|
|
# 答疑2 | 第7~12讲课后思考题答案及常见问题答疑
|
|
|
|
|
|
你好,我是蒋德钧。
|
|
|
|
|
|
在今天的答疑中,我除了会解答课程之前的思考题以外,还会带你再进一步了解和数据结构设计、进程管理、高性能线程模型、IO复用、预定义宏等相关的开发知识。希望你能通过这节课的答疑,进一步扩展你的知识面。
|
|
|
|
|
|
## [第7讲](https://time.geekbang.org/column/article/406284)
|
|
|
|
|
|
**问题:作为有序索引,Radix Tree也能提供范围查询,那么与我们日常使用的B+树,以及**[第5讲](https://time.geekbang.org/column/article/404391)**中介绍的跳表相比,你觉得Radix Tree有什么优势和不足吗?**
|
|
|
|
|
|
对于这道题,有不少同学比如@Kaito、@曾轼麟等同学,都对Radix Tree、B+树和跳表做了对比,这里我就来总结一下。
|
|
|
|
|
|
**Radix Tree的优势**
|
|
|
|
|
|
* 因为Radix Tree是前缀树,所以,当保存数据的key具有相同前缀时,Radix Tree会在不同的key间共享这些前缀,这样一来,和B+树、跳表相比,就节省内存空间。
|
|
|
* Radix Tree在查询单个key时,其查询复杂度O(K)只和key的长度k有关,和现存的总数据量无关。而B+树、跳表的查询复杂度和数据规模有关,所以Radix Tree查询单个key的效率要高于B+树、跳表。
|
|
|
* Radix Tree适合保存大量具有相同前缀的数据。比如一个典型场景,就是Linux内核中的page cache,使用了Radix Tree保存文件内部偏移位置和缓存页的对应关系,其中树上的key就是文件中的偏移值。
|
|
|
|
|
|
**Radix Tree的不足**
|
|
|
|
|
|
* 一般在实现Radix Tree时,每个叶子节点就保存一个key,它的范围查询性能没有B+树和跳表好。这是因为B+树,它的叶子节点可以保存多个key,而对于跳表来说,它可以遍历有序链表。因此,它们可以更快地支持范围查询。
|
|
|
* Radix Tree的原理较为复杂,实现复杂度要高于B+ 树和跳表。
|
|
|
|
|
|
## [第8讲](https://time.geekbang.org/column/article/406556)
|
|
|
|
|
|
**问题:****Redis源码的main函数在调用initServer函数之前,会执行如下的代码片段,你知道这个代码片段的作用是什么吗?**
|
|
|
|
|
|
```plain
|
|
|
int main(int argc, char **argv) {
|
|
|
...
|
|
|
server.supervised = redisIsSupervised(server.supervised_mode);
|
|
|
int background = server.daemonize && !server.supervised;
|
|
|
if (background) daemonize();
|
|
|
...
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
这段代码的目的呢,是先检查Redis是否设置成让upstart或systemd这样的系统管理工具,来启停Redis。这是由**redisIsSupervised函数**,来检查redis.conf配置文件中的supervised选项,而supervised选项的可用配置值,包括no、upstart、systemd、auto,其中no就表示不用系统管理工具来启停Redis,其他选项会用系统管理工具。
|
|
|
|
|
|
而如果Redis没有设置用系统管理工具,同时又设置了使用守护进程方式(对应配置项daemonize=yes,server.daemonize值为1),那么,这段代码就调用**daemonize函数**以守护进程的方式,启动Redis。
|
|
|
|
|
|
## [第9讲](https://time.geekbang.org/column/article/407901)
|
|
|
|
|
|
**问题:****在Redis事件驱动框架代码中,分别使用了Linux系统上的select和epoll两种机制,****你知道为什么****Redis没有使用poll这一机制吗?**
|
|
|
|
|
|
这道题呢,主要是希望你对select和poll这两个IO多路复用机制,有进一步的了解。课程的留言区中有不少同学也都回答正确了,我在这里说下我的答案。
|
|
|
|
|
|
select机制的本质,是**阻塞式监听存放文件描述符的集合**,当监测到有描述符就绪时,select会结束监测返回就绪的描述符个数。而select机制的不足有两个:一是它对单个进程能监听的描述符数量是有限制的,默认是1024个;二是即使select监测到有文件描述符就绪,程序还是需要线性扫描描述符集合,才能知道具体是哪些文件描述符就绪了。
|
|
|
|
|
|
而poll机制相比于select机制,本质其实没有太大区别,它只是把select机制中文件描述符数量的限制给取消了,允许进程一次监听超过1024个描述符。**在线性扫描描述符集合获得就绪的具体描述符这个操作上,poll并没有优化改进。**所以,poll相比select改进比较有限。而且,就像@可怜大灰狼、@Kaito等同学提到的,select机制的兼容性好,可以在Linux和Windows上使用。
|
|
|
|
|
|
也正是因为poll机制改进有限,而且它对运行平台的支持度不及select,所以Redis的事件驱动框架就没有使用poll机制。在Linux上,事件驱动框架直接使用了epoll,而在Windows上,框架则使用的是select。
|
|
|
|
|
|
不过,这里你也要注意的是,Redis的ae.c文件实现了**aeWait函数**,这个函数实际会使用poll机制来监测文件描述符。而aeWait函数会被rewriteAppendOnlyFile函数(在aof.c文件中)和migrateGetSocket函数(在cluster.c文件中)调用。@可怜大灰狼同学在回答思考题时,就提到了这一点。
|
|
|
|
|
|
此外,在解答这道题的时候,@Darren、@陌等同学还进一步回答了epoll机制的实现细节,我在这里也简单总结下他们的答案,分享给你。
|
|
|
|
|
|
当某进程调用epoll\_create方法时,Linux内核会创建一个eventpoll结构体,这个结构体中包含了一个红黑树rbr和一个双链表rdlist,如下所示:
|
|
|
|
|
|
```plain
|
|
|
struct eventpoll{
|
|
|
//红黑树的根节点,树中存放着所有添加到epoll中需要监控的描述符
|
|
|
struct rb_root rbr;
|
|
|
//双链表中存放着已经就绪的描述符,会通过epoll_wait返回给调用程序
|
|
|
struct list_head rdlist;
|
|
|
...
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
epoll\_create创建了eventpoll结构体后,程序调用epoll\_ctl函数,添加要监听的文件描述符时,这些描述符会被保存在红黑树上。
|
|
|
同时,当有描述符上有事件发生时,一个名为ep\_poll\_callback的函数会被调用。这个函数会把就绪的描述符添加到rdllist链表中。而epoll\_wait函数,会检查rdlist链表中是否有描述符添加进来。如果rdlist链表不为空,那么epoll\_wait函数,就会把就绪的描述符返回给调用程序了。
|
|
|
|
|
|
## [第10讲](https://time.geekbang.org/column/article/408491)
|
|
|
|
|
|
**问题:这节课我们学习了Reactor模型,除了Redis,你还了解什么软件系统使用了Reactor模型吗?**
|
|
|
|
|
|
对于这道题,不少同学都给出了使用Reactor模型的其他软件系统,比如@Darren、@Kaito、@曾轼麟、@结冰的水滴等同学。那么,使用Reator模型的常见软件系统,实际上还包括Netty、Nginx、Memcached、Kafka等等。
|
|
|
|
|
|
在解答这道题的时候,我看到@Darren同学做了很好的扩展,回答了Reactor模型的三种类型。在这里,我也总结下分享给你。
|
|
|
|
|
|
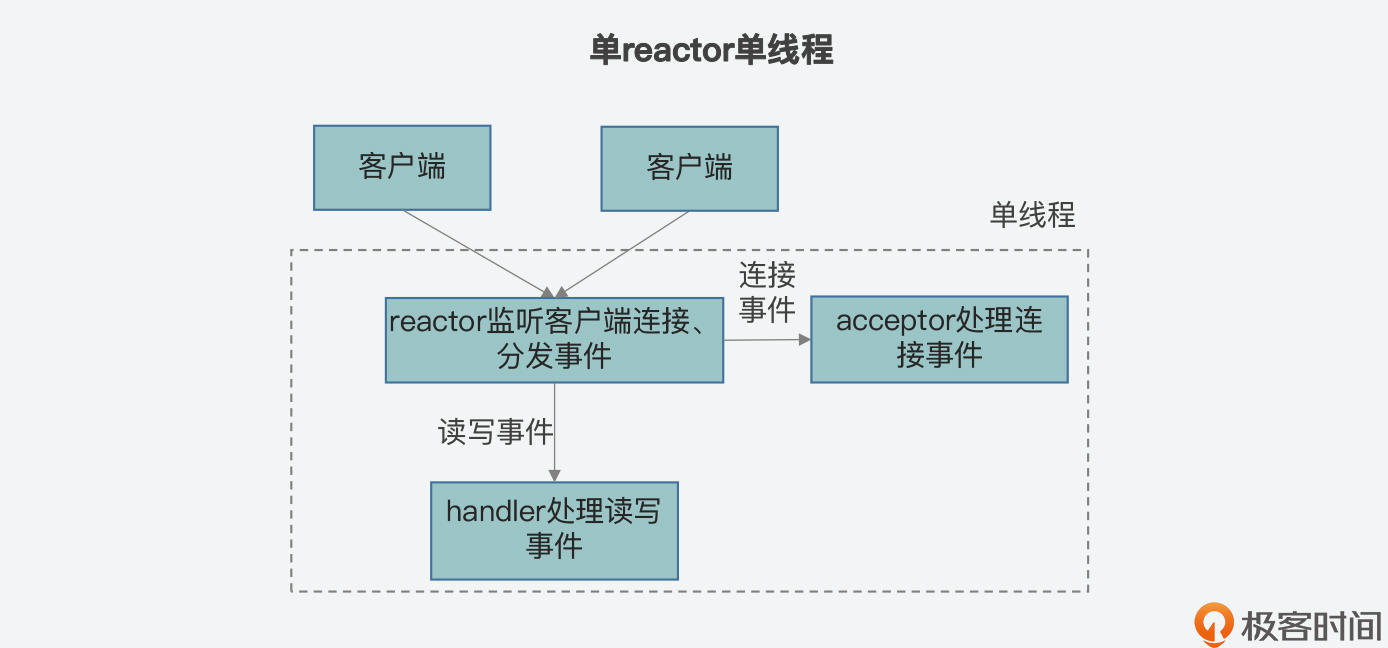
* **类型一:单reactor单线程**
|
|
|
|
|
|
在这个类型中,Reactor模型中的reactor、acceptor和handler的功能都是由一个线程来执行的。reactor负责监听客户端事件,一旦有连接事件发生,它会分发给acceptor,由acceptor负责建立连接,然后创建一个handler,负责处理连接建立后的事件。如果是有非连接的读写事件发生,reactor将事件分发给handler进行处理。handler负责读取客户端请求,进行业务处理,并最终给客户端返回结果。Redis就是典型的单reactor单线程类型。
|
|
|
|
|
|
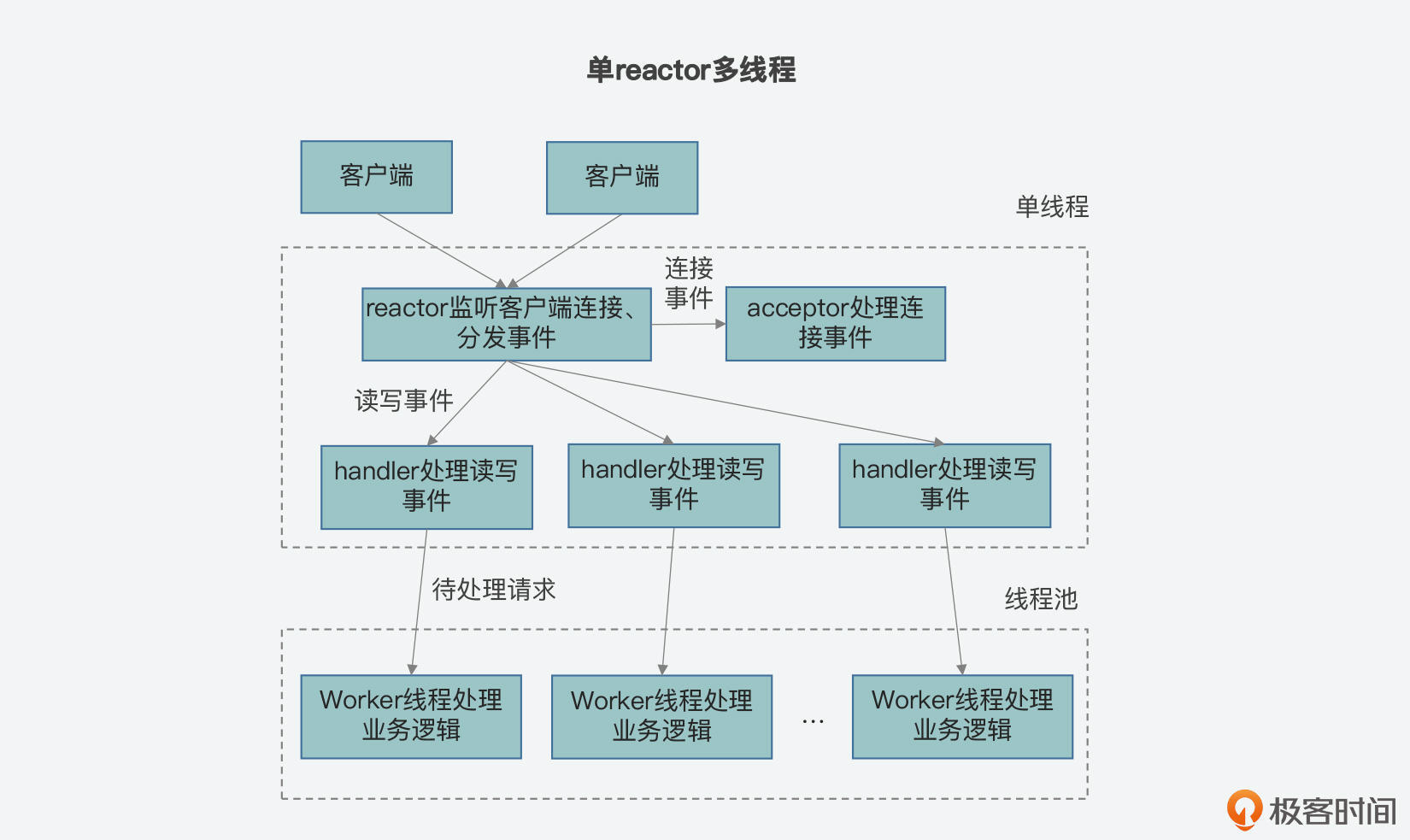
* **类型二:单reactor多线程**
|
|
|
|
|
|
在这个类型中,reactor、acceptor和handler的功能由一个线程来执行,与此同时,会有一个线程池,由若干worker线程组成。在监听客户端事件、连接事件处理方面,这个类型和单rector单线程是相同的,但是不同之处在于,在单reactor多线程类型中,handler只负责读取请求和写回结果,而具体的业务处理由worker线程来完成。
|
|
|
|
|
|
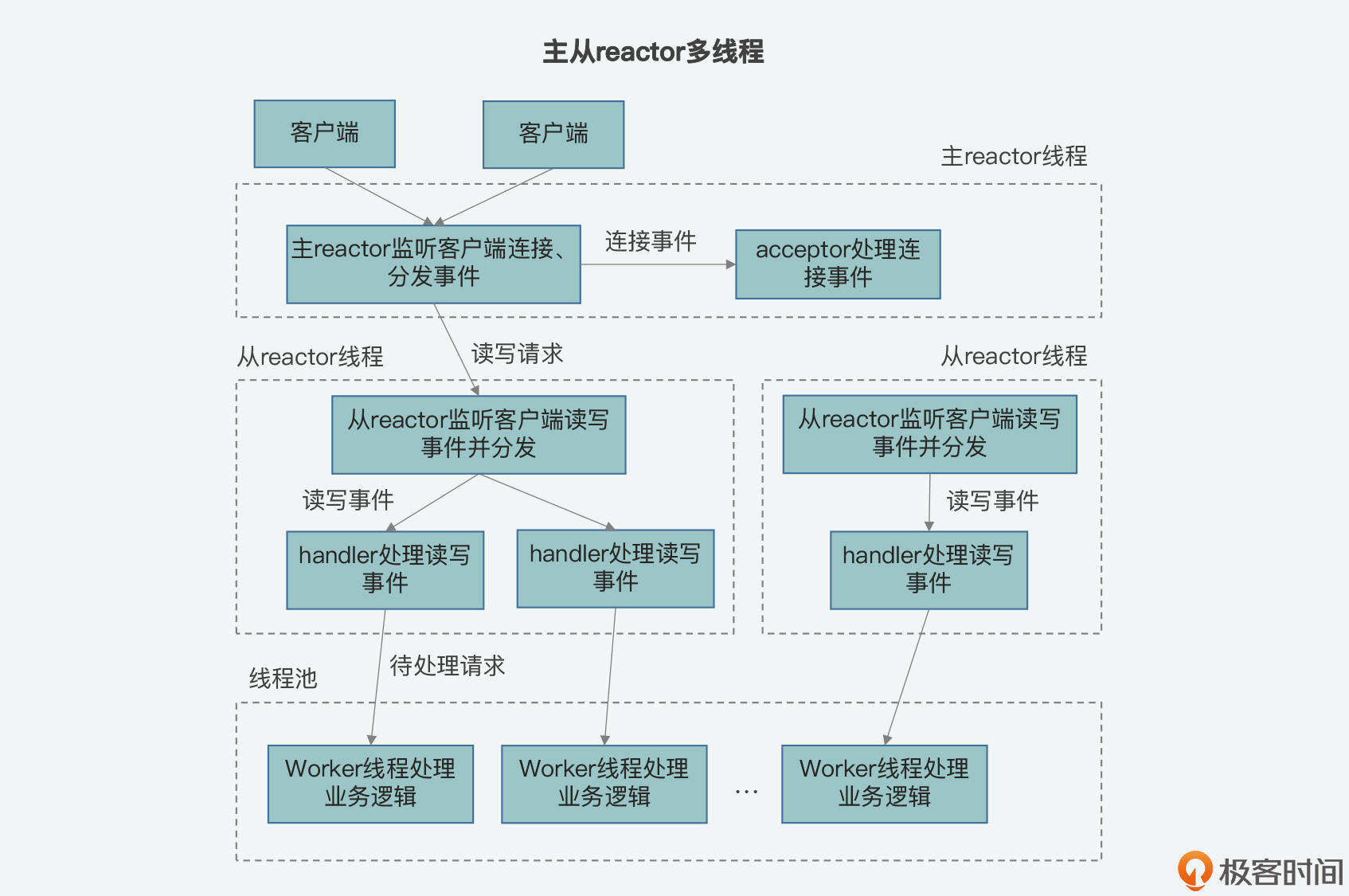
* **类型三:主-从Reactor多线程**
|
|
|
|
|
|
在这个类型中,会有一个主reactor线程、多个子reactor线程和多个worker线程组成的一个线程池。其中,主reactor负责监听客户端事件,并在同一个线程中让acceptor处理连接事件。一旦连接建立后,主reactor会把连接分发给子reactor线程,由子reactor负责这个连接上的后续事件处理。
|
|
|
|
|
|
那么,子reactor会监听客户端连接上的后续事件,有读写事件发生时,它会让在同一个线程中的handler读取请求和返回结果,而和单reactor多线程类似,具体业务处理,它还是会让线程池中的worker线程处理。刚才介绍的Netty使用的就是这个类型。
|
|
|
|
|
|
我在下面画了三张图,展示了刚才介绍的三个类型的区别,你可以再整体回顾下。
|
|
|
|
|
|
|
|
|
|
|
|
## [第11讲](https://time.geekbang.org/column/article/408857)
|
|
|
|
|
|
**问题:已知,Redis事件驱动框架的aeApiCreate、aeApiAddEvent等等这些函数,是对操作系统提供的IO多路复用函数进行了封装,具体的IO多路复用函数分别是在**[ae\_epoll.c](https://github.com/redis/redis/tree/5.0/src/ae_epoll.c)**,**[ae\_evport.c](https://github.com/redis/redis/tree/5.0/src/ae_evport.c)**,**[ae\_kqueue.c](https://github.com/redis/redis/tree/5.0/src/ae_kqueue.c)**,**[ae\_select.c](https://github.com/redis/redis/tree/5.0/src/ae_select.c)**四个代码文件中定义的。那么你知道,Redis在调用aeApiCreate、aeApiAddEvent这些函数时,是根据什么条件来决定,具体调用哪个文件中的IO多路复用函数的吗?**
|
|
|
|
|
|
其实,这道题的目的,主要是希望你能通过它进一步了解如何进行跨平台的编程开发。在实际业务场景中,我们开发的系统可能需要在不同的平台上运行,比如Linux和Windows。那么,我们在开发时,就需要用同一套代码支持在不同平台上的执行。
|
|
|
|
|
|
就像Redis中使用的IO多路复用机制一样,不同平台上支持的IO多路复用函数是不一样的。但是,使用这些函数的事件驱动整体框架又可以用一套框架来实现。所以,我们就需要在同一套代码中区分底层平台,从而可以正确地使用该平台对应函数。
|
|
|
|
|
|
对应Redis事件驱动框架来说,它是用aeApiCreate、aeApiAddEven等函数,封装了不同的IO多路复用函数,而在ae.c文件的开头部分,它使用了#ifdef、#else、#endif等**条件编译指令**,来区分封装的函数应该具体使用哪种IO多路复用函数。
|
|
|
|
|
|
下面的代码就展示了刚才介绍的条件编译。
|
|
|
|
|
|
```plain
|
|
|
#ifdef HAVE_EVPORT
|
|
|
#include "ae_evport.c"
|
|
|
#else
|
|
|
#ifdef HAVE_EPOLL
|
|
|
#include "ae_epoll.c"
|
|
|
#else
|
|
|
#ifdef HAVE_KQUEUE
|
|
|
#include "ae_kqueue.c"
|
|
|
#else
|
|
|
#include "ae_select.c"
|
|
|
#endif
|
|
|
#endif
|
|
|
#endif
|
|
|
|
|
|
```
|
|
|
|
|
|
从这段代码中我们可以看到,如果 `HAVE_EPOLL` 宏被定义了,那么,代码就会包含ae\_epoll.c文件,这也就是说,aeApiCreate、aeApiAddEven、aeApiPoll这些函数就会调用epoll\_create、epoll\_ctl、epoll\_wait这些机制。
|
|
|
|
|
|
类似的,如果 `HAVE_KQUEUE` 宏被定义了,那么,代码就会包含ae\_kqueue.c文件,框架函数也会实际调用kqueue的机制。
|
|
|
|
|
|
那么,接下来的一个问题就是,**`HAVE_EPOLL`、`HAVE_KQUEUE` 这些宏又是在哪里被定义的呢?**
|
|
|
|
|
|
其实,它们是在config.h文件中定义的。
|
|
|
|
|
|
在config.h文件中,代码会判断是否定义了`__linux__`宏,如果有的话,那么,代码就会定义 `HAVE_EPOLL` 宏。而如果定义了`__FreeBSD__`、`__OpenBSD__`等宏,那么代码就会定义 `HAVE_KQUEUE` 宏。
|
|
|
|
|
|
下面的代码展示了config.h中的这部分逻辑,你可以看下。
|
|
|
|
|
|
```plain
|
|
|
#ifdef __linux__
|
|
|
#define HAVE_EPOLL 1
|
|
|
#endif
|
|
|
|
|
|
#if (defined(__APPLE__) && defined(MAC_OS_X_VERSION_10_6)) || defined(__FreeBSD__) || defined(__OpenBSD__) || defined (__NetBSD__)
|
|
|
#define HAVE_KQUEUE 1
|
|
|
#endif
|
|
|
|
|
|
```
|
|
|
|
|
|
好了,到这里,我们就知道了,Redis源码中是根据`__linux__`、`__FreeBSD__`、`__OpenBSD__`这些宏,来决定当前的运行平台是哪个平台,然后再设置相应的IO多路复用函数的宏。**而`__linux__`、`__FreeBSD__`、`__OpenBSD__`这些宏,又是如何定义的呢?**
|
|
|
|
|
|
其实,这就和运行平台上的编译器有关了。编译器会根据所运行的平台提供预定义宏。像刚才的`__linux__`、`__FreeBSD__`这些都是属于预定义宏,这些预定义宏的名称都是以“\_\_”两条下划线开头和结尾的。你在Linux的系统中,比如CentOS或者Ubuntu,运行如下所示的gcc命令,你就可以看到Linux中运行的gcc编译器,已经提供了`__linux__`这个预定义宏了。
|
|
|
|
|
|
```plain
|
|
|
gcc -dM -E -x c /dev/null | grep linux
|
|
|
|
|
|
#define __linux 1
|
|
|
#define __linux__ 1
|
|
|
#define __gnu_linux_x 1
|
|
|
#define linux 1
|
|
|
|
|
|
```
|
|
|
|
|
|
而如果你在macOS的系统中运行如下所示的gcc命令,你也能看到macOS中运行的gcc编译器,已经提供了`__APPLE__`预定义宏。
|
|
|
|
|
|
```plain
|
|
|
gcc -dM -E -x c /dev/null | grep APPLE
|
|
|
#define __APPLE__ 1
|
|
|
|
|
|
```
|
|
|
|
|
|
这样一来,当我们在某个系统平台上使用gcc编译Redis源码时,就可以根据编译器提供的预定义宏,来决定当前究竟该使用哪个IO多路复用函数了。而此时使用的IO多路复用函数,也是和Redis当前运行的平台是匹配的。
|
|
|
|
|
|
## [第12讲](https://time.geekbang.org/column/article/409927)
|
|
|
|
|
|
**问题:Redis后台任务使用了bio\_job结构体来描述,该结构体用了三个指针变量来表示任务参数,如下所示。那么,如果你创建的任务所需要的参数大于3个,你有什么应对方法来传参吗?**
|
|
|
|
|
|
```plain
|
|
|
struct bio_job {
|
|
|
time_t time;
|
|
|
void *arg1, *arg2, *arg3; //传递给任务的参数
|
|
|
};
|
|
|
|
|
|
```
|
|
|
|
|
|
这道题其实是需要你了解在C函数开发时,如果想传递很多参数该如何处理。
|
|
|
|
|
|
其实,这里我们可以充分利用函数参数中的指针,让指针指向一个结构体,比如数组或哈希表。而数组或哈希表这样的结构体中,就可以保存很多参数了。这样一来,我们就可以通过指针指向结构体来传递多个参数了。
|
|
|
|
|
|
不过,你要注意的是,在函数使用参数时,还需要解析指针指向的结构体,这个会产生一些开销。
|
|
|
|
|
|
## 小结
|
|
|
|
|
|
这节课,我们解答了第7讲到第12讲的课后思考题。在设计这些思考题时,有些题我希望你能通过它们了解一些C语言编程开发的技巧,比如使用编译器提供的预定义宏实现跨平台的开发,或者是通过指针给C函数传递批量参数等。而有些题,我是希望你能对计算机系统的一些关键机制设计有更多的了解,比如IO多路复用机制的对比。
|
|
|
|
|
|
其实,在回答这些思考题的时候,你有没有感受到,Redis就像一个小宝藏一样,我们可以从中学到从编程开发、到系统管理、再到系统设计等多方面的知识。希望你能在阅读Redis源码的道路上充分挖掘这个宝藏,充实自己的知识财富。
|
|
|
|