶多叉树。所以,B+树的一个节点就能存储一个包含m个元素的数组,这样的话,一个只有2到4层的B+树,就能索引数量级非常大的数据了,因此B+树的层数往往很矮。比如说,一个4K的节点的内部可以存储400个元素,那么一个4层的B+树最多能存储400^4,也就是256亿个元素。
不过,因为B+树只有4层,这就意味着我们最多只需要读取4次磁盘就能到达叶子节点。并且,我们还可以通过将上面几层的内部节点全部读入内存的方式,来降低磁盘读取的次数。
比如说,对于一个4层的B+树,每个节点大小为4K,那么第一层根节点就是4K,第二层最多有400个节点,一共就是1.6M;第三层最多有400^2,也就是160000个节点,一共就是640M。对于现在常见的计算机来说,前三层的内部节点其实都可以存储在内存中,只有第四层的叶子节点才需要存储在磁盘中。这样一来,我们就只需要读取一次磁盘即可。这也是为什么,B+树要将内部节点和叶子节点区分开的原因。通过这种只让内部节点存储索引数据的设计,我们就能更容易地把内部节点全部加载到内存中了。
B+树是如何动态调整的?
现在,你已经知道B+树的结构和原理了。那B+树在“新增节点”和“删除节点”这样的动态变化场景中,又是怎么操作的呢?接下来,让我们一起来看一下。
首先,我们来看插入数据。由于具体的数据都是存储在叶子节点上的,因此,数据的插入也是从叶子节点开始的。以一个节点有3个元素的B+树为例,如果我们要插入一个ID=6的节点,首先要查询到对应的叶子节点。如果叶子节点的数组未满,那么直接将该元素插入数组即可。具体过程如下图所示:
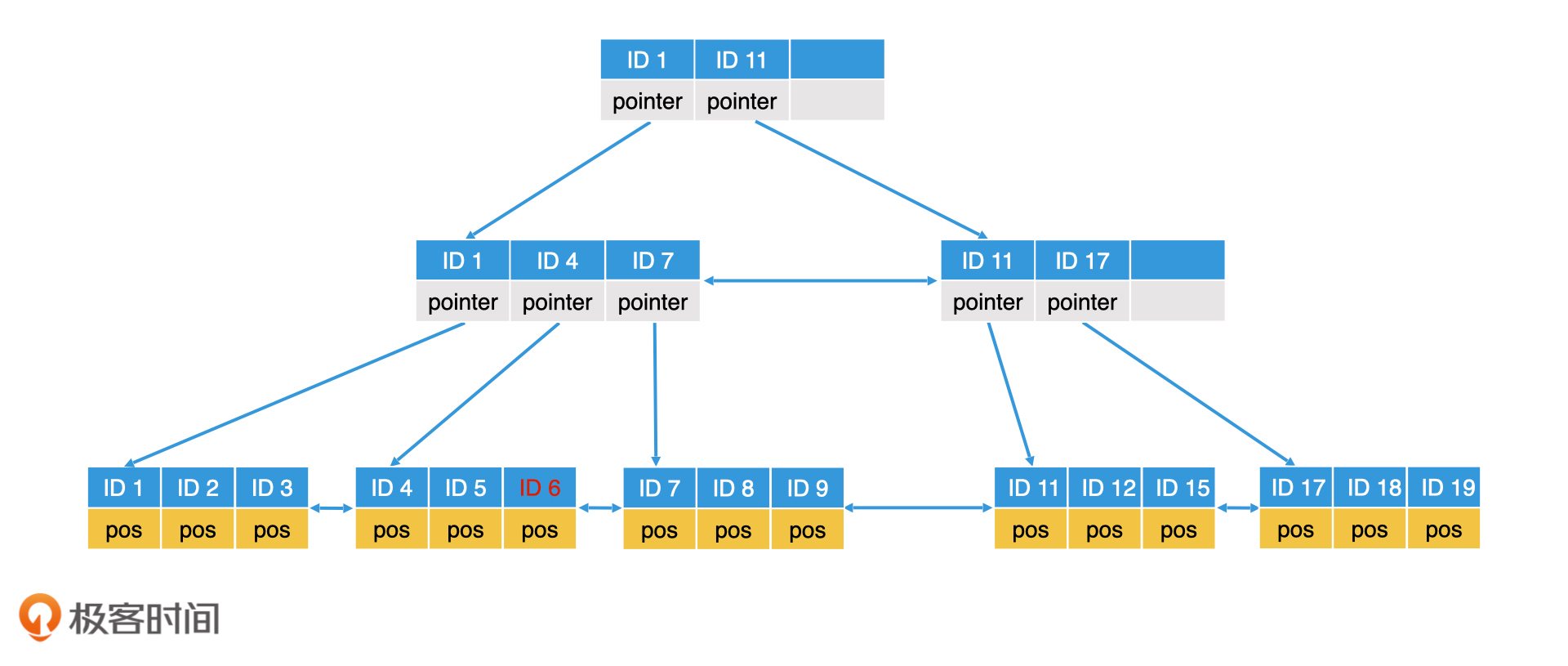
插入ID 6
如果我们插入的是ID=10的节点呢?按之前的逻辑,我们应该插入到ID 9后面,但是ID 9所在的这个节点已经存满了3个节点,无法继续存入了。因此,我们需要将该叶子节点分裂。分裂的逻辑就是生成一个新节点,并将数据在两个节点中平分。
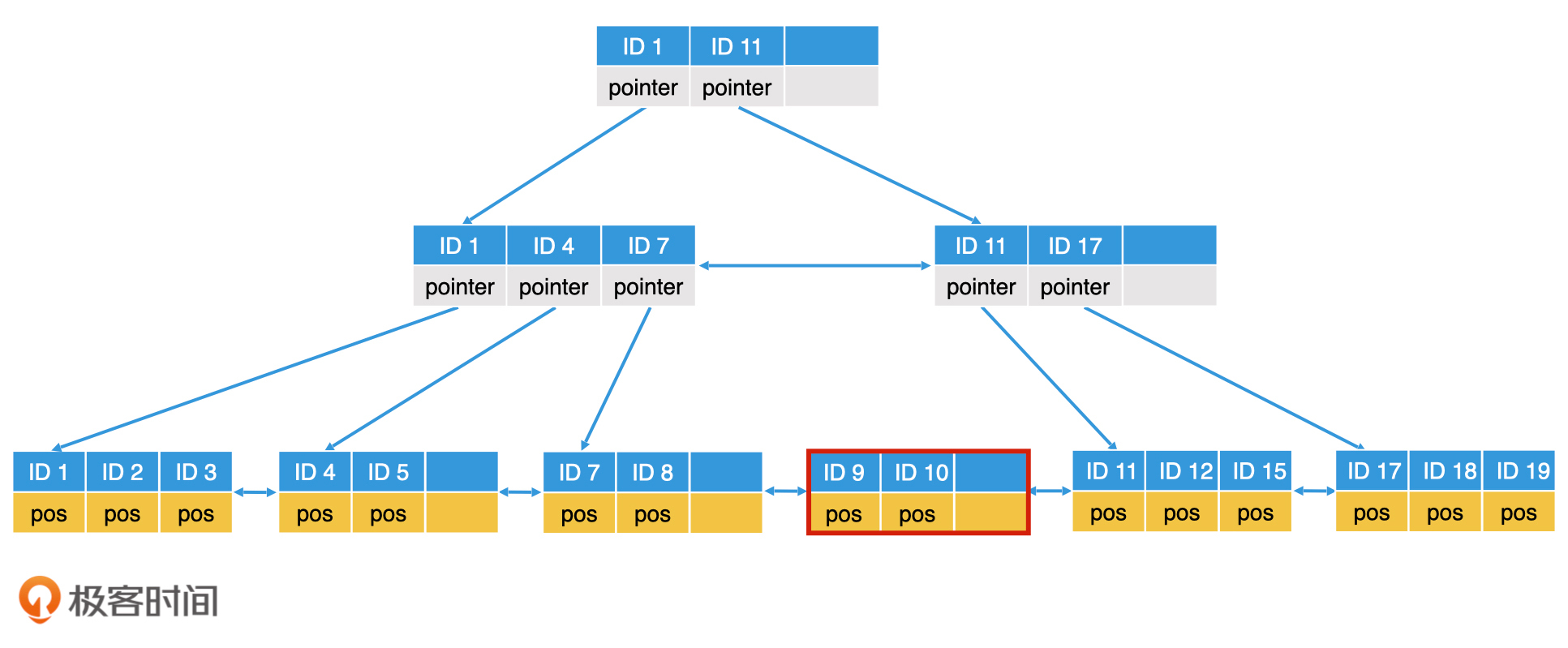
插入ID 10,叶子节点分裂
叶子节点分裂完成以后,上一层的内部节点也需要修改。但如果上一层的父节点也是满的,那么上一层的父节点也需要分裂。
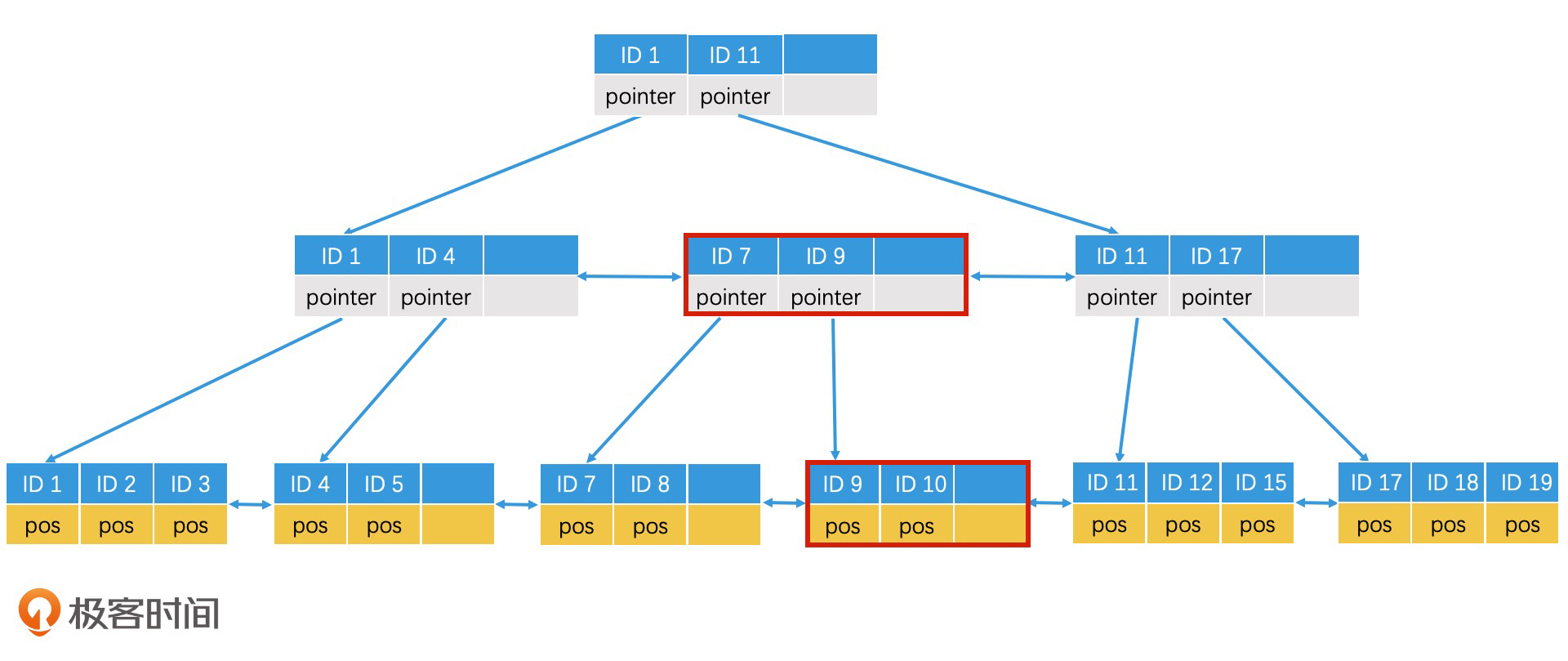
插入ID 10,内部节点修改
内部节点调整好了,下一步我们就要调整根节点了。由于根节点未满,因此我们不需要分裂,直接修改即可。
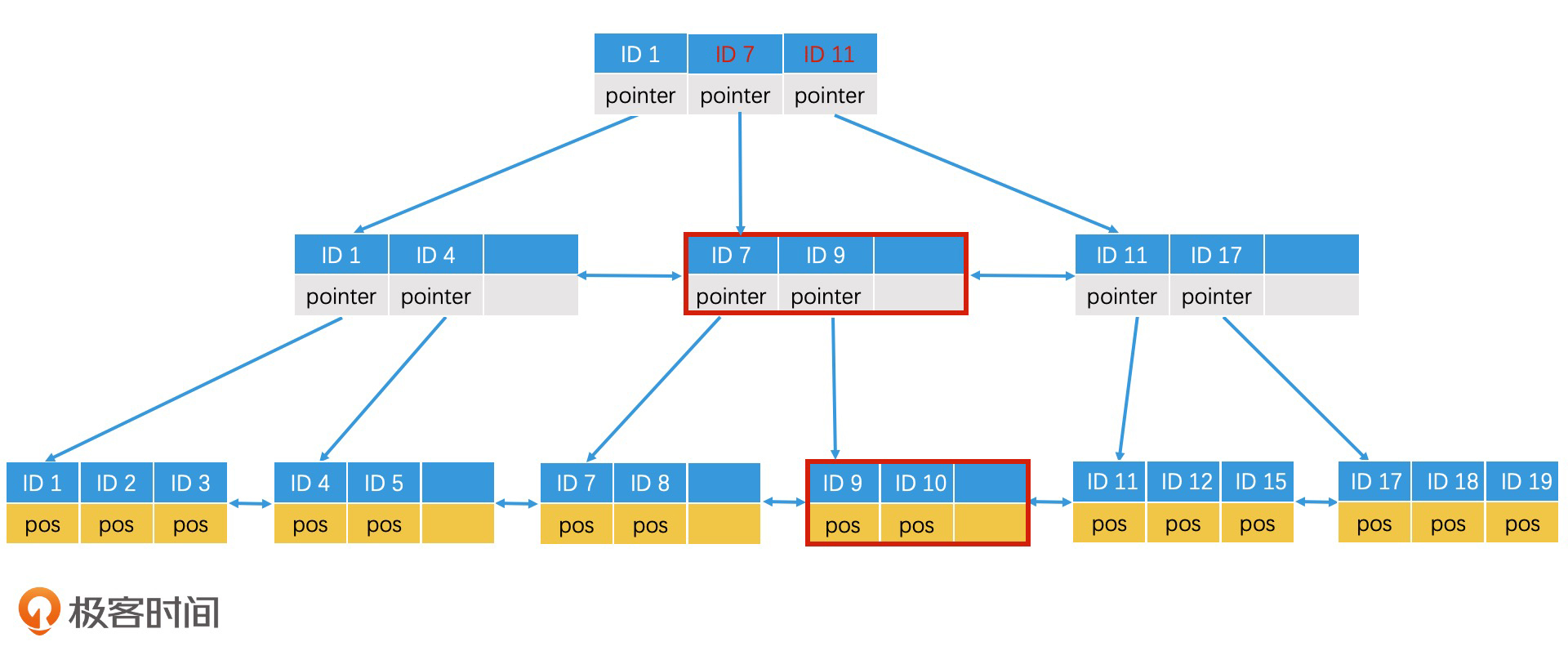
插入ID 10,根节点修改
删除数据也类似,如果节点数组较满,直接删除;如果删除后数组有一半以上的空间为空,那为了提高节点的空间利用率,该节点需要将左右两边兄弟节点的元素转移过来。可以成功转移的条件是,元素转移后该节点及其兄弟节点的空间必须都能维持在半满以上。如果无法满足这个条件,就说明兄弟节点其实也足够空闲,那我们直接将该节点的元素并入兄弟节点,然后删除该节点即可。
重点回顾
好了,今天的内容就先讲到这里。你会发现,即使是复杂的B+树,我们将它拆解开来,其实也是由简单的数组、链表和树组成的,而且B+树的检索过程其实也是二分查找。因此,如果B+树完全加载在内存中的话,它的检索效率其实并不会比有序数组或者二叉检索树更高,也还是二分查找的log(n)的效率。并且,它还比数组和二叉检索树更加复杂,还会带来额外的开销。
但是,B+树最大的优点在于,它提供了将索引数据存在磁盘中,以及高效检索的方案。这让检索技术摆脱了内存的限制,得到了更广泛地使用。
另外,这一节还有一个很重要的设计思想需要你掌握,那就是将索引和数据分离。通过这样的方式,我们能将索引的数组大小保持在一个较小的范围内,让它能加载在内存中。在许多大规模系统中,都是使用这个设计思想来精简索引的。而且,B+树的内部节点和叶子节点的区分,其实也是索引和数据分离的一次实践。
课堂讨论
最后,咱们来看一道讨论题。
B+树有一个很大的优势,就是适合做范围查询。如果我们要检索值在x到y之间的所有元素,你会怎么操作呢?
欢迎在留言区畅所欲言,说出你的思考过程和最终答案。如果有收获,也欢迎把这篇文章分享给你的朋友。