16 KiB
16|DevOps现代化: 从持续构建到持续集成
你好,我是姚琪琳。
前面我们用八节课的篇幅,一起学习了代码现代化和架构现代化的众多模式。掌握了这些遗留系统代码和架构的治理方法,应对遗留系统的挑战你是不是也更有信心了?
不过只治理代码和架构还不够,我们希望修改后的代码可以“火速”部署到生产环境里,这样才能提高整个端到端的交付效率,让每次改动工作都能及时得到反馈,尽快验证效果。
遗留系统的构建方式
遗憾的是,遗留系统的特点之一就是DevOps相当落后,甚至可以说完全没有。
在遗留系统中,一次上线前构建过程可能是这样的:一位打包专员,在本地或远程的机器上拉取代码,完成集成、打包和测试的工作,并准备手动部署。这时,即使再紧急的代码提交都会被拒绝,因为一个干净的打包环境来之不易,新引入的代码会导致所有的流程重来一遍,对打包专员来说是相当痛苦的。
这样的过程死板、低效、容易出错,一点也体现不出软件中“软”的特点(即灵活)。所以,后来市面上出现了越来越多的自动构建工具,可以自动拉取代码、构建、集成、打包和部署,甚至还能运行自动化测试,这简直就是打包专员们的福音。
但是,如果只是在打包和部署时使用这些工具,那真是大材小用了。而且,这样也没有解决软件开发中最难解决的问题之一,就是多人协作的情况下,代码集成的问题。
这里的集成是指,将多个人的工作成果合并在一起,并验证这些合并后的代码是否达到了一定的质量要求,是否可以工作的过程。
Kent Beck早在上世纪90年代就提出了持续集成的概念,即集成的频率越高越好,极限情况下就是持续地每时每刻都在集成。你可能会问,真的需要这样吗?
我来给你举个例子。相信你肯定有类似的经历,如果家里一周不扫地,再扫地时就会发现很多尘土,每次大扫除也变得十分辛苦。但如果你每天都坚持扫地,每次的工作就不会有很多,因为灰尘的积累时间只有短短的一天。这其实就是极限编程的理念:越是痛苦的事情,就越要频繁地去做,这样每次做的时候就没有那么痛苦。
集成是软件开发中很痛苦的事情,因为会发生很多不可预知的情况,很容易就要花费比原始编程更多的时间。越长时间不集成,不可预知的事情就越多,消耗的时间就越长。因此我们就要更加频繁地去集成,这样每次集成就不会那么痛苦了。
对于遗留系统来说,如果连自动化的流水线都还不存在,那么你的首要任务,就是先打造这样一条流水线,先做到持续构建。
持续构建
持续构建是指,每次代码提交都会触发一次构建工作,并执行一些相关任务。这个过程由持续集成工具自动化完成,大致过程如下:
1.开发人员将代码提交(PUSH)到远程代码仓库;
2.持续集成服务器按一定时间间隔(比如1分钟)轮询代码仓库,以便及时发现代码变更;
3.如果发现了代码变更,持续集成服务器就将代码拉取(PULL)到自己本地;
4.持续集成服务器按照指定的构建脚本执行各项任务,包括编译、单元测试、代码扫描、安全扫描、打包等;
5.任务执行完毕后,会把结果(成功或失败)反馈给开发团队。
有了持续构建,就能解决遗留系统最头疼的问题之一:不知道从哪去找可以部署到各个环境的软件包。打包部署不再依赖于打包专员的手工操作,大大缩短和简化了部署流程。
在遗留系统中引入持续构建
你可以使用Jekins或GoCD这样的开源持续集成工具,来搭建持续集成服务器。也可以搭配上BitBucket或GitLab之类的源代码管理工具,来提供Pull Request和Code Review等其他功能。
我建议你选用Atlassian公司的三件套:BitBucket、Jira和Confluence。可以将代码管理、需求管理和知识管理打通,补齐遗留系统中缺失的这些内容。当然,其他替代工具也是完全没有问题的。
很多时候,遗留系统的代码体量过于庞大,想要在本地构建一次需要很长时间,甚至会内存溢出。你当然可以从代码和架构层面通过拆分代码库来解决,但这无法解决燃眉之急。更快速的方式是,在合并代码的时候,触发Web Hook,让持续集成服务器在远端的特性分支上先执行一次构建,用这次构建来替代本地的构建。然后合并代码,并在合并后的目标分支上再执行一次构建。
代码的构建解决了,下一步就是解决数据库的迁移脚本。在遗留系统中,往往各个环境中的数据库都不完全相同,因为各个环境都可能有手工改动的痕迹。因此你第一步要做的,就是以生产库为标准,统一所有环境数据库的DDL,并以此作为基线。然后将后续的所有DDL和DML都通过Flayway管理起来,并版本化。
遗留系统要做到单次构建(如每日构建)还是相对容易的,但要想做到“持续”构建,开发人员就必须改变之前的一些工作习惯。就拿提交代码来说,很多开发人员会等到所有的代码都编写完成,才进行一次提交。这样,代码冲突的风险非常高,很可能出现代码写了两天,合并就用了半天的尴尬情况。如果每个人都这样,就无法做到每天构建多次的目标。
任务分解
要避免这种局面,开发人员就要对自己编写的代码做出良好的规划,分解出若干小的任务,每个任务都能在很短的时间内完成(比如15分钟、40分钟,或者是一个番茄钟的时间),而且任务最好是按照一个功能的端到端的场景来划分,而不要按技术层级去划分。
为什么不推荐按技术层级划分呢?比如在开发一个需求时,大多数开发人员都是这样的:先修改数据库层,看看是否需要增加表或字段;再开发数据访问层,对新增加的表或字段编写映射代码;然后编写服务层的代码,这时可能才真正接触业务逻辑;接下来是Controller,可能要添加新的API或修改已有的API;最后,可能还会涉及到一些前端的修改。
如果按照这样的顺序去开发,每次完成的小任务都是不能提交的,因为新的场景没有开发完,而旧的场景又可能被新添加的代码破坏。
正确的做法是按端到端的方式去分解任务,一个任务完成一个简单的业务场景。每个任务开发完毕,一个端到端的小场景就开发完了,你可以针对这个小场景写单元测试,也可以在本地环境进行自测。然后就可以提交(commit)代码了。
比如你要开发一个简单的登录功能,那么可以这样做任务分解:
1.用户可以使用用户名和密码来登录网站
2.用户名不存在,则登录失败
3.密码错误,则登录失败
你会看到,我是从一个端到端的业务场景来描述一个任务的,而不是我要修改Service层的那几个方法。完成第一个任务可能要耗费一些时间,搭建一些基础代码,而后面的任务就像是对第一个任务的增强,就像是一种迭代式的演进过程。
多个小任务完成之后,你感觉差不多了,就可以更新一下远端的代码,解决一下冲突,然后PUSH。这时每个commit都覆盖了一个小的场景,是系统的一个增量,是可以交付的。
这就好像是创作一幅水粉画,你首先需要画出大概的轮廓,再逐层往上叠加各种颜料,直到最后完成。这个过程中,每一次叠加别人都可能看出整体大致的样子,给出修改意见。而如果你一开始就只精雕细琢局部一小部分,别人可能根本不知道你画的是什么。
更多关于任务分解的内容,你可以参考郑晔的在《10x程序员工作法》专栏中的文章。
小步提交
上面提到的按分解的任务开发并且提交的方式,就是小步提交。有些人理解小步提交就是指每次commit尽量少的代码,这其实是错误的。如果你提交的内容很少,但却破坏了编译和测试,这样的提交也是不合格的,因为它没有办法PUSH,没法做到持续提交。
真正的小步提交是指,每个commit都完成了一个端到端的功能点,因此都是可以PUSH到代码仓库的。如果愿意,你可以针对这个commit进行验证、测试甚至部署。只有这样,最终才能做到真正的持续交付。
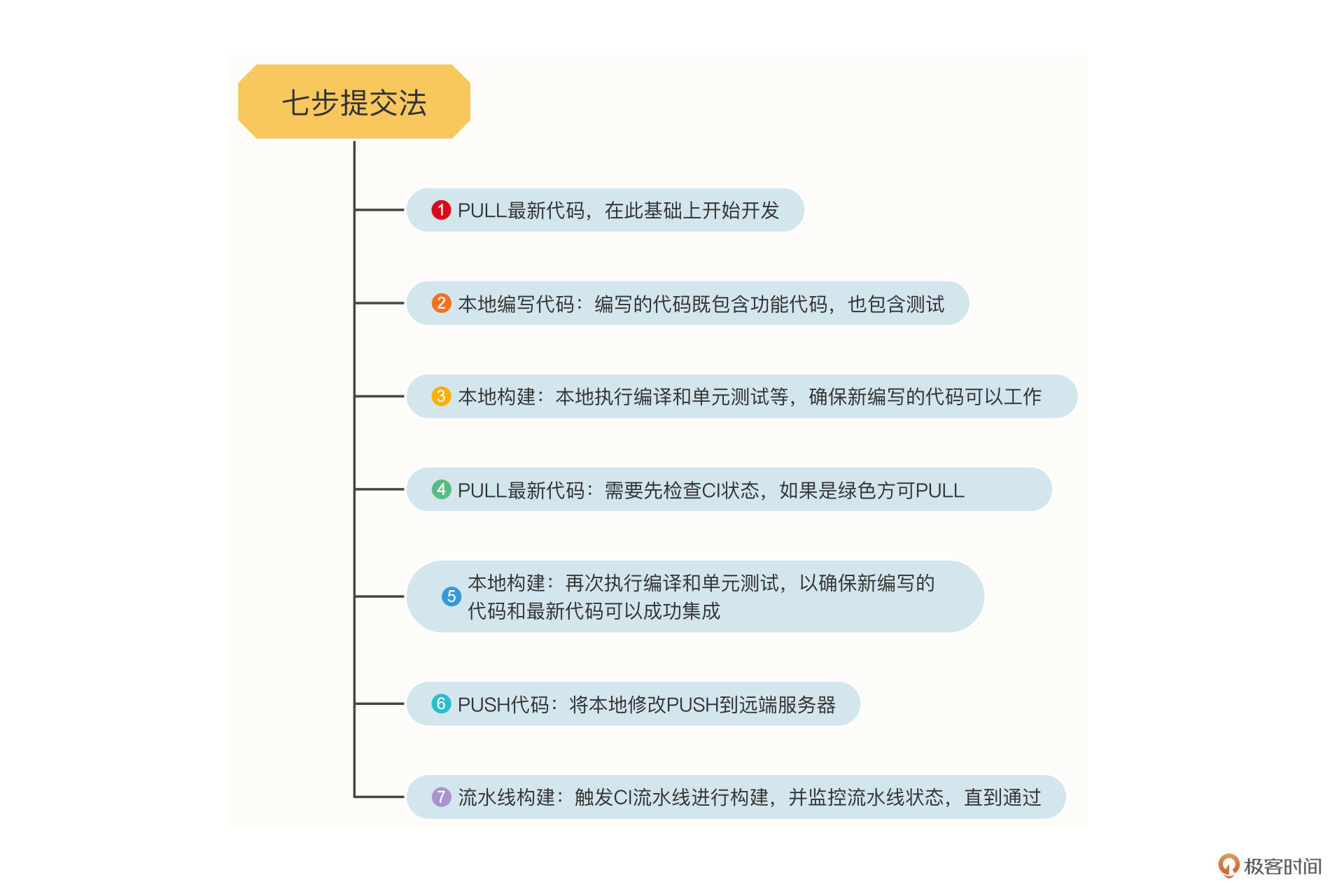
在提交代码时,我的同事们早年总结了一套行之有效的七步提交法,它的过程是这样的:
1.PULL最新代码,确保在最新的代码基础上开始开发;
2.本地编写代码;
3.本地构建:本地执行编译和单元测试等,以确保新编写的代码是可以工作的;
4.PULL最新代码:需要先检查CI状态,如果是绿色则可以PULL;
5.本地构建:再次执行编译和单元测试,以确保新编写的代码和最新代码可以成功集成;
6.PUSH代码:将本地修改PUSH到远端服务器;
7.流水线构建:触发CI流水线进行构建,并监控流水线状态,直到通过。
对于第二步编写的代码,既可以是与一个需求相关的若干commit,也可以小到仅仅是一个commit。在这个commit中,既要包含功能代码,也要包含测试。
不要害怕编写测试,如果你的任务分解是基于业务场景的,而测试是根据分解的任务编写的,你会发现这一切就会变得很容易,甚至测试驱动开发也是很自然而然的事情。在此,我再次推荐徐昊的《TDD项目实战70讲》。
质量门禁
持续构建的过程不仅仅是对最新的代码进行编译和打包,还要进行一定的质量检查,也就是质量门禁。效率最高的检查手段就是单元测试,它运行快,反馈快,可以在本地运行,能让你在第一时间知道自己的代码是否破坏了其他功能,或者是否达到了单元测试覆盖率的要求。
第八节课我们讲过,遗留系统很可能没法直接做单元测试。你可以先对代码进行可测试化重构,再添加单元测试。但这将是一个十分漫长的过程,因此在搭建遗留系统的持续集成流水线时,可以先跳过这一步骤,等有了单元测试之后,再加到流水线中来。
除了单元测试,代码扫描也是一种检查质量的有效方式。你可以使用SonarQube这样的工具对代码进行静态扫描,检查代码的规范和各种潜在的错误。一方面它能为我们敲响警钟,提升代码质量,另一方面也可以让Code Review更专注在代码的设计上。
一般来说,代码扫描的结果如果超过某个配置的阈值,就会阻断整个持续集成流水线。但对于遗留系统来说,可能会扫出成千上万个代码漏洞。这时你可以选择不阻断流水线,只将扫描结果作为参考,也可以将某个结果作为基线,来验证新提交的代码是否包含新的漏洞。
如果你的遗留系统在DevOps方面还是一张白纸,我建议你先引入工具和平台,做到持续构建。在持续构建时,也可以考虑自身情况,进行一些剪裁,比如去除单元测试覆盖率检查,去除代码扫描,只做代码的编译和打包。这样虽然看上去很单薄,但引入工具本身已经前进了一大步。对很多遗留系统来说,能做到这一步,已经相当不容易了。
等到团队适应了新的工作方式,我们再逐步添加质量门禁和其他DevOps实践,做到持续集成。
持续集成
持续集成包含持续构建的所有步骤,并且在它后面还增加了部署到某个环境的流程,比如部署到测试环境,并且进行冒烟测试、接口测试等。同时,在这个阶段,你还可以优化一下流水线,进一步提升效率。
分级构建
持续集成流水线的重要作用之一就是快速反馈。对于编译不通过、测试失败、代码风格不符合标准等问题,我们都希望第一时间看到流水线失败,继而根据日志去分析失败原因,快速修复。
但遗留系统的代码库往往很庞大,仅仅编译可能就会很长时间,如果再跑测试和代码扫描,我们得到反馈的时间就会大大拉长。
Martin Fowler在《持续集成》一文中提出了次级构建的概念,即对构建进行分级,把那些执行速度快、反馈质量高的步骤放到一级构建中,将执行速度慢的步骤放到次级构建环节。
比如单元测试执行的速度很快,就可以放到较早的构建环节;而集成测试很慢,就可以放到次级构建;对于代码扫描这种更慢的构建,甚至可以使用单独的流水线,在每天晚上执行一遍。
只有把不同构建过程按执行速度和反馈效果拆分为不同阶段,整个构建或集成过程才更像是一条真正的流水线。
在真正的工业流水线上,工人们围绕一个制品(artifact)进行组装,一个工人完成工作后,就把制品传递给下一个工人。这就好像是一个构建阶段结束后,把制品传递给下一个构建阶段。
制品晋级
持续集成流水线的产物也叫做制品(artifact),有时也翻译为工件。一次代码轮询所触发的流水线构建,只会产生一个制品。在持续集成的时候,可以把构建阶段产生的软件包作为制品,存入制品库中。在需要部署的时候,会从制品库中抽取最新的制品。
通常来说,不同的测试环境有各自的制品库,当一个制品满足了相应环境的要求后,就可以晋级到这个环境中。
举个例子,一次提交在成功构建后产生的制品,经历了单元测试、代码扫描等质量门禁,才会进入QA制品库。这时这个制品就可以部署到QA环境中。在QA环境通过QA测试后,方能进入UAT制品库,进而部署到UAT环境。以此类推,如果该制品通过了所有非生产环境的验证,就可以进入PROD制品库,作为部署到生产环境的候选制品了。
这种制品晋级的机制,是持续集成和持续交付的基础。很多号称做到持续交付的项目,其实只不过是交付的频率高一些而已,根本没有制品晋级的机制,并不是持续交付。
遗留系统在一开始做持续构建时,可以先不做制品晋级,只把制品作为部署的候选包。等其他DevOps实践慢慢丰富以后,再考虑实现制品晋级。
小结
今天我们学习了如何在一个没有持续集成流水线的遗留系统中,逐步搭建基础设施,从持续构建开始,慢慢做到持续集成的初级阶段。
这其中包含很多工作习惯的改变,比如任务分解、小步提交等,一开始你可能并不适应,但要知道,只有做好任务分解,才能做到小步提交,才能做到持续提交代码并持续构建。这些都是DevOps文化的一部分。一个遗留系统要想真正做好DevOps现代化,就必须转变思想,摒弃成见,彻底拥抱DevOps。
这节课的七步提交法,我也为你准备了图解,供你参考。
在做到持续构建之后,你可以逐步引入分级构建、制品晋级等实践,慢慢向持续集成演进。当然,要想真正做到持续集成,团队需要转变的东西还很多,我们就留到下节课来讲解吧。
思考题
感谢你学完了今天的内容,今天的思考题是,请你分享一下现在项目的DevOps实践,并分析一下是属于哪个阶段?是持续构建?还是持续集成?
期待你的分享,如果你觉得这节课对你有帮助,别忘了分享给你的同事和朋友,我们一起转换思维,拥抱DevOps。