32 KiB
54 | 存储虚拟化(下):如何建立自己保管的单独档案库?
上一节,我们讲了qemu启动过程中的存储虚拟化。好了,现在qemu启动了,硬盘设备文件已经打开了。那如果我们要往虚拟机的一个进程写入一个文件,该怎么做呢?最终这个文件又是如何落到宿主机上的硬盘文件的呢?这一节,我们一起来看一看。
前端设备驱动virtio_blk
虚拟机里面的进程写入一个文件,当然要通过文件系统。整个过程和咱们在文件系统那一节讲的过程没有区别。只是到了设备驱动层,我们看到的就不是普通的硬盘驱动了,而是virtio的驱动。
virtio的驱动程序代码在Linux操作系统的源代码里面,文件名叫drivers/block/virtio_blk.c。
static int __init init(void)
{
int error;
virtblk_wq = alloc_workqueue("virtio-blk", 0, 0);
major = register_blkdev(0, "virtblk");
error = register_virtio_driver(&virtio_blk);
......
}
module_init(init);
module_exit(fini);
MODULE_DEVICE_TABLE(virtio, id_table);
MODULE_DESCRIPTION("Virtio block driver");
MODULE_LICENSE("GPL");
static struct virtio_driver virtio_blk = {
......
.driver.name = KBUILD_MODNAME,
.driver.owner = THIS_MODULE,
.id_table = id_table,
.probe = virtblk_probe,
.remove = virtblk_remove,
......
};
前面我们介绍过设备驱动程序,从这里的代码中,我们能看到非常熟悉的结构。它会创建一个workqueue,注册一个块设备,并获得一个主设备号,然后注册一个驱动函数virtio_blk。
当一个设备驱动作为一个内核模块被初始化的时候,probe函数会被调用,因而我们来看一下virtblk_probe。
static int virtblk_probe(struct virtio_device *vdev)
{
struct virtio_blk *vblk;
struct request_queue *q;
......
vdev->priv = vblk = kmalloc(sizeof(*vblk), GFP_KERNEL);
vblk->vdev = vdev;
vblk->sg_elems = sg_elems;
INIT_WORK(&vblk->config_work, virtblk_config_changed_work);
......
err = init_vq(vblk);
......
vblk->disk = alloc_disk(1 << PART_BITS);
memset(&vblk->tag_set, 0, sizeof(vblk->tag_set));
vblk->tag_set.ops = &virtio_mq_ops;
vblk->tag_set.queue_depth = virtblk_queue_depth;
vblk->tag_set.numa_node = NUMA_NO_NODE;
vblk->tag_set.flags = BLK_MQ_F_SHOULD_MERGE;
vblk->tag_set.cmd_size =
sizeof(struct virtblk_req) +
sizeof(struct scatterlist) * sg_elems;
vblk->tag_set.driver_data = vblk;
vblk->tag_set.nr_hw_queues = vblk->num_vqs;
err = blk_mq_alloc_tag_set(&vblk->tag_set);
......
q = blk_mq_init_queue(&vblk->tag_set);
vblk->disk->queue = q;
q->queuedata = vblk;
virtblk_name_format("vd", index, vblk->disk->disk_name, DISK_NAME_LEN);
vblk->disk->major = major;
vblk->disk->first_minor = index_to_minor(index);
vblk->disk->private_data = vblk;
vblk->disk->fops = &virtblk_fops;
vblk->disk->flags |= GENHD_FL_EXT_DEVT;
vblk->index = index;
......
device_add_disk(&vdev->dev, vblk->disk);
err = device_create_file(disk_to_dev(vblk->disk), &dev_attr_serial);
......
}
在virtblk_probe中,我们首先看到的是struct request_queue,这是每一个块设备都有的一个队列。还记得吗?它有两个函数,一个是make_request_fn函数,用于生成request;另一个是request_fn函数,用于处理request。
这个request_queue的初始化过程在blk_mq_init_queue中。它会调用blk_mq_init_allocated_queue->blk_queue_make_request。在这里面,我们可以将make_request_fn函数设置为blk_mq_make_request,也就是说,一旦上层有写入请求,我们就通过blk_mq_make_request这个函数,将请求放入request_queue队列中。
另外,在virtblk_probe中,我们会初始化一个gendisk。前面我们也讲了,每一个块设备都有这样一个结构。
在virtblk_probe中,还有一件重要的事情就是,init_vq会来初始化virtqueue。
static int init_vq(struct virtio_blk *vblk)
{
int err;
int i;
vq_callback_t **callbacks;
const char **names;
struct virtqueue **vqs;
unsigned short num_vqs;
struct virtio_device *vdev = vblk->vdev;
......
vblk->vqs = kmalloc_array(num_vqs, sizeof(*vblk->vqs), GFP_KERNEL);
names = kmalloc_array(num_vqs, sizeof(*names), GFP_KERNEL);
callbacks = kmalloc_array(num_vqs, sizeof(*callbacks), GFP_KERNEL);
vqs = kmalloc_array(num_vqs, sizeof(*vqs), GFP_KERNEL);
......
for (i = 0; i < num_vqs; i++) {
callbacks[i] = virtblk_done;
names[i] = vblk->vqs[i].name;
}
/* Discover virtqueues and write information to configuration. */
err = virtio_find_vqs(vdev, num_vqs, vqs, callbacks, names, &desc);
for (i = 0; i < num_vqs; i++) {
vblk->vqs[i].vq = vqs[i];
}
vblk->num_vqs = num_vqs;
......
}
按照上面的原理来说,virtqueue是一个介于客户机前端和qemu后端的一个结构,用于在这两端之间传递数据。这里建立的struct virtqueue是客户机前端对于队列的管理的数据结构,在客户机的linux内核中通过kmalloc_array进行分配。
而队列的实体需要通过函数virtio_find_vqs查找或者生成,所以这里我们还把callback函数指定为virtblk_done。当buffer使用发生变化的时候,我们需要调用这个callback函数进行通知。
static inline
int virtio_find_vqs(struct virtio_device *vdev, unsigned nvqs,
struct virtqueue *vqs[], vq_callback_t *callbacks[],
const char * const names[],
struct irq_affinity *desc)
{
return vdev->config->find_vqs(vdev, nvqs, vqs, callbacks, names, NULL, desc);
}
static const struct virtio_config_ops virtio_pci_config_ops = {
.get = vp_get,
.set = vp_set,
.generation = vp_generation,
.get_status = vp_get_status,
.set_status = vp_set_status,
.reset = vp_reset,
.find_vqs = vp_modern_find_vqs,
.del_vqs = vp_del_vqs,
.get_features = vp_get_features,
.finalize_features = vp_finalize_features,
.bus_name = vp_bus_name,
.set_vq_affinity = vp_set_vq_affinity,
.get_vq_affinity = vp_get_vq_affinity,
};
根据virtio_config_ops的定义,virtio_find_vqs会调用vp_modern_find_vqs。
static int vp_modern_find_vqs(struct virtio_device *vdev, unsigned nvqs,
struct virtqueue *vqs[],
vq_callback_t *callbacks[],
const char * const names[], const bool *ctx,
struct irq_affinity *desc)
{
struct virtio_pci_device *vp_dev = to_vp_device(vdev);
struct virtqueue *vq;
int rc = vp_find_vqs(vdev, nvqs, vqs, callbacks, names, ctx, desc);
/* Select and activate all queues. Has to be done last: once we do
* this, there's no way to go back except reset.
*/
list_for_each_entry(vq, &vdev->vqs, list) {
vp_iowrite16(vq->index, &vp_dev->common->queue_select);
vp_iowrite16(1, &vp_dev->common->queue_enable);
}
return 0;
}
在vp_modern_find_vqs中,vp_find_vqs会调用vp_find_vqs_intx。
static int vp_find_vqs_intx(struct virtio_device *vdev, unsigned nvqs,
struct virtqueue *vqs[], vq_callback_t *callbacks[],
const char * const names[], const bool *ctx)
{
struct virtio_pci_device *vp_dev = to_vp_device(vdev);
int i, err;
vp_dev->vqs = kcalloc(nvqs, sizeof(*vp_dev->vqs), GFP_KERNEL);
err = request_irq(vp_dev->pci_dev->irq, vp_interrupt, IRQF_SHARED,
dev_name(&vdev->dev), vp_dev);
vp_dev->intx_enabled = 1;
vp_dev->per_vq_vectors = false;
for (i = 0; i < nvqs; ++i) {
vqs[i] = vp_setup_vq(vdev, i, callbacks[i], names[i],
ctx ? ctx[i] : false,
VIRTIO_MSI_NO_VECTOR);
......
}
}
在vp_find_vqs_intx中,我们通过request_irq注册一个中断处理函数vp_interrupt,当设备的配置信息发生改变,会产生一个中断,当设备向队列中写入信息时,也会产生一个中断,我们称为vq中断,中断处理函数需要调用相应的队列的回调函数。
然后,我们根据队列的数目,依次调用vp_setup_vq,完成virtqueue、vring的分配和初始化。
static struct virtqueue *vp_setup_vq(struct virtio_device *vdev, unsigned index,
void (*callback)(struct virtqueue *vq),
const char *name,
bool ctx,
u16 msix_vec)
{
struct virtio_pci_device *vp_dev = to_vp_device(vdev);
struct virtio_pci_vq_info *info = kmalloc(sizeof *info, GFP_KERNEL);
struct virtqueue *vq;
unsigned long flags;
......
vq = vp_dev->setup_vq(vp_dev, info, index, callback, name, ctx,
msix_vec);
info->vq = vq;
if (callback) {
spin_lock_irqsave(&vp_dev->lock, flags);
list_add(&info->node, &vp_dev->virtqueues);
spin_unlock_irqrestore(&vp_dev->lock, flags);
} else {
INIT_LIST_HEAD(&info->node);
}
vp_dev->vqs[index] = info;
return vq;
}
static struct virtqueue *setup_vq(struct virtio_pci_device *vp_dev,
struct virtio_pci_vq_info *info,
unsigned index,
void (*callback)(struct virtqueue *vq),
const char *name,
bool ctx,
u16 msix_vec)
{
struct virtio_pci_common_cfg __iomem *cfg = vp_dev->common;
struct virtqueue *vq;
u16 num, off;
int err;
/* Select the queue we're interested in */
vp_iowrite16(index, &cfg->queue_select);
/* Check if queue is either not available or already active. */
num = vp_ioread16(&cfg->queue_size);
/* get offset of notification word for this vq */
off = vp_ioread16(&cfg->queue_notify_off);
info->msix_vector = msix_vec;
/* create the vring */
vq = vring_create_virtqueue(index, num,
SMP_CACHE_BYTES, &vp_dev->vdev,
true, true, ctx,
vp_notify, callback, name);
/* activate the queue */
vp_iowrite16(virtqueue_get_vring_size(vq), &cfg->queue_size);
vp_iowrite64_twopart(virtqueue_get_desc_addr(vq),
&cfg->queue_desc_lo, &cfg->queue_desc_hi);
vp_iowrite64_twopart(virtqueue_get_avail_addr(vq),
&cfg->queue_avail_lo, &cfg->queue_avail_hi);
vp_iowrite64_twopart(virtqueue_get_used_addr(vq),
&cfg->queue_used_lo, &cfg->queue_used_hi);
......
return vq;
}
struct virtqueue *vring_create_virtqueue(
unsigned int index,
unsigned int num,
unsigned int vring_align,
struct virtio_device *vdev,
bool weak_barriers,
bool may_reduce_num,
bool context,
bool (*notify)(struct virtqueue *),
void (*callback)(struct virtqueue *),
const char *name)
{
struct virtqueue *vq;
void *queue = NULL;
dma_addr_t dma_addr;
size_t queue_size_in_bytes;
struct vring vring;
/* TODO: allocate each queue chunk individually */
for (; num && vring_size(num, vring_align) > PAGE_SIZE; num /= 2) {
queue = vring_alloc_queue(vdev, vring_size(num, vring_align),
&dma_addr,
GFP_KERNEL|__GFP_NOWARN|__GFP_ZERO);
if (queue)
break;
}
if (!queue) {
/* Try to get a single page. You are my only hope! */
queue = vring_alloc_queue(vdev, vring_size(num, vring_align),
&dma_addr, GFP_KERNEL|__GFP_ZERO);
}
queue_size_in_bytes = vring_size(num, vring_align);
vring_init(&vring, num, queue, vring_align);
vq = __vring_new_virtqueue(index, vring, vdev, weak_barriers, context, notify, callback, name);
to_vvq(vq)->queue_dma_addr = dma_addr;
to_vvq(vq)->queue_size_in_bytes = queue_size_in_bytes;
to_vvq(vq)->we_own_ring = true;
return vq;
}
在vring_create_virtqueue中,我们会调用vring_alloc_queue,来创建队列所需要的内存空间,然后调用vring_init初始化结构struct vring,来管理队列的内存空间,调用__vring_new_virtqueue,来创建struct vring_virtqueue。
这个结构的一开始,是struct virtqueue,它也是struct virtqueue的一个扩展,紧接着后面就是struct vring。
struct vring_virtqueue {
struct virtqueue vq;
/* Actual memory layout for this queue */
struct vring vring;
......
}
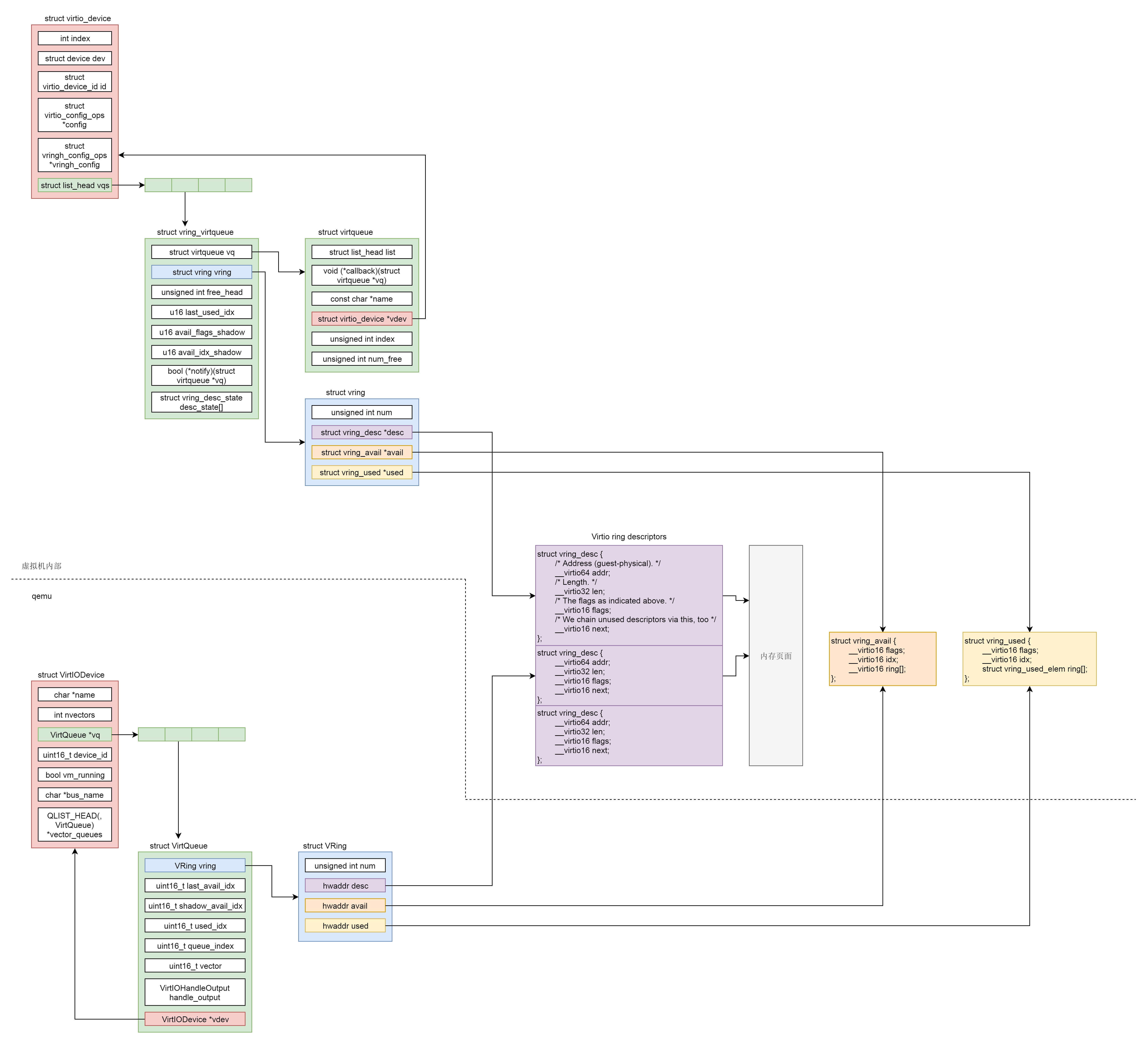
至此我们发现,虚拟机里面的virtio的前端是这样的结构:struct virtio_device里面有一个struct vring_virtqueue,在struct vring_virtqueue里面有一个struct vring。
中间virtio队列的管理
还记不记得我们上面讲qemu初始化的时候,virtio的后端有数据结构VirtIODevice,VirtQueue和vring一模一样,前端和后端对应起来,都应该指向刚才创建的那一段内存。
现在的问题是,我们刚才分配的内存在客户机的内核里面,如何告知qemu来访问这段内存呢?
别忘了,qemu模拟出来的virtio block device只是一个PCI设备。对于客户机来讲,这是一个外部设备,我们可以通过给外部设备发送指令的方式告知外部设备,这就是代码中vp_iowrite16的作用。它会调用专门给外部设备发送指令的函数iowrite,告诉外部的PCI设备。
告知的有三个地址virtqueue_get_desc_addr、virtqueue_get_avail_addr,virtqueue_get_used_addr。从客户机角度来看,这里面的地址都是物理地址,也即GPA(Guest Physical Address)。因为只有物理地址才是客户机和qemu程序都认可的地址,本来客户机的物理内存也是qemu模拟出来的。
在qemu中,对PCI总线添加一个设备的时候,我们会调用virtio_pci_device_plugged。
static void virtio_pci_device_plugged(DeviceState *d, Error **errp)
{
VirtIOPCIProxy *proxy = VIRTIO_PCI(d);
......
memory_region_init_io(&proxy->bar, OBJECT(proxy),
&virtio_pci_config_ops,
proxy, "virtio-pci", size);
......
}
static const MemoryRegionOps virtio_pci_config_ops = {
.read = virtio_pci_config_read,
.write = virtio_pci_config_write,
.impl = {
.min_access_size = 1,
.max_access_size = 4,
},
.endianness = DEVICE_LITTLE_ENDIAN,
};
在这里面,对于这个加载的设备进行I/O操作,会映射到读写某一块内存空间,对应的操作为virtio_pci_config_ops,也即写入这块内存空间,这就相当于对于这个PCI设备进行某种配置。
对PCI设备进行配置的时候,会有这样的调用链:virtio_pci_config_write->virtio_ioport_write->virtio_queue_set_addr。设置virtio的queue的地址是一项很重要的操作。
void virtio_queue_set_addr(VirtIODevice *vdev, int n, hwaddr addr)
{
vdev->vq[n].vring.desc = addr;
virtio_queue_update_rings(vdev, n);
}
从这里我们可以看出,qemu后端的VirtIODevice的VirtQueue的vring的地址,被设置成了刚才给队列分配的内存的GPA。
接着,我们来看一下这个队列的格式。
/* Virtio ring descriptors: 16 bytes. These can chain together via "next". */
struct vring_desc {
/* Address (guest-physical). */
__virtio64 addr;
/* Length. */
__virtio32 len;
/* The flags as indicated above. */
__virtio16 flags;
/* We chain unused descriptors via this, too */
__virtio16 next;
};
struct vring_avail {
__virtio16 flags;
__virtio16 idx;
__virtio16 ring[];
};
/* u32 is used here for ids for padding reasons. */
struct vring_used_elem {
/* Index of start of used descriptor chain. */
__virtio32 id;
/* Total length of the descriptor chain which was used (written to) */
__virtio32 len;
};
struct vring_used {
__virtio16 flags;
__virtio16 idx;
struct vring_used_elem ring[];
};
struct vring {
unsigned int num;
struct vring_desc *desc;
struct vring_avail *avail;
struct vring_used *used;
};
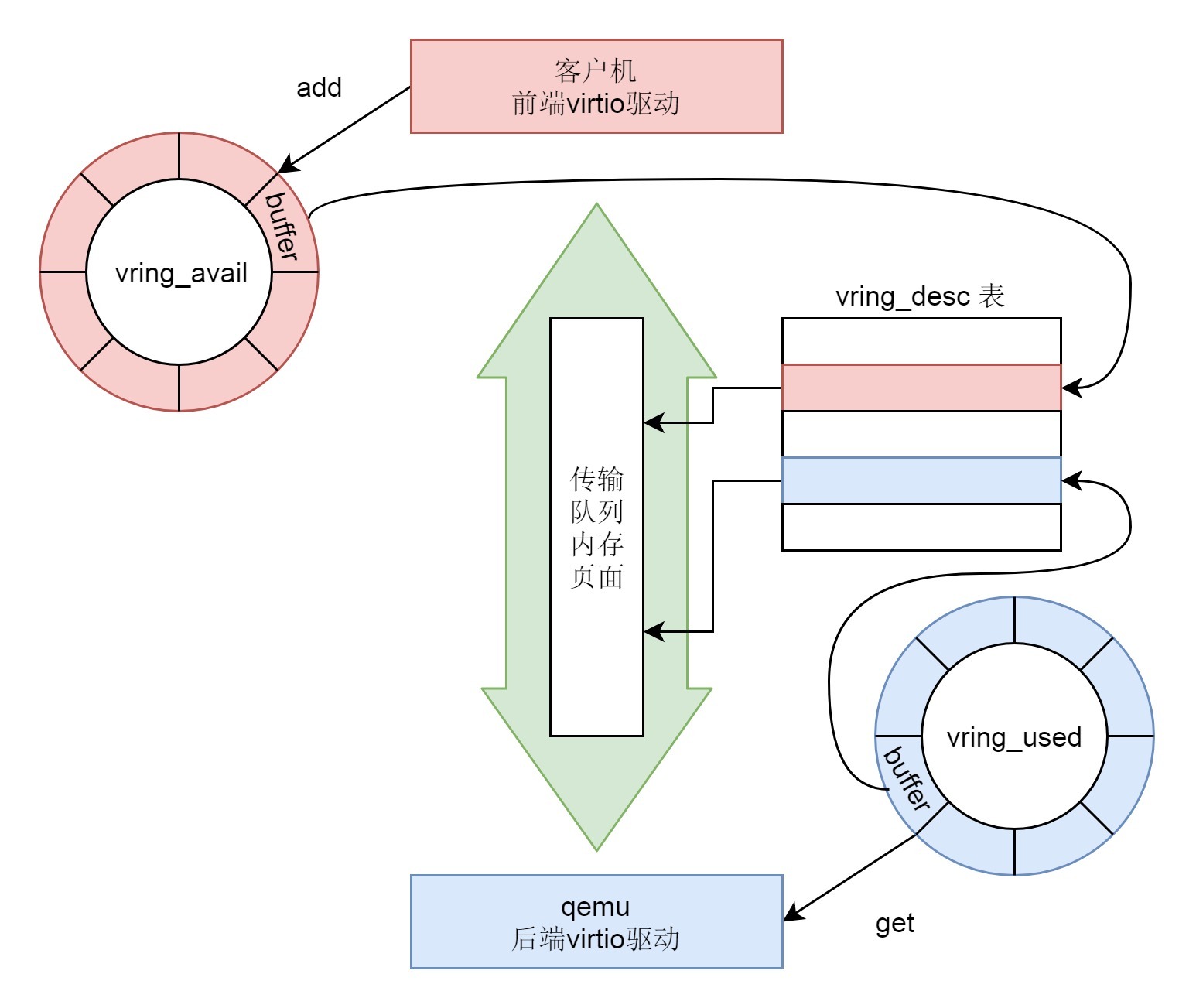
vring包含三个成员:
- vring_desc指向分配的内存块,用于存放客户机和qemu之间传输的数据。
- avail->ring[]是发送端维护的环形队列,指向需要接收端处理的vring_desc。
- used->ring[]是接收端维护的环形队列,指向自己已经处理过了的vring_desc。
数据写入的流程
接下来,我们来看,真的写入一个数据的时候,会发生什么。
按照上面virtio驱动初始化的时候的逻辑,blk_mq_make_request会被调用。这个函数比较复杂,会分成多个分支,但是最终都会调用到request_queue的virtio_mq_ops的queue_rq函数。
struct request_queue *q = rq->q;
q->mq_ops->queue_rq(hctx, &bd);
static const struct blk_mq_ops virtio_mq_ops = {
.queue_rq = virtio_queue_rq,
.complete = virtblk_request_done,
.init_request = virtblk_init_request,
.map_queues = virtblk_map_queues,
};
根据virtio_mq_ops的定义,我们现在要调用virtio_queue_rq。
static blk_status_t virtio_queue_rq(struct blk_mq_hw_ctx *hctx,
const struct blk_mq_queue_data *bd)
{
struct virtio_blk *vblk = hctx->queue->queuedata;
struct request *req = bd->rq;
struct virtblk_req *vbr = blk_mq_rq_to_pdu(req);
......
err = virtblk_add_req(vblk->vqs[qid].vq, vbr, vbr->sg, num);
......
if (notify)
virtqueue_notify(vblk->vqs[qid].vq);
return BLK_STS_OK;
}
在virtio_queue_rq中,我们会将请求写入的数据,通过virtblk_add_req放入struct virtqueue。
因此,接下来的调用链为:virtblk_add_req->virtqueue_add_sgs->virtqueue_add。
static inline int virtqueue_add(struct virtqueue *_vq,
struct scatterlist *sgs[],
unsigned int total_sg,
unsigned int out_sgs,
unsigned int in_sgs,
void *data,
void *ctx,
gfp_t gfp)
{
struct vring_virtqueue *vq = to_vvq(_vq);
struct scatterlist *sg;
struct vring_desc *desc;
unsigned int i, n, avail, descs_used, uninitialized_var(prev), err_idx;
int head;
bool indirect;
......
head = vq->free_head;
indirect = false;
desc = vq->vring.desc;
i = head;
descs_used = total_sg;
for (n = 0; n < out_sgs; n++) {
for (sg = sgs[n]; sg; sg = sg_next(sg)) {
dma_addr_t addr = vring_map_one_sg(vq, sg, DMA_TO_DEVICE);
......
desc[i].flags = cpu_to_virtio16(_vq->vdev, VRING_DESC_F_NEXT);
desc[i].addr = cpu_to_virtio64(_vq->vdev, addr);
desc[i].len = cpu_to_virtio32(_vq->vdev, sg->length);
prev = i;
i = virtio16_to_cpu(_vq->vdev, desc[i].next);
}
}
/* Last one doesn't continue. */
desc[prev].flags &= cpu_to_virtio16(_vq->vdev, ~VRING_DESC_F_NEXT);
/* We're using some buffers from the free list. */
vq->vq.num_free -= descs_used;
/* Update free pointer */
vq->free_head = i;
/* Store token and indirect buffer state. */
vq->desc_state[head].data = data;
/* Put entry in available array (but don't update avail->idx until they do sync). */
avail = vq->avail_idx_shadow & (vq->vring.num - 1);
vq->vring.avail->ring[avail] = cpu_to_virtio16(_vq->vdev, head);
/* Descriptors and available array need to be set before we expose the new available array entries. */
virtio_wmb(vq->weak_barriers);
vq->avail_idx_shadow++;
vq->vring.avail->idx = cpu_to_virtio16(_vq->vdev, vq->avail_idx_shadow);
vq->num_added++;
......
return 0;
}
在virtqueue_add函数中,我们能看到,free_head指向的整个内存块空闲链表的起始位置,用head变量记住这个起始位置。
接下来,i也指向这个起始位置,然后是一个for循环,将数据放到内存块里面,放的过程中,next不断指向下一个空闲位置,这样空闲的内存块被不断的占用。等所有的写入都结束了,i就会指向这次存放的内存块的下一个空闲位置,然后free_head就指向i,因为前面的都填满了。
至此,从head到i之间的内存块,就是这次写入的全部数据。
于是,在vring的avail变量中,在ring[]数组中分配新的一项,在avail的位置,avail的计算是avail_idx_shadow & (vq->vring.num - 1),其中,avail_idx_shadow是上一次的avail的位置。这里如果超过了ring[]数组的下标,则重新跳到起始位置,就说明是一个环。这次分配的新的avail的位置就存放新写入的从head到i之间的内存块。然后是avail_idx_shadow++,这说明这一块内存可以被接收方读取了。
接下来,我们回到virtio_queue_rq,调用virtqueue_notify通知接收方。而virtqueue_notify会调用vp_notify。
bool vp_notify(struct virtqueue *vq)
{
/* we write the queue's selector into the notification register to
* signal the other end */
iowrite16(vq->index, (void __iomem *)vq->priv);
return true;
}
然后,我们写入一个I/O会触发VM exit。我们在解析CPU的时候看到过这个逻辑。
int kvm_cpu_exec(CPUState *cpu)
{
struct kvm_run *run = cpu->kvm_run;
int ret, run_ret;
......
run_ret = kvm_vcpu_ioctl(cpu, KVM_RUN, 0);
......
switch (run->exit_reason) {
case KVM_EXIT_IO:
DPRINTF("handle_io\n");
/* Called outside BQL */
kvm_handle_io(run->io.port, attrs,
(uint8_t *)run + run->io.data_offset,
run->io.direction,
run->io.size,
run->io.count);
ret = 0;
break;
}
......
}
这次写入的也是一个I/O的内存空间,同样会触发virtio_ioport_write,这次会调用virtio_queue_notify。
void virtio_queue_notify(VirtIODevice *vdev, int n)
{
VirtQueue *vq = &vdev->vq[n];
......
if (vq->handle_aio_output) {
event_notifier_set(&vq->host_notifier);
} else if (vq->handle_output) {
vq->handle_output(vdev, vq);
}
}
virtio_queue_notify会调用VirtQueue的handle_output函数,前面我们已经设置过这个函数了,是virtio_blk_handle_output。
接下来的调用链为:virtio_blk_handle_output->virtio_blk_handle_output_do->virtio_blk_handle_vq。
bool virtio_blk_handle_vq(VirtIOBlock *s, VirtQueue *vq)
{
VirtIOBlockReq *req;
MultiReqBuffer mrb = {};
bool progress = false;
......
do {
virtio_queue_set_notification(vq, 0);
while ((req = virtio_blk_get_request(s, vq))) {
progress = true;
if (virtio_blk_handle_request(req, &mrb)) {
virtqueue_detach_element(req->vq, &req->elem, 0);
virtio_blk_free_request(req);
break;
}
}
virtio_queue_set_notification(vq, 1);
} while (!virtio_queue_empty(vq));
if (mrb.num_reqs) {
virtio_blk_submit_multireq(s->blk, &mrb);
}
......
return progress;
}
在virtio_blk_handle_vq中,有一个while循环,在循环中调用函数virtio_blk_get_request从vq中取出请求,然后调用virtio_blk_handle_request处理从vq中取出的请求。
我们先来看virtio_blk_get_request。
static VirtIOBlockReq *virtio_blk_get_request(VirtIOBlock *s, VirtQueue *vq)
{
VirtIOBlockReq *req = virtqueue_pop(vq, sizeof(VirtIOBlockReq));
if (req) {
virtio_blk_init_request(s, vq, req);
}
return req;
}
void *virtqueue_pop(VirtQueue *vq, size_t sz)
{
unsigned int i, head, max;
VRingMemoryRegionCaches *caches;
MemoryRegionCache *desc_cache;
int64_t len;
VirtIODevice *vdev = vq->vdev;
VirtQueueElement *elem = NULL;
unsigned out_num, in_num, elem_entries;
hwaddr addr[VIRTQUEUE_MAX_SIZE];
struct iovec iov[VIRTQUEUE_MAX_SIZE];
VRingDesc desc;
int rc;
......
/* When we start there are none of either input nor output. */
out_num = in_num = elem_entries = 0;
max = vq->vring.num;
i = head;
caches = vring_get_region_caches(vq);
desc_cache = &caches->desc;
vring_desc_read(vdev, &desc, desc_cache, i);
......
/* Collect all the descriptors */
do {
bool map_ok;
if (desc.flags & VRING_DESC_F_WRITE) {
map_ok = virtqueue_map_desc(vdev, &in_num, addr + out_num,
iov + out_num,
VIRTQUEUE_MAX_SIZE - out_num, true,
desc.addr, desc.len);
} else {
map_ok = virtqueue_map_desc(vdev, &out_num, addr, iov,
VIRTQUEUE_MAX_SIZE, false,
desc.addr, desc.len);
}
......
rc = virtqueue_read_next_desc(vdev, &desc, desc_cache, max, &i);
} while (rc == VIRTQUEUE_READ_DESC_MORE);
......
/* Now copy what we have collected and mapped */
elem = virtqueue_alloc_element(sz, out_num, in_num);
elem->index = head;
for (i = 0; i < out_num; i++) {
elem->out_addr[i] = addr[i];
elem->out_sg[i] = iov[i];
}
for (i = 0; i < in_num; i++) {
elem->in_addr[i] = addr[out_num + i];
elem->in_sg[i] = iov[out_num + i];
}
vq->inuse++;
......
return elem;
}
我们可以看到,virtio_blk_get_request会调用virtqueue_pop。在这里面,我们能看到对于vring的操作,也即从这里面将客户机里面写入的数据读取出来,放到VirtIOBlockReq结构中。
接下来,我们就要调用virtio_blk_handle_request处理这些数据。所以接下来的调用链为:virtio_blk_handle_request->virtio_blk_submit_multireq->submit_requests。
static inline void submit_requests(BlockBackend *blk, MultiReqBuffer *mrb,int start, int num_reqs, int niov)
{
QEMUIOVector *qiov = &mrb->reqs[start]->qiov;
int64_t sector_num = mrb->reqs[start]->sector_num;
bool is_write = mrb->is_write;
if (num_reqs > 1) {
int i;
struct iovec *tmp_iov = qiov->iov;
int tmp_niov = qiov->niov;
qemu_iovec_init(qiov, niov);
for (i = 0; i < tmp_niov; i++) {
qemu_iovec_add(qiov, tmp_iov[i].iov_base, tmp_iov[i].iov_len);
}
for (i = start + 1; i < start + num_reqs; i++) {
qemu_iovec_concat(qiov, &mrb->reqs[i]->qiov, 0,
mrb->reqs[i]->qiov.size);
mrb->reqs[i - 1]->mr_next = mrb->reqs[i];
}
block_acct_merge_done(blk_get_stats(blk),
is_write ? BLOCK_ACCT_WRITE : BLOCK_ACCT_READ,
num_reqs - 1);
}
if (is_write) {
blk_aio_pwritev(blk, sector_num << BDRV_SECTOR_BITS, qiov, 0,
virtio_blk_rw_complete, mrb->reqs[start]);
} else {
blk_aio_preadv(blk, sector_num << BDRV_SECTOR_BITS, qiov, 0,
virtio_blk_rw_complete, mrb->reqs[start]);
}
}
在submit_requests中,我们看到了BlockBackend。这是在qemu启动的时候,打开qcow2文件的时候生成的,现在我们可以用它来写入文件了,调用的是blk_aio_pwritev。
BlockAIOCB *blk_aio_pwritev(BlockBackend *blk, int64_t offset,
QEMUIOVector *qiov, BdrvRequestFlags flags,
BlockCompletionFunc *cb, void *opaque)
{
return blk_aio_prwv(blk, offset, qiov->size, qiov,
blk_aio_write_entry, flags, cb, opaque);
}
static BlockAIOCB *blk_aio_prwv(BlockBackend *blk, int64_t offset, int bytes,
void *iobuf, CoroutineEntry co_entry,
BdrvRequestFlags flags,
BlockCompletionFunc *cb, void *opaque)
{
BlkAioEmAIOCB *acb;
Coroutine *co;
acb = blk_aio_get(&blk_aio_em_aiocb_info, blk, cb, opaque);
acb->rwco = (BlkRwCo) {
.blk = blk,
.offset = offset,
.iobuf = iobuf,
.flags = flags,
.ret = NOT_DONE,
};
acb->bytes = bytes;
acb->has_returned = false;
co = qemu_coroutine_create(co_entry, acb);
bdrv_coroutine_enter(blk_bs(blk), co);
acb->has_returned = true;
return &acb->common;
}
在blk_aio_pwritev中,我们看到,又是创建了一个协程来进行写入。写入完毕之后调用virtio_blk_rw_complete->virtio_blk_req_complete。
static void virtio_blk_req_complete(VirtIOBlockReq *req, unsigned char status)
{
VirtIOBlock *s = req->dev;
VirtIODevice *vdev = VIRTIO_DEVICE(s);
trace_virtio_blk_req_complete(vdev, req, status);
stb_p(&req->in->status, status);
virtqueue_push(req->vq, &req->elem, req->in_len);
virtio_notify(vdev, req->vq);
}
在virtio_blk_req_complete中,我们先是调用virtqueue_push,更新vring中used变量,表示这部分已经写入完毕,空间可以回收利用了。但是,这部分的改变仅仅改变了qemu后端的vring,我们还需要通知客户机中virtio前端的vring的值,因而要调用virtio_notify。virtio_notify会调用virtio_irq发送一个中断。
还记得咱们前面注册过一个中断处理函数vp_interrupt吗?它就是干这个事情的。
static irqreturn_t vp_interrupt(int irq, void *opaque)
{
struct virtio_pci_device *vp_dev = opaque;
u8 isr;
/* reading the ISR has the effect of also clearing it so it's very
* important to save off the value. */
isr = ioread8(vp_dev->isr);
/* Configuration change? Tell driver if it wants to know. */
if (isr & VIRTIO_PCI_ISR_CONFIG)
vp_config_changed(irq, opaque);
return vp_vring_interrupt(irq, opaque);
}
就像前面说的一样vp_interrupt这个中断处理函数,一是处理配置变化,二是处理I/O结束。第二种的调用链为:vp_interrupt->vp_vring_interrupt->vring_interrupt。
irqreturn_t vring_interrupt(int irq, void *_vq)
{
struct vring_virtqueue *vq = to_vvq(_vq);
......
if (vq->vq.callback)
vq->vq.callback(&vq->vq);
return IRQ_HANDLED;
}
在vring_interrupt中,我们会调用callback函数,这个也是在前面注册过的,是virtblk_done。
接下来的调用链为:virtblk_done->virtqueue_get_buf->virtqueue_get_buf_ctx。
void *virtqueue_get_buf_ctx(struct virtqueue *_vq, unsigned int *len,
void **ctx)
{
struct vring_virtqueue *vq = to_vvq(_vq);
void *ret;
unsigned int i;
u16 last_used;
......
last_used = (vq->last_used_idx & (vq->vring.num - 1));
i = virtio32_to_cpu(_vq->vdev, vq->vring.used->ring[last_used].id);
*len = virtio32_to_cpu(_vq->vdev, vq->vring.used->ring[last_used].len);
......
/* detach_buf clears data, so grab it now. */
ret = vq->desc_state[i].data;
detach_buf(vq, i, ctx);
vq->last_used_idx++;
......
return ret;
}
在virtqueue_get_buf_ctx中,我们可以看到,virtio前端的vring中的last_used_idx加一,说明这块数据qemu后端已经消费完毕。我们可以通过detach_buf将其放入空闲队列中,留给以后的写入请求使用。
至此,整个存储虚拟化的写入流程才全部完成。
总结时刻
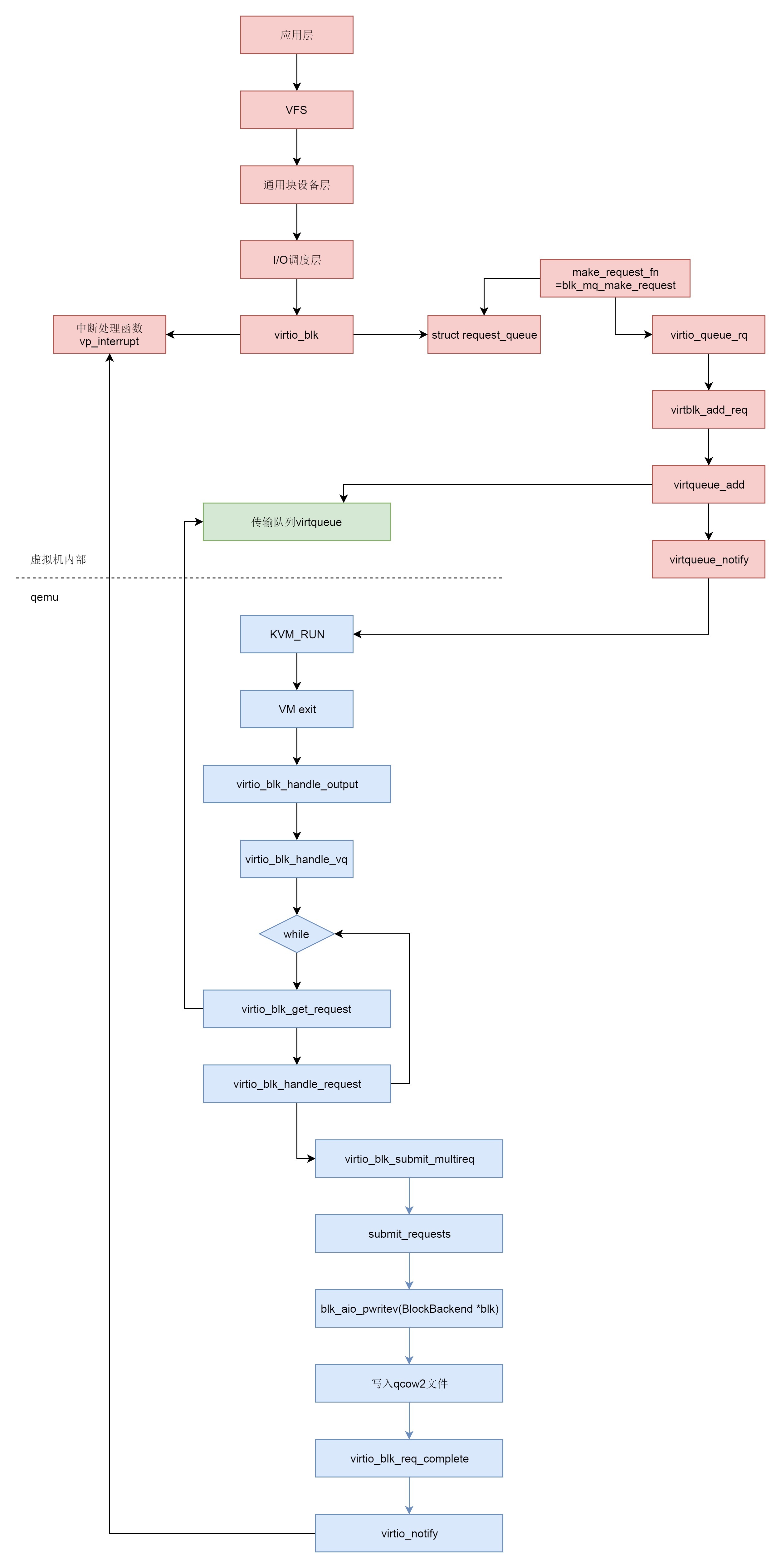
下面我们来总结一下存储虚拟化的场景下,整个写入的过程。
- 在虚拟机里面,应用层调用write系统调用写入文件。
- write系统调用进入虚拟机里面的内核,经过VFS,通用块设备层,I/O调度层,到达块设备驱动。
- 虚拟机里面的块设备驱动是virtio_blk,它和通用的块设备驱动一样,有一个request queue,另外有一个函数make_request_fn会被设置为blk_mq_make_request,这个函数用于将请求放入队列。
- 虚拟机里面的块设备驱动是virtio_blk会注册一个中断处理函数vp_interrupt。当qemu写入完成之后,它会通知虚拟机里面的块设备驱动。
- blk_mq_make_request最终调用virtqueue_add,将请求添加到传输队列virtqueue中,然后调用virtqueue_notify通知qemu。
- 在qemu中,本来虚拟机正处于KVM_RUN的状态,也即处于客户机状态。
- qemu收到通知后,通过VM exit指令退出客户机状态,进入宿主机状态,根据退出原因,得知有I/O需要处理。
- qemu调用virtio_blk_handle_output,最终调用virtio_blk_handle_vq。
- virtio_blk_handle_vq里面有一个循环,在循环中,virtio_blk_get_request函数从传输队列中拿出请求,然后调用virtio_blk_handle_request处理请求。
- virtio_blk_handle_request会调用blk_aio_pwritev,通过BlockBackend驱动写入qcow2文件。
- 写入完毕之后,virtio_blk_req_complete会调用virtio_notify通知虚拟机里面的驱动。数据写入完成,刚才注册的中断处理函数vp_interrupt会收到这个通知。
课堂练习
请你沿着代码,仔细分析并牢记virtqueue的结构以及写入和读取方式。这个结构在下面的网络传输过程中,还要起大作用。
欢迎留言和我分享你的疑惑和见解,也欢迎收藏本节内容,反复研读。你也可以把今天的内容分享给你的朋友,和他一起学习和进步。
