|
|
# 13 | 弹性分布式数据集:Spark大厦的地基(上)
|
|
|
|
|
|
你好,我是蔡元楠。
|
|
|
|
|
|
今天我要与你分享的主题是“弹性分布式数据集”。
|
|
|
|
|
|
上一讲中提到,Spark最基本的数据抽象是弹性分布式数据集(Resilient Distributed Dataset, 下文用RDD代指)。
|
|
|
|
|
|
Spark基于RDD定义了很多数据操作,从而使得数据处理的代码十分简洁、高效。所以,要想深入学习Spark,我们必须首先理解RDD的设计思想和特性。
|
|
|
|
|
|
## 为什么需要新的数据抽象模型?
|
|
|
|
|
|
传统的MapReduce框架之所以运行速度缓慢,很重要的原因就是有向无环图的中间计算结果需要写入硬盘这样的稳定存储介质中来防止运行结果丢失。
|
|
|
|
|
|
而每次调用中间计算结果都需要要进行一次硬盘的读取,反复对硬盘进行读写操作以及潜在的数据复制和序列化操作大大提高了计算的延迟。
|
|
|
|
|
|
因此,很多研究人员试图提出一个新的分布式存储方案,不仅保持之前系统的稳定性、错误恢复和可扩展性,还要尽可能地减少硬盘I/O操作。
|
|
|
|
|
|
一个可行的设想就是在分布式内存中,存储中间计算的结果,因为对内存的读写操作速度远快于硬盘。而RDD就是一个基于分布式内存的数据抽象,它不仅支持基于工作集的应用,同时具有数据流模型的特点。
|
|
|
|
|
|
## RDD的定义
|
|
|
|
|
|
弹性分布式数据集是英文直译的名字,乍一看这个名字相信你会不知所云。如果你去Google或者百度搜索它的定义,你会得到如下结果:
|
|
|
|
|
|
**RDD表示已被分区、不可变的,并能够被并行操作的数据集合。**
|
|
|
|
|
|
这个定义很不直观,我认识的很多Spark初学者在查阅了很多资料后还是对RDD一头雾水,很难理解这个抽象的概念。接下来,让我们一起来对这个晦涩的概念抽丝剥茧,见其真义。
|
|
|
|
|
|
在上述定义以及RDD的中文译名中,我们不难发现,RDD有以下基本特性:分区、不可变和并行操作。接下来让我分别讲解这些特点。
|
|
|
|
|
|
### 分区
|
|
|
|
|
|
顾名思义,分区代表同一个RDD包含的数据被存储在系统的不同节点中,这也是它可以被并行处理的前提。
|
|
|
|
|
|
逻辑上,我们可以认为RDD是一个大的数组。数组中的每个元素代表一个分区(Partition)。
|
|
|
|
|
|
在物理存储中,每个分区指向一个存放在内存或者硬盘中的数据块(Block),而这些数据块是独立的,它们可以被存放在系统中的不同节点。
|
|
|
|
|
|
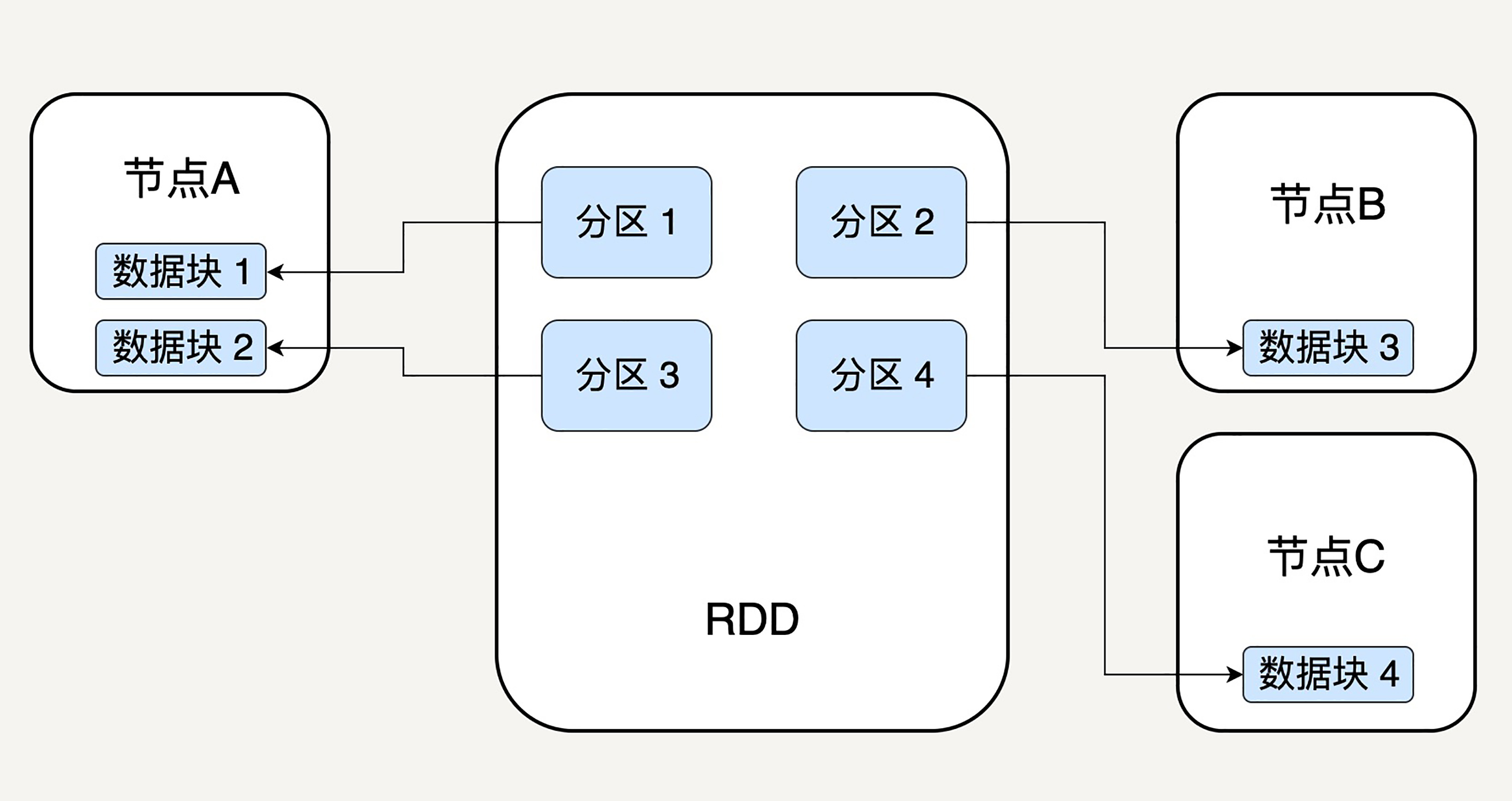
所以,RDD只是抽象意义的数据集合,分区内部并不会存储具体的数据。下图很好地展示了RDD的分区逻辑结构:
|
|
|
|
|
|
|
|
|
|
|
|
RDD中的每个分区存有它在该RDD中的index。通过RDD的ID和分区的index可以唯一确定对应数据块的编号,从而通过底层存储层的接口中提取到数据进行处理。
|
|
|
|
|
|
在集群中,各个节点上的数据块会尽可能地存放在内存中,只有当内存没有空间时才会存入硬盘。这样可以最大化地减少硬盘读写的开销。
|
|
|
|
|
|
虽然 RDD 内部存储的数据是只读的,但是,我们可以去修改(例如通过 repartition 转换操作)并行计算单元的划分结构,也就是分区的数量。
|
|
|
|
|
|
### 不可变性
|
|
|
|
|
|
不可变性代表每一个RDD都是只读的,它所包含的分区信息不可以被改变。既然已有的RDD不可以被改变,我们只可以对现有的RDD进行**转换**(Transformation)操作,得到新的RDD作为中间计算的结果。从某种程度上讲,RDD与函数式编程的Collection很相似。
|
|
|
|
|
|
```
|
|
|
lines = sc.textFile("data.txt")
|
|
|
lineLengths = lines.map(lambda s: len(s))
|
|
|
totalLength = lineLengths.reduce(lambda a, b: a + b)
|
|
|
|
|
|
```
|
|
|
|
|
|
在上述的简单例子中,我们首先读入文本文件data.txt,创建了第一个RDD lines,它的每一个元素是一行文本。然后调用map函数去映射产生第二个RDD lineLengths,每个元素代表每一行简单文本的字数。最后调用reduce函数去得到第三个RDD totalLength,它只有一个元素,代表整个文本的总字数。
|
|
|
|
|
|
那么这样会带来什么好处呢?显然,对于代表中间结果的RDD,我们需要记录它是通过哪个RDD进行哪些转换操作得来,即**依赖关系**,而不用立刻去具体存储计算出的数据本身。
|
|
|
|
|
|
这样做有助于提升Spark的计算效率,并且使错误恢复更加容易。
|
|
|
|
|
|
试想,在一个有N步的计算模型中,如果记载第N步输出RDD的节点发生故障,数据丢失,我们可以从第N-1步的RDD出发,再次计算,而无需重复整个N步计算过程。这样的容错特性也是RDD为什么是一个“弹性”的数据集的原因之一。后边我们会提到RDD如何存储这样的依赖关系。
|
|
|
|
|
|
### 并行操作
|
|
|
|
|
|
由于单个RDD的分区特性,使得它天然支持并行操作,即不同节点上的数据可以被分别处理,然后产生一个新的RDD。
|
|
|
|
|
|
## RDD的结构
|
|
|
|
|
|
通过上述讲解,我们了解了RDD的基本特性——分区、不可变和并行计算。而且,我们还提到每一个RDD里都会包括分区信息、所依赖的父RDD以及通过怎样的转换操作才能由父RDD得来等信息。
|
|
|
|
|
|
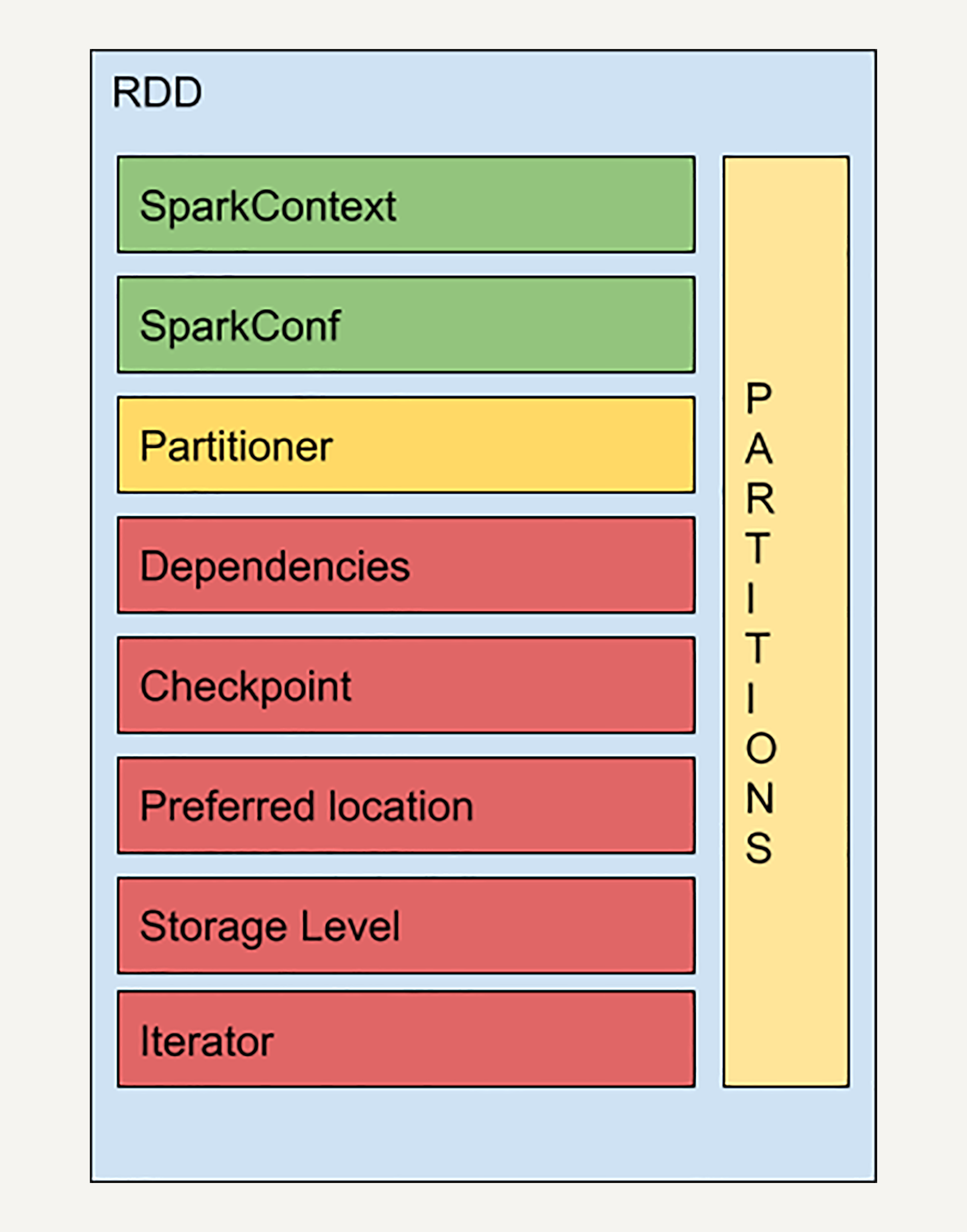
实际上RDD的结构远比你想象的要复杂,让我们来看一个RDD的简易结构示意图:
|
|
|
|
|
|
|
|
|
|
|
|
SparkContext是所有Spark功能的入口,它代表了与Spark节点的连接,可以用来创建RDD对象以及在节点中的广播变量等。一个线程只有一个SparkContext。SparkConf则是一些参数配置信息。感兴趣的同学可以去阅读官方的技术文档,一些相对不重要的概念我就不再赘述了。
|
|
|
|
|
|
Partitions前文中我已经提到过,它代表RDD中数据的逻辑结构,每个Partition会映射到某个节点内存或硬盘的一个数据块。
|
|
|
|
|
|
Partitioner决定了RDD的分区方式,目前有两种主流的分区方式:Hash partitioner和Range partitioner。Hash,顾名思义就是对数据的Key进行散列分区,Range则是按照Key的排序进行均匀分区。此外我们还可以创建自定义的Partitioner。
|
|
|
|
|
|
### 依赖关系
|
|
|
|
|
|
Dependencies是RDD中最重要的组件之一。如前文所说,Spark不需要将每个中间计算结果进行数据复制以防数据丢失,因为每一步产生的RDD里都会存储它的依赖关系,即它是通过哪个RDD经过哪个转换操作得到的。
|
|
|
|
|
|
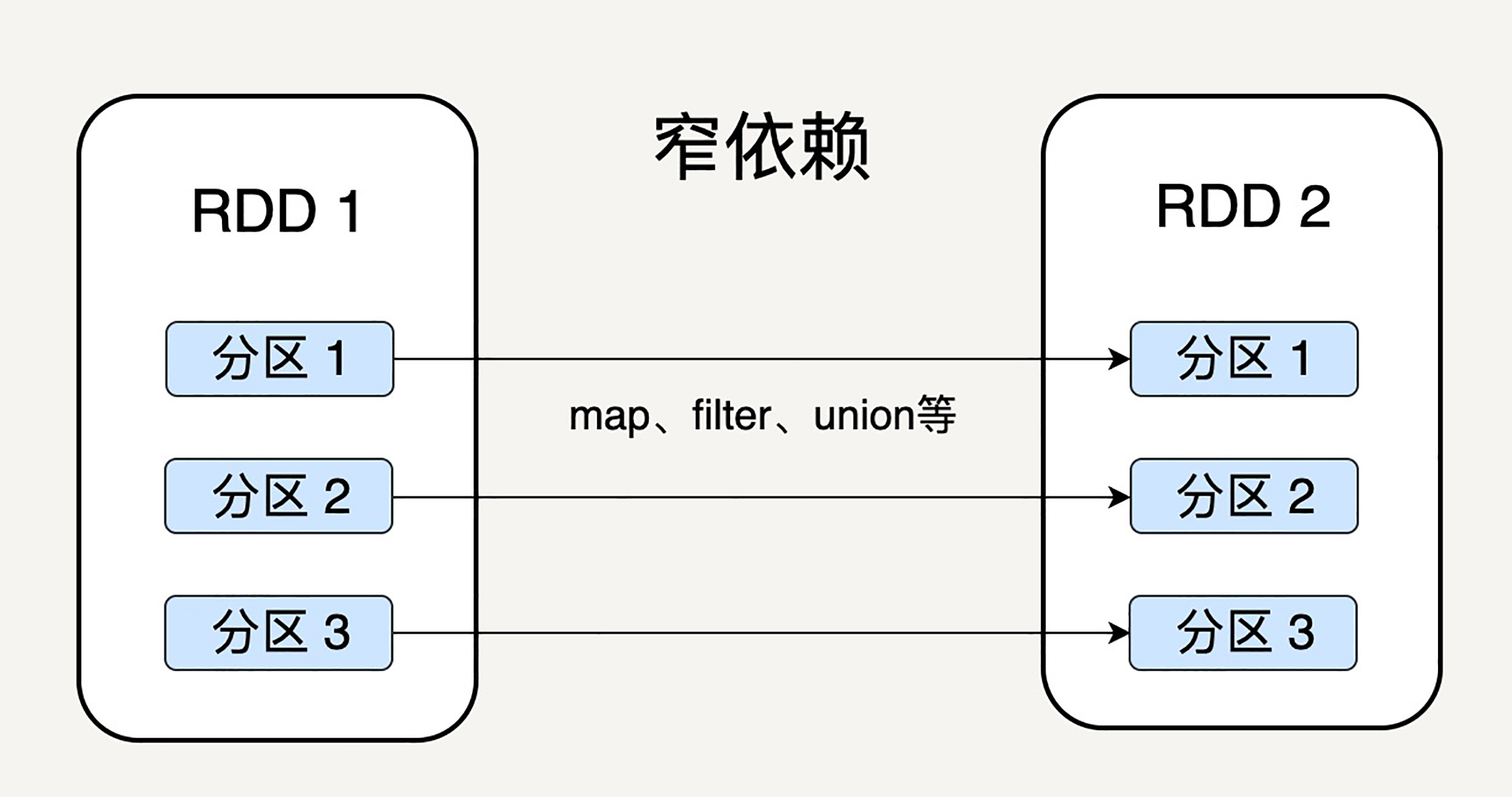
细心的读者会问这样一个问题,父RDD的分区和子RDD的分区之间是否是一对一的对应关系呢?Spark支持两种依赖关系:窄依赖(Narrow Dependency)和宽依赖(Wide Dependency)。
|
|
|
|
|
|
|
|
|
|
|
|
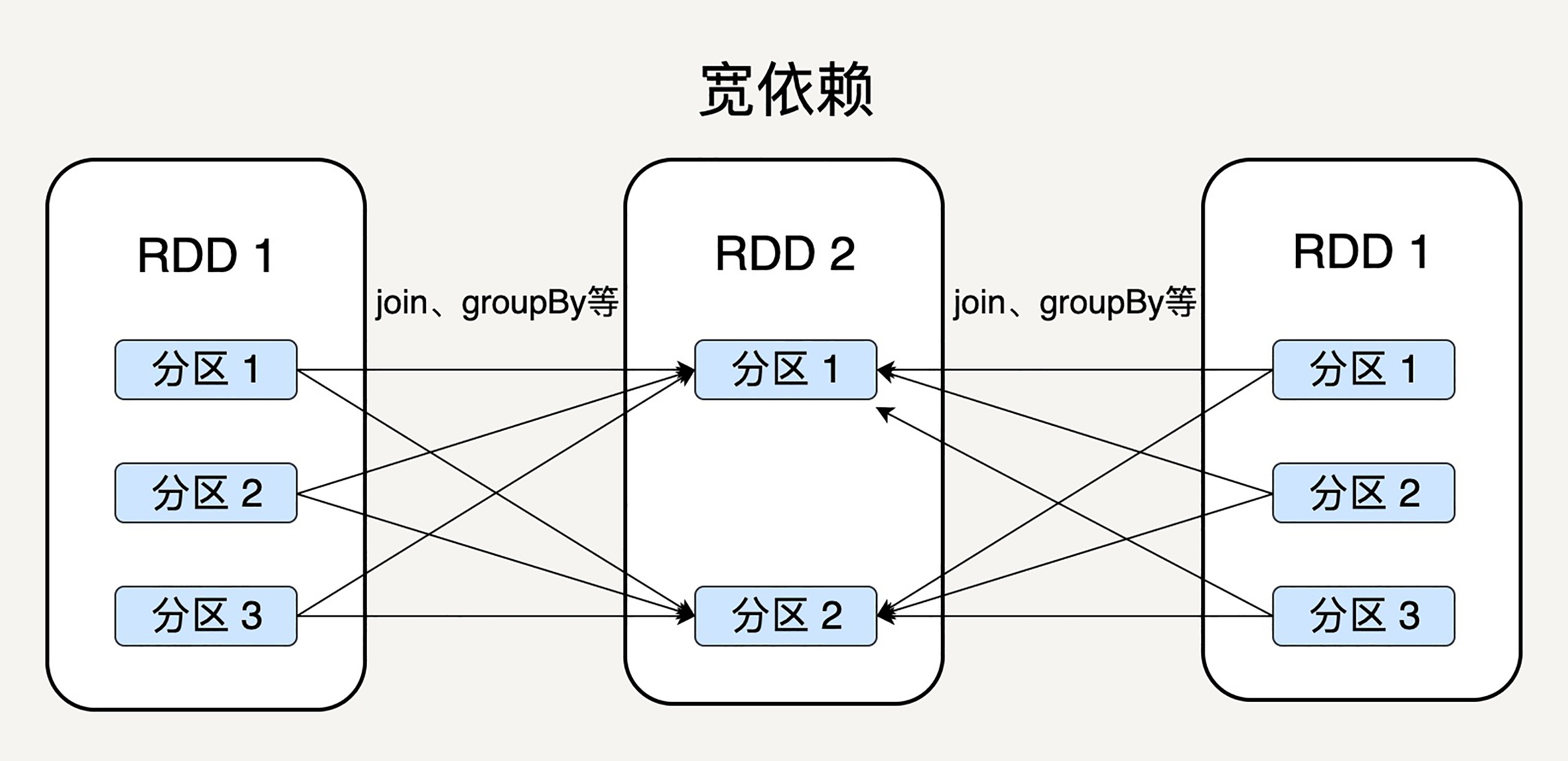
窄依赖就是父RDD的分区可以一一对应到子RDD的分区,宽依赖就是父RDD的每个分区可以被多个子RDD的分区使用。
|
|
|
|
|
|
|
|
|
|
|
|
显然,窄依赖允许子RDD的每个分区可以被并行处理产生,而宽依赖则必须等父RDD的所有分区都被计算好之后才能开始处理。
|
|
|
|
|
|
如上图所示,一些转换操作如map、filter会产生窄依赖关系,而Join、groupBy则会生成宽依赖关系。
|
|
|
|
|
|
这很容易理解,因为map是将分区里的每一个元素通过计算转化为另一个元素,一个分区里的数据不会跑到两个不同的分区。而groupBy则要将拥有所有分区里有相同Key的元素放到同一个目标分区,而每一个父分区都可能包含各种Key的元素,所以它可能被任意一个子分区所依赖。
|
|
|
|
|
|
Spark之所以要区分宽依赖和窄依赖是出于以下两点考虑:
|
|
|
|
|
|
* 窄依赖可以支持在同一个节点上链式执行多条命令,例如在执行了 map 后,紧接着执行 filter。相反,宽依赖需要所有的父分区都是可用的,可能还需要调用类似 MapReduce 之类的操作进行跨节点传递。
|
|
|
|
|
|
* 从失败恢复的角度考虑,窄依赖的失败恢复更有效,因为它只需要重新计算丢失的父分区即可,而宽依赖牵涉到 RDD 各级的多个父分区。
|
|
|
|
|
|
|
|
|
## 小结
|
|
|
|
|
|
弹性分布式数据集作为Spark的基本数据抽象,相较于Hadoop/MapReduce的数据模型而言,各方面都有很大的提升。
|
|
|
|
|
|
首先,它的数据可以尽可能地存在内存中,从而大大提高的数据处理的效率;其次它是分区存储,所以天然支持并行处理;而且它还存储了每一步骤计算结果之间的依赖关系,从而大大提升了数据容错性和错误恢复的正确率,使Spark更加可靠。
|
|
|
|
|
|
下一讲,我们会继续深入研究RDD的容错机制、任务执行机制,以及Spark定义在RDD上的各种转换与动作操作。
|
|
|
|
|
|
## 思考题
|
|
|
|
|
|
窄依赖是指父RDD的每一个分区都可以唯一对应子RDD中的分区,那么是否意味着子RDD中的一个分区只可以对应父RDD中的一个分区呢?如果子RDD的一个分区需要由父RDD中若干个分区计算得来,是否还算窄依赖?
|
|
|
|
|
|
最后,欢迎你把对弹性分布式数据集的疑问写在留言区,与我和其他同学一起讨论。
|
|
|
|
|
|
如果你觉得有所收获,也欢迎把文章分享给你的朋友。
|
|
|
|