|
|
# 答疑篇:加餐篇思考题答案合集
|
|
|
|
|
|
你好,我是朱晔。
|
|
|
|
|
|
今天,我们继续一起分析这门课的“不定期加餐”篇中5讲的课后思考题。这些题目涉及了Java 8基础知识、定位和分析应用问题相关的几大知识点。
|
|
|
|
|
|
接下来,我们就一一具体分析吧。
|
|
|
|
|
|
### [加餐1 | 带你吃透课程中Java 8的那些重要知识点(一)](https://time.geekbang.org/column/article/212374)
|
|
|
|
|
|
**问题:**对于并行流部分的并行消费处理1到100的例子,如果把forEach替换为forEachOrdered,你觉得会发生什么呢?
|
|
|
|
|
|
答:forEachOrdered 会让parallelStream丧失部分的并行能力,主要原因是forEach遍历的逻辑无法并行起来(需要按照循序遍历,无法并行)。
|
|
|
|
|
|
我们来比较下面的三种写法:
|
|
|
|
|
|
```
|
|
|
//模拟消息数据需要1秒时间
|
|
|
private static void consume(int i) {
|
|
|
try {
|
|
|
TimeUnit.SECONDS.sleep(1);
|
|
|
} catch (InterruptedException e) {
|
|
|
e.printStackTrace();
|
|
|
}
|
|
|
System.out.print(i);
|
|
|
}
|
|
|
//模拟过滤数据需要1秒时间
|
|
|
private static boolean filter(int i) {
|
|
|
try {
|
|
|
TimeUnit.SECONDS.sleep(1);
|
|
|
} catch (InterruptedException e) {
|
|
|
e.printStackTrace();
|
|
|
}
|
|
|
return i % 2 == 0;
|
|
|
}
|
|
|
@Test
|
|
|
public void test() {
|
|
|
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", String.valueOf(10));
|
|
|
|
|
|
StopWatch stopWatch = new StopWatch();
|
|
|
stopWatch.start("stream");
|
|
|
stream();
|
|
|
stopWatch.stop();
|
|
|
stopWatch.start("parallelStream");
|
|
|
parallelStream();
|
|
|
stopWatch.stop();
|
|
|
stopWatch.start("parallelStreamForEachOrdered");
|
|
|
parallelStreamForEachOrdered();
|
|
|
stopWatch.stop();
|
|
|
System.out.println(stopWatch.prettyPrint());
|
|
|
}
|
|
|
//filtre和forEach串行
|
|
|
private void stream() {
|
|
|
IntStream.rangeClosed(1, 10)
|
|
|
.filter(ForEachOrderedTest::filter)
|
|
|
.forEach(ForEachOrderedTest::consume);
|
|
|
}
|
|
|
//filter和forEach并行
|
|
|
private void parallelStream() {
|
|
|
IntStream.rangeClosed(1, 10).parallel()
|
|
|
.filter(ForEachOrderedTest::filter)
|
|
|
.forEach(ForEachOrderedTest::consume);
|
|
|
}
|
|
|
//filter并行而forEach串行
|
|
|
private void parallelStreamForEachOrdered() {
|
|
|
IntStream.rangeClosed(1, 10).parallel()
|
|
|
.filter(ForEachOrderedTest::filter)
|
|
|
.forEachOrdered(ForEachOrderedTest::consume);
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
得到输出:
|
|
|
|
|
|
```
|
|
|
---------------------------------------------
|
|
|
ns % Task name
|
|
|
---------------------------------------------
|
|
|
15119607359 065% stream
|
|
|
2011398298 009% parallelStream
|
|
|
6033800802 026% parallelStreamForEachOrdered
|
|
|
|
|
|
```
|
|
|
|
|
|
从输出中,我们可以看到:
|
|
|
|
|
|
* stream方法的过滤和遍历全部串行执行,总时间是10秒+5秒=15秒;
|
|
|
* parallelStream方法的过滤和遍历全部并行执行,总时间是1秒+1秒=2秒;
|
|
|
* parallelStreamForEachOrdered方法的过滤并行执行,遍历串行执行,总时间是1秒+5秒=6秒。
|
|
|
|
|
|
### [加餐2 | 带你吃透课程中Java 8的那些重要知识点(二)](https://time.geekbang.org/column/article/212398)
|
|
|
|
|
|
**问题1:**使用Stream可以非常方便地对List做各种操作,那有没有什么办法可以实现在整个过程中观察数据变化呢?比如,我们进行filter+map操作,如何观察filter后map的原始数据呢?
|
|
|
|
|
|
答:要想观察使用Stream对List的各种操作的过程中的数据变化,主要有下面两个办法。
|
|
|
|
|
|
第一,**使用peek方法**。比如如下代码,我们对数字1~10进行了两次过滤,分别是找出大于5的数字和找出偶数,我们通过peek方法把两次过滤操作之前的原始数据保存了下来:
|
|
|
|
|
|
```
|
|
|
List<Integer> firstPeek = new ArrayList<>();
|
|
|
List<Integer> secondPeek = new ArrayList<>();
|
|
|
List<Integer> result = IntStream.rangeClosed(1, 10)
|
|
|
.boxed()
|
|
|
.peek(i -> firstPeek.add(i))
|
|
|
.filter(i -> i > 5)
|
|
|
.peek(i -> secondPeek.add(i))
|
|
|
.filter(i -> i % 2 == 0)
|
|
|
.collect(Collectors.toList());
|
|
|
System.out.println("firstPeek:" + firstPeek);
|
|
|
System.out.println("secondPeek:" + secondPeek);
|
|
|
System.out.println("result:" + result);
|
|
|
|
|
|
```
|
|
|
|
|
|
最后得到输出,可以看到第一次过滤之前是数字1~10,一次过滤后变为6~10,最终输出6、8、10三个数字:
|
|
|
|
|
|
```
|
|
|
firstPeek:[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
|
|
|
secondPeek:[6, 7, 8, 9, 10]
|
|
|
result:[6, 8, 10]
|
|
|
|
|
|
```
|
|
|
|
|
|
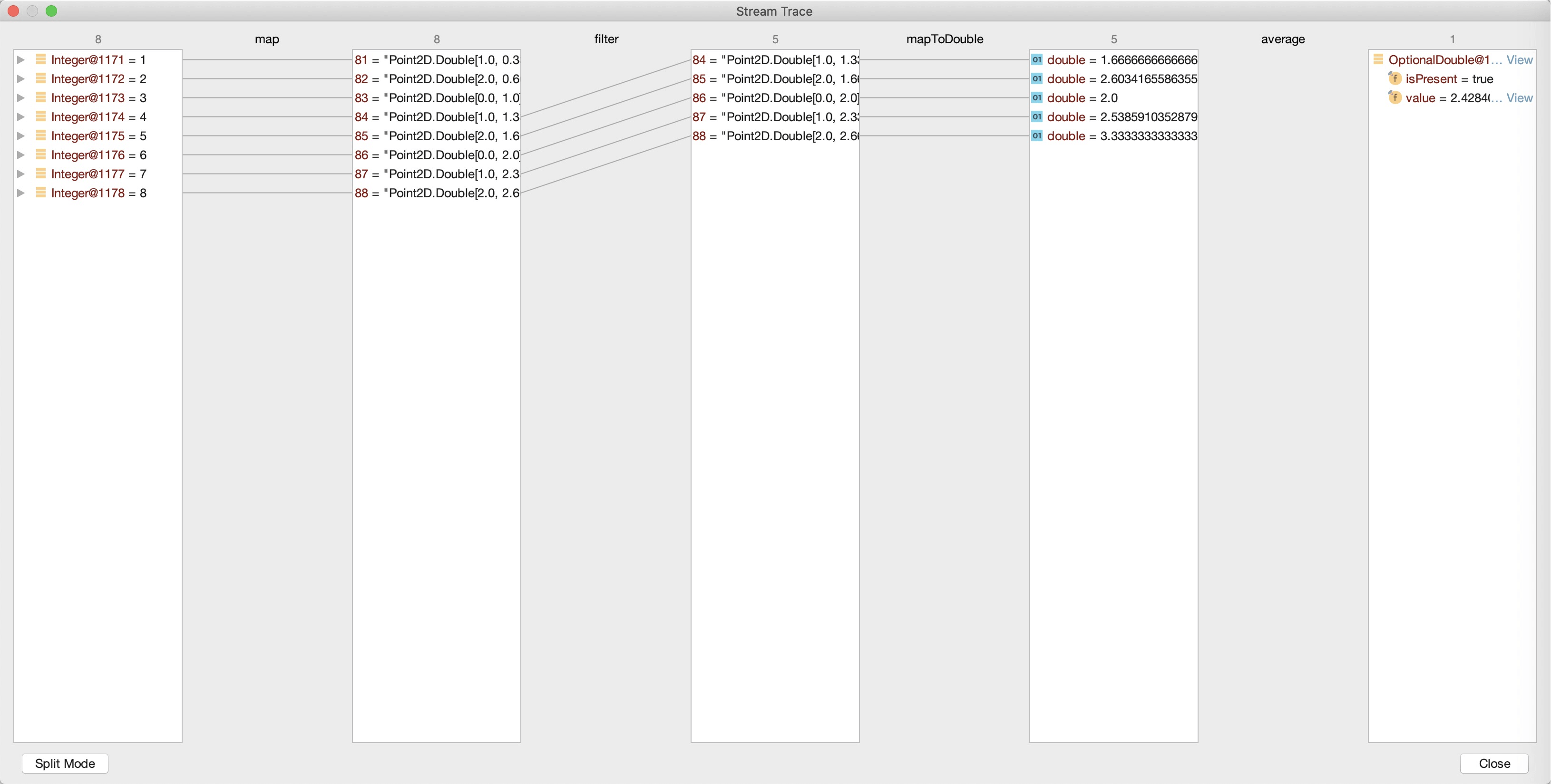
第二,**借助IDEA的Stream的调试功能**。详见[这里](https://www.jetbrains.com/help/idea/analyze-java-stream-operations.html),效果类似下图:
|
|
|
|
|
|
|
|
|
|
|
|
**问题2:**Collectors类提供了很多现成的收集器,那我们有没有办法实现自定义的收集器呢?比如,实现一个MostPopularCollector,来得到List中出现次数最多的元素,满足下面两个测试用例:
|
|
|
|
|
|
```
|
|
|
assertThat(Stream.of(1, 1, 2, 2, 2, 3, 4, 5, 5).collect(new MostPopularCollector<>()).get(), is(2));
|
|
|
assertThat(Stream.of('a', 'b', 'c', 'c', 'c', 'd').collect(new MostPopularCollector<>()).get(), is('c'));
|
|
|
|
|
|
```
|
|
|
|
|
|
答:我来说下我的实现思路和方式:通过一个HashMap来保存元素的出现次数,最后在收集的时候找出Map中出现次数最多的元素:
|
|
|
|
|
|
```
|
|
|
public class MostPopularCollector<T> implements Collector<T, Map<T, Integer>, Optional<T>> {
|
|
|
//使用HashMap保存中间数据
|
|
|
@Override
|
|
|
public Supplier<Map<T, Integer>> supplier() {
|
|
|
return HashMap::new;
|
|
|
}
|
|
|
//每次累积数据则累加Value
|
|
|
@Override
|
|
|
public BiConsumer<Map<T, Integer>, T> accumulator() {
|
|
|
return (acc, elem) -> acc.merge(elem, 1, (old, value) -> old + value);
|
|
|
}
|
|
|
//合并多个Map就是合并其Value
|
|
|
@Override
|
|
|
public BinaryOperator<Map<T, Integer>> combiner() {
|
|
|
return (a, b) -> Stream.concat(a.entrySet().stream(), b.entrySet().stream())
|
|
|
.collect(Collectors.groupingBy(Map.Entry::getKey, summingInt(Map.Entry::getValue)));
|
|
|
}
|
|
|
//找出Map中Value最大的Key
|
|
|
@Override
|
|
|
public Function<Map<T, Integer>, Optional<T>> finisher() {
|
|
|
return (acc) -> acc.entrySet().stream()
|
|
|
.reduce(BinaryOperator.maxBy(Map.Entry.comparingByValue()))
|
|
|
.map(Map.Entry::getKey);
|
|
|
}
|
|
|
|
|
|
@Override
|
|
|
public Set<Characteristics> characteristics() {
|
|
|
return Collections.emptySet();
|
|
|
}
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
### [加餐3 | 定位应用问题,排错套路很重要](https://time.geekbang.org/column/article/221982)
|
|
|
|
|
|
**问题:**如果你现在打开一个App后发现首页展示了一片空白,那这到底是客户端兼容性的问题,还是服务端的问题呢?如果是服务端的问题,又如何进一步细化定位呢?你有什么分析思路吗?
|
|
|
|
|
|
答:首先,我们需要区分客户端还是服务端错误。我们可以先从客户端下手,排查看看是否是服务端问题,也就是通过抓包来看服务端的返回(一般而言客户端发布之前会经过测试,而且无法随时变更,所以服务端出错的可能性会更大一点)。因为一个客户端程序可能对应几百个服务端接口,先从客户端(发出请求的根源)开始排查问题,更容易找到方向。
|
|
|
|
|
|
服务端没有返回正确的输出,那么就需要继续排查服务端接口或是上层的负载均衡了,排查方式为:
|
|
|
|
|
|
* 查看负载均衡(比如Nginx)的日志;
|
|
|
* 查看服务端日志;
|
|
|
* 查看服务端监控。
|
|
|
|
|
|
如果服务端返回了正确的输出,那么要么是由于客户端的Bug,要么就是外部配置等问题了,排查方式为:
|
|
|
|
|
|
* 查看客户端报错(一般而言,客户端都会对接SAAS的异常服务);
|
|
|
* 直接本地启动客户端调试。
|
|
|
|
|
|
### [加餐4 | 分析定位Java问题,一定要用好这些工具(一)](https://time.geekbang.org/column/article/224816)
|
|
|
|
|
|
**问题1:**JDK中还有一个jmap工具,我们会使用jmap -dump命令来进行堆转储。那么,这条命令和jmap -dump:live有什么区别呢?你能否设计一个实验,来证明下它们的区别呢?
|
|
|
|
|
|
答:jmap -dump命令是转储堆中的所有对象,而jmap -dump:live是转储堆中所有活着的对象。因为,jmap -dump:live会触发一次FullGC。
|
|
|
|
|
|
写一个程序测试一下:
|
|
|
|
|
|
```
|
|
|
@SpringBootApplication
|
|
|
@Slf4j
|
|
|
public class JMapApplication implements CommandLineRunner {
|
|
|
|
|
|
//-Xmx512m -Xms512m
|
|
|
public static void main(String[] args) {
|
|
|
SpringApplication.run(JMapApplication.class, args);
|
|
|
}
|
|
|
@Override
|
|
|
public void run(String... args) throws Exception {
|
|
|
while (true) {
|
|
|
//模拟产生字符串,每次循环后这个字符串就会失去引用可以GC
|
|
|
String payload = IntStream.rangeClosed(1, 1000000)
|
|
|
.mapToObj(__ -> "a")
|
|
|
.collect(Collectors.joining("")) + UUID.randomUUID().toString();
|
|
|
log.debug(payload);
|
|
|
TimeUnit.MILLISECONDS.sleep(1);
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
然后,使用jmap不带和带live分别生成两个转储:
|
|
|
|
|
|
```
|
|
|
jmap -dump:format=b,file=nolive.hprof 57323
|
|
|
jmap -dump:live,format=b,file=live.hprof 5732
|
|
|
|
|
|
```
|
|
|
|
|
|
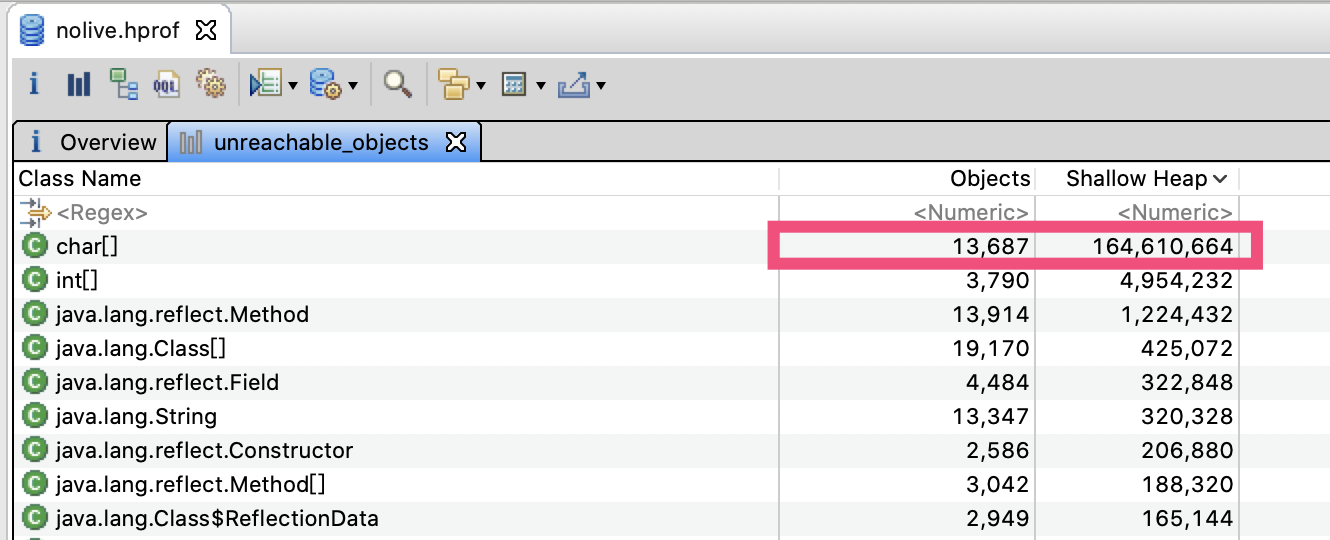
可以看到,nolive这个转储的不可到达对象包含了164MB char\[\](可以认为基本是字符串):
|
|
|
|
|
|
|
|
|
|
|
|
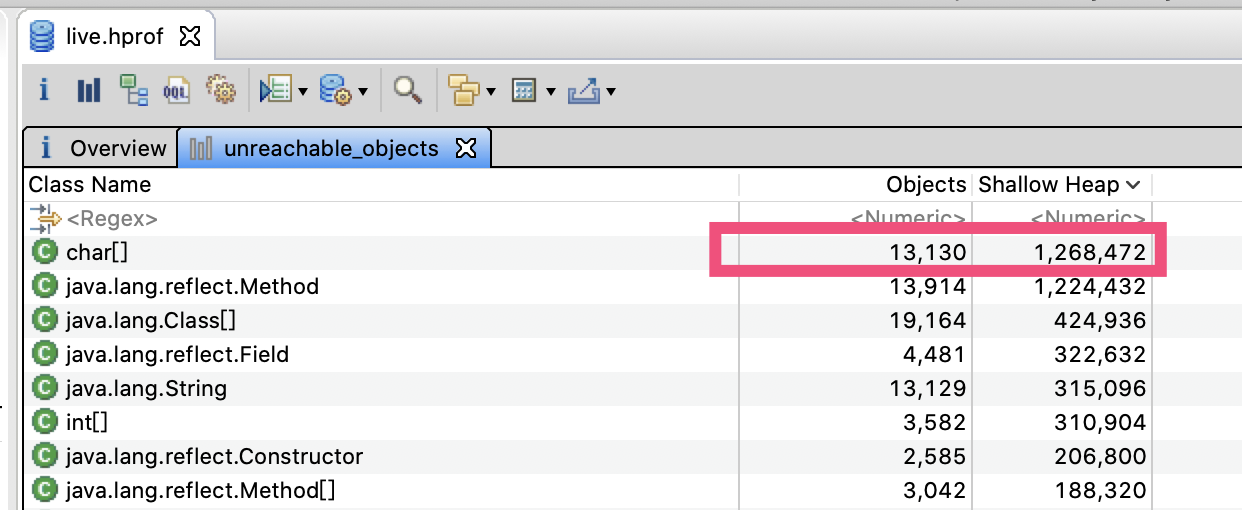
而live这个转储只有1.3MB的char\[\],说明程序循环中的这些字符串都被GC了:
|
|
|
|
|
|
|
|
|
|
|
|
**问题2:**你有没有想过,客户端是如何和MySQL进行认证的呢?你能否对照[MySQL的文档](https://dev.mysql.com/doc/internals/en/connection-phase-packets.html#packet-Protocol::Handshake),使用Wireshark观察分析这一过程呢?
|
|
|
|
|
|
答:一般而言,认证(握手)过程分为三步。
|
|
|
|
|
|
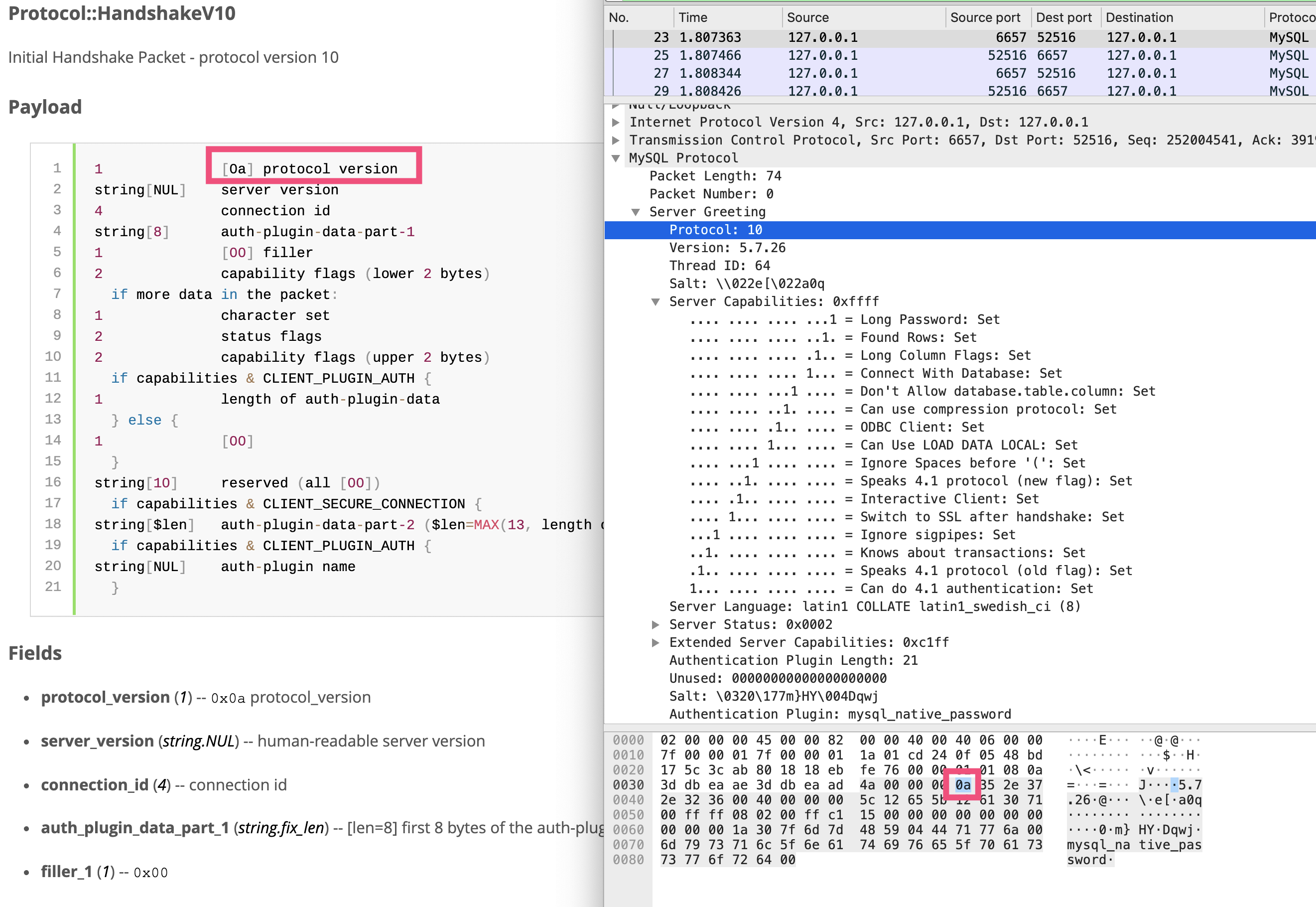
首先,服务端给客户端主动发送握手消息:
|
|
|
|
|
|
|
|
|
|
|
|
Wireshark已经把消息的字段做了解析,你可以对比[官方文档](https://dev.mysql.com/doc/internals/en/connection-phase-packets.html#packet-Protocol::Handshake)的协议格式一起查看。HandshakeV10消息体的第一个字节是消息版本0a,见图中红色框标注的部分。前面四个字节是MySQL的消息头,其中前三个字节是消息体长度(16进制4a=74字节),最后一个字节是消息序列号。
|
|
|
|
|
|
然后,客户端给服务端回复的HandshakeResponse41消息体,包含了登录的用户名和密码:
|
|
|
|
|
|
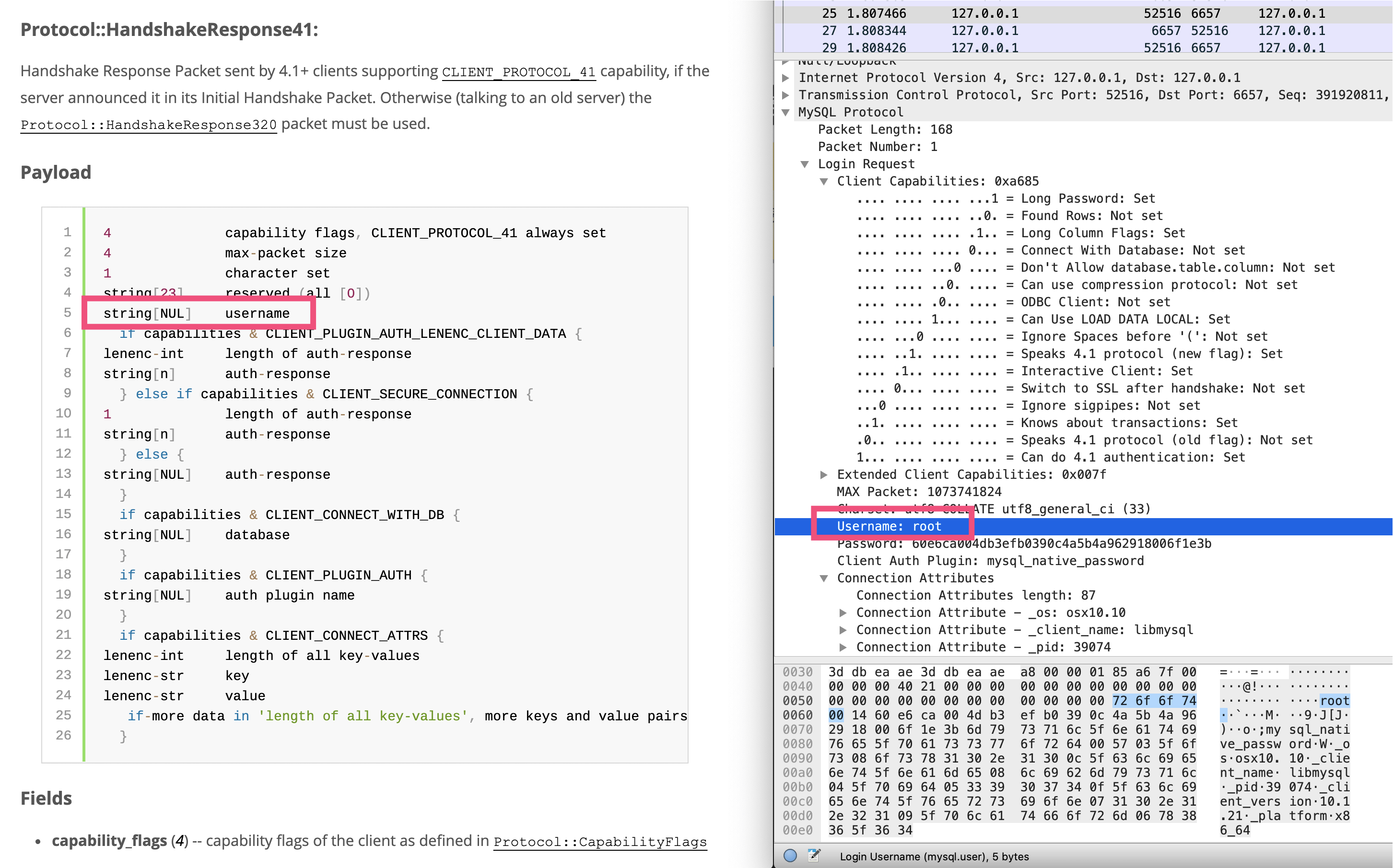
|
|
|
|
|
|
可以看到,用户名是string\[NUL\]类型的,说明字符串以00结尾代表字符串结束。关于MySQL协议中的字段类型,你可以参考[这里](https://dev.mysql.com/doc/internals/en/string.html)。
|
|
|
|
|
|
最后,服务端回复的OK消息,代表握手成功:
|
|
|
|
|
|
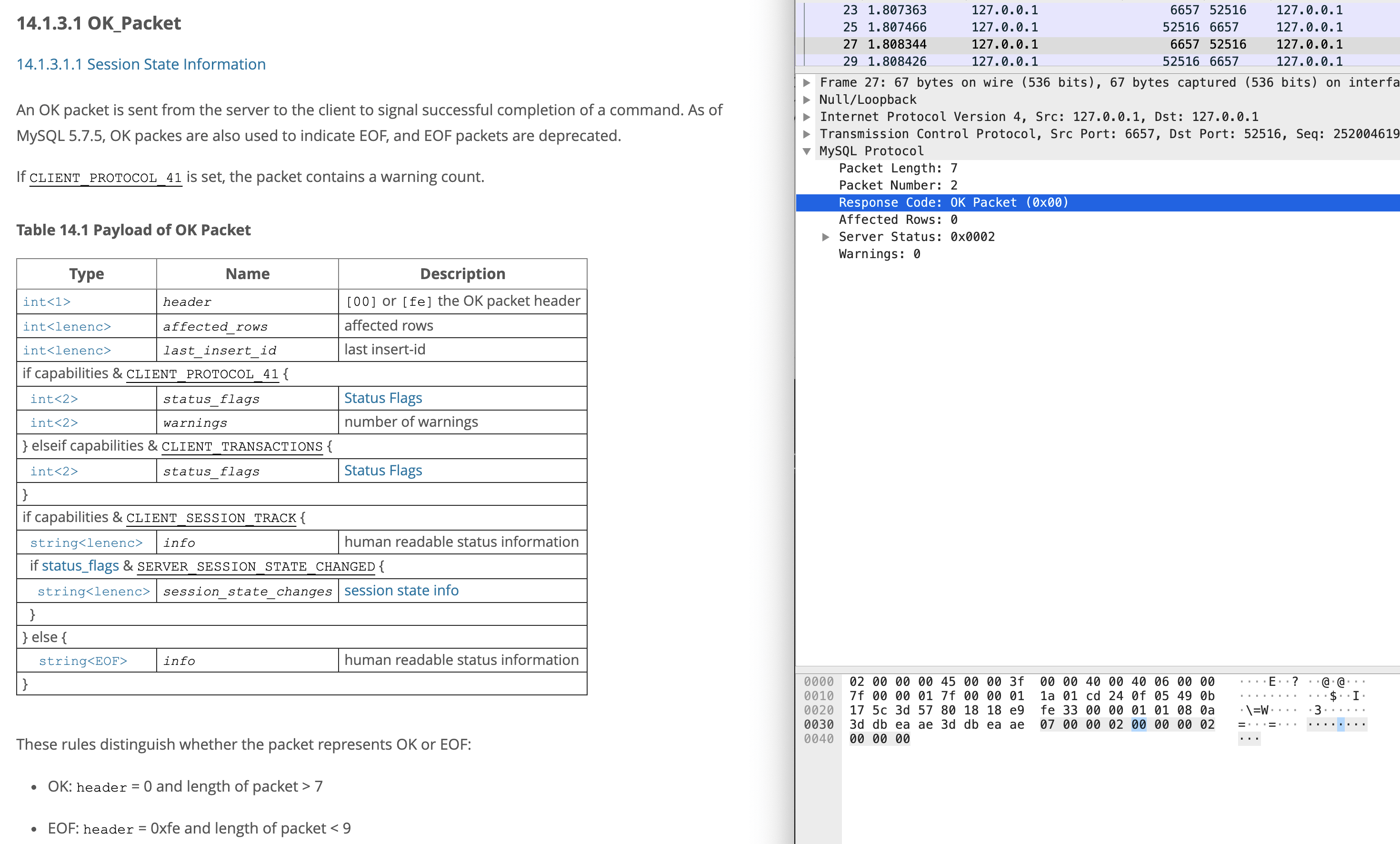
|
|
|
|
|
|
这样分析下来,我们可以发现使用Wireshark观察客户端和MySQL的认证过程,非常方便。而如果不借助Wireshark工具,我们只能一个字节一个字节地对照协议文档分析内容。
|
|
|
|
|
|
其实,各种CS系统定义的通讯协议本身并不深奥,甚至可以说对着协议文档写通讯客户端是体力活。你可以继续按照这里我说的方式,结合抓包和文档,分析一下MySQL的查询协议。
|
|
|
|
|
|
### [加餐5 | 分析定位Java问题,一定要用好这些工具(二)](https://time.geekbang.org/column/article/230534)
|
|
|
|
|
|
**问题:**Arthas还有一个强大的热修复功能。比如,遇到高CPU问题时,我们定位出是管理员用户会执行很多次MD5,消耗大量CPU资源。这时,我们可以直接在服务器上进行热修复,步骤是:jad命令反编译代码->使用文本编辑器(比如Vim)直接修改代码->使用sc命令查找代码所在类的ClassLoader->使用redefine命令热更新代码。你可以尝试使用这个流程,直接修复程序(注释doTask方法中的相关代码)吗?
|
|
|
|
|
|
答:Arthas的官方文档有[详细的操作步骤](https://alibaba.github.io/arthas/redefine.html),实现jad->sc->redefine的整个流程,需要注意的是:
|
|
|
|
|
|
* redefine命令和jad/watch/trace/monitor/tt等命令会冲突。执行完redefine之后,如果再执行上面提到的命令,则会把redefine的字节码重置。 原因是,JDK本身redefine和Retransform是不同的机制,同时使用两种机制来更新字节码,只有最后的修改会生效。
|
|
|
* 使用redefine不允许新增或者删除field/method,并且运行中的方法不会立即生效,需要等下次运行才能生效。
|
|
|
|
|
|
以上,就是咱们这门课里面5篇加餐文章的思考题答案了。至此,咱们这个课程的“答疑篇”模块也就结束了。
|
|
|
|
|
|
关于这些题目,以及背后涉及的知识点,如果你还有哪里感觉不清楚的,欢迎在评论区与我留言,也欢迎你把今天的内容分享给你的朋友或同事,一起交流。
|
|
|
|