|
|
# 29 | Dispatchers是如何工作的?
|
|
|
|
|
|
你好,我是朱涛。今天,我们来分析Kotlin协程当中的Dispatchers。
|
|
|
|
|
|
上节课里,我们分析了launch的源代码,从中我们知道,Kotlin的launch会调用startCoroutineCancellable(),接着又会调用createCoroutineUnintercepted(),最终会调用编译器帮我们生成SuspendLambda实现类当中的create()方法。这样,协程就创建出来了。不过,协程是创建出来了,可它是如何运行的呢?
|
|
|
|
|
|
另外我们也都知道,协程无法脱离线程运行,Kotlin当中所有的协程,最终都是运行在线程之上的。**那么,协程创建出来以后,它又是如何跟线程产生关联的?**这节课,我们将进一步分析launch的启动流程,去发掘上节课我们忽略掉的代码分支。
|
|
|
|
|
|
我相信,经过这节课的学习,你会对协程与线程之间的关系有一个更加透彻的认识。
|
|
|
|
|
|
## Dispatchers
|
|
|
|
|
|
在上节课里我们学习过,launch{}本质上是调用了startCoroutineCancellable()当中的createCoroutineUnintercepted()方法创建了协程。
|
|
|
|
|
|
```plain
|
|
|
// 代码段1
|
|
|
|
|
|
public fun <T> (suspend () -> T).startCoroutineCancellable(completion: Continuation<T>): Unit = runSafely(completion) {
|
|
|
// 注意这里
|
|
|
// ↓
|
|
|
createCoroutineUnintercepted(completion).intercepted().resumeCancellableWith(Result.success(Unit))
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
那么下面,我们就接着上节课的流程,继续分析createCoroutineUnintercepted(completion)之后的 **intercepted()方法**。
|
|
|
|
|
|
不过,在正式分析intercepted()之前,我们还需要弄清楚Dispatchers、CoroutineDispatcher、ContinuationInterceptor、CoroutineContext之间的关系。
|
|
|
|
|
|
```plain
|
|
|
// 代码段2
|
|
|
|
|
|
public actual object Dispatchers {
|
|
|
|
|
|
public actual val Default: CoroutineDispatcher = DefaultScheduler
|
|
|
|
|
|
public actual val Main: MainCoroutineDispatcher get() = MainDispatcherLoader.dispatcher
|
|
|
|
|
|
public actual val Unconfined: CoroutineDispatcher = kotlinx.coroutines.Unconfined
|
|
|
|
|
|
public val IO: CoroutineDispatcher = DefaultIoScheduler
|
|
|
|
|
|
public fun shutdown() { }
|
|
|
}
|
|
|
|
|
|
public abstract class CoroutineDispatcher :
|
|
|
AbstractCoroutineContextElement(ContinuationInterceptor), ContinuationInterceptor {}
|
|
|
|
|
|
public interface ContinuationInterceptor : CoroutineContext.Element {}
|
|
|
|
|
|
public interface Element : CoroutineContext {}
|
|
|
|
|
|
```
|
|
|
|
|
|
在[第17讲](https://time.geekbang.org/column/article/488571)当中,我们曾经分析过它们之间的继承关系。Dispatchers是一个单例对象,它当中的Default、Main、Unconfined、IO,类型都是CoroutineDispatcher,而它本身就是CoroutineContext。所以,它们之间的关系就可以用下面这个图来描述。
|
|
|
|
|
|
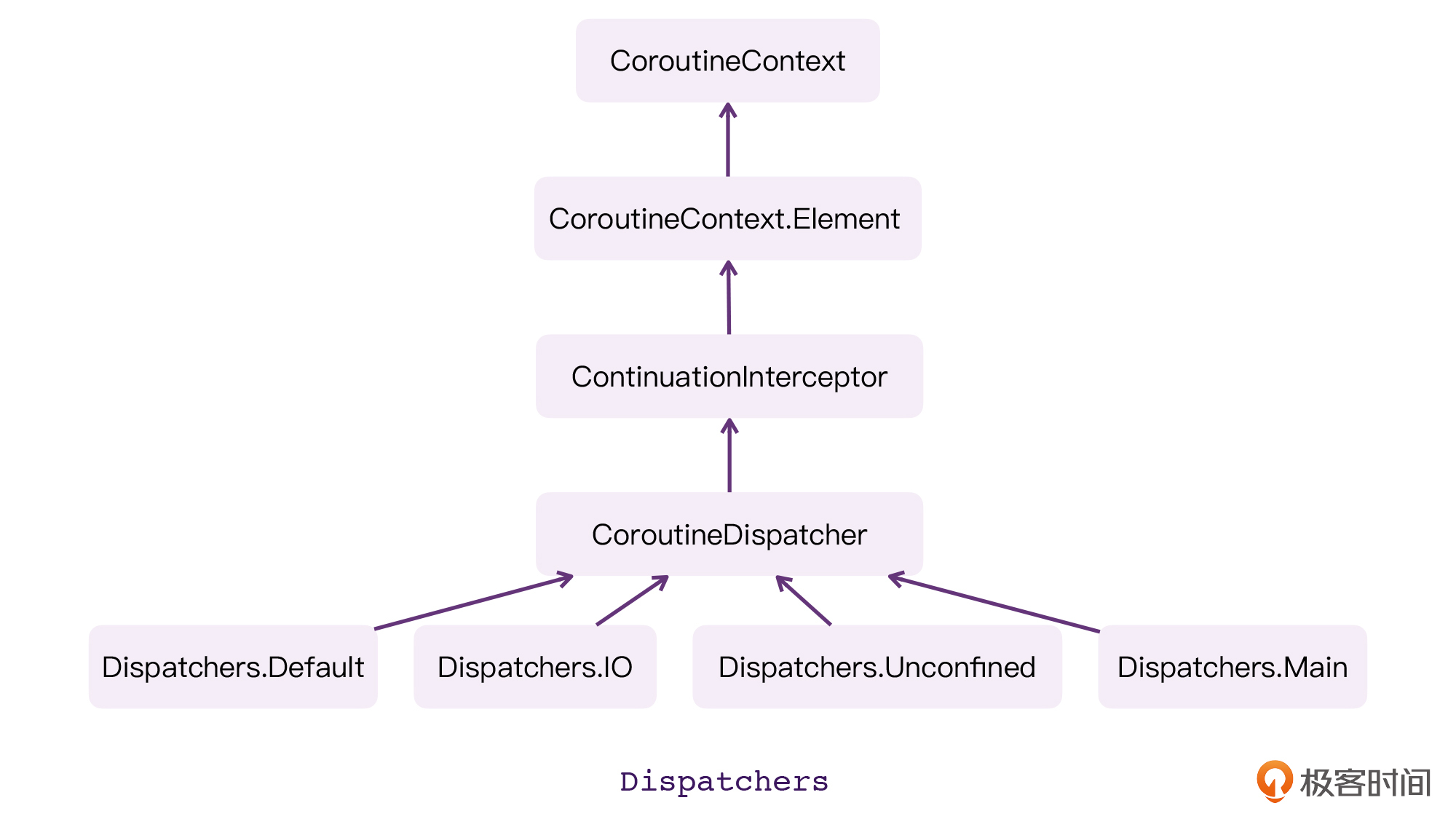
|
|
|
|
|
|
让我们结合这张图,来看看下面这段代码:
|
|
|
|
|
|
```plain
|
|
|
// 代码段3
|
|
|
|
|
|
fun main() {
|
|
|
testLaunch()
|
|
|
Thread.sleep(2000L)
|
|
|
}
|
|
|
|
|
|
private fun testLaunch() {
|
|
|
val scope = CoroutineScope(Job())
|
|
|
scope.launch{
|
|
|
logX("Hello!")
|
|
|
delay(1000L)
|
|
|
logX("World!")
|
|
|
}
|
|
|
}
|
|
|
|
|
|
/**
|
|
|
* 控制台输出带协程信息的log
|
|
|
*/
|
|
|
fun logX(any: Any?) {
|
|
|
println(
|
|
|
"""
|
|
|
================================
|
|
|
$any
|
|
|
Thread:${Thread.currentThread().name}
|
|
|
================================""".trimIndent()
|
|
|
)
|
|
|
}
|
|
|
|
|
|
/*
|
|
|
输出结果
|
|
|
================================
|
|
|
Hello!
|
|
|
Thread:DefaultDispatcher-worker-1 @coroutine#1
|
|
|
================================
|
|
|
================================
|
|
|
World!
|
|
|
Thread:DefaultDispatcher-worker-1 @coroutine#1
|
|
|
================================
|
|
|
*/
|
|
|
|
|
|
```
|
|
|
|
|
|
在这段代码中,我们没有为launch()传入任何CoroutineContext参数,但通过执行结果,我们发现协程代码居然执行在DefaultDispatcher,并没有运行在main线程之上。这是为什么呢?
|
|
|
|
|
|
我们可以回过头来分析下launch的源代码,去看看上节课中我们刻意忽略的地方。
|
|
|
|
|
|
```plain
|
|
|
// 代码段4
|
|
|
|
|
|
public fun CoroutineScope.launch(
|
|
|
context: CoroutineContext = EmptyCoroutineContext,
|
|
|
start: CoroutineStart = CoroutineStart.DEFAULT,
|
|
|
block: suspend CoroutineScope.() -> Unit
|
|
|
): Job {
|
|
|
// 1
|
|
|
val newContext = newCoroutineContext(context)
|
|
|
val coroutine = if (start.isLazy)
|
|
|
LazyStandaloneCoroutine(newContext, block) else
|
|
|
StandaloneCoroutine(newContext, active = true)
|
|
|
coroutine.start(start, coroutine, block)
|
|
|
return coroutine
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
首先,请留意launch的第一个参数,context,它的默认值是EmptyCoroutineContext。在第17讲里,我曾提到过,CoroutineContext就相当于Map,而EmptyCoroutineContext则相当于一个空的Map。所以,我们可以认为,这里的EmptyCoroutineContext传了也相当于没有传,它的目的只是为了让context参数不为空而已。**这其实也体现出了Kotlin的空安全思维,Kotlin官方用EmptyCoroutineContext替代了null。**
|
|
|
|
|
|
接着,请留意上面代码的注释1,这行代码会调用newCoroutineContext(context),将传入的context参数重新包装一下,然后返回。让我们看看它具体的逻辑:
|
|
|
|
|
|
```plain
|
|
|
// 代码段5
|
|
|
|
|
|
public actual fun CoroutineScope.newCoroutineContext(context: CoroutineContext): CoroutineContext {
|
|
|
// 1
|
|
|
val combined = coroutineContext.foldCopiesForChildCoroutine() + context
|
|
|
// 2
|
|
|
val debug = if (DEBUG) combined + CoroutineId(COROUTINE_ID.incrementAndGet()) else combined
|
|
|
// 3
|
|
|
return if (combined !== Dispatchers.Default && combined[ContinuationInterceptor] == null)
|
|
|
debug + Dispatchers.Default else debug
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
这段代码一共有三个注释,我们来分析一下:
|
|
|
|
|
|
* 注释1,由于newCoroutineContext()是CoroutineScope的扩展函数,因此,我们可以直接访问CoroutineScope的coroutineContext对象,它其实就是CoroutineScope对应的上下文。foldCopiesForChildCoroutine()的作用,其实就是将CoroutineScope当中的所有上下文元素都拷贝出来,然后跟传入的context参数进行合并。**这行代码,可以让子协程继承父协程的上下文元素。**
|
|
|
* 注释2,它的作用是在调试模式下,为我们的协程对象增加唯一的ID。我们在代码段3的输出结果中看到的“@coroutine#1”,其中的数字“1”就是在这个阶段生成的。
|
|
|
* 注释3,如果合并过后的combined当中没有CoroutineDispatcher,那么,就会默认使用Dispatchers.Default。
|
|
|
|
|
|
看到这里,你也许会有一个疑问,为什么协程默认的线程池是Dispatchers.Default,而不是Main呢?答案其实也很简单,因为Kotlin协程是支持多平台的,**Main线程只在UI编程平台才有可用**。因此,当我们的协程没有指定Dispatcher的时候,就只能使用Dispatchers.Default了。毕竟,协程是无法脱离线程执行的。
|
|
|
|
|
|
那么现在,代码段3当中的协程执行在Dispatchers.Default的原因也就找到了:由于我们定义的scope没有指定Dispatcher,同时launch的参数也没有传入Dispatcher,最终在newCoroutineContext()的时候,会被默认指定为Default线程池。
|
|
|
|
|
|
好,有了前面的基础以后,接下来,我们就可以开始intercepted()的逻辑了。
|
|
|
|
|
|
## CoroutineDispatcher拦截器
|
|
|
|
|
|
让我们回到课程开头提到过的startCoroutineCancellable()方法的源代码,其中的createCoroutineUnintercepted()方法,我们在上节课已经分析过了,它的返回值类型就是�Continuation。而**intercepted()方法,其实就是Continuation的扩展函数**。
|
|
|
|
|
|
```plain
|
|
|
// 代码段6
|
|
|
|
|
|
public fun <T> (suspend () -> T).startCoroutineCancellable(completion: Continuation<T>): Unit = runSafely(completion) {
|
|
|
// 注意这里
|
|
|
// ↓
|
|
|
createCoroutineUnintercepted(completion).intercepted().resumeCancellableWith(Result.success(Unit))
|
|
|
}
|
|
|
|
|
|
|
|
|
public actual fun <T> Continuation<T>.intercepted(): Continuation<T> =
|
|
|
(this as? ContinuationImpl)?.intercepted() ?: this
|
|
|
|
|
|
internal abstract class ContinuationImpl(
|
|
|
completion: Continuation<Any?>?,
|
|
|
private val _context: CoroutineContext?
|
|
|
) : BaseContinuationImpl(completion) {
|
|
|
constructor(completion: Continuation<Any?>?) : this(completion, completion?.context)
|
|
|
|
|
|
@Transient
|
|
|
private var intercepted: Continuation<Any?>? = null
|
|
|
|
|
|
// 1
|
|
|
public fun intercepted(): Continuation<Any?> =
|
|
|
intercepted
|
|
|
?: (context[ContinuationInterceptor]?.interceptContinuation(this) ?: this)
|
|
|
.also { intercepted = it }
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
从上面的代码中,我们可以看到,startCoroutineCancellable()当中的intercepted()最终会调用BaseContinuationImpl的intercepted()方法。
|
|
|
|
|
|
这里,请你留意代码中我标记出的注释,intercepted()方法首先会判断它的成员变量 **intercepted是否为空**,如果为空,就会调用context\[ContinuationInterceptor\],获取上下文当中的Dispatcher对象。以代码段3当中的逻辑为例,这时候的Dispatcher肯定是Default线程池。
|
|
|
|
|
|
然后,如果我们继续跟进interceptContinuation(this)方法的话,会发现程序最终会调用CoroutineDispatcher的interceptContinuation()方法。
|
|
|
|
|
|
```plain
|
|
|
// 代码段7
|
|
|
|
|
|
public abstract class CoroutineDispatcher :
|
|
|
AbstractCoroutineContextElement(ContinuationInterceptor), ContinuationInterceptor {
|
|
|
|
|
|
// 1
|
|
|
public final override fun <T> interceptContinuation(continuation: Continuation<T>): Continuation<T> =
|
|
|
DispatchedContinuation(this, continuation)
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
同样留意下这里的注释1,interceptContinuation()直接返回了一个DispatchedContinuation对象,并且将this、continuation作为参数传了进去。这里的this,其实就是Dispatchers.Default。
|
|
|
|
|
|
所以,如果我们把startCoroutineCancellable()改写一下,它实际上会变成下面这样:
|
|
|
|
|
|
```plain
|
|
|
// 代码段8
|
|
|
|
|
|
public fun <T> (suspend () -> T).startCoroutineCancellable(completion: Continuation<T>): Unit = runSafely(completion) {
|
|
|
createCoroutineUnintercepted(completion).intercepted().resumeCancellableWith(Result.success(Unit))
|
|
|
}
|
|
|
|
|
|
// 等价
|
|
|
// ↓
|
|
|
|
|
|
public fun <T> (suspend () -> T).startCoroutineCancellable(completion: Continuation<T>): Unit = runSafely(completion) {
|
|
|
// 1
|
|
|
val continuation = createCoroutineUnintercepted(completion)
|
|
|
// 2
|
|
|
val dispatchedContinuation = continuation.intercepted()
|
|
|
// 3
|
|
|
dispatchedContinuation.resumeCancellableWith(Result.success(Unit))
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
在上面的代码中,注释1,2我们都已经分析完了,现在只剩下注释3了。这里的resumeCancellableWith(),其实就是真正将协程任务分发到线程上的逻辑。让我们继续跟进分析源代码:
|
|
|
|
|
|
```plain
|
|
|
// 代码段9
|
|
|
|
|
|
internal class DispatchedContinuation<in T>(
|
|
|
@JvmField val dispatcher: CoroutineDispatcher,
|
|
|
@JvmField val continuation: Continuation<T>
|
|
|
) : DispatchedTask<T>(MODE_UNINITIALIZED), CoroutineStackFrame, Continuation<T> by continuation {
|
|
|
|
|
|
inline fun resumeCancellableWith(
|
|
|
result: Result<T>,
|
|
|
noinline onCancellation: ((cause: Throwable) -> Unit)?
|
|
|
) {
|
|
|
// 省略,留到后面分析
|
|
|
}
|
|
|
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
也就是,DispatchedContinuation是实现了Continuation接口,同时,它使用了“类委托”的语法,将接口的具体实现委托给了它的成员属性continuation。通过之前代码段7的分析,我们知道它的成员属性 **dispatcher对应的就是Dispatcher.Default**,而成员属性 **continuation对应的则是launch当中传入的SuspendLambda实现类**。
|
|
|
|
|
|
另外,DispatchedContinuation还继承自DispatchedTask,我们来看看DispatchedTask到底是什么。
|
|
|
|
|
|
```plain
|
|
|
internal abstract class DispatchedTask<in T>(
|
|
|
@JvmField public var resumeMode: Int
|
|
|
) : SchedulerTask() {
|
|
|
|
|
|
}
|
|
|
|
|
|
internal actual typealias SchedulerTask = Task
|
|
|
|
|
|
internal abstract class Task(
|
|
|
@JvmField var submissionTime: Long,
|
|
|
@JvmField var taskContext: TaskContext
|
|
|
) : Runnable {
|
|
|
constructor() : this(0, NonBlockingContext)
|
|
|
inline val mode: Int get() = taskContext.taskMode // TASK_XXX
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
可以看到,DispatchedContinuation继承自DispatchedTask,而它则是SchedulerTask的子类,SchedulerTask是Task的类型别名,而Task实现了Runnable接口。因此,**DispatchedContinuation不仅是一个Continuation,同时还是一个Runnable。**
|
|
|
|
|
|
那么,既然它是Runnable,也就意味着它可以被分发到Java的线程当中去执行了。所以接下来,我们就来看看resumeCancellableWith()当中具体的逻辑:
|
|
|
|
|
|
```plain
|
|
|
// 代码段9
|
|
|
|
|
|
internal class DispatchedContinuation<in T>(
|
|
|
@JvmField val dispatcher: CoroutineDispatcher,
|
|
|
@JvmField val continuation: Continuation<T>
|
|
|
) : DispatchedTask<T>(MODE_UNINITIALIZED), CoroutineStackFrame, Continuation<T> by continuation {
|
|
|
|
|
|
inline fun resumeCancellableWith(
|
|
|
result: Result<T>,
|
|
|
noinline onCancellation: ((cause: Throwable) -> Unit)?
|
|
|
) {
|
|
|
val state = result.toState(onCancellation)
|
|
|
// 1
|
|
|
if (dispatcher.isDispatchNeeded(context)) {
|
|
|
_state = state
|
|
|
resumeMode = MODE_CANCELLABLE
|
|
|
// 2
|
|
|
dispatcher.dispatch(context, this)
|
|
|
} else {
|
|
|
// 3
|
|
|
executeUnconfined(state, MODE_CANCELLABLE) {
|
|
|
if (!resumeCancelled(state)) {
|
|
|
resumeUndispatchedWith(result)
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
|
|
|
}
|
|
|
|
|
|
public abstract class CoroutineDispatcher :
|
|
|
AbstractCoroutineContextElement(ContinuationInterceptor), ContinuationInterceptor {
|
|
|
// 默认是true
|
|
|
public open fun isDispatchNeeded(context: CoroutineContext): Boolean = true
|
|
|
|
|
|
public abstract fun dispatch(context: CoroutineContext, block: Runnable)
|
|
|
}
|
|
|
|
|
|
internal object Unconfined : CoroutineDispatcher() {
|
|
|
// 只有Unconfined会重写成false
|
|
|
override fun isDispatchNeeded(context: CoroutineContext): Boolean = false
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
这段代码里也有三个注释,我们来分析一下:
|
|
|
|
|
|
* 注释1,dispatcher.isDispatchNeeded(),通过查看CoroutineDispatcher的源代码,我们发现它的返回值始终都是true。在它的子类当中,只有Dispatchers.Unconfined会将其重写成false。这也就意味着,除了Unconfined以外,其他的Dispatcher都会返回true。对于我们代码段3当中的代码而言,我们的Dispatcher是默认的Default,所以,代码将会进入注释2对应的分支。
|
|
|
* 注释2,dispatcher.dispatch(context, this),这里其实就相当于将代码的执行流程分发到Default线程池。dispatch()的第二个参数要求是Runnable,这里我们传入的是this,这是因为DispatchedContinuation本身就间接实现了Runnable接口。
|
|
|
* 注释3,executeUnconfined{},它其实就对应着Dispather是Unconfined的情况,这时候,协程的执行不会被分发到别的线程,而是直接在当前线程执行。
|
|
|
|
|
|
接下来,让我们继续沿着注释2进行分析,这里的dispatcher.dispatch()其实就相当于调用了Dispatchers.Default.dispatch()。让我们看看它的逻辑:
|
|
|
|
|
|
```plain
|
|
|
public actual object Dispatchers {
|
|
|
|
|
|
@JvmStatic
|
|
|
public actual val Default: CoroutineDispatcher = DefaultScheduler
|
|
|
}
|
|
|
|
|
|
internal object DefaultScheduler : SchedulerCoroutineDispatcher(
|
|
|
CORE_POOL_SIZE, MAX_POOL_SIZE,
|
|
|
IDLE_WORKER_KEEP_ALIVE_NS, DEFAULT_SCHEDULER_NAME
|
|
|
) {}
|
|
|
|
|
|
```
|
|
|
|
|
|
那么,从上面的代码中,我们可以看到,**Dispatchers.Default本质上是一个单例对象DefaultScheduler**,它是SchedulerCoroutineDispatcher的子类。
|
|
|
我们也来看看SchedulerCoroutineDispatcher的源代码:
|
|
|
|
|
|
```plain
|
|
|
internal open class SchedulerCoroutineDispatcher(
|
|
|
private val corePoolSize: Int = CORE_POOL_SIZE,
|
|
|
private val maxPoolSize: Int = MAX_POOL_SIZE,
|
|
|
private val idleWorkerKeepAliveNs: Long = IDLE_WORKER_KEEP_ALIVE_NS,
|
|
|
private val schedulerName: String = "CoroutineScheduler",
|
|
|
) : ExecutorCoroutineDispatcher() {
|
|
|
|
|
|
private var coroutineScheduler = createScheduler()
|
|
|
|
|
|
override fun dispatch(context: CoroutineContext, block: Runnable): Unit = coroutineScheduler.dispatch(block)
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
根据以上代码,我们可以看到Dispatchers.Default.dispatch()最终会调用SchedulerCoroutineDispatcher的dispatch()方法,而它实际上调用的是coroutineScheduler.dispatch()。
|
|
|
|
|
|
这里,我们同样再来看看CoroutineScheduler的源代码:
|
|
|
|
|
|
```plain
|
|
|
internal class CoroutineScheduler(
|
|
|
@JvmField val corePoolSize: Int,
|
|
|
@JvmField val maxPoolSize: Int,
|
|
|
@JvmField val idleWorkerKeepAliveNs: Long = IDLE_WORKER_KEEP_ALIVE_NS,
|
|
|
@JvmField val schedulerName: String = DEFAULT_SCHEDULER_NAME
|
|
|
) : Executor, Closeable {
|
|
|
|
|
|
override fun execute(command: Runnable) = dispatch(command)
|
|
|
|
|
|
fun dispatch(block: Runnable, taskContext: TaskContext = NonBlockingContext, tailDispatch: Boolean = false) {
|
|
|
trackTask()
|
|
|
// 1
|
|
|
val task = createTask(block, taskContext)
|
|
|
// 2
|
|
|
val currentWorker = currentWorker()
|
|
|
// 3
|
|
|
val notAdded = currentWorker.submitToLocalQueue(task, tailDispatch)
|
|
|
if (notAdded != null) {
|
|
|
if (!addToGlobalQueue(notAdded)) {
|
|
|
|
|
|
throw RejectedExecutionException("$schedulerName was terminated")
|
|
|
}
|
|
|
}
|
|
|
val skipUnpark = tailDispatch && currentWorker != null
|
|
|
|
|
|
if (task.mode == TASK_NON_BLOCKING) {
|
|
|
if (skipUnpark) return
|
|
|
signalCpuWork()
|
|
|
} else {
|
|
|
|
|
|
signalBlockingWork(skipUnpark = skipUnpark)
|
|
|
}
|
|
|
}
|
|
|
|
|
|
private fun currentWorker(): Worker? = (Thread.currentThread() as? Worker)?.takeIf { it.scheduler == this }
|
|
|
|
|
|
// 内部类 Worker
|
|
|
internal inner class Worker private constructor() : Thread() {
|
|
|
}
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
你发现了吗?CoroutineScheduler其实是Java并发包下的Executor的子类,它的execute()方法也被转发到了dispatch()。
|
|
|
|
|
|
上面的代码里也有三个注释,我们分别来看看:
|
|
|
|
|
|
* 注释1,将传入的Runnable类型的block(也就是DispatchedContinuation),包装成Task。
|
|
|
* 注释2,currentWorker(),拿到当前执行的线程。这里的Worker其实是一个内部类,它本质上仍然是Java的Thread。
|
|
|
* 注释3,currentWorker.submitToLocalQueue(),将当前的Task添加到Worker线程的本地队列,等待执行。
|
|
|
|
|
|
那么接下来,我们就来分析下Worker是如何执行Task的。
|
|
|
|
|
|
```plain
|
|
|
internal inner class Worker private constructor() : Thread() {
|
|
|
|
|
|
override fun run() = runWorker()
|
|
|
|
|
|
@JvmField
|
|
|
var mayHaveLocalTasks = false
|
|
|
|
|
|
private fun runWorker() {
|
|
|
var rescanned = false
|
|
|
while (!isTerminated && state != WorkerState.TERMINATED) {
|
|
|
// 1
|
|
|
val task = findTask(mayHaveLocalTasks)
|
|
|
|
|
|
if (task != null) {
|
|
|
rescanned = false
|
|
|
minDelayUntilStealableTaskNs = 0L
|
|
|
// 2
|
|
|
executeTask(task)
|
|
|
continue
|
|
|
} else {
|
|
|
mayHaveLocalTasks = false
|
|
|
}
|
|
|
|
|
|
if (minDelayUntilStealableTaskNs != 0L) {
|
|
|
if (!rescanned) {
|
|
|
rescanned = true
|
|
|
} else {
|
|
|
rescanned = false
|
|
|
tryReleaseCpu(WorkerState.PARKING)
|
|
|
interrupted()
|
|
|
LockSupport.parkNanos(minDelayUntilStealableTaskNs)
|
|
|
minDelayUntilStealableTaskNs = 0L
|
|
|
}
|
|
|
continue
|
|
|
}
|
|
|
|
|
|
tryPark()
|
|
|
}
|
|
|
tryReleaseCpu(WorkerState.TERMINATED)
|
|
|
}
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
实际上,Worker会重写Thread的run()方法,然后把执行流程交给runWorker(),以上代码里有两个关键的地方,我也用注释标记了。
|
|
|
|
|
|
* 注释1,在while循环当中,会一直尝试从Worker的本地队列取Task出来,如果存在需要执行的Task,就会进入下一步。
|
|
|
* 注释2,executeTask(task),其实就是执行对应的Task。
|
|
|
|
|
|
而接下来的逻辑,就是**最关键的部分**了:
|
|
|
|
|
|
```plain
|
|
|
internal inner class Worker private constructor() : Thread() {
|
|
|
private fun executeTask(task: Task) {
|
|
|
val taskMode = task.mode
|
|
|
idleReset(taskMode)
|
|
|
beforeTask(taskMode)
|
|
|
// 1
|
|
|
runSafely(task)
|
|
|
afterTask(taskMode)
|
|
|
}
|
|
|
}
|
|
|
|
|
|
fun runSafely(task: Task) {
|
|
|
try {
|
|
|
// 2
|
|
|
task.run()
|
|
|
} catch (e: Throwable) {
|
|
|
val thread = Thread.currentThread()
|
|
|
thread.uncaughtExceptionHandler.uncaughtException(thread, e)
|
|
|
} finally {
|
|
|
unTrackTask()
|
|
|
}
|
|
|
}
|
|
|
|
|
|
internal abstract class Task(
|
|
|
@JvmField var submissionTime: Long,
|
|
|
@JvmField var taskContext: TaskContext
|
|
|
) : Runnable {
|
|
|
constructor() : this(0, NonBlockingContext)
|
|
|
inline val mode: Int get() = taskContext.taskMode // TASK_XXX
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
在Worker的executeTask()方法当中,会调用runSafely()方法,而在这个方法当中,最终会调用task.run()。前面我们就提到过 **Task本质上就是Runnable,而Runnable.run()其实就代表了我们的协程任务真正执行了!**
|
|
|
|
|
|
那么,task.run()具体执行的代码是什么呢?其实它是执行的 **DispatchedTask.run()**。这里的DispatchedTask实际上是DispatchedContinuation的父类。
|
|
|
|
|
|
```plain
|
|
|
internal class DispatchedContinuation<in T>(
|
|
|
@JvmField val dispatcher: CoroutineDispatcher,
|
|
|
@JvmField val continuation: Continuation<T>
|
|
|
) : DispatchedTask<T>(MODE_UNINITIALIZED), CoroutineStackFrame, Continuation<T> by continuation {
|
|
|
|
|
|
public final override fun run() {
|
|
|
|
|
|
val taskContext = this.taskContext
|
|
|
var fatalException: Throwable? = null
|
|
|
try {
|
|
|
val delegate = delegate as DispatchedContinuation<T>
|
|
|
val continuation = delegate.continuation
|
|
|
withContinuationContext(continuation, delegate.countOrElement) {
|
|
|
val context = continuation.context
|
|
|
val state = takeState()
|
|
|
val exception = getExceptionalResult(state)
|
|
|
|
|
|
val job = if (exception == null && resumeMode.isCancellableMode) context[Job] else null
|
|
|
if (job != null && !job.isActive) {
|
|
|
// 1
|
|
|
val cause = job.getCancellationException()
|
|
|
cancelCompletedResult(state, cause)
|
|
|
continuation.resumeWithStackTrace(cause)
|
|
|
} else {
|
|
|
if (exception != null) {
|
|
|
// 2
|
|
|
continuation.resumeWithException(exception)
|
|
|
} else {
|
|
|
// 3
|
|
|
continuation.resume(getSuccessfulResult(state))
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
} catch (e: Throwable) {
|
|
|
|
|
|
fatalException = e
|
|
|
} finally {
|
|
|
val result = runCatching { taskContext.afterTask() }
|
|
|
handleFatalException(fatalException, result.exceptionOrNull())
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
上面的代码有三个关键的注释,我们一起来分析:
|
|
|
|
|
|
* 注释1,在协程代码执行之前,它首先会判断当前协程是否已经取消。如果已经取消的话,就会调用continuation.resumeWithStackTrace(cause)将具体的原因传出去。
|
|
|
* 注释2,判断协程是否发生了异常,如果已经发生了异常,则需要调用continuation.resumeWithException(exception)将异常传递出去。
|
|
|
* 注释3,如果一切正常,则会调用continuation.resume(getSuccessfulResult(state)),这时候,协程才会正式启动,并且执行launch当中传入的Lambda表达式。
|
|
|
|
|
|
最后,按照惯例,我还是制作了一个视频,来向你展示整个Dispather的代码执行流程。
|
|
|
|
|
|
## 小结
|
|
|
|
|
|
这节课,我们围绕着launch,着重分析了它的Dispatchers执行流程。Dispatchers是协程框架中与线程交互的关键,这里面主要涉及以下几个步骤:
|
|
|
|
|
|
* 第一步,createCoroutineUnintercepted(completion)创建了协程的Continuation实例,紧接着就会调用它的intercepted()方法,将其封装成DispatchedContinuation对象。
|
|
|
* 第二步,DispatchedContinuation会持有CoroutineDispatcher、以及前面创建的Continuation对象。课程中的CoroutineDispatcher实际上就是Default线程池。
|
|
|
* 第三步,执行DispatchedContinuation的resumeCancellableWith()方法,这时候,就会执行dispatcher.dispatch(),这就会将协程的Continuation封装成Task添加到Worker的本地任务队列,等待执行。这里的Worker本质上就是Java的Thread。**在这一步,协程就已经完成了线程的切换**。
|
|
|
* 第四步,Worker的run()方法会调用runWork(),它会从本地的任务队列当中取出Task,并且调用task.run()。而它实际上调用的是DispatchedContinuation的run()方法,在这里,会调用continuation.resume(),它将执行原本launch当中生成的SuspendLambda子类。**这时候,launch协程体当中的代码,就在线程上执行了**。
|
|
|
|
|
|
## 思考题
|
|
|
|
|
|
经过这节课的学习以后,请问你是否对协程的本质有了更深入的认识?请讲讲你的心得体会吧!
|
|
|
|