237 lines
16 KiB
Markdown
237 lines
16 KiB
Markdown
# 答疑3 | 第13~18讲课后思考题答案及常见问题答疑
|
||
|
||
你好,我是蒋德钧。
|
||
|
||
今天这节课,我们继续来解答第13讲到第18讲的课后思考题。这些思考题除了涉及Redis自身的开发与实现机制外,还包含了多线程模型使用、系统调用优化等通用的开发知识,希望你能掌握这些扩展的通用知识,并把它们用在自己的开发工作中。
|
||
|
||
## [第13讲](https://time.geekbang.org/column/article/410666)
|
||
|
||
**问题:**Redis 多IO线程机制使用startThreadedIO函数和stopThreadedIO函数,来设置IO线程激活标识io\_threads\_active为1和为0。此处,这两个函数还会对线程互斥锁数组进行解锁和加锁操作,如下所示。那么,你知道为什么这两个函数要执行解锁和加锁操作吗?
|
||
|
||
```plain
|
||
void startThreadedIO(void) {
|
||
...
|
||
for (int j = 1; j < server.io_threads_num; j++)
|
||
pthread_mutex_unlock(&io_threads_mutex[j]); //给互斥锁数组中每个线程对应的互斥锁做解锁操作
|
||
server.io_threads_active = 1;
|
||
}
|
||
|
||
void stopThreadedIO(void) {
|
||
...
|
||
for (int j = 1; j < server.io_threads_num; j++)
|
||
pthread_mutex_lock(&io_threads_mutex[j]); //给互斥锁数组中每个线程对应的互斥锁做加锁操作
|
||
server.io_threads_active = 0;
|
||
}
|
||
|
||
```
|
||
|
||
我设计这道题的目的,主要是希望你可以了解多线程运行时,如何通过互斥锁来控制线程运行状态的变化。这里我们就来看下线程在运行过程中,是如何使用互斥锁的。通过了解这个过程,你就能知道题目中提到的解锁和加锁操作的目的了。
|
||
|
||
首先,在初始化和启动多IO线程的**initThreadedIO函数**中,主线程会先获取每个IO线程对应的互斥锁。然后,主线程会创建IO线程。当每个IO线程启动后,就会运行IOThreadMain函数,如下所示:
|
||
|
||
```plain
|
||
void initThreadedIO(void) {
|
||
…
|
||
for (int i = 0; i < server.io_threads_num; i++) {
|
||
…
|
||
pthread_mutex_init(&io_threads_mutex[i],NULL);
|
||
io_threads_pending[i] = 0;
|
||
pthread_mutex_lock(&io_threads_mutex[i]); //主线程获取每个IO线程的互斥锁
|
||
if (pthread_create(&tid,NULL,IOThreadMain,(void*)(long)i) != 0) {…} //启动IO线程,线程运行IOThreadMain函数
|
||
…} …}
|
||
|
||
```
|
||
|
||
而IOThreadMain函数会一直执行一个**while(1)**的循环流程。在这个流程中,线程又会先执行一个100万次的循环,而在这个循环中,线程会一直检查有没有待处理的任务,这些任务的数量是用**io\_threads\_pending数组**保存的。
|
||
在这个100万次的循环中,一旦线程检查到有待处理任务,也就是io\_threads\_pending数组中和当前线程对应的元素值不为0,那么线程就会跳出这个循环,并根据任务类型进行实际的处理。
|
||
|
||
下面的代码展示了这部分的逻辑,你可以看下。
|
||
|
||
```plain
|
||
void *IOThreadMain(void *myid) {
|
||
…
|
||
while(1) {
|
||
//循环100万次,每次检查有没有待处理的任务
|
||
for (int j = 0; j < 1000000; j++) {
|
||
if (io_threads_pending[id] != 0) break; //如果有任务就跳出循环
|
||
}
|
||
… //从io_threads_lis中取出待处理任务,根据任务类型,调用相应函数进行处理
|
||
}
|
||
…}
|
||
|
||
```
|
||
|
||
而如果线程执行了100万次循环后,仍然没有任务处理。那么,它就会**调用pthread\_mutex\_lock函数**去获取它对应的互斥锁。但是,就像我刚才给你介绍的,在initThreadedIO函数中,主线程已经获得了IO线程的互斥锁了。所以,在IOThreadedMain函数中,线程会因为无法获得互斥锁,而进入等待状态。此时,线程不会消耗CPU。
|
||
|
||
与此同时,主线程在进入事件驱动框架的循环前,会**调用beforeSleep函数**,在这个函数中,主线程会进一步调用handleClientsWithPendingWritesUsingThreads函数,来给IO线程分配待写客户端。
|
||
|
||
那么,在handleClientsWithPendingWritesUsingThreads函数中,如果主线程发现IO线程没有被激活的话,它就会**调用startThreadedIO函数**。
|
||
|
||
好了,到这里,startThreadedIO函数就开始执行了。这个函数中会依次调用pthread\_mutex\_unlock函数,给每个线程对应的锁进行解锁操作。这里,你需要注意的是,startThreadedIO是在主线程中执行的,而每个IO线程的互斥锁也是在IO线程初始化时,由主线程获取的。
|
||
|
||
所以,主线程可以调用pthread\_mutex\_unlock函数来释放每个线程的互斥锁。
|
||
|
||
一旦主线程释放了线程的互斥锁,那么IO线程执行的IOThreadedMain函数,就能获得对应的互斥锁。紧接着,IOThreadedMain函数又会释放释放互斥锁,并继续执行while(1),如下所示:
|
||
|
||
```plain
|
||
void *IOThreadMain(void *myid) {
|
||
…
|
||
while(1) {
|
||
…
|
||
if (io_threads_pending[id] == 0) {
|
||
pthread_mutex_lock(&io_threads_mutex[id]); //获得互斥锁
|
||
pthread_mutex_unlock(&io_threads_mutex[id]); //释放互斥锁
|
||
continue;
|
||
}
|
||
…} …}
|
||
|
||
```
|
||
|
||
那么,这里就是解答第13讲课后思考题的关键所在了。
|
||
在IO线程释放了互斥锁后,主线程可能正好在执行handleClientsWithPendingWritesUsingThreads函数,这个函数中除了刚才介绍的,会根据IO线程是否激活来启动IO线程之外,它也会**调用stopThreadedIOIfNeeded函数,来判断是否需要暂停IO线程**。
|
||
|
||
stopThreadedIOIfNeeded函数一旦发现待处理任务数,不足IO线程数的2倍,它就会调用stopThreadedIO函数来暂停IO线程。
|
||
|
||
**而暂停IO线程的办法,就是让主线程获得线程的互斥锁。**所以,stopThreadedIO函数就会依次调用pthread\_mutex\_lock函数,来获取每个IO线程对应的互斥锁。刚才我们介绍的IOThreadedMain函数在获得互斥锁后,紧接着就释放互斥锁,其实就是希望主线程执行的stopThreadedIO函数,能在IO线程释放锁后的这个时机中,获得线程的互斥锁。
|
||
|
||
这样一来,因为IO线程执行IOThreadedMain函数时,会一直运行while(1)循环,并且一旦判断当前待处理任务为0时,它会去获取互斥锁。而此时,如果主线程已经拿到锁了,那么IO线程就只能进入等待状态了,这就相当于暂停了IO线程。
|
||
|
||
这里,你还需要注意的一点是,**stopThreadedIO函数还会把表示当前IO线程激活的标记io\_threads\_active设为0**,这样一来,主线程的handleClientsWithPendingWritesUsingThreads函数在执行时,又会根据这个标记来再次调用startThreadedIO启用IO线程。而就像刚才我们提到的,startThreadedIO函数会释放主线程拿的锁,让IO线程从等待状态进入运行状态。
|
||
|
||
关于这道题,不少同学都提到了,题目中所说的加解锁操作是为了控制IO线程的启停,而且像是@土豆种南城同学,还特别强调了IOThreadedMain函数中执行的100万次循环的作用。
|
||
|
||
因为这个题目涉及的锁操作在好几个函数间轮流执行,所以,我刚才也是把这个过程的整体流程给你做了解释。下面我也画了一张图,展示了主线程通过加解锁控制IO线程启停的基本过程,你可以再整体回顾下。
|
||
|
||
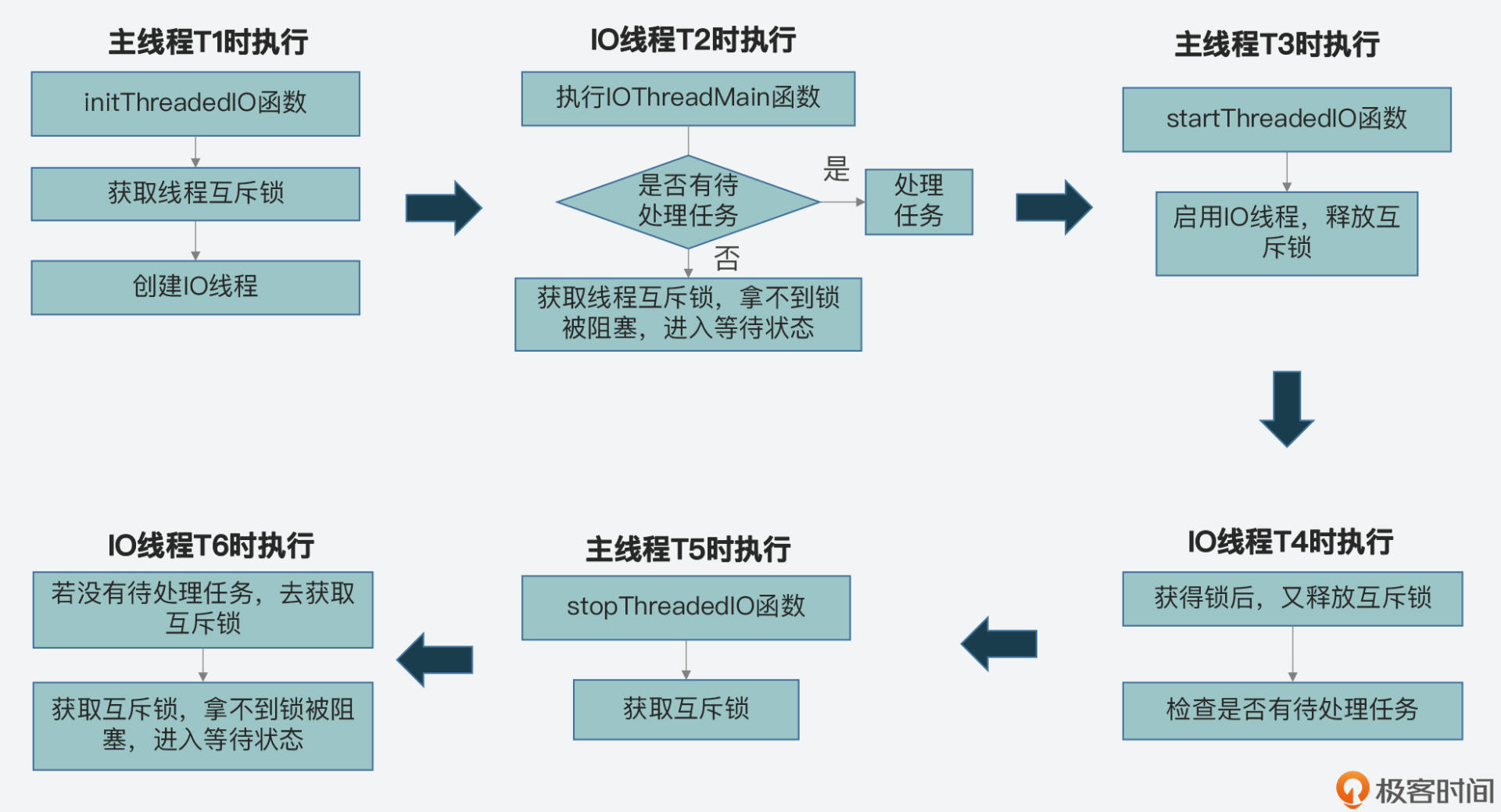
|
||
|
||
## [第14讲](https://time.geekbang.org/column/article/411558)
|
||
|
||
**问题:**如果我们将命令处理过程中的命令执行也交给多IO线程执行,你觉得除了对原子性有影响,会有什么好处或其他不足的影响吗?
|
||
|
||
这道题主要是希望你能对多线程执行模型的优势和不足,有进一步的思考。
|
||
|
||
其实,使用多IO线程执行命令的好处很直接,就是可以充分利用CPU的多核资源,让每个核上的IO线程并行处理命令,从而提升整体的吞吐率。
|
||
|
||
但是,这里你要注意的是,如果多个命令执行时要对同一个数据结构进行写操作,那么,此时也就是多个线程要并发写某个数据结构。为了保证操作正确性,我们就需要使用**互斥方法**,比如加锁,来提供并发控制。
|
||
|
||
这实际上是使用多IO线程时的不足,它会带来两个影响:一个是基于加锁等互斥操作的并发控制,会降低系统整体性能;二个是多线程并发控制的开发与调试比较难,会增加开发者的负担。
|
||
|
||
## [第15讲](https://time.geekbang.org/column/article/412164)
|
||
|
||
**问题:**Redis源码中提供了getLRUClock函数来计算全局LRU时钟值,同时键值对的LRU时钟值是通过LRU\_CLOCK函数来获取的,以下代码也展示了LRU\_CLOCK函数的执行逻辑,这个函数包括了两个分支,一个分支是直接从全局变量server的lruclock中获取全局时钟值,另一个是调用getLRUClock函数获取全局时钟值。
|
||
|
||
那么你知道,为什么键值对的LRU时钟值,不直接通过调用getLRUClock函数来获取呢?
|
||
|
||
```plain
|
||
unsigned int LRU_CLOCK(void) {
|
||
unsigned int lruclock;
|
||
if (1000/server.hz <= LRU_CLOCK_RESOLUTION) {
|
||
atomicGet(server.lruclock,lruclock);
|
||
} else {
|
||
lruclock = getLRUClock();
|
||
}
|
||
return lruclock;
|
||
}
|
||
|
||
```
|
||
|
||
这道题有不少同学都给出了正确答案,比如@可怜大灰狼、@Kaito、@曾轼麟等等。这里我来总结下。
|
||
|
||
其实,调用getLRUClock函数获取全局时钟值,它最终会调用**gettimeofday**这个系统调用来获取时间。而系统调用会触发用户态和内核态的切换,会带来微秒级别的开销。
|
||
|
||
而对于Redis来说,它的吞吐率是每秒几万QPS,所以频繁地执行系统调用,这里面带来的微秒级开销有些大。所以,**Redis只是以固定频率调用getLRUClock函数**,使用系统调用获取全局时钟值,然后将该时钟值赋值给全局变量server.lruclock。当要获取时钟时,直接从全局变量中获取就行,节省了系统调用的开销。
|
||
|
||
刚才介绍的这种实现方法,在系统的性能优化过程中是有不错的参考价值的,你可以重点掌握下。
|
||
|
||
## [第16讲](https://time.geekbang.org/column/article/413038)
|
||
|
||
**问题:**LFU算法在初始化键值对的访问次数时,会将访问次数设置为LFU\_INIT\_VAL,它的默认值是5次。那么,你能结合这节课介绍的代码,说说如果LFU\_INIT\_VAL设置为1,会发生什么情况吗?
|
||
|
||
这道题目主要是希望你能理解LFU算法实现时,对键值对访问次数的增加和衰减操作。**LFU\_INIT\_VAL会在LFULogIncr函数中使用**,如下所示:
|
||
|
||
```plain
|
||
uint8_t LFULogIncr(uint8_t counter) {
|
||
…
|
||
double r = (double)rand()/RAND_MAX;
|
||
double baseval = counter - LFU_INIT_VAL;
|
||
if (baseval < 0) baseval = 0;
|
||
double p = 1.0/(baseval*server.lfu_log_factor+1);
|
||
if (r < p) counter++;
|
||
…}
|
||
|
||
```
|
||
|
||
从代码中可以看到,如果LFU\_INIT\_VAL比较小,那么baseval值会比较大,这就导致p值比较小,那么counter++操作的机会概率就会变小,这也就是说,键值对访问次数counter不容易增加。
|
||
|
||
而另一方面,**LFU算法在执行时,会调用LFUDecrAndReturn函数**,对键值对访问次数counter进行衰减操作。counter值越小,就越容易被衰减后淘汰掉。所以,如果LFU\_INIT\_VAL值设置为1,就容易导致刚刚写入缓存的键值对很快被淘汰掉。
|
||
|
||
因此,为了避免这个问题,LFU\_INIT\_VAL值就要设置的大一些。
|
||
|
||
## [第17讲](https://time.geekbang.org/column/article/413997)
|
||
|
||
**问题:**freeMemoryIfNeeded函数在使用后台线程删除被淘汰数据的时候,你觉得在这个过程中,主线程仍然可以处理外部请求吗?
|
||
|
||
这道题像@Kaito等不少同学都给出了正确答案,我在这里总结下,也给你分享一下我的思考过程。
|
||
|
||
Redis主线程在执行freeMemoryIfNeeded函数时,这个函数确定了淘汰某个key 之后,会先把这个key从全局哈希表中删除。然后,这个函数会在dbAsyncDelete函数中,**调用lazyfreeGetFreeEffort函数,评估释放内存的代价。**
|
||
|
||
这个代价的计算,主要考虑的是要释放的键值对是集合时,集合中的元素数量。如果要释放的元素过多,主线程就会在后台线程中执行释放内存操作。此时,主线程就可以继续正常处理客户端请求了。而且因为被淘汰的key已从全局哈希表中删除,所以客户端也查询不到这个key了,不影响客户端正常操作。
|
||
|
||
## [第18讲](https://time.geekbang.org/column/article/415563)
|
||
|
||
**问题:**你能在serverCron函数中,查找到rdbSaveBackground函数一共会被调用执行几次么?这又分别对应了什么场景呢?
|
||
|
||
这道题,我们通过在serverCron函数中查找**rdbSaveBackground函数**,就可以知道它被调用执行了几次。@曾轼麟同学做了比较详细的查找,我整理了下他的答案,分享给你。
|
||
|
||
首先,在serverCron 函数中,它会直接调用rdbSaveBackground两次。
|
||
|
||
**第一次直接调用**是在满足RDB生成的条件时,也就是修改的键值对数量和距离上次生成RDB的时间满足配置阈值时,serverCron函数会调用rdbSaveBackground函数,创建子进程生成RDB,如下所示:
|
||
|
||
```plain
|
||
if (server.dirty >= sp->changes && server.unixtime-server.lastsave > sp->seconds &&
|
||
(server.unixtime-server.lastbgsave_try> CONFIG_BGSAVE_RETRY_DELAY
|
||
|| server.lastbgsave_status == C_OK)) {
|
||
…
|
||
rdbSaveBackground(server.rdb_filename,rsiptr);
|
||
…}
|
||
|
||
```
|
||
|
||
**第二次直接调用**是在客户端执行了BGSAVE命令后,Redis设置了rdb\_bgsave\_scheduled等于1,此时,serverCron函数会检查这个变量值以及当前RDB子进程是否运行。
|
||
|
||
如果子进程没有运行的话,那么serverCron函数就调用rdbSaveBackground函数,生成RDB,如下所示:
|
||
|
||
```plain
|
||
if (!hasActiveChildProcess() && server.rdb_bgsave_scheduled &&
|
||
(server.unixtime-server.lastbgsave_try > CONFIG_BGSAVE_RETRY_DELAY ||
|
||
server.lastbgsave_status == C_OK)) {
|
||
…
|
||
if (rdbSaveBackground(server.rdb_filename,rsiptr) == C_OK)
|
||
…}
|
||
|
||
```
|
||
|
||
而除了刚才介绍的两次直接调用以外,在serverCron函数中,还会有两次对rdbSaveBackground的**间接调用**。
|
||
|
||
一次间接调用是通过replicationCron -> startBgsaveForReplication -> rdbSaveBackground这个调用关系,来间接调用rdbSaveBackground函数,为主从复制定时任务生成RDB文件。
|
||
|
||
另一次间接调用是通过checkChildrenDone –> backgroundSaveDoneHandler -> backgroundSaveDoneHandlerDisk -> updateSlavesWaitingBgsave -> startBgsaveForReplication -> rdbSaveBackground这个调用关系,来生成RDB文件的。而这个调用主要是考虑到在主从复制过程中,有些从节点在等待当前的RDB生成过程结束,因此在当前的RDB子进程结束后,这个调用为这些等待的从节点新调度启动一次RDB子进程。
|
||
|
||
## 小结
|
||
|
||
好了,今天这节课就到这里了。我来总结下。
|
||
|
||
在今天的课程上,我给你解答了第13讲到第18讲的课后思考题。在这其中,我觉得有两个内容是你需要重点掌握的。
|
||
|
||
**一个是你要了解系统调用的开销**。从绝对值上来看,系统调用开销并不高,但是对于像Redis这样追求高性能的系统来说,每一处值得优化的地方都要仔细考虑。避免额外的系统开销,就是高性能系统开发的一个重要设计指导原则。
|
||
|
||
**另一个是多IO线程模型的使用**。我们通过思考题,了解了Redis会通过线程互斥锁,来实现对线程运行和等待状态的控制,以及多线程的优点和不足。现在的服务器硬件都是多核CPU,所以多线程模型也被广泛使用,用好多线程模型可以帮助我们实现系统性能的提升。
|
||
|
||
所以在最后,我也再给你关于多线程模型开发的三个小建议:
|
||
|
||
* 尽量减少共享数据结构的使用,比如采用key partition的方法,让每个线程负责一部分key的访问,这样可以减少并发访问的冲突。当然,如果要做范围查询,程序仍然需要访问多个线程负责的key。
|
||
* 对共享数据结构进行优化,尽量采用原子操作来减少并发控制的开销。
|
||
* 将线程和CPU核绑定,减少线程在不同核上调度时带来的切换开销。
|
||
|
||
欢迎继续给我留言,分享你在学习课程时的思考。
|
||
|