|
|
# 25 | 过期缓存:如何防止缓存被流量打穿?
|
|
|
|
|
|
你好,我是陶辉。
|
|
|
|
|
|
这一讲我们将对一直零散介绍的缓存做个全面的总结,同时讨论如何解决缓存被流量打穿的场景。
|
|
|
|
|
|
在分布式系统中,缓存无处不在。比如,浏览器会缓存用户Cookie,CDN会缓存图片,负载均衡会缓存TLS的握手信息,Redis会缓存用户的session,MySQL会缓存select查询出的行数据,HTTP/2会用动态表缓存传输过的HTTP头部,TCP Socket Buffer会缓存TCP报文,Page Cache会缓存磁盘IO,CPU会缓存主存上的数据,等等。
|
|
|
|
|
|
只要系统间的访问速度有较大差异,缓存就能提升性能。如果你不清楚缓存的存在,两个组件间重合的缓存就会带来不必要的复杂性,同时还增大了数据不一致引发错误的概率。比如,MySQL为避免自身缓存与Page Cache的重合,就使用直接IO绕过了磁盘高速缓存。
|
|
|
|
|
|
缓存提升性能的幅度,不只取决于存储介质的速度,还取决于缓存命中率。为了提高命中率,缓存会基于时间、空间两个维度更新数据。在时间上可以采用LRU、FIFO等算法淘汰数据,而在空间上则可以预读、合并连续的数据。如果只是简单地选择最流行的缓存管理算法,就很容易忽略业务特性,从而导致缓存性能的下降。
|
|
|
|
|
|
在分布式系统中,缓存服务会为上游应用挡住许多流量。如果只是简单的基于定时器淘汰缓存,一旦热点数据在缓存中失效,超载的流量会立刻打垮上游应用,导致系统不可用。
|
|
|
|
|
|
这一讲我会系统地介绍缓存及其数据变更策略,同时会以Nginx为例介绍过期缓存的用法。
|
|
|
|
|
|
## 缓存是最有效的性能提升工具
|
|
|
|
|
|
在计算机体系中,各类硬件的访问速度天差地别。比如:
|
|
|
|
|
|
* CPU访问缓存的耗时在10纳秒左右,访问内存的时延则翻了10倍;
|
|
|
* 如果访问SSD固态磁盘,时间还要再翻个1000倍,达到100微秒;
|
|
|
* 如果访问机械硬盘,对随机小IO的访问要再翻个100倍,时延接近10毫秒;
|
|
|
* 如果跨越网络,访问时延更要受制于主机之间的物理距离。比如杭州到伦敦相距9200公里,ping时延接近200毫秒。当然,网络传输的可靠性低很多,一旦报文丢失,TCP还需要至少1秒钟才能完成报文重传。
|
|
|
|
|
|
可见,最快的CPU缓存与最慢的网络传输,有1亿倍的速度差距!一旦高速、低速硬件直接互相访问,前者就会被拖慢运行速度。因此,**我们会使用高速的存储介质创建缓冲区,通过预处理、批处理以及缓冲数据的反复命中,提升系统的整体性能。**
|
|
|
|
|
|
不只是硬件层面,软件设计对访问速度的影响更大。比如,对关系数据库的非索引列做条件查询,时间复杂度是O(N),而对Memcached做Key/Value查询,时间复杂度则是O(1),所以在海量数据下,两者的性能差距远高于硬件。因此,RabbitMQ、Kafka这样的消息服务也会充当高速、低速应用间的缓存。
|
|
|
|
|
|
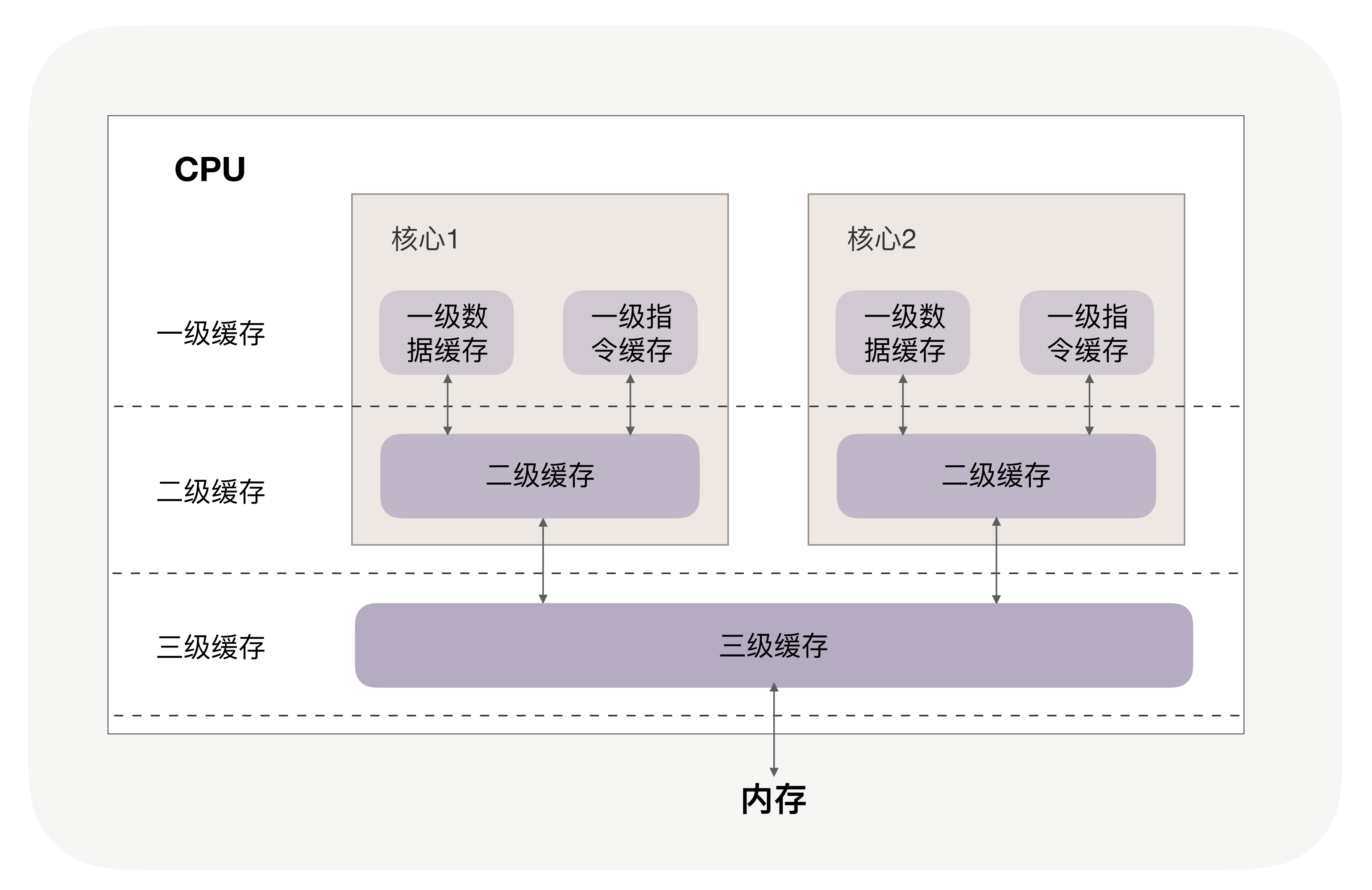
如果两个实体之间的访问时延差距过大,还可以通过多级缓存,逐级降低访问速度差,提升整体性能。比如[\[第1讲\]](https://time.geekbang.org/column/article/230194) 我们介绍过CPU三级缓存,每级缓存越靠近CPU速度越快,容量也越小,以此缓解CPU频率与主存的速度差,提升CPU的运行效率。
|
|
|
|
|
|
|
|
|
|
|
|
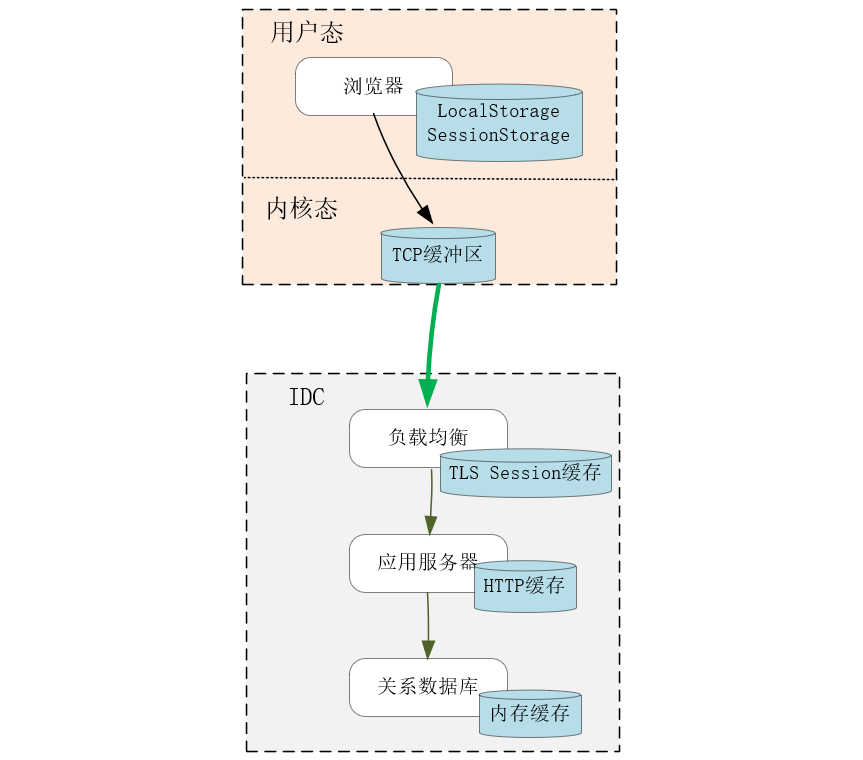
再比如下图的Web场景中,浏览器的本地缓存、操作系统内核中的TCP缓冲区(参见[\[第11讲\]](https://time.geekbang.org/column/article/239176))、负载均衡中的TLS握手缓存、应用服务中的HTTP响应缓存、MySQL中的查询缓存等,每一级缓存都缓解了上下游间不均衡的访问速度,通过缩短访问路径降低了请求时延,通过异步访问、批量处理提升了系统效率。当然,缓存使用了简单的Key/Value结构,因此可以用哈希表、查找树等容器做索引,这也提升了访问速度。
|
|
|
|
|
|
|
|
|
|
|
|
从系统底层到业务高层,缓存都大有用武之地。比如在Django这个Python Web Server中,既可以使用视图缓存,将动态的HTTP响应缓存下来:
|
|
|
|
|
|
```
|
|
|
from django.views.decorators.cache import cache_page
|
|
|
|
|
|
@cache_page(60 * 15)
|
|
|
def my_view(request):
|
|
|
...
|
|
|
|
|
|
```
|
|
|
|
|
|
也可以使用[django-cachealot](https://django-cachalot.readthedocs.io/en/latest/) 这样的中间件,将所有SQL查询结果缓存起来:
|
|
|
|
|
|
```
|
|
|
INSTALLED_APPS = [
|
|
|
...
|
|
|
'cachalot',
|
|
|
...
|
|
|
]
|
|
|
|
|
|
```
|
|
|
|
|
|
还可以在更细的粒度上,使用Cache API中的get、set等函数,将较为耗时的运算结果存放在缓存中:
|
|
|
|
|
|
```
|
|
|
cache.set('online_user_count', counts, 3600)
|
|
|
user_count = cache.get('online_user_count')
|
|
|
|
|
|
```
|
|
|
|
|
|
这些缓存的应用场景大相径庭,但数据的更新方式却很相似,下面我们来看看缓存是基于哪些原理来更新数据的。
|
|
|
|
|
|
## 缓存数据的更新方式
|
|
|
|
|
|
缓存的存储容量往往小于原始数据集,这有许多原因,比如:
|
|
|
|
|
|
* 缓存使用了速度更快的存储介质,而这类硬件的单位容量更昂贵,因此从经济原因上只能选择更小的存储容量;
|
|
|
* 负载均衡可以将上游服务的动态响应转换为静态缓存,从时间维度上看,上游响应是无限的,这样负载均衡的缓存容量就一定会不足;
|
|
|
* 即使桌面主机的磁盘容量达到了TB级,但浏览器要对用户访问的所有站点做缓存,就不可能缓存一个站点上的全部资源,在一对多的空间维度下,缓存一样是稀缺资源。
|
|
|
|
|
|
因此,我们必须保证在有限的缓存空间内,只存放会被多次访问的热点数据,通过提高命中率来提升系统性能。要完成这个目标,必须精心设计向缓存中添加哪些数据,缓存溢出时淘汰出哪些冷数据。我们先来看前者。
|
|
|
|
|
|
通常,缓存数据的添加或者更新,都是由用户请求触发的,这往往可以带来更高的命中率。比如,当读请求完成后,将读出的内容放入缓存,基于时间局部性原理,它有很高的概率被后续的读请求命中。[\[第15讲\]](https://time.geekbang.org/column/article/242667) 介绍过的HTTP缓存就采用了这种机制。
|
|
|
|
|
|
对于磁盘操作,还可以基于空间局部性原理,采用预读算法添加缓存数据(参考[\[第4讲\]](https://time.geekbang.org/column/article/232676) 介绍的PageCache)。比如当我们统计出连续两次读IO的操作范围也是连续的,就可以判断这是一个顺序读IO,如果这个读IO获取32KB的数据,就可以在这次磁盘中,多读出128KB的数据放在缓存,这会带来2个收益:
|
|
|
|
|
|
* 首先,通过减少定位时间提高了磁盘工作效率。机械磁盘容量大价格低,它的顺序读写速度由磁盘旋转速度与存储密度决定,通常可以达到100MB/s左右。然而,由于机械转速难以提高(服务器磁盘的转速也只有10000转/s),磁头定位与旋转延迟大约消耗了8毫秒,因此对于绝大部分时间花在磁头定位上的随机小IO(比如4KB),读写吞吐量只有几MB。
|
|
|
* 其次,当后续的读请求命中提前读入缓存的数据时,请求时延会大幅度降低,这提升了用户体验。
|
|
|
|
|
|
而且,并不是只有单机进程才能使用预读算法。比如公有云中的云磁盘,之所以可以实时地挂载到任意虚拟机上,就是因为它实际存放在类似HDFS这样的分布式文件系统中。因此,云服务会在宿主物理机的内存中缓存虚拟机发出的读写IO,由于网络传输的成本更高,所以预读效果也更好。
|
|
|
|
|
|
写请求也可以更新缓存,你可以参考[\[第20讲\]](https://time.geekbang.org/column/article/251062) 我们介绍过write through和write back方式。其中,write back采用异步调用回写数据,能通过批量处理提升性能。比如Linux在合并IO的同时,也会像电梯运行一样,每次使磁头仅向一个方向旋转写入数据,提升机械磁盘的工作效率,因此得名为电梯调度算法。
|
|
|
|
|
|
说完数据的添加,我们再来看2种最常见的缓存淘汰算法。
|
|
|
|
|
|
首先来看[FIFO](https://en.wikipedia.org/wiki/FIFO_(computing_and_electronics))(First In, First Out)先入先出淘汰算法。[\[第16讲\]](https://time.geekbang.org/column/article/245966) 介绍的HTTP/2动态表,会将HTTP/2连接上首次出现的HTTP头部,缓存在客户端、服务器的内存中。由于它们基于相同的规则生成,所以拥有相同的动态表序号。这样,传输1-2个字节的表序号,要比传输几十个字节的头部划算得多。当内存容量超过SETTINGS\_HEADER\_TABLE\_SIZE阈值时,会基于FIFO算法将最早缓存的HTTP头部淘汰出动态表。
|
|
|
|
|
|
[")](https://en.wikipedia.org/wiki/FIFO_(computing_and_electronics))
|
|
|
|
|
|
再比如[\[第14讲\]](https://time.geekbang.org/column/article/241632) 介绍的TLS握手很耗时,所以我们可以将密钥缓存在客户端、服务器中,等再次建立连接时,通过session ID迅速恢复TLS会话。由于内存有限,服务器必须及时淘汰过期的密钥,其中,Nginx也是采用FIFO队列淘汰TLS缓存的。
|
|
|
|
|
|
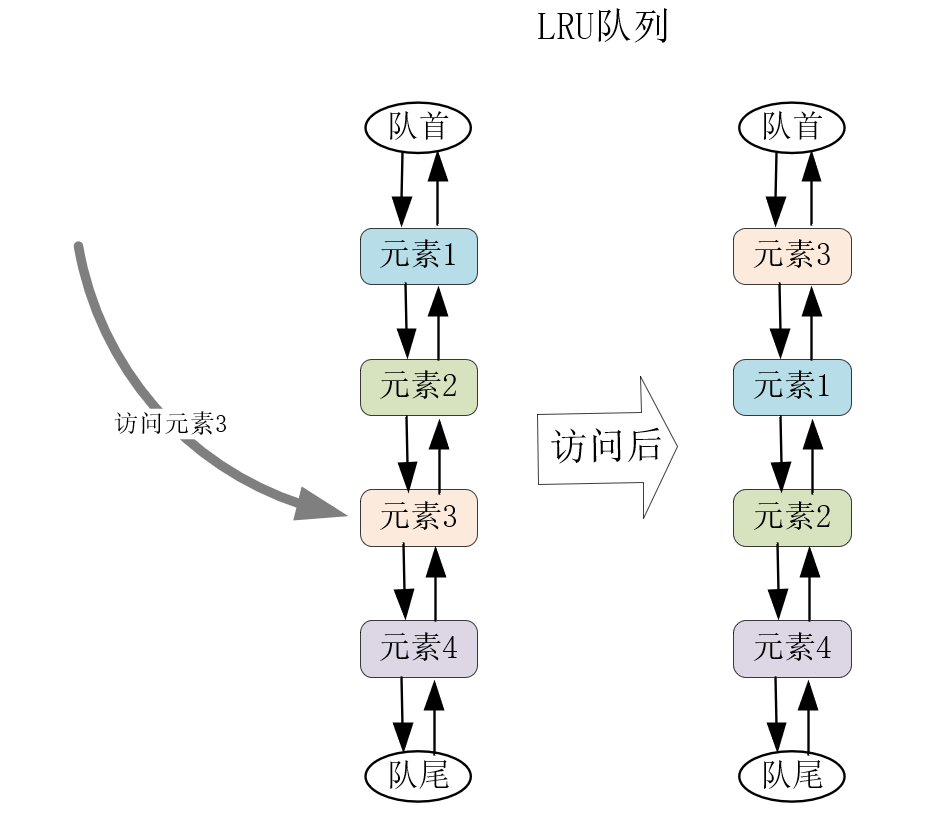
其次,LRU(Less Recently Used)也是最常用的淘汰算法,比如Redis服务就通过它来淘汰数据,OpenResty在进程间共享数据的shared\_dict在达到共享内存最大值后,也会通过LRU算法淘汰数据。LRU通常使用双向队列实现(时间复杂度为O(1)),队首是最近访问的元素,队尾就是最少访问、即将淘汰的元素。当访问了队列中某个元素时,可以将其移动到队首。当缓存溢出需要淘汰元素时,直接删除队尾元素,如下所示:
|
|
|
|
|
|
|
|
|
|
|
|
以上我只谈了缓存容量到达上限后的淘汰策略,为了避免缓存与源数据不一致,在传输成本高昂的分布式系统中,通常会基于过期时间来淘汰缓存。比如HTTP响应中的Cache-Control、Expires或者Last-Modified头部,都会用来设置定时器,响应过期后会被淘汰出缓存。然而,一旦热点数据被淘汰出缓存,那么来自用户的流量就会穿透缓存到达应用服务。由于缓存服务性能远大于应用服务,过大的流量很可能会将应用压垮。因此,过期缓存并不能简单地淘汰,下面我们以Nginx为例,看看如何利用过期缓存提升系统的可用性。
|
|
|
|
|
|
## Nginx是如何防止流量打穿缓存的?
|
|
|
|
|
|
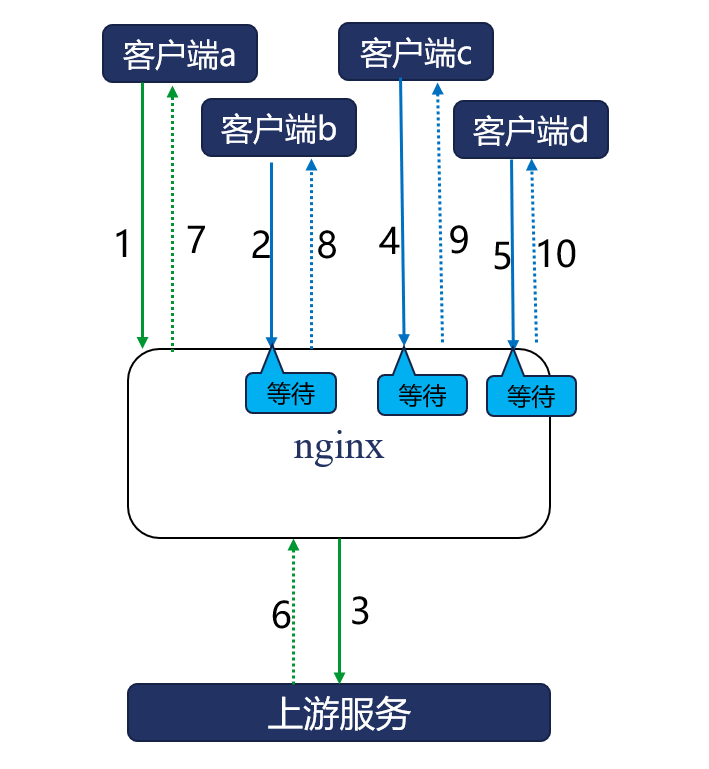
当热点缓存淘汰后,大量的并发请求会同时回源上游应用,其实这是不必要的。比如下图中Nginx的合并回源功能开启后,Nginx会将多个并发请求合并为1条回源请求,并锁住所有的客户端请求,直到回源请求返回后,才会更新缓存,同时向所有客户端返回响应。由于Nginx可以支持C10M级别的并发连接,因此可以很轻松地锁住这些并发请求,降低应用服务的负载。
|
|
|
|
|
|
|
|
|
|
|
|
启用合并回源功能很简单,只需要在nginx.conf中添加下面这条指令即可:
|
|
|
|
|
|
```
|
|
|
proxy_cache_lock on;
|
|
|
|
|
|
```
|
|
|
|
|
|
当1个请求回源更新时,其余请求将会默认等待,如果5秒(可由proxy\_cache\_lock\_timeout修改)后缓存依旧未完成更新,这些请求也会回源,但它们的响应不会用于更新缓存。同时,第1个回源请求也有时间限制,如果到达5秒(可由proxy\_cache\_lock\_age修改)后未获得响应,就会放行其他并发请求回源更新缓存。
|
|
|
|
|
|
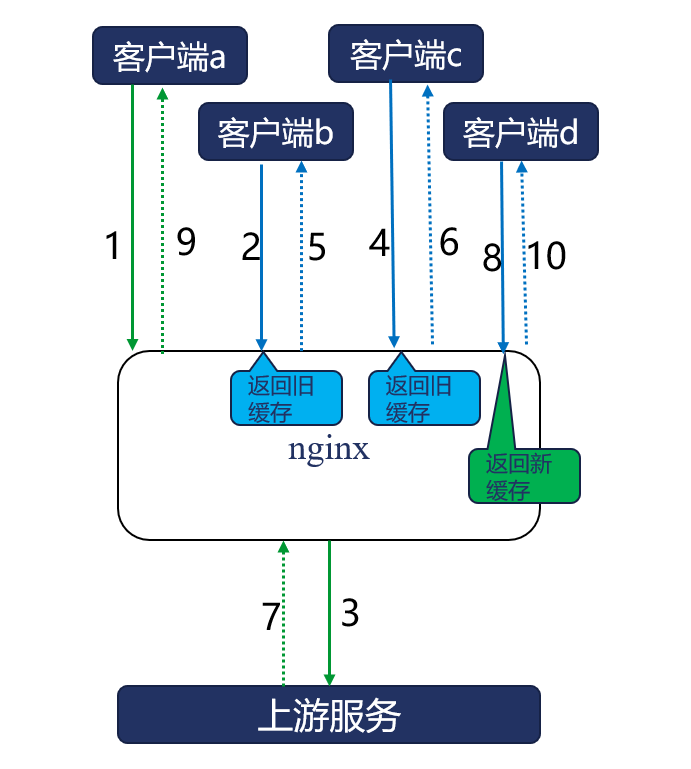
如果Nginx上的缓存已经过期(未超过proxy\_cache\_path中inactive时间窗口的过期缓存,并不会被删除),且上游服务此时已不可用,那有没有办法可以通过Nginx提供降级服务呢?所谓“服务降级”,是指部分服务出现故障后,通过有策略地放弃一些可用性,来保障核心服务的运行,这也是[\[第20讲\]](https://time.geekbang.org/column/article/251062) BASE理论中Basically Available的实践。如果Nginx上持有着过期的缓存,那就可以通过牺牲一致性,向用户返回过期缓存,以保障基本的可用性。比如下图中,Nginx会直接将过期缓存返回给客户端,同时也会一直试图更新缓存。
|
|
|
|
|
|
|
|
|
|
|
|
开启过期缓存功能也很简单,添加下面2行指令即可:
|
|
|
|
|
|
```
|
|
|
proxy_cache_use_stale updating;
|
|
|
proxy_cache_background_update on;
|
|
|
|
|
|
```
|
|
|
|
|
|
当然,上面两条Nginx指令只是开启了最基本的功能,如果你想进一步了解它们的用法,可以观看[《Nginx核心知识100讲》第102课](https://time.geekbang.org/course/detail/100020301-76629)。
|
|
|
|
|
|
## 小结
|
|
|
|
|
|
这一讲我们系统地总结了缓存的工作原理,以及Nginx解决缓存穿透问题的方案。
|
|
|
|
|
|
当组件间的访问速度差距很大时,直接访问会降低整体性能,在二者之间添加更快的缓存是常用的解决方案。根据时间局部性原理,将请求结果放入缓存,会有很大概率被再次命中,而根据空间局部性原理,可以将相邻的内容预取至缓存中,这样既能通过批处理提升效率,也能降低后续请求的时延。
|
|
|
|
|
|
由于缓存容量小于原始数据集,因此需要将命中概率较低的数据及时淘汰出去。其中最常用的淘汰算法是FIFO与LRU,它们执行的时间复杂度都是O(1),效率很高。
|
|
|
|
|
|
由于缓存服务的性能远大于上游应用,一旦大流量穿透失效的缓存到达上游后,就可能压垮应用。Nginx作为HTTP缓存使用时,可以打开合并回源功能,减轻上游压力。在上游应用宕机后,还可以使用过期缓存为用户提供降级服务。
|
|
|
|
|
|
## 思考题
|
|
|
|
|
|
最后,留给你一道讨论题。缓存并不总是在提高性能,回想一下,在你的实践中,有哪些情况是增加了缓存服务,但并没有提高系统性能的?原因又是什么?欢迎你在留言区与大家一起分享。
|
|
|
|
|
|
感谢阅读,如果你觉得这节课让你加深了对缓存的理解,也欢迎把它分享给你的朋友。
|
|
|
|