190 lines
17 KiB
Markdown
190 lines
17 KiB
Markdown
# 22|微服务拆分(二):三招搞定数据库表解耦
|
||
|
||
你好,我是姚琪琳。
|
||
|
||
上节课,我们学习了微服务拆分之初,需要搭建好的两个基础设施,一个是基于开关的反向代理,另一个是数据同步机制。有了这两个设施做保障,接下来就可以大刀阔斧地一一拆解了。
|
||
|
||
除此之外,我们还讲了如何用API来取代代码依赖。你可能已经发现了,这个实践与其说是解决了对于单体代码的依赖,不如说是解决了对于单体数据库的依赖。
|
||
|
||
诚然,对于保险系统以及大多数这种数据密集型系统来说,所有的操作最终都将体现到数据库上。在这类系统的改造过程中,最不好解决的问题莫过于数据库表的解耦了。
|
||
|
||
这种面向数据库编程在21世纪初的国内是十分流行的,像Delphi、VB等都提供了很方便的数据库连接组件,而PowerBuilder更是推出了可以直连数据库的DataWindow,将数据的访问和展示耦合在了一起。
|
||
|
||
在这样的大背景下,将所有逻辑都放在客户端组件的Smart UI模式,以及将业务逻辑和数据访问逻辑混杂的“事务脚本模式”为什么如此流行,也就不难理解了。然而随着业务的发展,这种模式的弊病也越来越明显,很多团队都意识到了这个问题并着手解决。但在遗留系统中,这样的代码还是随处可见。
|
||
|
||
在微服务拆分的过程中,如何界定数据库表的所有权,进而拆分给不同的服务,就成了最为棘手的工作。这节课我们一起继续探索遗留系统的改造实践,按照从易到难的顺序,分别学习三种行之有效的方法,帮你搞定数据库表的解耦。
|
||
|
||
## 第一招:用API调用取代连表查询
|
||
|
||
在[上一节课](https://time.geekbang.org/column/article/522486)的代码示例中,我们分别用PolicyDao和UnderwriteApplicationDao去查询保单和核保申请数据,再组合成我们需要的核保申请数据并返回。
|
||
|
||
然而,在大多数遗留系统中,模块对于数据的所有权边界往往是很模糊的,也就是说,在任何模块中都可以随意访问本属于其他模块的数据。
|
||
|
||
所以,对于这样的代码,真实情况往往是这样:使用一个连表查询,一次性查出所有想要的数据。
|
||
|
||
```java
|
||
// 核保服务中的代码 - UnderwriteApplicationService.java
|
||
public UnderwriteApplicationDto getUnderwriteApplication(long policyId) {
|
||
UnderwriteApplicationDao underwriteApplicationDao = new UnderwriteApplicationDao();
|
||
UnderwriteApplicationModel underwriteApplicationModel = underwriteApplicationDao.getUnderwriteApplication(policyId);
|
||
return getUnderwriteApplicationDto(underwriteApplicationModel);
|
||
}
|
||
|
||
// 核保服务中的代码 - UnderwriteApplicationDao.java
|
||
public UnderwriteApplicationModel getUnderwriteApplication(long policyId) {
|
||
String sql = "SELECT * FROM TBL_UNDERWRITE_APPLICATION UC, TBL_POLICY P WHERE UC.POLICY_ID = P.ID AND P.ID = :policyId";
|
||
return executeSqlAndConvertToUnderwriteApplicationModel(sql, policyId);
|
||
}
|
||
|
||
```
|
||
|
||
注意,我们忽略了具体的执行SQL语句的框架,它可能直接使用了JDBC,也可能使用了MyBatis,这并不是重点。重点是如何拆分这样一个SQL语句。
|
||
|
||
在这条SQL语句中,TBL\_UNDERWRITE\_APPLICATION是指核保申请所对应的表,显然它应该属于核保数据库,而TBL\_POLICY是保单所对应的表,应该留在单体库中。
|
||
|
||
怎么拆分呢?其实要拆分这样的连表查询并不难,我们的方案和上节课处理代码依赖问题采用的方法类似,也是通过API的方式来替换。
|
||
|
||
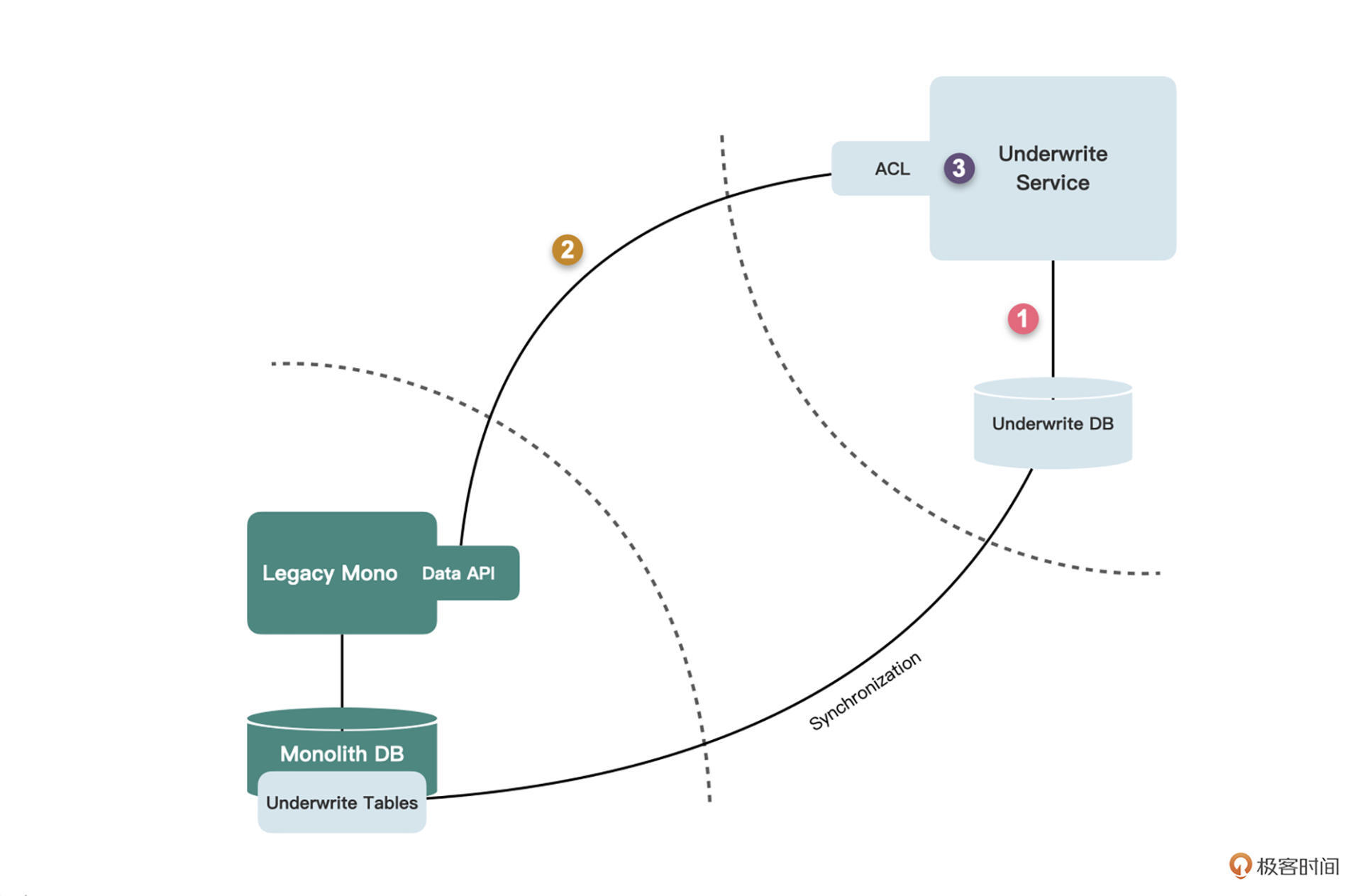
|
||
|
||
具体来说仍然是三步走,即调自己、调服务、组数据。最终的代码也几乎与解决代码依赖的方案一样,这里就不重复说了,你可以回顾第二十一节课。
|
||
|
||
用API调用取代连表查询和上节课的用API调用取代代码依赖,都用到了两种前面学到的模式,分别是改造老城区的**变更数据所有权模式**,和建设新城区中的**数据库包装服务模式**。
|
||
|
||
在核保服务和单体服务的分权之争中,开发人员作为裁判做了这样一件事儿:把保单数据的访问功能从核保服务那里剥离出来,核保服务不再拥有这部分数据的所有权,而是转给单体服务。
|
||
|
||
当然了,在现阶段拆分出来的数据,会暂且放在统一的数据API中,至于到底划到单体中哪个模块,不是我们现阶段应该关注的。这里为了变更数据所有权,我们采用把数据库封装为API的方式。获取保单数据的API仅仅是个提供数据库数据的接口,不包含任何业务逻辑。
|
||
|
||
到这里,简单的数据解耦我们就能轻松应对了。但遗留系统的代码千奇百怪,各种数据库表的连表查询更是百怪千奇,接下来咱们就来迎战更高难的复杂查询。
|
||
|
||
## 第二招:为复杂查询建立单独的数据库
|
||
|
||
下面这张图是我从一个真实的遗留系统中提取出来的SQL语句,我对具体的内容做了模糊处理,但重要的是了解它的长度和复杂度。
|
||
|
||

|
||
|
||
这种复杂查询在遗留系统中屡见不鲜,我甚至在有的项目中遇到过需要十几张A4纸才能完整打印的SQL语句。
|
||
|
||
如果非要硬来,对上面这种复杂SQL也用API调用来替换,那成本和风险都是相当高的,而且有些甚至是做不到的。比如有些查询会把分页逻辑也写在SQL语句里,但如果WHERE条件中包含单体服务中的表,把这个依赖转换成API查询,然后在内存中再去过滤,分页就会乱掉。
|
||
|
||
那么对于类似这样的复杂查询应该如何处理呢?你可以针对这样的查询,提取一个单独的查询数据库出来。
|
||
|
||
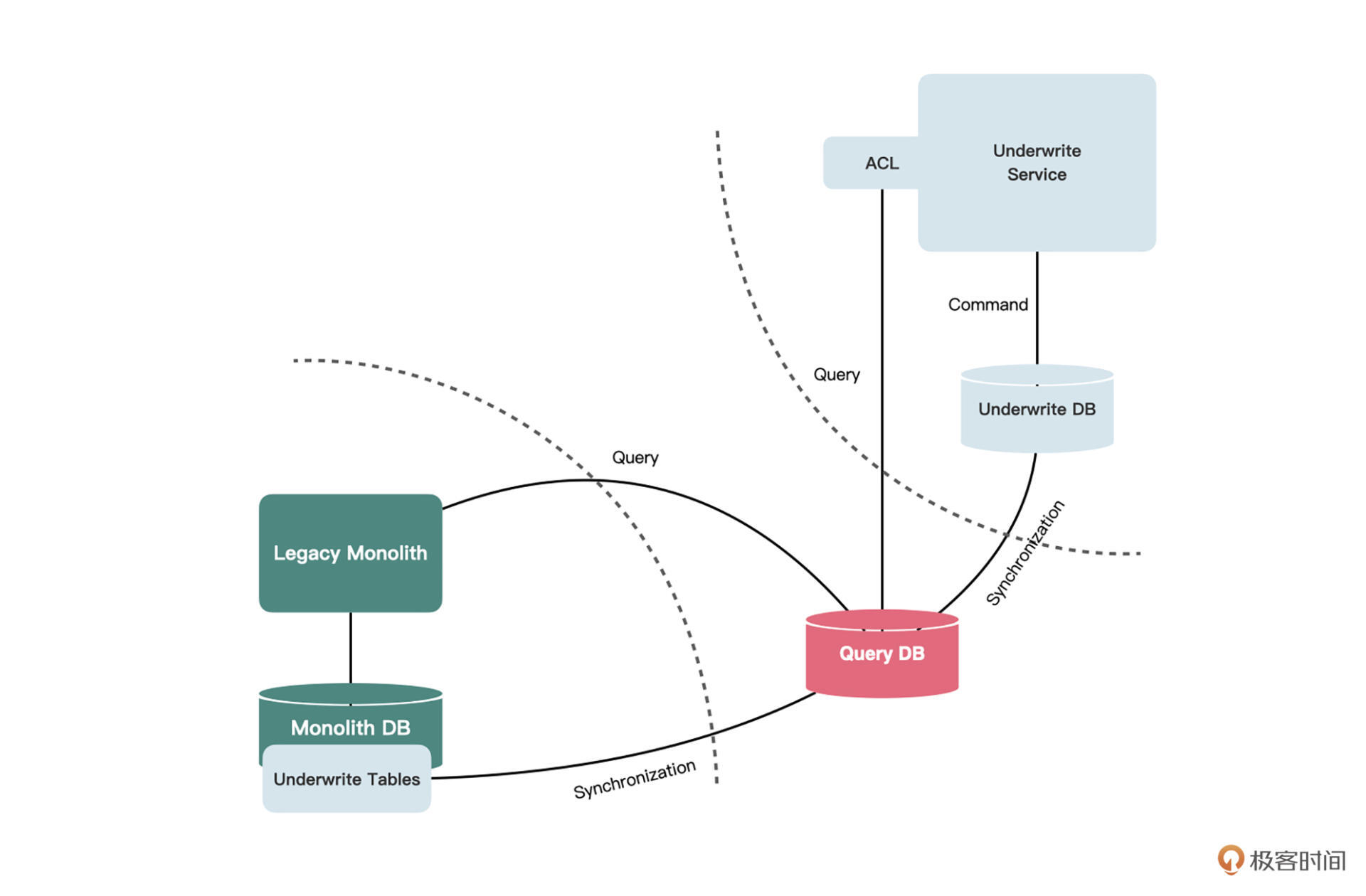
|
||
|
||
我们新建一个独立的数据库,把核保和单体数据库中的数据都同步到这个数据库中,核保服务可以直接连接到该库中进行查询操作。由于该库包含了查询所需的全部表,因此SQL语句甚至不需要做任何修改,只需要区分查询和修改数据库的连接地址就可以了。
|
||
|
||
这样在一定程度上还实现了**读写分离**。在未来剥离单体服务中对于核保表的依赖时,也可以让单体服务访问查询数据库。以后再从单体中继续剥离其他服务时,也同样可以复用这个库,可谓一举多得。
|
||
|
||
有同学可能会问,多个微服务共享一个数据库,这不是典型的反模式吗?注意这里我们共享的并不是业务数据,而是查询数据,是只读的。它并不需要独立演进。
|
||
|
||
比如如果单体库独立进行了修改,并且不需要让核保服务知道,查询库就不需要跟着修改,反之亦然。而如果单体库的修改需要通知核保服务做出相应的修改,可能就需要同时修改查询库,并且重新部署,这也是很正常的情况,因为反正都需要重新部署核保服务。
|
||
|
||
最重要的是,我们通过新的、单独的查询数据库,极大地降低了认知负载,再也不需要去修改复杂的SQL语句了。回顾一下第十五节课的内容,这其实就是**报表数据库模式**。
|
||
|
||
## 第三招:冗余数据
|
||
|
||
除了单独的查询数据库,还有一种方式是将复杂查询所用到的数据,都冗余到核保库中。这样,复杂SQL仍然不需要做修改,改造的成本也非常低。
|
||
|
||
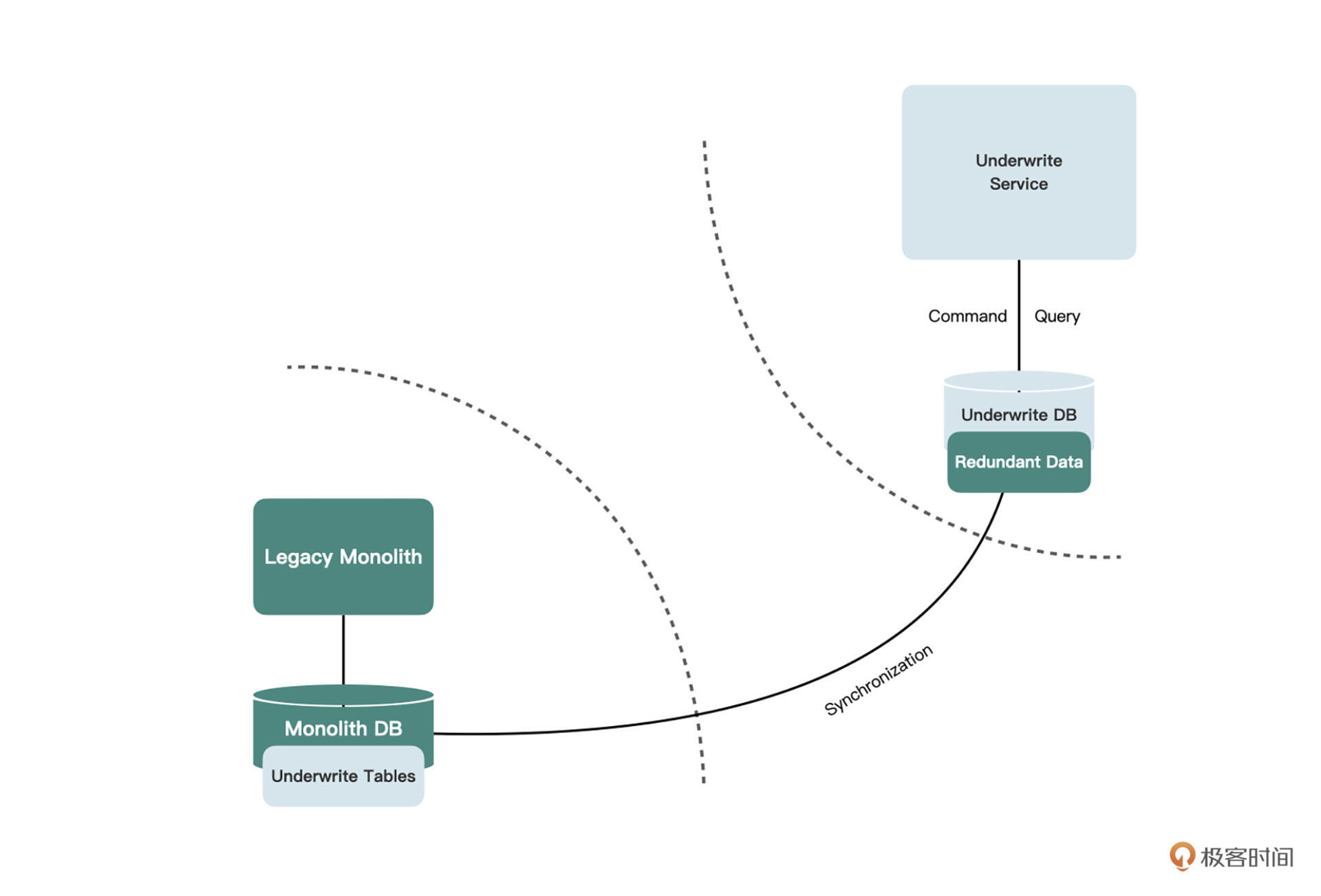
|
||
|
||
都有哪些数据需要冗余到核保服务中呢?表面上看,是核保服务中,所有查询SQL中所涉及到的表和字段的并集。不过实际上,我们应该先把这些表和字段分类,对不同的类别采取不同的处理策略。
|
||
|
||
### 快照数据的冗余
|
||
|
||
**第一种类型是快照数据**。快照数据是指那些只关心数据当时的状态,而不关心数据后续变化的场景。我们可以把这类数据存储(或缓存)在消费端,一方面需要这些数据的时候就不需要远程获取了,提升了性能,另一方面当远程服务宕机的时候,也不至于影响消费端服务。
|
||
|
||
关于这类数据,我们最常见的就是微信头像更新。你一定发现了,在点击好友头像的时候会更新一下头像,平时我们看到的都是他以前用的头像,这个头像就是本地存储的一个快照。
|
||
|
||
平时我们聊天和视频,头像是否是最新的我们并不关心,等到点击头像的时候再更新,我们也不会觉得有啥问题。相反,如果一定要保持头像的实时更新,对每一个手机客户端来说,都是非常严重的资源消耗。
|
||
|
||
遗留系统中其实也存在类似的数据。比如每个核保申请都有一个核保员对其进行核保。假设某个核保员叫张三,后来改名为李四,我们是希望由他核保的历史核保申请信息上,显示的仍然是张三,还是改名后的李四呢?如果仍然可以显示张三,那么我们就说核保申请上的核保员姓名这个信息,可以存储为快照数据。
|
||
|
||
按照大多数遗留系统的设计,核保申请表上存储的就是员工表的主键。当员工(核保员也是员工,因此信息存储在员工表里)改名后,连表查出来的员工姓名肯定会发生改变。我们在做服务拆分的时候,可以用API调用来取代这个连表查询,从而得到员工的新姓名。
|
||
|
||
但当查询极其复杂,无法用API调用来取代的时候,你就可以回过头来想想,某个核保申请上的核保员姓名,是否必须是最新的,是否可以仅存一份快照数据而没必要更新。
|
||
|
||
冗余数据放在哪?我们有两种处理方法。
|
||
|
||
第一种方法是冗余到主表上。比如核保申请表上本来存储的是员工主键,现在可以增加一列姓名。在创建核保申请时,同时插入员工的主键和姓名。在查询时,不通过员工主键连表查询员工表,而是直接查出姓名。采取这种方法时,需要对原有SQL进行少量修改。
|
||
|
||
第二种方式是冗余到新表中。有时候要冗余的某张表的字段会很多,比如除了员工姓名,可能还需要员工号、员工级别、员工所在分公司等。
|
||
|
||
除此之外,还包括申请核保的员工信息、保单的投保人信息、被保人信息等等。如果这些字段都冗余到主表,就会喧宾夺主,关注点不聚焦。因此我们可以把这些字段分别冗余到不同的新表中。
|
||
|
||
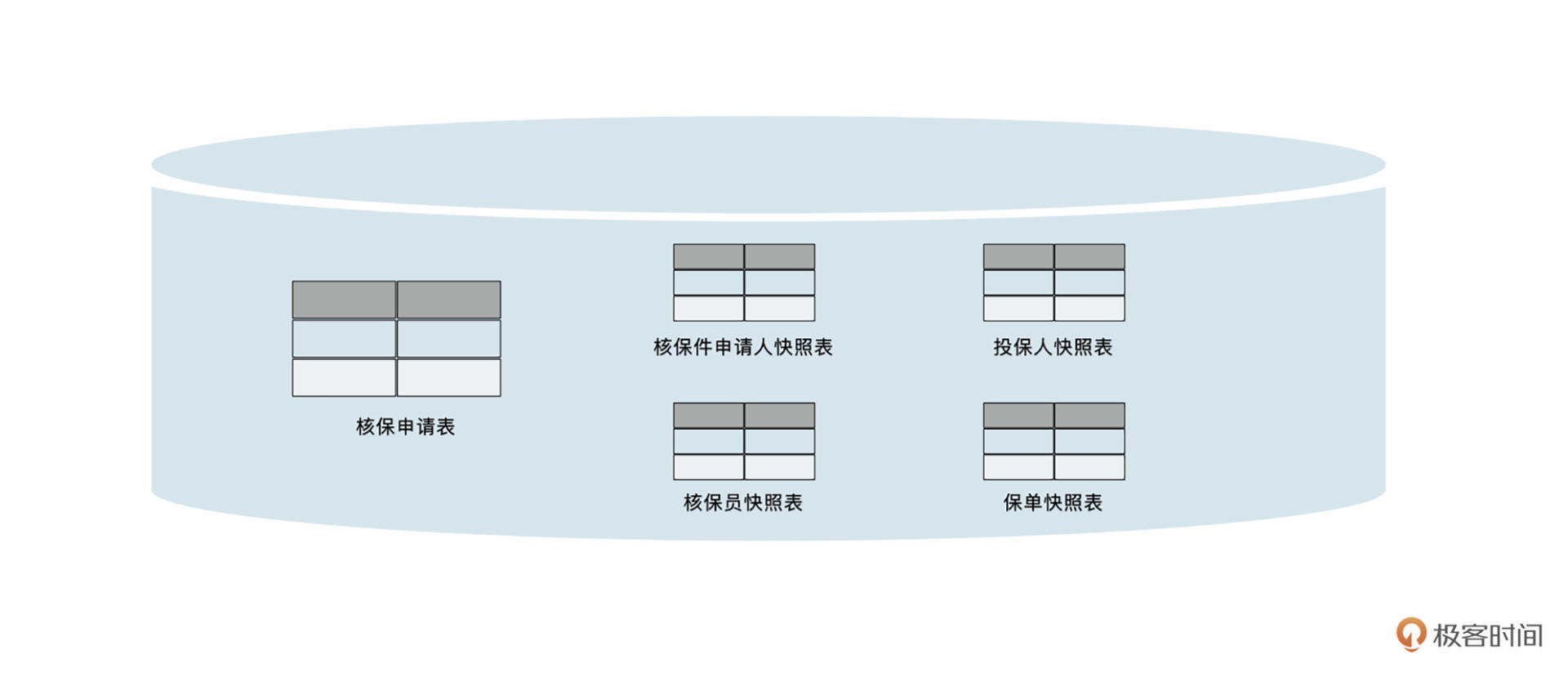
|
||
|
||
值得注意的是,新表的名称应该根据业务去命名,而不能跟原表的名称一样。像申请人、核保员都来自原来的员工表,我们没有办法在核保库中建一个员工表,来解决这两份数据的快照。
|
||
|
||
因此我们要建一张核保申请人表,一张核保申请核保员表,分别来存储申请人和核保员的快照数据。在快照表中,不再像原表那样以员工ID为主键,而应该以核保表的主键为主键,将原来的一对多关系改为一对一。采取这种方法时,原有SQL的改动就更少了,可能只需要改一下表名。
|
||
|
||
### 业务数据的冗余
|
||
|
||
**第二种需要冗余的数据是业务数据**。业务数据与快照数据不同,它的变化会影响到当前业务,因此不能按快照进行冗余。比如被保人的年龄在申请的时候填错了,进行了修改,如果还是以快照数据来存储,在核保服务中就无法得到新的年龄,就会得出不同的核保结论。
|
||
|
||
因此对于冗余到核保库中的业务数据,必须进行同步,以得到最新值。同步方式可以参见第二十一节课的内容。
|
||
|
||
在实际项目中,必须与业务人员一起讨论哪些数据是快照数据,哪些数据是业务数据。这一点开发人员是决定不了的,必须由业务人员来决定,但开发人员可以给出一些建议。比如业务人员在得知要将核保员姓名改成快照的时候,他们和开发人员之间很可能会发生这样的对话:
|
||
|
||
业务人员:系统使用了很多年,都是随时可以查出最新的核保员姓名,这么改不符合业务(注意这里可能并不是真正的业务,而是软件系统培养出来的操作习惯,开发人员要善于捕捉这一点)。
|
||
|
||
开发人员:那我们想想在纸质办公时代,核保员就是在核保申请上签个字或盖个章,证明是他操作的核保申请。这个签章其实就是快照,他当时叫什么名字,签章就是什么名字,以后改名了当时的签章也不会变了,不是吗?
|
||
|
||
业务人员若有所思:……
|
||
|
||
开发人员趁热打铁:所以快照才是真正符合业务的,对吗?
|
||
|
||
业务人员:纸质时代签名盖章很可能是无奈之举,我们引入软件系统不就是为了带来这些便利吗?而且像报表之类的功能,比如按核保员名称去查询他所核保的所有核保申请,如果改名了就查不出来了,会非常不方便。
|
||
|
||
开发人员:您说的很有道理,报表这里我们会特殊处理以满足功能,但是在当前这个复杂查询的场景里,我们是否可以只查出当时的快照呢?
|
||
|
||
业务人员:可以吧……
|
||
|
||
这当然是一个假想的偏理想化的对话情景,真实的情况下要想说服业务人员可能相当困难,因为看问题的视角不同。但也是非常值得去尝试的,因为一旦存储成快照数据,的确会给服务拆分带来极大的便利,显著地降低认知负载。
|
||
|
||
注意,以上两种类型的数据,我们都只需要冗余我们用到的字段,不需要的字段就没必要冗余了。
|
||
|
||
在第一次创建主表数据(即核保申请)的时候,我们可以连带着把所要冗余的快照数据和业务数据,一起插入到核保库的相应表中。当业务数据发生变化的时候,再通过同步机制将其同步到核保库中。
|
||
|
||
### 参考数据的冗余
|
||
|
||
**第三种需要冗余的数据是参考数据**,即Reference Data。参考数据是指那些对其他数据进行分类的数据,如国家的名称和缩写(如CHN、USA等)、机场的三字码(如PEK、DAX等)、货币代码(如CNY、USD等)。这些数据都是静态不变,或变化很慢的数据,因此也有人称之为静态数据。
|
||
|
||
在单体的遗留系统中,这类参考数据往往存储在单体的数据库或配置文件中,只有单体服务可以访问到。在从单体向外拆分微服务的时候,这类参考数据也是需要冗余的,否则拆分出来的服务就无法使用了。
|
||
|
||
不管参考数据存储在数据库还是配置文件中,我们都可以直接在新服务中也创建一份,直接使用即可。这是认知负载最低的解决方案。如果由于某种原因导致参考数据发生了变化,直接在两个库或配置文件中都进行修改就可以了,毕竟这种情况发生的概率很低,没有必要在它们之间建立同步机制。
|
||
|
||
当然更理想的方式是将参考数据加载到缓存中,供多个服务使用,这样就没有必要冗余了。如果遗留系统原来就是这么做的,当然可以直接复用。但如果不是,就没有必要非按照理想的方式来,毕竟这需要额外的工作量。
|
||
|
||
我们在遗留系统现代化的过程中,要切忌这种发散式的思维方式。本来目标是服务拆分,结果却引入了参考数据治理这个新的任务,导致工作不聚焦,工作范围扩大。
|
||
|
||
## 小结
|
||
|
||
今天的内容讲完了,我们做个总结。
|
||
|
||
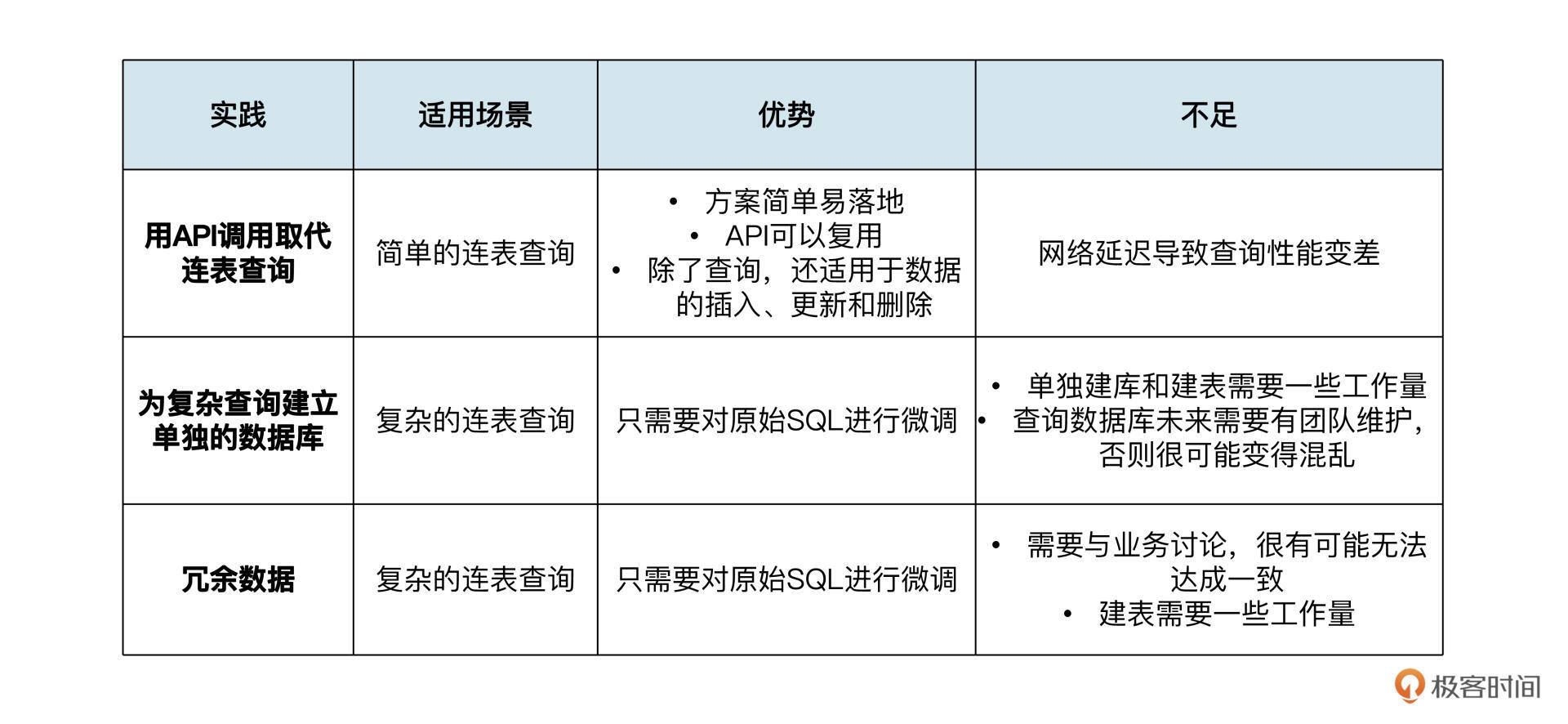
我为你梳理了一张表格,对比了拆分查询SQL的三种方案,以及上面没有提到的一些优势和不足。你可以结合自己的实际需求,对照表格选择更合理的方案。
|
||
|
||
|
||
|
||
上面我们介绍的解耦数据库表的方法都是基于查询的SQL,对于INSERT、UPDATE和DELETE的SQL,我们也可以用API调用来取代,这里就不详细介绍了。
|
||
|
||
## 思考题
|
||
|
||
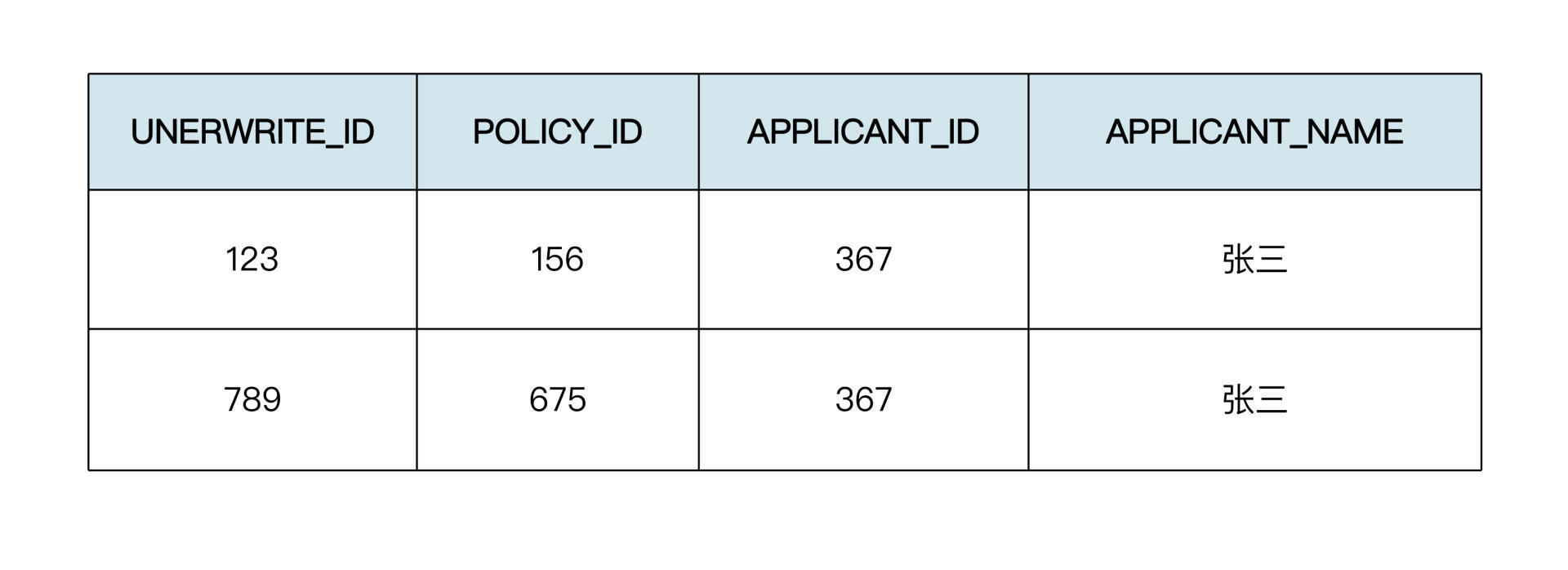
感谢你学完了今天的课程,今天的思考题是这样的:假设我们要将员工信息冗余到核保服务的数据库中,以下两种方式各有哪些优缺点呢?他们所对应的SQL语句有什么区别?
|
||
|
||
方案一:
|
||
|
||
TBL\_UNDERWRITE\_APPLICATION(核保申请表)
|
||
|
||
|
||
|
||
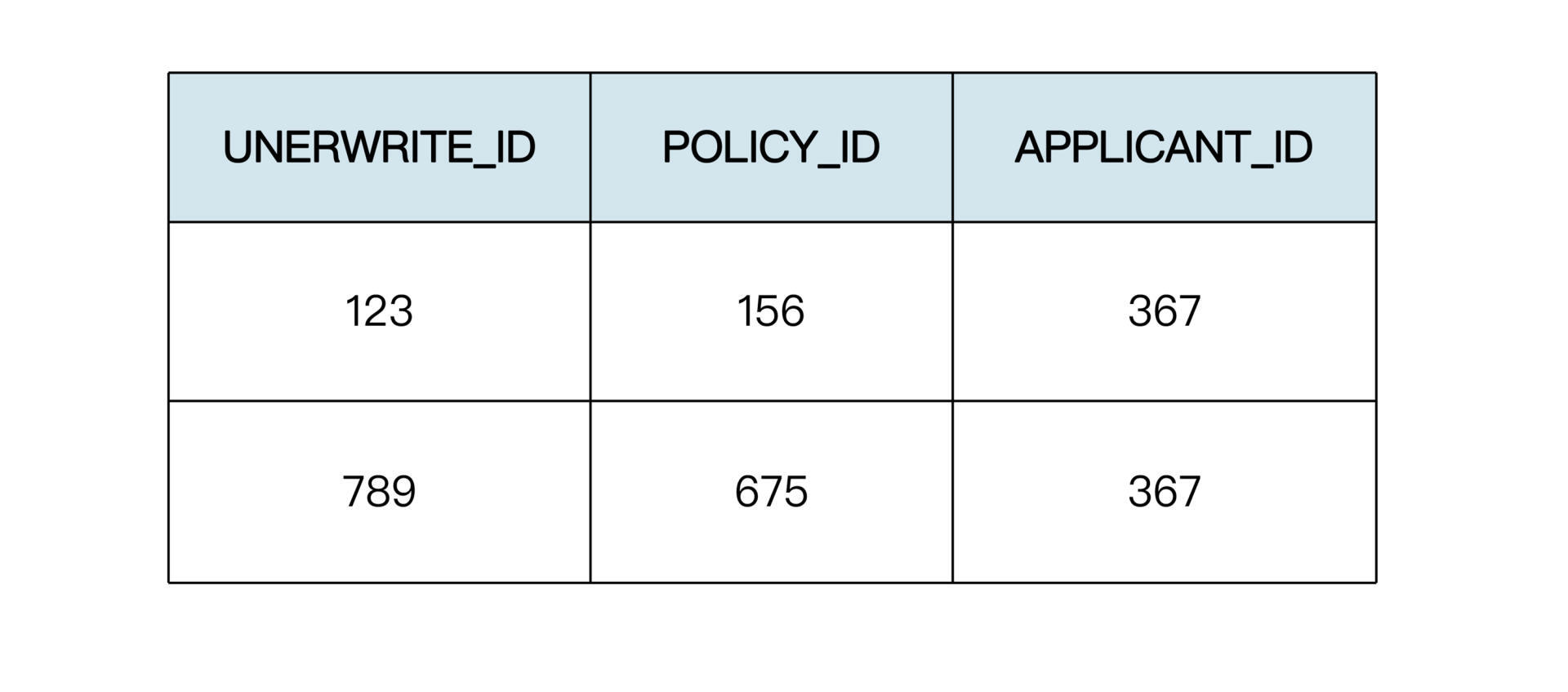
方案二:
|
||
|
||
TBL\_UNDERWRITE\_APPLICATION(核保申请表)
|
||
|
||
|
||
|
||
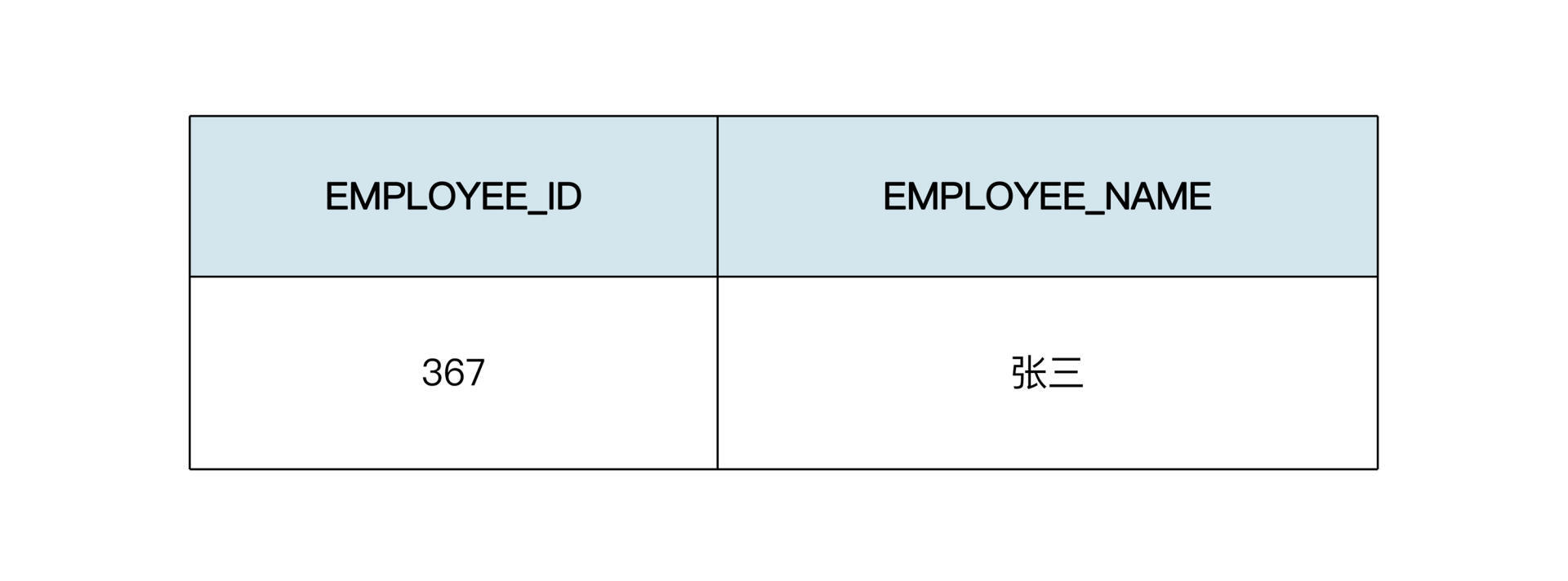
TBL\_EMPLOYEE(员工表)
|
||
|
||
|
||
|
||
欢迎你在留言区跟我交流互动。如果你身边有朋友遇到解耦数据库表的困惑,也推荐你把这节课分享给他。
|
||
|