|
|
# 30 | 预压测:如何基于小流量快速验证容量压测效果?
|
|
|
|
|
|
你好,我是高楼。
|
|
|
|
|
|
上一节课呢,我们重点讲解了基准场景、容量场景、稳定性场景和异常场景这四类性能场景。通过对一个接口的基准场景模拟,我们提前发现了Calico IPIP模式单网卡软中断的问题,为后面容量场景的测试减少了一些麻烦。
|
|
|
|
|
|
这节课,我们就再进一步,把容量场景跑起来。我们先预压测一下,把场景中存在的小问题先找出来。
|
|
|
|
|
|
因为是预压测,所以一开始我们不用上太多的线程。先添加20个线程,运行一下看看结果就可以了。
|
|
|
|
|
|
说明一下,这里我换到JMeter上来运行,倒不是因为GoReplay不能满足压测需求,经过前面的改造,GoReplay其实已经可以完成我们的压测需求了。只是我还是更习惯JMeter在功能上的丰富性,所以在预压测这一讲,我们还是用JMeter来执行。
|
|
|
|
|
|
## 第一阶段
|
|
|
|
|
|
### 压力场景数据
|
|
|
|
|
|
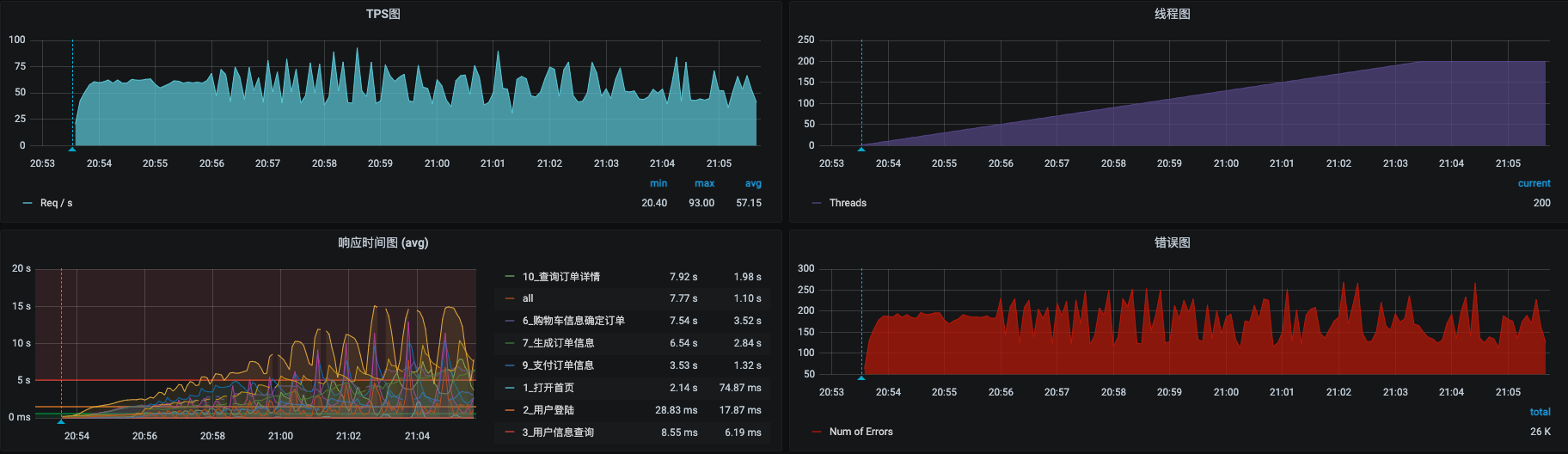
怀着激动的心情,我们先来启动压力:
|
|
|
|
|
|
|
|
|
|
|
|
果然是不压不知道,一压心直跳呀。错误率很高不说,响应时间也很长。这就是我们要面对的问题了。
|
|
|
|
|
|
我们先来分析一下错误在哪。
|
|
|
|
|
|

|
|
|
|
|
|
从报错的信息来看,是断言判断不到设定的“操作成功”和“下单成功”字样。这是什么问题呢?
|
|
|
|
|
|
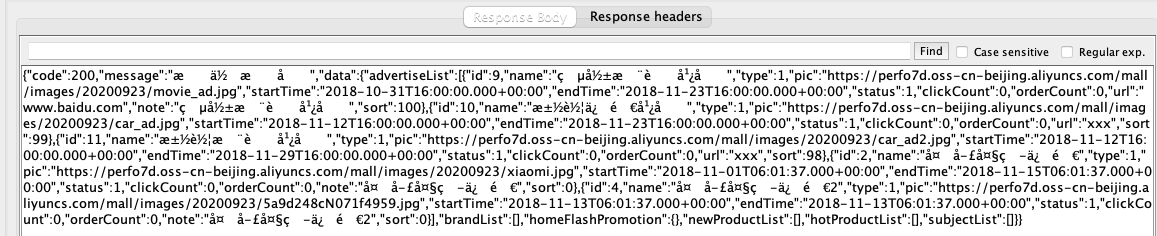
我们先把脚本拿到本地来跑一下试试。
|
|
|
|
|
|
|
|
|
|
|
|
我们发现,返回信息里的中文全是乱码。这样一来,断言自然也就失效了。为了解决乱码,我们打开JMeter目录中的/bin/jmeter.properties,添加UTF-8的配置到文件中。
|
|
|
|
|
|
```java
|
|
|
sampleresult.default.encoding=utf-8
|
|
|
|
|
|
```
|
|
|
|
|
|
再次回放,脚本就可以正常显示了。
|
|
|
|
|
|

|
|
|
|
|
|
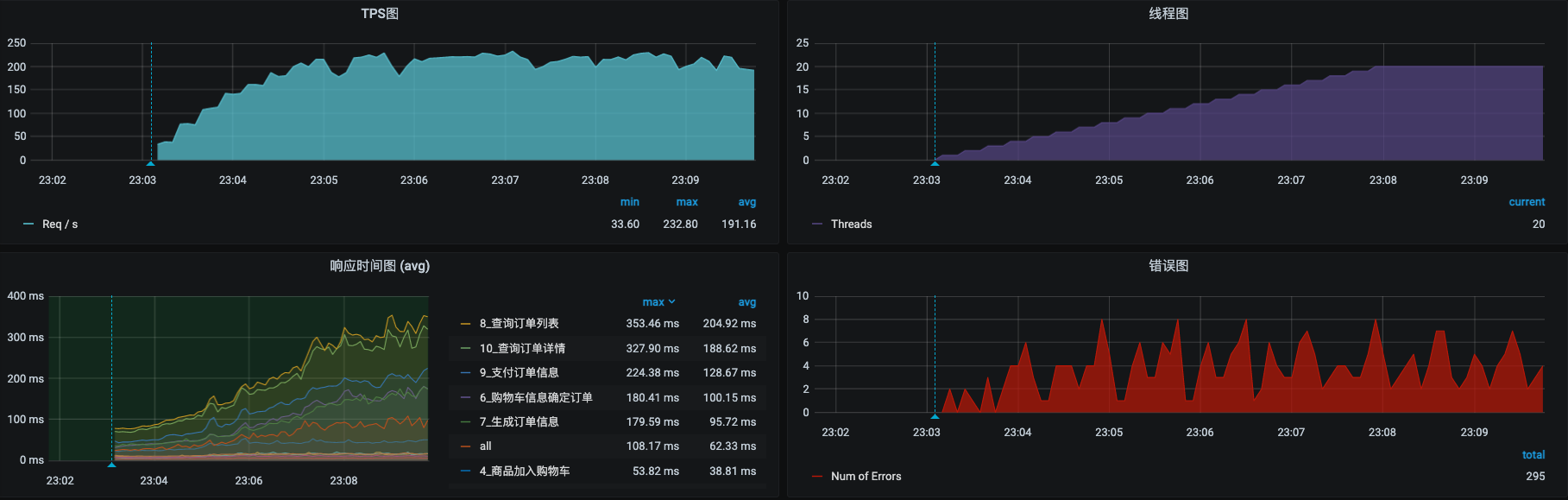
我们还是用不大的压力(20个线程)再把压力跑起来,压力数据变成了下面这个样子:
|
|
|
|
|
|
|
|
|
|
|
|
看起来好像还不错。虽然也有几个错误,但相比刚才已经少很多了。剩下的这些错误应该就是真正的业务错误了。不过我们现在先不管它。先看看资源使用率的情况。
|
|
|
|
|
|
### 全局监控分析
|
|
|
|
|
|

|
|
|
|
|
|
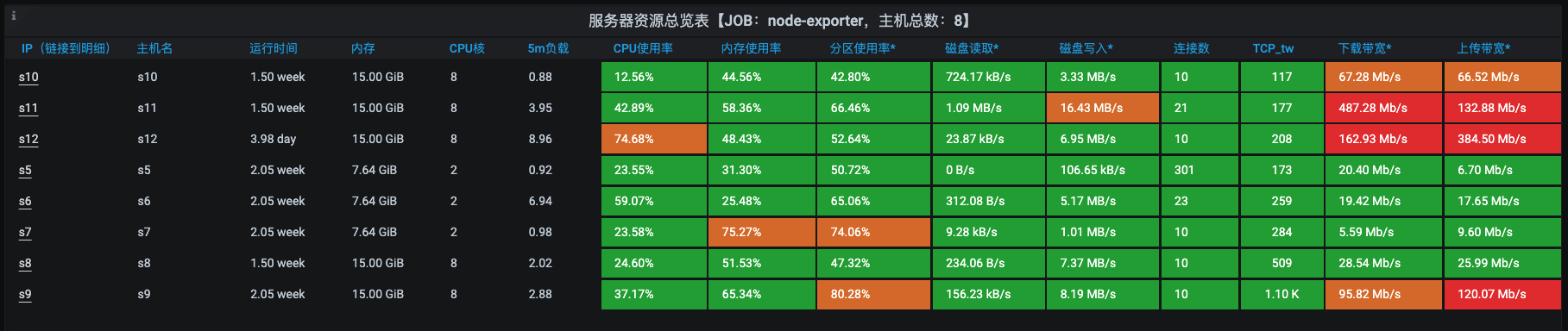
通过这张全局监控截图,我们比较欣喜地看到,终于有一个机器的CPU已经标红了。在这种情况下,再分析就是要走我们的RESAR性能分析七步法了,保证手到擒来。
|
|
|
|
|
|
下面我们进到CPU高的s12服务器,执行top。
|
|
|
|
|
|
```java
|
|
|
top - 23:14:44 up 3 days, 22:55, 1 user, load average: 14.43, 11.99, 8.53
|
|
|
Tasks: 193 total, 1 running, 192 sleeping, 0 stopped, 0 zombie
|
|
|
%Cpu0 : 76.4 us, 6.7 sy, 0.0 ni, 13.8 id, 0.3 wa, 0.0 hi, 2.7 si, 0.0 st
|
|
|
%Cpu1 : 71.4 us, 7.7 sy, 0.0 ni, 19.9 id, 0.3 wa, 0.0 hi, 0.7 si, 0.0 st
|
|
|
%Cpu2 : 76.5 us, 6.4 sy, 0.0 ni, 14.8 id, 1.0 wa, 0.0 hi, 1.3 si, 0.0 st
|
|
|
%Cpu3 : 79.9 us, 4.7 sy, 0.0 ni, 14.1 id, 0.7 wa, 0.0 hi, 0.7 si, 0.0 st
|
|
|
%Cpu4 : 85.6 us, 3.7 sy, 0.0 ni, 9.4 id, 0.3 wa, 0.0 hi, 1.0 si, 0.0 st
|
|
|
%Cpu5 : 81.4 us, 4.1 sy, 0.0 ni, 13.2 id, 1.0 wa, 0.0 hi, 0.3 si, 0.0 st
|
|
|
%Cpu6 : 87.6 us, 4.4 sy, 0.0 ni, 5.4 id, 0.7 wa, 0.0 hi, 2.0 si, 0.0 st
|
|
|
%Cpu7 : 85.2 us, 5.4 sy, 0.0 ni, 8.4 id, 0.7 wa, 0.0 hi, 0.3 si, 0.0 st
|
|
|
KiB Mem : 15731892 total, 1074660 free, 7042760 used, 7614472 buff/cache
|
|
|
KiB Swap: 0 total, 0 free, 0 used. 8349352 avail Mem
|
|
|
|
|
|
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
|
|
6515 27 20 0 3916212 325008 13304 S 547.0 2.1 715:56.39 /opt/rh/rh-mysql57/root/usr/libexec/mysqld --defaults-file=/etc/my.cnf
|
|
|
3868 root 20 0 9706460 804212 14332 S 61.3 5.1 113:43.58 java -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.port=1100 +
|
|
|
29812 1000 20 0 1942964 243780 9608 S 25.5 1.5 0:38.93 java -Xms512m -Xmx512m -Duser.timezone=Asia/Shanghai -Djava.io.tmpdir=/tmp -cp classes zipkin2.dependencies.ZipkinDependenciesJob
|
|
|
25306 nfsnobo+ 20 0 2599060 489856 51700 S 7.3 3.1 59:17.13 /bin/prometheus --config.file=/etc/prometheus/prometheus.yml --web.enable-lifecycle --storage.tsdb.path=/prometheus --storage.tsdb.retention.time=10d --web.console.libr+
|
|
|
1189 root 20 0 1275732 108700 30124 S 6.6 0.7 92:33.30 /usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock
|
|
|
1174 root 20 0 2271884 104784 36608 S 4.3 0.7 152:25.24 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubelet/config.yaml --network+
|
|
|
22095 root 10 -10 200708 33180 15344 S 2.0 0.2 6:42.03 /usr/local/aegis/aegis_client/aegis_11_17/AliYunDun
|
|
|
24216 1000 20 0 2068796 486356 13508 S 2.0 3.1 5:23.46 java -Xms512m -Xmx512m -Dlogging.level.zipkin=DEBUG -Dlogging.level.zipkin2=DEBUG -Duser.timezone=Asia/Shanghai -cp . -Dlog4j2.disable.jmx=true org.springframework.boot+
|
|
|
3850 root 20 0 109096 8148 2652 S 1.7 0.1 3:10.85 containerd-shim -namespace moby -workdir /var/lib/containerd/io.containerd.runtime.v1.linux/moby/0be4d32538621f4f99f2837f37f860c939fd9f3bf0faeb7b84c7da4ee0e38f68 -addre+ 3773 1000 20 0 7509920 3.4g 22540 S 0.7 22.6 30:48.27 /usr/share/elasticsearch/jdk/bin/java -Xshare:auto -Des.networkaddress.cache.ttl=60 -Des.networkaddress.cache.negative.ttl=10 -XX:+AlwaysPreTouch -Xss1m -Djava.awt.head+
|
|
|
1 root 20 0 44252 4672 2656 S 0.3 0.0 2:04.64 /usr/lib/systemd/systemd --switched-root --system --deserialize 22 6 root 20 0 0 0 0 S 0.3 0.0 0:30.63 [ksoftirqd/0]
|
|
|
414 root 20 0 149560 77504 77136 S 0.3 0.5 2:19.20 /usr/lib/systemd/systemd-journald
|
|
|
|
|
|
```
|
|
|
|
|
|
从top的数据来看,问题在于mysql消耗的CPU较高。
|
|
|
|
|
|
### 定向监控分析
|
|
|
|
|
|
在我的经验中,这种时候就可以直接到innodb\_trx里面蒙一把了,里面大概率是能看到慢日志的。我们在查询innodb\_trx表中的数据时要多查几次,如果同一事务ID持续了一段时间,那就是明显慢了。当然,如果你开启了慢日志,可以到慢日志里去查看。
|
|
|
|
|
|

|
|
|
|
|
|
果不其然,我在这里确实抓到了可能比较慢的SQL。我们取出它的执行计划看看。
|
|
|
|
|
|

|
|
|
|
|
|
因为ot表上是全表扫描,涉及到10万条数据,这数据太多了,又没走索引。我们执行语句,添加一个索引。
|
|
|
|
|
|
```java
|
|
|
alter table mall.oms_order_item add index index_order_id(order_id) ;
|
|
|
analyze table mall.oms_order_item;
|
|
|
|
|
|
```
|
|
|
|
|
|
再次查看执行计划看看区别:
|
|
|
|
|
|

|
|
|
|
|
|
这回,从rows那一列是不是看到了明显的变化?ot表相关的type也变成了我们添加的索引。这种问题,应该说是非常常见了。
|
|
|
|
|
|
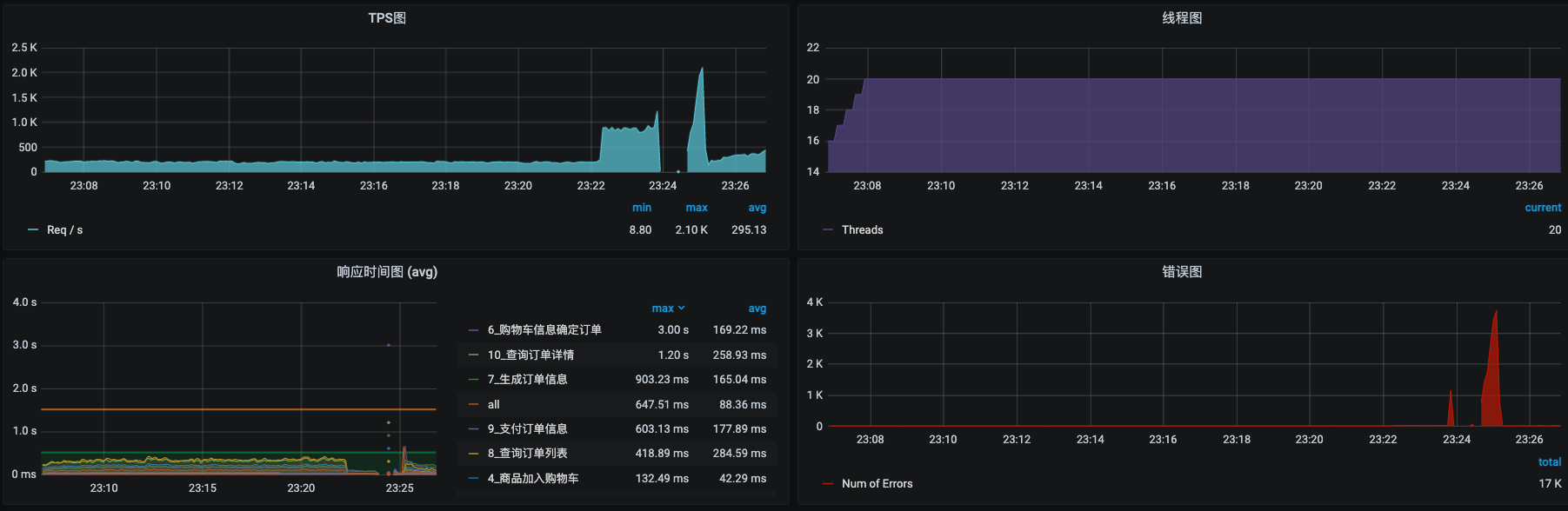
这时候我又刷新了几下innodb\_trx表,又找了几个走全表扫描的SQL。各自添加索引之后,我们再回去看一眼TPS:
|
|
|
|
|
|
|
|
|
|
|
|
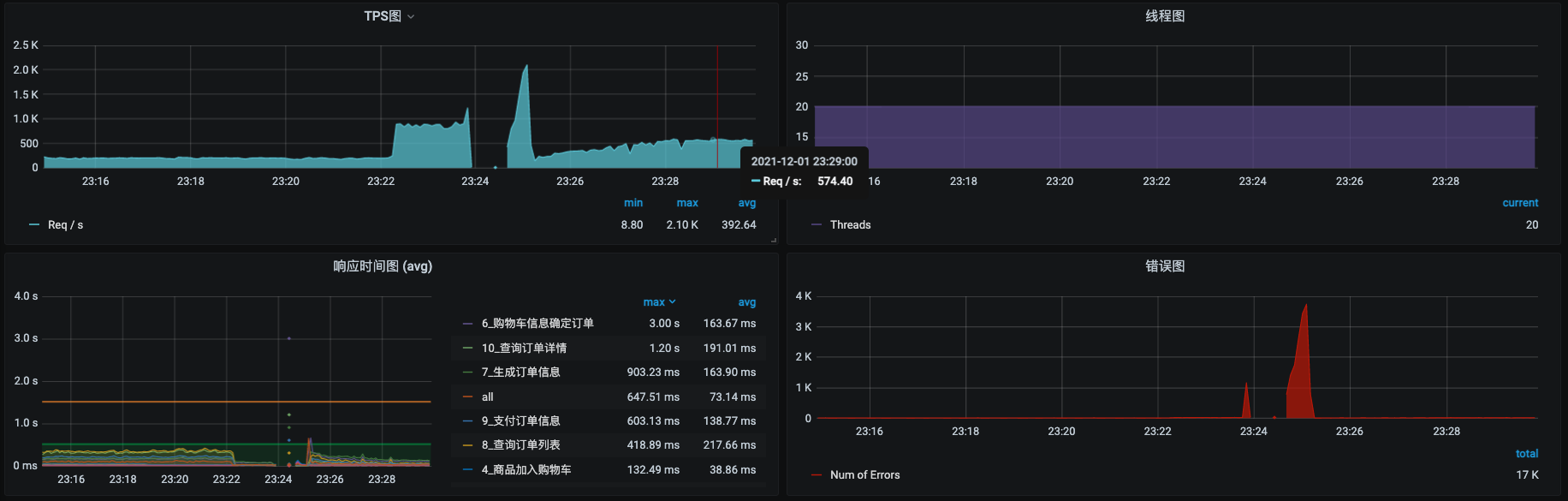
截图里这种情况就有点奇怪了呀。很显然在刚才改索引的时候,TPS是上去过的,你可以看一下23:24分之前的那一段,TPS曾经达到过800左右。但是中间却断了一会儿,这里应该是和我刚才执行的添加索引、分析表的SQL语句有关。我们再观察一会儿:
|
|
|
|
|
|
|
|
|
|
|
|
可以看到,报错之后压力并没有变化,但TPS是在逐渐恢复的。这是个好的方向。这时候我们再回来看看资源使用的情况:
|
|
|
|
|
|

|
|
|
|
|
|
还记得上面我们看到的是s12资源使用率多吗?现在已经转移到了s6身上了吧。这说明上一个问题已经解决,现在是个新问题了。
|
|
|
|
|
|
## 第二阶段
|
|
|
|
|
|
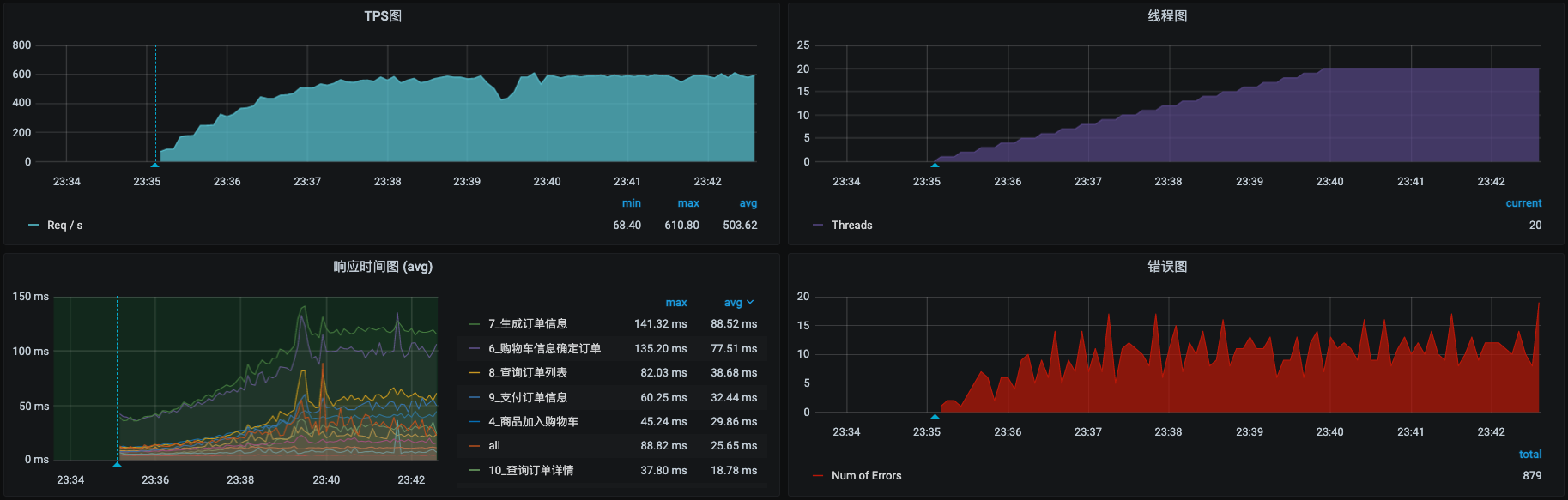
接下来我们再运行一段时间场景,看看还有啥问题。
|
|
|
|
|
|
|
|
|
|
|
|
这里还是有一些报错。我查了一下日志,发现是因为库存不足。
|
|
|
|
|
|
```java
|
|
|
2021-12-01 23:39:53.327 ERROR [mall-order,,,] 1 --- [io-8084-exec-18] o.a.c.c.C.[.[.[/].[dispatcherServlet] : Servlet.service() for servlet [dispatcherServlet] in context with path [] threw exception [Request processing failed; nested exception is com.dunshan.mall.common.exception.ApiException: 库存不足,无法下单] with root cause
|
|
|
|
|
|
com.dunshan.mall.common.exception.ApiException: 库存不足,无法下单
|
|
|
at com.dunshan.mall.common.exception.Asserts.fail(Asserts.java:11)
|
|
|
at com.dunshan.mall.order.service.impl.PortalOrderServiceImpl.generateOrder(PortalOrderServiceImpl.java:190)
|
|
|
at com.dunshan.mall.order.service.impl.PortalOrderServiceImpl$$FastClassBySpringCGLIB$$9b833cea.invoke(<generated>)
|
|
|
......................
|
|
|
|
|
|
```
|
|
|
|
|
|
业务的问题比较好处理,加上库存就行了。
|
|
|
|
|
|
从上面这张图我们也可以看到,TPS一直稳稳地在近600左右。
|
|
|
|
|
|
资源使用率方面呢,根据上面的全局监控,我们可以知道s6上的资源使用率过高。所以我们要登录到这台主机,看看是什么进程导致的。
|
|
|
|
|
|
```java
|
|
|
top - 23:45:54 up 14 days, 8:12, 2 users, load average: 18.57, 16.12, 11.52
|
|
|
Tasks: 126 total, 2 running, 124 sleeping, 0 stopped, 0 zombie
|
|
|
%Cpu0 : 70.9 us, 13.6 sy, 0.0 ni, 2.3 id, 0.0 wa, 0.0 hi, 13.2 si, 0.0 st
|
|
|
%Cpu1 : 71.1 us, 16.5 sy, 0.0 ni, 8.9 id, 0.3 wa, 0.0 hi, 3.1 si, 0.0 st
|
|
|
KiB Mem : 8008964 total, 173104 free, 2266508 used, 5569352 buff/cache
|
|
|
KiB Swap: 0 total, 0 free, 0 used. 5433884 avail Mem
|
|
|
|
|
|
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
|
|
31288 root 20 0 4624912 536084 12736 S 100.3 6.7 19:48.18 java -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.port=1100 +
|
|
|
7931 root 20 0 4637452 697772 12728 S 60.5 8.7 90:39.72 java -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.port=1100 +
|
|
|
1473 root 20 0 675600 94608 26768 S 16.6 1.2 540:03.39 /usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock
|
|
|
1894 root 20 0 1729636 90460 35948 S 2.3 1.1 618:52.03 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubelet/config.yaml --network+
|
|
|
21598 root 10 -10 197132 27972 15480 S 2.3 0.3 10:07.67 /usr/local/aegis/aegis_client/aegis_11_17/AliYunDun
|
|
|
31271 root 20 0 107688 3380 2556 S 2.3 0.0 0:27.37 containerd-shim -namespace moby -workdir /var/lib/containerd/io.containerd.runtime.v1.linux/moby/e15c7ab19edcf9e3e02a3a03f2f8c4dc80232b6af2795eb70f4c12b0dd821f11 -addre+
|
|
|
7913 root 20 0 109096 5620 2716 S 1.7 0.1 3:33.94 containerd-shim -namespace moby -workdir /var/lib/containerd/io.containerd.runtime.v1.linux/moby/4516faf8c4c2f8545e63224a793f60c17a21eee0ef5a4585cba2842063c78067 -addre+
|
|
|
9 root 20 0 0 0 0 R 0.3 0.0 11:05.99 [rcu_sched]
|
|
|
609 root 20 0 835660 26056 7852 S 0.3 0.3 58:34.33 CmsGoAgent-Worker start
|
|
|
2927 1000 20 0 141496 29604 12708 S 0.3 0.4 13:10.48 /metrics-server --cert-dir=/tmp --secure-port=4443 --kubelet-insecure-tls=true --kubelet-preferred-address-types=InternalIP,Hostname,InternalDNS,externalDNS
|
|
|
................
|
|
|
|
|
|
```
|
|
|
|
|
|
通过top中的process table,我们看到上面有两个Java的进程,由于名字太长看不全,不知道是什么具体的服务。这种情况是有多个服务跑在了一个2C的s6上。接下来,我们查看一下s6上有什么Pod:
|
|
|
|
|
|
```java
|
|
|
[root@s5 runMall]# kubectl get pods -n default -o wide | grep s6
|
|
|
kafka-1 1/1 Running 48 13d 10.100.1.3 s6 <none> <none>
|
|
|
node-exporter-rqgrx 1/1 Running 0 3d4h 172.31.184.226 s6 <none> <none>
|
|
|
svc-mall-cart-dd5db86d7-dcwdd 1/1 Running 0 3d23h 10.100.1.14 s6 <none> <none>
|
|
|
svc-mall-order-67cd58db5-ht5mb 1/1 Running 0 12m 10.100.1.15 s6 <none> <none>
|
|
|
[root@s5 runMall]#
|
|
|
|
|
|
```
|
|
|
|
|
|
果然,这里有两个服务,还都是重要的服务。对一个2C的虚拟机来说,能跑近600的TPS,我觉得已经挺好的了,不能再指望更高的TPS了。为了让TPS再高一些,我把Order服务移到s8上去,因为s8感觉没用上。
|
|
|
|
|
|
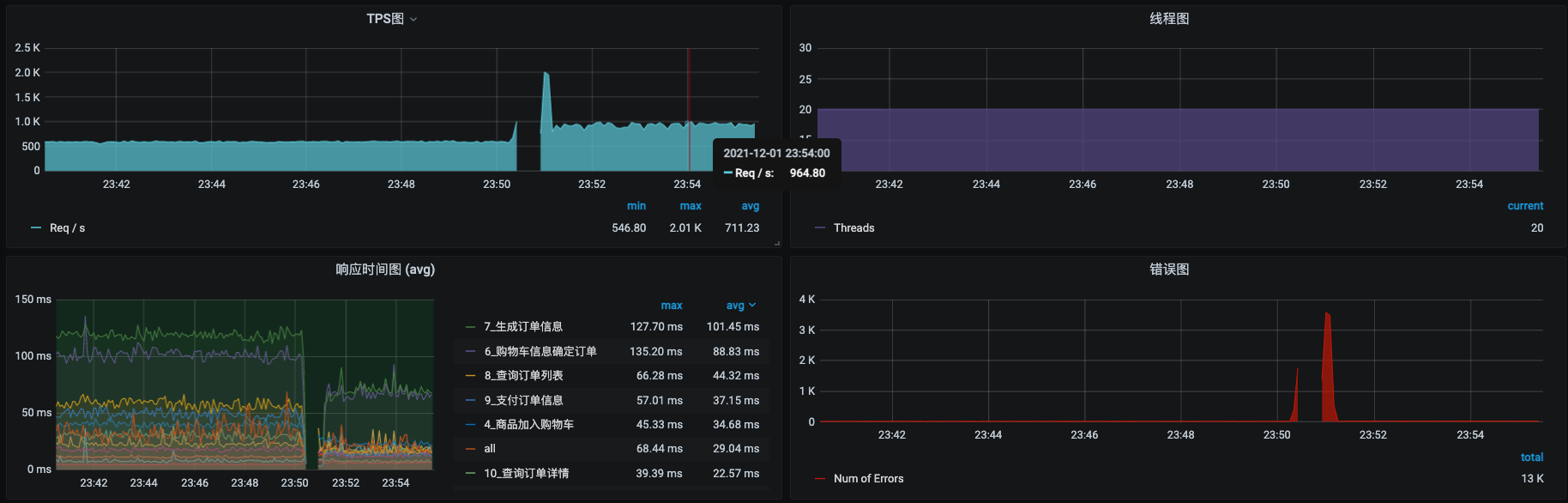
把Order服务从s6移到s8之后,再执行一会场景,查看压力数据:
|
|
|
|
|
|
|
|
|
|
|
|
看起来不错哦,TPS从600左右上升到了960左右。
|
|
|
|
|
|
接着我们再回来看一下全局监控数据:
|
|
|
|
|
|
|
|
|
|
|
|
资源使用率也比之前高了不少。
|
|
|
|
|
|
看起来,我们的系统已经要进入到正常的系统状态了,到这里,预压测也就可以结束了。下节课,我们就可以上更大一些的压力接着玩了。
|
|
|
|
|
|
## 总结
|
|
|
|
|
|
好了,这节课就讲到这里。刚才,我们对容量场景进行了预压测。
|
|
|
|
|
|
其实这个过程和正式的容量场景没有什么区别,只是压力线程少一点而已。预压测可以验证场景设置、参数化数据、网络环境、硬件环境等内容。它可以让我们在执行正式的场景的时候,不至于出现耗时的问题。像这节课讲的“索引”这种基础问题,就应该在预压测的时候就解决掉,不应该出现在大压力的场景之中。
|
|
|
|
|
|
在很多人的性能思路中,基准场景就是拿三五个压力线程运行一下,而预压测的过程则根本不存在。但是在我的RESAR性能工程的理念中,在真正模拟生产峰值的容量场景之前,是有必要加上预压测的部分的。预压测使用的是生产的业务模型,是混合的业务场景。预压测的存在可以给容量场景做好充分的铺垫。
|
|
|
|
|
|
## 课后题
|
|
|
|
|
|
学完这节课,请你思考两个问题:
|
|
|
|
|
|
1. 预压测是不是必须的呢?
|
|
|
2. 不做预压测会带来什么问题?
|
|
|
|
|
|
欢迎你在留言区与我交流讨论。当然了,你也可以把这节课分享给你身边的朋友,他们的一些想法或许会让你有更大的收获。我们下节课见!
|
|
|
|