|
|
# 28 | MapReduce:如何通过集群实现离线计算?
|
|
|
|
|
|
你好,我是陶辉。
|
|
|
|
|
|
接下来的2节课我将介绍如何通过分布式集群优化计算任务。这一讲我们首先来看对于有边界静态数据的离线计算,下一讲再来看对无边界数据流的实时计算。
|
|
|
|
|
|
对大量数据做计算时,我们通常会采用分而治之的策略提升计算速度。比如单机上基于递归、分治思想实现的快速排序、堆排序,时间复杂度只有O(N\*logN),这比在原始数据集上工作的插入排序、冒泡排序要快得多(O(N2))。然而,当单机磁盘容量无法存放全部数据,或者受限于CPU频率、核心数量,单机的计算时间远大于可接受范围时,我们就需要在分布式集群上使用分治策略。
|
|
|
|
|
|
比如,大规模集群每天产生的日志量是以TB为单位计算的,这种日志分析任务单台服务器的处理能力是远远不够的。我们需要将计算任务分解成单机可以完成的小任务,由分布式集群并行处理后,再从中间结果中归并得到最终的运算结果。这一过程由Google抽象为[MapReduce](https://zh.wikipedia.org/wiki/MapReduce) 模式,实现在Hadoop等分布式系统中。
|
|
|
|
|
|
虽然MapReduce已经有十多个年头的历史了,但它仍是分布式计算的基石,这种编程思想在新出现的各种技术中都有广泛的应用。比如当在单机上使用TensorFlow完成一轮深度学习的时间过久,或者单颗GPU显存无法存放完整的神经网络模型时,就可以通过Map思想把数据或者模型分解给多个TensorFlow实例,并行计算后再根据Reduce思想合并得到最终结果。再比如知识图谱也是通过MapReduce思想并行完成图计算任务的。
|
|
|
|
|
|
接下来我们就具体看看如何在分布式集群中实现离线计算,以及MapReduce是怎样提供SQL语言接口的。
|
|
|
|
|
|
## 分而治之:如何实现集群中的批量计算?
|
|
|
|
|
|
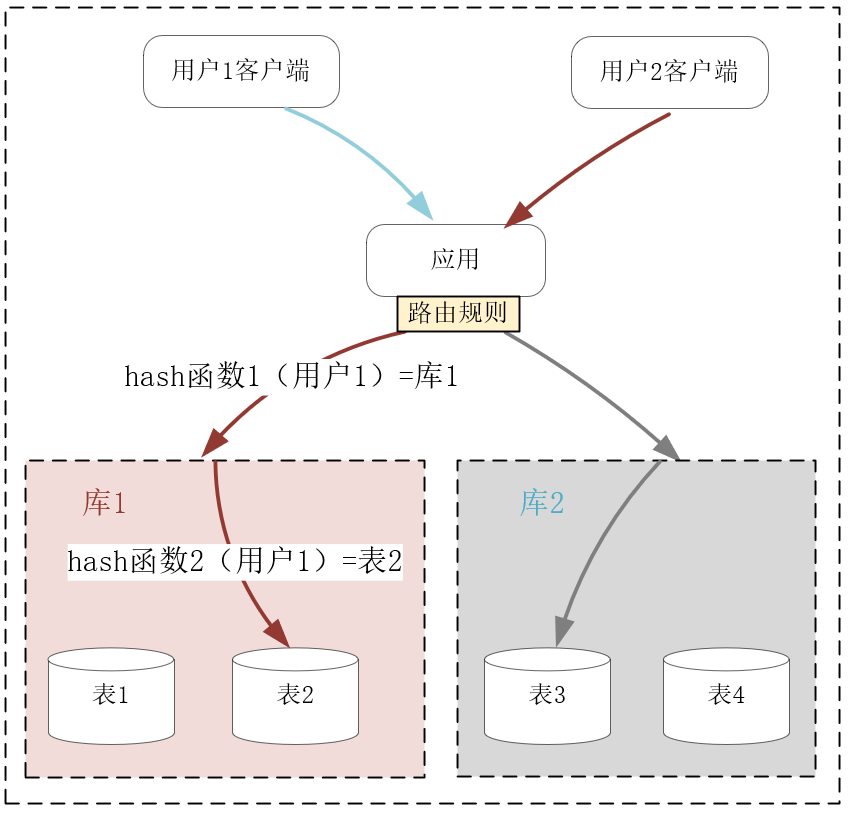
分而治之的思想在分布式系统中广为使用,比如[\[第21讲\]](https://time.geekbang.org/column/article/252741) 介绍过的AKF立方体Z轴扩展,就是基于用户的请求,缩小集群中单个节点待处理的数据量,比如下图中当关系数据库中单表行数达到千万行以上时,此时不得不存放在磁盘中的索引将会严重降低SQL语句的查询速度。而执行分库分表后,由应用或者中间层的代理分解查询语句,待多个不足百万行的表快速返回查询结果后,再归并为最终的结果集。
|
|
|
|
|
|
|
|
|
|
|
|
与上述的IO类任务不同,并非所有的计算任务都可以基于分治策略,分解为可以并发执行的子任务。比如[\[第14讲\]](https://time.geekbang.org/column/article/241632) 介绍过的基于[CBC分组模式](https://zh.wikipedia.org/zh-hans/%E5%88%86%E7%BB%84%E5%AF%86%E7%A0%81%E5%B7%A5%E4%BD%9C%E6%A8%A1%E5%BC%8F)的AES加密算法就无法分解执行,如下图所示,每16个字节的块在加密时,都依赖前1个块的加密结果,这样的计算过程既无法利用多核CPU,也无法基于MapReduce思想放在多主机上并发执行。
|
|
|
|
|
|
[](https://zh.wikipedia.org/zh-hans/%E5%88%86%E7%BB%84%E5%AF%86%E7%A0%81%E5%B7%A5%E4%BD%9C%E6%A8%A1%E5%BC%8F)
|
|
|
|
|
|
我们再来看可以使用MapReduce的计算任务,其中最经典的例子是排序(Google在构建倒排索引时要为大量网页排序)。当使用插入排序(不熟悉插入排序的同学,可以想象自己拿了一手乱牌,然后在手中一张张重新插入将其整理有序)在整个数据集上操作时,计算的时间复杂度是O(N2),但快排、堆排序、归并排序等算法的时间复杂度只有O(N\*logN),这就是通过分治策略,缩小子问题数据规模实现的。
|
|
|
|
|
|
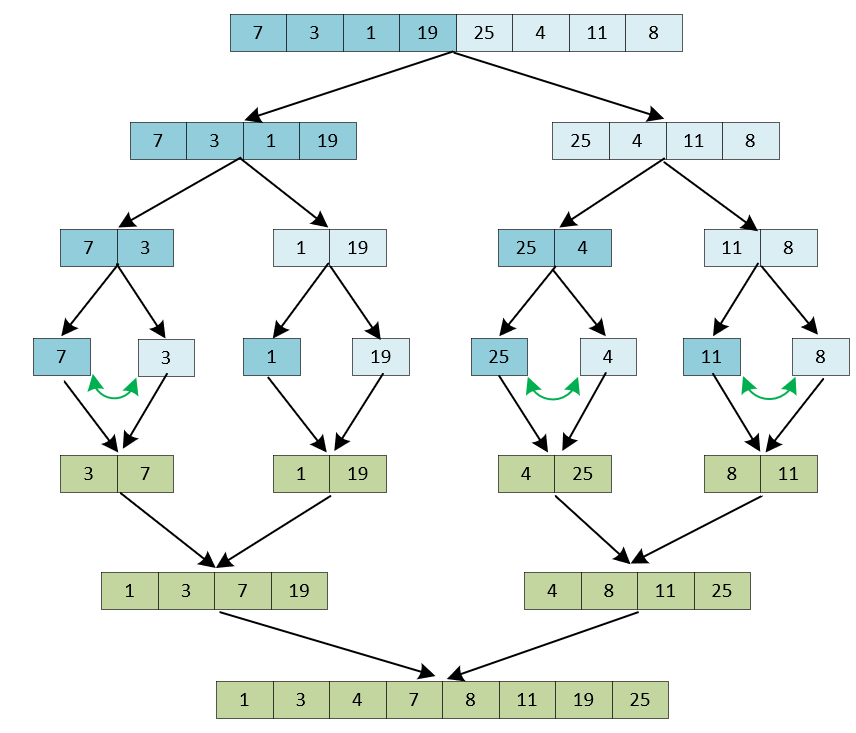
比如下图是在8个数字上使用归并排序算法进行排序的流程。我们将数组递归地进行3(log8)轮对半拆分后,每个子数组就只有2个元素。对2个元素排序只需要进行1次比较就能完成。接着,再将有序的子数组不断地合并,就可以得到完整的有序数组。
|
|
|
|
|
|
|
|
|
|
|
|
其中,将两个含有N/2个元素的有序子数组(比如1、3、7、19和4、8、11、25),合并为一个有序数组时只需要做N/2到N-1次比较(图中只做了5次比较),速度非常快。因此,比较次数乘以迭代轮数就可以得出时间复杂度为O(N\*logN)。
|
|
|
|
|
|
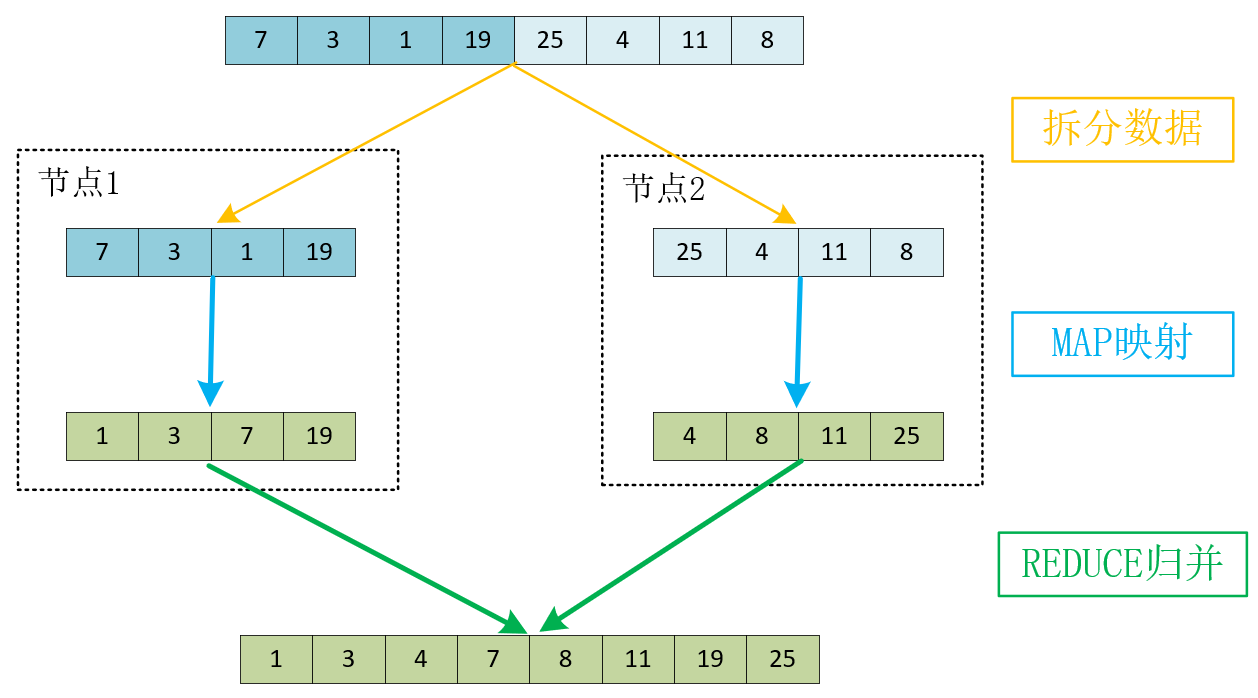
同样的道理引申到分布式系统中,就成为了MapReduce模式。其中,原始数据集要通过SPLIT步骤拆分到分布式系统中的多个节点中,而每个节点并发执行用户预定义的MAP函数,最后将MAP运算出的结果通过用户预定义的REDUCE函数,归并为最终的结果。比如上例中我们可以将8个元素拆分到2个节点中并行计算,其中每个节点究竟是继续采用归并排序,还是使用其他排序算法,这由预定义的MAP函数决定。当MAP函数生成有序的子数组后,REDUCE函数再将它们归并为完整的有序数组,具体如下图所示:
|
|
|
|
|
|
|
|
|
|
|
|
当面对TB、PB级别的数据时,MapReduce思想就成了唯一的解决方案。当然,在实际软件工程中实现MapReduce的框架要比上面的示意图复杂许多,毕竟在大规模分布式系统中,故障每时每刻都会发生,如何分发数据、调度节点执行MAP映射、监控计算节点等,都需要精心的设计。特别是,当单个节点的磁盘无法存放下全部数据时,常常使用类似HDFS的分布式文件系统存放数据,所以MapReduce框架往往还需要对接这样的系统来获取数据,具体如下图所示:
|
|
|
|
|
|
[](http://a4academics.com/tutorials/83-hadoop/840-map-reduce-architecture)
|
|
|
|
|
|
而且,生产环境中的任务远比整数排序复杂得多,所以写对Map、Reduce函数并不容易。另一方面,大部分数据分析任务又是高度相似的,所以我们没有必要总是直接编写Map、Reduce函数,实现发布式系统的离线计算。由于SQL语言支持聚合分析、表关联,还内置了许多统计函数,很适合用来做数据分析,它的学习成本又非常低,所以大部分MapReduce框架都提供了类SQL语言的接口,可以替代自行编写Map、Reduce函数。接下来我们看看,SQL语言统计数据时,Map、Reduce函数是怎样工作的。
|
|
|
|
|
|
## SQL是如何简化MapReduce模式的?
|
|
|
|
|
|
我们以最常见的Web日志分析为例,观察用SQL语言做统计时,MapReduce流程是怎样执行的。举个例子,Nginx的access.log访问日志是这样的(基于默认的combined格式):
|
|
|
|
|
|
```
|
|
|
127.0.0.1 - - [18/Jul/2020:10:16:15 +0800] "GET /login?userid=101 HTTP/1.1" 200 56 "-" "curl/7.29.0"
|
|
|
|
|
|
```
|
|
|
|
|
|
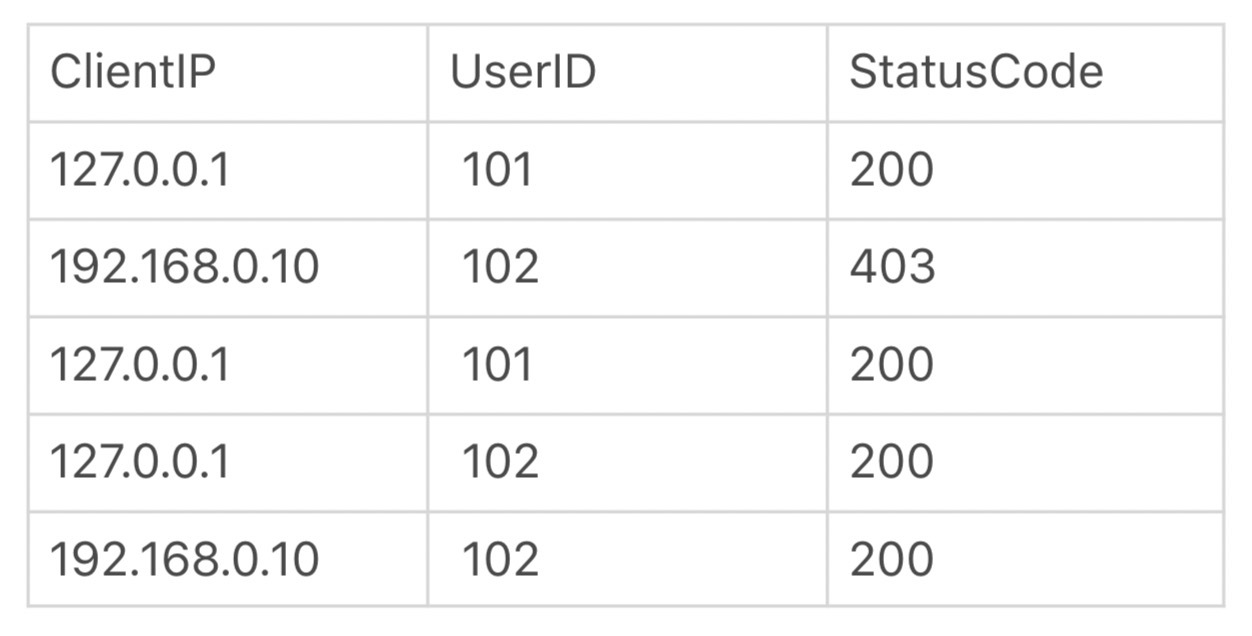
你可以通过正则表达式取出客户端IP地址、用户名、HTTP响应码,这样就可以生成结构化的数据表格:
|
|
|
|
|
|
|
|
|
|
|
|
如果我们想按照客户端IP、HTTP响应码聚合统计访问次数,基于通用的SQL规则,就可以写出下面这行SQL语句:
|
|
|
|
|
|
```
|
|
|
select ClientIp, StatusCode, count(*) from access_log group by ClientIp, StatusCode
|
|
|
|
|
|
```
|
|
|
|
|
|
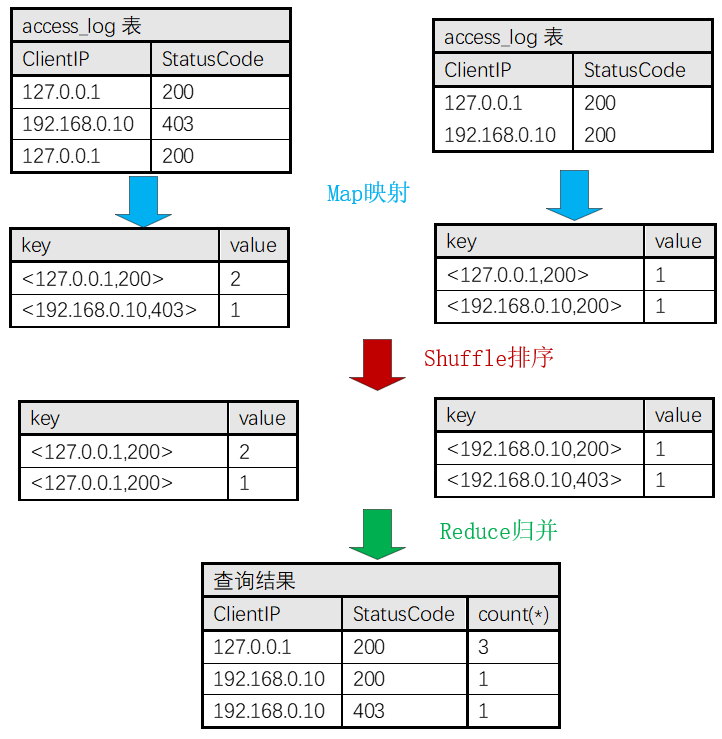
而建立在MapReduce之上的框架(比如Hive)会将它翻译成如下图所示的MapReduce流程:
|
|
|
|
|
|
|
|
|
|
|
|
其中,我们假定5行数据被拆分到2个节点中执行Map函数,其中它们分别基于2行、3行这样小规模的数据集,生成了正确的聚合统计结果。接着,在Shuffle步骤基于key关键字排序后,再交由Reduce函数归并出正确的结果。
|
|
|
|
|
|
除了这个例子中的count函数,像max(求最大值)、min(求最小值)、distinct(去重)、sum(求和)、avg(求平均数)、median(求中位数)、stddev(求标准差)等函数,都很容易分解为子任务并发执行,最后归并出最终结果。
|
|
|
|
|
|
当多个数据集之间需要做交叉统计时,SQL中的join功能(包括内连接、左外连接、右外连接、全连接四种模式)也很容易做关联查询。此时,我们可以在并行计算的Map函数中,把where条件中的关联字段作为key关键字,经由Reduce阶段实现结果的关联。
|
|
|
|
|
|
由于MapReduce操作的数据集非常庞大,还需要经由网络调度多台服务器才能完成计算,因此任务的执行时延至少在分钟级,所以通常不会服务于用户的实时请求,而只是作为离线的异步任务将运算结果写入数据库。
|
|
|
|
|
|
## 小结
|
|
|
|
|
|
这一讲我们介绍了在集群中使用分治算法统计大规模数据的MapReduce模式。
|
|
|
|
|
|
当数据量很大,或者计算时间过长时,如果计算过程可以被分解为并发执行的子任务,就可以基于MapReduce思想,利用分布式集群的计算力完成任务。其中,用户可以预定义在节点中并发执行的Map函数,以及将Map输出的列表合并为最终结果的Reduce函数。
|
|
|
|
|
|
虽然MapReduce将并行计算抽象为统一的模型,但开发Map、Reduce函数的成本还是太高了,于是针对高频场景,许多MapReduce之上的框架提供了类SQL语言接口,通过group by的聚合、join连接以及各种统计函数,我们就可以利用整个集群完成数据分析。
|
|
|
|
|
|
MapReduce模式针对的是静态数据,也叫有边界数据,它更多用于业务的事前或者事后处理流程中,而做事中处理时必须面对实时、不断增长的无边界数据流,此时MapReduce就无能为力了。下一讲我们将介绍处理无边界数据的流式计算框架。
|
|
|
|
|
|
## 思考题
|
|
|
|
|
|
最后,留给你一道思考题。你遇到过哪些计算任务是无法使用MapReduce模式完成的?欢迎你在留言区与大家一起探讨。
|
|
|
|
|
|
感谢阅读,如果你觉得这节课让你有所收获,也欢迎你把今天的内容分享给你的朋友。
|
|
|
|