22 KiB
20 | 智能语音:好玩的语音控制是怎么实现的?
你好,我是郭朝斌。
实战篇的前几讲,我们打造了联网智能电灯,并实现了跟光照传感器的场景联动。今天我们来玩一个更酷的,智能音箱。
智能音箱为我们提供了一种更加自然的交互方式,所以亚马逊的Echo产品一经问世,就迅速流行起来。与智能家居结合之后,它更是引起了行业巨头的注意,被认为是很有发展潜力的用户入口和平台级产品。
我们先不论智能音箱最终到底能不能发展成智能家居的平台级产品,至少这波热潮已经极大地推动了相关技术的发展,而且用户覆盖率也有了很大的提升。
这一讲我就为你介绍一下智能音箱的语音控制是怎么实现的,并且带你动手完成开发过程(如有需要,你可以根据这份文档自行采购相关硬件)。
智能音箱的技术架构
智能音箱主要涉及拾音、前端信号处理、语音识别、自然语言处理和语音合成等技术,现在一些产品甚至提供了声纹识别技术。
当然,智能音箱最重要的是提供各种功能,完成一些任务,比如控制电灯的开和关,这被称为技能。
整体的技术架构如下图所示:
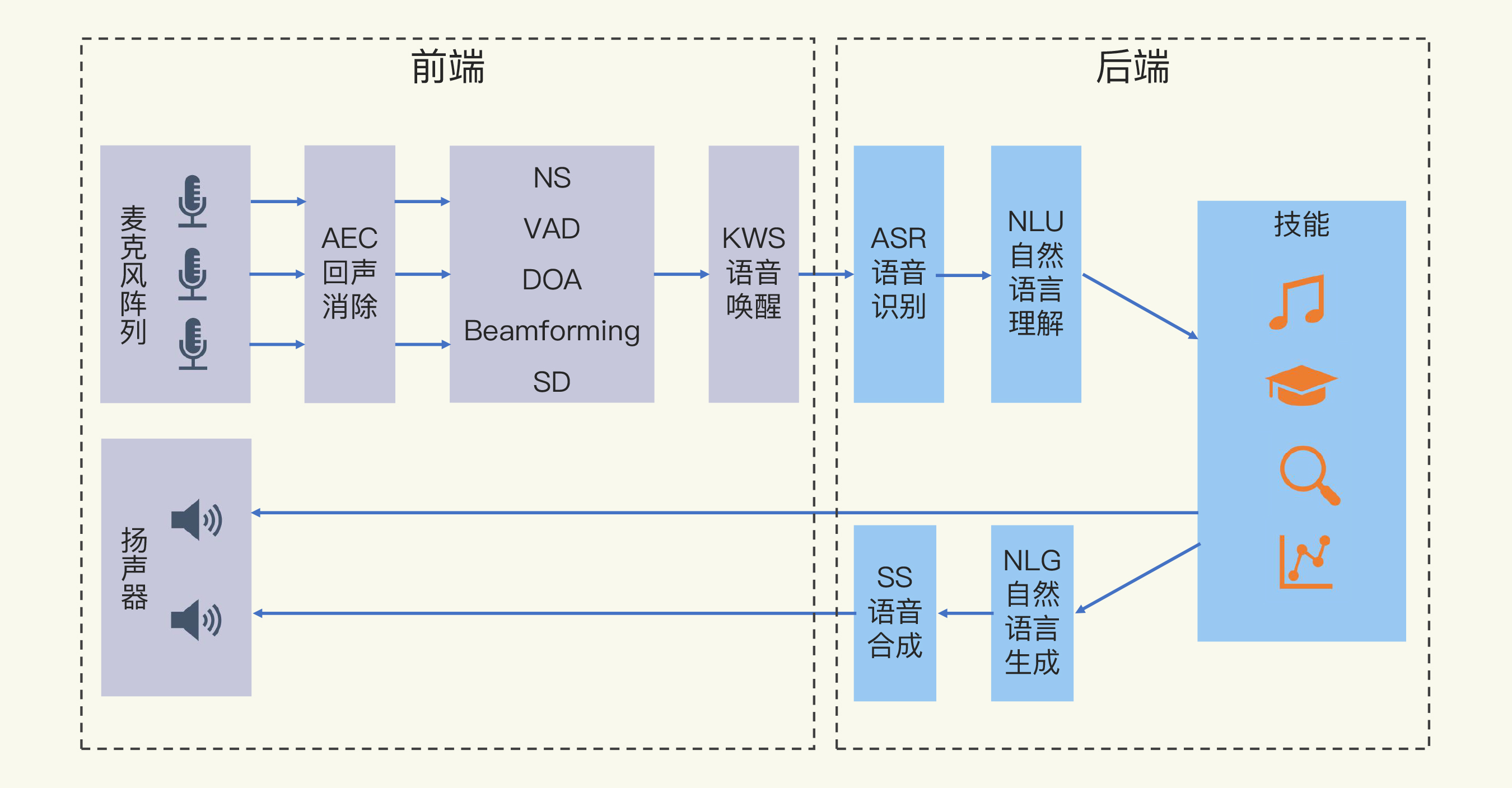
接下来,我会逐个讲解这些技术组成。
拾音
拾音,就是通过麦克风获取你的语音。
我们都用微信发送过语音消息,手机就是通过麦克风来获取你说的话的,这么说起来,拾音好像很简单。但是,智能音箱应对的环境要更复杂,因为用户可能在比较远的地方下达语音指令。
因此,智能音箱上一般采用麦克风阵列(Mic Array),也就是按照一定规则排列的多个麦克风,比如下图展示的就是Amazon Echo由7个麦克风组成的阵列(绿色圆圈部分)。

前端语音信号处理
在收集到声音信号后,还需要进行前端语音信号处理。只有经过处理,智能音箱才能获取到相对干净的语音信号,也才能提高后面的语音识别的准确率。
这些处理技术包括回声消除(Acoustic Echo Cancellaction, AEC)、噪音抑制(Noise Suppression,NS)、语音检测(Voice Activity Detection,VAD)、声源定位(Direction of Arrival estimation,DOA)、波束成型(Beamforming)和混响消除(Speech Dereverberation)等。

语音唤醒
语音唤醒(Keyword Spotting,KWS),就是通过特定的唤醒词来激活智能音箱,以便进行后续的语音交互任务。这样做一方面可以保护用户的隐私,因为只有唤醒后,音箱才收集和识别用户的语音信息,另一方面也可以简化语音的识别和理解,比如小米智能音箱的“小爱同学”就是这样的唤醒词。
语音识别
语音识别(Automatic Speech Recognition,ASR),主要完成的任务是将语音转换成文本,所以也被称为STT(Speech to Text)。
自然语言理解
自然语言理解(Natural Language Understanding,NLU),是对语音识别生成的文本进行处理,识别用户的意图,并生产结构化的数据。
当然,以现在的人工智能发展水平来看,自然语言理解还有很长的路要走。这也是我们常发现智能音箱不够“智能”的原因。
技能
技能(Skills)一般要借助后端云平台的强大能力,云平台可以提供知识图谱、家居设备远程控制和音乐等音频资源等能力。
自然语言生成
自然语言生成(Natural Language Generation,NLG),就是将各种技能的响应结果组织成文本语言。比如当你询问天气时,根据获取的天气状况和温度等信息生成“北京今天晴,最高温度5°,最低温度-6°”这样的语句。自然语言生成和自然语言理解都属于自然语言处理(Natural Language Processing,NLP)的范畴。
语音合成
语音合成(Speech Synthesis),就是将自然语言生成的文本转换为语音的形式,提供给智能音箱播放出来,给人的感觉就像和音箱在对话。因此,这个过程也叫做TTS(Text to Speech)。
智能音箱的开发
了解完智能音箱的基本技术构成,下面我们就基于树莓派开发一个自己的简易智能音箱吧。
首先,我需要说明一下树莓派的系统。为什么呢?因为在第15讲中,我们安装了Gladys Assistant系统镜像,而这个系统Raspbian是基于Debian buster版本的,一些语音识别开源库对于buster的支持并不够好。
所以,如果你的树莓派是Raspberry Pi 3系列,强烈建议你把系统镜像切换成Debian stretch版本。通过这个链接就可以下载基于Debian stretch版本的Raspbian镜像文件压缩包,安装还是使用Etcher工具,你可以回头看一下第15讲的介绍。
至于树莓派Raspberry Pi 4系列,因为官方系统Raspbian只有buster版本支持,所以我们还是继续基于第15讲的系统开发。
麦克风阵列
麦克风阵列我使用的是ReSpeaker 2-Mics Pi HAT,它的2个麦克风分布在模组的两边。我们现在来配置一下,让它可以在树莓派上正常工作。
你可以通过下面的命令安装它的驱动程序。首先,你最好切换一下树莓派的软件安装源,将它切换到国内的腾讯云安装源,这样下载安装的速度比较快。运行下面的命令修改配置文件:
$ sudo vim /etc/apt/sources.list
将文件修改为下面的内容:
deb https://mirrors.cloud.tencent.com/raspbian/raspbian/ buster main contrib non-free rpi
# Uncomment line below then 'apt-get update' to enable 'apt-get source'
deb-src https://mirrors.cloud.tencent.com/raspbian/raspbian/ buster main contrib non-free rpi
修改另一个软件安装源的配置文件,命令如下所示:
$ sudo vim /etc/apt/sources.list.d/raspi.list
修改后的文件内容如下:
deb https://mirrors.cloud.tencent.com/raspberrypi/ buster main
# Uncomment line below then 'apt-get update' to enable 'apt-get source'
deb-src https://mirrors.cloud.tencent.com/raspberrypi/ buster main
然后,你需要运行下面的命令更新安装源:
$ sudo apt-get clean all
$ sudo apt-get update
现在,你可以运行下面命令安装麦克风阵列的驱动程序。因为这个驱动依赖的wm8960 编解码器没有包含在树莓派系统的内核里面,需要重新加载内核,编译驱动,所以整个过程比较久。在等待的过程中,你可以先阅读这一讲的其他部分。
$ sudo apt-get install git
$ git clone --depth=1 https://github.com/respeaker/seeed-voicecard
$ cd seeed-voicecard
$ sudo ./install.sh
$ sudo reboot
树莓派重启之后,你可以在树莓派终端输入下面的命令,查看音频的输入和输出设备是否正常工作。
$ arecord -l
$ aplay -l
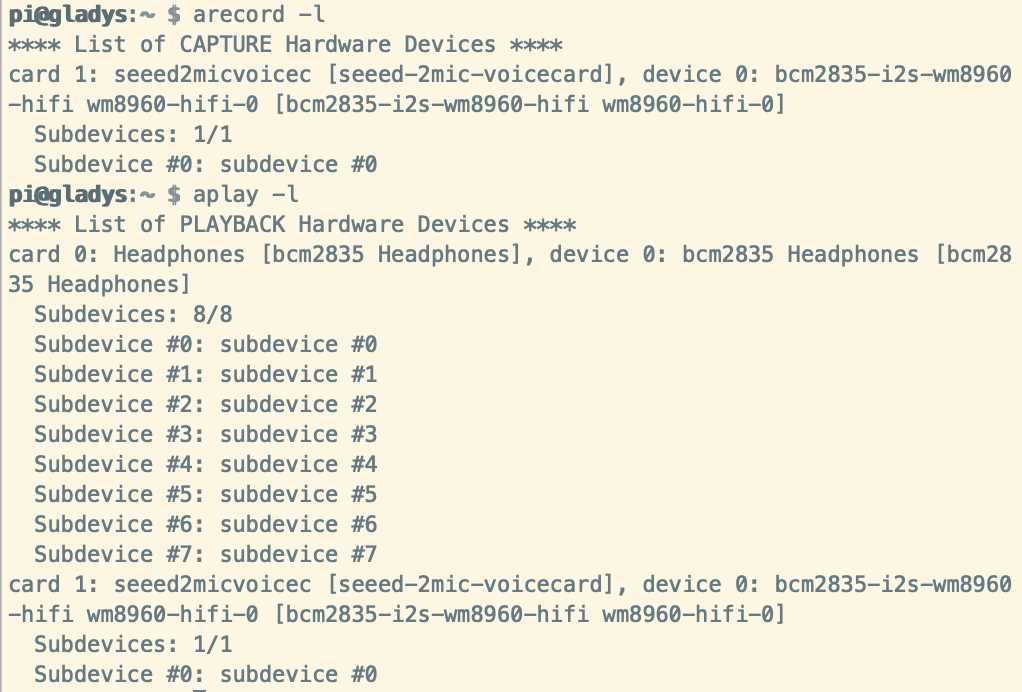
如果一切正常,我们就可以测试录音和播放功能了。在ReSpeaker 2-Mics Pi HAT的耳机插口上插入耳机或者扬声器,运行下面的命令,并说几句话。
$ arecord -d 5 test.wav
$ aplay test.wav
另外,你也可以通过软件AlsaMixer(命令alsamixer)来配置声音设置和调整音量,左、右箭头键用于选择通道或设备,向上、向下箭头控制当前所选设备的音量。退出程序使用ALT + Q,或者按Esc键。
为了简化开发,也考虑到麦克风硬件的限制,我们这里就先不关注前端语音信号处理的相关开发了。接下来,我们直接来到实现语音唤醒的环节。
语音唤醒
为了实现语音唤醒,我们需要选择一个轻量级的、可以在树莓派上运行的唤醒词监测器软件。
你可能首先想到的是Snowboy,没错,它确实是一个非常流行的工具。不过,Snowboy团队在2020年初的时候宣布,2020年12月31日会停止提供服务,所以我们只能寻找替代方案。
我选择的是Mycroft Precise,它是一个基于RNN神经网络的语音唤醒工具。
接下来,我们在树莓派安装Mycroft Precise。因为需要训练唤醒词模型,我们需要基于源代码来编译、安装。
首先,我们通过git命令把Mycroft Precise的源代码下载到树莓派的/home/pi目录:
$ cd ~
$ git clone https://github.com/mycroftai/mycroft-precise
$ cd mycroft-precise
在安装之前,把pypi的安装源修改到清华数据源,可以获得更快的下载速度。我们打开目录中的setup.sh文件:
$ vim setup.sh
将文件中的这行内容:
extra-index-url=https://www.piwheels.org/simple
替换成下面的内容:
index-url=https://pypi.tuna.tsinghua.edu.cn/simple
extra-index-url=https://www.piwheels.org/simple
然后,我们运行它自带的安装脚本,开始编译和安装。中间如果执行中断,可以重新执行这个命令,继续安装过程。(提示:有些ARM平台的库只有piwheels上有,所以这些库安装时速度还是很慢。这种情况下,可以电脑上使用下载工具获取这个模块的安装文件,然后上传到树莓派上,手动安装。)
$ ./setup.sh
安装完成后,我们开始使用Mycroft Precise来训练一个唤醒词模型,唤醒词可以根据喜好来选择,比如“极客时间”。
我们需要先激活Python的虚拟环境,因为Mycroft Precise在安装过程中创建了这个虚拟环境。
$ source .venv/bin/activate
接下来,我们通过工具precise-collect来收集语音模型训练的声音素材,运行后,根据提示录制12段声音。
$ precise-collect
Audio name (Ex. recording-##): geektime.##
Press space to record (esc to exit)...
Recording...
Saved as geektime-00.wav
Press space to record (esc to exit)...
然后,我们需要将这些声音随机分为两份,一份是训练样本,包括8个声音文件,另一份是测试样本,包括4个声音文件,并且把这两份样本分别放到geektime/wake-word/和/geektime/test/wake-word/这两个目录下面。
接着,我们执行下面的命令,生成神经网络模型geektime.net:
$ precise-train -e 60 geektime.net geektime/
最后,我们还需要将geektime.net的模型格式做一下转换,将它从Keras模型格式改为TensorFlow模型格式,因为TensorFlow模型更加通用。
$ precise-convert geektime.net
执行完成之后,我们会得到两个文件:
- geektime.pb,TensorFlow模型文件
- geektime.pb.params,包含Mycroft Precise在处理音频时需要的一些参数信息。
当然,为了提高模型的准确性,我们还可以使用precise-train-incremental工具来增加负样本,重新训练刚才的模型。如果环境复杂的话,你可以尝试一下。
然后,我们可以运行一段代码来测试这个唤醒词模型。不过,因为portaudio这个库在树莓派上运行有问题,我们需要先修复一下portaudio库。你可以运行下面的命令:
$ sudo apt-get remove libportaudio2
$ sudo apt-get install libasound2-dev
$ git clone -b alsapatch https://github.com/gglockner/portaudio
$ cd portaudio
$ ./configure && make
$ sudo make install
$ sudo ldconfig
测试程序的代码如下:
# File:kwsdemo.py
#!/usr/bin/env python3
from precise_runner import PreciseEngine, PreciseRunner
engine = PreciseEngine('precise-engine/precise-engine', 'geektime.pb')
runner = PreciseRunner(engine, on_activation=lambda: print('hello'))
runner.start()
# Sleep forever
from time import sleep
while True:
sleep(10)
现在,我们把kwsdemo.py文件,还有两个geektime.pb模型相关的文件,都上传到树莓派的Mycroft Precise目录下,然后运行kwsdemo.py文件,说出“极客时间”几个字,就会看到终端显示出“hello”这个单词。
语音识别
对于语音识别,我们直接采用腾讯云提供的语音识别SDK来完成(你需要提前在腾讯云控制台开通这个服务)。它会将语音发送到云端,由云端服务器计算出文本信息。你可以通过下面命令来安装:
$ pip3 install tencentcloud-sdk-python
在开始使用之前,你需要访问这个链接创建一个密钥,然后记录下SecretId和SecretKey的信息。
你可以参考下面的代码,来完成一个录音文件的识别。
from tencentcloud.common import credential
from tencentcloud.common.profile.client_profile import ClientProfile
from tencentcloud.common.profile.http_profile import HttpProfile
from tencentcloud.common.exception.tencent_cloud_sdk_exception import TencentCloudSDKException
from tencentcloud.asr.v20190614 import asr_client, models
import base64
import io
import sys
SECRET_ID = "你的Secret ID"
SECRET_KEY = "你的Secret Key"
try:
cred = credential.Credential(SECRET_ID, SECRET_KEY)
httpProfile = HttpProfile()
httpProfile.endpoint = "asr.tencentcloudapi.com"
clientProfile = ClientProfile()
clientProfile.httpProfile = httpProfile
clientProfile.signMethod = "TC3-HMAC-SHA256"
client = asr_client.AsrClient(cred, "ap-beijing", clientProfile)
#读取文件以及 base64
with open('./geektime-00.wav', "rb") as f:
if sys.version_info[0] == 2:
content = base64.b64encode(f.read())
else:
content = base64.b64encode(f.read()).decode('utf-8')
f.close()
#发送请求
req = models.SentenceRecognitionRequest()
params = {"ProjectId":0,"SubServiceType":2,"SourceType":1,"UsrAudioKey":"sessionid-geektime"}
req._deserialize(params)
req.DataLen = len(content)
req.Data = content
req.EngSerViceType = "16k_zh"
req.VoiceFormat = "wav"
resp = client.SentenceRecognition(req)
print(resp.to_json_string())
except TencentCloudSDKException as err:
print(err)
语音合成
接下来,我来介绍一下语音合成。
你可能会问,刚才介绍技术架构的时候,不是还讲了自然语言理解、技能和自然语言生成吗?这里怎么跳过去了呢?
首先,因为我们的任务很简单,只需要查询语音识别的文本中是否有“开”、“灯”,和“关”、“灯”就可以完成判断,所以自然语言理解直接判断字符串是否匹配即可。
其次,我们要实现控制智能电灯,这个技能我在后面会介绍。
最后,智能音箱只需要反馈执行开关灯的结果就可以,比如“我已经把灯打开了”或者“我已经把灯关了”,自然语言生成的部分按照固定的文本就可以了,不需要考虑动态生成的问题。
语音合成,就是我们希望把类似“我已经把灯关了”这样的文本信息,转换为音频,便于智能音箱播放出来。你可以基于离线的TTS引擎来实现,比如HanTTS这个项目。
当然,我们也可以使用腾讯云的语音合成服务(你需要提前在腾讯云控制台开通这个服务)。你可以参考下面的代码:
import json
import base64
from tencentcloud.common import credential
from tencentcloud.common.profile.client_profile import ClientProfile
from tencentcloud.common.profile.http_profile import HttpProfile
from tencentcloud.common.exception.tencent_cloud_sdk_exception import TencentCloudSDKException
from tencentcloud.tts.v20190823 import tts_client, models
SECRET_ID = "你的Secret ID"
SECRET_KEY = "你的Secret Key"
try:
cred = credential.Credential(SECRET_ID, SECRET_KEY)
httpProfile = HttpProfile()
httpProfile.endpoint = "tts.tencentcloudapi.com"
clientProfile = ClientProfile()
clientProfile.httpProfile = httpProfile
client = tts_client.TtsClient(cred, "ap-beijing", clientProfile)
req = models.TextToVoiceRequest()
params = {
"Text": "我已经把灯关了",
"SessionId": "sessionid-geektime",
"ModelType": 1,
"ProjectId": 0,
"VoiceType": 1002
}
req.from_json_string(json.dumps(params))
resp = client.TextToVoice(req)
print(resp.to_json_string())
if resp.Audio is not None:
audio = resp.Audio
data = base64.b64decode(audio)
wav_file = open("temp.wav", "wb")
wav_file.write(data)
wav_file.close()
except TencentCloudSDKException as err:
print(err)
通过智能音箱控制电灯
为了实现控制智能电灯的目的,我们需要借助物联网平台提供的开发接口。
首先,我们进入物联网开发平台,选择“智能家居”项目。
然后,点击左侧的“应用开发”,进入新建应用的界面,点击“新建应用”。
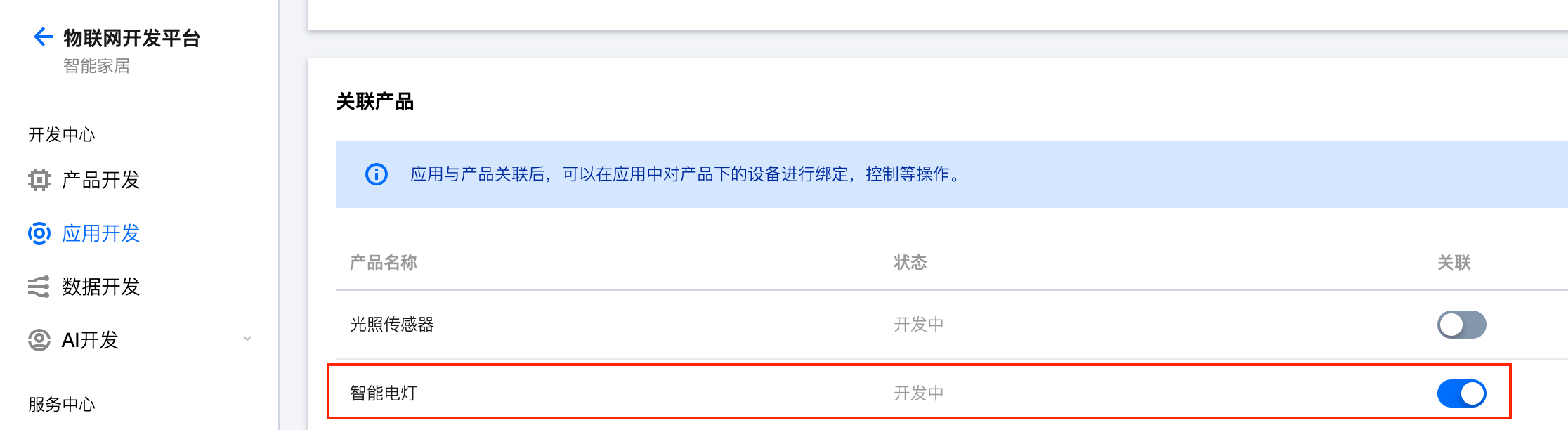
完成后,点击应用列表里面的应用名称,进入应用的详情页面。你可以看到应用的SecretId和SecretKey信息。这里,你需要将下面“关联产品”中的智能电灯勾选上。只有建立关联,应用才可以控制这个设备。
具体代码可以参考腾讯提供的开源实现,包括iOS、Android和小程序。
不过,这种方式需要用户账号的登录认证,在树莓派上不太方便。还有一个方式就是基于物联网开发平台提供的通用API接口。其中的“设备远程控制”接口可以满足我们的需求。
具体的控制方法,你可以参考下面的代码(注意,目前只支持ap-guangzhou区域)。
import json
from led2.main import PRODUCT_ID
from tencentcloud.common import credential
from tencentcloud.common.profile.client_profile import ClientProfile
from tencentcloud.common.profile.http_profile import HttpProfile
from tencentcloud.common.exception.tencent_cloud_sdk_exception import TencentCloudSDKException
from tencentcloud.iotexplorer.v20190423 import iotexplorer_client, models
SECRET_ID = "你的Secret ID"
SECRET_KEY = "你的Secret Key"
PRODUCT_ID = "你的ProductID"
def Light_control(state):
try:
cred = credential.Credential(SECRET_ID, SECRET_KEY)
httpProfile = HttpProfile()
httpProfile.endpoint = "iotexplorer.tencentcloudapi.com"
clientProfile = ClientProfile()
clientProfile.httpProfile = httpProfile
client = iotexplorer_client.IotexplorerClient(cred, "ap-guangzhou", clientProfile)
req = models.ControlDeviceDataRequest()
data = {
"power_switch": state
}
data_str = json.dumps(data)
params = {
"DeviceName": "Led_1",
"ProductId": PRODUCT_ID,
"Data": data_str
}
req.from_json_string(json.dumps(params))
resp = client.ControlDeviceData(req)
print(resp.to_json_string())
except TencentCloudSDKException as err:
print(err)
Light_control(0)
小结
总结一下,在这一讲中,我介绍了智能音箱的技术架构,以及在树莓派上用于实现智能音箱的一些可选的技术方案,并且带你实现了语音控制智能电灯的目的。你需要重点关注的知识有:
- 智能音箱的实现,需要前端音箱本体和后端云平台上一系列技术的支持。这些技术有前端的拾音、语音信号处理、语音唤醒和播音,以及后端的语音识别、自然语言理解、技能、自然语言生成和语音合成。
- 在树莓派的实现上,拾音可以选择使用麦克风阵列,因为基于麦克风阵列可以更好地实现前端语音信号处理,比如声源定位和波束成型等。
- 语言唤醒需要在智能音箱本体上实现,所以需要一些轻量级的识别引擎和训练好的唤醒词模型。之前比较流行的Snowboy将要停止服务,这里我选择了Mycroft Precise这个开源方案。
- 语音识别、自然语言理解、技能、自然语言生成和语音合成等任务适合基于云平台的能力来实现,因为云平台的计算能力更强,有更好的性能和准确度。
智能音箱的技术也一直在发展,比如现在越来越多的智能音箱开始配备屏幕和摄像头,这为智能音箱引入了声音、UI和视觉等多模态的交互方式,相应地,这也给声纹识别、人脸识别和动作识别等技术带来了新的应用场景。我相信智能音箱未来的产品形态和功能还会不断地进化和发展。
思考题
最后,我给你留一个思考题吧。
在这一讲中,我们是通过物联网平台提供的API接口来控制智能电灯的。除了这种方式,你还能想到其他的方法来远程控制智能电灯吗?你能实现一个虚拟的联网开关,基于场景联动来控制智能电灯的开和关吗?
欢迎你在留言区写下你思考的结果,也欢迎你将这一讲分享给你的朋友,大家一起交流学习。