134 lines
13 KiB
Markdown
134 lines
13 KiB
Markdown
# 02 | 内存池:如何提升内存分配的效率?
|
||
|
||
你好,我是陶辉。
|
||
|
||
上一讲我们提到,高频地命中CPU缓存可以提升性能。这一讲我们把关注点从CPU转移到内存,看看如何提升内存分配的效率。
|
||
|
||
或许有同学会认为,我又不写底层框架,内存分配也依赖虚拟机,并不需要应用开发者了解。如果你也这么认为,我们不妨看看这个例子:在Linux系统中,用Xmx设置JVM的最大堆内存为8GB,但在近百个并发线程下,观察到Java进程占用了14GB的内存。为什么会这样呢?
|
||
|
||
这是因为,绝大部分高级语言都是用C语言编写的,包括Java,申请内存必须经过C库,而C库通过预分配更大的空间作为内存池,来加快后续申请内存的速度。这样,预分配的6GB的C库内存池就与JVM中预分配的8G内存池叠加在一起,造成了Java进程的内存占用超出了预期。
|
||
|
||
掌握内存池的特性,既可以避免写程序时内存占用过大,导致服务器性能下降或者进程OOM(Out Of Memory,内存溢出)被系统杀死,还可以加快内存分配的速度。在系统空闲时申请内存花费不了多少时间,但是对于分布式环境下繁忙的多线程服务,获取内存的时间会上升几十倍。
|
||
|
||
另一方面,内存池是非常底层的技术,当我们理解它后,可以更换适合应用场景的内存池。在多种编程语言共存的分布式系统中,内存池有很广泛的应用,优化内存池带来的任何微小的性能提升,都将被分布式集群巨大的主机规模放大,从而带来整体上非常可观的收益。
|
||
|
||
接下来,我们就通过对内存池的学习,看看如何提升内存分配的效率。
|
||
|
||
## 隐藏的内存池
|
||
|
||
实际上,在你的业务代码与系统内核间,往往有两层内存池容易被忽略,尤其是其中的C库内存池。
|
||
|
||
当代码申请内存时,首先会到达应用层内存池,如果应用层内存池有足够的可用内存,就会直接返回给业务代码,否则,它会向更底层的C库内存池申请内存。比如,如果你在Apache、Nginx等服务之上做模块开发,这些服务中就有独立的内存池。当然,Java中也有内存池,当通过启动参数Xmx指定JVM的堆内存为8GB时,就设定了JVM堆内存池的大小。
|
||
|
||
你可能听说过Google的TCMalloc和FaceBook的JEMalloc,它们也是C库内存池。当C库内存池无法满足内存申请时,才会向操作系统内核申请分配内存。如下图所示:
|
||
|
||
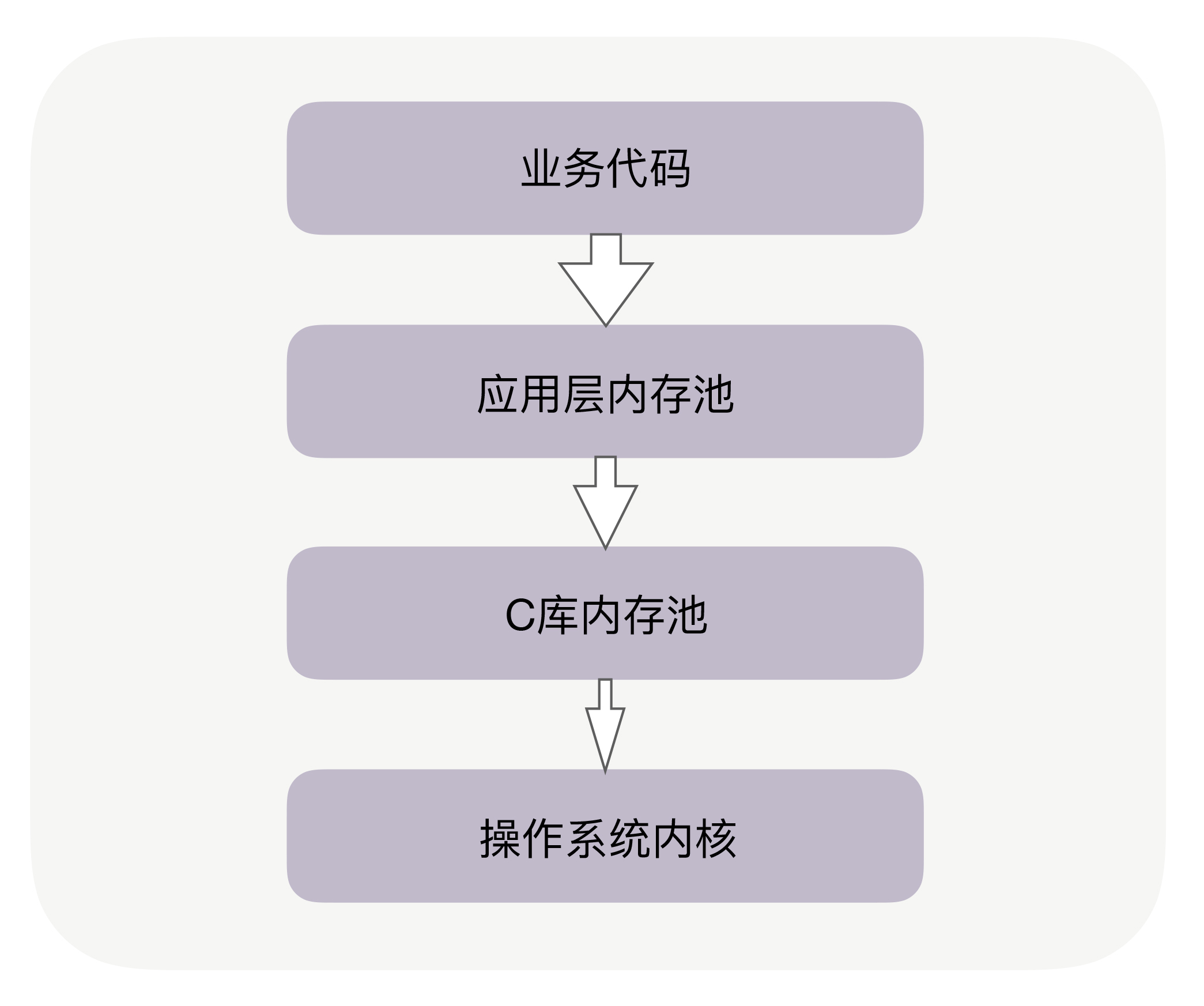
|
||
|
||
回到文章开头的问题,Java已经有了应用层内存池,为什么还会受到C库内存池的影响呢?这是因为,除了JVM负责管理的堆内存外,Java还拥有一些堆外内存,由于它不使用JVM的垃圾回收机制,所以更稳定、持久,处理IO的速度也更快。这些堆外内存就会由C库内存池负责分配,这是Java受到C库内存池影响的原因。
|
||
|
||
其实不只是Java,几乎所有程序都在使用C库内存池分配出的内存。C库内存池影响着系统下依赖它的所有进程。我们就以Linux系统的默认C库内存池Ptmalloc2来具体分析,看看它到底对性能发挥着怎样的作用。
|
||
|
||
C库内存池工作时,会预分配比你申请的字节数更大的空间作为内存池。比如说,当主进程下申请1字节的内存时,Ptmalloc2会预分配132K字节的内存(Ptmalloc2中叫Main Arena),应用代码再申请内存时,会从这已经申请到的132KB中继续分配。
|
||
|
||
如下所示(你可以在[这里](https://github.com/russelltao/geektime_distrib_perf/tree/master/2-memory/alloc_address)找到示例程序,注意地址的单位是16进制):
|
||
|
||
```
|
||
# cat /proc/2891/maps | grep heap
|
||
01643000-01664000 rw-p 00000000 00:00 0 [heap]
|
||
|
||
```
|
||
|
||
当我们释放这1字节时,Ptmalloc2也不会把内存归还给操作系统。Ptmalloc2认为,与其把这1字节释放给操作系统,不如先缓存着放进内存池里,仍然当作用户态内存留下来,进程再次申请1字节的内存时就可以直接复用,这样速度快了很多。
|
||
|
||
你可能会想,132KB不多呀?为什么这一讲开头提到的Java进程,会被分配了几个GB的内存池呢?这是因为**多线程与单线程的预分配策略并不相同**。
|
||
|
||
每个**子线程预分配的内存是64MB**(Ptmalloc2中被称为Thread Arena,32位系统下为1MB,64位系统下为64MB)。如果有100个线程,就将有6GB的内存都会被内存池占用。当然,并不是设置了1000个线程,就会预分配60GB的内存,子线程内存池最多只能到8倍的CPU核数,比如在32核的服务器上,最多只会有256个子线程内存池,但这也非常夸张了,16GB(64MB \* 256 = 16GB)的内存将一直被Ptmalloc2占用。
|
||
|
||
回到本文开头的问题,Linux下的JVM编译时默认使用了Ptmalloc2内存池,因此每个线程都预分配了64MB的内存,这造成含有上百个Java线程的JVM多使用了6GB的内存。在多数情况下,这些预分配出来的内存池,可以提升后续内存分配的性能。
|
||
|
||
然而,Java中的JVM内存池已经管理了绝大部分内存,确实不能接受莫名多出来6GB的内存,那该怎么办呢?既然我们知道了Ptmalloc2内存池的存在,就有两种解决办法。
|
||
|
||
首先可以调整Ptmalloc2的工作方式。**通过设置MALLOC\_ARENA\_MAX环境变量,可以限制线程内存池的最大数量**,当然,线程内存池的数量减少后,会影响Ptmalloc2分配内存的速度。不过由于Java主要使用JVM内存池来管理对象,这点影响并不重要。
|
||
|
||
其次可以更换掉Ptmalloc2内存池,选择一个预分配内存更少的内存池,比如Google的TCMalloc。
|
||
|
||
这并不是说Google出品的TCMalloc性能更好,而是在特定的场景中的选择不同。而且,盲目地选择TCMalloc很可能会降低性能,否则Linux系统早把默认的内存池改为TCMalloc了。
|
||
|
||
TCMalloc和Ptmalloc2是目前最主流的两个内存池,接下来我带你通过对比TCMalloc与Ptmalloc2内存池,看看到底该如何选择内存池。
|
||
|
||
## 选择Ptmalloc2还是TCMalloc?
|
||
|
||
先来看TCMalloc适用的场景,**它对多线程下小内存的分配特别友好。**
|
||
|
||
比如,在2GHz的CPU上分配、释放256K字节的内存,Ptmalloc2耗时32纳秒,而TCMalloc仅耗时10纳秒(测试代码参见[这里](https://github.com/russelltao/geektime_distrib_perf/tree/master/2-memory/benchmark))。**差距超过了3倍,为什么呢?**这是因为,Ptmalloc2假定,如果线程A申请并释放了的内存,线程B可能也会申请类似的内存,所以它允许内存池在线程间复用以提升性能。
|
||
|
||
因此,每次分配内存,Ptmalloc2一定要加锁,才能解决共享资源的互斥问题。然而,加锁的消耗并不小。如果你监控分配速度的话,会发现单线程服务调整为100个线程,Ptmalloc2申请内存的速度会变慢10倍。TCMalloc针对小内存做了很多优化,每个线程独立分配内存,无须加锁,所以速度更快!
|
||
|
||
而且,**线程数越多,Ptmalloc2出现锁竞争的概率就越高。**比如我们用40个线程做同样的测试,TCMalloc只是从10纳秒上升到25纳秒,只增长了1.5倍,而Ptmalloc2则从32纳秒上升到137纳秒,增长了3倍以上。
|
||
|
||
下图是TCMalloc作者给出的性能测试数据,可以看到线程数越多,二者的速度差距越大。所以,**当应用场景涉及大量的并发线程时,换成TCMalloc库也更有优势!**
|
||
|
||

|
||
|
||
那么,为什么GlibC不把默认的Ptmalloc2内存池换成TCMalloc呢?**因为Ptmalloc2更擅长大内存的分配。**
|
||
|
||
比如,单线程下分配257K字节的内存,Ptmalloc2的耗时不变仍然是32纳秒,但TCMalloc就由10纳秒上升到64纳秒,增长了5倍以上!**现在TCMalloc反过来比Ptmalloc2慢了1倍!**这是因为TCMalloc特意针对小内存做了优化。
|
||
|
||
多少字节叫小内存呢?TCMalloc把内存分为3个档次,小于等于256KB的称为小内存,从256KB到1M称为中等内存,大于1MB的叫做大内存。TCMalloc对中等内存、大内存的分配速度很慢,比如我们用单线程分配2M的内存,Ptmalloc2耗时仍然稳定在32纳秒,但TCMalloc已经上升到86纳秒,增长了7倍以上。
|
||
|
||
所以,**如果主要分配256KB以下的内存,特别是在多线程环境下,应当选择TCMalloc;否则应使用Ptmalloc2,它的通用性更好。**
|
||
|
||
## 从堆还是栈上分配内存?
|
||
|
||
不知道你发现没有,刚刚讨论的内存池中分配出的都是堆内存,如果你把在堆中分配的对象改为在栈上分配,速度还会再快上1倍(具体测试代码可以在[这里](https://github.com/russelltao/geektime_distrib_perf/tree/master/2-memory/benchmark)找到)!为什么?
|
||
|
||
可能有同学还不清楚堆和栈内存是如何分配的,我先简单介绍一下。
|
||
|
||
如果你使用的是静态类型语言,那么,不使用new关键字分配的对象大都是在栈中的。比如:
|
||
|
||
```
|
||
C/C++/Java语言:int a = 10;
|
||
|
||
```
|
||
|
||
否则,通过new或者malloc关键字分配的对象则是在堆中的:
|
||
|
||
```
|
||
C语言:int * a = (int*) malloc(sizeof(int));
|
||
C++语言:int * a = new int;
|
||
Java语言:int a = new Integer(10);
|
||
|
||
```
|
||
|
||
另外,对于动态类型语言,无论是否使用new关键字,内存都是从堆中分配的。
|
||
|
||
了解了这一点之后,我们再来看看,为什么从栈中分配内存会更快。
|
||
|
||
这是因为,由于每个线程都有独立的栈,所以分配内存时不需要加锁保护,而且栈上对象的尺寸在编译阶段就已经写入可执行文件了,执行效率更高!性能至上的Golang语言就是按照这个逻辑设计的,即使你用new关键字分配了堆内存,但编译器如果认为在栈中分配不影响功能语义时,会自动改为在栈中分配。
|
||
|
||
当然,在栈中分配内存也有缺点,它有功能上的限制。一是, 栈内存生命周期有限,它会随着函数调用结束后自动释放,在堆中分配的内存,并不随着分配时所在函数调用的结束而释放,它的生命周期足够使用。二是,栈的容量有限,如CentOS 7中是8MB字节,如果你申请的内存超过限制会造成栈溢出错误(比如,递归函数调用很容易造成这种问题),而堆则没有容量限制。
|
||
|
||
**所以,当我们分配内存时,如果在满足功能的情况下,可以在栈中分配的话,就选择栈。**
|
||
|
||
## 小结
|
||
|
||
最后我们对这一讲做个小结。
|
||
|
||
进程申请内存的速度,以及总内存空间都受到内存池的影响。知道这些隐藏内存池的存在,是提升分配内存效率的前提。
|
||
|
||
隐藏着的C库内存池,对进程的内存开销有很大的影响。当进程的占用空间超出预期时,你需要清楚你正在使用的是什么内存池,它对每个线程预分配了多大的空间。
|
||
|
||
不同的C库内存池,都有它们最适合的应用场景,例如TCMalloc对多线程下的小内存分配特别友好,而Ptmalloc2则对各类尺寸的内存申请都有稳定的表现,更加通用。
|
||
|
||
内存池管理着堆内存,它的分配速度比不上在栈中分配内存。只是栈中分配的内存受到生命周期和容量大小的限制,应用场景更为有限。然而,如果有可能的话,尽量在栈中分配内存,它比内存池中的堆内存分配速度快很多!
|
||
|
||
OK,今天我们从内存分配的角度聊了分布式系统性能提升的内容,希望学习过今天的内容后,你知道如何最快速地申请到内存,了解你正在使用的内存池,并清楚它对进程最终内存大小的影响。即使对第三方组件,我们也可以通过LD\_PRELOAD环境变量,在程序启动时更换最适合的C库内存池(Linux中通过LD\_PRELOAD修改动态库来更换内存池,参见[示例代码](https://github.com/russelltao/geektime_distrib_perf/tree/master/2-memory/benchmark))。
|
||
|
||
内存分配时间虽然不起眼,但时刻用最快的方法申请内存,正是高手与初学者的区别,相似算法的性能差距就体现在这些编码细节上,希望你能够重视它。
|
||
|
||
## 思考题
|
||
|
||
最后,留给你一个思考题。分配对象时,除了分配内存,还需要初始化对象的数据结构。内存池对于初始化对象有什么帮助吗?欢迎你在留言区与大家一起探讨。
|
||
|
||
感谢阅读,如果你觉得这节课对你有一些启发,也欢迎把它分享给你的朋友。
|
||
|