|
|
# 33 | 编译原理(中):Vue Compiler模块全解析
|
|
|
|
|
|
你好,我是大圣。
|
|
|
|
|
|
上一讲我带你手写了一个迷你的Vue compiler,还学习了编译原理的基础知识。通过实现这个迷你Vue compiler,我们知道了tokenizer可以用来做语句分析,而parse负责生成抽象语法树AST。然后我们一起分析AST中的Vue语法,最后通过generate函数生成最终的代码。
|
|
|
|
|
|
今天我就带你深入Vue的compiler源码之中,看看Vue内部到底是怎么实现的。有了上一讲编译原理的入门基础,你会对Compiler执行全流程有更深的理解。
|
|
|
|
|
|
## Vue compiler入口分析
|
|
|
|
|
|
Vue 3内部有4个和compiler相关的包。compiler-dom和compiler-core负责实现浏览器端的编译,这两个包是我们需要深入研究的,compiler-ssr负责服务器端渲染,我们后面讲ssr的时候再研究,compiler-sfc是编译.vue单文件组件的,有兴趣的同学可以自行探索。
|
|
|
|
|
|
首先我们进入到vue-next/packages/compiler-dom/index.ts文件下,在[GitHub](https://github.com/vuejs/vue-next/blob/master/packages/compiler-dom/src/index.ts#L40)上你可以找到下面这段代码。
|
|
|
|
|
|
compiler函数有两个参数,第一个参数template,它是我们项目中的模板字符串;第二个参数options是编译的配置,内部调用了baseCompile函数。我们可以看到,这里的调用关系和runtime-dom、runtime-core的关系类似,compiler-dom负责传入浏览器Dom相关的API,实际编译的baseCompile是由compiler-core提供的。
|
|
|
|
|
|
```javascript
|
|
|
export function compile(
|
|
|
template: string,
|
|
|
options: CompilerOptions = {}
|
|
|
): CodegenResult {
|
|
|
return baseCompile(
|
|
|
template,
|
|
|
extend({}, parserOptions, options, {
|
|
|
nodeTransforms: [
|
|
|
// ignore <script> and <tag>
|
|
|
// this is not put inside DOMNodeTransforms because that list is used
|
|
|
// by compiler-ssr to generate vnode fallback branches
|
|
|
ignoreSideEffectTags,
|
|
|
...DOMNodeTransforms,
|
|
|
...(options.nodeTransforms || [])
|
|
|
],
|
|
|
directiveTransforms: extend(
|
|
|
{},
|
|
|
DOMDirectiveTransforms,
|
|
|
options.directiveTransforms || {}
|
|
|
),
|
|
|
transformHoist: __BROWSER__ ? null : stringifyStatic
|
|
|
})
|
|
|
)
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
我们先来看看compiler-dom做了哪些额外的配置。
|
|
|
|
|
|
首先,parserOption传入了parse的配置,通过parserOption传递的isNativeTag来区分element和component。这里的实现也非常简单,把所有html的标签名存储在一个对象中,然后就可以很轻松地判断出div是浏览器自带的element。
|
|
|
|
|
|
baseCompile传递的其他参数nodeTransforms和directiveTransforms,它们做的也是和上面代码类似的事。
|
|
|
|
|
|
```javascript
|
|
|
|
|
|
export const parserOptions: ParserOptions = {
|
|
|
isVoidTag,
|
|
|
isNativeTag: tag => isHTMLTag(tag) || isSVGTag(tag),
|
|
|
isPreTag: tag => tag === 'pre',
|
|
|
decodeEntities: __BROWSER__ ? decodeHtmlBrowser : decodeHtml,
|
|
|
|
|
|
isBuiltInComponent: (tag: string): symbol | undefined => {
|
|
|
if (isBuiltInType(tag, `Transition`)) {
|
|
|
return TRANSITION
|
|
|
} else if (isBuiltInType(tag, `TransitionGroup`)) {
|
|
|
return TRANSITION_GROUP
|
|
|
}
|
|
|
},
|
|
|
...
|
|
|
}
|
|
|
const HTML_TAGS =
|
|
|
'html,body,base,head,link,meta,style,title,address,article,aside,footer,' +
|
|
|
'header,h1,h2,h3,h4,h5,h6,nav,section,div,dd,dl,dt,figcaption,' +
|
|
|
'figure,picture,hr,img,li,main,ol,p,pre,ul,a,b,abbr,bdi,bdo,br,cite,code,' +
|
|
|
'data,dfn,em,i,kbd,mark,q,rp,rt,ruby,s,samp,small,span,strong,sub,sup,' +
|
|
|
'time,u,var,wbr,area,audio,map,track,video,embed,object,param,source,' +
|
|
|
'canvas,script,noscript,del,ins,caption,col,colgroup,table,thead,tbody,td,' +
|
|
|
'th,tr,button,datalist,fieldset,form,input,label,legend,meter,optgroup,' +
|
|
|
'option,output,progress,select,textarea,details,dialog,menu,' +
|
|
|
'summary,template,blockquote,iframe,tfoot'
|
|
|
export const isHTMLTag = /*#__PURE__*/ makeMap(HTML_TAGS)
|
|
|
|
|
|
```
|
|
|
|
|
|
## Vue浏览器端编译的核心流程
|
|
|
|
|
|
然后,我们进入到baseCompile函数中,这就是Vue浏览器端编译的核心流程。
|
|
|
|
|
|
下面的代码中可以很清楚地看到,我们先通过baseParse把传递的template解析成AST,然后通过transform函数对AST进行语义化分析,最后通过generate函数生成代码。
|
|
|
|
|
|
这个主要逻辑和我们写的迷你compiler基本一致,这些函数大概要做的事你也心中有数了。这里你也能体验到,亲手实现一个迷你版本对我们阅读源码很有帮助。
|
|
|
|
|
|
接下来,我们就进入到这几个函数之中去,看一下跟迷你compiler里的实现相比,我们到底做了哪些优化。
|
|
|
|
|
|
```javascript
|
|
|
export function baseCompile(
|
|
|
template: string | RootNode,
|
|
|
options: CompilerOptions = {}
|
|
|
): CodegenResult {
|
|
|
const ast = isString(template) ? baseParse(template, options) : template
|
|
|
const [nodeTransforms, directiveTransforms] =
|
|
|
getBaseTransformPreset(prefixIdentifiers)
|
|
|
|
|
|
transform(
|
|
|
ast,
|
|
|
extend({}, options, {
|
|
|
prefixIdentifiers,
|
|
|
nodeTransforms: [
|
|
|
...nodeTransforms,
|
|
|
...(options.nodeTransforms || []) // user transforms
|
|
|
],
|
|
|
directiveTransforms: extend(
|
|
|
{},
|
|
|
directiveTransforms,
|
|
|
options.directiveTransforms || {} // user transforms
|
|
|
)
|
|
|
})
|
|
|
)
|
|
|
return generate(
|
|
|
ast,
|
|
|
extend({}, options, {
|
|
|
prefixIdentifiers
|
|
|
})
|
|
|
)
|
|
|
}
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
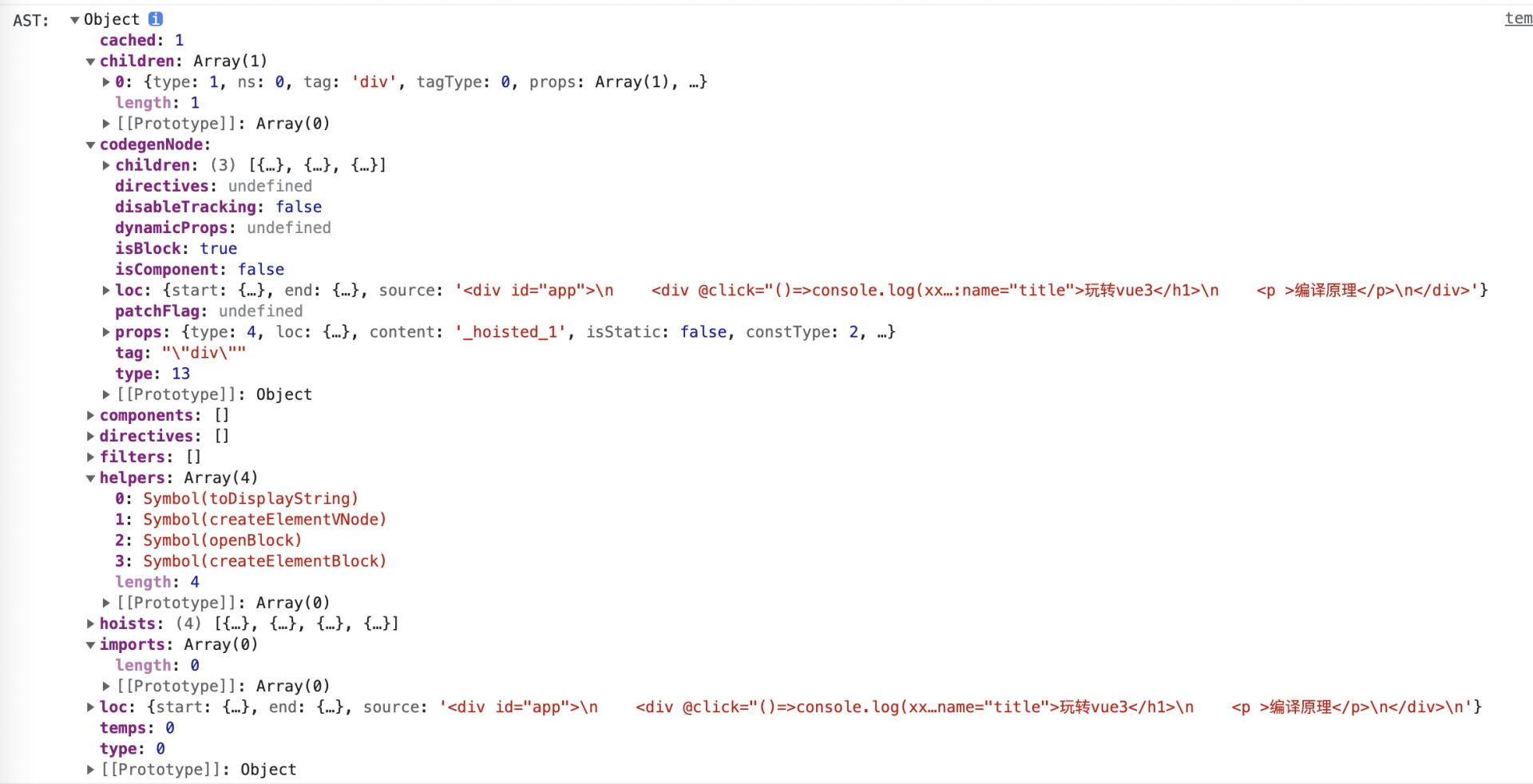
上一讲中我们体验了Vue的在线模板编译环境,可以在console中看到Vue解析得到的AST。
|
|
|
|
|
|
如下图所示,可以看到这个AST比迷你版多了很多额外的属性。**loc用来描述节点对应代码的信息,component和directive用来记录代码中出现的组件和指令等等**。
|
|
|
|
|
|
|
|
|
|
|
|
然后我们进入到baseParse函数中, 这里的createParserContext和createRoot用来生成上下文,其实就是创建了一个对象,保存当前parse函数中需要共享的数据和变量,最后调用parseChildren。
|
|
|
|
|
|
children内部开始判断<开头的标识符,判断开始还是闭合标签后,接着会生成一个nodes数组。其中,advanceBy函数负责更新context中的source用来向前遍历代码,最终对不同的场景执行不同的函数。
|
|
|
|
|
|
```javascript
|
|
|
export function baseParse(
|
|
|
content: string,
|
|
|
options: ParserOptions = {}
|
|
|
): RootNode {
|
|
|
const context = createParserContext(content, options)
|
|
|
const start = getCursor(context)
|
|
|
return createRoot(
|
|
|
parseChildren(context, TextModes.DATA, []),
|
|
|
getSelection(context, start)
|
|
|
)
|
|
|
}
|
|
|
function parseChildren(
|
|
|
context: ParserContext,
|
|
|
mode: TextModes,
|
|
|
ancestors: ElementNode[]
|
|
|
): TemplateChildNode[] {
|
|
|
const parent = last(ancestors)
|
|
|
// 依次生成node
|
|
|
const nodes: TemplateChildNode[] = []
|
|
|
// 如果遍历没结束
|
|
|
while (!isEnd(context, mode, ancestors)) {
|
|
|
|
|
|
const s = context.source
|
|
|
let node: TemplateChildNode | TemplateChildNode[] | undefined = undefined
|
|
|
|
|
|
if (mode === TextModes.DATA || mode === TextModes.RCDATA) {
|
|
|
if (!context.inVPre && startsWith(s, context.options.delimiters[0])) {
|
|
|
// 处理vue的变量标识符,两个大括号 '{{'
|
|
|
node = parseInterpolation(context, mode)
|
|
|
} else if (mode === TextModes.DATA && s[0] === '<') {
|
|
|
// 处理<开头的代码,可能是<div>也有可能是</div> 或者<!的注释
|
|
|
if (s.length === 1) {
|
|
|
// 长度是1,只有一个< 有问题 报错
|
|
|
emitError(context, ErrorCodes.EOF_BEFORE_TAG_NAME, 1)
|
|
|
} else if (s[1] === '!') {
|
|
|
// html注释
|
|
|
if (startsWith(s, '<!--')) {
|
|
|
node = parseComment(context)
|
|
|
} else if (startsWith(s, '<!DOCTYPE')) {
|
|
|
|
|
|
// DOCTYPE
|
|
|
node = parseBogusComment(context)
|
|
|
}
|
|
|
} else if (s[1] === '/') {
|
|
|
//</ 开头的标签,结束标签
|
|
|
// https://html.spec.whatwg.org/multipage/parsing.html#end-tag-open-state
|
|
|
if (/[a-z]/i.test(s[2])) {
|
|
|
emitError(context, ErrorCodes.X_INVALID_END_TAG)
|
|
|
parseTag(context, TagType.End, parent)
|
|
|
continue
|
|
|
}
|
|
|
} else if (/[a-z]/i.test(s[1])) {
|
|
|
// 解析节点
|
|
|
node = parseElement(context, ancestors)
|
|
|
// 2.x <template> with no directive compat
|
|
|
node = node.children
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
if (!node) {
|
|
|
// 文本
|
|
|
node = parseText(context, mode)
|
|
|
}
|
|
|
// node树数组,遍历puish
|
|
|
if (isArray(node)) {
|
|
|
for (let i = 0; i < node.length; i++) {
|
|
|
pushNode(nodes, node[i])
|
|
|
}
|
|
|
} else {
|
|
|
pushNode(nodes, node)
|
|
|
}
|
|
|
}
|
|
|
|
|
|
return removedWhitespace ? nodes.filter(Boolean) : nodes
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
parseInterpolation和parseText函数的逻辑比较简单。parseInterpolation负责识别变量的分隔符 {{ 和}} ,然后通过parseTextData获取变量的值,并且通过innerStart和innerEnd去记录插值的位置;parseText负责处理模板中的普通文本,主要是把文本包裹成AST对象。
|
|
|
|
|
|
接着我们看看处理节点的parseElement函数都做了什么。首先要判断pre和v-pre标签,然后通过isVoidTag判断标签是否是自闭合标签,这个函数是从compiler-dom中传来的,之后会递归调用parseChildren,接着再解析开始标签、解析子节点,最后解析结束标签。
|
|
|
|
|
|
```javascript
|
|
|
const VOID_TAGS =
|
|
|
'area,base,br,col,embed,hr,img,input,link,meta,param,source,track,wbr'
|
|
|
|
|
|
export const isVoidTag = /*#__PURE__*/ makeMap(VOID_TAGS)
|
|
|
function parseElement(
|
|
|
context: ParserContext,
|
|
|
ancestors: ElementNode[]
|
|
|
): ElementNode | undefined {
|
|
|
// Start tag.
|
|
|
// 是不是pre标签和v-pre标签
|
|
|
const wasInPre = context.inPre
|
|
|
const wasInVPre = context.inVPre
|
|
|
const parent = last(ancestors)
|
|
|
// 解析标签节点
|
|
|
const element = parseTag(context, TagType.Start, parent)
|
|
|
const isPreBoundary = context.inPre && !wasInPre
|
|
|
const isVPreBoundary = context.inVPre && !wasInVPre
|
|
|
|
|
|
if (element.isSelfClosing || context.options.isVoidTag(element.tag)) {
|
|
|
// #4030 self-closing <pre> tag
|
|
|
if (isPreBoundary) {
|
|
|
context.inPre = false
|
|
|
}
|
|
|
if (isVPreBoundary) {
|
|
|
context.inVPre = false
|
|
|
}
|
|
|
return element
|
|
|
}
|
|
|
|
|
|
// Children.
|
|
|
ancestors.push(element)
|
|
|
const mode = context.options.getTextMode(element, parent)
|
|
|
const children = parseChildren(context, mode, ancestors)
|
|
|
ancestors.pop()
|
|
|
element.children = children
|
|
|
|
|
|
// End tag.
|
|
|
if (startsWithEndTagOpen(context.source, element.tag)) {
|
|
|
parseTag(context, TagType.End, parent)
|
|
|
} else {
|
|
|
emitError(context, ErrorCodes.X_MISSING_END_TAG, 0, element.loc.start)
|
|
|
if (context.source.length === 0 && element.tag.toLowerCase() === 'script') {
|
|
|
const first = children[0]
|
|
|
if (first && startsWith(first.loc.source, '<!--')) {
|
|
|
emitError(context, ErrorCodes.EOF_IN_SCRIPT_HTML_COMMENT_LIKE_TEXT)
|
|
|
}
|
|
|
}
|
|
|
}
|
|
|
|
|
|
element.loc = getSelection(context, element.loc.start)
|
|
|
|
|
|
if (isPreBoundary) {
|
|
|
context.inPre = false
|
|
|
}
|
|
|
if (isVPreBoundary) {
|
|
|
context.inVPre = false
|
|
|
}
|
|
|
return element
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
最后,我们来看下解析节点的parseTag函数的逻辑,匹配文本标签结束的位置后,先通过parseAttributes函数处理属性,然后对pre和v-pre标签进行检查,最后通过isComponent函数判断是否为组件。
|
|
|
|
|
|
isComponent内部会通过compiler-dom传递的isNativeTag来辅助判断结果,最终返回一个描述节点的对象,包含当前节点所有解析之后的信息,tag表示标签名,children表示子节点的数组,具体代码我放在了后面。
|
|
|
|
|
|
```javascript
|
|
|
function parseTag(
|
|
|
context: ParserContext,
|
|
|
type: TagType,
|
|
|
parent: ElementNode | undefined
|
|
|
): ElementNode | undefined {
|
|
|
|
|
|
// Tag open.
|
|
|
const start = getCursor(context)
|
|
|
//匹配标签结束的位置
|
|
|
const match = /^<\/?([a-z][^\t\r\n\f />]*)/i.exec(context.source)!
|
|
|
const tag = match[1]
|
|
|
const ns = context.options.getNamespace(tag, parent)
|
|
|
// 向前遍历代码
|
|
|
advanceBy(context, match[0].length)
|
|
|
advanceSpaces(context)
|
|
|
|
|
|
// save current state in case we need to re-parse attributes with v-pre
|
|
|
const cursor = getCursor(context)
|
|
|
const currentSource = context.source
|
|
|
|
|
|
// check <pre> tag
|
|
|
if (context.options.isPreTag(tag)) {
|
|
|
context.inPre = true
|
|
|
}
|
|
|
// Attributes.
|
|
|
// 解析属性
|
|
|
let props = parseAttributes(context, type)
|
|
|
// check v-pre
|
|
|
if (){...}
|
|
|
// Tag close.
|
|
|
let isSelfClosing = false
|
|
|
if (type === TagType.End) {
|
|
|
return
|
|
|
}
|
|
|
|
|
|
let tagType = ElementTypes.ELEMENT
|
|
|
if (!context.inVPre) {
|
|
|
if (tag === 'slot') {
|
|
|
tagType = ElementTypes.SLOT
|
|
|
} else if (tag === 'template') {
|
|
|
if (
|
|
|
props.some(
|
|
|
p =>
|
|
|
p.type === NodeTypes.DIRECTIVE && isSpecialTemplateDirective(p.name)
|
|
|
)
|
|
|
) {
|
|
|
tagType = ElementTypes.TEMPLATE
|
|
|
}
|
|
|
} else if (isComponent(tag, props, context)) {
|
|
|
tagType = ElementTypes.COMPONENT
|
|
|
}
|
|
|
}
|
|
|
|
|
|
return {
|
|
|
type: NodeTypes.ELEMENT,
|
|
|
ns,
|
|
|
tag,
|
|
|
tagType,
|
|
|
props,
|
|
|
isSelfClosing,
|
|
|
children: [],
|
|
|
loc: getSelection(context, start),
|
|
|
codegenNode: undefined // to be created during transform phase
|
|
|
}
|
|
|
}
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
parse函数生成AST之后,我们就有了一个完整描述template的对象,它包含了template中所有的信息。
|
|
|
|
|
|
## AST的语义化分析
|
|
|
|
|
|
下一步我们要对AST进行语义化的分析。transform函数的执行流程分支很多,**核心的逻辑就是识别一个个的Vue的语法,并且进行编译器的优化,我们经常提到的静态标记就是这一步完成的**。
|
|
|
|
|
|
我们进入到transform函数中,可以看到,内部通过createTransformContext创建上下文对象,这个对象包含当前分析的属性配置,包括是否ssr,是否静态提升还有工具函数等等,这个对象的属性你可以在 [GitHub](https://github.com/vuejs/vue-next/blob/0dc521b9e15ce4aa3d5229e90d2173644529e92b/packages/compiler-core/src/transforms/transformElement.ts)上看到。
|
|
|
|
|
|
```javascript
|
|
|
|
|
|
|
|
|
export function transform(root: RootNode, options: TransformOptions) {
|
|
|
const context = createTransformContext(root, options)
|
|
|
traverseNode(root, context)
|
|
|
if (options.hoistStatic) {
|
|
|
hoistStatic(root, context)
|
|
|
}
|
|
|
if (!options.ssr) {
|
|
|
createRootCodegen(root, context)
|
|
|
}
|
|
|
// finalize meta information
|
|
|
root.helpers = [...context.helpers.keys()]
|
|
|
root.components = [...context.components]
|
|
|
root.directives = [...context.directives]
|
|
|
root.imports = context.imports
|
|
|
root.hoists = context.hoists
|
|
|
root.temps = context.temps
|
|
|
root.cached = context.cached
|
|
|
|
|
|
if (__COMPAT__) {
|
|
|
root.filters = [...context.filters!]
|
|
|
}
|
|
|
}
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
然后通过traverseNode即可编译AST所有的节点。核心的转换流程是在遍历中实现,内部使用switch判断node.type执行不同的处理逻辑。比如如果是Interpolation,就需要在helper中导入toDisplayString工具函数,这个迷你版本中我们也实现过。
|
|
|
|
|
|
```javascript
|
|
|
|
|
|
export function traverseNode(
|
|
|
node: RootNode | TemplateChildNode,
|
|
|
context: TransformContext
|
|
|
) {
|
|
|
context.currentNode = node
|
|
|
// apply transform plugins
|
|
|
const { nodeTransforms } = context
|
|
|
const exitFns = []
|
|
|
for (let i = 0; i < nodeTransforms.length; i++) {
|
|
|
// 处理exitFns
|
|
|
}
|
|
|
swtch (node.type) {
|
|
|
case NodeTypes.COMMENT:
|
|
|
if (!context.ssr) {
|
|
|
context.helper(CREATE_COMMENT)
|
|
|
}
|
|
|
break
|
|
|
case NodeTypes.INTERPOLATION:
|
|
|
if (!context.ssr) {
|
|
|
context.helper(TO_DISPLAY_STRING)
|
|
|
}
|
|
|
break
|
|
|
case NodeTypes.IF:
|
|
|
for (let i = 0; i < node.branches.length; i++) {
|
|
|
traverseNode(node.branches[i], context)
|
|
|
}
|
|
|
break
|
|
|
case NodeTypes.IF_BRANCH:
|
|
|
case NodeTypes.FOR:
|
|
|
case NodeTypes.ELEMENT:
|
|
|
case NodeTypes.ROOT:
|
|
|
traverseChildren(node, context)
|
|
|
break
|
|
|
}
|
|
|
|
|
|
// exit transforms
|
|
|
context.currentNode = node
|
|
|
let i = exitFns.length
|
|
|
while (i--) {
|
|
|
exitFns[i]()
|
|
|
}
|
|
|
}
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
transform中还会调用transformElement来转换节点,用来处理props和children的静态标记,transformText用来转换文本,这里的代码比较简单, 你可以自行在[Github](https://github.com/vuejs/vue-next/blob/0dc521b9e15ce4aa3d5229e90d2173644529e92b/packages/compiler-core/src/transforms/transformElement.ts)上查阅。
|
|
|
transform函数参数中的nodeTransforms和directiveTransforms传递了Vue中template语法的配置,这个两个函数由getBaseTransformPreset返回。
|
|
|
|
|
|
下面的代码中,transformIf和transformFor函数式解析Vue中v-if和v-for的语法转换,transformOn和transformModel是解析v-on和v-model的语法解析,这里我们只关注v-开头的语法。
|
|
|
|
|
|
```javascript
|
|
|
|
|
|
|
|
|
export function getBaseTransformPreset(
|
|
|
prefixIdentifiers?: boolean
|
|
|
): TransformPreset {
|
|
|
return [
|
|
|
[
|
|
|
transformOnce,
|
|
|
transformIf,
|
|
|
transformMemo,
|
|
|
transformFor,
|
|
|
...(__COMPAT__ ? [transformFilter] : []),
|
|
|
...(!__BROWSER__ && prefixIdentifiers
|
|
|
? [
|
|
|
// order is important
|
|
|
trackVForSlotScopes,
|
|
|
transformExpression
|
|
|
]
|
|
|
: __BROWSER__ && __DEV__
|
|
|
? [transformExpression]
|
|
|
: []),
|
|
|
transformSlotOutlet,
|
|
|
transformElement,
|
|
|
trackSlotScopes,
|
|
|
transformText
|
|
|
],
|
|
|
{
|
|
|
on: transformOn,
|
|
|
bind: transformBind,
|
|
|
model: transformModel
|
|
|
}
|
|
|
]
|
|
|
}
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
然后我们再来看看transformIf的函数实现。首先判断v-if、v-else和v-else-if属性,内部通过createCodegenNodeForBranch来创建条件分支,在AST中标记当前v-if的处理逻辑。这段逻辑标记结束后,在generate中就会把v-if标签和后面的v-else标签解析成三元表达式。
|
|
|
|
|
|
```javascript
|
|
|
export const transformIf = createStructuralDirectiveTransform(
|
|
|
/^(if|else|else-if)$/,
|
|
|
(node, dir, context) => {
|
|
|
return processIf(node, dir, context, (ifNode, branch, isRoot) => {
|
|
|
const siblings = context.parent!.children
|
|
|
let i = siblings.indexOf(ifNode)
|
|
|
let key = 0
|
|
|
while (i-- >= 0) {
|
|
|
const sibling = siblings[i]
|
|
|
if (sibling && sibling.type === NodeTypes.IF) {
|
|
|
key += sibling.branches.length
|
|
|
}
|
|
|
}
|
|
|
return () => {
|
|
|
if (isRoot) {
|
|
|
ifNode.codegenNode = createCodegenNodeForBranch(
|
|
|
branch,
|
|
|
key,
|
|
|
context
|
|
|
) as IfConditionalExpression
|
|
|
} else {
|
|
|
// attach this branch's codegen node to the v-if root.
|
|
|
const parentCondition = getParentCondition(ifNode.codegenNode!)
|
|
|
parentCondition.alternate = createCodegenNodeForBranch(
|
|
|
branch,
|
|
|
key + ifNode.branches.length - 1,
|
|
|
context
|
|
|
)
|
|
|
}
|
|
|
}
|
|
|
})
|
|
|
}
|
|
|
)
|
|
|
|
|
|
```
|
|
|
|
|
|
transform对AST分析结束之后,我们就得到了一个优化后的AST对象,最后我们需要调用generate函数最终生成render函数。
|
|
|
|
|
|
## template到render函数的转化
|
|
|
|
|
|
结合下面的代码我们可以看到,generate首先通过createCodegenContext创建上下文对象,然后通过genModulePreamble生成预先定义好的代码模板,然后生成render函数,最后生成创建虚拟DOM的表达式。
|
|
|
|
|
|
```javascript
|
|
|
export function generate(
|
|
|
ast,
|
|
|
options
|
|
|
): CodegenResult {
|
|
|
const context = createCodegenContext(ast, options)
|
|
|
const {
|
|
|
mode,
|
|
|
push,
|
|
|
prefixIdentifiers,
|
|
|
indent,
|
|
|
deindent,
|
|
|
newline,
|
|
|
scopeId,
|
|
|
ssr
|
|
|
} = context
|
|
|
|
|
|
if (!__BROWSER__ && mode === 'module') {
|
|
|
// 预设代码,module风格 就是import语句
|
|
|
genModulePreamble(ast, preambleContext, genScopeId, isSetupInlined)
|
|
|
} else {
|
|
|
// 预设代码,函数风格 就是import语句
|
|
|
genFunctionPreamble(ast, preambleContext)
|
|
|
}
|
|
|
// render还是ssrRender
|
|
|
const functionName = ssr ? `ssrRender` : `render`
|
|
|
const args = ssr ? ['_ctx', '_push', '_parent', '_attrs'] : ['_ctx', '_cache']
|
|
|
if (!__BROWSER__ && options.bindingMetadata && !options.inline) {
|
|
|
// binding optimization args
|
|
|
args.push('$props', '$setup', '$data', '$options')
|
|
|
}
|
|
|
const signature =
|
|
|
!__BROWSER__ && options.isTS
|
|
|
? args.map(arg => `${arg}: any`).join(',')
|
|
|
: args.join(', ')
|
|
|
|
|
|
if (isSetupInlined) {
|
|
|
push(`(${signature}) => {`)
|
|
|
} else {
|
|
|
push(`function ${functionName}(${signature}) {`)
|
|
|
}
|
|
|
indent()
|
|
|
|
|
|
// 组件,指令声明代码
|
|
|
if (ast.components.length) {
|
|
|
genAssets(ast.components, 'component', context)
|
|
|
if (ast.directives.length || ast.temps > 0) {
|
|
|
newline()
|
|
|
}
|
|
|
}
|
|
|
if (ast.components.length || ast.directives.length || ast.temps) {
|
|
|
push(`\n`)
|
|
|
newline()
|
|
|
}
|
|
|
|
|
|
if (ast.codegenNode) {
|
|
|
genNode(ast.codegenNode, context)
|
|
|
} else {
|
|
|
push(`null`)
|
|
|
}
|
|
|
|
|
|
if (useWithBlock) {
|
|
|
deindent()
|
|
|
push(`}`)
|
|
|
}
|
|
|
|
|
|
deindent()
|
|
|
push(`}`)
|
|
|
|
|
|
return {
|
|
|
ast,
|
|
|
code: context.code,
|
|
|
preamble: isSetupInlined ? preambleContext.code : ``,
|
|
|
// SourceMapGenerator does have toJSON() method but it's not in the types
|
|
|
map: context.map ? (context.map as any).toJSON() : undefined
|
|
|
}
|
|
|
}
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
我们来看下关键的步骤,genModulePreamble函数生成import风格的代码,这也是我们迷你版本中的功能:通过遍历helpers,生成import字符串,这对应了代码的第二行。
|
|
|
|
|
|
```javascript
|
|
|
// 生成这个
|
|
|
// import { toDisplayString as _toDisplayString, createElementVNode as _createElementVNode, openBlock as _openBlock, createElementBlock as _createElementBlock } from "vue"
|
|
|
|
|
|
function genModulePreamble(
|
|
|
ast: RootNode,
|
|
|
context: CodegenContext,
|
|
|
genScopeId: boolean,
|
|
|
inline?: boolean
|
|
|
) {
|
|
|
|
|
|
if (genScopeId && ast.hoists.length) {
|
|
|
ast.helpers.push(PUSH_SCOPE_ID, POP_SCOPE_ID)
|
|
|
}
|
|
|
// generate import statements for helpers
|
|
|
if (ast.helpers.length) {
|
|
|
push(
|
|
|
`import { ${ast.helpers
|
|
|
.map(s => `${helperNameMap[s]} as _${helperNameMap[s]}`)
|
|
|
.join(', ')} } from ${JSON.stringify(runtimeModuleName)}\n`
|
|
|
)
|
|
|
}
|
|
|
}
|
|
|
...
|
|
|
}
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
接下来的步骤就是生成渲染函数render和component的代码,最后通过genNode生成创建虚拟的代码,执行switch语句生成不同的代码,一共有十几种情况,这里就不一一赘述了。我们可以回顾上一讲中迷你代码的逻辑,总之针对变量,标签,v-if和v-for都有不同的代码生成逻辑,最终才实现了template到render函数的转化。
|
|
|
|
|
|
```javascript
|
|
|
function genNode(node: CodegenNode | symbol | string, context: CodegenContext) {
|
|
|
if (isString(node)) {
|
|
|
context.push(node)
|
|
|
return
|
|
|
}
|
|
|
if (isSymbol(node)) {
|
|
|
context.push(context.helper(node))
|
|
|
return
|
|
|
}
|
|
|
switch (node.type) {
|
|
|
case NodeTypes.ELEMENT:
|
|
|
case NodeTypes.IF:
|
|
|
case NodeTypes.FOR:
|
|
|
genNode(node.codegenNode!, context)
|
|
|
break
|
|
|
case NodeTypes.TEXT:
|
|
|
genText(node, context)
|
|
|
break
|
|
|
case NodeTypes.SIMPLE_EXPRESSION:
|
|
|
genExpression(node, context)
|
|
|
break
|
|
|
case NodeTypes.INTERPOLATION:
|
|
|
genInterpolation(node, context)
|
|
|
break
|
|
|
case NodeTypes.TEXT_CALL:
|
|
|
genNode(node.codegenNode, context)
|
|
|
break
|
|
|
case NodeTypes.COMPOUND_EXPRESSION:
|
|
|
genCompoundExpression(node, context)
|
|
|
break
|
|
|
case NodeTypes.COMMENT:
|
|
|
genComment(node, context)
|
|
|
break
|
|
|
case NodeTypes.VNODE_CALL:
|
|
|
genVNodeCall(node, context)
|
|
|
break
|
|
|
|
|
|
case NodeTypes.JS_CALL_EXPRESSION:
|
|
|
genCallExpression(node, context)
|
|
|
break
|
|
|
case NodeTypes.JS_OBJECT_EXPRESSION:
|
|
|
genObjectExpression(node, context)
|
|
|
break
|
|
|
case NodeTypes.JS_ARRAY_EXPRESSION:
|
|
|
genArrayExpression(node, context)
|
|
|
break
|
|
|
case NodeTypes.JS_FUNCTION_EXPRESSION:
|
|
|
genFunctionExpression(node, context)
|
|
|
break
|
|
|
case NodeTypes.JS_CONDITIONAL_EXPRESSION:
|
|
|
genConditionalExpression(node, context)
|
|
|
break
|
|
|
case NodeTypes.JS_CACHE_EXPRESSION:
|
|
|
genCacheExpression(node, context)
|
|
|
break
|
|
|
case NodeTypes.JS_BLOCK_STATEMENT:
|
|
|
genNodeList(node.body, context, true, false)
|
|
|
break
|
|
|
|
|
|
/* istanbul ignore next */
|
|
|
case NodeTypes.IF_BRANCH:
|
|
|
// noop
|
|
|
break
|
|
|
|
|
|
}
|
|
|
}
|
|
|
|
|
|
```
|
|
|
|
|
|
## 总结
|
|
|
|
|
|
今天的内容到这就讲完了,我给你总结一下今天讲到的内容吧。
|
|
|
|
|
|
今天我们一起分析了Vue中的compiler执行全流程,有了上一讲编译入门知识的基础之后,今天的parse,transform和generate模块就是在上一讲的基础之上,更加全面地实现代码的编译和转化。
|
|
|
|
|
|
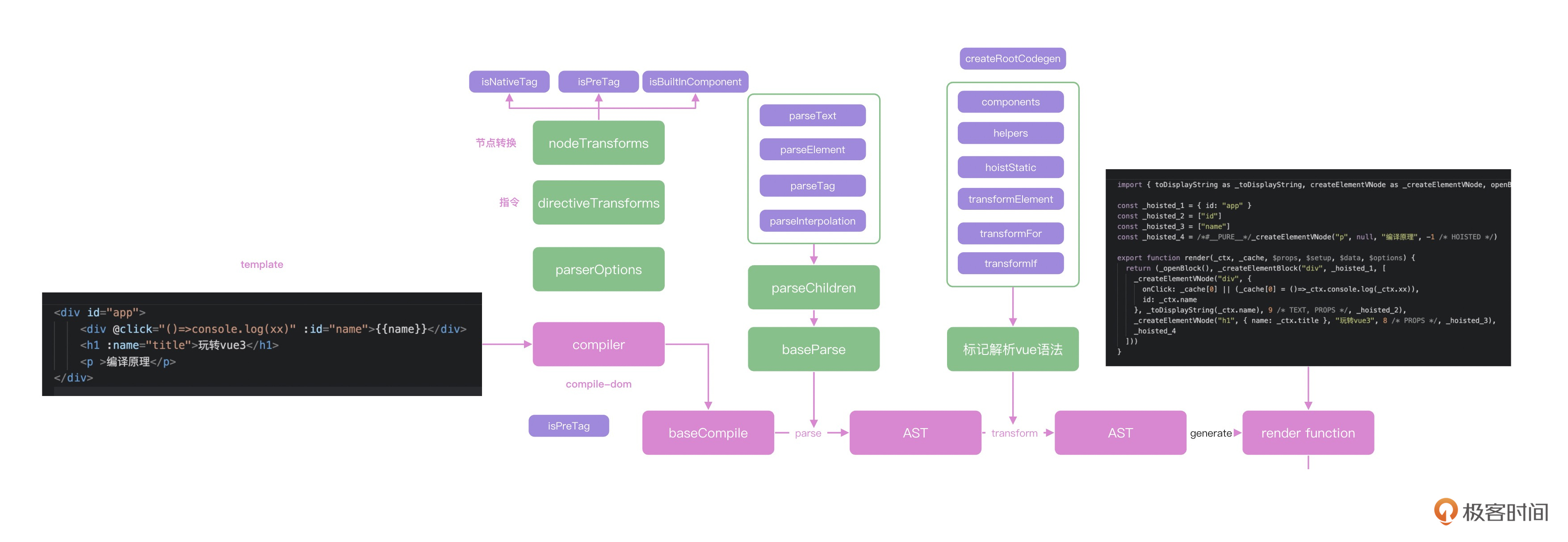
|
|
|
|
|
|
上面的流程图中,我们代码中的template是通过compiler函数进行编译转换,compiler内部调用了compiler-core中的baseCompile函数,并且传递了浏览器平台的转换逻辑。
|
|
|
|
|
|
比如isNativeTag等函数,baseCompie函数中首先通过baseParse函数把template处理成为AST,并且由transform函数进行标记优化,transfom内部的transformIf,transformOn等函数会对Vue中的语法进行标记,这样在generate函数中就可以使用优化后的AST去生成最终的render函数。
|
|
|
|
|
|
最终,render函数会和我们写的setup函数一起组成组件对象,交给页面进行渲染。后面我特意为你绘制了一幅Vue全流程的架构图,你可以保存下来随时查阅。
|
|
|
|
|
|
|
|
|
|
|
|
Vue源码中的编译优化也是Vue框架的亮点之一,我们自己也要思考编译器优化的机制,可以提高浏览器运行时的性能,我们项目中该如何借鉴这种思路呢?下一讲我会详细剖析编译原理在实战里的应用,敬请期待。
|
|
|
|
|
|
## 思考题
|
|
|
|
|
|
最后留一个思考题,transform函数中针对Vue中的语法有很多的函数处理,比如transformIf会把v-if指令编译成为一个三元表达式,请你从其余的函数选一个在评论区分享transform处理的结果吧。欢迎在评论区分享你的答案,我们下一讲再见!
|
|
|
|