|
|
# 08 | 分段:MTU引发的血案
|
|
|
|
|
|
你好,我是胜辉。
|
|
|
|
|
|
在[第1讲](https://time.geekbang.org/column/article/477510)里,我给你介绍过TCP segment(TCP段)作为“部分”,是从“整体”里面切分出来的。这种切分机制在网络设计里面很常见,但同时也容易引起问题。更麻烦的是,这些概念因为看起来都很像,特别容易引起混淆。比如,你可能也听说过下面这些概念:
|
|
|
|
|
|
* TCP分段(segmentation)
|
|
|
* IP分片(fragmentation)
|
|
|
* MTU(最大传输单元)
|
|
|
* MSS(最大分段大小)
|
|
|
* TSO(TCP分段卸载)
|
|
|
* ……
|
|
|
|
|
|
所以这节课,我就通过一个案例,来帮助你彻底搞清楚这些概念的联系和区别,这样你以后遇到跟MTU、MSS、分片、分段等相关的问题的时候,就不会再茫然失措,也不会再张冠李戴了,而是能清晰地知道问题在哪里,并能针对性地搞定它。
|
|
|
|
|
|
## 案例:重传失败导致应用压测报错
|
|
|
|
|
|
我先来给你介绍下案例背景。
|
|
|
|
|
|
在公有云服务的时候,一个客户对我们公有云的软件负载均衡(LB)进行压力测试,结果遇到了大量报错。要知道,这是一个比较大的客户,这样的压测失败,意味着可能这个大客户要流失,所以我们打起十二分的精神,投入了排查工作。
|
|
|
|
|
|
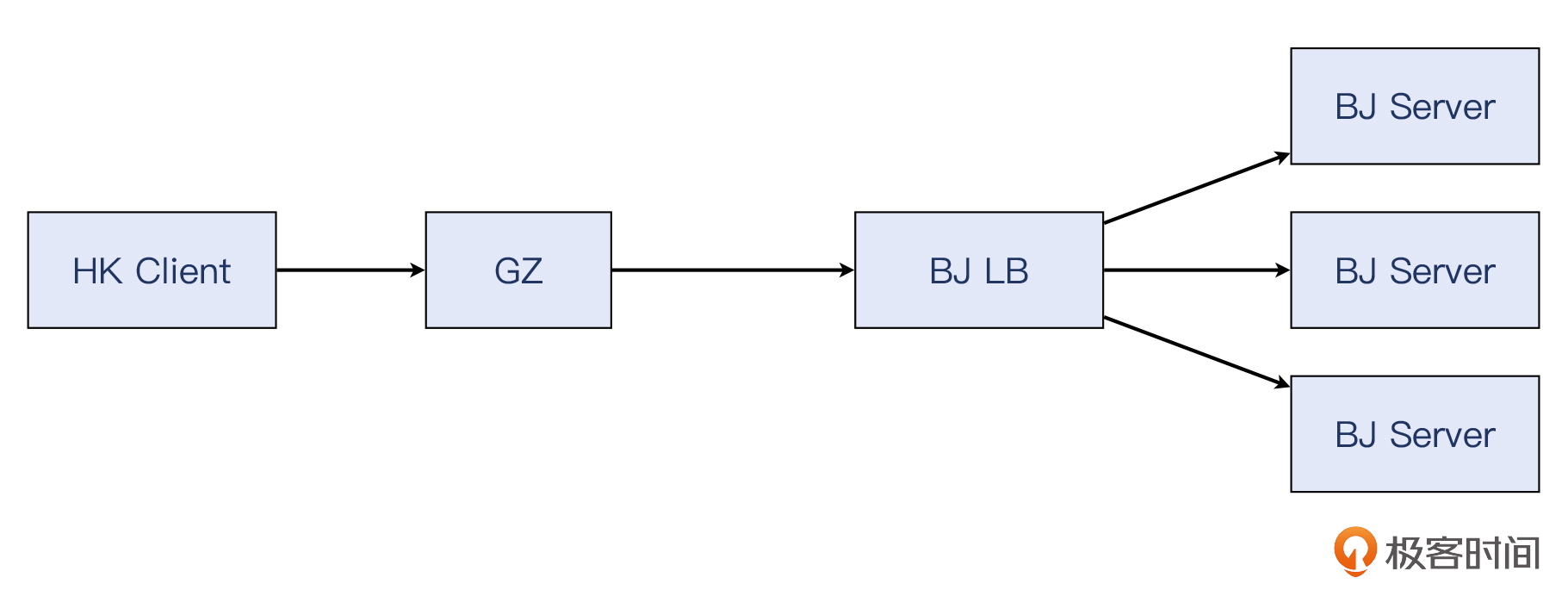
首先,我们看一下这个客户的压测环境拓扑图:
|
|
|
|
|
|
|
|
|
|
|
|
这里的香港和北京,都是指客户在我们平台上租赁的云计算资源。从香港的客户端机器,发起对北京LB上的VIP的压力测试,也就是短时间内有成千上万的请求会发送过来,北京LB就分发这些请求到后端的那些同时在北京的服务器上。照理说,我们的云LB的性能十分出色,承受数十万的连接没有问题。不夸张地说,就算客户端垮了,LB都能正常工作。
|
|
|
|
|
|
但是在这次压测中,客户发现有大量的HTTP报错。我们看了具体情况,这个压测对每个请求的超时时间设置为1秒。也就是说,如果请求不能在1秒内得到返回,就会报错。而问题症状就是出现了大量这样的超时报错。
|
|
|
|
|
|
既然通过LB做压测有问题,客户就绕过LB,从香港客户端直接对北京服务器进行测试,结果发现是正常的,压测可以顺利完成。当然,因为单台服务器的能力比不上LB加多台服务器的配置,所以压测数据不会太高,但至少没有报错了。
|
|
|
|
|
|
那这样的话,客户是用不了我们的LB了?
|
|
|
|
|
|
我们还是用**抓包分析**来查看这个问题。显然,我们知道了两种场景,一种是正常的,一种是异常的。那么我们就在两种场景下分别做了抓包。
|
|
|
|
|
|
### 绕过LB的压测
|
|
|
|
|
|
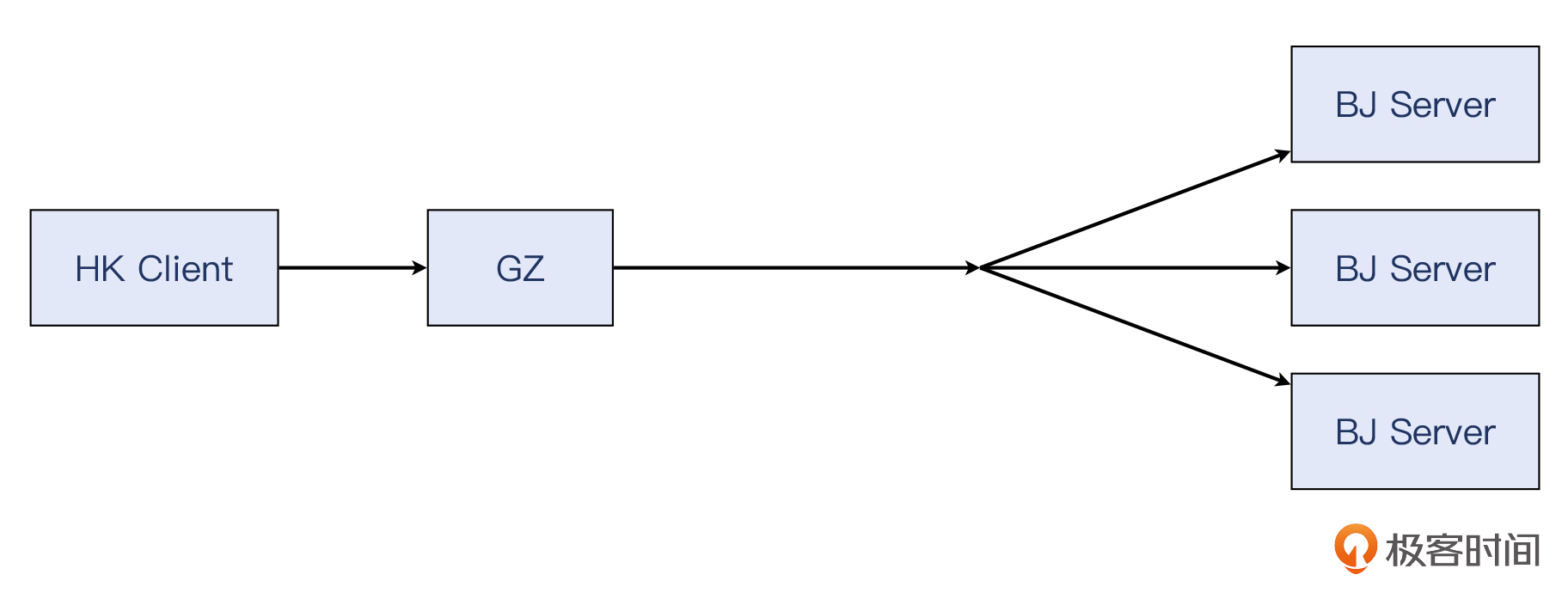
我们来看一下绕过LB的话,请求是如何到服务器的。香港机房的客户端发起HTTP请求,通过专线进入广州机房,然后经由广州-北京专线,直达北京机房的服务器。
|
|
|
|
|
|
|
|
|
|
|
|
我们来看一下这种场景下的抓包文件:
|
|
|
|
|
|
> 抓包文件已经脱敏后上传至[gitee](https://gitee.com/steelvictor/network-analysis/blob/master/08/bypassLB.pcap)。
|
|
|
|
|
|
|
|
|
|
|
|
考虑到压测的问题是关于HTTP的,我们需要查看一下HTTP事务的报文。这里只需要输入过滤器http就可以了:
|
|
|
|
|
|
|
|
|
|
|
|
我们选中任意一个这样的报文,然后Follow -> TCP Stream,来看看整个过程:
|
|
|
|
|
|
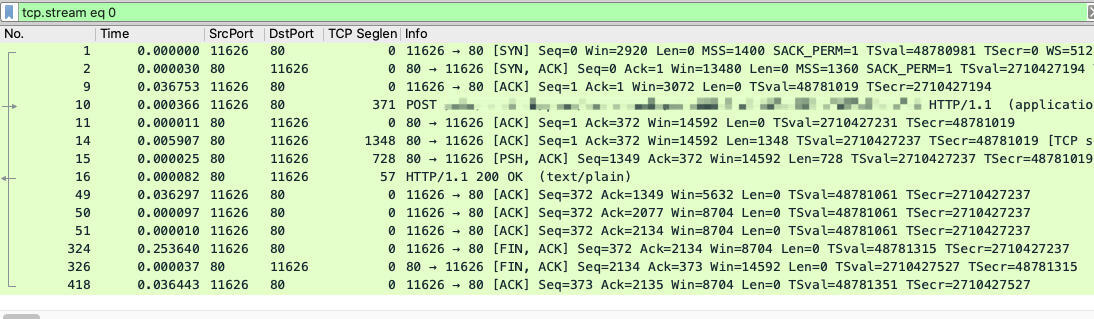
|
|
|
|
|
|
从这个正常的TCP流里,我们可以获取到以下信息:
|
|
|
|
|
|
* **时延(往返时间)在36.8ms**,因为SYN+ACK(2号报文)和ACK(9号报文)之间,就是隔了0.036753秒,即36.8ms。
|
|
|
* **HTTP处理时间也很快**,从服务端收到HTTP请求(在10号报文),到服务端回复HTTP响应(14到16号报文),一共只花费了大约6ms。
|
|
|
* 在收到HTTP响应后,客户端在25ms(324号报文)后,发起了TCP挥手。
|
|
|
|
|
|
看起来,服务器确实没有问题,整个TCP交互的过程也十分正常。那么,我们再来看一下“经过LB”的失败场景又是什么样的,然后在报文中“顺藤摸瓜”,进一步就能逼近根因了。
|
|
|
|
|
|
### 经过LB的压测
|
|
|
|
|
|
我们打开绕过LB的压测的抓包文件,在[第7讲](https://time.geekbang.org/column/article/482610)中,我提到过利用Expert Information(专家信息)来展开排查的小技巧。那么这里也是如此。
|
|
|
|
|
|
> 抓包文件已经脱敏后上传至[gitee](https://gitee.com/steelvictor/network-analysis/blob/master/08/viaLB.pcap)。
|
|
|
|
|
|
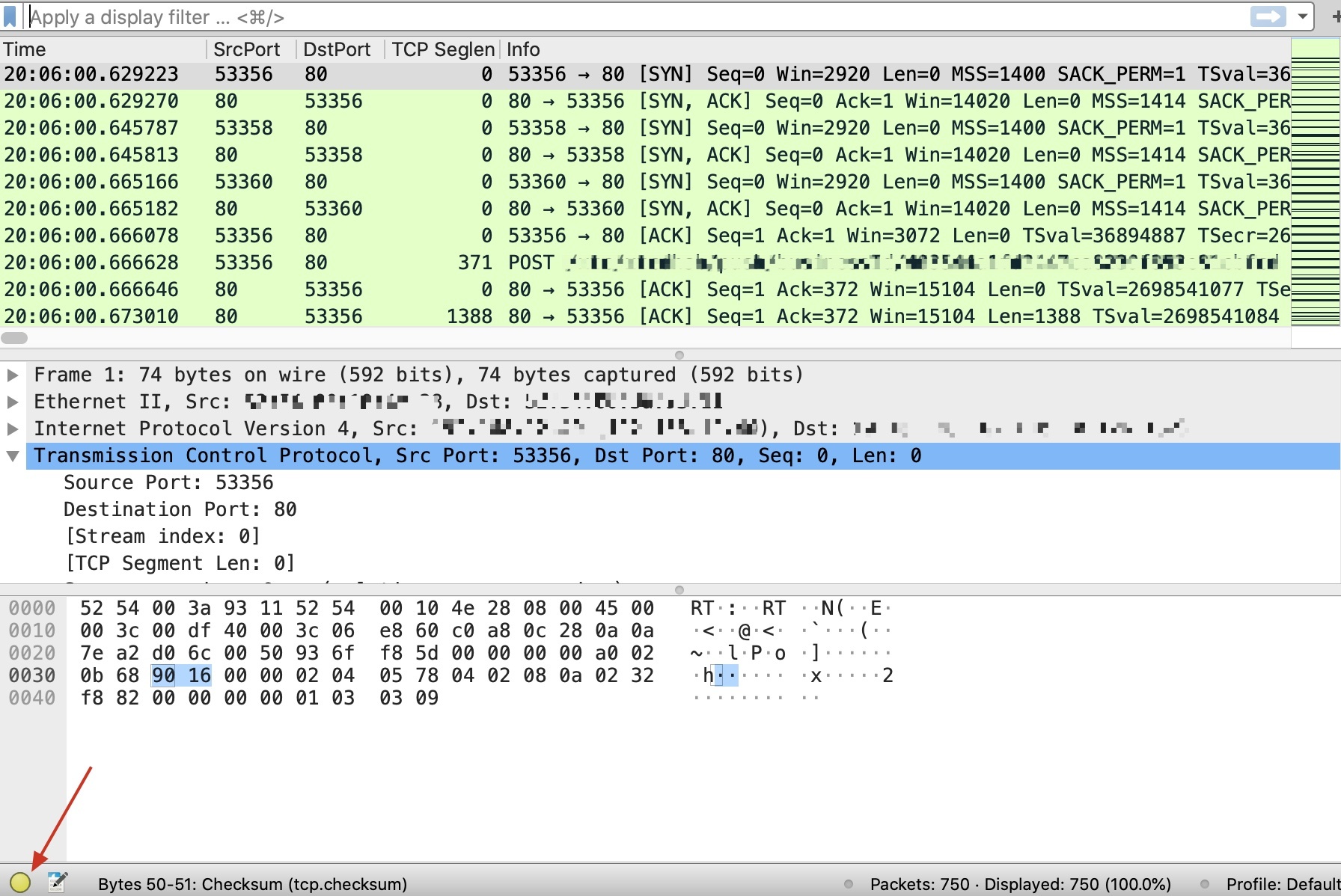
|
|
|
|
|
|
可以看到,里面有标黄色的Warning级别的信息,有50个需要我们注意的RST报文:
|
|
|
|
|
|

|
|
|
|
|
|
我们展开Warning Connection reset (RST),选一个报文然后找到它的TCP流来看一下:
|
|
|
|
|
|
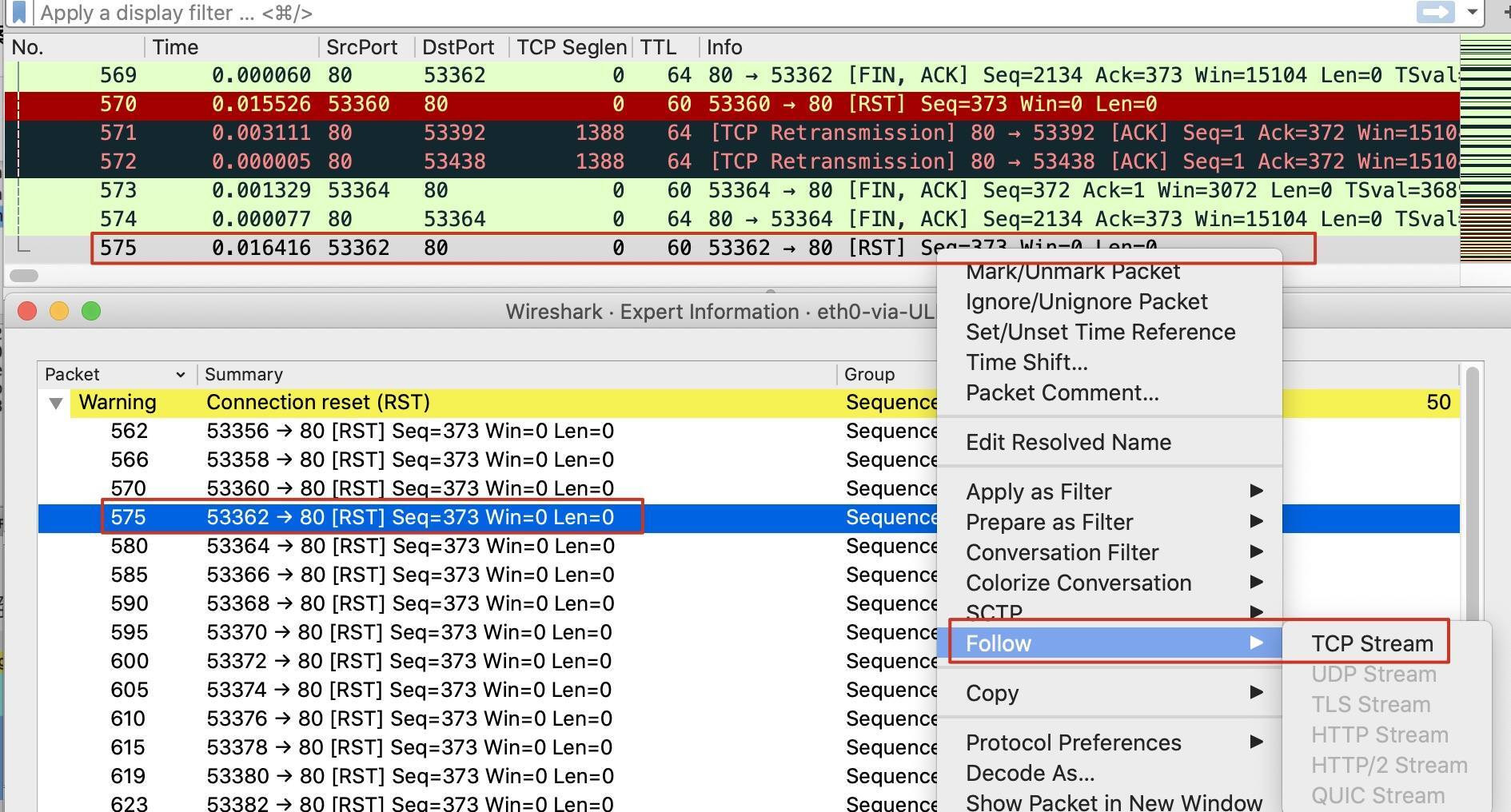
|
|
|
|
|
|
比如上图中,我们选中575号报文,然后Follow -> TCP Stream,就来到了这条TCP流:
|
|
|
|
|
|
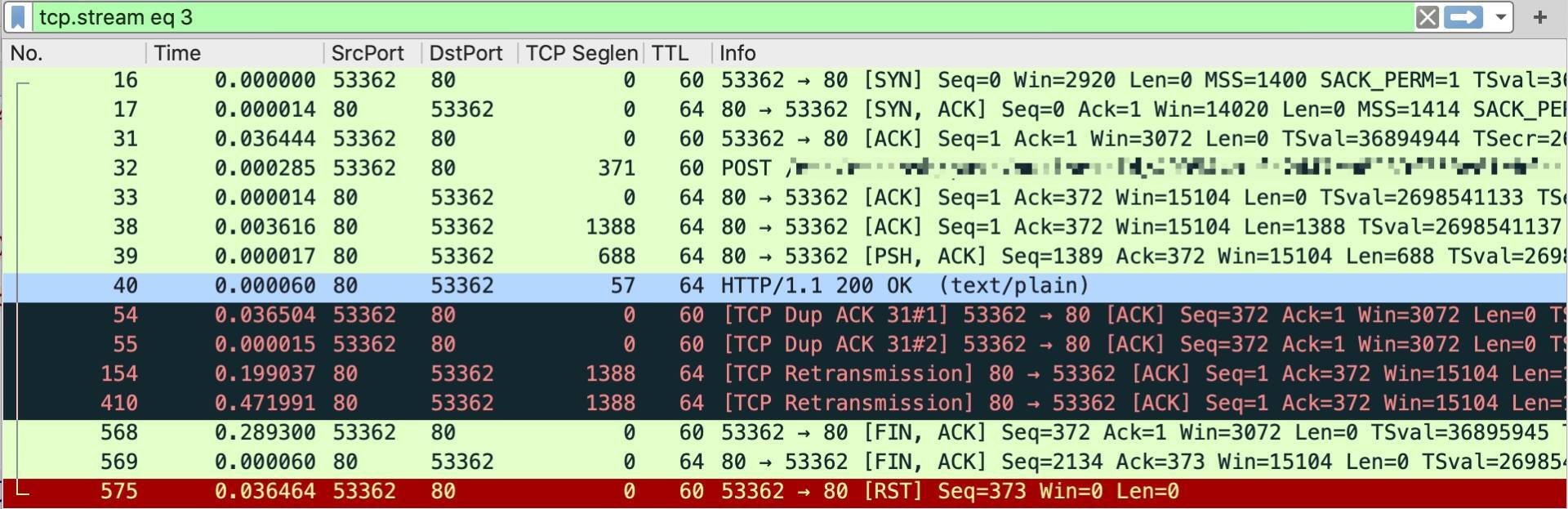
|
|
|
|
|
|
不过这里,我先考考你,**目前这个抓包是在客户端还是服务端抓取的呢?**
|
|
|
|
|
|
如果你对[第2讲](https://time.geekbang.org/column/article/478189)还有印象,应该已经知道如何根据TTL来做这个判断了。没错,因为SYN+ACK报文的TTL是64,所以这个抓包就是在发送SYN+ACK的一端,也就是服务端做的。
|
|
|
|
|
|
接下来就是重点了。显然,这个TCP流里面,有两个重复确认(54和55号报文),还有两个重传(154和410号报文),在它们之后,就是客户端(源端口53362)发起了TCP挥手,最终以客户端发出的RST结束。
|
|
|
|
|
|
这里隐含着两个疑问,我们能回答这两个疑问了,那么问题的根因也就找到了。
|
|
|
|
|
|
#### 第一个疑问:为什么有重复确认(DupAck)?
|
|
|
|
|
|
重复确认在TCP里面有很重要的价值,它的出现,一般意味着传输中出现了丢包、乱序等情况。我们来看看这两个重复确认报文的细节。
|
|
|
|
|
|

|
|
|
|
|
|
我们很容易发现,这两个DupAck报文的确认号是1。这意味着什么呢?你现在对TCP握手已经挺熟悉了,显然应该能想到,这个1的确认号,其实就是**握手阶段完成时候的确认号**。也就是说,客户端其实并没有收到握手后服务端发送的第一个数据报文,所以确认号“停留”在1。
|
|
|
|
|
|
那么,为什么是两个重复确认报文呢?我们把视线从2个DupAck报文往上挪,关注到整个TCP流的情况。
|
|
|
|
|
|
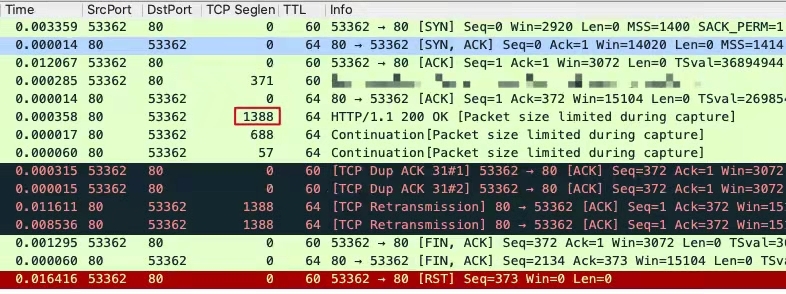
|
|
|
|
|
|
握手完成后,客户端就发送了POST请求,然后服务端先回复了一个ACK,确认收到了这个请求。之后有连续3个报文作为HTTP响应,返回给客户端。
|
|
|
|
|
|
按照TCP的机制,它可以收一个报文,就发送一个确认报文;也可以收多个报文,发送一个确认报文。反过来说,一端发送几次确认报文,就意味着它收到了至少同样数量的数据报文。
|
|
|
|
|
|
在当前的例子里,因为有2个DupAck报文,那么客户端一定至少收到了2个数据报文。是哪两个呢?一定是连续3个报文的第二和第三个,也就是1388字节报文的后面两个。因为如果是收到了1388字节那个,那确认号就一定不是1,而是1389(1388+1)了。
|
|
|
|
|
|
我们再把视线从2个DupAck往下挪,这里有2个TCP重传。
|
|
|
|
|
|
我们关注一下Time列,第一个重传是隔了大约200ms,第二次重传隔了大约472毫秒。这就是**TCP的超时重传机制**引发的行为。关于重传这个话题,后续课程里会有大量的展开,你可以期待一下。
|
|
|
|
|
|

|
|
|
|
|
|
那么结合上面这些信息,我们也就理解了“通过LB压测失败”的整个过程,在TCP里面具体发生了什么。我还是用示意图来展示一下:
|
|
|
|
|
|
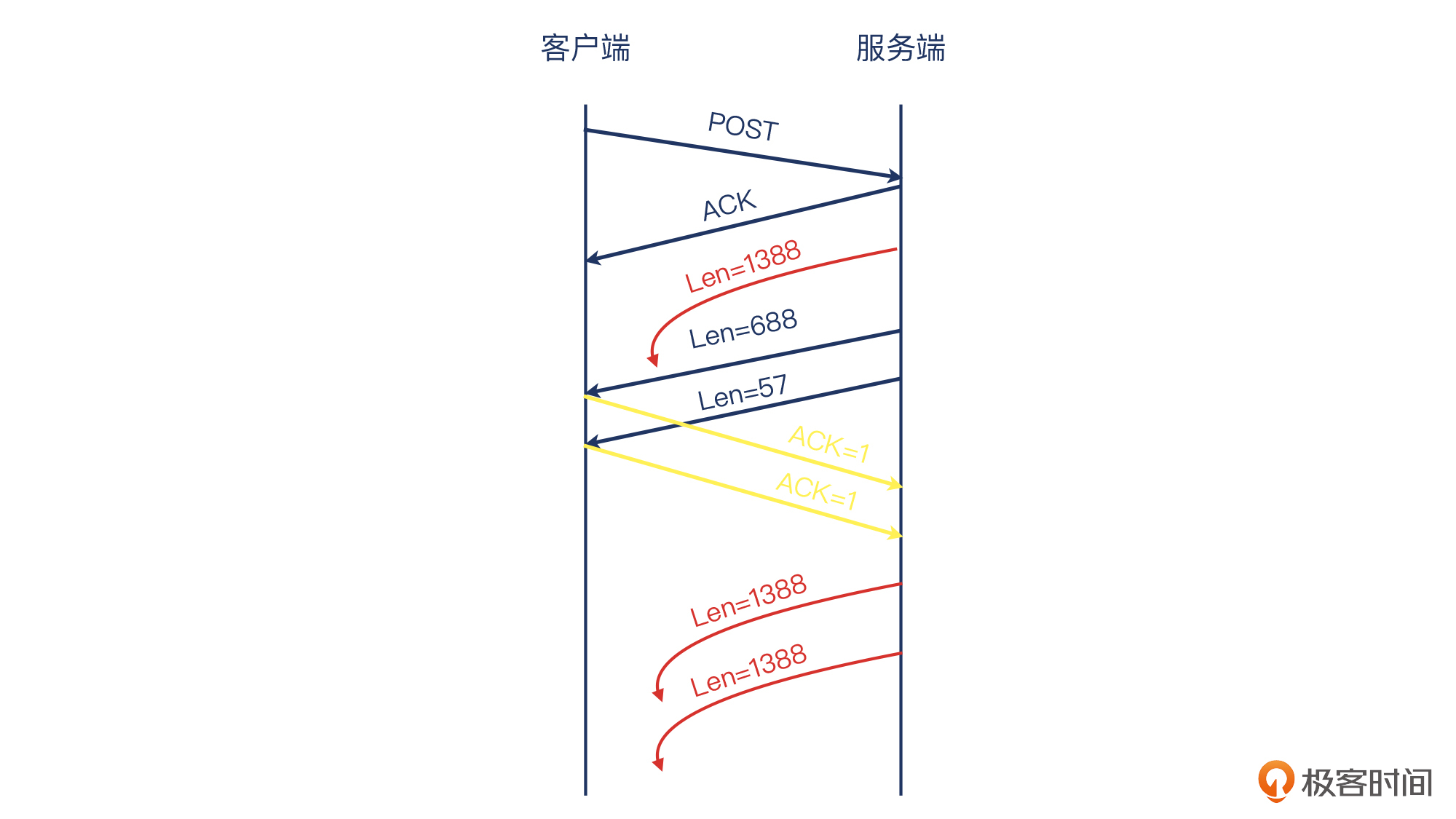
|
|
|
|
|
|
不过你也许会问:“每次这样画一个示意图,好像比较麻烦啊?难道Wireshark就不能提供类似的功能吗?”
|
|
|
|
|
|
Wireshark主窗口里展示的报文,确实有点类似“一维”,也就是从上到下依次排列,在解读通信双方的具体行为时,如果能添加上另外一个“维度”,比如增加向左和向右的箭头,是不是可以让我们更容易理解呢?
|
|
|
|
|
|
其实,我们能想到的,Wireshark的聪明的开发者也想到了,Wireshark里确实有一个小工具可以起到这个作用,它就是**Flow Graph**。
|
|
|
|
|
|
你可以这样找到它:点开Statistics菜单,在下拉菜单中找到Flow Graph,点击它,就可以看到这个抓包文件的“二维图”了。不过,因为我们要查看的是过滤出来的TCP流,而Flow Graph只会展示抓包文件里所有的报文,所以,我们需要这么做:
|
|
|
|
|
|
* 先把过滤出来的报文,保存为一个新的抓包文件;
|
|
|
* 然后打开那个新文件,再查看Flow Graph。
|
|
|
|
|
|
比如这次我就可以看到下面这个Flow Graph:
|
|
|
|
|
|
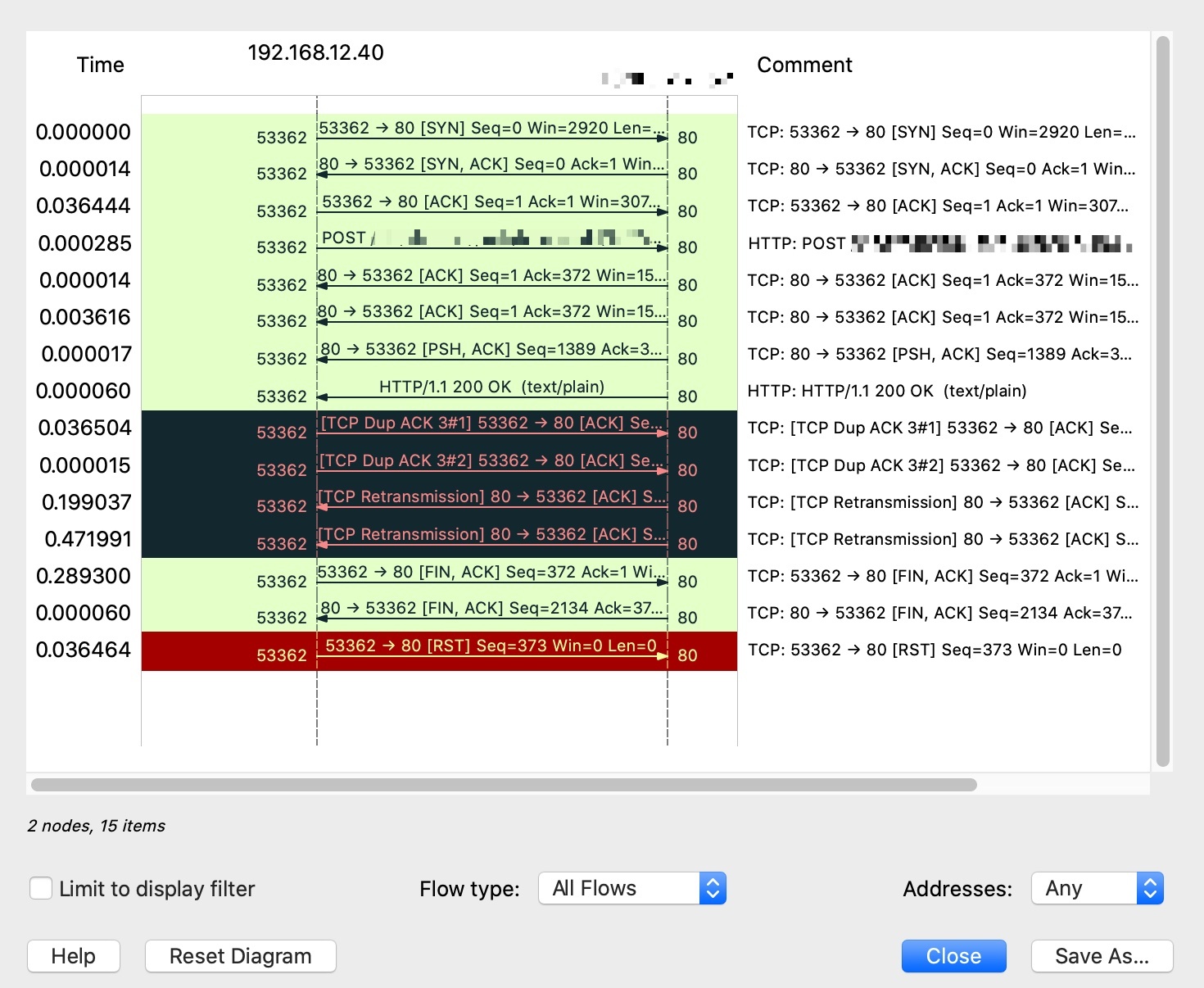
|
|
|
|
|
|
上图读起来,是不是感觉信息量要比主界面要多一些?特别是有了左右方向箭头,给我们大脑形成了“第二个维度”,报文的流向可以直接看出来,而不再去看端口或者IP去推导出流向了。
|
|
|
|
|
|
好了,“为什么会有重复确认”的问题,我们搞清楚了,它就是由于三个报文中,第一个报文没有到达客户端,而后两个到达的报文触发了客户端发送两次重复确认。我们接下来看更为关键的问题。
|
|
|
|
|
|
#### 第二个疑问:为什么重传没有成功?
|
|
|
|
|
|
第一个报文就算暂时丢失,后续也有两次重传,为什么这些重传都没成功呢?既然我们同时有成功情况和不成功情况下的抓包文件,那我们直接比较,也许就能找到原因了。
|
|
|
|
|
|
让我们把两个文件中的类似的TCP流对比一下:
|
|
|
|
|
|
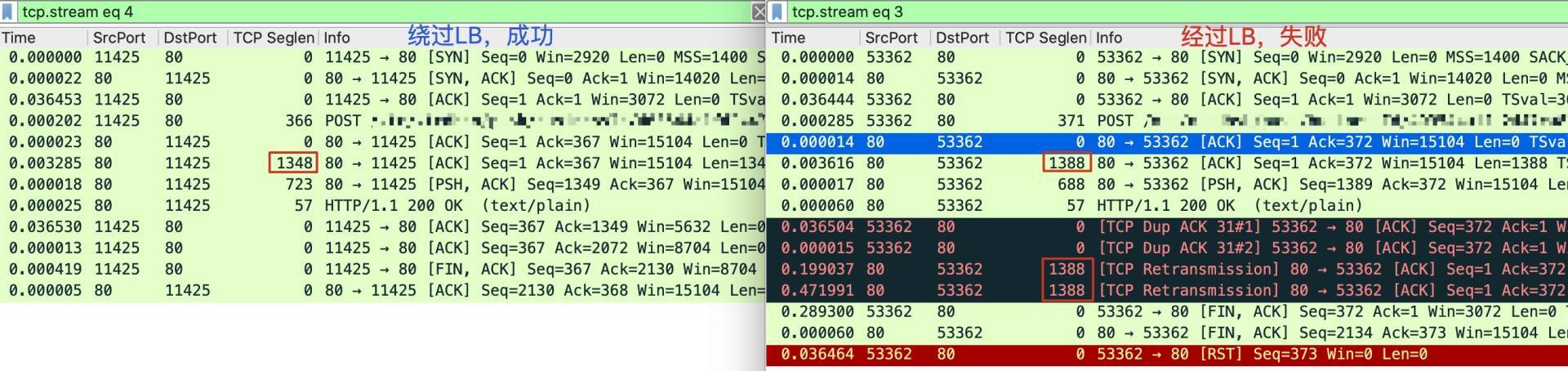
|
|
|
|
|
|
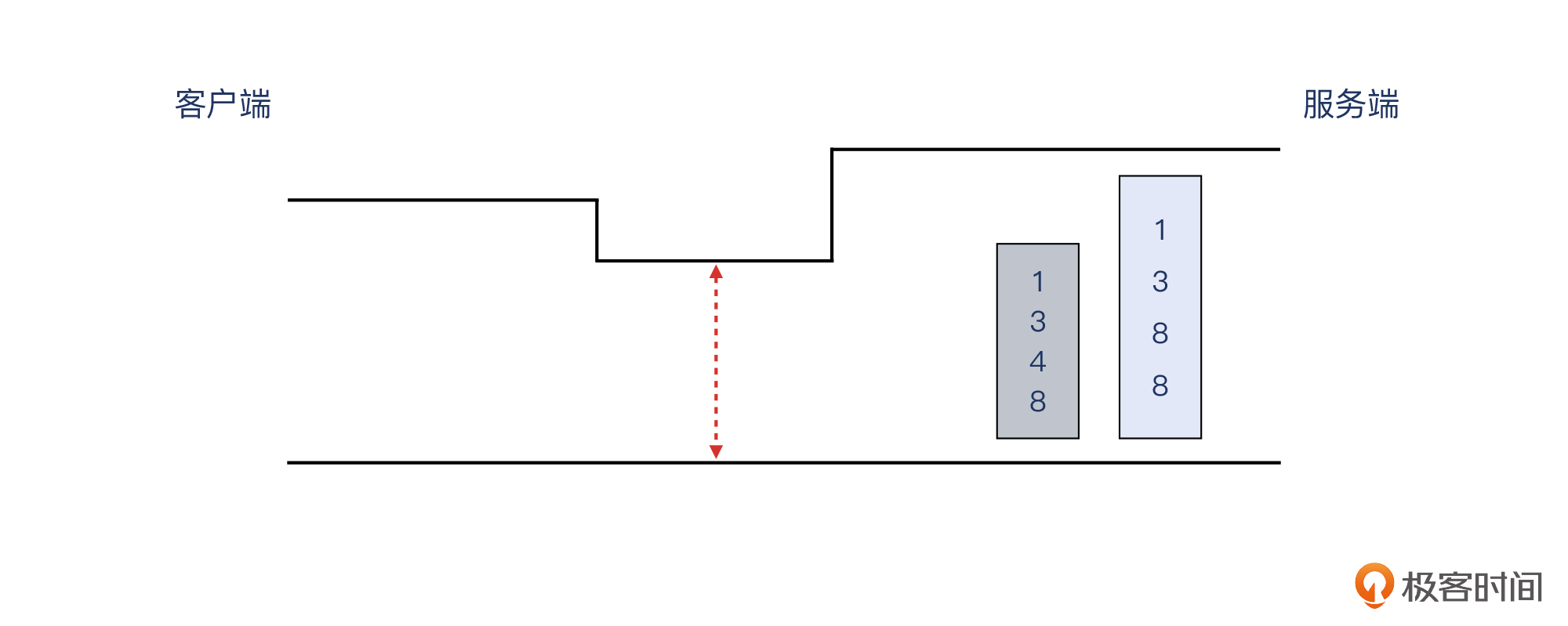
你能发现其中的不同吗?这应该还是比较容易发现的,它就是:**HTTP响应报文的大小**。两次测试中,虽然HTTP响应报文都分成了3个TCP报文,但最大报文大小不同:左边是1348,右边是1388,相差有40字节。既然已经提到了报文大小,那你应该会联想到我们这节课的主题,MTU了吧?
|
|
|
|
|
|
**MTU,中文叫最大传输单元,也就是第三层的报文大小的上限。**我们知道,网络路径中,小的报文相对容易传输,而大的报文遇到路径中某个MTU限制的可能会更大。那么在这里,假如这个问题真的是MTU限制导致的,显然,1388会比1348更容易遇到这个问题!
|
|
|
|
|
|
|
|
|
|
|
|
就像上面示意图展示的那样,如果路径中有一个偏小的MTU环节,那么完全有可能导致1388字节的报文无法通过,而1348字节的报文就可以通过。
|
|
|
|
|
|
而且,因为MTU是一个静态设置,在同样的路径上,一旦某个尺寸的报文一次没通过,后续的这个尺寸的报文全都不能通过。这样的话,后续重传的两次1388字节的报文也都失败这个事实,也就可以解释了。
|
|
|
|
|
|
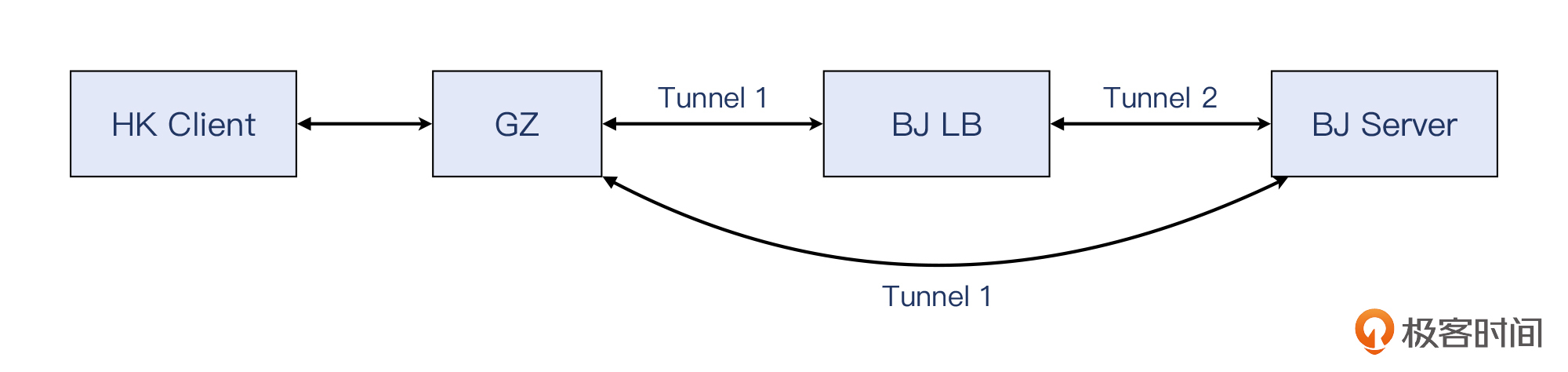
既然问题跟MTU有关,我们就检查了客户端到服务端之间的一整条链路,发现了一个之前没注意到的情况:除了广州到北京之间有一条隧道,在北京LB到服务端之间,还有一条额外的隧道。我们在[第5讲](https://time.geekbang.org/column/article/481042)里学习过,**隧道会增加报文的大小**。而正是这条额外隧道,造成了报文被封装后,超过了路径最小MTU的大小!从下面的示意图中,我们能看到两次路径上的区别所在:
|
|
|
|
|
|
|
|
|
|
|
|
经过LB的时候,报文需要做2次封装(Tunnel 1和Tunnel 2),而绕过LB就只要做1次封装(只有Tunnel 1)。跟生活中的例子一样,同样体型的两个人,穿两件衣服的那个看起来比穿单衣的那个要显胖一点,也是理所当然。要显瘦,穿薄点。或者实在要穿两件,那只好自己锻炼瘦身(改小自己的MTU)了!
|
|
|
|
|
|
另外,由于Tunnel 1比Tunnel 2的封装更大一些,所以服务端选择了不同的传输尺寸,一个是1388,一个是1348。
|
|
|
|
|
|
#### 第三个疑问:为什么重传只有两次?
|
|
|
|
|
|
一般我们印象里TCP重传会有很多次,为什么这个案例里只有两次呢?如果你能联想到[第3讲](https://time.geekbang.org/column/article/479163)里提到的多个内核TCP配置参数,那可能你会想到`net.ipv4.tcp_retries2`这个参数。确实,通过这个参数的调整,是可以把重传次数改小,比如改为两次的。不过在这个案例里不太可能。一方面,除非有必要,没人会特地去改动这个值;另外一个原因,是因为我们找到了更合理的解释。
|
|
|
|
|
|
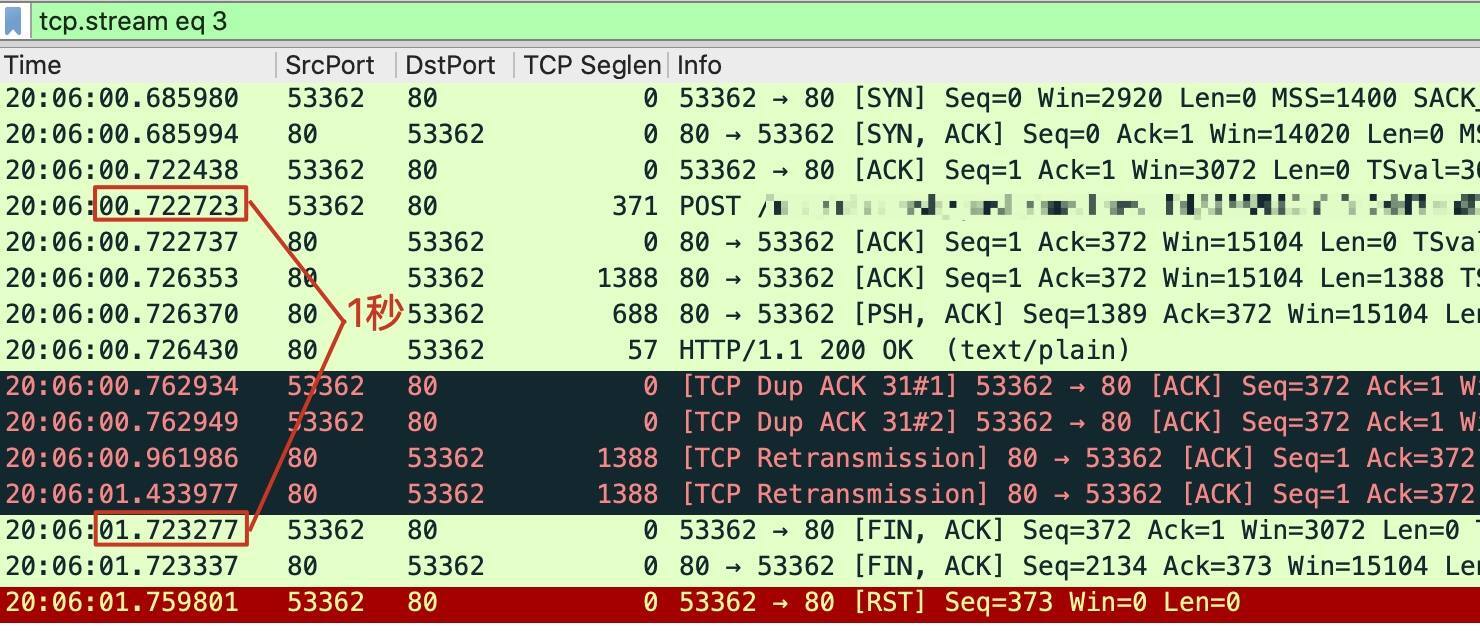
这个解释就是**客户端超时**,这一点其实我在前面介绍案例的时候就提到过。从TCP流来看,从发送POST请求开始到FIN结束,一共耗时正好在1秒左右。我们可以把Time列从显示时间差(delta time)改为显示绝对时间(absolute time),得到下图:
|
|
|
|
|
|
|
|
|
|
|
|
可见,客户端在0.72秒发出了POST请求,在1.72秒发出了TCP挥手(第一个FIN),相差正好1秒,更多的重传还来不及发生,连接就结束了。
|
|
|
|
|
|
这种“整数值”,一般是跟某种特定的(有意的)配置有关,而不是偶然。那么显然,这个案例里,客户端压测程序配置了1秒超时,目的也容易理解:这样可以保证即使一些请求没有得到回复,客户端还是可以快速释放资源,开启下一个测试请求。
|
|
|
|
|
|
## 一般对策
|
|
|
|
|
|
其实,我估计你在日常工作中也可能遇到过这种MTU引发的问题。那一般来说,我们的对策是把两端的MTU往下调整,使得报文发出的时候的尺寸就小于路径最小MTU,这样就可以规避掉这类问题了。
|
|
|
|
|
|
举个例子,在我的测试机上,执行**ip addr**命令,就可以查看到各个接口的MTU,比如下面的输出里,enp0s3口的当前MTU是1500:
|
|
|
|
|
|
```plain
|
|
|
$ ip addr
|
|
|
1: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
|
|
|
link/ether 08:00:27:09:92:f9 brd ff:ff:ff:ff:ff:ff
|
|
|
inet 192.168.2.29/24 brd 192.168.2.255 scope global dynamic enp0s3
|
|
|
valid_lft 82555sec preferred_lft 82555sec
|
|
|
inet6 fe80::a00:27ff:fe09:92f9/64 scope link
|
|
|
valid_lft forever preferred_lft forever
|
|
|
|
|
|
```
|
|
|
|
|
|
而假如,路径上有一个比1500更小的MTU,那为了适配这个状况,我们就需要调小MTU。这么做很简单,比如执行以下命令,就可以把MTU调整为1400字节:
|
|
|
|
|
|
```plain
|
|
|
$ sudo ip link set enp0s3 mtu 1400
|
|
|
|
|
|
```
|
|
|
|
|
|
## “暗箱操作”
|
|
|
|
|
|
那除了这个方法,是不是就没有别的方法了呢?其实,我喜欢网络的一个重要原因是,它有很强的“可玩性”。**只要我们有可能拆解网络报文,然后遵照协议规范做事情,那还是有不少灵活的操作空间的。**你可能会好奇:这听起来有点像“灰色地带”一样,难道网络还能玩“潜规则”吗?
|
|
|
|
|
|
比如这次的案例,网络环节都是软件路由和软件网关,所以“暗箱操作”也成了可能,我们不需要修改两端MTU就能解决这个问题。是不是有点神奇?不过,你理解了TCP和MTU的关系,就会明白这是如何做到的了。
|
|
|
|
|
|
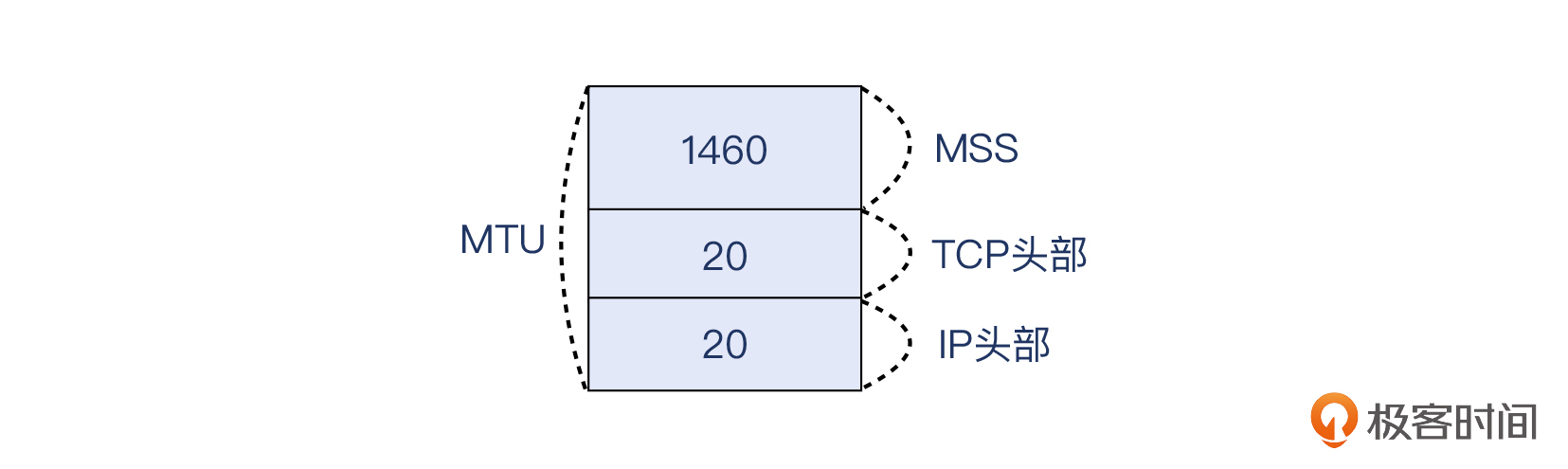
MTU本身是三层的概念,而在第四层的TCP层面,有个对应的概念叫**MSS,Maximum Segment Size(最大分段尺寸),也就是单纯的TCP载荷的最大尺寸**。MTU是三层报文的大小,在MTU的基础上刨去IP头部20字节和TCP头部20字节,就得到了最常见的MSS 1460字节。如果你之前对MTU和MSS还分不清楚的话,现在应该能搞清楚了。
|
|
|
|
|
|
|
|
|
|
|
|
MSS在TCP里是怎么体现的呢?其实我在TCP握手那一讲里提到过 [Window Scale](https://time.geekbang.org/column/article/479163),你很容易能联想到,MSS其实也是在握手阶段完成“通知”的。在SYN报文里,客户端向服务端通报了自己的MSS。而在SYN+ACK里,服务端也做了类似的事情。这样,两端就知道了对端的MSS,在这条连接里发送报文的时候,双方发送的TCP载荷都不会超过对方声明的MSS。
|
|
|
|
|
|
当然,如果发送端本地网口的MTU值,比对方的MSS + IP header + TCP header更低,那么会以本地MTU为准,这一点也不难理解。这里借用一下 [RFC879](https://datatracker.ietf.org/doc/html/rfc879) 里的公式:
|
|
|
|
|
|
> **SndMaxSegSiz = MIN((MTU - sizeof(TCPHDR) - sizeof(IPHDR)), MSS)**
|
|
|
|
|
|
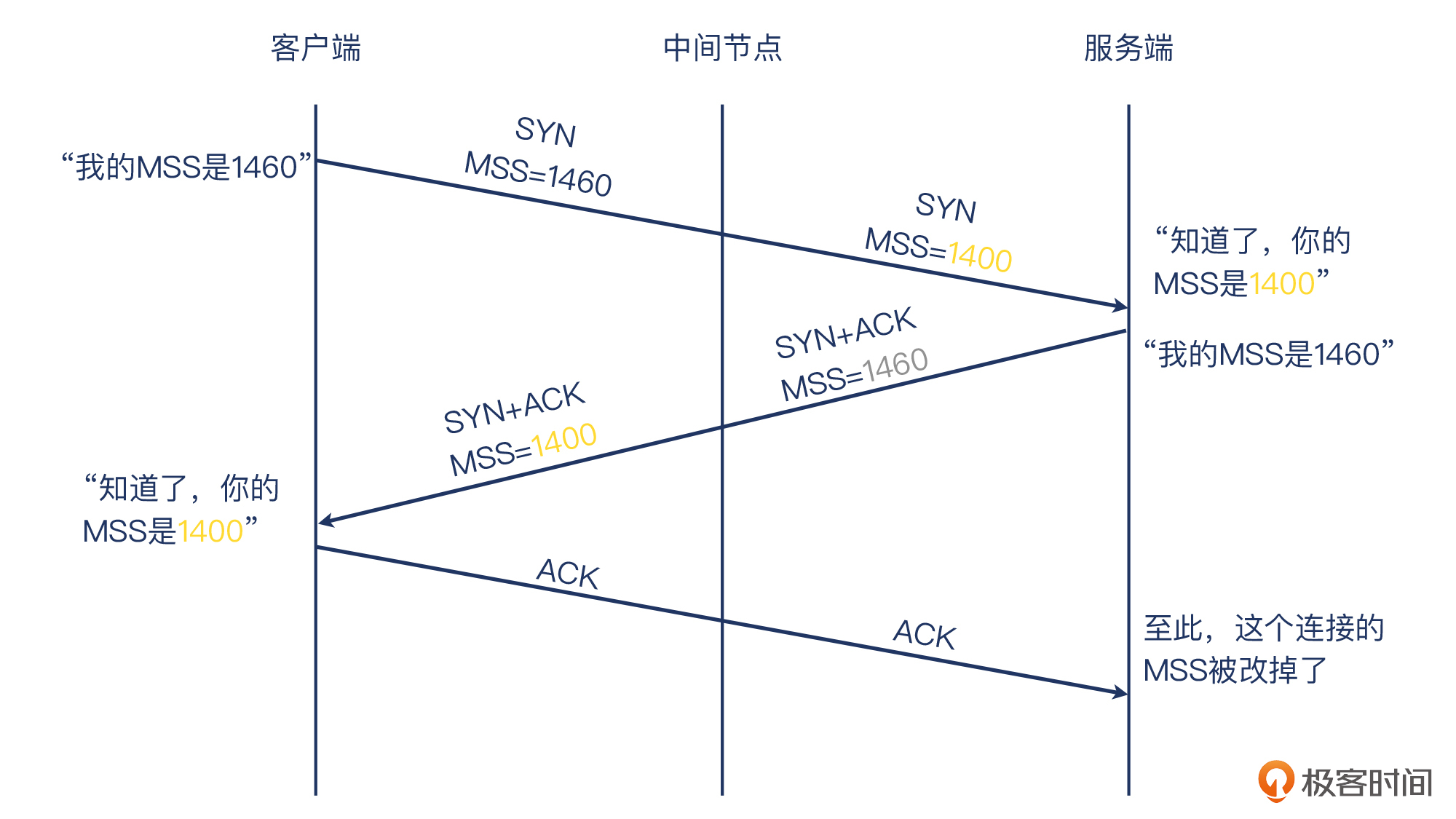
MTU是两端的静态配置,除非我们登录机器,否则改不了它们的MTU。但是,它们的TCP报文却是在网络上传送的,而我们做“暗箱操作”的机会在于:**TCP本身不加密,这就使得它可以被改变!**也就是我们可以在中间环节修改TCP报文,让其中的MSS变为我们想要的值,比如把它调小。
|
|
|
|
|
|
这里立功的又是一张熟悉的面孔:**iptables**。在中间环节(比如某个软件路由或者软件网关)上,在iptabes的FORWARD链这个位置,我们可以添加规则,修改报文的MSS值。比如在这个案例里,我们通过下面这条命令,把经过这个网络环节的TCP握手报文里的MSS,改为1400字节:
|
|
|
|
|
|
```plain
|
|
|
iptables -A FORWARD -p tcp --tcp-flags SYN SYN -j TCPMSS --set-mss 1400
|
|
|
|
|
|
```
|
|
|
|
|
|
它工作起来就是下图这样,是不是很巧妙?通过这种途中的修改,两端就以修改后的MSS来工作了,这样就避免了用原先过大的MSS引发的问题。我称之为“暗箱操作”,就是因为这是通信双方都不知道的一个操作,而正是这个操作不动声色地解决了问题。
|
|
|
|
|
|
|
|
|
|
|
|
## 什么是TSO?
|
|
|
|
|
|
前面说的都是操作系统会做TCP分段的情况。但是,这个工作其实还是有一些CPU的开销的,毕竟需要把应用层消息切分为多个分段,然后给它们组装TCP头部等。而为了提高性能,网卡厂商们提供了一个特性,就是让这个分段的工作**从内核下沉到网卡上来完成**,这个特性就是**TCP Segmentation Offload**。
|
|
|
|
|
|
这里的offload,如果仅仅翻译成“卸载”,可能还是有点晦涩。其实,它是off + load,那什么是load呢?就是CPU的开销。如果网卡硬件芯片完成了这部分计算任务,那么CPU就减轻负担了,这就是offload一词的真正含义。
|
|
|
|
|
|
TSO启用后,发送出去的报文可能会超过MSS。同样的,在接收报文的方向,我们也可以启用GRO(Generic Receive Offload)。比如下图中,TCP载荷就有2800字节,这并不是说这些报文真的是以2800字节这个尺寸从网络上传输过来的,而是由于接收端启用了GRO,由接收端的网卡负责把几个小报文“拼接”成了2800字节。
|
|
|
|
|
|

|
|
|
|
|
|
所以,如果以后你在Wireshark里看到这种超过1460字节的TCP段长度,不要觉得奇怪了,这只是因为你启用了TSO(发送方向),或者是GRO(接收方向),而不是TCP报文真的就有这么大!
|
|
|
|
|
|
想要确认你的网卡是否启用了这些特性,可以用ethtool命令,比如下面这样:
|
|
|
|
|
|
```plain
|
|
|
$ ethtool -k enp0s3 | grep offload
|
|
|
tcp-segmentation-offload: on
|
|
|
generic-segmentation-offload: on
|
|
|
generic-receive-offload: on
|
|
|
large-receive-offload: off [fixed]
|
|
|
rx-vlan-offload: on
|
|
|
tx-vlan-offload: on [fixed]
|
|
|
l2-fwd-offload: off [fixed]
|
|
|
hw-tc-offload: off [fixed]
|
|
|
esp-hw-offload: off [fixed]
|
|
|
esp-tx-csum-hw-offload: off [fixed]
|
|
|
rx-udp_tunnel-port-offload: off [fixed]
|
|
|
tls-hw-tx-offload: off [fixed]
|
|
|
tls-hw-rx-offload: off [fixed]
|
|
|
|
|
|
```
|
|
|
|
|
|
当然,在上面的输出中,你也能看到有好几种别的offload。如果你感兴趣,可以自己搜索研究下,这里就不展开了。
|
|
|
|
|
|
对了,要想启用或者关闭TSO/GRO,也是用ethtool命令,比如这样:
|
|
|
|
|
|
```plain
|
|
|
$ sudo ethtool -K enp0s3 tso off
|
|
|
$ sudo ethtool -k enp0s3 | grep offload
|
|
|
tcp-segmentation-offload: off
|
|
|
|
|
|
```
|
|
|
|
|
|
## IP分片
|
|
|
|
|
|
IP层也有跟TCP分段类似的机制,它就是IP分片。很多人搞不清IP分片和TCP分段的区别,甚至经常混为一谈。事实上,它们是两个在不同层面的分包机制,互不影响。
|
|
|
|
|
|
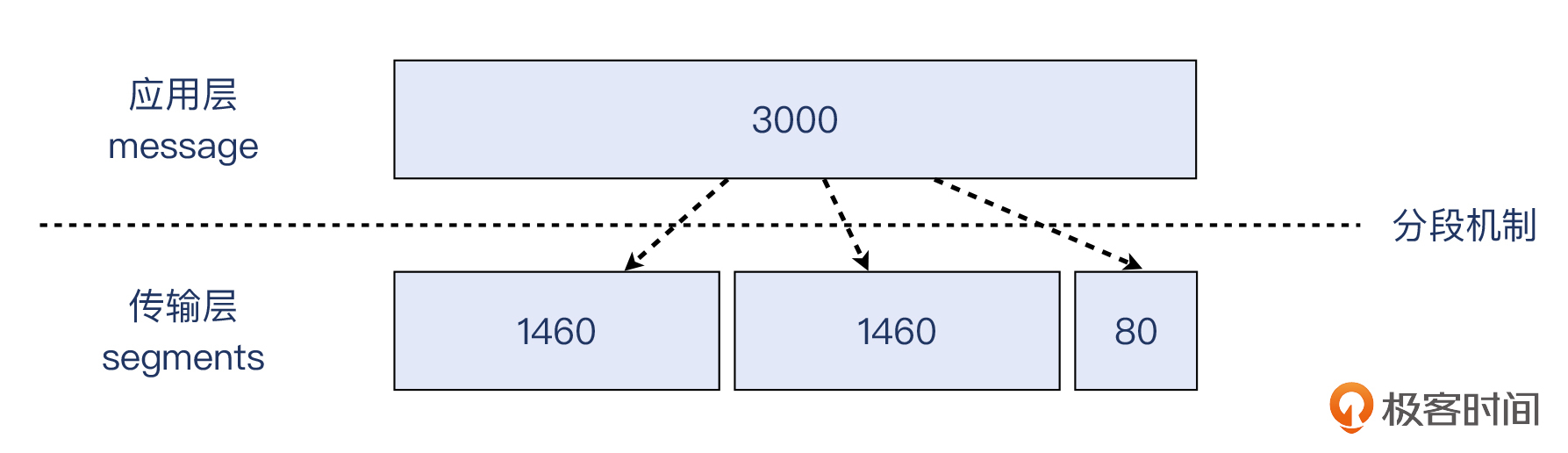
**在TCP这一层,分段的对象是应用层发给TCP的消息体**(message)。比如应用给TCP协议栈发送了3000字节的消息,那么TCP发现这个消息超过了MSS(常见值为1460),就必须要进行分段,比如可能分成1460,1460,80这三个TCP段。
|
|
|
|
|
|
|
|
|
|
|
|
**在IP这一层,分片的对象是IP包的载荷**,它可以是TCP报文,也可以是UDP报文,还可以是IP层自己的报文比如ICMP。
|
|
|
|
|
|
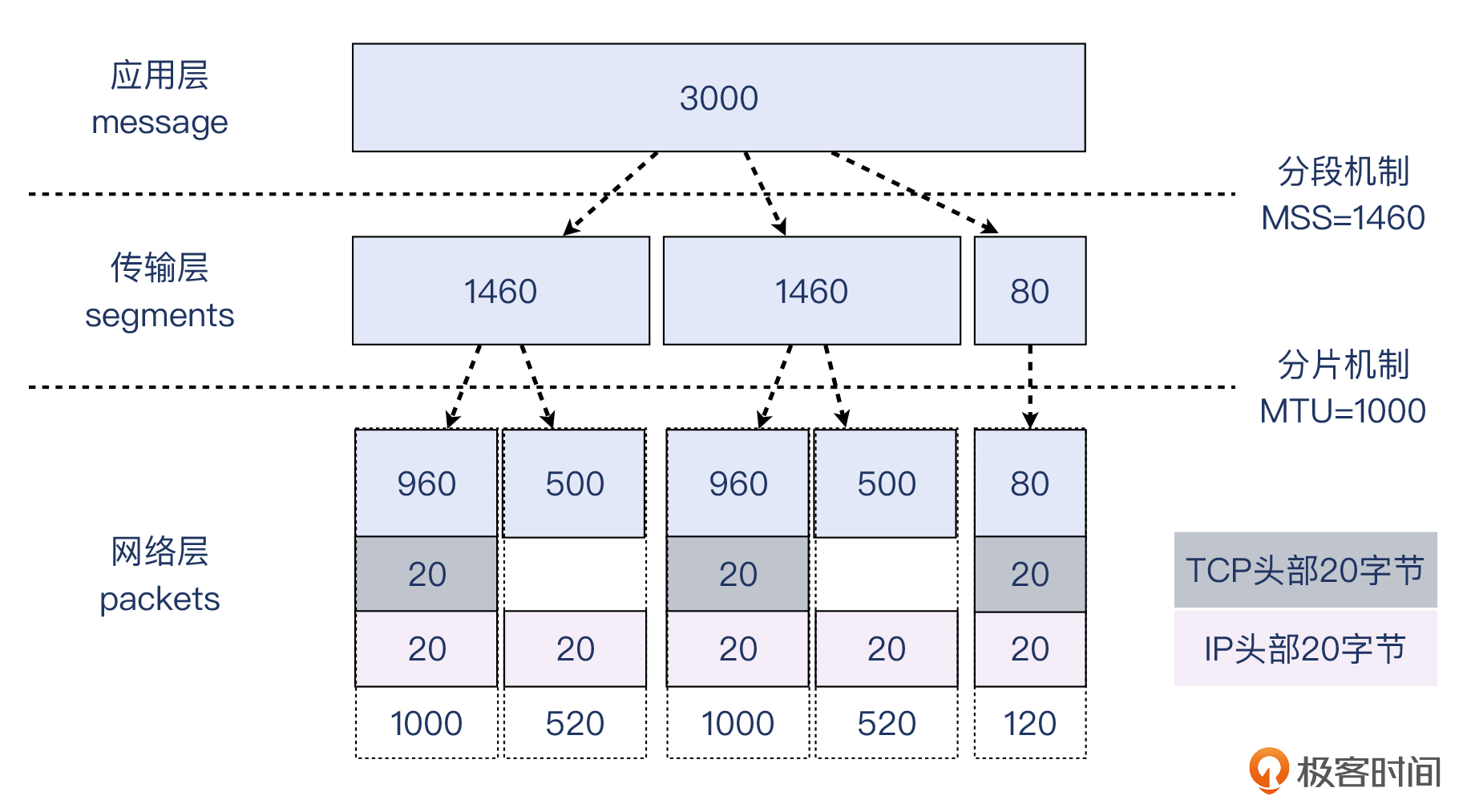
为了帮助你理解segmentation和fragmentation的区别,我现在假设一个“奇葩”的场景,也就是MSS为1460字节,而MTU却只有1000字节,那么segmentation和fragmentation将按照如下示意图来工作:
|
|
|
|
|
|
|
|
|
|
|
|
> 补充:为了方便讨论,我们假设TCP头部就是没有Option扩展的20字节。但实际场景里,很可能MSS小于1460字节,而TCP头部也超过20字节。
|
|
|
|
|
|
当然,实际的操作系统不太会做这种自我矛盾的傻事,这是因为它自身会解决好MSS跟MTU的关系,比如一般来说,MSS会自动调整为MTU减去40字节。但是我们如果把视野扩大到局域网,也就是主机再加上网络设备,那么就有可能发生这样的情况:1460字节的TCP分段由这台主机完成,1000字节的IP分片由路径中某台MTU为1000的网络设备完成。
|
|
|
|
|
|
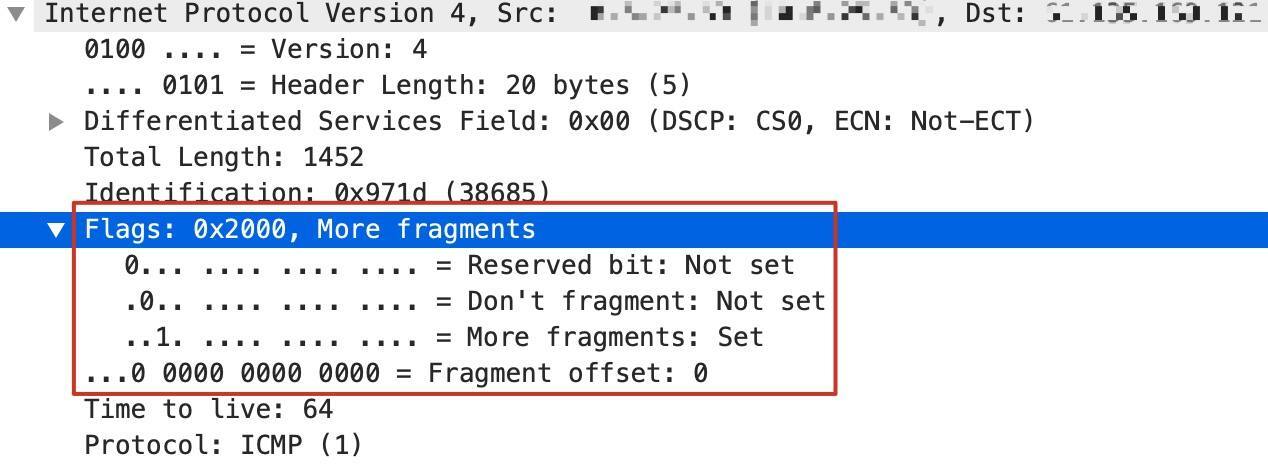
这里其实也有个隐含的条件,就是主机发出的1500字节的报文,不能设置 **DF(Don’t Fragment)位**,否则它既超过了1000这个路径最小MTU,又不允许分片,那么网络设备只能把它丢弃。
|
|
|
|
|
|
在Wireshark里,我们可以清楚地看到IP报文的这几个标志位:
|
|
|
|
|
|
|
|
|
|
|
|
现在我们假设主机发出的报文是不带DF位的,那么在这种情况下,这台网络设备会把它切分为一个1000(也就是960+20+20)字节的报文和一个520(也就是500+20)字节的报文。1000字节的IP报文的 **MF位(More Fragment)**会设置为1,表示后续还有更多分片,而520字节的IP报文的MF字段为0。
|
|
|
|
|
|
这样的话,接收端收到第一个IP报文时发现MF是1,就会等第二个IP报文到达,又因为第二个报文的MF是0,那么结合第二个报文的fragment offset信息(这个报文在分片流中的位置),就把这两个报文重组为一个新的完整的IP报文,然后进入正常处理流程,也就是上报给TCP。
|
|
|
|
|
|
不过在现实场景里,**IP分片是需要尽量避免的**,原因有很多,主要是因为互联网是一个松散的架构,这就导致路径中的各个环节未必会完全遵照所有的约定。比如你发出了大于PMTU的报文,寄希望于MTU较小的那个网络环节为你做分片,但事实上它可能不做分片,而是直接丢弃,比如下面两种情况:
|
|
|
|
|
|
* 它考虑到开销等问题,未必做分片,所以直接丢弃。
|
|
|
* 如果你的报文有DF标志位,那么也是直接丢弃。
|
|
|
|
|
|
即使它帮你做了分片,但因为开销比较大,增加的时延对性能也是一个不利因素。
|
|
|
|
|
|
另外一个原因是,分片后,TCP报文头部只在第一个IP分片中,后续分片不带TCP头部,那么防火墙就不知道后面这几个报文用的传输层协议是什么,可能判断为有害报文而丢弃。
|
|
|
|
|
|
总之,为了避免这些麻烦,我们还是不要开启IP分片功能。事实上,Linux默认的配置就是,发出的IP报文都设置了DF位,就是明确告诉每个三层设备:“不要对我的报文做分片,如果超出了你的MTU,那就直接丢弃,好过你慢腾腾地做分片,反而降低了网络性能”。
|
|
|
|
|
|
## 小结
|
|
|
|
|
|
这节课,我们通过拆解一个典型的MTU引发的传输问题,学习了MTU和MSS、分段和分片、各种卸载(offload)机制等概念。这里,我帮你再提炼几个要点:
|
|
|
|
|
|
* 在案例分析的过程中,我们解读了Wireshark里的信息,特别是两次DupAck和两次重传,推导出了问题的根因。这里,你需要了解 **200ms超时重传这个知识点**,这在平时排查重传问题时也经常用到。
|
|
|
* 借助 **Wireshark的Flow graph**,我们可以更加清晰地看到两端报文的流动过程,这对我们推导问题提供了便利。
|
|
|
* 如果能稳定重现成功和失败这两种不同场景,那就对我们排查工作提供了极大的便利。我们通过**对比成功和失败两种场景下的不同的抓包文件**,能比较快地定位到问题根因。
|
|
|
* 如果排查中遇到**有“整数值”出现**,可以重点查一下,一般这跟人为的设置有关系,也有可能就是根因,或者与根因有关。
|
|
|
* 如果你对网络中间环节(包括LB、网关、防火墙等)有权限,又不想改动两端机器的MTU,那么可以选择在中间环节实施“暗箱操作”,也就是**用iptables规则改动双方的MSS**,从而间接地达到“双方不发送超过MTU的报文”的目的。
|
|
|
* 我们也学习了如何**用ethtool工具查看offload相关特性**,包括TSO、LRO、GRO等等。同样通过ethtool,我们还可以对这些特性进行启用或者禁用,这为我们的排查和调优工作提供了更大的余地。
|
|
|
|
|
|
## 思考题
|
|
|
|
|
|
最后再给你留两道思考题:
|
|
|
|
|
|
* 在LB或者网关上修改MSS,虽然可以减小MSS,从而达到让通信成功这个目的,但是这个方案有没有什么劣势或者不足,也同样需要我们认真考量呢?可以从运维和可用性的角度来思考。
|
|
|
* 你有没有遇到过MTU引发的问题呢?欢迎你分享到留言区,一同交流。
|
|
|
|
|
|
## 附录
|
|
|
|
|
|
抓包示例文件:[https://gitee.com/steelvictor/network-analysis/tree/master/08](https://gitee.com/steelvictor/network-analysis/tree/master/08)
|
|
|
|