130 lines
15 KiB
Markdown
130 lines
15 KiB
Markdown
# 31 | GPU(下):为什么深度学习需要使用GPU?
|
||
|
||
上一讲,我带你一起看了三维图形在计算机里的渲染过程。这个渲染过程,分成了顶点处理、图元处理、 栅格化、片段处理,以及最后的像素操作。这一连串的过程,也被称之为图形流水线或者渲染管线。
|
||
|
||
因为要实时计算渲染的像素特别地多,图形加速卡登上了历史的舞台。通过3dFx的Voodoo或者NVidia的TNT这样的图形加速卡,CPU就不需要再去处理一个个像素点的图元处理、栅格化和片段处理这些操作。而3D游戏也是从这个时代发展起来的。
|
||
|
||
你可以看这张图,这是“古墓丽影”游戏的多边形建模的变化。这个变化,则是从1996年到2016年,这20年来显卡的进步带来的。
|
||
|
||

|
||
|
||
[图片来源](http://www.gamesgrabr.com/blog/2016/01/07/the-evolution-of-lara-croft/)
|
||
|
||
## Shader的诞生和可编程图形处理器
|
||
|
||
不知道你有没有发现,在Voodoo和TNT显卡的渲染管线里面,没有“顶点处理“这个步骤。在当时,把多边形的顶点进行线性变化,转化到我们的屏幕的坐标系的工作还是由CPU完成的。所以,CPU的性能越好,能够支持的多边形也就越多,对应的多边形建模的效果自然也就越像真人。而3D游戏的多边形性能也受限于我们CPU的性能。无论你的显卡有多快,如果CPU不行,3D画面一样还是不行。
|
||
|
||
所以,1999年NVidia推出的GeForce 256显卡,就把顶点处理的计算能力,也从CPU里挪到了显卡里。不过,这对于想要做好3D游戏的程序员们还不够,即使到了GeForce 256。整个图形渲染过程都是在硬件里面固定的管线来完成的。程序员们在加速卡上能做的事情呢,只有改配置来实现不同的图形渲染效果。如果通过改配置做不到,我们就没有什么办法了。
|
||
|
||
这个时候,程序员希望我们的GPU也能有一定的可编程能力。这个编程能力不是像CPU那样,有非常通用的指令,可以进行任何你希望的操作,而是在整个的**渲染管线**(Graphics Pipeline)的一些特别步骤,能够自己去定义处理数据的算法或者操作。于是,从2001年的Direct3D 8.0开始,微软第一次引入了**可编程管线**(Programable Function Pipeline)的概念。
|
||
|
||
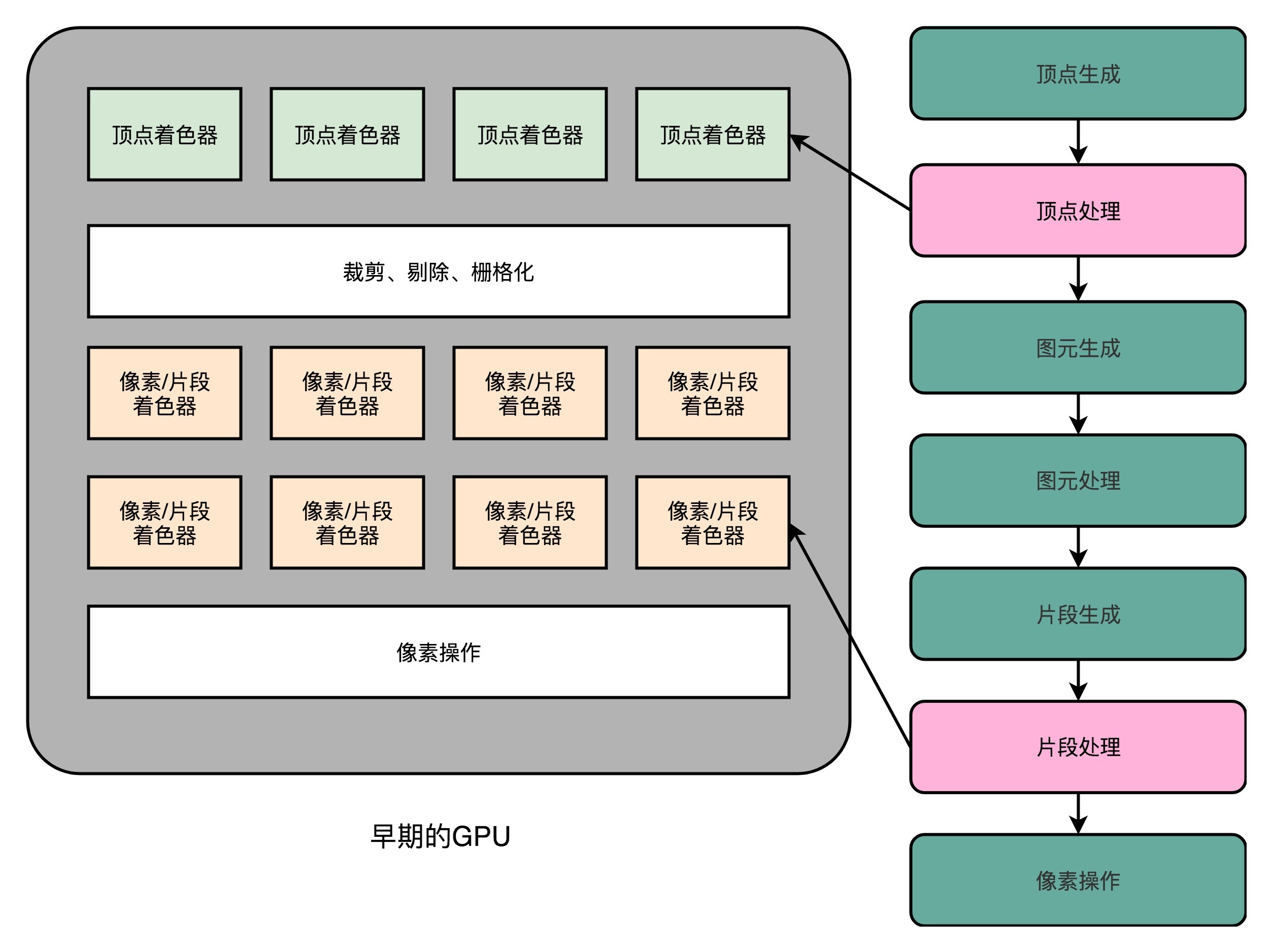
|
||
|
||
早期的可编程管线的GPU,提供了单独的顶点处理和片段处理(像素处理)的着色器
|
||
|
||
一开始的可编程管线呢,仅限于顶点处理(Vertex Processing)和片段处理(Fragment Processing)部分。比起原来只能通过显卡和Direct3D这样的图形接口提供的固定配置,程序员们终于也可以开始在图形效果上开始大显身手了。
|
||
|
||
这些可以编程的接口,我们称之为**Shader**,中文名称就是**着色器**。之所以叫“着色器”,是因为一开始这些“可编程”的接口,只能修改顶点处理和片段处理部分的程序逻辑。我们用这些接口来做的,也主要是光照、亮度、颜色等等的处理,所以叫着色器。
|
||
|
||
这个时候的GPU,有两类Shader,也就是Vertex Shader和Fragment Shader。我们在上一讲看到,在进行顶点处理的时候,我们操作的是多边形的顶点;在片段操作的时候,我们操作的是屏幕上的像素点。对于顶点的操作,通常比片段要复杂一些。所以一开始,这两类Shader都是独立的硬件电路,也各自有独立的编程接口。因为这么做,硬件设计起来更加简单,一块GPU上也能容纳下更多的Shader。
|
||
|
||
不过呢,大家很快发现,虽然我们在顶点处理和片段处理上的具体逻辑不太一样,但是里面用到的指令集可以用同一套。而且,虽然把Vertex Shader和Fragment Shader分开,可以减少硬件设计的复杂程度,但是也带来了一种浪费,有一半Shader始终没有被使用。在整个渲染管线里,Vertext Shader运行的时候,Fragment Shader停在那里什么也没干。Fragment Shader在运行的时候,Vertext Shader也停在那里发呆。
|
||
|
||
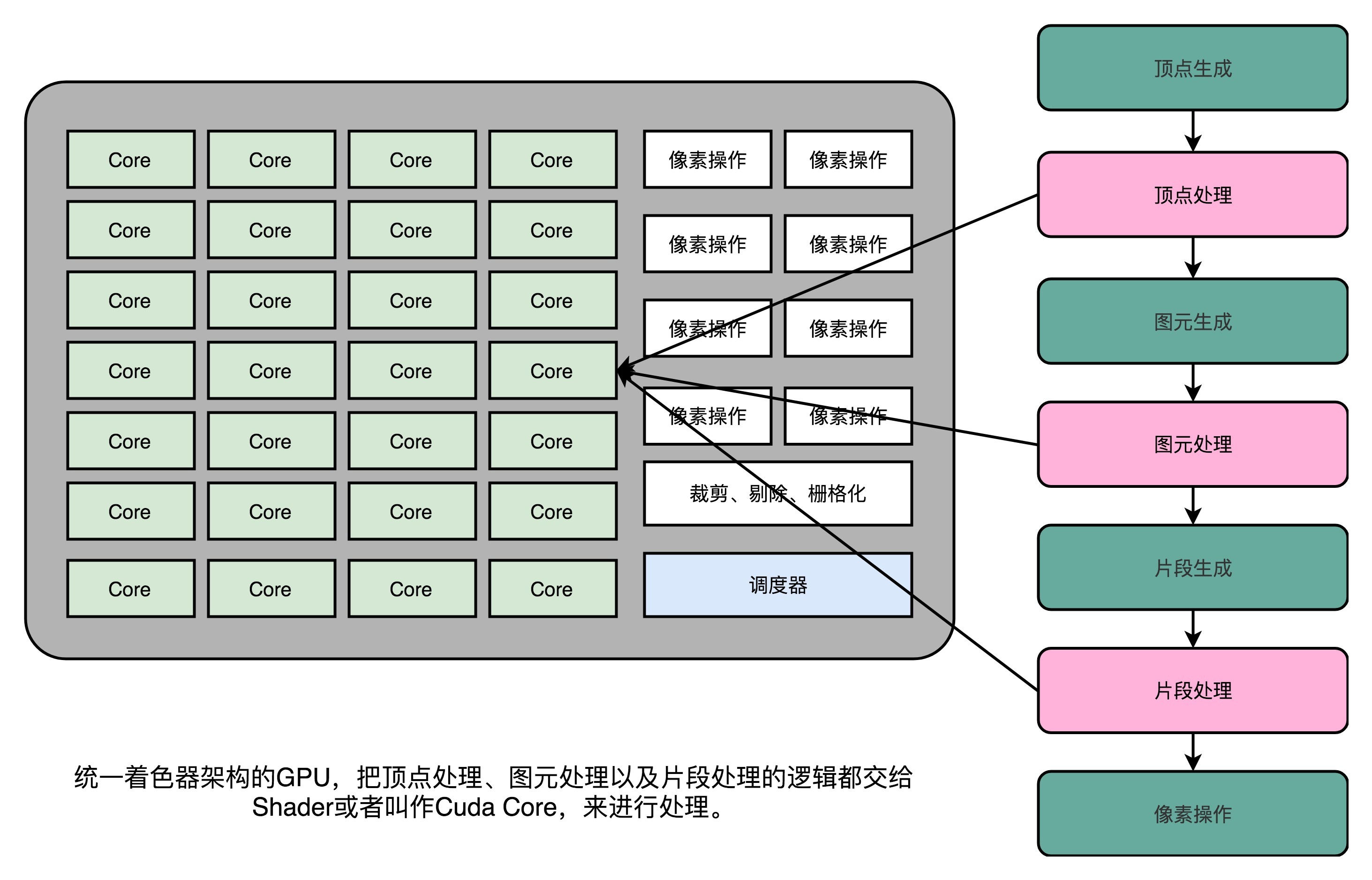
本来GPU就不便宜,结果设计的电路有一半时间是闲着的。喜欢精打细算抠出每一分性能的硬件工程师当然受不了了。于是,**统一着色器架构**(Unified Shader Architecture)就应运而生了。
|
||
|
||
既然大家用的指令集是一样的,那不如就在GPU里面放很多个一样的Shader硬件电路,然后通过统一调度,把顶点处理、图元处理、片段处理这些任务,都交给这些Shader去处理,让整个GPU尽可能地忙起来。这样的设计,就是我们现代GPU的设计,就是统一着色器架构。
|
||
|
||
有意思的是,这样的GPU并不是先在PC里面出现的,而是来自于一台游戏机,就是微软的XBox 360。后来,这个架构才被用到ATI和NVidia的显卡里。这个时候的“着色器”的作用,其实已经和它的名字关系不大了,而是变成了一个通用的抽象计算模块的名字。
|
||
|
||
正是因为Shader变成一个“通用”的模块,才有了把GPU拿来做各种通用计算的用法,也就是**GPGPU**(General-Purpose Computing on Graphics Processing Units,通用图形处理器)。而正是因为GPU可以拿来做各种通用的计算,才有了过去10年深度学习的火热。
|
||
|
||
|
||
|
||
## 现代GPU的三个核心创意
|
||
|
||
讲完了现代GPU的进化史,那么接下来,我们就来看看,为什么现代的GPU在图形渲染、深度学习上能那么快。
|
||
|
||
### 芯片瘦身
|
||
|
||
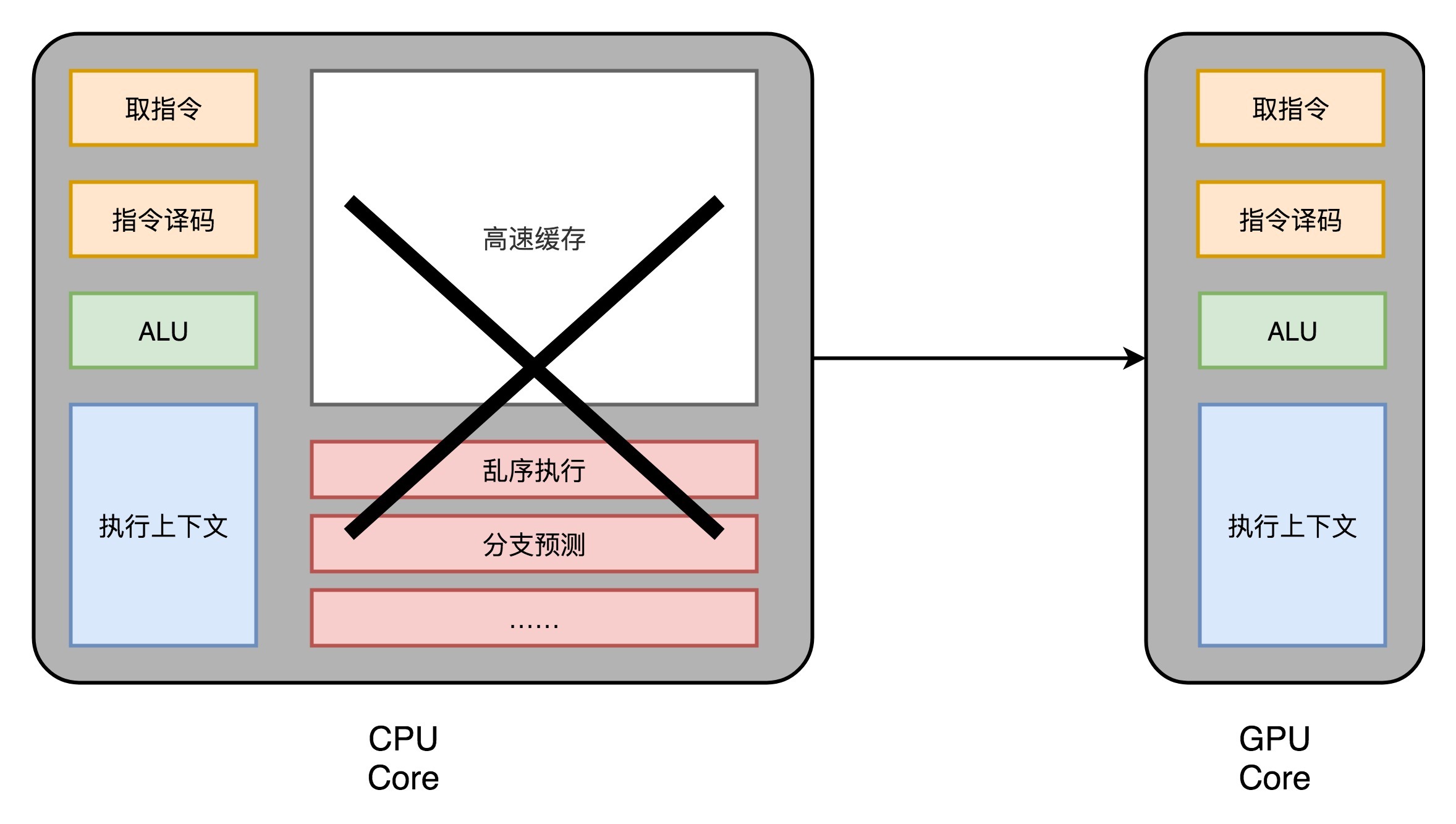
我们先来回顾一下,之前花了很多讲仔细讲解的现代CPU。现代CPU里的晶体管变得越来越多,越来越复杂,其实已经不是用来实现“计算”这个核心功能,而是拿来实现处理乱序执行、进行分支预测,以及我们之后要在存储器讲的高速缓存部分。
|
||
|
||
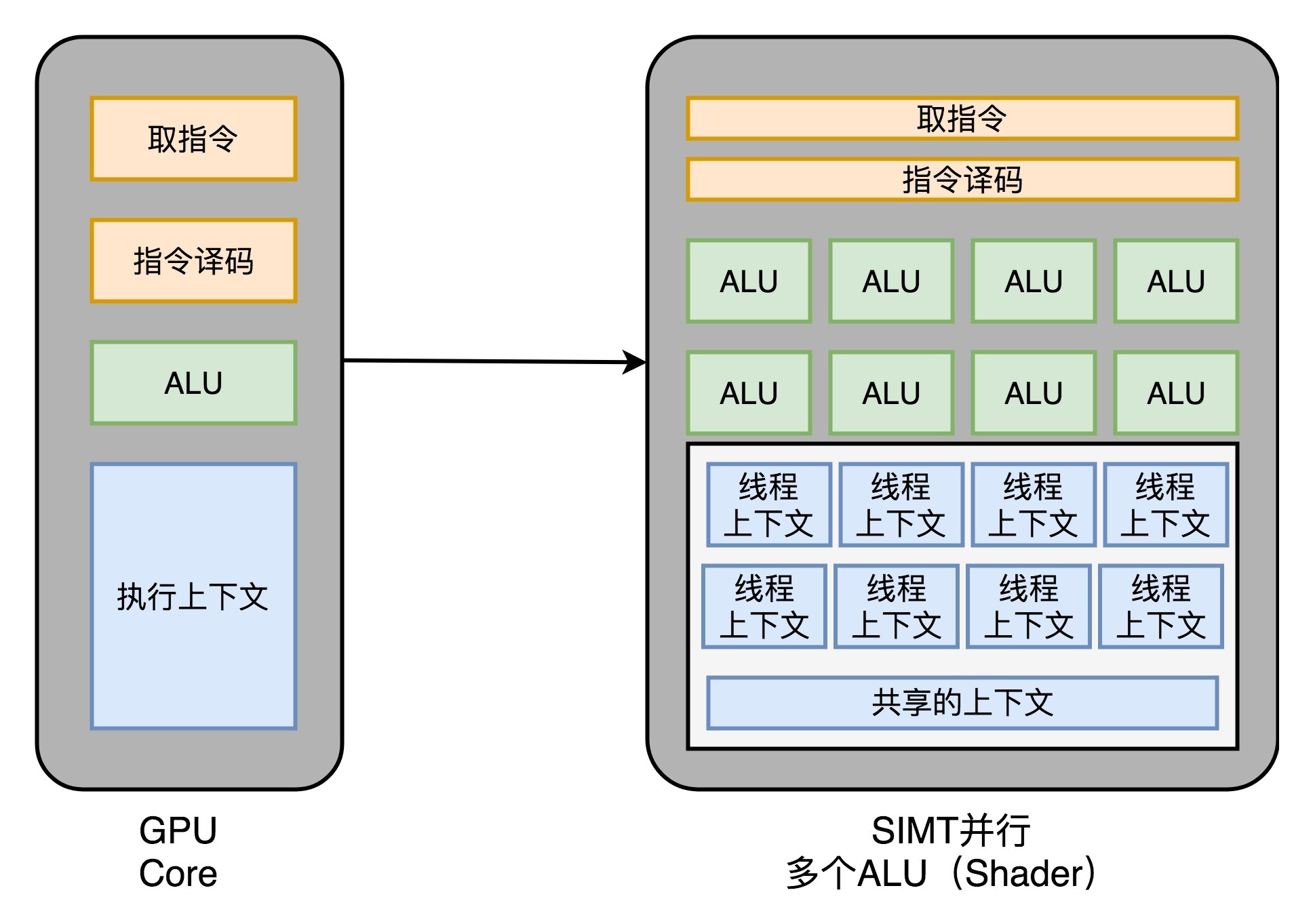
而在GPU里,这些电路就显得有点多余了,GPU的整个处理过程是一个[流式处理](https://en.wikipedia.org/wiki/Stream_processing)(Stream Processing)的过程。因为没有那么多分支条件,或者复杂的依赖关系,我们可以把GPU里这些对应的电路都可以去掉,做一次小小的瘦身,只留下取指令、指令译码、ALU以及执行这些计算需要的寄存器和缓存就好了。一般来说,我们会把这些电路抽象成三个部分,就是下面图里的取指令和指令译码、ALU和执行上下文。
|
||
|
||
|
||
|
||
### 多核并行和SIMT
|
||
|
||
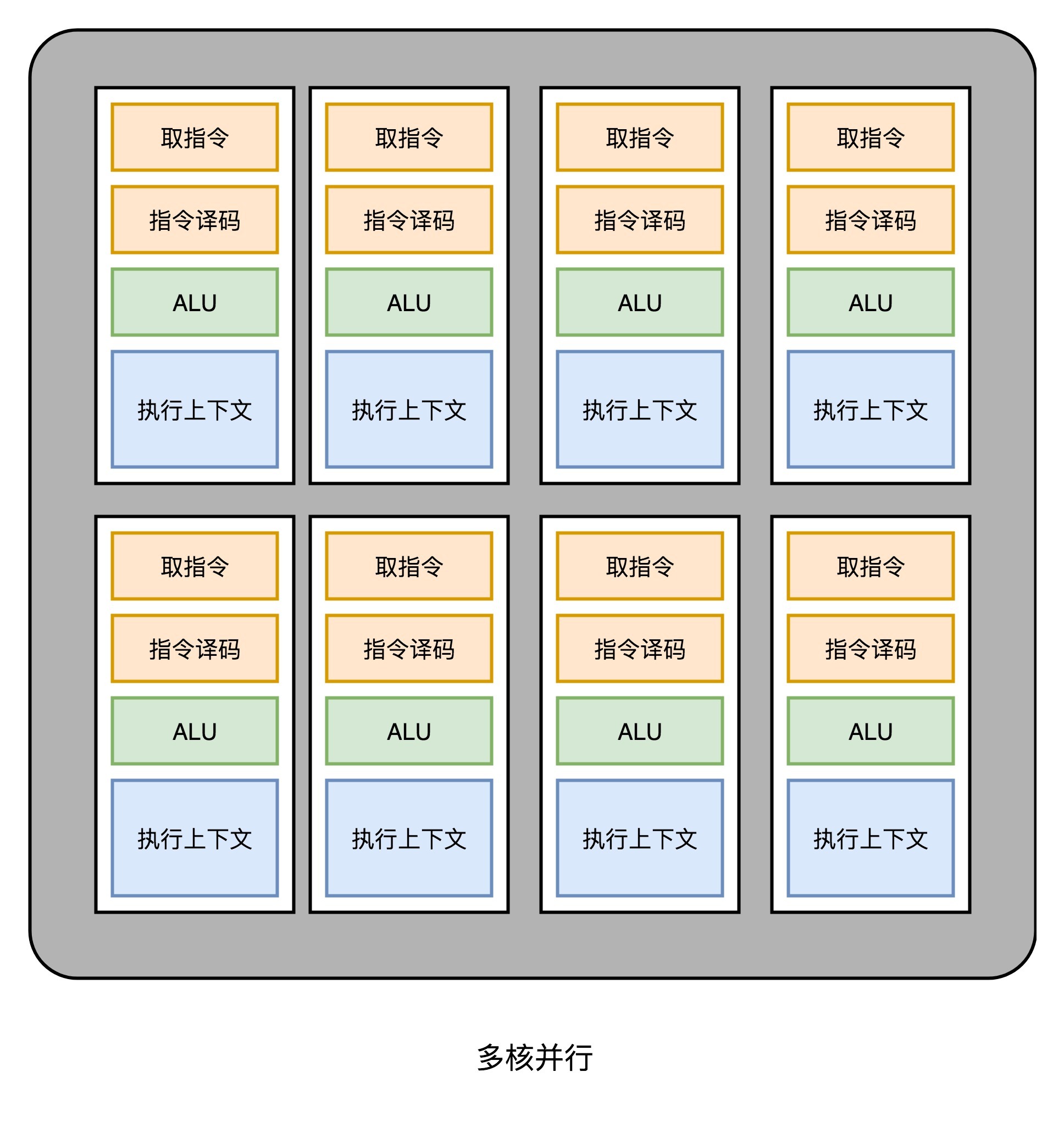
这样一来,我们的GPU电路就比CPU简单很多了。于是,我们就可以在一个GPU里面,塞很多个这样并行的GPU电路来实现计算,就好像CPU里面的多核CPU一样。和CPU不同的是,我们不需要单独去实现什么多线程的计算。因为GPU的运算是天然并行的。
|
||
|
||
|
||
|
||
我们在上一讲里面其实已经看到,无论是对多边形里的顶点进行处理,还是屏幕里面的每一个像素进行处理,每个点的计算都是独立的。所以,简单地添加多核的GPU,就能做到并行加速。不过光这样加速还是不够,工程师们觉得,性能还有进一步被压榨的空间。
|
||
|
||
我们在[第27讲](https://time.geekbang.org/column/article/103433)里面讲过,CPU里有一种叫作SIMD的处理技术。这个技术是说,在做向量计算的时候,我们要执行的指令是一样的,只是同一个指令的数据有所不同而已。在GPU的渲染管线里,这个技术可就大有用处了。
|
||
|
||
无论是顶点去进行线性变换,还是屏幕上临近像素点的光照和上色,都是在用相同的指令流程进行计算。所以,GPU就借鉴了CPU里面的SIMD,用了一种叫作[SIMT](https://en.wikipedia.org/wiki/Single_instruction,_multiple_threads)(Single Instruction,Multiple Threads)的技术。SIMT呢,比SIMD更加灵活。在SIMD里面,CPU一次性取出了固定长度的多个数据,放到寄存器里面,用一个指令去执行。而SIMT,可以把多条数据,交给不同的线程去处理。
|
||
|
||
各个线程里面执行的指令流程是一样的,但是可能根据数据的不同,走到不同的条件分支。这样,相同的代码和相同的流程,可能执行不同的具体的指令。这个线程走到的是if的条件分支,另外一个线程走到的就是else的条件分支了。
|
||
|
||
于是,我们的GPU设计就可以进一步进化,也就是在取指令和指令译码的阶段,取出的指令可以给到后面多个不同的ALU并行进行运算。这样,我们的一个GPU的核里,就可以放下更多的ALU,同时进行更多的并行运算了。
|
||
|
||
|
||
|
||
### GPU里的“超线程”
|
||
|
||
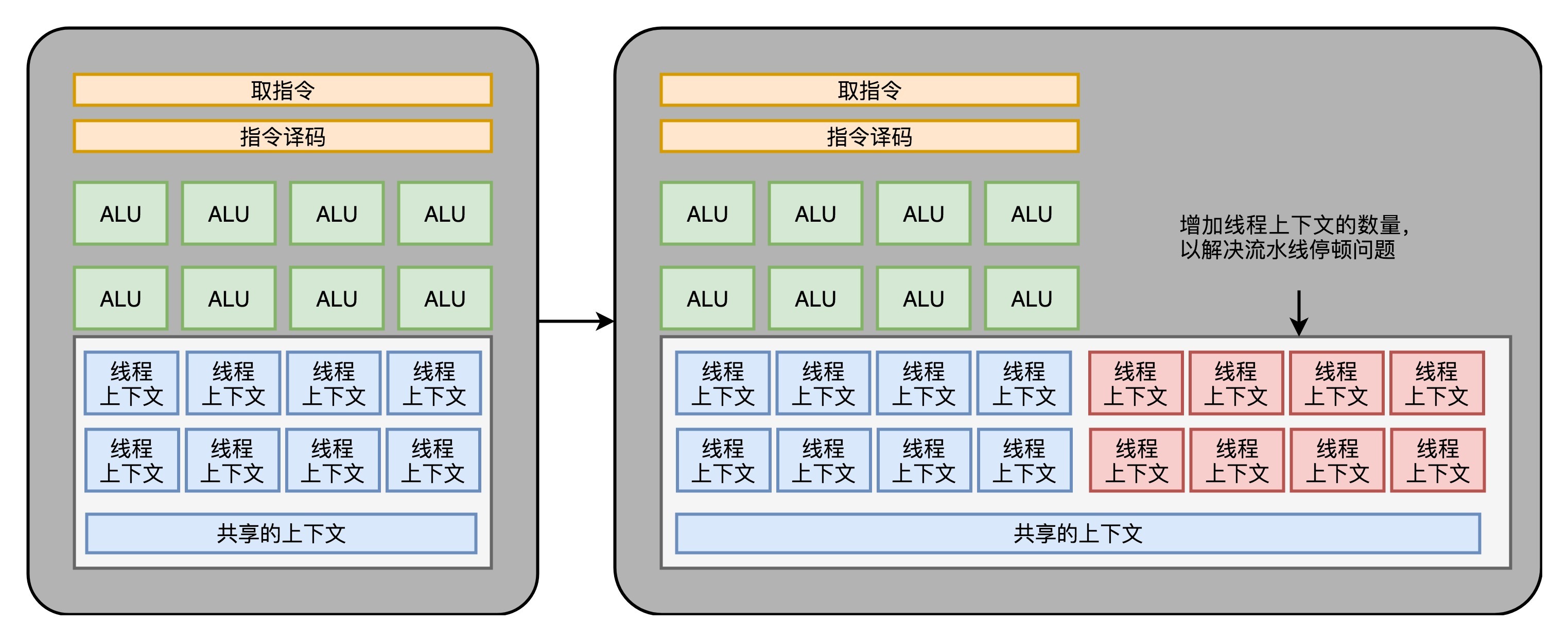
虽然GPU里面的主要以数值计算为主。不过既然已经是一个“通用计算”的架构了,GPU里面也避免不了会有if…else这样的条件分支。但是,在GPU里我们可没有CPU这样的分支预测的电路。这些电路在上面“芯片瘦身”的时候,就已经被我们砍掉了。
|
||
|
||
所以,GPU里的指令,可能会遇到和CPU类似的“流水线停顿”问题。想到流水线停顿,你应该就能记起,我们之前在CPU里面讲过超线程技术。在GPU上,我们一样可以做类似的事情,也就是遇到停顿的时候,调度一些别的计算任务给当前的ALU。
|
||
|
||
和超线程一样,既然要调度一个不同的任务过来,我们就需要针对这个任务,提供更多的**执行上下文**。所以,一个Core里面的**执行上下文**的数量,需要比ALU多。
|
||
|
||
|
||
|
||
## GPU在深度学习上的性能差异
|
||
|
||
在通过芯片瘦身、SIMT以及更多的执行上下文,我们就有了一个更擅长并行进行暴力运算的GPU。这样的芯片,也正适合我们今天的深度学习的使用场景。
|
||
|
||
一方面,GPU是一个可以进行“通用计算”的框架,我们可以通过编程,在GPU上实现不同的算法。另一方面,现在的深度学习计算,都是超大的向量和矩阵,海量的训练样本的计算。整个计算过程中,没有复杂的逻辑和分支,非常适合GPU这样并行、计算能力强的架构。
|
||
|
||
我们去看NVidia 2080显卡的[技术规格](https://www.techpowerup.com/gpu-specs/geforce-rtx-2080.c3224),就可以算出,它到底有多大的计算能力。
|
||
|
||
2080一共有46个SM(Streaming Multiprocessor,流式处理器),这个SM相当于GPU里面的GPU Core,所以你可以认为这是一个46核的GPU,有46个取指令指令译码的渲染管线。每个SM里面有64个Cuda Core。你可以认为,这里的Cuda Core就是我们上面说的ALU的数量或者Pixel Shader的数量,46x64呢一共就有2944个Shader。然后,还有184个TMU,TMU就是Texture Mapping Unit,也就是用来做纹理映射的计算单元,它也可以认为是另一种类型的Shader。
|
||
|
||

|
||
|
||
[图片来源](https://www.anandtech.com/show/13282/nvidia-turing-architecture-deep-dive/7)
|
||
|
||
2080 Super显卡有48个SM,比普通版的2080多2个。每个SM(SM也就是GPU Core)里有64个Cuda Core,也就是Shader
|
||
|
||
2080的主频是1515MHz,如果自动超频(Boost)的话,可以到1700MHz。而NVidia的显卡,根据硬件架构的设计,每个时钟周期可以执行两条指令。所以,能做的浮点数运算的能力,就是:
|
||
|
||
(2944 + 184)× 1700 MHz × 2 = 10.06 TFLOPS
|
||
|
||
对照一下官方的技术规格,正好就是10.07TFLOPS。
|
||
|
||
那么,最新的Intel i9 9900K的性能是多少呢?不到1TFLOPS。而2080显卡和9900K的价格却是差不多的。所以,在实际进行深度学习的过程中,用GPU所花费的时间,往往能减少一到两个数量级。而大型的深度学习模型计算,往往又是多卡并行,要花上几天乃至几个月。这个时候,用CPU显然就不合适了。
|
||
|
||
今天,随着GPGPU的推出,GPU已经不只是一个图形计算设备,更是一个用来做数值计算的好工具了。同样,也是因为GPU的快速发展,带来了过去10年深度学习的繁荣。
|
||
|
||
## 总结延伸
|
||
|
||
这一讲里面,我们讲了,GPU一开始是没有“可编程”能力的,程序员们只能够通过配置来设计需要用到的图形渲染效果。随着“可编程管线”的出现,程序员们可以在顶点处理和片段处理去实现自己的算法。为了进一步去提升GPU硬件里面的芯片利用率,微软在XBox 360里面,第一次引入了“统一着色器架构”,使得GPU变成了一个有“通用计算”能力的架构。
|
||
|
||
接着,我们从一个CPU的硬件电路出发,去掉了对GPU没有什么用的分支预测和乱序执行电路,来进行瘦身。之后,基于渲染管线里面顶点处理和片段处理就是天然可以并行的了。我们在GPU里面可以加上很多个核。
|
||
|
||
又因为我们的渲染管线里面,整个指令流程是相同的,我们又引入了和CPU里的SIMD类似的SIMT架构。这个改动,进一步增加了GPU里面的ALU的数量。最后,为了能够让GPU不要遭遇流水线停顿,我们又在同一个GPU的计算核里面,加上了更多的执行上下文,让GPU始终保持繁忙。
|
||
|
||
GPU里面的多核、多ALU,加上多Context,使得它的并行能力极强。同样架构的GPU,如果光是做数值计算的话,算力在同样价格的CPU的十倍以上。而这个强大计算能力,以及“统一着色器架构”,使得GPU非常适合进行深度学习的计算模式,也就是海量计算,容易并行,并且没有太多的控制分支逻辑。
|
||
|
||
使用GPU进行深度学习,往往能够把深度学习算法的训练时间,缩短一个,乃至两个数量级。而GPU现在也越来越多地用在各种科学计算和机器学习上,而不仅仅是用在图形渲染上了。
|
||
|
||
## 推荐阅读
|
||
|
||
关于现代GPU的工作原理,你可以仔细阅读一下 haifux.org 上的这个[PPT](http://haifux.org/lectures/267/Introduction-to-GPUs.pdf),里面图文并茂地解释了现代GPU的架构设计的思路。
|
||
|
||
## 课后思考
|
||
|
||
上面我给你算了NVidia 2080显卡的FLOPS,你可以尝试算一下9900K CPU的FLOPS。
|
||
|
||
欢迎在留言区写下你的答案,你也可以把今天的内容分享给你的朋友,和他一起学习和进步。
|
||
|