211 lines
14 KiB
Markdown
211 lines
14 KiB
Markdown
# 43 | PCA主成分分析(下):为什么要计算协方差矩阵的特征值和特征向量?
|
||
|
||
你好,我是黄申,今天我们继续来聊PCA主成分分析的下半部分。
|
||
|
||
上一节,我们讲解了一种特征降维的方法:PCA主成分分析。这个方法主要是利用不同维度特征之间的协方差,构造一个协方差矩阵,然后获取这个矩阵的特征值和特征向量。根据特征值的大小,我们可以选取那些更为重要的特征向量,或者说主成分。最终,根据这些主成分,我们就可以对原始的数据矩阵进行降维。
|
||
|
||
PCA方法的操作步骤有些繁琐,并且背后的理论支持也不是很直观,因此对于初学者来说并不好理解。考虑到这些,我今天会使用一个具体的矩阵示例,详细讲解每一步操作的过程和结果,并辅以基于Python的核心代码进行分析验证。除此之外,我还会从多个角度出发,分析PCA方法背后的理论,帮助你进一步的理解和记忆。
|
||
|
||
## 基于Python的案例分析
|
||
|
||
这么说可能有一些抽象,让我使用一个具体的案例来帮你理解。假设我们有一个样本集合,包含了3个样本,每个样本有3维特征$x\_1$,$x\_2$和$x\_3$。
|
||
|
||
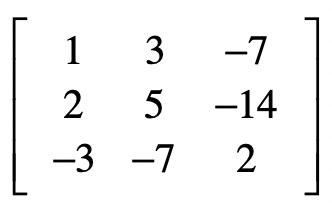
|
||
|
||
在标准化的时候,需要注意的是,我们的分母都使用m而不是m-1,这是为了和之后Python中sklearn库的默认实现保持一致。
|
||
|
||
首先需要获取标准化之后的数据。
|
||
|
||
第一维特征的数据是1,2,-3。平均值是0,方差是
|
||
|
||
$\\sqrt{\\frac{1+4+9}{3}}≈2.16$
|
||
|
||
标准化之后第一维特征的数据是1/2.16=0.463,2/2.16=0.926,-3/2.16=-1.389。以此类推,我们可以获得第二个维度和第三个维度标准化之后的数据。
|
||
|
||
当然,全部手动计算工作量不小,这时可以让计算机做它擅长的事情:重复性计算。下面的Python代码展示了如何对样本矩阵的数据进行标准化。
|
||
|
||
```
|
||
from numpy import *
|
||
from numpy import linalg as LA
|
||
from sklearn.preprocessing import scale
|
||
|
||
# 原始数据,包含了3个样本和3个特征,每一行表示一个样本,每一列表示一维特征
|
||
x = mat([[1,3,-7],[2,5,-14],[-3,-7,2]])
|
||
|
||
# 矩阵按列进行标准化
|
||
x_s = scale(x, with_mean=True, with_std=True, axis=0)
|
||
print("标准化后的矩阵:", x_s)
|
||
|
||
```
|
||
|
||
其中,scale函数使用了axis=0,表示对列进行标准化,因为目前的矩阵排列中,每一列代表一个特征维度,这点需要注意。如果矩阵排列中每一行代表一个特征维度,那么可以使用axis=1对行进行标准化。
|
||
|
||
最终标准化之后的矩阵是这样的:
|
||
|
||
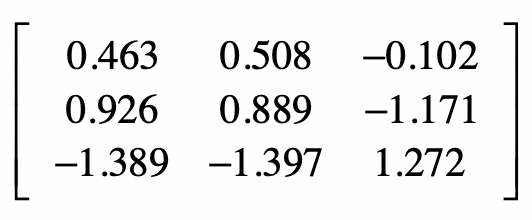
|
||
|
||
接下来是协方差的计算。对于第1维向量的方差,有
|
||
|
||
$\\frac{0.463^2 +0.926^2+(-1.389^2)}{2}≈1.5$
|
||
|
||
第1维和第2维向量之间的协方差是
|
||
|
||
$\\frac{0.463×0.508+0.926×0.889+(-1.389)×(-1.397)}{2}≈1.5$
|
||
|
||
以此类推,我们就可以获得完整的协方差矩阵。同样的,为了减少推算的工作量,我们可以使用Python代码获得协方差矩阵。
|
||
|
||
```
|
||
# 计算协方差矩阵,注意这里需要先进行转置,因为这里的函数是看行与行之间的协方差
|
||
x_cov = cov(x_s.transpose())
|
||
# 输出协方差矩阵
|
||
print("协方差矩阵:\n", x_cov, "\n")
|
||
|
||
```
|
||
|
||
和sklearn中的标准化函数scale有所不同,numpy中的协方差函数cov除以的是(m-1),而不是m。最终完整的协方差矩阵是:
|
||
|
||
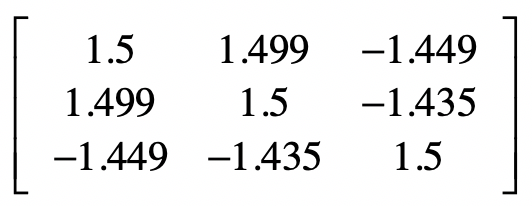
|
||
|
||
然后,我们要求解协方差矩阵的特征值和特征向量。
|
||
|
||
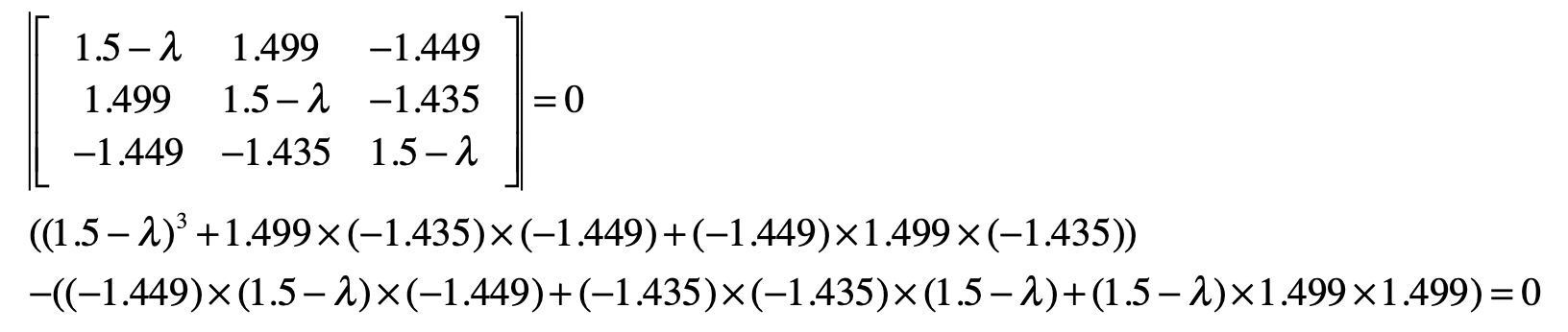
|
||
|
||
最后化简为:
|
||
|
||
$-λ^3+4.5λ^2=0.343λ=0$
|
||
$λ(0.0777-λ)(λ-4.4223)=0$
|
||
|
||
所以$λ$有3个近似解,分别是0、0.0777和4.4223。
|
||
|
||
特征向量的求解过程如果手动推算比较繁琐,我们还是利用Python语言直接求出特征值和对应的特征向量。
|
||
|
||
```
|
||
# 求协方差矩阵的特征值和特征向量
|
||
eigVals,eigVects = LA.eig(x_cov)
|
||
print("协方差矩阵的特征值:", eigVals)
|
||
print("协方差的特征向量(主成分):\n", eigVects, "\n")
|
||
|
||
```
|
||
|
||
我们可以得到三个特征值及它们对应的特征向量。
|
||
|
||
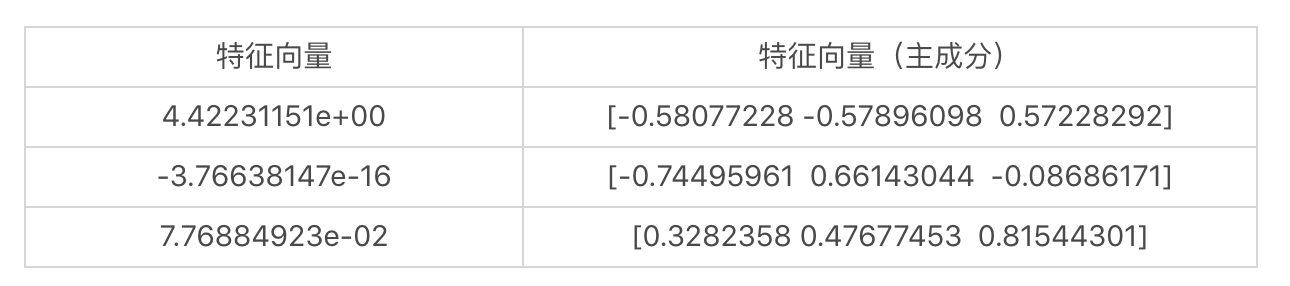
|
||
|
||
需要注意,Python代码输出的特征向量是列向量,而我表格中列出的是行向量。
|
||
|
||
我使用下面的这段代码,找出特征值最大的特征向量,也就是最重要的主成分,然后利用这个主成分,对原始的样本矩阵进行变换。
|
||
|
||
```
|
||
# 找到最大的特征值,及其对应的特征向量
|
||
max_eigVal = -1
|
||
max_eigVal_index = -1
|
||
|
||
for i in range(0, eigVals.size):
|
||
if (eigVals[i] > max_eigVal):
|
||
max_eigVal = eigVals[i]
|
||
max_eigVal_index = i
|
||
|
||
eigVect_with_max_eigVal = eigVects[:,max_eigVal_index]
|
||
|
||
# 输出最大的特征值及其对应的特征向量,也就是第一个主成分
|
||
print("最大的特征值:", max_eigVal)
|
||
print("最大特征值所对应的特征向量:", eigVect_with_max_eigVal)
|
||
|
||
# 输出变换后的数据矩阵。注意,这里的三个值是表示三个样本,而特征从3维变为1维了。
|
||
print("变换后的数据矩阵:", x_s.dot(eigVect_with_max_eigVal), "\n")
|
||
|
||
```
|
||
|
||
很明显,最大的特征值是4.422311507725755,对应的特征向量是\[-0.58077228 -0.57896098 0.57228292\]。变换后的样本矩阵是:
|
||
|
||

|
||
它从原来的3个特征维度降为1个特征维度了。
|
||
|
||
Python的sklearn库也实现了PCA,我们可以通过下面的代码来尝试一下。
|
||
|
||
```
|
||
from sklearn.decomposition import PCA
|
||
|
||
# 挑选前2个主成分
|
||
pca = PCA(n_components=2)
|
||
|
||
# 进行PCA分析
|
||
pca.fit(x_s)
|
||
|
||
# 输出变换后的数据矩阵。注意,这里的三个值是表示三个样本,而特征从3维变为1维了。
|
||
print("方差(特征值): ", pca.explained_variance_)
|
||
print("主成分(特征向量)", pca.components_)
|
||
print("变换后的样本矩阵:", pca.transform(x_s))
|
||
print("信息量: ", pca.explained_variance_ratio_)
|
||
|
||
```
|
||
|
||
这段代码中,我把输出的主成分设置为2,也就是说挑出前2个最重要的主成分。相应的,变化后的样本矩阵有2个特征维度。
|
||
|
||
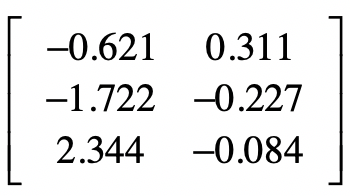
|
||
|
||
除了输出主成分和变换后的矩阵,sklearn的PCA分析还提供了信息量的数据。
|
||
|
||
```
|
||
信息量: [0.98273589 0.01726411]
|
||
|
||
```
|
||
|
||
它是各个主成分的方差所占的比例,表示第一个主成分包含了原始样本矩阵中的98.27%的信息,而第二个主成分包含了原始样本矩阵中的1.73%的信息,可想而知,最后一个主成分提供的信息量基本为0了,我们可以忽略不计了。如果我们觉得95%以上的信息量就足够了,那么就可以只保留第一个主成分,把原始的样本矩阵的特征维度降到1维。
|
||
|
||
当然,学习的更高境界,不是仅仅“知其然”,还要做到“知其所以然”。即使现在你对PCA的操作步骤了如指掌,可能还是有不少疑惑,比如,为什么我们要使用协方差矩阵?这个矩阵的特征值和特征向量又表示什么?为什么选择特征值最大的主成分,就能涵盖最多的信息量呢?不用着急,接下来,我会给你做出更透彻的解释,让你不仅明白如何进行PCA分析,同时还明白为什么要这么做。
|
||
|
||
## PCA背后的核心思想
|
||
|
||
### 为什么要使用协方差矩阵?
|
||
|
||
首先要回答的第一个问题是,为什么我们要使用样本数据中,各个维度之间的协方差,来构建一个新的协方差矩阵?要弄清楚这一点,首先要回到PCA最终的目标:降维。降维就是要去除那些表达信息量少,或者冗余的维度。
|
||
|
||
我们首先来看如何定义维度的信息量大小。这里我们认为样本在某个特征上的差异就越大,那么这个特征包含的信息量就越大,就越重要。相反,信息量就越小,需要被过滤掉。很自然,我们就能想到使用某维特征的方差来定义样本在这个特征维度上的差异。
|
||
|
||
另一方面,我们要看如何发现冗余的信息。如果两种特征是有很高的相关性,那我们可以从一个维度的值推算出另一个维度的值,所表达的信息就是重复的。在概率和统计模块,我介绍过多个变量间的相关性,而在实际运用中,我们可以使用皮尔森(Pearson)相关系数,来描述两个变量之间的线性相关程度。这个系数的取值范围是$\[-1,1\]$,绝对值越大,说明相关性越高,正数表示正相关,负数表示负相关。
|
||
|
||
我使用下面这张图,来表示正相关和负相关的含义。左侧$X$曲线和$Y$曲线有非常近似的变化趋势,当$X$上升$Y$往往也是上升的,$X$下降$Y$往往也下降,这表示两者有较强的正相关性。右侧$X$和$Y$两者相反,当$X$上升的时候,$Y$往往是下降的,$X$下降的时候,$Y$往往是上升,这表示两者有较强的负相关性。
|
||
|
||
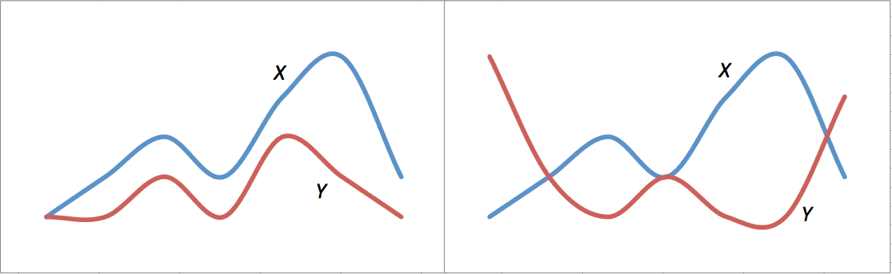
|
||
|
||
皮尔森系数计算公式如下:
|
||
|
||

|
||
|
||
其中$n$表示向量维度,$x\_{k,i}$和$x\_{k,j}$分别为两个特征维度$i$和$j$在第$k$个采样上的数值。 $\\bar{x\_{,i}}$和$\\bar{x\_{,j}}$分别表示两个特征维度上所有样本的均值,$σx$和$σy$分别表示两个特征维度上所有样本的标准差。
|
||
|
||
我把皮尔森系数的公式稍加变化,你来观察一下皮尔森系数和协方差之间的关系。
|
||
|
||

|
||
|
||
你看,变换后的分子不就是协方差吗?而分母类似于标准化数据中的分母。所以在本质上,皮尔森相关系数和数据标准化后的协方差是一致的。
|
||
|
||
考虑到协方差既可以衡量信息量的大小,也可以衡量不同维度之间的相关性,因此我们就使用各个维度之间的协方差所构成的矩阵,作为PCA分析的对象。就如前面所讲述的,这个协方差矩阵主对角线上的元素是各维度上的方差,也就体现了信息量,而其他元素是两两维度间的协方差,也就体现了相关性。
|
||
|
||
既然协方差矩阵提供了我们所需要的方差和相关性,那么下一步,我们就要考虑对这个矩阵进行怎样的操作了。
|
||
|
||
### 为什么要计算协方差矩阵的特征值和特征向量?
|
||
|
||
关于这点,我们可以从两个角度来理解。
|
||
|
||
第一个角度是对角矩阵。所谓对角矩阵,就是说只有矩阵主对角线之上的元素有非0值,而其他元素的值都为0。我们刚刚解释了协方差矩阵的主对角线上,都是表示信息量的方差,而其他元素都是表示相关性的协方差。既然我们希望尽可能保留大信息量的维度,而去除相关的维度,那么就意味着我们希望对协方差进行对角化,尽可能地使得矩阵只有主对角线上有非0元素。
|
||
|
||
假如我们确实可以把矩阵尽可能地对角化,那么对角化之后的矩阵,它的主对角线上元素就是、或者接近矩阵的特征值,而特征值本身又表示了转换后的方差,也就是信息量。而此时,对应的各个特征向量之间是基本正交的,也就是相关性极低甚至没有相关性。
|
||
|
||
第二个角度是特征值和特征向量的几何意义。在向量空间中,对某个向量左乘一个矩阵,实际上是对这个向量进行了一次变换。在这个变换的过程中,被左乘的向量主要发生旋转和伸缩这两种变化。如果左乘矩阵对某一个向量或某些向量只发生伸缩变换,不对这些向量产生旋转的效果,那么这些向量就称为这个矩阵的特征向量,而伸缩的比例就是特征值。换句话来说,某个矩阵的特征向量表示了这个矩阵在空间中的变换方向,这些方向都是趋于正交的,而特征值表示每个方向上伸缩的比例。
|
||
|
||
如果一个特征值很大,那么说明在对应的特征向量所表示的方向上,伸缩幅度很大。这也是为什么,我们需要使用原始的数据去左乘这个特征向量,来获取降维后的新数据。因为这样做可以帮助我们找到一个方向,让它最大程度地包含原有的信息。需要注意的是,这个新的方向,往往不代表原始的特征,而是多个原始特征的组合和缩放。
|
||
|
||
## 小结
|
||
|
||
这两节,我详细讲解了PCA主成分分析法,它是一种针对数值型特征、较为通用的降维方法。和特征选择不同,它并不需要监督式学习中的样本标签,而是从不同维度特征之间的关系出发,进行了一系列的操作和分析。主要步骤包括,标准化原始的数据矩阵、构建协方差矩阵、计算这种协方差矩阵的特征值和特征向量、挑选较大特征值所对应的特征向量、进行原始特征数据的转换。如果排名靠前的特征向量,或者说主成分,已经包括了足够的信息量,那么我们就可以通过选择较少的主成分,对原始的样本矩阵进行转换,从而达到降维的目的。
|
||
|
||
PCA方法一开始不是很好理解,其主要的原因之一是它背后的核心思想并不是很直观。为此,我详细解释了为什么PCA会从标准化和协方差入手来构建协方差矩阵。对于同类的特征来说,标准化之后的协方差就是方差,表示了这一维特征所包含的信息量。而对于不同类的特征来说,标准化之后的协方差体现了这两维特征的相关性。鉴于这两个特性,我们需要求解协方差矩阵的特征值和特征向量。如果你弄清楚了这几个关键点,那么PCA方法也就不难理解了。
|
||
|
||
## 思考题
|
||
|
||
到目前为止,我们讲解了两种特征降维的方法。第一,在监督式学习中,基于分类标签的特征选择;第二,基于特征协方差矩阵的PCA主成分分析。请尝试从你自己的理解,来说说这两种降维方法各自的优缺点。
|
||
|
||
欢迎留言和我分享,也欢迎你在留言区写下今天的学习笔记。你可以点击“请朋友读”,把今天的内容分享给你的好友,和他一起精进。
|
||
|