286 lines
18 KiB
Markdown
286 lines
18 KiB
Markdown
# 23|微服务拆分(三):如何拆分存储过程?
|
||
|
||
你好,我是姚琪琳。
|
||
|
||
上节课我们学习了解耦数据库表的三种方法,单体架构拆分的挑战又下一城。
|
||
|
||
虽然在遗留系统中,用Java直接调用SQL语句十分常见,但真正的大Boss,是调用链很深的存储过程。
|
||
|
||
在十几二十年前,将业务逻辑写在数据库的存储过程或函数中是一种潮流。虽然这种潮流有着当时的历史背景,但在现在看来显然是“最差实践”了。如果遗留系统中存在大量的存储过程,该如何应对呢?我们今天就来学习这方面的内容。
|
||
|
||
## 将存储过程或函数封装成API
|
||
|
||
在遗留系统中,存储过程和函数往往用来封装复杂的业务逻辑。比如“审核核保申请”这样一个功能,可能会修改二十多张表。这里的表有的与核保相关,也有的与核保关系并不大,比如保单表。
|
||
|
||
然而用存储过程或函数来编写业务逻辑的风气一旦形成,很多简单的业务逻辑,比如对单张或少量表的修改,开发人员也会自然而然放到存储过程或函数里。
|
||
|
||
我曾经见过用数据库函数来比较时间前后关系的自定义函数,明明任何一门编程语言都提供了这种基本功能,但当时的开发人员却偏偏钟爱SQL,真的是难以理解。
|
||
|
||
这样一来,真正的代码反而变成了薄薄的一层胶水,真的是面向数据库编程啊。看到这你先别忙着叹气,我们一起理理思路,争取“分而治之”。
|
||
|
||
对于十分简单的存储过程或函数(如比较时间前后关系),我们可以将它们改造成代码。这个改造过程不会太难,我就不展开说了。
|
||
|
||
对于只涉及少量表的存储过程和函数,我们首先要分析它里面的表的所有权属于谁。主要分成三种情况。
|
||
|
||
* 第一种情况:如果全都是与核保业务相关的表,就可以把整个存储过程或函数复制到核保库中,让核保服务的代码直接访问。
|
||
|
||
* 第二种情况:如果全都是非核保业务相关的表,就可以**将其封装为数据API**,让核保服务调用,具体方式和步骤与上节课的第一招“用API调用取代连表查询”类似。
|
||
|
||
* 第三种情况:如果既包含与核保业务相关的表,又包含不相关的表,就要先将其拆分成相关和不相关的两部分存储过程或函数,再分别应用上面两种处理方式来处理。
|
||
|
||
|
||
在拆分存储过程和函数的时候,必然会涉及到一些修改。特别是拆分出来的多个存储过程或函数之间,会依赖彼此数据的情况。
|
||
|
||
比如下面这个与审核核保申请相关的存储过程(为了突出重点,我做了一定简化):
|
||
|
||
```sql
|
||
PROCEDURE APPROVE_UNDERWRITE(I_UW_ID IN NUMBER) AS
|
||
V_UNDERWRITE_APPLICATION TBL_UNDERWRITE_APPLICATION%ROWTYPE;
|
||
BEGIN
|
||
-- 更新核保申请表
|
||
UPDATE TBL_UNDERWRITE_APPLICATION
|
||
SET UNDERWRITE_STATUS = 2
|
||
-- 其他字段赋值
|
||
WHERE UNDERWRITE_ID = I_UW_ID;
|
||
SELECT * INTO V_UNDERWRITE_APPLICATION WHERE UNDERWRITE_ID = I_UW_ID;
|
||
-- 更新保单表
|
||
UPDATE TBL_POLICY
|
||
SET POLICY_STATUS = V_UNDERWRITE_APPLICATION.POLICY_STATUS
|
||
-- 其他字段赋值
|
||
WHERE POLICY_ID = V_UNDERWRITE_APPLICATION.POLICY_ID
|
||
END APPROVE_UNDERWRITE;
|
||
|
||
```
|
||
|
||
这段存储过程大体上可以拆分为两个阶段,第一个阶段是修改核保申请表,第二个阶段是用修改后的核保申请数据来更新保单表。如果存储过程中的SQL语句和方法一样,也存在代码交织、混乱不堪的情况,你可以复习一下[第九节课](https://time.geekbang.org/column/article/513599)讲的**拆分阶段**模式,它也可以应用到存储过程的重构中。
|
||
|
||
这个存储过程原本是位于单体数据库中的,我们要对其进行拆分,就要将访问核保表的部分迁移到核保库中:
|
||
|
||
```sql
|
||
-- 核保库中新增的存储过程
|
||
PROCEDURE APPROVE_UNDERWRITE(I_UW_ID IN NUMBER) AS
|
||
BEGIN
|
||
UPDATE TBL_UNDERWRITE_APPLICATION
|
||
SET UNDERWRITE_STATUS = 2
|
||
-- 其他字段赋值
|
||
WHERE UNDERWRITE_ID = I_UW_ID;
|
||
END APPROVE_UNDERWRITE;
|
||
|
||
```
|
||
|
||
但是在原存储过程中就不能直接查询核保申请表了,需要对它进行改写,在调用该存储过程的地方通过API获得核保申请数据,然后再将核保申请数据作为参数传递给这个存储过程。如果数据库支持PL/SQL,我们可以**引入对象类型来进行参数传递**。
|
||
|
||
```sql
|
||
-- 新建的对象类型
|
||
CREATE OR REPLACE TYPE OBJ_UNDERWRITE_APPLICATION AS OBJECT
|
||
(
|
||
UNDERWRITE_ID NUMBER, POLICY_ID NUMBER, UNDERWRITE_STATUS VARCHAR2(1), -- 其他字段
|
||
CONSTRUCTOR FUNCTION OBJ_UNDERWRITE_APPLICATION RETURN SELF AS RESULT,
|
||
CONSTRUCTOR FUNCTION OBJ_UNDERWRITE_APPLICATION(POLICY_ID IN NUMBER, POLICY_ID IN NUMBER, UNDERWRITE_STATUS IN VARCHAR2) RETURN SELF AS RESULT
|
||
);
|
||
-- 单体库中复制出来的原存储过程修改之后
|
||
PROCEDURE APPROVE_UNDERWRITE(V_UNDERWRITE_APPLICATION AS OBJ_UNDERWRITE_APPLICATION)) AS
|
||
BEGIN
|
||
UPDATE TBL_POLICY
|
||
SET POLICY_STATUS = V_UNDERWRITE_APPLICATION.POLICY_STATUS
|
||
-- 其他字段赋值
|
||
WHERE POLICY_ID = V_UNDERWRITE_APPLICATION.POLICY_ID
|
||
END APPROVE_UNDERWRITE;
|
||
|
||
```
|
||
|
||
别忘了,我们要把原来的存储过程复制一份出来,不能在原存储过程上直接修改,否则就无法回退了。
|
||
|
||
这样一来,调用这个存储过程的代码就变成了这样:
|
||
|
||
```java
|
||
-- 调用上面存储过程的Java代码
|
||
Object[] underwriteApplicationFields = new Object[] { underwriteApplicationDto.getPolicyId(), /*...*/ };
|
||
Connection connection = getConnection();
|
||
-- 在Java中,与对象类型对应的是Struct
|
||
Struct underwriteApplicationStruct = connection.createStruct("OBJ_UNDERWRITE_APPLICATION", underwriteApplicationFields);
|
||
Statement statement = connection.prepareCall("{ CALL APPROVE_UNDERWRITE(:underwriteApplication) }");
|
||
statement.setObject("underwriteApplication", underwriteApplicationStruct);
|
||
statement.execute();
|
||
|
||
```
|
||
|
||
以上存储过程我们都可以先在单体数据库中实现,然后在核保库中建立同义词,来访问单体库中的存储过程。
|
||
|
||
对于表很少的简单情况,还算比较好拆分。当表又多,关系又错综复杂的时候,就比较棘手了。我们接下来就看看这种情况如何应对。
|
||
|
||
## 拆分复杂存储过程或函数
|
||
|
||
遗留系统中的存储过程和函数往往是很复杂的,有的时候会涉及到几十甚至上百张表也不为过。我们分情况讨论一下要如何进行拆分。
|
||
|
||
**第一种情况是SQL的执行彼此之间没有前后顺序关系**。有些存储过程和函数虽然也涉及到很多表,但实际上它们的执行顺序是可以调换的,彼此之间没有依赖关系,先执行谁后执行谁不会影响最终的结果。
|
||
|
||
这时候只需要完成下面四步即可:
|
||
|
||
1.调整SQL的执行顺序,按数据的所有权进行分组,也就是将涉及单体库表的和涉及核保库表的SQL语句分组;
|
||
|
||
2.从与单体库表相关的SQL语句中,提取出一个新的存储过程或函数,并封装成数据API;
|
||
|
||
3.在核保服务的防腐层代码中,分别调用数据API和只包含核保库表的那个存储过程或函数(因为它们的执行顺序无关,所以这里调用的前后顺序也无所谓);
|
||
|
||
4.如果涉及到参数传递,就引入对象类型。
|
||
|
||
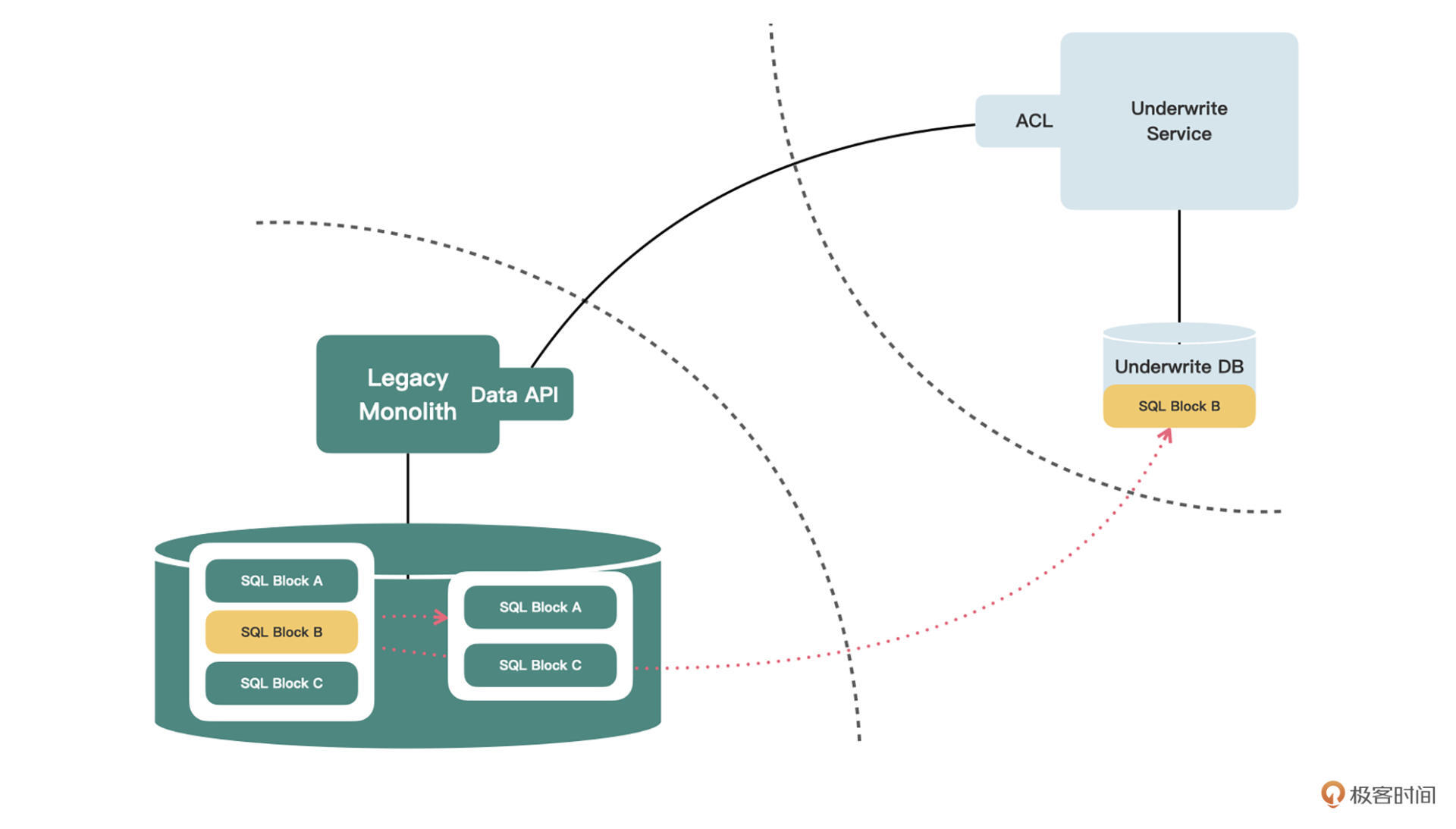
|
||
|
||
我们仍然拿审核核保申请的存储过程举例,假设它由以下三个子存储过程组成,各个子存储过程之间没有先后顺序:
|
||
|
||
```sql
|
||
PROCEDURE APPROVE_UNDERWRITE(I_UW_ID IN NUMBER) AS
|
||
V_POLICY_ID NUMBER;
|
||
BEGIN
|
||
UPDATE_POLICY_FOR_APPROVAL(I_UW_ID);
|
||
SELECT POLICY_ID INTO V_POLICY_ID FROM TBL_UNDERWRITE_APPLICATION WHERE UNDERWRITE_ID = I_UW_ID;
|
||
UPDATE_UNDERWRITE_APPLICATION_FOR_APPROVAL(V_POLICY_ID);
|
||
UPDATE_POLICY_PRODUCT_FOR_APPROVAL(V_POLICY_ID);
|
||
END APPROVE_UNDERWRITE;
|
||
|
||
```
|
||
|
||
按上面的步骤改写完之后就变成了两个,分别位于单体和核保的数据库中:
|
||
|
||
```sql
|
||
-- 单体库中的存储过程
|
||
PROCEDURE APPROVE_UNDERWRITE(I_POLICY_ID IN NUMBER) AS
|
||
BEGIN
|
||
UPDATE_POLICY_FOR_APPROVAL(I_POLICY_ID);
|
||
UPDATE_POLICY_PRODUCT_FOR_APPROVAL(I_POLICY_ID);
|
||
END FINISH_UNDERWRITE;
|
||
-- 核保库中的存储过程
|
||
PROCEDURE APPROVE_UNDERWRITE(I_UW_ID IN NUMBER) AS
|
||
BEGIN
|
||
UPDATE_UNDERWRITE_APPLICATION_FOR_APPROVAL(I_UW_ID);
|
||
END FINISH_UNDERWRITE;
|
||
|
||
```
|
||
|
||
而核保中的原API就改为了先执行核保内的存储过程,再通过API来调用单体库中的存储过程:
|
||
|
||
```java
|
||
public void approveUnderwrite(long underwriteId) {
|
||
// 调用本地存储过程
|
||
Connection connection = getConnection();
|
||
Statement statement = connection.prepareCall("{ CALL APPROVE_UNDERWRITE(:underwriteId) }");
|
||
statement.setLong("underwriteId", underwriteId);
|
||
statement.execute();
|
||
// 通过API调用远程存储过程
|
||
PolicyServiceProvider policyService = new PolicyServiceProvider();
|
||
policyService.approveUnderwrite(underwriteId);
|
||
}
|
||
|
||
```
|
||
|
||
**第二种情况是SQL的执行有前后顺序关系**,比如后面的SQL会依赖到前面SQL的执行结果。这个时候就相当麻烦,并没有好的解决方案,只能按照下面这样的顺序拆分:
|
||
|
||
1.将众多SQL按数据的所有权拆分成一组一组的小块,每一小块的内部是顺序无关的;
|
||
|
||
2.将这些小块抽取成不同的存储过程或函数;
|
||
|
||
3.将属于单体库的存储过程或函数逐一封装成数据API,将属于核保库的存储过程或函数复制到核保库中;
|
||
|
||
4.然后再按照原存储过程或函数内部的顺序,在核保服务的防腐层代码中去逐个调用这些API和属于核保库的存储过程或函数;
|
||
|
||
5.如果涉及到参数传递,就引入对象类型。
|
||
|
||
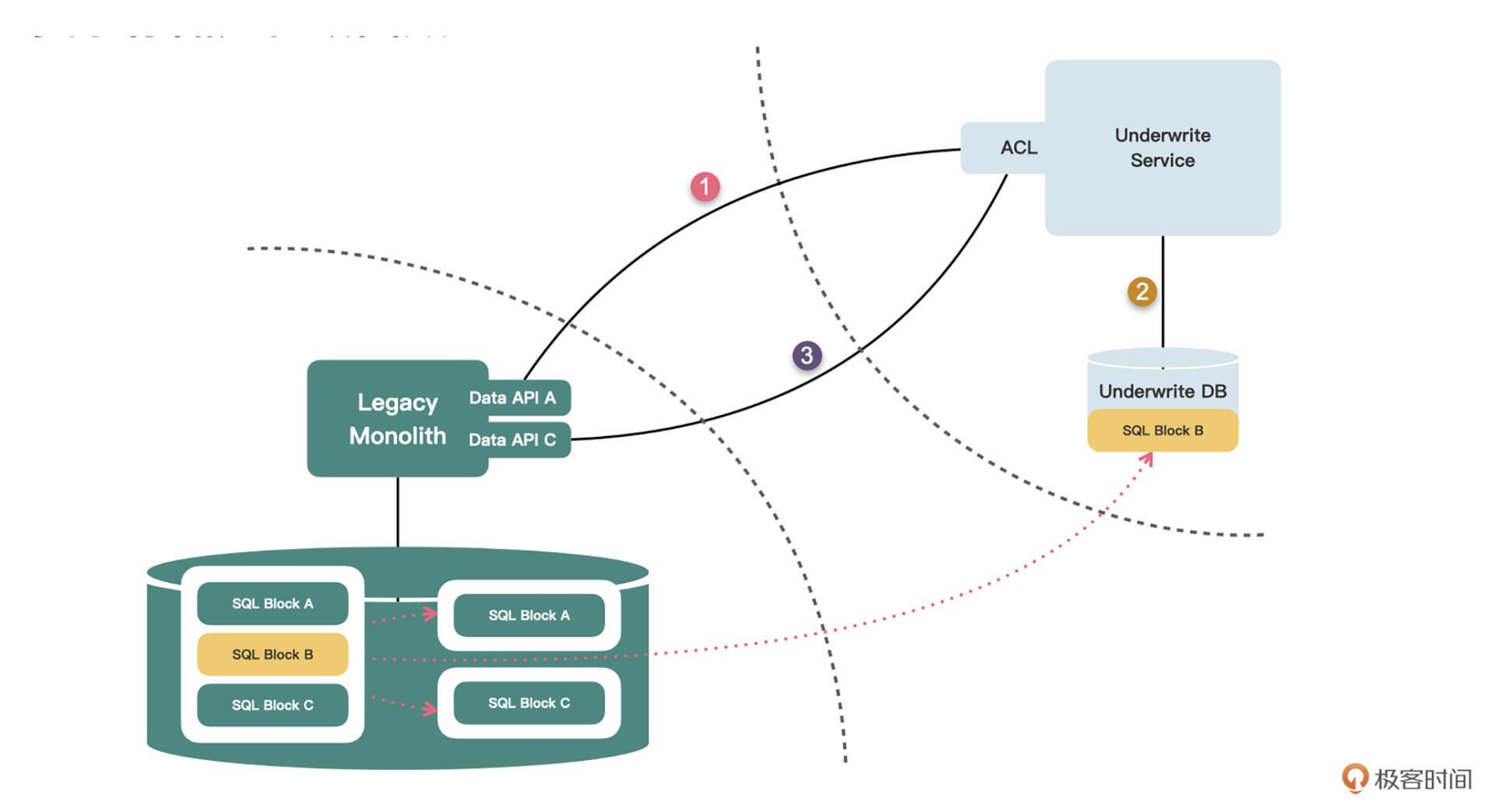
|
||
|
||
对于复杂的存储过程和函数除了拆分本身的工作量外,最重要的就是要确定它们之间的相互依赖关系。对于这一点,并没有非常好的方法,只能耐心加细心。
|
||
|
||
## 用重试来取代回滚
|
||
|
||
在前面介绍的诸多实践中,我们把大量的SQL语句转换成了API调用。表面上看,它们的执行结果是相同的,但实质上我们已经把很多事务性的操作,转换成了非事务性的。比如在审核核保申请时,本来我们是在一个数据库事务中,修改核保申请表和保单表,任何一个修改失败都会导致整个操作的回滚。
|
||
|
||
但这样的修改在解决老问题的同时,也会给我们带来新问题:当把对保单表的修改替换成远程API调用后,情况就变得复杂起来。
|
||
|
||
在代码直接修改完毕后,如果我们不做任何调整,原来的事务所包裹的除了执行SQL的代码之外,还包括了调用远程API的代码。这是应该避免的。因为远程API的调用相对来说是不稳定的,有可能耗时过长,也有可能执行成功了,但由于网络问题返回了错误的响应。前者会导致长事务,后者会导致错误的回滚。这时我们就要把调用API的代码从事务中挪出来。
|
||
|
||
但这样虽然解决了长事务的问题,回滚又变得麻烦了。如果API调用真的失败了,需要回滚前面的SQL,我们可以编写一个补偿性的SQL来对冲它。但如果API调用是假失败,该怎么处理呢?有的时候,我们甚至无从知道到底是真失败还是假失败。
|
||
|
||
作为聪明的开发者,实在解不出答案的时候,我们可以尝试直接“改题目”,也就是回溯问题本身(遵循第一性原理),看看能不能换道题解答。要解决在远程调用失败的情况下本地SQL的回滚问题,不如重新思考一下,这两步操作是否必须在一个事务下?
|
||
|
||
单体系统中的代码为了方便,很多有关、无关的批量SQL操作,都会无脑地放入一个事务中,靠数据库提供的提交和回滚功能来进行流程控制。但这些批量操作是否在业务上必须是事务的,恐怕没有人去深究。我们在改造这样的代码时,不妨来把这一课补上,以方便拆分事务。
|
||
|
||
还拿审核核保申请这个功能来举例。在修改了核保申请的状态后,要在保单表中也回写一个状态,以前这两步操作位于同一个事务中。但仔细思考并且与业务人员讨论后,我们就会发现,保单表状态是否写入成功,不应该影响当前核保申请的正常核保业务。
|
||
|
||
假想一下在线下操作中可能发生的场景:核保员在审核完核保申请之后,在核保申请上填上核保意见、日期并签字盖章,然后在投保单上填上核保意见、日期并签字盖章。我能因为签投保单时笔没水了,就把刚签完的投保单撤销吗?这显然是荒谬的。
|
||
|
||
事实上只有在DDD的一个限界上下文内,操作才应该是事务性的。跨限界上下文的调用,都不应该是事务性的,否则就说明限界上下文的划分有问题。在进行微服务拆分之前,既然我们已经把核保作为一个限界上下文了,就说明它与单体的交互就不应该再具有事务性了。
|
||
|
||
我们可以选择当API调用失败之后,不管是真失败还是假失败,都可以采取不断重试的方式保证数据的最终一致性。不过这时要注意的一个问题是,**需要重试的API本身必须是幂等的**,即多次重复调用后产生的结果是一致的。否则,多次重试后产生了多个结果,就会造成数据错误。
|
||
|
||
如果讨论之后,业务人员还是认为应该保证数据的实时性和一致性,并且限界上下文的划分在大多数情况下也是合理的,这时候就不得不引入分布式事务来解决了。关于分布式事务,极客时间上有很多相关课程,你可以自行拓展学习。但值得说一句的是,分布式事务的解决方案会给整体拆分过程带来极大的认知负载,不到万不得已,不建议采用。
|
||
|
||
通过前面的课程,你一定已经清楚了,**将代码依赖或数据依赖改为API依赖,是我们进行服务拆分的最基本手段**。然而API调用有时又会带来新的问题,接下来我就分享两个实践,帮你避免这些问题。
|
||
|
||
## 用批量API取代单次API
|
||
|
||
在遗留系统中,可能存在下面这样的循环:
|
||
|
||
```java
|
||
for(long productId : request.getSelectedProductIds()) {
|
||
ProductDao productDao = new ProductDao();
|
||
ProductModel product = productDao.getProductById(productId);
|
||
// 针对单个险种给出核保结论
|
||
// ...
|
||
}
|
||
|
||
```
|
||
|
||
如果直接使用API调用取代代码依赖这个实践,将会得到这样的代码:
|
||
|
||
```java
|
||
for(long productId : request.getSelectedProductIds()) {
|
||
ProductServiceProvider productServiceProvider = new ProductServiceProvider();
|
||
ProductModel product = productServiceProvider.getProductById(productId);
|
||
// 针对单个险种给出核保结论
|
||
// ...
|
||
}
|
||
|
||
```
|
||
|
||
这段代码功能上没有任何问题,但会导致潜在的性能问题,因为它在一个循环内部多次调用了同一个API,列表中的元素越多,API调用就越多。
|
||
|
||
有的时候我们这么做只是为了复用已有的API(比如这个ProductServiceProvider.getProductById),或者说为了尽量少地在遗留系统中添加新的API,或者就是单纯的没有在code review的时候发现问题。这样的代码一旦上线,就很难复查,直到发现性能问题。
|
||
|
||
这时候我们需要增加一个新的批量API,一次性查询出所有后续要用到的对象,然后再进入循环中去逐个处理:
|
||
|
||
```java
|
||
ProductServiceProvider productServiceProvider = new ProductServiceProvider();
|
||
List<ProductModel> products = productServiceProvider.getProducts(request.getSelectedProductIds());
|
||
for(ProductModel product : products) {
|
||
// 针对单个险种给出核保结论
|
||
// ...
|
||
}
|
||
|
||
```
|
||
|
||
用这种批量的API来取代单次的API,可以很容易地解决性能问题。
|
||
|
||
## 将同步API调用改为异步事件
|
||
|
||
之前我们说了,用同步的API调用来取代代码依赖或数据库表依赖,会对性能造成一定影响,特别是依赖较复杂需要改成多次API调用的情况。而且当API调用失败时,用代码实现的重试机制也不够灵活。这里我向你推荐一种在分布式系统中常见的解决方案,也就是事件机制。
|
||
|
||
前面课程里我们讲过事件实现数据同步有时候是不现实的,因为遗留系统中的事件缺得太多,无法满足数据同步的要求。但是用事件来实现异步调用,还是可以胜任的。
|
||
|
||
我们将调用API的地方改为抛出一个事件,发送到消息中间件上,然后在消费端消费这个事件,从而完成原本由API完成的工作。
|
||
|
||
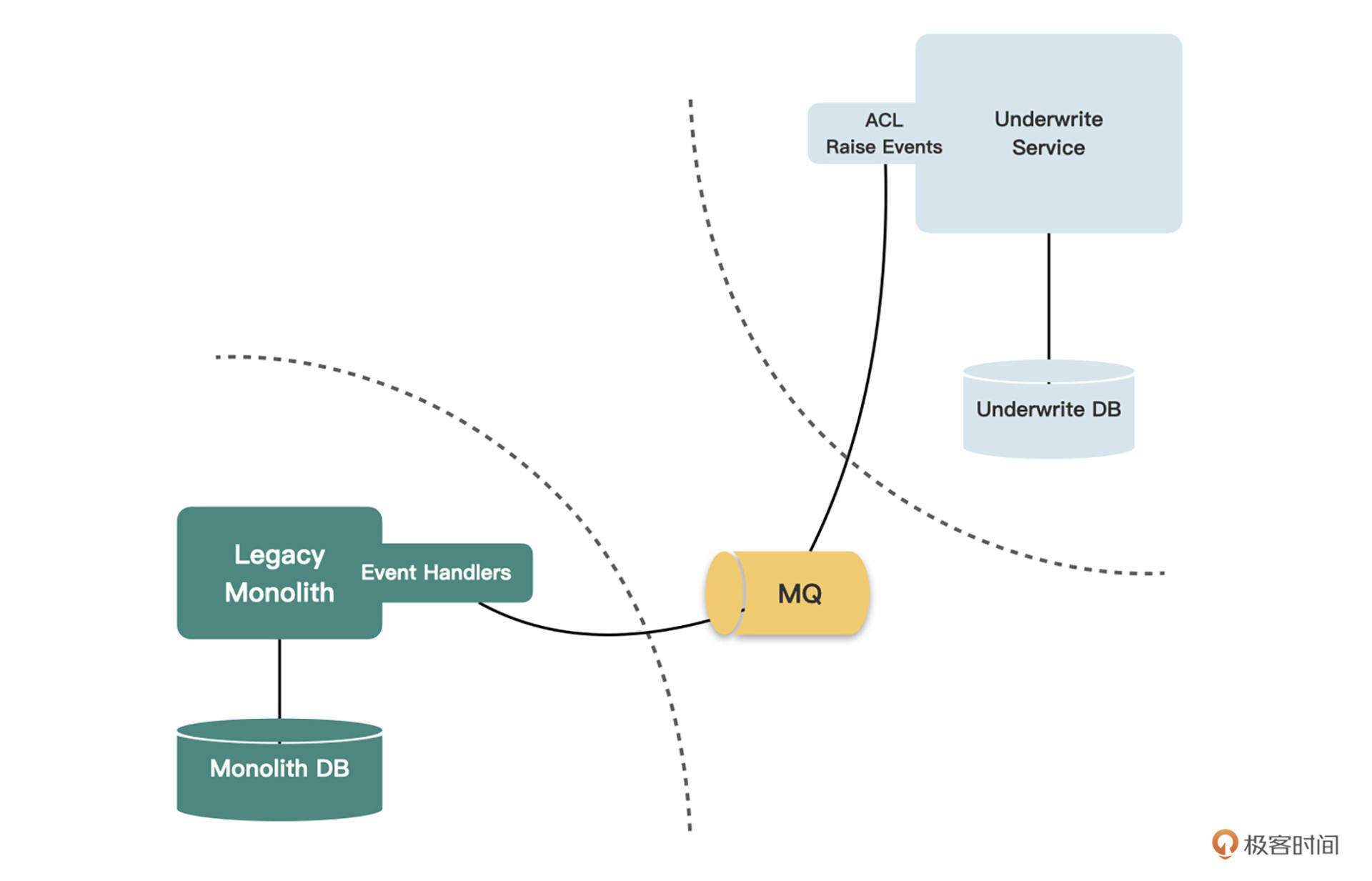
|
||
|
||
## 小结
|
||
|
||
总结一下今天的内容,我们学习了如何拆分存储过程和函数,总体思路还是转换成API调用,但对于过于复杂的场景,转换成API调用的工作也并不轻松。此外,我还分享了一些数据拆分时的小技巧,包括以重试的方式来代替回滚操作、用批量API来取代单次API的循环调用,以及用异步事件来取代同步API。
|
||
|
||
有些时候存储过程过于复杂,你可能考虑把它们转换成Java代码。我劝你一定要慎重。并不是说不能这么做,只是这样做的认知负载仍然是相当高的,你应该根据实际情况,先去寻找相对认知负载低的方案。
|
||
|
||
数据拆分是遗留系统拆分最复杂的部分,没有轻松的解决方案。而且不同的遗留系统现状也不同,需要具体问题具体分析。今天的课程只包含一些通用的方案,不过我们在实践中总结了一些针对特定场景的技巧,之后我将邀请我的同事以加餐的形式为你分享。
|
||
|
||
## 思考题
|
||
|
||
感谢你学完了今天的内容,今天的思考题是,对于复杂的存储过程拆分,你有没有其他思路?
|
||
|
||
期待你的分享,如果你觉得这节课对你有帮助,别忘了分享给你的同事和朋友,我们一起开始拆分存储过程。
|
||
|