|
|
# 21|微服务拆分(一):迈出遗留系统现代化第一步
|
|
|
|
|
|
你好,我是姚琪琳。
|
|
|
|
|
|
在前面的课程中,我们结合案例讲解了如何启动一个遗留系统现代化项目。从这节课起,我们将重点介绍项目启动之后的内容,也就是具体的现代化工作。
|
|
|
|
|
|
当我们完成了项目的战略设计,大体设计出目标架构,又根据系统的现状,决定采用“**战术分叉**”的方式进行微服务拆分之后,接下来的难点就变成了“如何拆分”的问题。
|
|
|
|
|
|
我们会用四节课的篇幅来讲解如何拆分,分别覆盖代码拆分、数据库拆分、存储过程拆分和一些其他注意事项。这节课我们先来看看如何拆分代码。
|
|
|
|
|
|
## 拆分目标与演进计划
|
|
|
|
|
|
我们先来回顾一下上节课所制定的架构目标和演进计划。
|
|
|
|
|
|
|
|
|
|
|
|
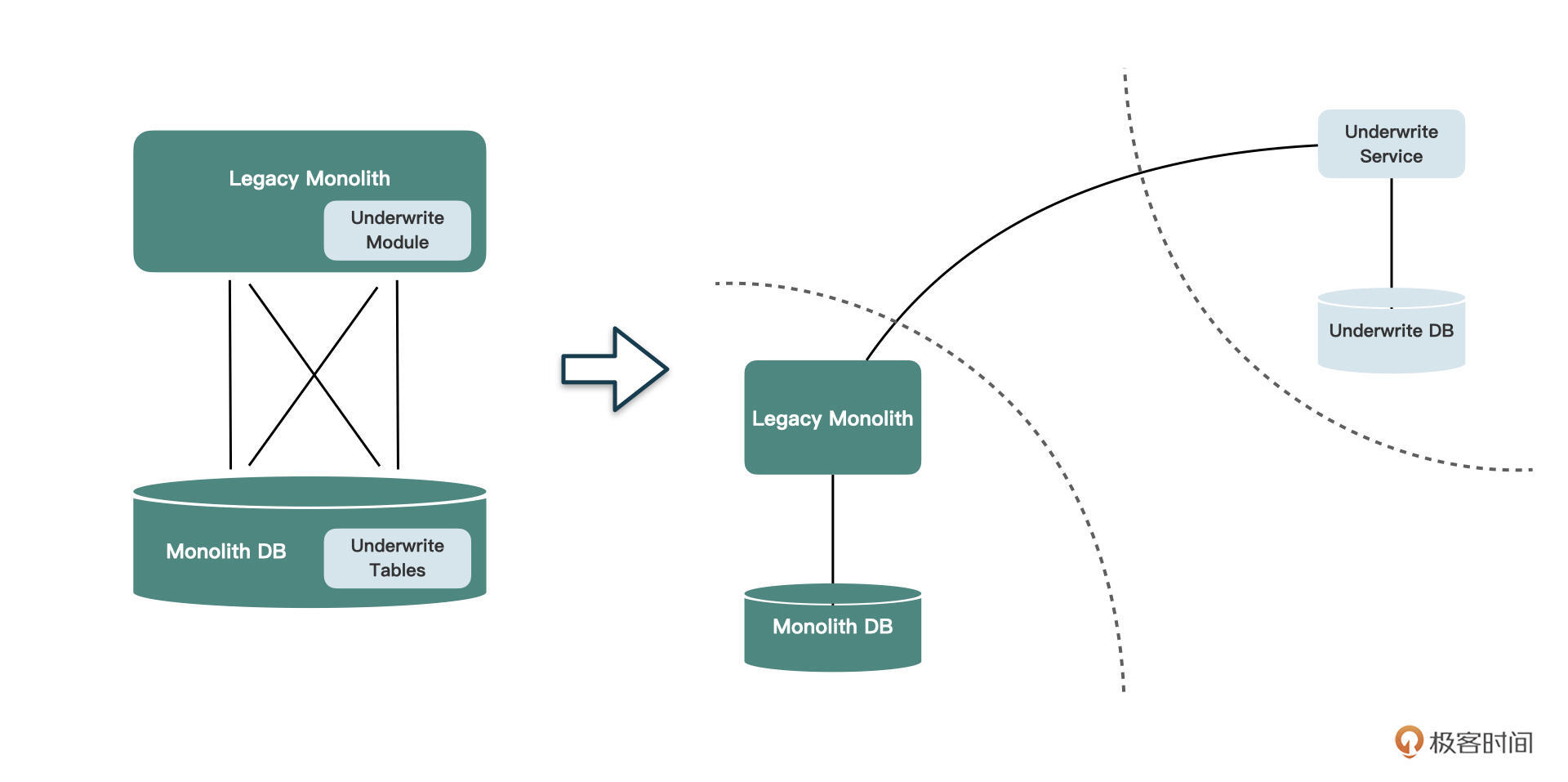
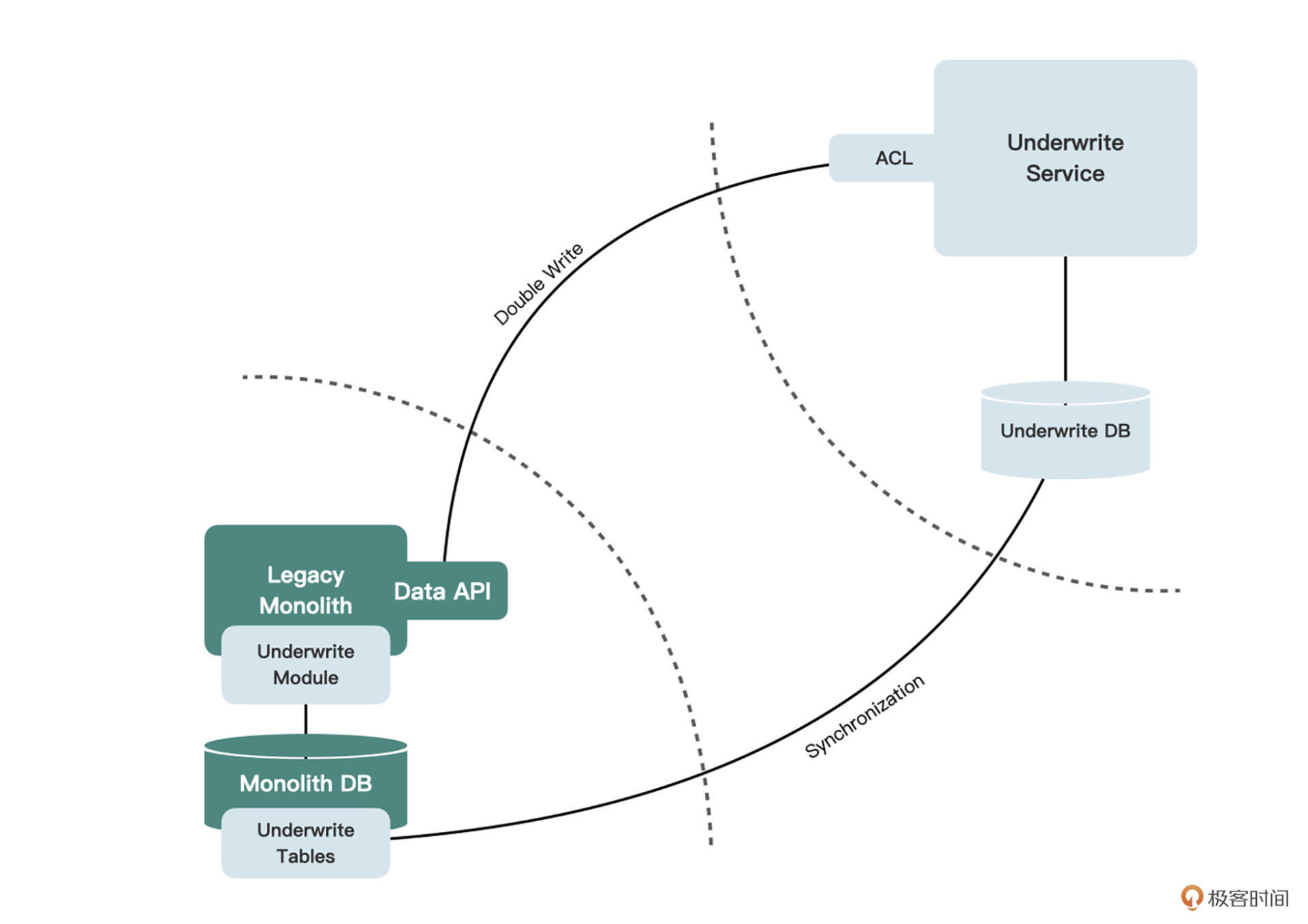
我们的目标是**将核保模块从遗留的单体应用中剥离出来,形成一个独立的微服务**。这意味着,我们不仅要将代码拆分出来,放到全新的代码库中,数据库也要从原来的单体数据库中独立出来。以前可以随意访问的代码和数据库表,都要通过某种方式完成解耦
|
|
|
|
|
|
最终核保服务和遗留单体服务之间的关系,可能会像下图这样:
|
|
|
|
|
|
|
|
|
|
|
|
接下来我们就来看看如何演进。
|
|
|
|
|
|
## 基于反向代理的特性开关
|
|
|
|
|
|
我们先通过战术分叉,将单体中的核保模块(包括数据库)以及它所依赖的其他代码都完全复制出来,放到一个全新的Maven module或代码库中,并引入Spring Boot或其他Web框架。这部分工作可能会比较繁琐,但并不太复杂。
|
|
|
|
|
|
这时候,所有的请求还都是指向遗留系统的,要想验证分叉出来的服务是否正确,需要将请求引流到新服务中。应该如何引流呢?我们来看今天的第一个实践:反向代理。
|
|
|
|
|
|
### 增量交付的粒度
|
|
|
|
|
|
在微服务拆分的过程中,我们要贯彻“**以增量演进为手段**”的原则,因此要确保整个拆分的过程是增量交付的,并且是可回退的。
|
|
|
|
|
|
对于增量交付,粒度上应该怎么灵活控制呢?可以粗一些到功能级别,即一次交付一个功能场景的改造,也可以细一些到API级别,甚至更细到方法级别。
|
|
|
|
|
|
不过根据我的经验,**API级别是最合适的**。功能级别粒度较粗,可能很难在一个交付周期内完成,无法增量迭代;方法级别又太琐碎,且控制开关的代码对业务代码的侵入较多。
|
|
|
|
|
|
当然,你在制定自己的增量交付计划时,还是要根据项目的实际情况去选择。比如每个功能都很小,只有一两个API,那也可以按功能级别进行控制。而如果某个API十分复杂,包含很多方法,也可以对这些方法添加开关。
|
|
|
|
|
|
API级别的增量交付要求我们一次改造一个端到端的请求,并进行独立的测试和上线。我们可以在一个交付周期内(如两周或四周)计划好要改造的若干API,并在上线截止日前完成开发和测试。
|
|
|
|
|
|
### 实现“特性开关”
|
|
|
|
|
|
在回退机制上,我们需要建立一个开关,当改造后的核保服务中的API发生问题的时候,能够回退到老的单体服务中。这有点类似于在开发功能时使用的“特性开关”。之后的第二十四节课,我还会详细分享更多在代码中使用特性开关的实践。
|
|
|
|
|
|
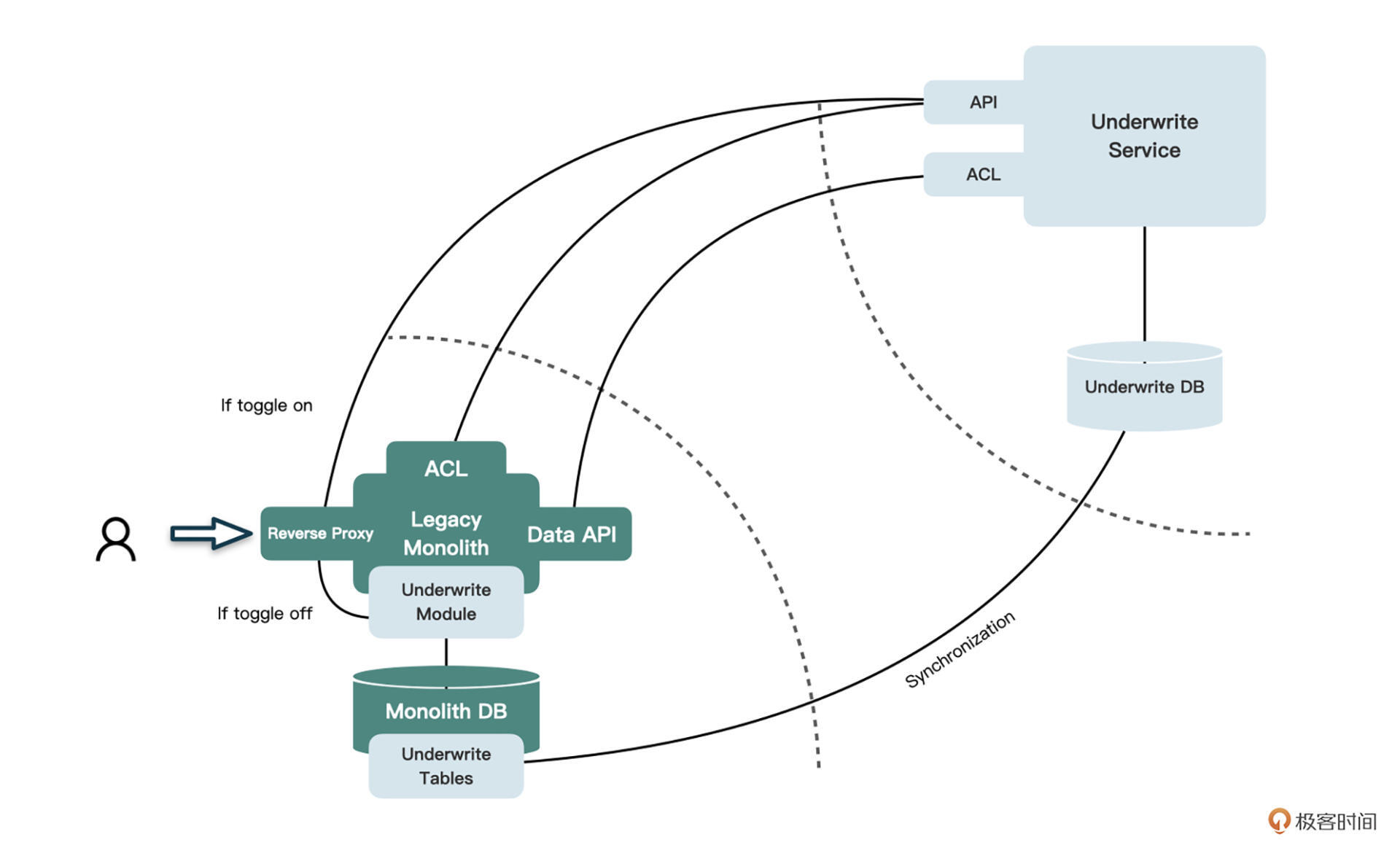
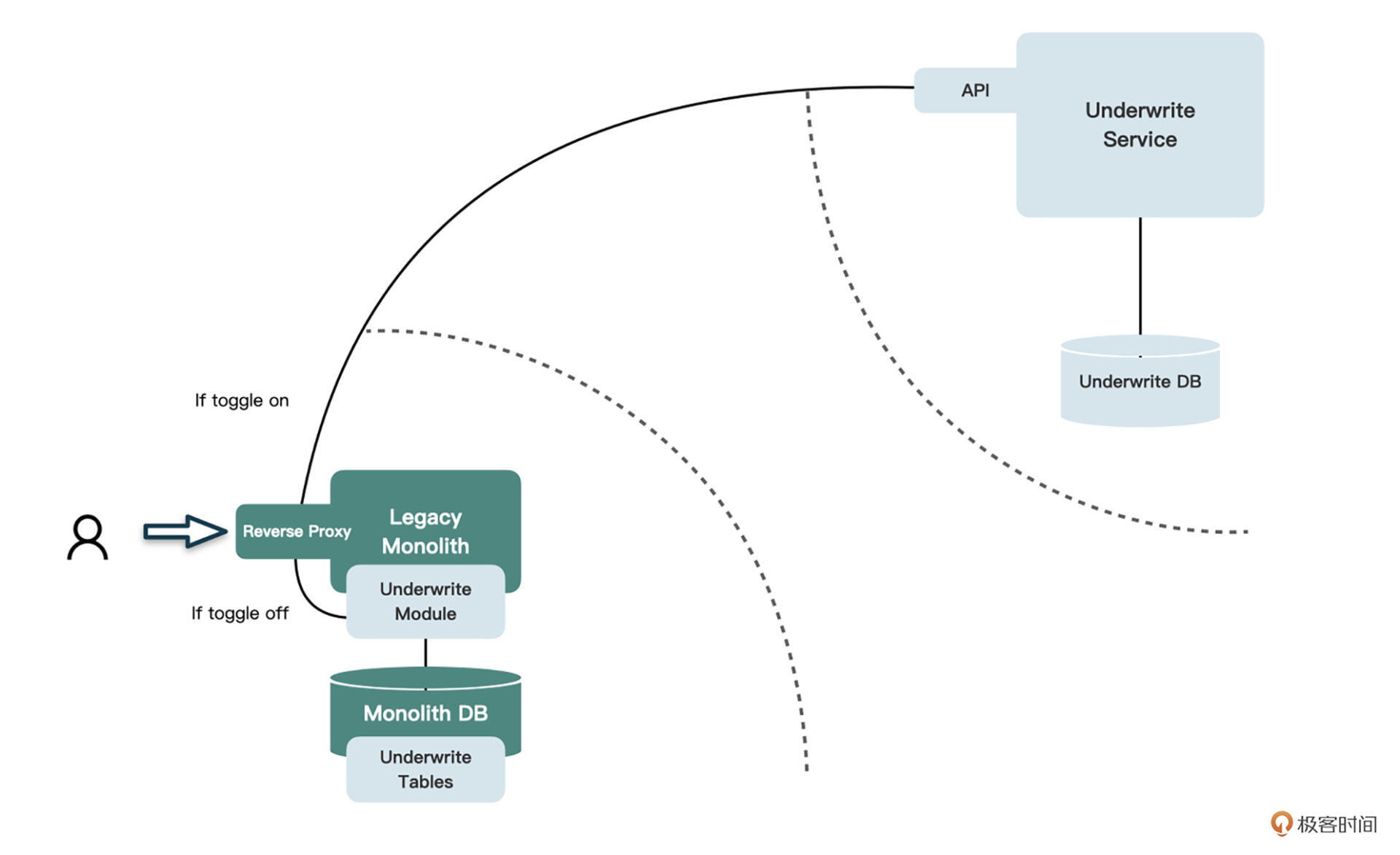
怎么实现这种开关呢?由于目前所有请求都是指向单体服务的,我们可以在单体服务中加入一个“反向代理”层,当一个请求进入单体服务中时,会先判断当前的请求是否由开关控制。
|
|
|
|
|
|
如果有开关且处于打开状态,就将请求重定向到新的核保服务中,否则就仍然访问单体中的旧代码。如果你的遗留系统中,在单体服务之外已经有了API Gateway,那当然就要把这个反向代理放在API Gateway中了。
|
|
|
|
|
|
|
|
|
|
|
|
这种反向代理的实现方式有很多。因为专栏里的案例是一个基于Servlet的JSP遗留系统,因此可以使用Filter的方式实现。开关可以存储在DB中,也可以放在配置文件里。下面是一个可以参考的代码实现:
|
|
|
|
|
|
```java
|
|
|
public class ReverseProxyFilter implements Filter {
|
|
|
@Override
|
|
|
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
|
|
|
throws IOException, ServletException {
|
|
|
// 根据request获取toggle状态
|
|
|
if (toggleOn) {
|
|
|
// 包装request
|
|
|
// 转发到核保服务
|
|
|
// 得到核保服务返回的响应
|
|
|
// 填充到response
|
|
|
return;
|
|
|
}
|
|
|
// 继续执行其他filter
|
|
|
}
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
在开关打开的时候,我们需要包装和转换当前的ServletRequeset,然后转发到核保服务。在得到核保服务的响应后,再次转换数据并填充到response中。在做请求转发的时候,可以使用OkHttpClient这样的工具。你可以思考一下,为什么要做这样的转换,为什么不能直接转发ServletRequest呢?
|
|
|
|
|
|
当反向代理功能实现完成之后,这段代码就可以上线做验证了。我们可以给任意核保模块的API设置开关,并打开开关,验证该请求是否能够正常完成。你看,我们为了保证增量演进所引入的功能,它本身也是按增量去交付的。
|
|
|
|
|
|
如果你对前面课程提到的架构现代化的一些模式掌握得很扎实,可能已经发现了,这里面我们其实使用的是“**绞杀植物模式**”(可以回顾[第十一节课](https://time.geekbang.org/column/article/514516))。
|
|
|
|
|
|
我们通过开关和反向代理,让新服务和单体中的旧模块共存。当新服务中要改造的API,完成对单体中其他代码和数据库的解耦之后,就可以上线,并打开开关做验证了。
|
|
|
|
|
|
如果新服务中的API有问题,产生了bug,就关闭开关,让请求依然指向单体中的旧模块,确保系统的正常运行。如果新服务中的API稳定运行了一段时间后,没有出现问题,我们对这次改造有了信心,就可以删除开关,让新服务中的API完全取代单体中的旧模块,从而完成这次“绞杀”。我们就这样逐个API地去绞杀,直到单体中的旧模块被新服务彻底代替。
|
|
|
|
|
|
看到这里,相信你已经对改造具体的API跃跃欲试了吧?先别急,我们来看看数据怎么处理,也就是实现数据同步。
|
|
|
|
|
|
## 建立数据同步机制
|
|
|
|
|
|
为什么需要做到数据同步呢?我们不妨从业务角度做个分析。
|
|
|
|
|
|
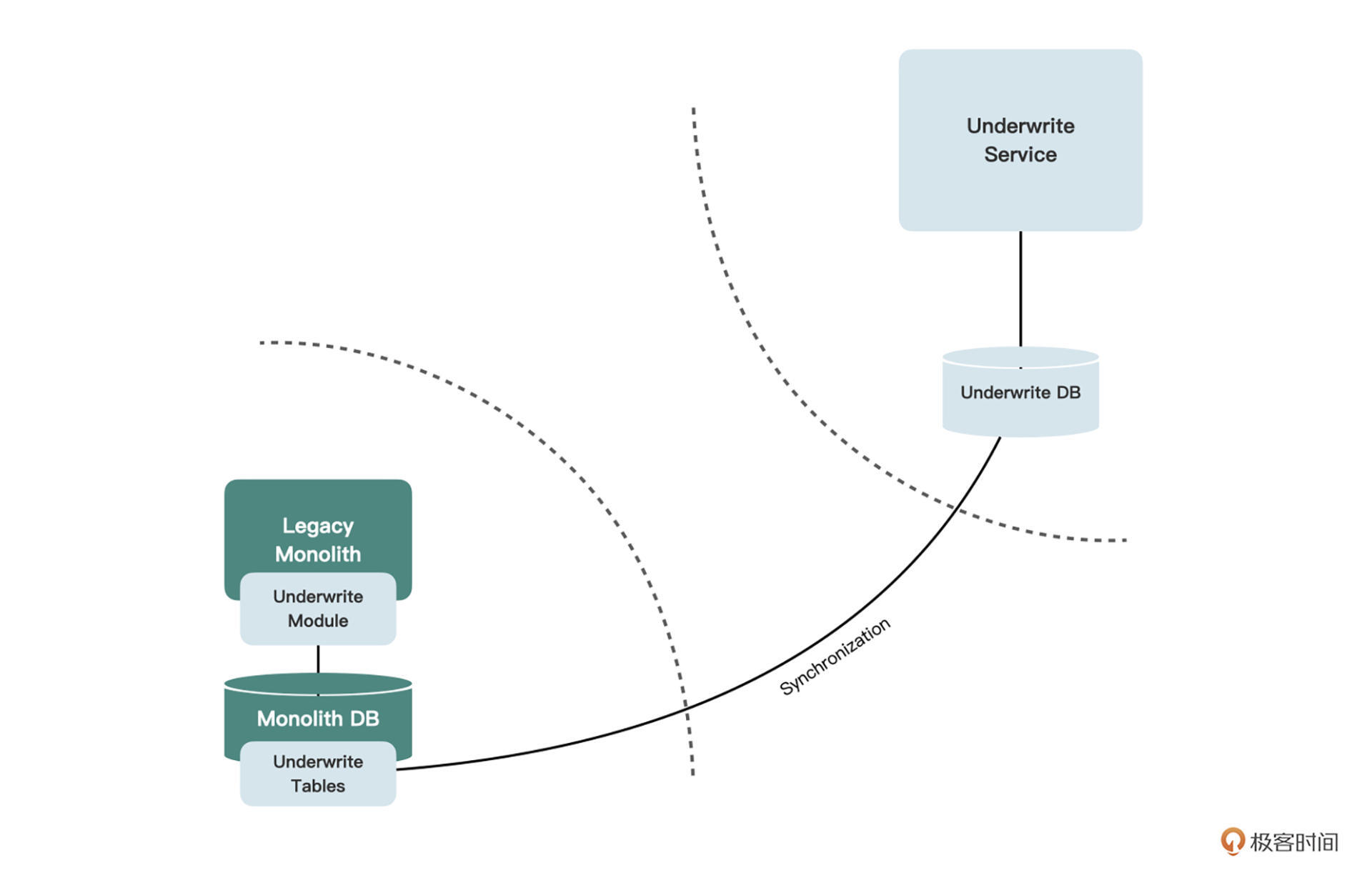
战术分叉只是将数据库复制了一份出来,但旧的单体服务仍在运行,所以总会有新的核保数据源源不断地写入核保相关的表中。如果这部分数据没有出现在新的核保库中,那么前面我们设置的开关就是无法打开的,因为数据不全,无法正常开展业务。
|
|
|
|
|
|
为了真正享有反向代理带来的随时可以回退的好处,我们必须建立某种数据同步机制,让写入旧核保表中的数据也能同步到新的核保库中,反之亦然。这样才能保证,开关无论打开还是关闭,看到的数据都能保持一致。
|
|
|
|
|
|
回忆一下我们建设新老城区的隐喻,这就好比是新城区中没有自来水厂,我们从老城区拉一条管线过去给新城区供水一样。
|
|
|
|
|
|
|
|
|
|
|
|
如何建立这种同步机制呢?
|
|
|
|
|
|
说到同步,你可能最先想到的就是**事件拦截**,这当然是非常有效且一劳永逸的方式。每一个数据变化的点,都会触发一个事件,并持久化到消息中间件中,事件的消费方通过消费这个事件来实现数据的同步。
|
|
|
|
|
|
如果你的系统中已经存在了消息中间件,并且有足够的事件,那么恭喜你,你是幸运的。然而大多数遗留系统是没有这些事件的,要想补齐所有事件来得到全部数据的修改点,工作量可能会超出服务拆分本身。
|
|
|
|
|
|
在这种时候,还是推荐你使用**变动数据捕获(CDC)**的方式来同步数据。建议你使用事务日志轮询,而不要使用触发器,因为需要捕获的数据很多,触发器多了会变得混乱。
|
|
|
|
|
|
你要记住的是,不但要做单体库到新库的同步,也要做新库到单体库的反向同步。为什么要做这种反向同步呢?因为当开关打开时,请求重定向给了新的核保服务,数据也写到了新的核保库中,此时的单体库中是没有这些数据的。这时关闭开关,数据就“丢失”了。
|
|
|
|
|
|
事件拦截和CDC的相关内容,你可以复习一下[第十一节课](https://time.geekbang.org/column/article/514516)。
|
|
|
|
|
|
还有一种方法,我们可以在单体服务和核保服务中对数据库进行“双写”,也就是既写入新的核保库,同时也写入旧的单体库,这样无论开关是否打开,都能保证两边的数据一致。
|
|
|
|
|
|
当然,双写的时候不能让核保服务直接访问单体数据库(否则我们做微服务拆分以及数据所有权的拆分就都没意义了),而应该在遗留单体中为单体库建立一系列**数据库包装服务**,来提供对单体数据库的读写访问。我们把这类API称为**数据API**。
|
|
|
|
|
|
|
|
|
|
|
|
尽管某种程度上来说数据API只是一个壳子,它还是会调用已有的旧代码去修改数据,不过双向CDC或双写的方式显然也增加了不少团队认知负载。我们再想想看,还有没有更简单的方法呢?
|
|
|
|
|
|
当然是有的,但这些方案都存在一定的局限性,需要根据项目实际情况来选择,我们一起来看一下后面这两种方案。
|
|
|
|
|
|
1.如果拆分出来的服务是**只读**的,我们可以在单体库中为相关的表创建**视图**,让新服务直接访问这些视图。当所有API改造完成之后,我们再根据这些视图,在新库中创建数据表,将数据一次性迁移到这些表中。
|
|
|
|
|
|
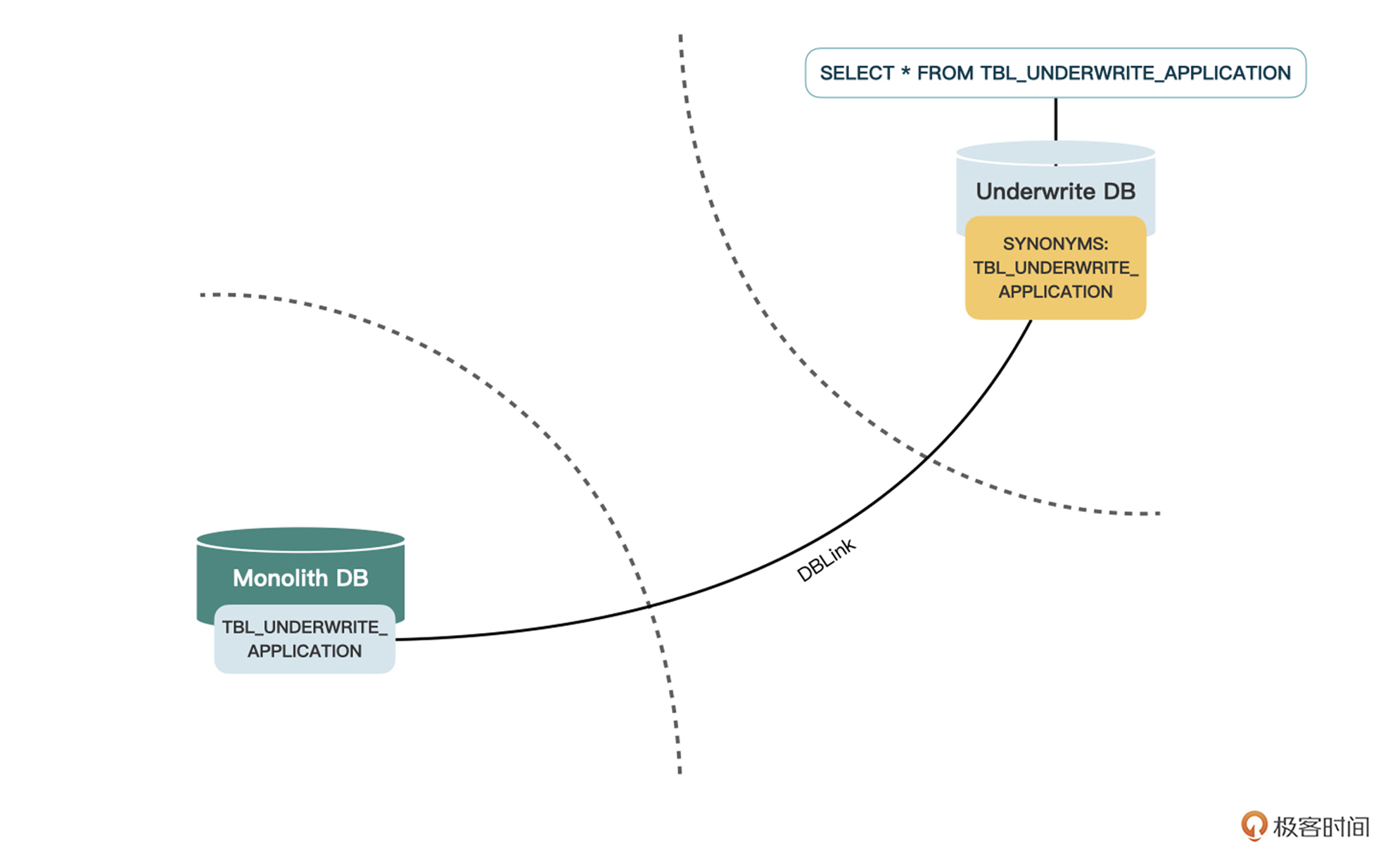
2.如果数据库是像Oracle这种包含类似DBLink技术的,我们可以在新库中创建同义词,通过DBLink指向旧库中的表,这样无论是读写都可以正常完成。当所有API改造完成后,我们根据所创建的同义词,在新库中创建表并迁移数据。
|
|
|
|
|
|
|
|
|
|
|
|
上述两种方案可能看起来都不是特别完美,相当于一个微服务通过某种方式,访问了它不应该访问的数据库。但不要忘了,这只是改造过程中的中间步骤。
|
|
|
|
|
|
当全部改造完成后,这种临时的基础设施(视图或同义词)就会被删除,所以完全不必纠结。另外,这样简单的方式,能让我们比较容易地获取原单体库中的数据,是符合“**以降低认知负载为前提**”这个原则的。
|
|
|
|
|
|
在这个案例中,虽然核保服务对于核保数据既包含读取,也包含写入,不能使用视图的方式,但由于数据库是Oracle,我们可以使用同义词的方式来实现双向同步。
|
|
|
|
|
|
建立好回退和数据同步机制之后,就可以逐个API做改造了。虽然我们已经通过战术分叉,将核保模块从单体中复制了一份到新的核保服务中,但核保服务中的代码还是对原单体有着很强的依赖。我们需要将各个API逐一改造,解除对于非核保代码的依赖。
|
|
|
|
|
|
## 用API调用取代代码依赖
|
|
|
|
|
|
我们先来看这样的一段位于核保服务中的代码。这里说明一下,为了聚焦于主要的问题,我对代码进行了大量的精简,实际遗留系统中的代码很可能比这要复杂很多,但解决思路是一致的。后面出现的代码也是如此。
|
|
|
|
|
|
```java
|
|
|
// 核保服务中的代码 - UnderwriteApplicationService.java
|
|
|
public UnderwriteApplicationDto getUnderwriteApplication(long policyId) {
|
|
|
UnderwriteApplicationDao underwriteApplicationDao = new UnderwriteApplicationDao();
|
|
|
UnderwriteApplicationModel underwriteApplicationModel = underwriteApplicationDao.getUnderwriteApplication(policyId);
|
|
|
PolicyDao policyDao = new PolicyDao();
|
|
|
PolicyModel policyModel = policyDao.getPolicy(policyId);
|
|
|
return getUnderwriteApplicationDto(underwriteApplicationModel, policyModel);
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
这段代码先通过UnderwriteApplicationDao获取核保申请数据(核保申请就是指一个正处于核保过程中的保单),然后通过PolicyDao获取保单数据,之后将这两个数据进行整合,得到我们想要返回的DTO。
|
|
|
|
|
|
可以看到,前面这段代码虽然位于核保服务中,但除了依赖了核保服务中的代码(即获取核保申请)之外,还依赖了本应属于单体中的代码(即获取保单),这就是我们在拆分的过程中会遇到的最典型的代码耦合,只有把这些耦合点全部解除,新的核保服务才能彻底摆脱对于单体的二进制依赖。因此下一步我们要做的就是把对于获取保单代码的依赖进行解耦。
|
|
|
|
|
|
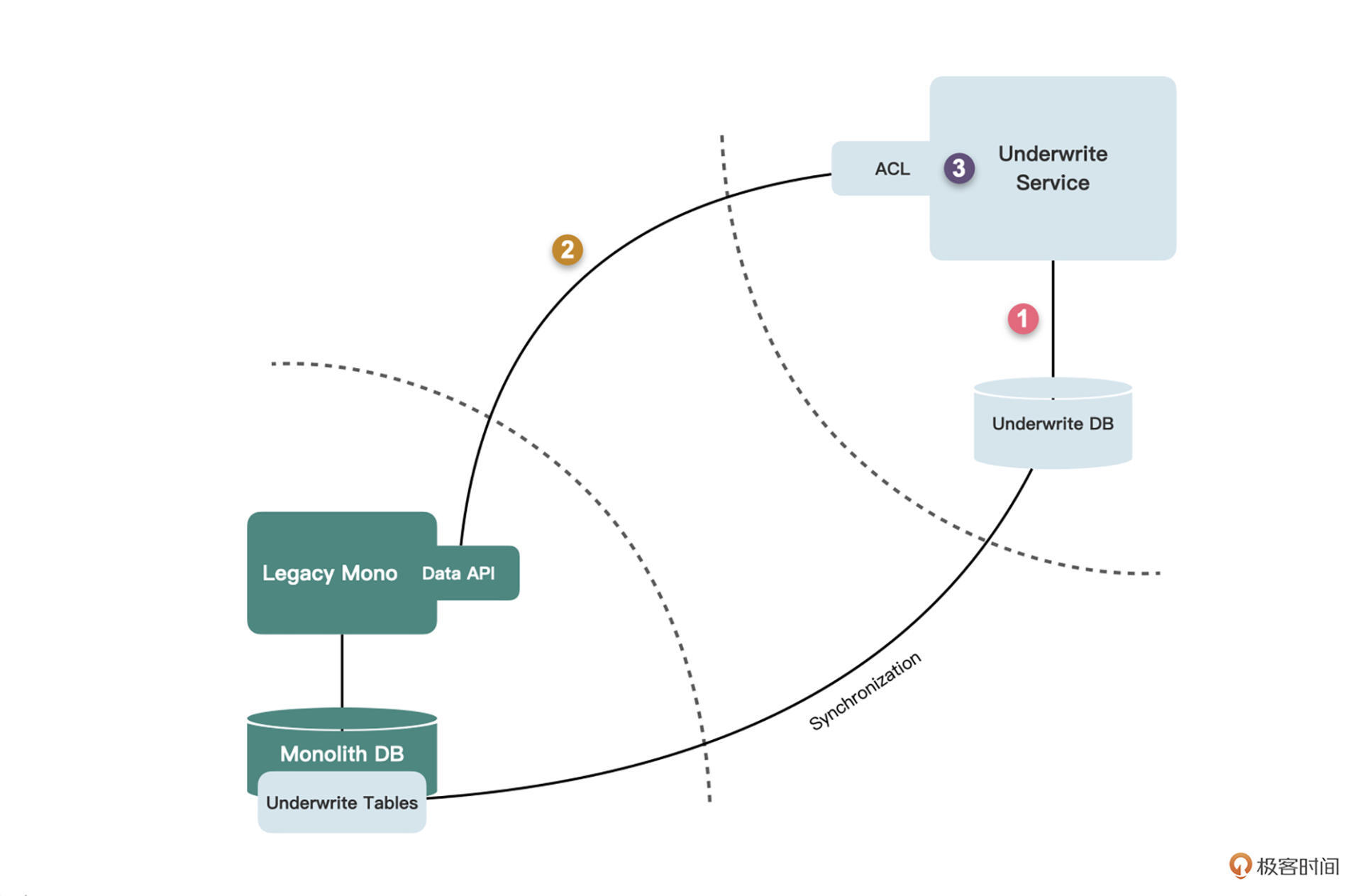
我们的解决方案非常的简单直观。简单总结就是三步走:
|
|
|
|
|
|
1.调自己;
|
|
|
|
|
|
2.调服务;
|
|
|
|
|
|
3.组数据。
|
|
|
|
|
|
|
|
|
|
|
|
我们首先让核保服务调用自己的数据库拿到核保申请数据。然后在单体中创建一个新的API,让它返回保单数据,在核保服务中的防腐层(ACL)中调用这个API,拿到保单数据。最后,在原来的代码处对两部分数据进行组合。由于这个新建的API也是为了给核保服务提供数据,我们仍然将其称为数据API。
|
|
|
|
|
|
改造后的代码类似下面这种:
|
|
|
|
|
|
```java
|
|
|
// 核保服务中的代码 - UnderwriteApplicationService.java
|
|
|
public UnderwriteApplicationDto getUnderwriteApplication(long policyId) {
|
|
|
UnderwriteApplicationDao underwriteApplicationDao = new UnderwriteApplicationDao();
|
|
|
UnderwriteApplicationModel underwriteApplicationModel = underwriteApplicationDao.getUnderwriteApplication(policyId);
|
|
|
// 核保服务中的防腐层,调用单体中的API来获取保单信息
|
|
|
PolicyServiceProvider policyServiceProvider = new PolicyServiceProvider();
|
|
|
PolicyModel policyModel = policyServiceProvider.getPolicy(policyId);
|
|
|
return getUnderwriteApplicationDto(underwriteApplication, policyModel);
|
|
|
}
|
|
|
|
|
|
// 核保服务中的防腐层 - PolicyServiceProvider.java
|
|
|
public PolicyModel getPolicy(long policyId) {
|
|
|
MonolithApiClient apiClient = new MonolithApiClient();
|
|
|
PolicyDto policyDto = apiClient.getPolicy(policyId);
|
|
|
return convertToPolicyModel(policyDto);
|
|
|
}
|
|
|
|
|
|
// 单体服务中的新API - PolicyController.java
|
|
|
public PolicyDto getPolicy(long policyId) {
|
|
|
PolicyDao policyDao = new PolicyDao();
|
|
|
PolicyModel policyModel = policyDao.getPolicy(policyId);
|
|
|
return convertToPolicyDto(policyModel);
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
有同学可能会问,为什么要建立这样一个防腐层呢?直接在原来的位置调用API不行吗?这样做不是多此一举吗?
|
|
|
|
|
|
我们在这里添加防腐层的主要目的,其实是为了解除对于API调用部分的依赖,并对获取到的数据进行转换,从用于数据传输的DTO,转回我们代码处所需要的Model。这样的防腐层可以有效防止业务代码的腐坏,把会发生变动的部分隔离在外面。
|
|
|
|
|
|
你可能还会问,上面的代码有很多坏味道(比如一些命名的问题和可测试性的问题),为什么不重构?答案是因为要分离关注点。我们现在关注的是架构解耦,并不是代码重构。一旦因为重构导致当前改造的范围扩大,就无法完成既定的交付目标了。
|
|
|
|
|
|
你可能还想到一个问题,就是这里是否可以使用**抽象分支**来进行增量重构,即将UnderwriteApplicationService提取成一个接口,将原来的类作为旧实现,再写一个新实现来解耦。
|
|
|
|
|
|
其实是没有必要的。因为我们在最上层已经通过特性开关来实现了这个“分支”,就没有必要在代码级别再使用抽象分支了。也就是说,我们使用了**绞杀植物模式**用服务替换旧模块,代码已经复制出来一份了,在复制出来的这部分中,就没必要再使用**修缮者模式**了。
|
|
|
|
|
|
## 小结
|
|
|
|
|
|
总结一下今天的课程。基于上节课的单体系统,我们开始着手拆分代码,不过这节课只前进了一小步,后面还有三节课的内容等着你。但今天这一小步却十分重要,因为“反向代理”和“数据同步”是后面几节课的基础,微服务拆分的方方面面都离不开这两个实践。
|
|
|
|
|
|
如果你的数据库是Oracle,强烈建议你使用基于DBLink的同义词来进行“数据同步”。
|
|
|
|
|
|
其实严格来说,这并不算是同步,而只是一种转换,但它可以让你暂时不用考虑数据的问题,降低了认知负载的同时,还能帮你梳理数据的所有权。等代码解耦完成,你会发现,在核保库中所创建的同义词,都是需要拆分到核保库中的数据表。
|
|
|
|
|
|
除此之外,我还分享了“用API取代代码依赖”,这也是比较基础的一个实践,是代码解耦的基本方法。后面的课程里要讲的数据访问解耦、存储过程解耦等,都使用了和这个实践类似的方法。
|
|
|
|
|
|
## 思考题
|
|
|
|
|
|
感谢你学完了今天的课程,今天的思考题我在文中已经给出了。也就是在通过开关进行反向代理的时候,为什么要将当前的ServletRequest做一下转换,再转发给核保服务呢?为什么不能直接调用request.sendRedirect方法直接转发呢?
|
|
|
|
|
|
欢迎你在留言区跟我交流互动,也推荐你把今天的内容分享给更多同事、朋友,我们一起来拆分单体。
|
|
|
|