|
|
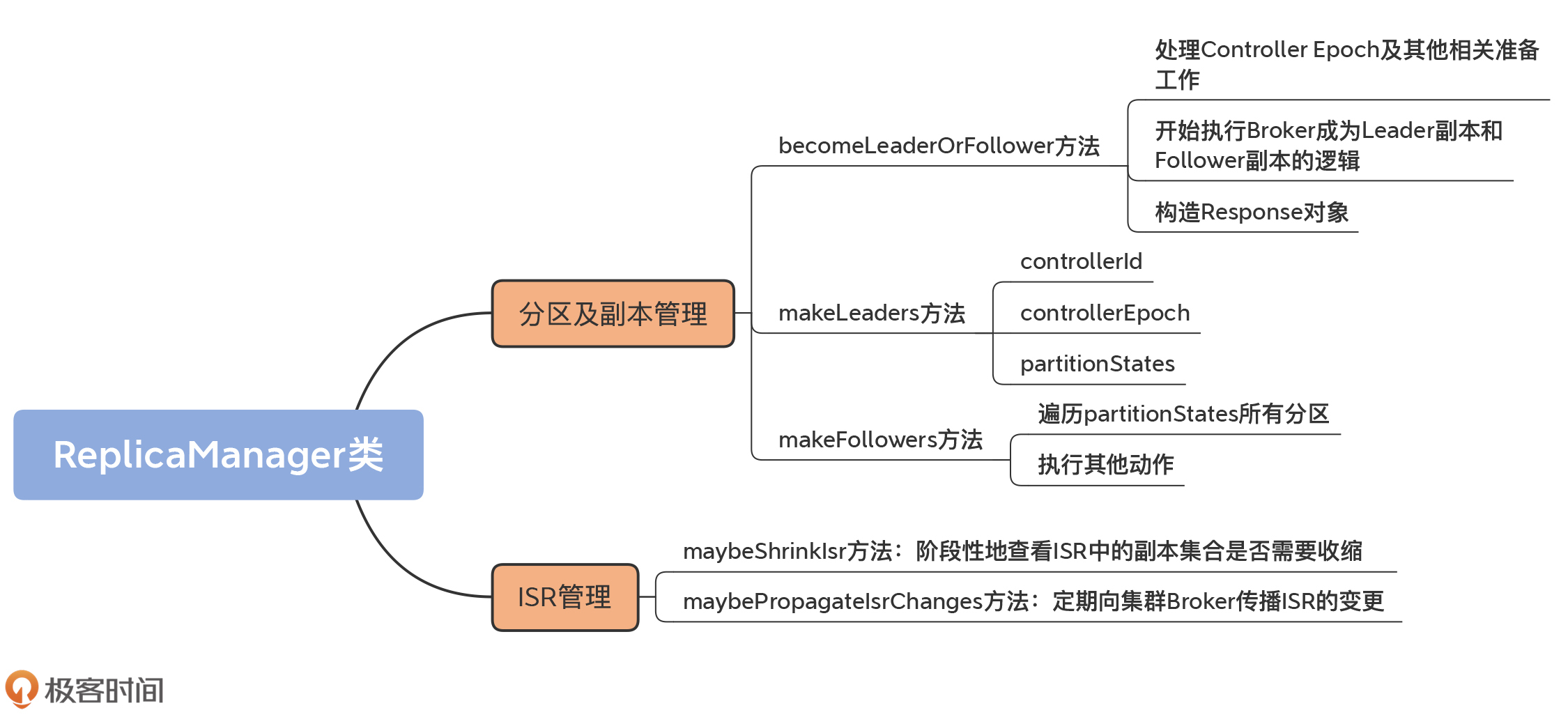
# 25 | ReplicaManager(下):副本管理器是如何管理副本的?
|
|
|
|
|
|
你好,我是胡夕。
|
|
|
|
|
|
上节课我们学习了ReplicaManager类源码中副本管理器是如何执行副本读写操作的。现在我们知道了,这个副本读写操作主要是通过appendRecords和fetchMessages这两个方法实现的,而这两个方法其实在底层分别调用了Log的append和read方法,也就是我们在[第3节课](https://time.geekbang.org/column/article/225993)中学到的日志消息写入和日志消息读取方法。
|
|
|
|
|
|
今天,我们继续学习ReplicaManager类源码,看看副本管理器是如何管理副本的。这里的副本,涵盖了广义副本对象的方方面面,包括副本和分区对象、副本位移值和ISR管理等。因此,本节课我们结合着源码,具体学习下这几个方面。
|
|
|
|
|
|
## 分区及副本管理
|
|
|
|
|
|
除了对副本进行读写之外,副本管理器还有一个重要的功能,就是管理副本和对应的分区。ReplicaManager管理它们的方式,是通过字段allPartitions来实现的。
|
|
|
|
|
|
所以,我想先带你复习下[第23节课](https://time.geekbang.org/column/article/249682)中的allPartitions的代码。不过,这次为了强调它作为容器的属性,我们要把注意力放在它是对象池这个特点上,即allPartitions把所有分区对象汇集在一起,统一放入到一个对象池进行管理。
|
|
|
|
|
|
```
|
|
|
private val allPartitions = new Pool[TopicPartition, HostedPartition](
|
|
|
valueFactory = Some(tp => HostedPartition.Online(Partition(tp, time, this)))
|
|
|
)
|
|
|
|
|
|
```
|
|
|
|
|
|
从代码可以看到,每个ReplicaManager实例都维护了所在Broker上保存的所有分区对象,而每个分区对象Partition下面又定义了一组副本对象Replica。通过这样的层级关系,副本管理器实现了对于分区的直接管理和对副本对象的间接管理。应该这样说,**ReplicaManager通过直接操作分区对象来间接管理下属的副本对象**。
|
|
|
|
|
|
对于一个Broker而言,它管理下辖的分区和副本对象的主要方式,就是要确定在它保存的这些副本中,哪些是Leader副本、哪些是Follower副本。
|
|
|
|
|
|
这些划分可不是一成不变的,而是随着时间的推移不断变化的。比如说,这个时刻Broker是分区A的Leader副本、分区B的Follower副本,但在接下来的某个时刻,Broker很可能变成分区A的Follower副本、分区B的Leader副本。
|
|
|
|
|
|
而这些变更是通过Controller给Broker发送LeaderAndIsrRequest请求来实现的。当Broker端收到这类请求后,会调用副本管理器的becomeLeaderOrFollower方法来处理,并依次执行“成为Leader副本”和“成为Follower副本”的逻辑,令当前Broker互换分区A、B副本的角色。
|
|
|
|
|
|
### becomeLeaderOrFollower方法
|
|
|
|
|
|
这里我们又提到了LeaderAndIsrRequest请求。其实,我们在学习Controller和控制类请求的时候就多次提到过它,在[第12讲](https://time.geekbang.org/column/article/235904)中也详细学习过它的作用了。因为隔的时间比较长了,我怕你忘记了,所以这里我们再回顾下。
|
|
|
|
|
|
简单来说,它就是告诉接收该请求的Broker:在我传给你的这些分区中,哪些分区的Leader副本在你这里;哪些分区的Follower副本在你这里。
|
|
|
|
|
|
becomeLeaderOrFollower方法,就是具体处理LeaderAndIsrRequest请求的地方,同时也是副本管理器添加分区的地方。下面我们就完整地学习下这个方法的源码。由于这部分代码很长,我将会分为3个部分向你介绍,分别是处理Controller Epoch事宜、执行成为Leader和Follower的逻辑以及构造Response。
|
|
|
|
|
|
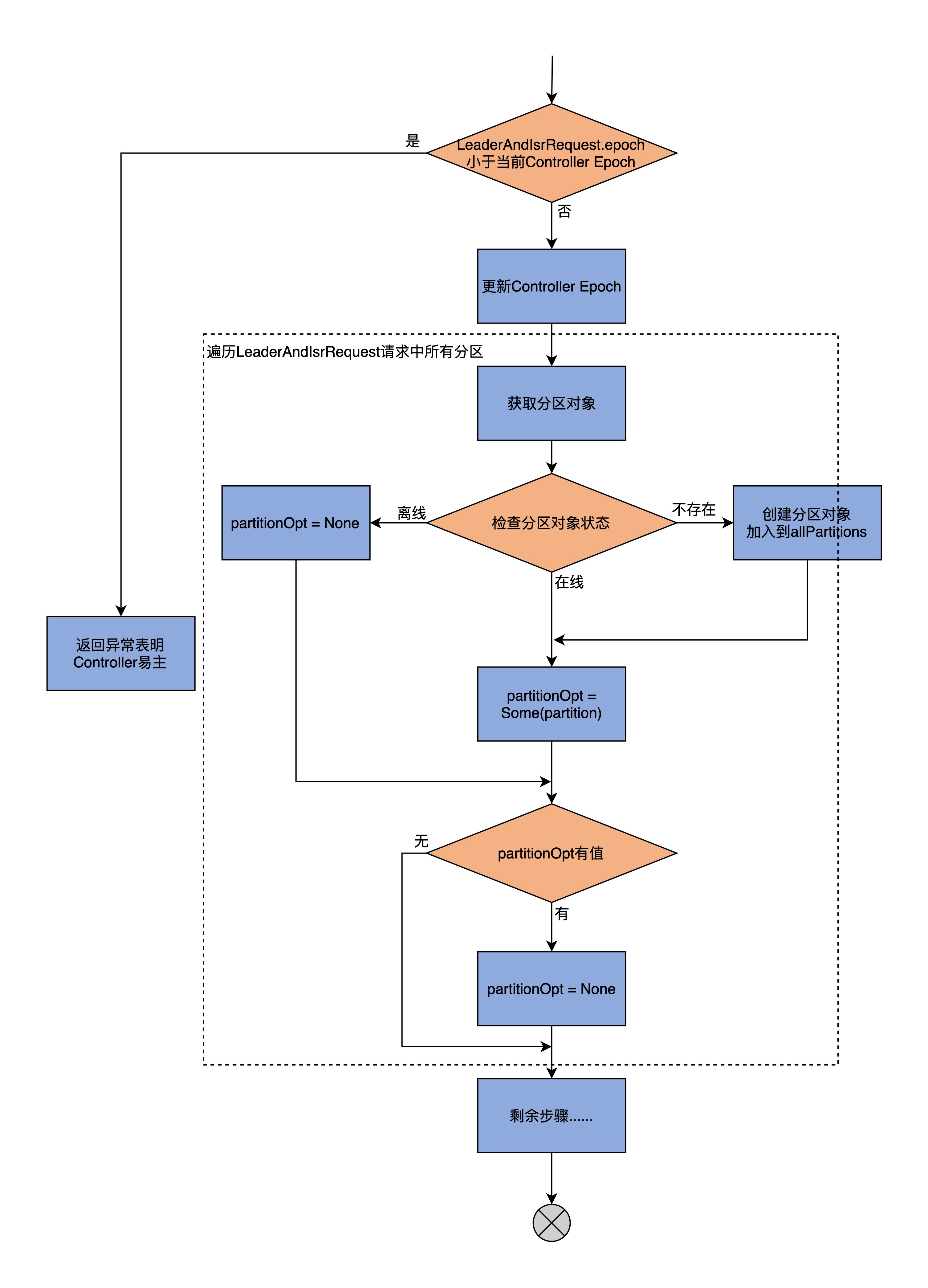
我们先看becomeLeaderOrFollower方法的第1大部分,**处理Controller Epoch及其他相关准备工作**的流程图:
|
|
|
|
|
|
|
|
|
|
|
|
因为becomeLeaderOrFollower方法的开头是一段仅用于调试的日志输出,不是很重要,因此,我直接从if语句开始讲起。第一部分的主体代码如下:
|
|
|
|
|
|
```
|
|
|
// 如果LeaderAndIsrRequest携带的Controller Epoch
|
|
|
// 小于当前Controller的Epoch值
|
|
|
if (leaderAndIsrRequest.controllerEpoch < controllerEpoch) {
|
|
|
stateChangeLogger.warn(s"Ignoring LeaderAndIsr request from controller $controllerId with " +
|
|
|
s"correlation id $correlationId since its controller epoch ${leaderAndIsrRequest.controllerEpoch} is old. " +
|
|
|
s"Latest known controller epoch is $controllerEpoch")
|
|
|
// 说明Controller已经易主,抛出相应异常
|
|
|
leaderAndIsrRequest.getErrorResponse(0, Errors.STALE_CONTROLLER_EPOCH.exception)
|
|
|
} else {
|
|
|
val responseMap = new mutable.HashMap[TopicPartition, Errors]
|
|
|
// 更新当前Controller Epoch值
|
|
|
controllerEpoch = leaderAndIsrRequest.controllerEpoch
|
|
|
val partitionStates = new mutable.HashMap[Partition, LeaderAndIsrPartitionState]()
|
|
|
// 遍历LeaderAndIsrRequest请求中的所有分区
|
|
|
requestPartitionStates.foreach { partitionState =>
|
|
|
val topicPartition = new TopicPartition(partitionState.topicName, partitionState.partitionIndex)
|
|
|
// 从allPartitions中获取对应分区对象
|
|
|
val partitionOpt = getPartition(topicPartition) match {
|
|
|
// 如果是Offline状态
|
|
|
case HostedPartition.Offline =>
|
|
|
stateChangeLogger.warn(s"Ignoring LeaderAndIsr request from " +
|
|
|
s"controller $controllerId with correlation id $correlationId " +
|
|
|
s"epoch $controllerEpoch for partition $topicPartition as the local replica for the " +
|
|
|
"partition is in an offline log directory")
|
|
|
// 添加对象异常到Response,并设置分区对象变量partitionOpt=None
|
|
|
responseMap.put(topicPartition, Errors.KAFKA_STORAGE_ERROR)
|
|
|
None
|
|
|
// 如果是Online状态,直接赋值partitionOpt即可
|
|
|
case HostedPartition.Online(partition) =>
|
|
|
Some(partition)
|
|
|
// 如果是None状态,则表示没有找到分区对象
|
|
|
// 那么创建新的分区对象将,新创建的分区对象加入到allPartitions统一管理
|
|
|
// 然后赋值partitionOpt字段
|
|
|
case HostedPartition.None =>
|
|
|
val partition = Partition(topicPartition, time, this)
|
|
|
allPartitions.putIfNotExists(topicPartition, HostedPartition.Online(partition))
|
|
|
Some(partition)
|
|
|
}
|
|
|
// 检查分区的Leader Epoch值
|
|
|
......
|
|
|
}
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
现在,我们一起来学习下这部分内容的核心逻辑。
|
|
|
|
|
|
首先,比较LeaderAndIsrRequest携带的Controller Epoch值和当前Controller Epoch值。如果发现前者小于后者,说明Controller已经变更到别的Broker上了,需要构造一个STALE\_CONTROLLER\_EPOCH异常并封装进Response返回。否则,代码进入else分支。
|
|
|
|
|
|
然后,becomeLeaderOrFollower方法会更新当前缓存的Controller Epoch值,再提取出LeaderAndIsrRequest请求中涉及到的分区,之后依次遍历这些分区,并执行下面的两步逻辑。
|
|
|
|
|
|
第1步,从allPartitions中取出对应的分区对象。在第23节课,我们学习了分区有3种状态,即在线(Online)、离线(Offline)和不存在(None),这里代码就需要分别应对这3种情况:
|
|
|
|
|
|
* 如果是Online状态的分区,直接将其赋值给partitionOpt字段即可;
|
|
|
* 如果是Offline状态的分区,说明该分区副本所在的Kafka日志路径出现I/O故障时(比如磁盘满了),需要构造对应的KAFKA\_STORAGE\_ERROR异常并封装进Response,同时令partitionOpt字段为None;
|
|
|
* 如果是None状态的分区,则创建新分区对象,然后将其加入到allPartitions中,进行统一管理,并赋值给partitionOpt字段。
|
|
|
|
|
|
第2步,检查partitionOpt字段表示的分区的Leader Epoch。检查的原则是要确保请求中携带的Leader Epoch值要大于当前缓存的Leader Epoch,否则就说明是过期Controller发送的请求,就直接忽略它,不做处理。
|
|
|
|
|
|
总之呢,becomeLeaderOrFollower方法的第一部分代码,主要做的事情就是创建新分区、更新Controller Epoch和校验分区Leader Epoch。我们在[第3讲](https://time.geekbang.org/column/article/225993)说到过Leader Epoch机制,因为是比较高阶的用法,你可以不用重点掌握,这不会影响到我们学习副本管理。不过,如果你想深入了解的话,推荐你课下自行阅读下LeaderEpochFileCache.scala的源码。
|
|
|
|
|
|
当为所有分区都执行完这两个步骤之后,**becomeLeaderOrFollower方法进入到第2部分,开始执行Broker成为Leader副本和Follower副本的逻辑**:
|
|
|
|
|
|
```
|
|
|
// 确定Broker上副本是哪些分区的Leader副本
|
|
|
val partitionsToBeLeader = partitionStates.filter { case (_, partitionState) =>
|
|
|
partitionState.leader == localBrokerId
|
|
|
}
|
|
|
// 确定Broker上副本是哪些分区的Follower副本
|
|
|
val partitionsToBeFollower = partitionStates.filter { case (k, _) => !partitionsToBeLeader.contains(k) }
|
|
|
|
|
|
val highWatermarkCheckpoints = new LazyOffsetCheckpoints(this.highWatermarkCheckpoints)
|
|
|
val partitionsBecomeLeader = if (partitionsToBeLeader.nonEmpty)
|
|
|
// 调用makeLeaders方法为partitionsToBeLeader所有分区
|
|
|
// 执行"成为Leader副本"的逻辑
|
|
|
makeLeaders(controllerId, controllerEpoch, partitionsToBeLeader, correlationId, responseMap,
|
|
|
highWatermarkCheckpoints)
|
|
|
else
|
|
|
Set.empty[Partition]
|
|
|
val partitionsBecomeFollower = if (partitionsToBeFollower.nonEmpty)
|
|
|
// 调用makeFollowers方法为令partitionsToBeFollower所有分区
|
|
|
// 执行"成为Follower副本"的逻辑
|
|
|
makeFollowers(controllerId, controllerEpoch, partitionsToBeFollower, correlationId, responseMap,
|
|
|
highWatermarkCheckpoints)
|
|
|
else
|
|
|
Set.empty[Partition]
|
|
|
val leaderTopicSet = leaderPartitionsIterator.map(_.topic).toSet
|
|
|
val followerTopicSet = partitionsBecomeFollower.map(_.topic).toSet
|
|
|
// 对于当前Broker成为Follower副本的主题
|
|
|
// 移除它们之前的Leader副本监控指标
|
|
|
followerTopicSet.diff(leaderTopicSet).foreach(brokerTopicStats.removeOldLeaderMetrics)
|
|
|
// 对于当前Broker成为Leader副本的主题
|
|
|
// 移除它们之前的Follower副本监控指
|
|
|
leaderTopicSet.diff(followerTopicSet).foreach(brokerTopicStats.removeOldFollowerMetrics)
|
|
|
// 如果有分区的本地日志为空,说明底层的日志路径不可用
|
|
|
// 标记该分区为Offline状态
|
|
|
leaderAndIsrRequest.partitionStates.forEach { partitionState =>
|
|
|
val topicPartition = new TopicPartition(partitionState.topicName, partitionState.partitionIndex)
|
|
|
if (localLog(topicPartition).isEmpty)
|
|
|
markPartitionOffline(topicPartition)
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
**首先**,这部分代码需要先确定两个分区集合,一个是把该Broker当成Leader的所有分区;一个是把该Broker当成Follower的所有分区。判断的依据,主要是看LeaderAndIsrRequest请求中分区的Leader信息,是不是和本Broker的ID相同。如果相同,则表明该Broker是这个分区的Leader;否则,表示当前Broker是这个分区的Follower。
|
|
|
|
|
|
一旦确定了这两个分区集合,**接着**,代码就会分别为它们调用makeLeaders和makeFollowers方法,正式让Leader和Follower角色生效。之后,对于那些当前Broker成为Follower副本的主题,代码需要移除它们之前的Leader副本监控指标,以防出现系统资源泄露的问题。同样地,对于那些当前Broker成为Leader副本的主题,代码要移除它们之前的Follower副本监控指标。
|
|
|
|
|
|
**最后**,如果有分区的本地日志为空,说明底层的日志路径不可用,那么标记该分区为Offline状态。所谓的标记为Offline状态,主要是两步:第1步是更新allPartitions中分区的状态;第2步是移除对应分区的监控指标。
|
|
|
|
|
|
小结一下,becomeLeaderOrFollower方法第2大部分的主要功能是,调用makeLeaders和makeFollowers方法,令Broker在不同分区上的Leader或Follower角色生效。关于这两个方法的实现细节,一会儿我再详细说。
|
|
|
|
|
|
现在,让我们看看**第3大部分的代码,构造Response对象**。这部分代码是becomeLeaderOrFollower方法的收尾操作。
|
|
|
|
|
|
```
|
|
|
// 启动高水位检查点专属线程
|
|
|
// 定期将Broker上所有非Offline分区的高水位值写入到检查点文件
|
|
|
startHighWatermarkCheckPointThread()
|
|
|
// 添加日志路径数据迁移线程
|
|
|
maybeAddLogDirFetchers(partitionStates.keySet, highWatermarkCheckpoints)
|
|
|
// 关闭空闲副本拉取线程
|
|
|
replicaFetcherManager.shutdownIdleFetcherThreads()
|
|
|
// 关闭空闲日志路径数据迁移线程
|
|
|
replicaAlterLogDirsManager.shutdownIdleFetcherThreads()
|
|
|
// 执行Leader变更之后的回调逻辑
|
|
|
onLeadershipChange(partitionsBecomeLeader, partitionsBecomeFollower)
|
|
|
// 构造LeaderAndIsrRequest请求的Response并返回
|
|
|
val responsePartitions = responseMap.iterator.map { case (tp, error) =>
|
|
|
new LeaderAndIsrPartitionError()
|
|
|
.setTopicName(tp.topic)
|
|
|
.setPartitionIndex(tp.partition)
|
|
|
.setErrorCode(error.code)
|
|
|
}.toBuffer
|
|
|
new LeaderAndIsrResponse(new LeaderAndIsrResponseData()
|
|
|
.setErrorCode(Errors.NONE.code)
|
|
|
.setPartitionErrors(responsePartitions.asJava))
|
|
|
|
|
|
```
|
|
|
|
|
|
我们来分析下这部分代码的执行逻辑吧。
|
|
|
|
|
|
首先,这部分开始时会启动一个专属线程来执行高水位值持久化,定期地将Broker上所有非Offline分区的高水位值写入检查点文件。这个线程是个后台线程,默认每5秒执行一次。
|
|
|
|
|
|
同时,代码还会添加日志路径数据迁移线程。这个线程的主要作用是,将路径A上面的数据搬移到路径B上。这个功能是Kafka支持JBOD(Just a Bunch of Disks)的重要前提。
|
|
|
|
|
|
之后,becomeLeaderOrFollower方法会关闭空闲副本拉取线程和空闲日志路径数据迁移线程。判断空闲与否的主要条件是,分区Leader/Follower角色调整之后,是否存在不再使用的拉取线程了。代码要确保及时关闭那些不再被使用的线程对象。
|
|
|
|
|
|
再之后是执行LeaderAndIsrRequest请求的回调处理逻辑。这里的回调逻辑,实际上只是对Kafka两个内部主题(\_\_consumer\_offsets和\_\_transaction\_state)有用,其他主题一概不适用。所以通常情况下,你可以无视这里的回调逻辑。
|
|
|
|
|
|
等这些都做完之后,代码开始执行这部分最后,也是最重要的任务:构造LeaderAndIsrRequest请求的Response,然后将新创建的Response返回。至此,这部分方法的逻辑结束。
|
|
|
|
|
|
纵观becomeLeaderOrFollower方法的这3大部分,becomeLeaderOrFollower方法最重要的职责,在我看来就是调用makeLeaders和makeFollowers方法,为各自的分区列表执行相应的角色确认工作。
|
|
|
|
|
|
接下来,我们就分别看看这两个方法是如何实现这种角色确认的。
|
|
|
|
|
|
### makeLeaders方法
|
|
|
|
|
|
makeLeaders方法的作用是,让当前Broker成为给定一组分区的Leader,也就是让当前Broker下该分区的副本成为Leader副本。这个方法主要有3步:
|
|
|
|
|
|
1. 停掉这些分区对应的获取线程;
|
|
|
2. 更新Broker缓存中的分区元数据信息;
|
|
|
3. 将指定分区添加到Leader分区集合。
|
|
|
|
|
|
我们结合代码分析下这些都是如何实现的。首先,我们看下makeLeaders的方法签名:
|
|
|
|
|
|
```
|
|
|
// controllerId:Controller所在Broker的ID
|
|
|
// controllEpoch:Controller Epoch值,可以认为是Controller版本号
|
|
|
// partitionStates:LeaderAndIsrRequest请求中携带的分区信息
|
|
|
// correlationId:请求的Correlation字段,只用于日志调试
|
|
|
// responseMap:按照主题分区分组的异常错误集合
|
|
|
// highWatermarkCheckpoints:操作磁盘上高水位检查点文件的工具类
|
|
|
private def makeLeaders(controllerId: Int,
|
|
|
controllerEpoch: Int,
|
|
|
partitionStates: Map[Partition, LeaderAndIsrPartitionState],
|
|
|
correlationId: Int,
|
|
|
responseMap: mutable.Map[TopicPartition, Errors],
|
|
|
highWatermarkCheckpoints: OffsetCheckpoints): Set[Partition] = {
|
|
|
......
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
可以看出,makeLeaders方法接收6个参数,并返回一个分区对象集合。这个集合就是当前Broker是Leader的所有分区。在这6个参数中,以下3个参数比较关键,我们看下它们的含义。
|
|
|
|
|
|
* controllerId:Controller所在Broker的ID。该字段只是用于日志输出,无其他实际用途。
|
|
|
* controllerEpoch:Controller Epoch值,可以认为是Controller版本号。该字段用于日志输出使用,无其他实际用途。
|
|
|
* partitionStates:LeaderAndIsrRequest请求中携带的分区信息,包括每个分区的Leader是谁、ISR都有哪些等数据。
|
|
|
|
|
|
好了,现在我们继续学习makeLeaders的代码。我把这个方法的关键步骤放在了注释里,并省去了一些日志输出相关的代码。
|
|
|
|
|
|
```
|
|
|
......
|
|
|
// 使用Errors.NONE初始化ResponseMap
|
|
|
partitionStates.keys.foreach { partition =>
|
|
|
......
|
|
|
responseMap.put(partition.topicPartition, Errors.NONE)
|
|
|
}
|
|
|
val partitionsToMakeLeaders = mutable.Set[Partition]()
|
|
|
try {
|
|
|
// 停止消息拉取
|
|
|
replicaFetcherManager.removeFetcherForPartitions(
|
|
|
partitionStates.keySet.map(_.topicPartition))
|
|
|
stateChangeLogger.info(s"Stopped fetchers as part of LeaderAndIsr request correlationId $correlationId from " +
|
|
|
s"controller $controllerId epoch $controllerEpoch as part of the become-leader transition for " +
|
|
|
s"${partitionStates.size} partitions")
|
|
|
// 更新指定分区的Leader分区信息
|
|
|
partitionStates.foreach { case (partition, partitionState) =>
|
|
|
try {
|
|
|
if (partition.makeLeader(partitionState, highWatermarkCheckpoints))
|
|
|
partitionsToMakeLeaders += partition
|
|
|
else
|
|
|
......
|
|
|
} catch {
|
|
|
case e: KafkaStorageException =>
|
|
|
......
|
|
|
// 把KAFKA_SOTRAGE_ERRROR异常封装到Response中
|
|
|
responseMap.put(partition.topicPartition, Errors.KAFKA_STORAGE_ERROR)
|
|
|
}
|
|
|
}
|
|
|
} catch {
|
|
|
case e: Throwable =>
|
|
|
......
|
|
|
}
|
|
|
......
|
|
|
partitionsToMakeLeaders
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
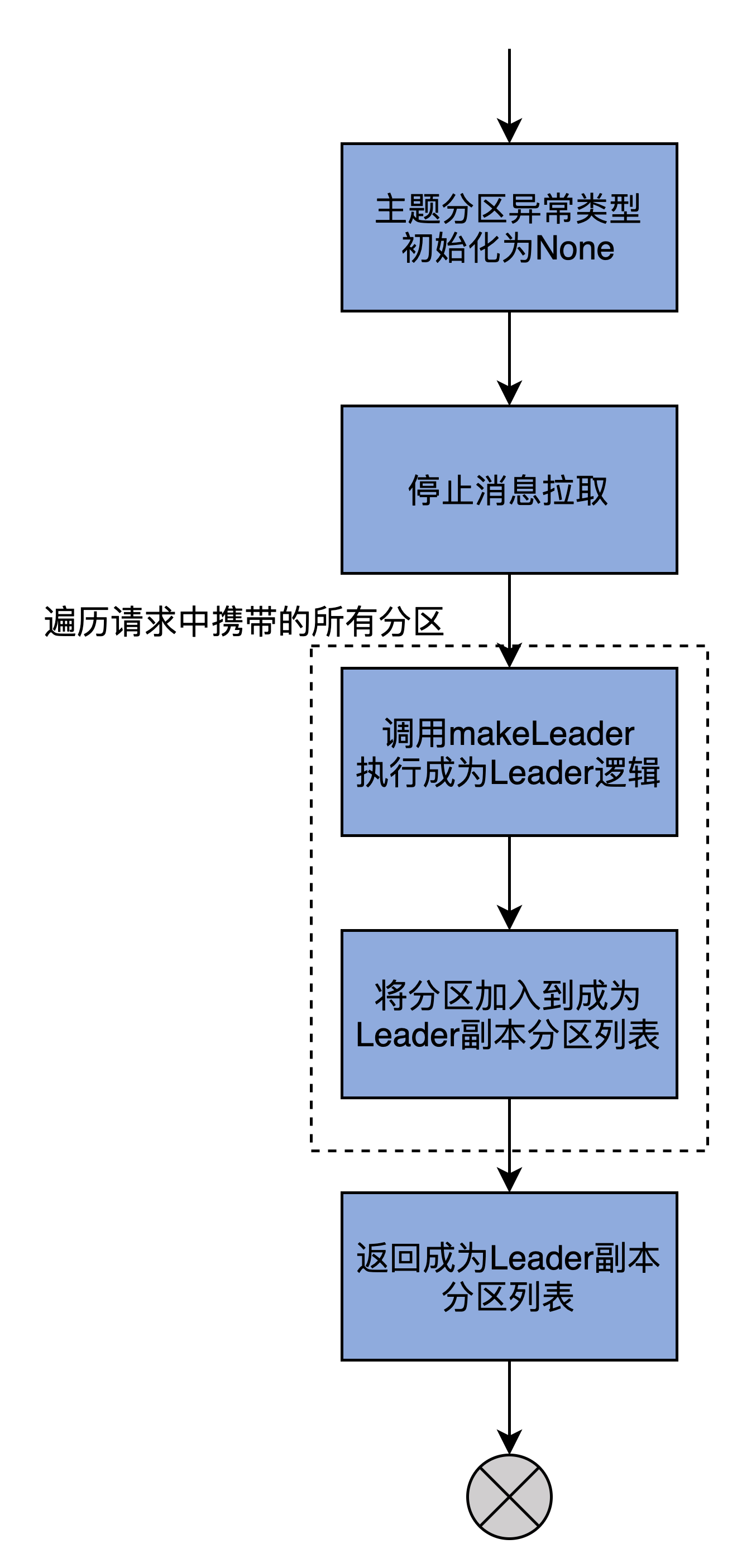
我把主要的执行流程,梳理为了一张流程图:
|
|
|
|
|
|
|
|
|
|
|
|
结合着图,我再带着你学习下这个方法的执行逻辑。
|
|
|
|
|
|
首先,将给定的一组分区的状态全部初始化成Errors.None。
|
|
|
|
|
|
然后,停止为这些分区服务的所有拉取线程。毕竟该Broker现在是这些分区的Leader副本了,不再是Follower副本了,所以没有必要再使用拉取线程了。
|
|
|
|
|
|
最后,makeLeaders方法调用Partition的makeLeader方法,去更新给定一组分区的Leader分区信息,而这些是由Partition类中的makeLeader方法完成的。该方法保存分区的Leader和ISR信息,同时创建必要的日志对象、重设远端Follower副本的LEO值。
|
|
|
|
|
|
那远端Follower副本,是什么意思呢?远端Follower副本,是指保存在Leader副本本地内存中的一组Follower副本集合,在代码中用字段remoteReplicas来表征。
|
|
|
|
|
|
ReplicaManager在处理FETCH请求时,会更新remoteReplicas中副本对象的LEO值。同时,Leader副本会将自己更新后的LEO值与remoteReplicas中副本的LEO值进行比较,来决定是否“抬高”高水位值。
|
|
|
|
|
|
而Partition类中的makeLeader方法的一个重要步骤,就是要重设这组远端Follower副本对象的LEO值。
|
|
|
|
|
|
makeLeaders方法执行完Partition.makeLeader后,如果当前Broker成功地成为了该分区的Leader副本,就返回True,表示新Leader配置成功,否则,就表示处理失败。倘若成功设置了Leader,那么,就把该分区加入到已成功设置Leader的分区列表中,并返回该列表。
|
|
|
|
|
|
至此,方法结束。我再来小结下,makeLeaders的作用是令当前Broker成为给定分区的Leader副本。接下来,我们再看看与makeLeaders方法功能相反的makeFollowers方法。
|
|
|
|
|
|
### makeFollowers方法
|
|
|
|
|
|
makeFollowers方法的作用是,将当前Broker配置成指定分区的Follower副本。我们还是先看下方法签名:
|
|
|
|
|
|
```
|
|
|
// controllerId:Controller所在Broker的Id
|
|
|
// controllerEpoch:Controller Epoch值
|
|
|
// partitionStates:当前Broker是Follower副本的所有分区的详细信息
|
|
|
// correlationId:连接请求与响应的关联字段
|
|
|
// responseMap:封装LeaderAndIsrRequest请求处理结果的字段
|
|
|
// highWatermarkCheckpoints:操作高水位检查点文件的工具类
|
|
|
private def makeFollowers(
|
|
|
controllerId: Int,
|
|
|
controllerEpoch: Int,
|
|
|
partitionStates: Map[Partition, LeaderAndIsrPartitionState],
|
|
|
correlationId: Int,
|
|
|
responseMap: mutable.Map[TopicPartition, Errors],
|
|
|
highWatermarkCheckpoints: OffsetCheckpoints) : Set[Partition] = {
|
|
|
......
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
你看,makeFollowers方法的参数列表与makeLeaders方法,是一模一样的。这里我也就不再展开了。
|
|
|
|
|
|
其中比较重要的字段,就是partitionStates和responseMap。基本上,你可以认为partitionStates是makeFollowers方法的输入,responseMap是输出。
|
|
|
|
|
|
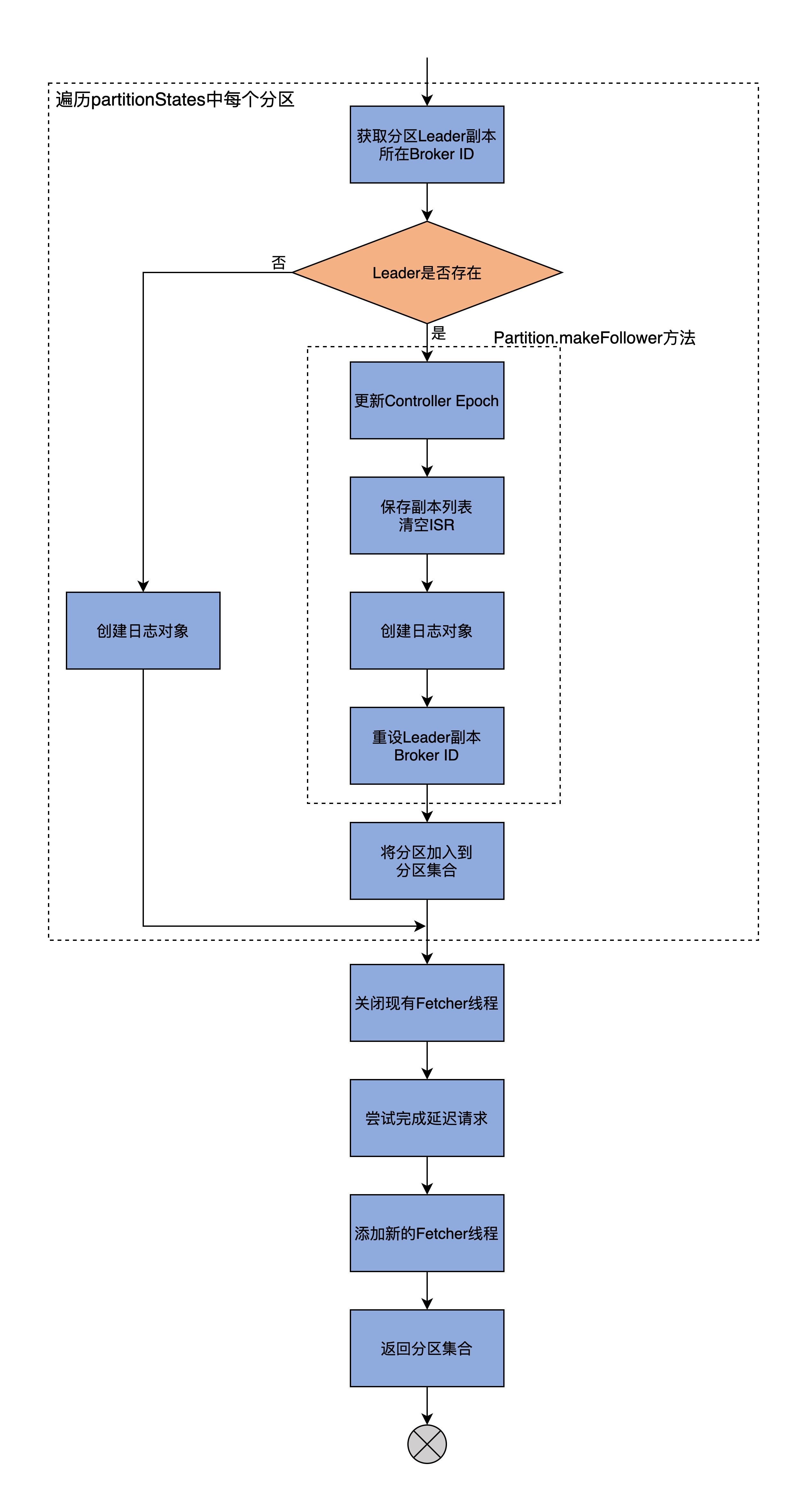
因为整个makeFollowers方法的代码很长,所以我接下来会先用一张图解释下它的核心逻辑,让你先有个全局观;然后,我再按照功能划分带你学习每一部分的代码。
|
|
|
|
|
|
|
|
|
|
|
|
总体来看,makeFollowers方法分为两大步:
|
|
|
|
|
|
* 第1步,遍历partitionStates中的所有分区,然后执行“成为Follower”的操作;
|
|
|
* 第2步,执行其他动作,主要包括重建Fetcher线程、完成延时请求等。
|
|
|
|
|
|
首先,**我们学习第1步遍历partitionStates所有分区的代码**:
|
|
|
|
|
|
```
|
|
|
// 第一部分:遍历partitionStates所有分区
|
|
|
......
|
|
|
partitionStates.foreach { case (partition, partitionState) =>
|
|
|
......
|
|
|
// 将所有分区的处理结果的状态初始化为Errors.NONE
|
|
|
responseMap.put(partition.topicPartition, Errors.NONE)
|
|
|
}
|
|
|
val partitionsToMakeFollower: mutable.Set[Partition] = mutable.Set()
|
|
|
try {
|
|
|
// 遍历partitionStates所有分区
|
|
|
partitionStates.foreach { case (partition, partitionState) =>
|
|
|
// 拿到分区的Leader Broker ID
|
|
|
val newLeaderBrokerId = partitionState.leader
|
|
|
try {
|
|
|
// 在元数据缓存中找到Leader Broke对象
|
|
|
metadataCache.getAliveBrokers.find(_.id == newLeaderBrokerId) match {
|
|
|
// 如果Leader确实存在
|
|
|
case Some(_) =>
|
|
|
// 执行makeFollower方法,将当前Broker配置成该分区的Follower副本
|
|
|
if (partition.makeFollower(partitionState, highWatermarkCheckpoints))
|
|
|
// 如果配置成功,将该分区加入到结果返回集中
|
|
|
partitionsToMakeFollower += partition
|
|
|
else // 如果失败,打印错误日志
|
|
|
......
|
|
|
// 如果Leader不存在
|
|
|
case None =>
|
|
|
......
|
|
|
// 依然创建出分区Follower副本的日志对象
|
|
|
partition.createLogIfNotExists(isNew = partitionState.isNew, isFutureReplica = false,
|
|
|
highWatermarkCheckpoints)
|
|
|
}
|
|
|
} catch {
|
|
|
case e: KafkaStorageException =>
|
|
|
......
|
|
|
}
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
在这部分代码中,我们可以把它的执行逻辑划分为两大步骤。
|
|
|
|
|
|
第1步,将结果返回集合中所有分区的处理结果状态初始化为Errors.NONE;第2步,遍历partitionStates中的所有分区,依次为每个分区执行以下逻辑:
|
|
|
|
|
|
* 从分区的详细信息中获取分区的Leader Broker ID;
|
|
|
* 拿着上一步获取的Broker ID,去Broker元数据缓存中找到Leader Broker对象;
|
|
|
* 如果Leader对象存在,则执行Partition类的makeFollower方法将当前Broker配置成该分区的Follower副本。如果makeFollower方法执行成功,就说明当前Broker被成功配置为指定分区的Follower副本,那么将该分区加入到结果返回集中。
|
|
|
* 如果Leader对象不存在,依然创建出分区Follower副本的日志对象。
|
|
|
|
|
|
说到Partition的makeFollower方法的执行逻辑,主要是包括以下4步:
|
|
|
|
|
|
1. 更新Controller Epoch值;
|
|
|
2. 保存副本列表(Assigned Replicas,AR)和清空ISR;
|
|
|
3. 创建日志对象;
|
|
|
4. 重设Leader副本的Broker ID。
|
|
|
|
|
|
接下来,**我们看下makeFollowers方法的第2步,执行其他动作的代码**:
|
|
|
|
|
|
```
|
|
|
// 第二部分:执行其他动作
|
|
|
// 移除现有Fetcher线程
|
|
|
replicaFetcherManager.removeFetcherForPartitions(
|
|
|
partitionsToMakeFollower.map(_.topicPartition))
|
|
|
......
|
|
|
// 尝试完成延迟请求
|
|
|
partitionsToMakeFollower.foreach { partition =>
|
|
|
completeDelayedFetchOrProduceRequests(partition.topicPartition)
|
|
|
}
|
|
|
if (isShuttingDown.get()) {
|
|
|
.....
|
|
|
} else {
|
|
|
// 为需要将当前Broker设置为Follower副本的分区
|
|
|
// 确定Leader Broker和起始读取位移值fetchOffset
|
|
|
val partitionsToMakeFollowerWithLeaderAndOffset = partitionsToMakeFollower.map { partition =>
|
|
|
val leader = metadataCache.getAliveBrokers
|
|
|
.find(_.id == partition.leaderReplicaIdOpt.get).get
|
|
|
.brokerEndPoint(config.interBrokerListenerName)
|
|
|
val fetchOffset = partition.localLogOrException.highWatermark
|
|
|
partition.topicPartition -> InitialFetchState(leader,
|
|
|
partition.getLeaderEpoch, fetchOffset)
|
|
|
}.toMap
|
|
|
// 使用上一步确定的Leader Broker和fetchOffset添加新的Fetcher线程
|
|
|
replicaFetcherManager.addFetcherForPartitions(
|
|
|
partitionsToMakeFollowerWithLeaderAndOffset)
|
|
|
}
|
|
|
} catch {
|
|
|
case e: Throwable =>
|
|
|
......
|
|
|
throw e
|
|
|
}
|
|
|
......
|
|
|
// 返回需要将当前Broker设置为Follower副本的分区列表
|
|
|
partitionsToMakeFollower
|
|
|
|
|
|
```
|
|
|
|
|
|
你看,这部分代码的任务比较简单,逻辑也都是线性递进的,很好理解。我带你简单地梳理一下。
|
|
|
|
|
|
首先,移除现有Fetcher线程。因为Leader可能已经更换了,所以要读取的Broker以及要读取的位移值都可能随之发生变化。
|
|
|
|
|
|
然后,为需要将当前Broker设置为Follower副本的分区,确定Leader Broker和起始读取位移值fetchOffset。这些信息都已经在LeaderAndIsrRequest中了。
|
|
|
|
|
|
接下来,使用上一步确定的Leader Broker和fetchOffset添加新的Fetcher线程。
|
|
|
|
|
|
最后,返回需要将当前Broker设置为Follower副本的分区列表。
|
|
|
|
|
|
至此,副本管理器管理分区和副本的主要方法实现,我们就都学完啦。可以看出,这些代码实现的大部分,都是围绕着如何处理LeaderAndIsrRequest请求数据展开的。比如,makeLeaders拿到请求数据后,会为分区设置Leader和ISR;makeFollowers拿到数据后,会为分区更换Fetcher线程以及清空ISR。
|
|
|
|
|
|
LeaderAndIsrRequest请求是Kafka定义的最重要的控制类请求。搞懂它是如何被处理的,对于你弄明白Kafka的副本机制是大有裨益的。
|
|
|
|
|
|
## ISR管理
|
|
|
|
|
|
除了读写副本、管理分区和副本的功能之外,副本管理器还有一个重要的功能,那就是管理ISR。这里的管理主要体现在两个方法:
|
|
|
|
|
|
* 一个是maybeShrinkIsr方法,作用是阶段性地查看ISR中的副本集合是否需要收缩;
|
|
|
* 另一个是maybePropagateIsrChanges方法,作用是定期向集群Broker传播ISR的变更。
|
|
|
|
|
|
首先,我们看下ISR的收缩操作。
|
|
|
|
|
|
### maybeShrinkIsr方法
|
|
|
|
|
|
收缩是指,把ISR副本集合中那些与Leader差距过大的副本移除的过程。所谓的差距过大,就是ISR中Follower副本滞后Leader副本的时间,超过了Broker端参数replica.lag.time.max.ms值的1.5倍。
|
|
|
|
|
|
稍等,为什么是1.5倍呢?你可以看下面的代码:
|
|
|
|
|
|
```
|
|
|
def startup(): Unit = {
|
|
|
scheduler.schedule("isr-expiration", maybeShrinkIsr _, period = config.replicaLagTimeMaxMs / 2, unit = TimeUnit.MILLISECONDS)
|
|
|
......
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
我来解释下。ReplicaManager类的startup方法会在被调用时创建一个异步线程,定时查看是否有ISR需要进行收缩。这里的定时频率是replicaLagTimeMaxMs值的一半,而判断Follower副本是否需要被移除ISR的条件是,滞后程度是否超过了replicaLagTimeMaxMs值。
|
|
|
|
|
|
因此理论上,滞后程度小于1.5倍replicaLagTimeMaxMs值的Follower副本,依然有可能在ISR中,不会被移除。这就是数字“1.5”的由来了。
|
|
|
|
|
|
接下来,我们看下maybeShrinkIsr方法的源码。
|
|
|
|
|
|
```
|
|
|
private def maybeShrinkIsr(): Unit = {
|
|
|
trace("Evaluating ISR list of partitions to see which replicas can be removed from the ISR")
|
|
|
allPartitions.keys.foreach { topicPartition =>
|
|
|
nonOfflinePartition(topicPartition).foreach(_.maybeShrinkIsr())
|
|
|
}
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
可以看出,maybeShrinkIsr方法会遍历该副本管理器上所有分区对象,依次为这些分区中状态为Online的分区,执行Partition类的maybeShrinkIsr方法。这个方法的源码如下:
|
|
|
|
|
|
```
|
|
|
def maybeShrinkIsr(): Unit = {
|
|
|
// 判断是否需要执行ISR收缩
|
|
|
val needsIsrUpdate = inReadLock(leaderIsrUpdateLock) {
|
|
|
needsShrinkIsr()
|
|
|
}
|
|
|
val leaderHWIncremented = needsIsrUpdate && inWriteLock(leaderIsrUpdateLock) {
|
|
|
leaderLogIfLocal match {
|
|
|
// 如果是Leader副本
|
|
|
case Some(leaderLog) =>
|
|
|
// 获取不同步的副本Id列表
|
|
|
val outOfSyncReplicaIds = getOutOfSyncReplicas(replicaLagTimeMaxMs)
|
|
|
// 如果存在不同步的副本Id列表
|
|
|
if (outOfSyncReplicaIds.nonEmpty) {
|
|
|
// 计算收缩之后的ISR列表
|
|
|
val newInSyncReplicaIds = inSyncReplicaIds -- outOfSyncReplicaIds
|
|
|
assert(newInSyncReplicaIds.nonEmpty)
|
|
|
info("Shrinking ISR from %s to %s. Leader: (highWatermark: %d, endOffset: %d). Out of sync replicas: %s."
|
|
|
.format(inSyncReplicaIds.mkString(","),
|
|
|
newInSyncReplicaIds.mkString(","),
|
|
|
leaderLog.highWatermark,
|
|
|
leaderLog.logEndOffset,
|
|
|
outOfSyncReplicaIds.map { replicaId =>
|
|
|
s"(brokerId: $replicaId, endOffset: ${getReplicaOrException(replicaId).logEndOffset})"
|
|
|
}.mkString(" ")
|
|
|
)
|
|
|
)
|
|
|
// 更新ZooKeeper中分区的ISR数据以及Broker的元数据缓存中的数据
|
|
|
shrinkIsr(newInSyncReplicaIds)
|
|
|
// 尝试更新Leader副本的高水位值
|
|
|
maybeIncrementLeaderHW(leaderLog)
|
|
|
} else {
|
|
|
false
|
|
|
}
|
|
|
// 如果不是Leader副本,什么都不做
|
|
|
case None => false
|
|
|
}
|
|
|
}
|
|
|
// 如果Leader副本的高水位值抬升了
|
|
|
if (leaderHWIncremented)
|
|
|
// 尝试解锁一下延迟请求
|
|
|
tryCompleteDelayedRequests()
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
可以看出,maybeShrinkIsr方法的整个执行流程是:
|
|
|
|
|
|
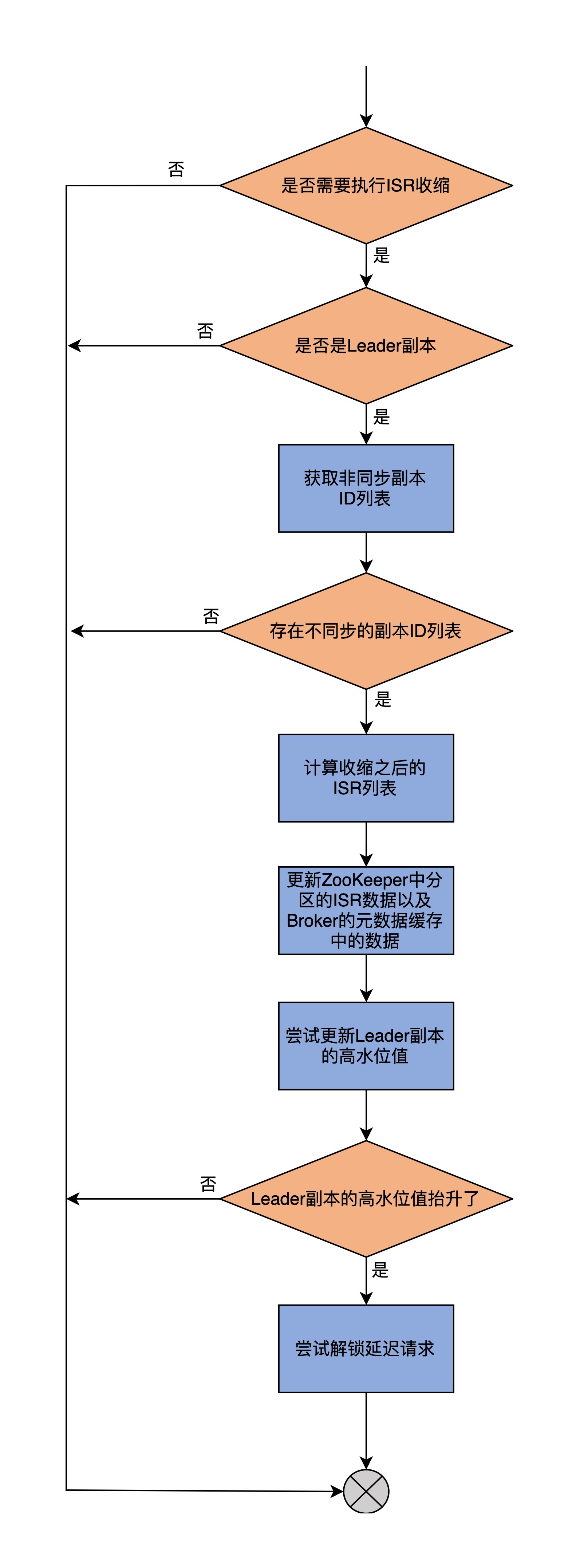
* **第1步**,判断是否需要执行ISR收缩。主要的方法是,调用needShrinkIsr方法来获取与Leader不同步的副本。如果存在这样的副本,说明需要执行ISR收缩。
|
|
|
* **第2步**,再次获取与Leader不同步的副本列表,并把它们从当前ISR中剔除出去,然后计算得出最新的ISR列表。
|
|
|
* **第3步**,调用shrinkIsr方法去更新ZooKeeper上分区的ISR数据以及Broker上元数据缓存。
|
|
|
* **第4步**,尝试更新Leader分区的高水位值。这里有必要检查一下是否可以抬升高水位值的原因在于,如果ISR收缩后只剩下Leader副本一个了,那么高水位值的更新就不再受那么多限制了。
|
|
|
* **第5步**,根据上一步的结果,来尝试解锁之前不满足条件的延迟操作。
|
|
|
|
|
|
我把这个执行过程,梳理到了一张流程图中:
|
|
|
|
|
|
|
|
|
|
|
|
### maybePropagateIsrChanges方法
|
|
|
|
|
|
ISR收缩之后,ReplicaManager还需要将这个操作的结果传递给集群的其他Broker,以同步这个操作的结果。这是由ISR通知事件来完成的。
|
|
|
|
|
|
在ReplicaManager类中,方法maybePropagateIsrChanges专门负责创建ISR通知事件。这也是由一个异步线程定期完成的,代码如下:
|
|
|
|
|
|
```
|
|
|
scheduler.schedule("isr-change-propagation", maybePropagateIsrChanges _, period = 2500L, unit = TimeUnit.MILLISECONDS)
|
|
|
|
|
|
```
|
|
|
|
|
|
接下来,我们看下maybePropagateIsrChanges方法的代码:
|
|
|
|
|
|
```
|
|
|
def maybePropagateIsrChanges(): Unit = {
|
|
|
val now = System.currentTimeMillis()
|
|
|
isrChangeSet synchronized {
|
|
|
// ISR变更传播的条件,需要同时满足:
|
|
|
// 1. 存在尚未被传播的ISR变更
|
|
|
// 2. 最近5秒没有任何ISR变更,或者自上次ISR变更已经有超过1分钟的时间
|
|
|
if (isrChangeSet.nonEmpty &&
|
|
|
(lastIsrChangeMs.get() + ReplicaManager.IsrChangePropagationBlackOut < now ||
|
|
|
lastIsrPropagationMs.get() + ReplicaManager.IsrChangePropagationInterval < now)) {
|
|
|
// 创建ZooKeeper相应的Znode节点
|
|
|
zkClient.propagateIsrChanges(isrChangeSet)
|
|
|
// 清空isrChangeSet集合
|
|
|
isrChangeSet.clear()
|
|
|
// 更新最近ISR变更时间戳
|
|
|
lastIsrPropagationMs.set(now)
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
可以看到,maybePropagateIsrChanges方法的逻辑也比较简单。我来概括下其执行逻辑。
|
|
|
|
|
|
首先,确定ISR变更传播的条件。这里需要同时满足两点:
|
|
|
|
|
|
* 一是, 存在尚未被传播的ISR变更;
|
|
|
* 二是, 最近5秒没有任何ISR变更,或者自上次ISR变更已经有超过1分钟的时间。
|
|
|
|
|
|
一旦满足了这两个条件,代码会创建ZooKeeper相应的Znode节点;然后,清空isrChangeSet集合;最后,更新最近ISR变更时间戳。
|
|
|
|
|
|
## 总结
|
|
|
|
|
|
今天,我们重点学习了ReplicaManager类的分区和副本管理功能,以及ISR管理。我们再完整地梳理下ReplicaManager类的核心功能和方法。
|
|
|
|
|
|
* 分区/副本管理。ReplicaManager类的核心功能是,应对Broker端接收的LeaderAndIsrRequest请求,并将请求中的分区信息抽取出来,让所在Broker执行相应的动作。
|
|
|
* becomeLeaderOrFollower方法。它是应对LeaderAndIsrRequest请求的入口方法。它会将请求中的分区划分成两组,分别调用makeLeaders和makeFollowers方法。
|
|
|
* makeLeaders方法。它的作用是让Broker成为指定分区Leader副本。
|
|
|
* makeFollowers方法。它的作用是让Broker成为指定分区Follower副本的方法。
|
|
|
* ISR管理。ReplicaManager类提供了ISR收缩和定期传播ISR变更通知的功能。
|
|
|
|
|
|
|
|
|
|
|
|
掌握了这些核心知识点,你差不多也就掌握了绝大部分的副本管理器功能,比如说Broker如何成为分区的Leader副本和Follower副本,以及ISR是如何被管理的。
|
|
|
|
|
|
你可能也发现了,有些非核心小功能我们今天并没有展开,比如Broker上的元数据缓存是怎么回事。下一节课,我将带你深入到这个缓存当中,去看看它到底是什么。
|
|
|
|
|
|
## 课后讨论
|
|
|
|
|
|
maybePropagateIsrChanges源码中,有个isrChangeSet字段。你知道它是在哪里被更新的吗?
|
|
|
|
|
|
欢迎在留言区写下你的思考和答案,跟我交流讨论,也欢迎你把今天的内容分享给你的朋友。
|
|
|
|