114 lines
12 KiB
Markdown
114 lines
12 KiB
Markdown
# 10 | 指数和KPI:智商是怎么计算出来的?
|
||
|
||
数据给你一双看透本质的眼睛,这里是《数据分析思维课》,我是郭炜。
|
||
|
||
在日常生活中,我们经常希望用一个数字去衡量一个特别复杂的事物,这样即使是外行也能一下就了解某件事情的程度和分布。
|
||
|
||
那什么数字可以满足这个苛刻的要求呢?答案是指数。
|
||
|
||
简单来讲,**凡是用指数描述的东西,都是一个长期存在或者需要大范围衡量的事情。**指数就像一把尺子,把指数放在这里一量,你就能知道现在这个事情所处的状态是怎样的。于是我们经常在生活当中看到各种各样的指数,从空气的污染指数到股票的上证指数,从用户忠诚度指数到智力指数(IQ)等等均是如此。
|
||
|
||
指数本身的定义很简单,就是变量值除以标准值再乘以100。
|
||
|
||

|
||
|
||
接下来你可以想想,如果让你来设计一个数字去代表上海证券交易所整体的行情,你会怎么做呢?
|
||
|
||
如果你只选一只股票来代表整个上海证券交易所的行情,就会出现很多问题。比如你找的这家公司的股票退市了,那怎么办?或者是它进行了一些股票的增发/除权,突然之间价格变化非常大,那它能代表着当时所有股票的行情吗?
|
||
|
||
很明显单只股票是无法代表整体行情的,这个时候就轮到指数登场了。
|
||
|
||
## 简单的指数:上证指数
|
||
|
||
接下来我就以上证指数为例,带你看一下一个标准的指数应该由什么构成。
|
||
|
||
首先它得有标准值,也就是分母。你要注意,这个标准值不仅是一个数字值,也代表一个具体的时间点。比如,新的上证综合指数就是以2005年12月30日为基日(即基准日),以当日所有样本股票的市值总值为基期,以1000点为基点来做的分母。
|
||
|
||
其次,一个指数还要有一个加权的计算公式,这个计算公式是这样子的。
|
||
|
||

|
||
|
||
也就是以基期和计算日的股票收盘价(如当日无成交,沿用上一日收盘价)分别乘以发行股数,相加后求得基期和计算日市价总值,再相除后乘以100即得股价指数。
|
||
|
||
看上去很简单,就是当前市值除以基期市值,但这还没完,上证指数还有**一套修正的规则**,这是非常重要的。因为一个指数不仅仅是一个数学公式,它背后还代表着一套管理规则。
|
||
|
||
所以对于上证指数来说,股票要有样本池,样本池可不是闭眼随便一选,而是需要由上海证券交易所选择的若干只大盘股和蓝筹股综合计算。
|
||
|
||
仅仅用上面这个公式还不够,因为样本池中的单一股票会由于非市场交易因素发生变动(例如配股和送股等),但是这些非交易因素发生变动而产生的价格变动都不计算在这个指数的变化范围内,这个时候就得用下面这个公式来做一下修正。
|
||
|
||

|
||
|
||
通过上证指数这个小例子希望你能够明白,其实指数公式本身很简单,关键在于指数公式的背后,你要如何去制定一个能够保持指数有效性的规则。指数不是一条一使劲就变长的橡皮筋,而是一把相对精准的尺子。
|
||
|
||
## 较复杂的指数:用户忠诚度指数
|
||
|
||
我们现在来看一个比上证指数要更复杂一些的例子。在互联网分析当中,我们经常会看到一个数据叫做用户忠诚度指数。
|
||
|
||
用户忠诚度指数顾名思义,它用来衡量用户做某种行为的忠诚度。这个指数和上证指数就不太一样了,它和大多数日常使用的指标一样,**复杂度在于你对于业务的定义**。例如我把忠诚度定义为第N日/周/月后回访的用户行为指标对于初始行为指标的占比,那么这个忠诚度指数就会变成下面这个样子。
|
||
|
||

|
||
|
||
这个公式看上去也很简单,但是这个公式在理解层面上相比于上证指数的公式,其实更难了。
|
||
|
||
比如说,什么叫初始行为指标?例如我们把这个行为定义成访问这个App或者网站的活跃用户数,这个忠诚度指数就是留存率。
|
||
|
||
但是问题又来了,什么是活跃用户数呢?我打开视频App看一秒钟算活跃吗?我要是第二秒就退出了,那我应该不是一个活跃用户。那是不是看五秒钟以上的用户就可以算活跃用户了呢?这些问题其实非常复杂。
|
||
|
||
并且对于用户忠诚度而言,我也可以说我今天在京东上面买了大闸蟹,我过了一周又去京东上买了大闸蟹,那么我在京东上对大闸蟹的用户忠诚度就很高。就像下图里一样,我们可以选择各种各样的条件来进行用户忠诚度分析。
|
||
|
||
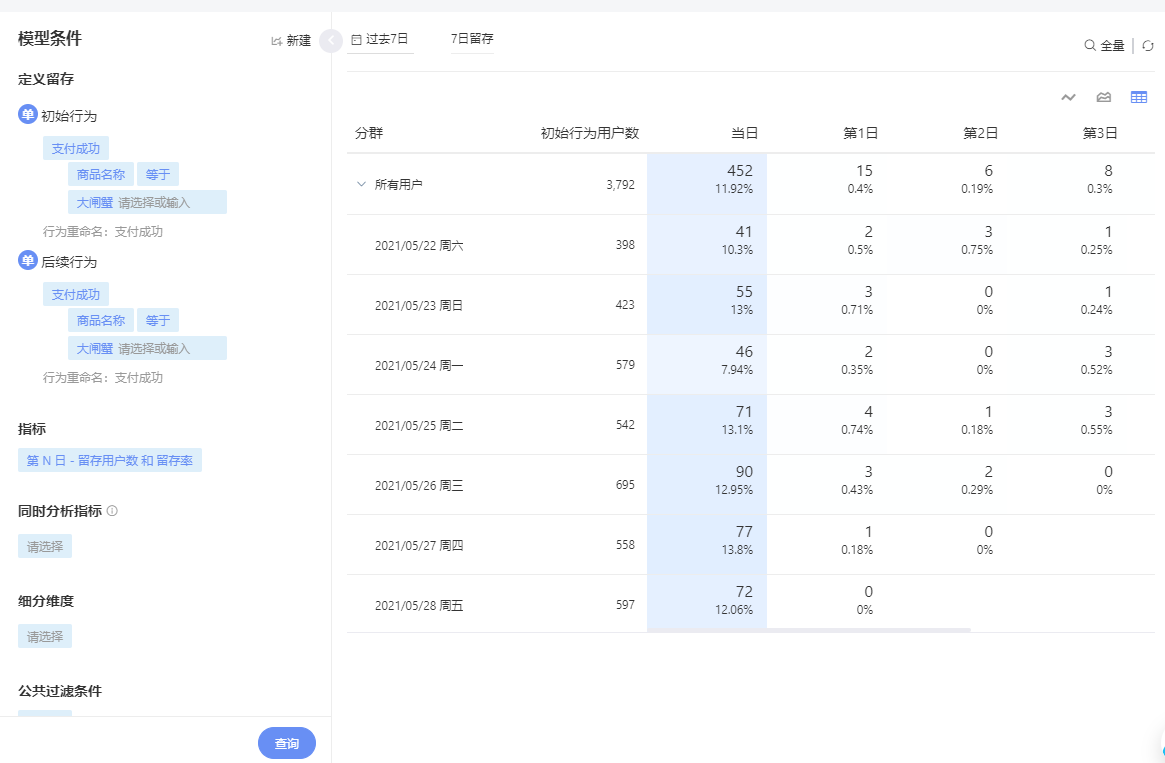
|
||
|
||
类似用户忠诚度这样的指数,在我们日常工作当中经常会出现。这样的指数往往会有这样一个明显的特征:看上去公式很容易定义,但是对于公式的解释往往非常复杂,而且需要大量业务经验的人员和经验通过“[数据治理](https://www.infoq.cn/article/ubch5bdk2twgdo5x*uzn)”这个过程才能把它定义好。
|
||
|
||
而这个数据治理的过程可以用外部专家或者内部项目,建立一套每年要有公司级别的共识和变化的策略(和上证指数修正方法类似),才可以把一个指数真的延续下去。
|
||
|
||
## 复杂的指数:智商(IQ)
|
||
|
||
刚刚我们讲的上证指数和用户忠诚度指数都是用一个数字去衡量一组数字,那么现在难题来了:我们怎样用数字化手段去衡量一个复杂的事物呢?**比如我们要怎样去衡量一个人的聪明程度?**
|
||
|
||
这件事情听上去就更复杂了。首先,就像我们前面提到的,制定某些维度去衡量一个人本身就是比较困难的。其次,人不是一成不变的,随着年龄的增长人的聪明程度也会发生变化。
|
||
|
||
我们能用一个固定公式来去囊括所有年龄的人吗?显然是不可行的。因为如果用大人的聪明程度去死板地衡量一个孩子,很可能就把一些特殊的聪明孩子给耽误了。
|
||
|
||
在20世纪初,法国心理学家比奈和他的学生编写了世界上第一套智力量表,后来心理学家推孟把这套量表介绍到美国,将其修订为斯坦福-比奈量表,并用标准测试题得出的心理年龄与生理年龄之比,作为评定智力水平的指数,这个比被称为智商。
|
||
|
||

|
||
|
||
上面这个公式就是现在网上大多数人会告诉你的智商的算法,但这个算法其实是不对的。通过这个公式我们虽然能看到神童的IQ很高,但也会发现随着我们经验阅历的增长,用这个公式算出来的智商反而越低,也就是说我们人会越活越笨,这不符合实际情况啊。
|
||
|
||
所以目前最流行的智商计算方法是叫做韦克斯勒的离差智商,它的基本原理就如同正态分布的原理一样。
|
||
|
||
韦克斯勒的量表是一个平均值为100,标准差为15的一个正态分布曲线。在用韦克斯勒的方法测量智商的时候,你得先做一组标准的测验题,然后再将你的得分套用到韦克斯勒正态分布表(韦氏量表)中对应,这样就能得出你的智商值了。
|
||
|
||
当然,由于年龄差异的问题,韦氏量表也分为韦氏成人智力量表、韦氏儿童智力量表和韦氏幼儿智力量表这三套量表,可以用于检测所有年龄段的智商。
|
||
|
||
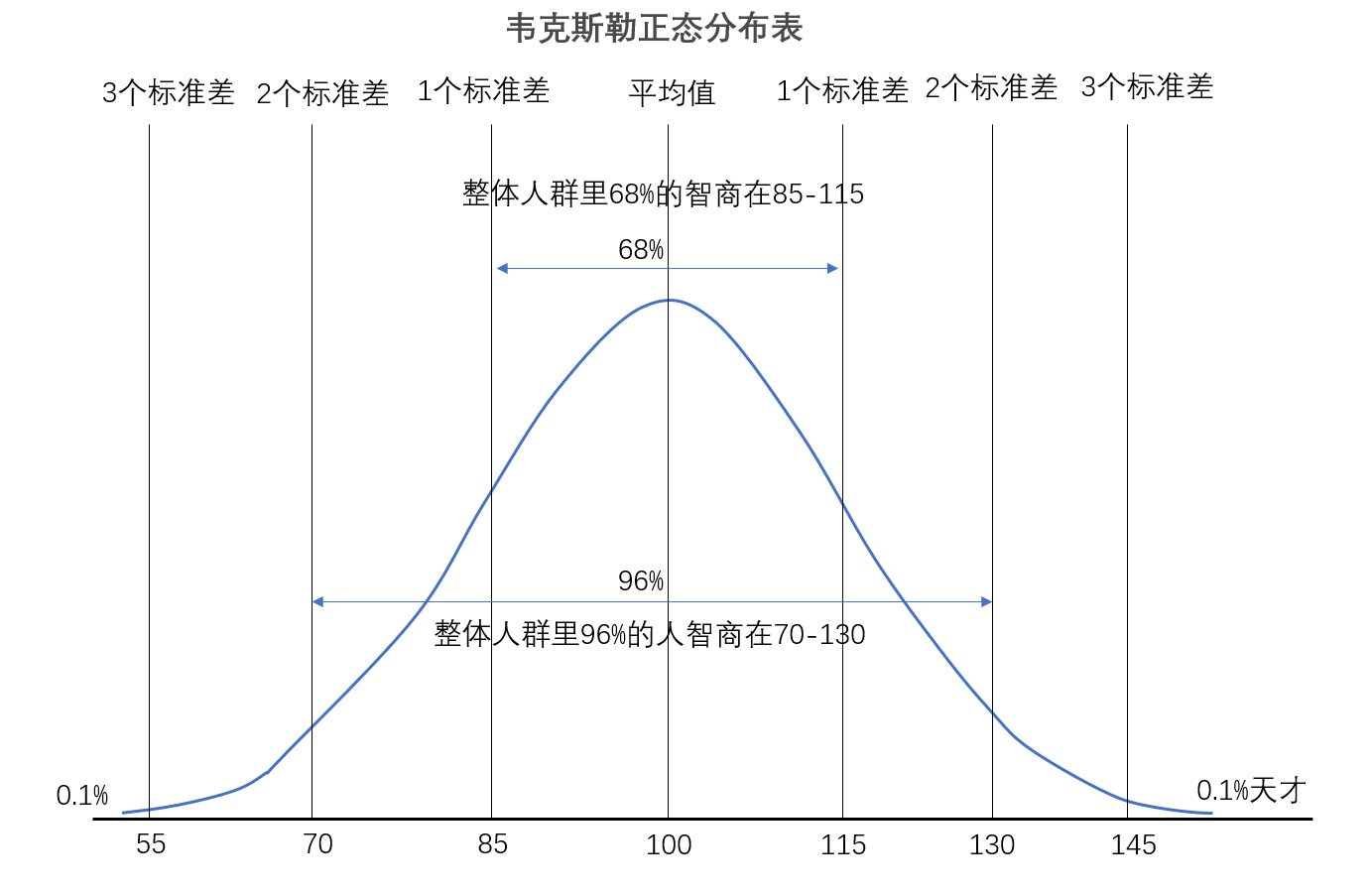
|
||
|
||
根据前面标准差的知识可知,正负3个标准差也就是6个σ能覆盖人类99.97%的情况。也就是说,100±15×3(也就是55到145之间)是大多数人的智商分布。所以当你的智商测试得分在100分以上,可以说你已经比较聪明了;如果是130分,你已经是相当聪明;如果你是150分,感谢你还在看我的专栏,因为你就是那个6个σ万世不遇的奇才,这就是现代智商的算法。
|
||
|
||
学到这,相信你也发现了,智商的计算在指数计算中是非常复杂的:既要有复杂的标准测试题,还要和全人类的实际情况进行比对,最终才能够得到一个合理的标准分值。
|
||
|
||
要做一把尺子来衡量人这种复杂动物的聪明程度,很难。
|
||
|
||
所以在咱们工作和生活当中,**当我们要制定某个指数,比方说设定KPI的时候,我们要注意不要光看公式的建立,而是要把一系列定义调整的制度算法规定出来,**否则很多KPI项目最后KPI完成了,但其实公司目的并没有达成。
|
||
|
||
可能这么说你还是有些不清楚,给你讲个小故事。话说有一天,小王发现路边上有两个人在热火朝天地干活:一个人在前面挖坑,土坑挖完后,后面的那个人赶紧跑上去把坑重新填上。小王就很疑惑,这不纯属在瞎忙活嘛!于是小王上前询问二人为什么要这么干。最后一问发现,原来是负责种树的那个人请假了,只剩下挖土填坑二人组自己完成自己的KPI,而没有完成种树这个目标。
|
||
|
||
所以最近新流行的管理方法OKR,其实是为了规避KPI管理的一些缺点,在某种程度上借鉴了指数建立和调整的规则:建立好目标O之后, KR可以进行动态监测和调整,并为之建立一套分层和计算调整体系。这里最关键的是对K(也就是key messuarement)的定义和相关的针对O的调整方法,和今天所讲的指标的定义和管理方法很类似,这套方法没定义好,不管是KPI还是OKR都很难有好的管理效果。
|
||
|
||
## 小结
|
||
|
||
讲到这,我们今天的这节课也就接近尾声了,最后我来给你总结一下今天的要点。
|
||
|
||
我们今天讲了指数,指数其实是把我们现实社会数字化的最常用的一种方式。仔细想一想,其实从我们个人的高考标准分到衡量我们每一个人工作的OKR或者KPI,再到现在衡量国家发展状况的居民消费价格指数CPI,其实这些数字都是指数在各种不同场景的表现。
|
||
|
||
我们聊了三个具体的指数例子,希望你能明白**指数不是一个简简单单的加权平均值,它背后映射了一套管理的思维逻辑。**即使是像上证指数一样有着复杂多变的股票的情况下,我们也得有一个标准的规则来去统计。而对于更复杂的情况(比如我们要衡量人的时候),我们更需要结合前面所学的多种数据分析方法和工具,来设计一个基于实验结果的指数计算方法,这样才能够客观地把活生生的人变成一组数字。
|
||
|
||
但在我们的生活和工作中,很多人往往会为了做一个可衡量的数字,不负责任地拍脑袋决策出一个结果。比如说我知道很多公司在做员工360度评估的时候,就是简单地套用一个标准公式,这样的评估往往是失败的。一定要基于细致的业务流程和实验,才能得到合理科学的结果。
|
||
|
||
因此我希望今天你学了指数这节课后,一方面当你在衡量一个事物的时候,不要轻易地拍脑袋造出一组数字来代表它。另一方面,希望你能够更加坚定地相信,数字是可以衡量这个世间所有事物的。毕竟如此复杂的我们都可以用数字来衡量,还有什么是不能衡量的呢?
|
||
|
||
## 课后思考
|
||
|
||
最后我们一块来做个思考题吧。你在日常生活和工作当中还会遇到哪些指数呢?它们属于我们这节课讲的指数类型的哪一种?它的定义和调整规则是什么?欢迎你分享出来,我们一起提高。
|
||
|