17 KiB
35|内存管理第2关:实现垃圾回收
你好,我是宫文学。
今天这节课,我们继续上一节课未完成的内容,完成垃圾回收功能。
在上一节课,我们已经实现了一个基于Arena做内存分配的模块。并且,我们还在可执行程序里保存了函数、类和闭包相关的元数据信息。
有了上一节课的基础之后,我们这节课就能正式编写垃圾回收的算法了。算法思路是这样的:
- 首先,我们要有一个种机制来触发垃圾回收,进入垃圾回收的处理程序;
- 第二,我们要基于元数据信息来遍历栈帧,找到所有的GC根;
- 第三,从每个GC根出发,我们需要去标记GC根直接和间接引用的内存对象;
- 最后,我们再基于对象的标记信息,来回收内存垃圾。
在今天这节课,你不仅仅会掌握标记-清除算法,其中涉及的知识点,也会让你能够更容易地实现其他垃圾回收算法,并且让我们的程序能更好地与运行时功能相配合。
那接下来,我们就顺着算法实现思路,看看如何启动垃圾回收机制。
启动垃圾回收机制
在现代的计算机语言中,我们可以有各种策略来启动垃圾回收机制。比如,在申请内存时,如果内存不足,就可以触发垃圾回收。甚至,你也可以每隔一段时间就触发一下垃圾收集。不过不论采取哪种机制,我们首先要有办法从程序的正常执行流程,进入垃圾回收程序才行。
进入垃圾回收程序,其实有一个经常使用的时机,就是在函数返回的时候。这个时候,我们可以不像平常那样,使用retq跳回调用者,而是先去检查是否需要做垃圾回收:如果需要做垃圾回收,那就先回收完垃圾,再返回到原来函数的调用者;如果不需要做垃圾回收,那就直接跳转到函数的调用者。
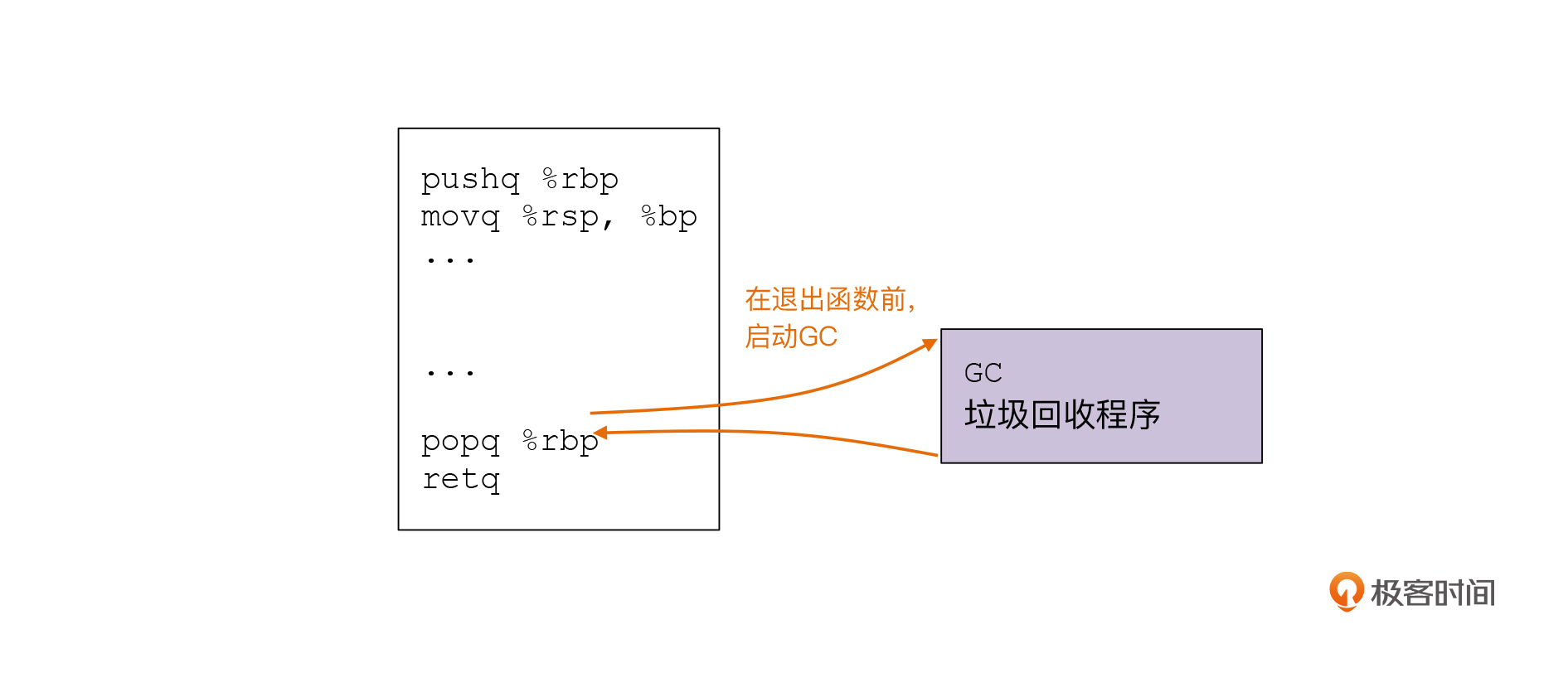
实现这个功能很简单,只需要在return语句之前调用frame_walker这个内置函数,并把当前%rbp寄存器的值作为参数传进去就好了:
visitReturnStatement(rtnStmt:ReturnStatement):any{
if (rtnStmt.exp!=null){
let ret = this.visit(rtnStmt.exp) as Oprand;
//调用一个内置函数,来做垃圾回收
this.callBuiltIns("frame_walker",[Register.rbp]);//把当前%rbp的值传进去
//把返回值赋给相应的寄存器
let dataType = getCpuDataType(rtnStmt.exp.theType as Type);
this.movIfNotSame(dataType, ret, Register.returnReg(dataType));
...
}
}
这样,我们就能获得调用GC程序的时机。
在这段代码中,frame_walker内置函数的功能是遍历整个调用栈。这就是我们启动垃圾回收机制后,要进行的下一个任务。接下来我们就来分析一下具体怎么做。
遍历栈帧和对象
遍历栈帧其实很简单,因为我们能够知道每个栈帧的起始地址。从哪里知道呢?就是rbp寄存器。rbp寄存器里保存的是每个栈帧的底部地址。
每次新建立一个栈帧的时候,我们总是把前一个栈帧的rbp值保护起来,这就是你在每个函数开头看到的第一行指令:pushq %rbp。因此,我们从栈帧里的第一个8字节区域,就可以读出前一个栈帧的%rbp值,这就意味着我们得到了前一个栈帧的栈底。然后你可以到这个位置,再继续获取更前一个栈帧的地址。具体你可以看下面这张图:
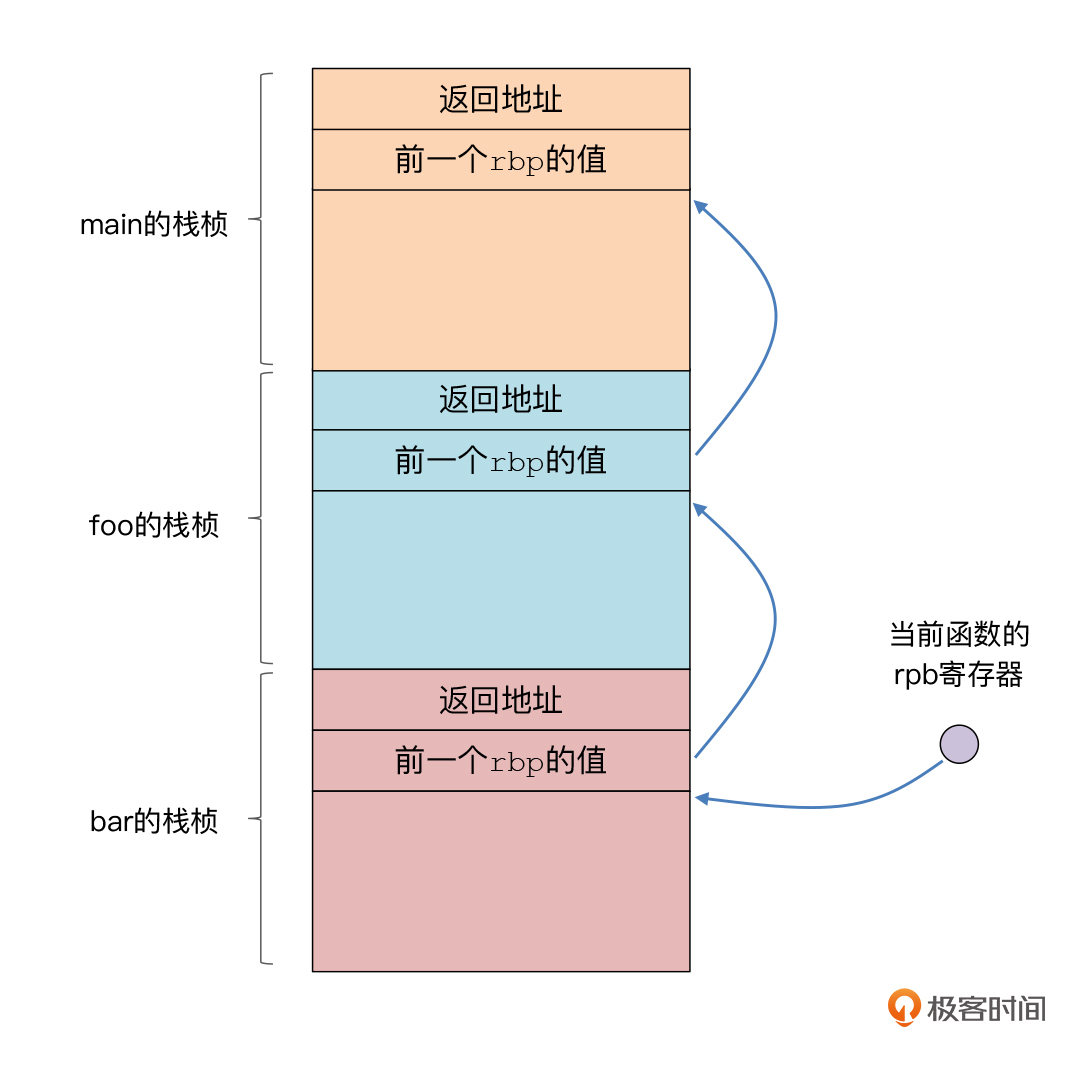
那这个思路真的有用吗?我们直接动手试一下!
首先,我写了一个简单的测试程序。在这个程序里,main函数调用了foo,foo又调用了bar。这样,在foo和bar返回前,我们都可以启动垃圾回收,但从main函数返回的时候就没有必要启动了,因为这个时候进程结束,进程从操作系统申请的所有内存,都会还给操作系统。
function foo(a:number):string{
let s:string = "PlayScript!"
let b:number = bar(a+5);
return s;
}
function bar(b:number):number{
let a:number[] = [1,2,b];
let s:string = "Hello";
println(s);
println(a[2]);
b = b*10;
return b;
}
println(foo(2));
接下来,我又写了一个frame_walker.c的程序。这个程序很简单,就是依次打印出每个栈帧所保存的rbp寄存器的地址。在程序里,rbpValue0是调用frame_walker.c程序的函数的rbp值,这个值是当前栈帧的底部。在这个地址里,保存的是前一个栈帧原来的rbp值,也就是前一个栈帧的rbp的地址,依次类推。
//遍历栈帧
void frame_walker(unsigned long rbpValue0){
//当前栈帧的rbp值
printf("\nrbpValue0:\t0x%lx(%ld)\n", rbpValue0, rbpValue0);
//往前一个栈帧的rbp值
unsigned long rbpValue1 = *(unsigned long*)rbpValue0;
printf("rbpValue1:\t0x%lx(%ld)\n", rbpValue1, rbpValue1);
//再往前一个栈帧
unsigned long rbpValue2 = *(unsigned long*)rbpValue1;
printf("rbpValue2:\t0x%lx(%ld)\n", rbpValue2, rbpValue2);
//再往前一个栈帧
unsigned long rbpValue3 = *(unsigned long*)rbpValue2;
printf("rbpValue3:\t0x%lx(%ld)\n", rbpValue3, rbpValue3);
//再往前一个栈帧
unsigned long rbpValue4 = *(unsigned long*)rbpValue3;
printf("rbpValue4:\t0x%lx(%ld)\n", rbpValue4, rbpValue4);
}
最后,你可以用make example_gc命令,编译成可执行文件。运行这个可执行文件,会打印出下面的输出内容:
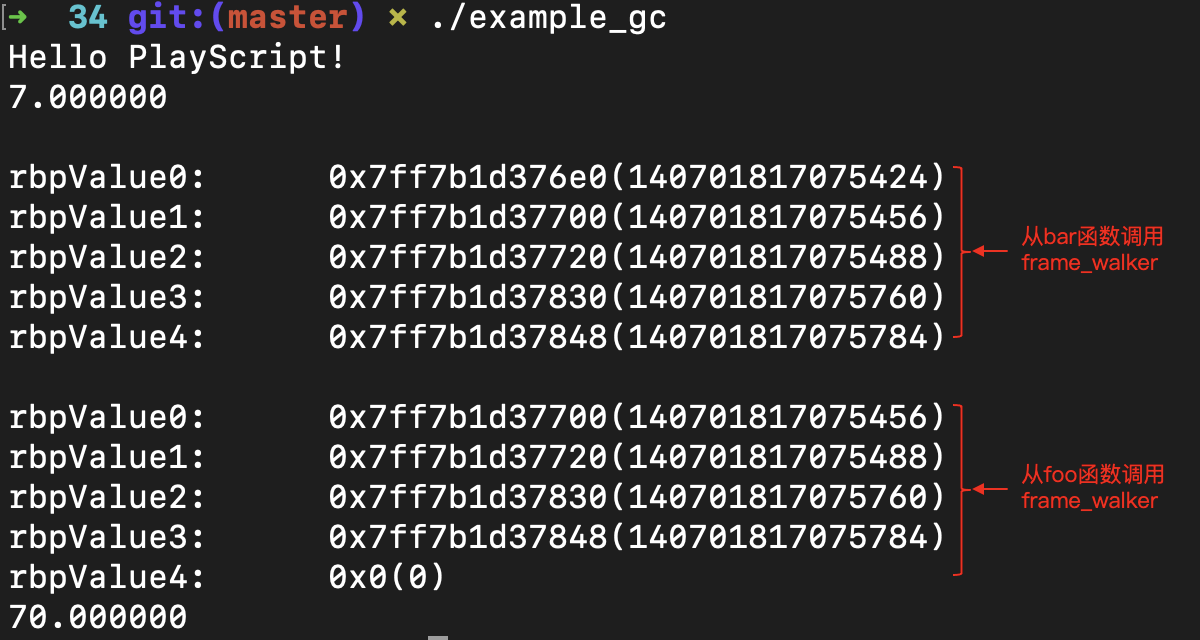
你可能注意到了,frame_walker一共打印了5个栈帧的rbp值。但是我们的程序最多的时候也只用到了3个栈帧呀,那之前更多的那些栈帧是什么呢?这个问题我留给你,看看你能不能用操作系统的知识来回答这个问题。
但目前,我们还只是能找到每个栈帧,接下来我们还要进一步解析栈帧里的内容,从而找到GC根,并经由GC跟查找到内存对象。这就需要我们查找函数的元数据了。
这时候你会发现,为了查找函数的元数据,我们必须知道每个栈帧是由哪个函数生成的。这个问题我们在闭包的那一节课也曾经讨论过,正好在这里实现。
具体实现起来倒也不复杂。我们可以约定,在栈帧的一开头、紧挨着保存%rbp寄存器的信息的下面,保存该函数的元数据区的指针。这样,每个函数的汇编代码的序曲部分就会像下面那样。其中,后两行代码就是用来保存meta区的地址的:
pushq %rbp
movq %rsp, %rbp
movq _foo.meta@GOTPCREL(%rip), %rax
movq %rax, -8(%rbp)
在这里,“_foo.meta@GOTPCREL(%rip)”是使用相对于%rip寄存器的偏移量,也就是通过下一行代码地址的偏移量来确定_foo.meta标签的地址的。
我们曾经也用过相对于%rip寄存器寻址的方式,比如获取double型字面量。你会发现这里有一点不同,当时我们并没有“@GOTPCREL”这一小段文字。这里会涉及到链接器和代码定位的一些技术细节。在这里,你可以理解为,因为我们把这些元数据声明在数据段,而不是像double字面量一样声明在文本段,所以就要用到一个不同的定位方式就行了。
好了,现在我们可以从每个函数的栈帧出发,来找到函数的元数据了。所以,我又写了一个新版本的frame_walker函数,来访问函数元数据,打印出每个栈帧里的变量的情况。我们给这个函数传递的参数,是当前栈帧rbp的值。
void frame_walker(unsigned long rbpValue){
printf("\nwalking the stack:\n");
while(1){
//rbp寄存器的值,也就是栈底的地址
printf("rbp value:\t\t\t0x%lx(%ld)\n", rbpValue, rbpValue);
//函数元数据区的地址
unsigned long metaAddress = *(unsigned long*)(rbpValue -8);
printf("address of function meta:\t0x%lx(%ld)\n", metaAddress, metaAddress);
//函数名称的地址,位于元数据区的第一个位置
unsigned long pFunName = *(unsigned long*)metaAddress;
printf("address of function name:\t0x%lx(%ld)\n", pFunName,pFunName);
//到函数名称区,去获取函数名称
const char* funName = (const char*)pFunName;
printf("function name:\t\t\t%s\n", funName);
//变量数量,位于元数据区的第二个位置
unsigned long numVars = *(unsigned long*)(metaAddress+8);
printf("number of vars:\t\t\t%ld\n", numVars);
//遍历所有的变量
for (int i = 0; i< numVars; i++){
//获取变量属性的压缩格式,3个属性压缩到了8个字节中
unsigned long varAttr = *(unsigned long*)(metaAddress+8*(i+2));
printf("var attribute(compact):\t\t0x%lx(%ld)\n", varAttr,varAttr);
//拆解出变量的属性
unsigned long varIndex = varAttr>>32; //变量下标,4个字节
unsigned long typeTag = (varAttr>>24) & 0x00000000000000ff; //变量类型编号,1个字节
unsigned long offset = varAttr & 0x0000000000ffffff; //变量在栈帧中的地址偏移量
printf("var attribute(decoded):\t\tvarIndex:%ld, typeTag:%ld, offset:%ld\n", varIndex, typeTag, offset);
}
//去遍历上一个栈帧
rbpValue = *(unsigned long*)rbpValue;
printf("\n");
//如果遇到main函数,则退出
if (strcmp(funName, "main")==0) break;
}
}
再次编译并运行,就会打印出每个函数栈帧里的信息。这些信息是在bar函数快要返回的时候,遍历各个栈帧打印出来的。从这些信息里,你能够清晰地看到每个函数的栈帧里保存了哪些变量,还有每个变量在栈帧中的位置和每个变量的类型。
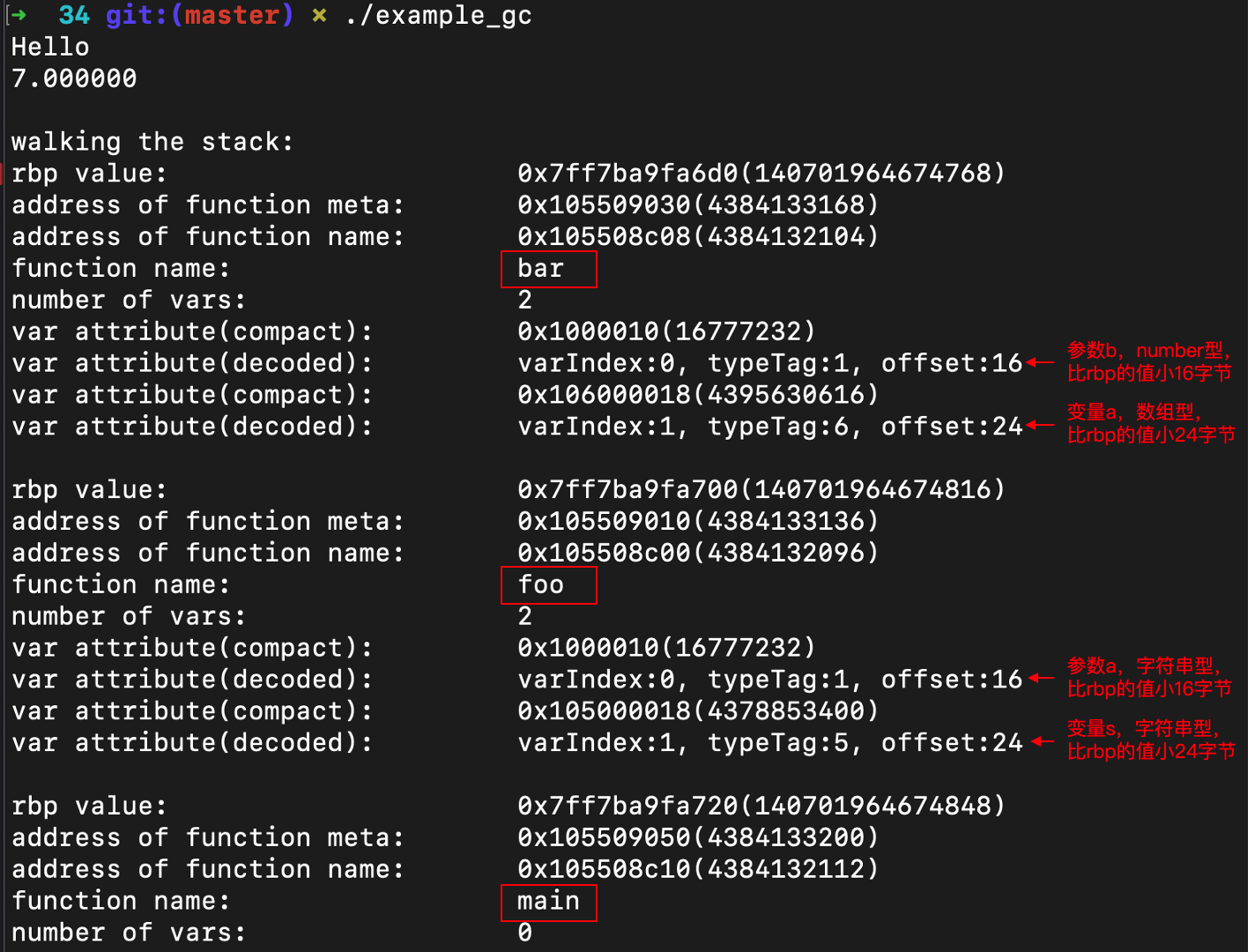
**接着我们来找GC根和它直接引用的对象。**你可以看到,bar函数的栈帧里一共有2个变量,分别是参数b和变量a。其中参数b是整型的,所以不是GC根。而变量a是一个数组,它是GC根,所以我们要标记该数组对象为活跃的。而foo函数的栈帧里也有两个变量,分别是参数a和变量s。
不过,看到这个结果,你肯定会产生一些疑问。首先,为什么bar函数里字符串变量s没有出现在栈帧里,而foo函数里同样的字符串变量s却出现在了栈桢里呢?
这是因为,在bar函数要返回的时刻,字符串s已经被bar函数使用完毕了,变成内存垃圾了。而foo函数现在是执行到第二个语句,并且调用了bar函数。在从bar函数返回以后,它还要在第三条语句中用到字符串变量s,所以s仍然是alive的,需要被保存下来。
bar函数里的参数b也是一样的,因为它是被return语句引用的,所以在返回之前,仍然是alive。
那可能你又要问了,不对呀,按照这么说,bar函数中的数组变量a和foo函数中的参数a,应该都没有用了呀,不用去遍历了呀。特别是bar函数中的数组,应该作为内存垃圾回收了才对。
没错,这是我们当前算法的缺陷。我们没有去保存变量活跃性分析的结果,也就是说在每一行代码处,到底哪些变量是活跃的,我们是不知道的。这样,我们也就没有办法精确地判断哪些变量其实已经失效了。并且,其实我们也没有办法精确地判断,每个函数现在执行到了哪一行代码,哪些代码是活跃的。
所以,我们这里用了一个近似的算法:只要是曾经被spill到栈帧里的变量,我们都认为它们是值得被保护的,还是活跃的。这个算法其实这在实际的应用中已经足够了。
那既然找到了对象引用,接下来我们就可以标记这个对象了。在每个对象的头部,我们都预留了8个字节的空间,用来设置各种标志位。这8个字节,在一开始申请内存的时候,都被设置成了0。我们现在要做的也比较简单,只需要把第一位作为“是否是内存垃圾”的标记位就好了。如果该标志位为1,那就说明这对象是有用的,不能回收。如果是0,那么就说明它是内存垃圾。
好了,现在我们已经完成了最复杂的任务,也就是遍历栈帧,找到并标记对象引用。接下来,我们还要基于这些对象,进一步找出它们所引用的其他内存对象。
在这一部分,针对自定义对象、数组和闭包,我们都需要编写相对应的遍历方法,但原理跟前面我们遍历函数寻找GC根是一致的,都是去查找元数据,这里我就不一一展开了,你可以去看mem.c中的源代码。
现在标记完所有的对象以后,接下来的事情就简单了。接下来,我们可以遍历Arena中的每个内存块,然后再在内存块里遍历每一个对象,把没有标记的对象删掉。对于标记过的对象,我们就要把它的标记去掉,为下一次垃圾收集做好准备。
好了到这里,我们相关算法的实现思路已经梳理清楚了。现在是时候验证我们的成果了,我们内存管理的相关算法到底是否能成功呢?
测试垃圾回收算法
我们直接运行程序,来检验一下。你可以运行命令make example_gc,生成可执行程序,并运行它,会得到如下输出结果:
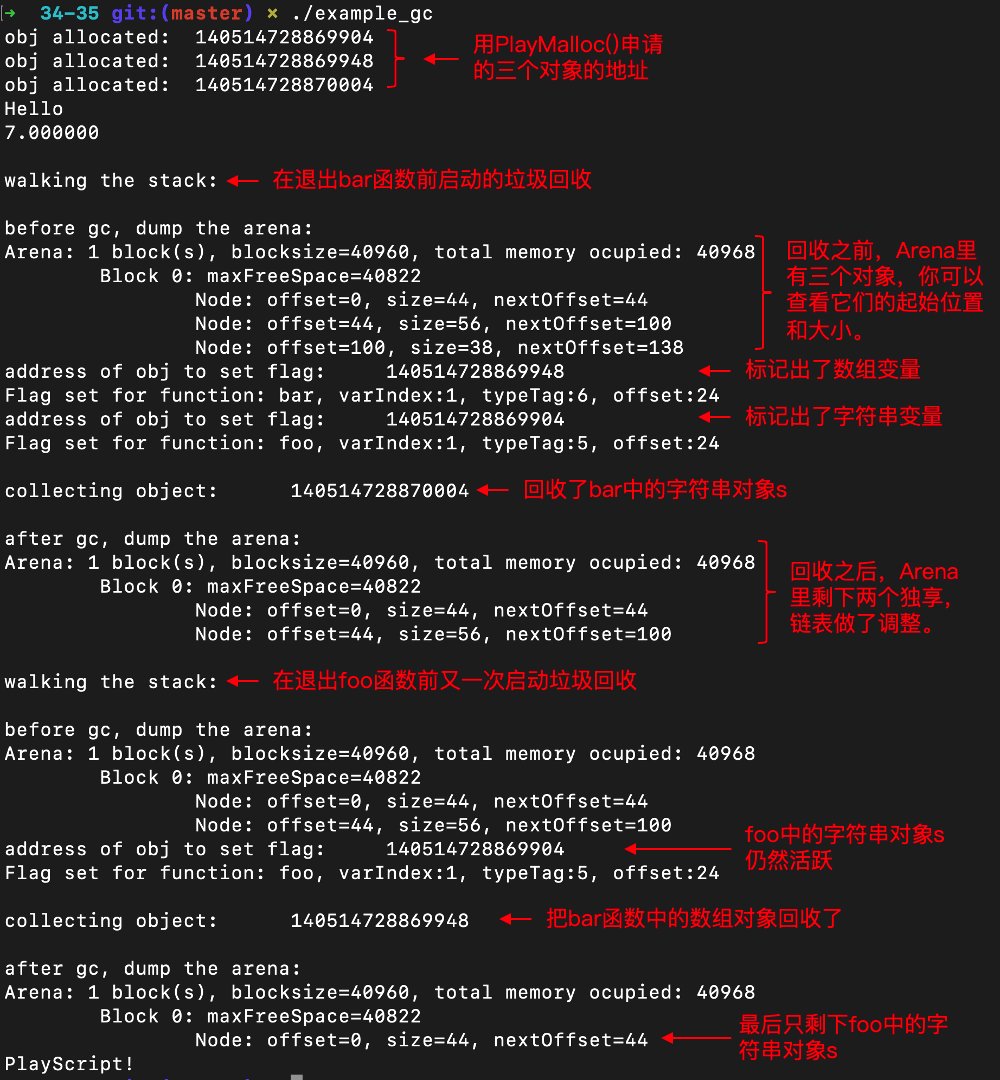
你可以看到,程序bar函数和foo函数结束的时候,分别释放了一些内存垃圾。并且,每次申请内存和垃圾回收,GC都打印出了当前Arena中的信息,你会看到Arena中内存分配的详细信息。在做完垃圾回收以后,相关内存空间确实被释放掉了。
也就是说,我们的垃圾回收算法算是圆满成功了!
课程小结
今天这一节课,我们接着上一节完成了垃圾回收算法。我希望你能记住几个要点:
第一,我们有很多种方式可以启动垃圾回收机制。在这里,我们用了最简单的一种方式,也就是在退出函数前触发垃圾回收机制。类似的,你还可以在循环语句的地方检查是否需要做垃圾回收,因为程序中的循环可能会耗费很长的时间,积累很多内存垃圾。这里,我们的程序和运行时就形成了一种协作机制。
其实这种协作机制,也是实现另一个重要的运行时功能,并发管理的基础,特别是协程机制,需要当前程序与协程的调度器主动配合,才能完成细颗粒度的并发调度。你从这节课中,应该会直观地感受到这些运行时的调度机制是怎么运作的。
第二,我们是通过查询栈帧的布局信息去寻找GC根的。我们可以认为,没有出现在栈帧布局中的变量,肯定是已经失效了的。而出现在栈帧布局中的变量,有些其实也已经失效了,但我们当前没有必要去做更加精细化地管控。
第三,这节课示范了如何具体访问各种元数据信息。这些技能很重要,能让你可以在可执行文件里自由地存放各种自己需要的静态数据,让程序的运行机制拥有更多的可能性。
最后,我们通过两节课实现了内存分配和垃圾回收的工作。虽然实现得比较简单,但却是一个良好的开始。你在此基础上,可以更快地实现其他的算法。比如,你可以把内存整理一下,减少内存碎片,这样就是实现了标记-整理算法。你还可以把所有分配了的内存对象拷贝到一个新的区域,这就实现了停止-拷贝算法,也就是Java等语言普遍采用的算法。
不过,当你在内存中移动对象的时候,又会遇到新的技术挑战。比如,你需要知道栈帧中的哪些变量是引用了这个对象,再来更新这些值。再比如,当你的程序正在读写一个数组的时候,整个数组却被GC挪到了另一个位置,那与数组处理有关的功能就可能会出错。当然,这些技术点也都有解决办法,相关的书籍和文章已经有很多。但有了我们这两节的基础,你可以自己动手来验证这些知识点了。
在作为开源项目的PlayScript代码库中,我会继续迭代、修改与垃圾收集有关的算法,如果你有兴趣可以继续一起研究。
思考题
在这节课的示例程序中,为了启动垃圾回收机制,我采用了一个普通的函数调用的方式。但是,有没有办法对这个方式进行优化?比如,因为当前函数要退出了,除了返回值,其他变量都不用检查了。再比如,这个函数的栈桢也可以被垃圾回收函数复用,就像尾调用优化那样。我想问一下,你要如何修改现有的调用垃圾回收函数的机制,才能实现上面的优化呢?
欢迎把这节课分享给更多对内存管理感兴趣的朋友。我是宫文学,我们下节课见。