146 lines
15 KiB
Markdown
146 lines
15 KiB
Markdown
# 27|多模态交互:替代触屏的交互新可能?
|
||
|
||
你好,我是Rocky。
|
||
|
||
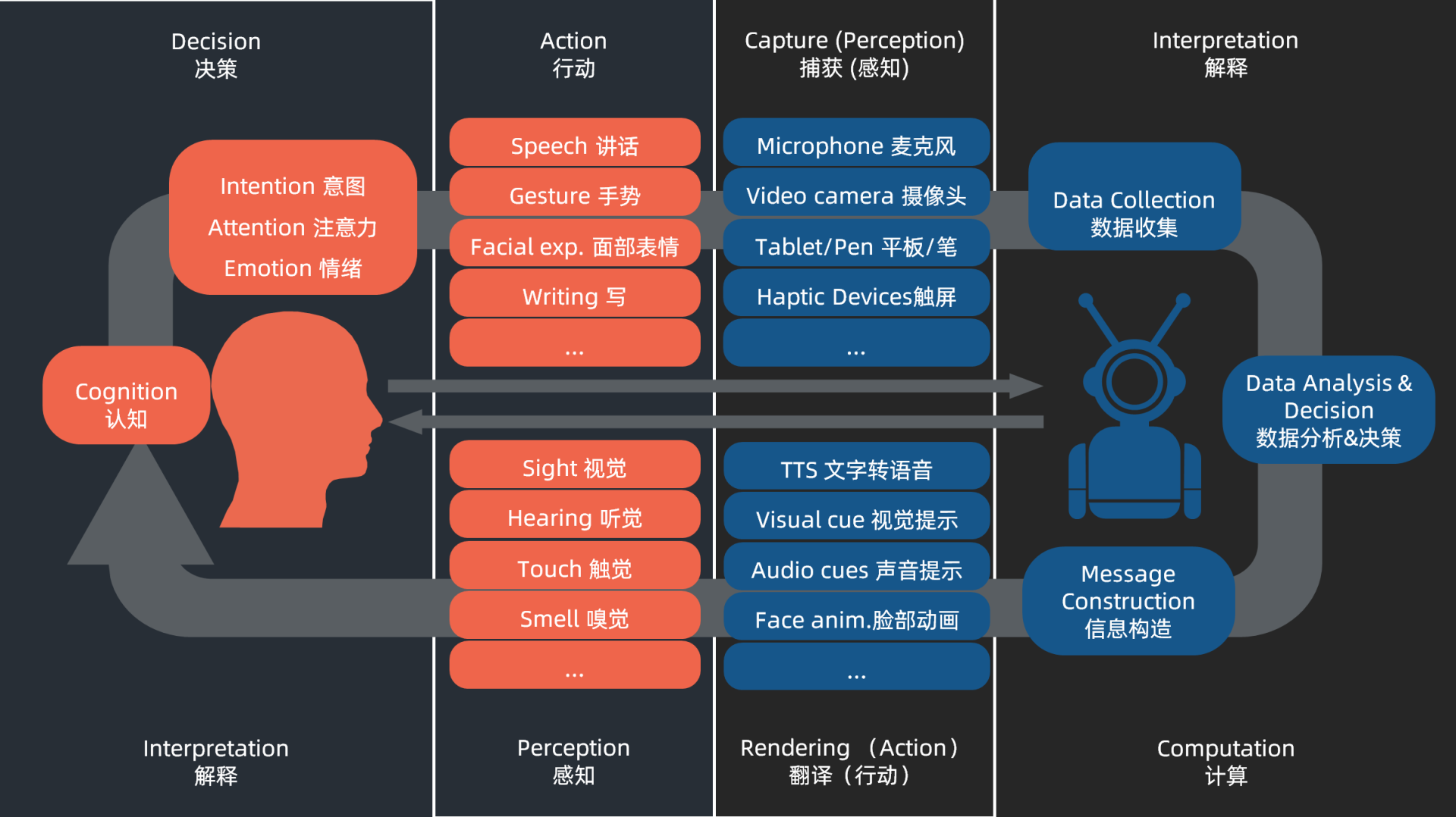
今天我们来聊聊多模态交互。到底什么是多模态交互呢?人和一个智能系统交互的时候,存在双方相互理解的过程,也就是双方都通过各种通道去表达,然后也都通过各种通道去分析对方的意图。**多模态是站在智能系统一方来表达,它更多强调的是智能系统通过多个通道去捕获人和环境的信息,或者通过多个通道去呈现信息。**
|
||
|
||
|
||
|
||
从多个通道呈现信息并非是个新鲜概念,比如我们的电影就是同时有画面和声音的多通道呈现的。我在前面的[第9课](https://time.geekbang.org/column/article/350185)讲到视听触的协同性时也提到,手机反馈要让用户通过视觉、听觉和触觉三个反馈通道去感知,这些也是多通道呈现信息的交互。而我们今天这节课要聊的重点是多模态交互的另一个方面:**智能系统如何从更多个通道获取用户的意图**。
|
||
|
||
## 多模态交互通道
|
||
|
||
我们先来简单看看智能系统的交互通道。智能系统应该从哪些通道来去理解人呢?我在[第3课](https://time.geekbang.org/column/article/345556)讲重新认识感觉时提到,要从人的角度来看我们有哪些感知觉在感知世界。相应地,我们理解智能系统也可以站在人的角度。
|
||
|
||
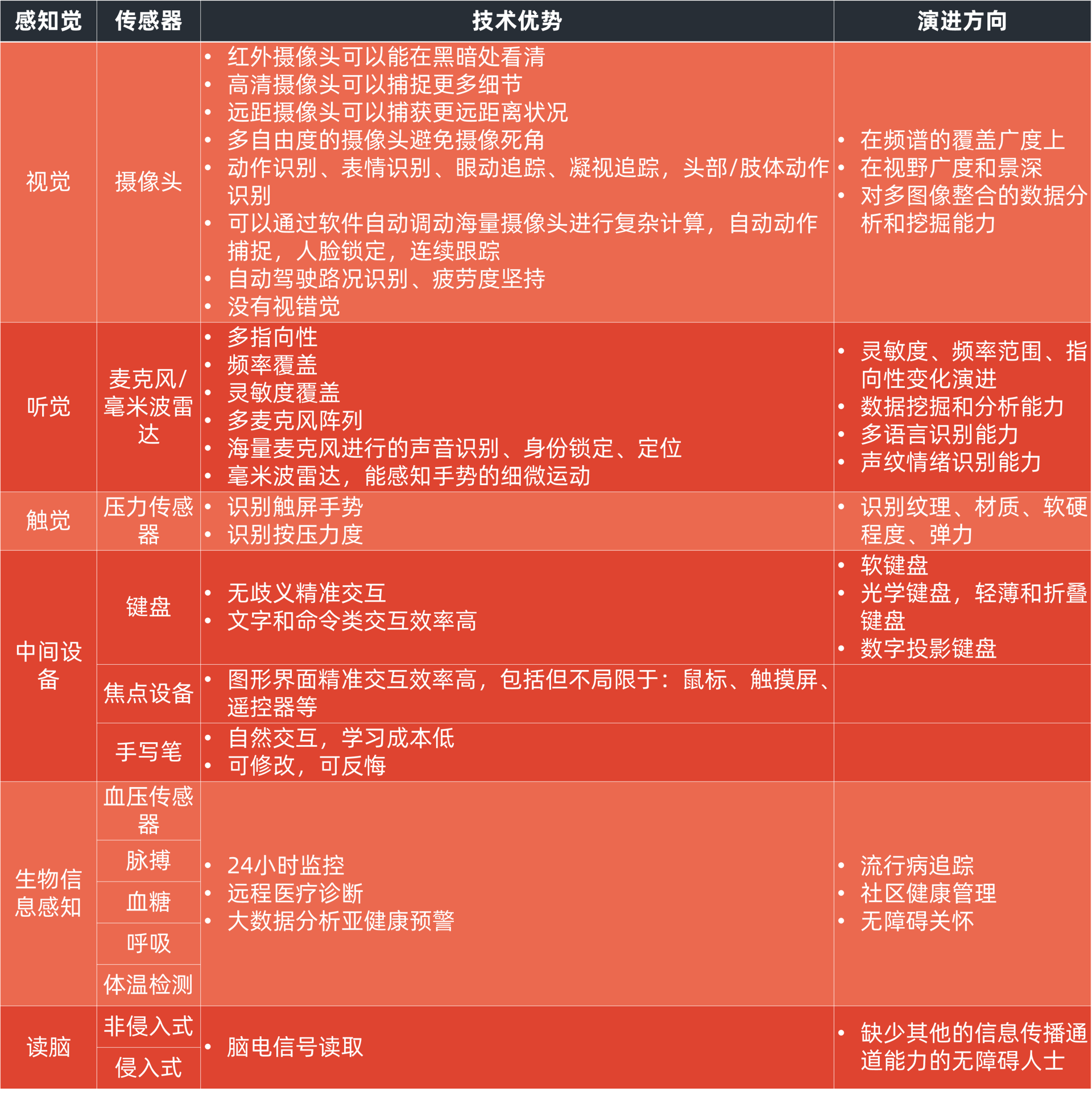
我们来做一下类比,列如计算机视觉就是通过摄像头模拟人的视觉,从而帮助智能系统来感知世界。但这不是简单的模拟,机器视觉有其独特的、并且还在不断高速演进中的技术优势。比如在分辨率、景深、可见光和非可见光光谱范围、多自由度视觉捕获能力等方面,以及AI和大数据加持的图像识别、海量摄像头数据分析及挖掘能力上,都会让计算机视觉表现出惊人的力量和生命力。
|
||
|
||
我下面列出了几种类似的感知觉技术优势和演进方向的表格,你可以对照着感受一下。
|
||
|
||
|
||
|
||
因为智能系统的演进速度非常快,技术的能力边界也在不断提升,很多已经远远超过人类。所以对于UX设计师而言,深入理解技术的当下能力和演进路径,对如何去设计一个多模态创新的交互界面会变得至关重要。我下面用一些案例来带着你来理解一下多模态交互创新设计。
|
||
|
||
## 非接触式交互
|
||
|
||
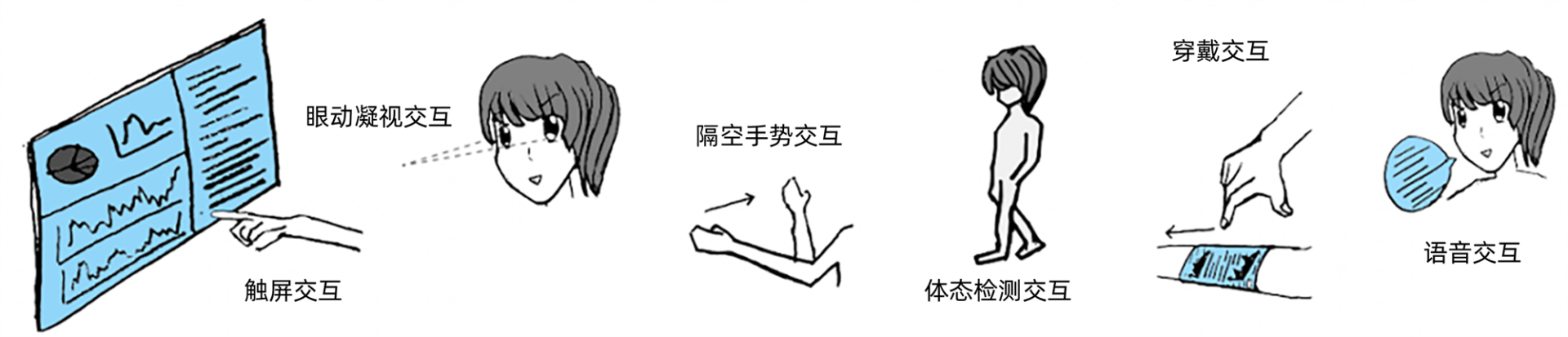
首先是非接触式交互。非接触式交互(Touchless UI,简称TUI)顾名思义就是指人不需要去触碰键盘、鼠标或者屏幕,直接通过身体运动、隔空手势、眼动凝视等手段完成与设备的交互。
|
||
|
||
|
||
|
||
非接触式交互的技术有很多种,有的需要普通的可见光摄像头,有的是需要感知深度的摄像头,有的是3D立体摄像头,有的是利用了毫米波雷达技术的摄像头,还有些是穿戴在人身上的设备,比如手套、手表、护腕等等。技术肯定是不断在演进的,但作用都是殊途同归。
|
||
|
||
和触屏交互不同,非接触式交互最近几年才在不同场合被热点关注(包括手机、VR/AR、智能驾驶等)。对任何交互而言,它的适用场景都非常重要。作为一个以大触摸屏为主的智能设备,手机是很难被人想到要进行非接触式交互的。
|
||
|
||
在当初设计华为的隔空手势时,我和同事们也曾激烈讨论过这一点。当时我们想到的一些非接触式交互的典型场景,就只有吃小龙虾、厨房做菜、油画创作等手脏需要操作手机的情况。
|
||
|
||
**不过在2020年新冠病毒疫情爆发后,非接触式交互已经变成一个非常重要的交互手段。**特别在公共场合,人们非常担心触摸公共屏幕,而喜欢通过扫码在本机上处理,但这也是一种治标不治本的方式。相信未来,真正的TUI会越来越变成一个被广泛运用的、重要的交互手段。
|
||
|
||

|
||
|
||
### 避免手势导致劳累
|
||
|
||
你在很多科幻电影比如《少数派报告》和《钢铁侠》中,都会看到隔空手势的设计。
|
||
|
||

|
||
|
||
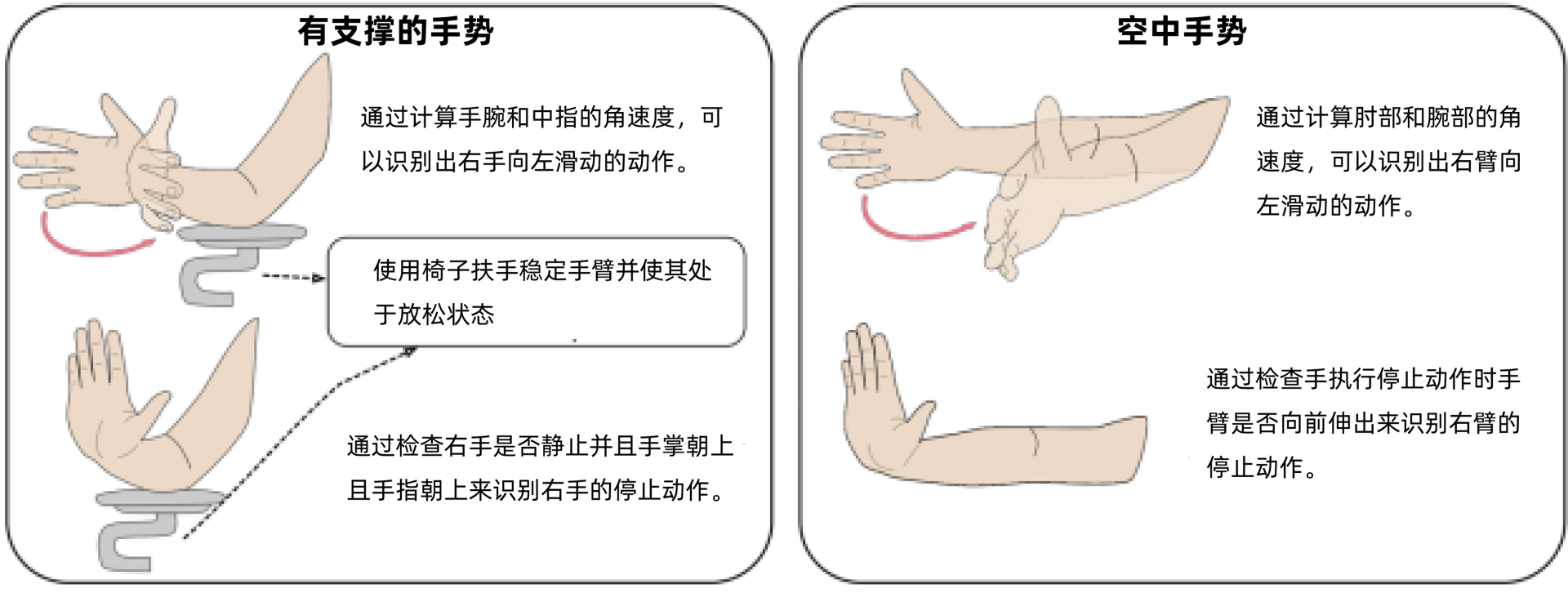
隔空手势在非接触式交互里是一种很炫酷的设计。但其实隔空手势有一点被经常忽视掉,就是大猩猩臂效应(大猩猩臂是指人们根本无法在手臂往外展开的姿势下长时间操作,这是灵长类动物身体结构的限制)。
|
||
|
||
如果你的隔空手势需要长时间抬起整个手臂进行,那这就是一种不符合人体工学、效率低并且极容易疲惫的交互手势,并不是一种理想的设计。**理想的手势设计应该如操作鼠标一般,不需要大幅度的动作就可以轻松完成任务。**
|
||
|
||
比如下图左半部分的动作整个手臂放在椅子扶手上,手的动作稳定,而且运动过程放松,不至于劳累。但是右半部分就不同了,相信人操作一会儿胳膊就会酸了。
|
||
|
||
|
||
|
||
你在设计手势的时候,手势的疲劳检测必须是一个重要的决定性指标,除非我们要做的设计是一个需要刻意耗费体力的竞技类游戏。
|
||
|
||
### 手势识别设计受技术的约束
|
||
|
||
再酷炫的设计,没有一个稳定先进的技术支撑也是不行的。如果我们手势的识别准确率过低,隔空手势功能也就会沦为用户一时冲动的尝鲜,无法成为有生命力、能够持续使用的特性。
|
||
|
||
手势识别也分为静态手势识别和动态手势识别,前者技术需求较为简单,但是要求手势交互要有停顿,不能够流畅、自然地识别,后者对摄像头和智能系统图像实时动态捕获精度和分析准确度的要求更高,需要能够识别运动的方向、速度以及加速度。
|
||
|
||
第一种**静态手势识别**,就是通过2D外观建模,对摄像头捕获的图像进行手势分析,不需要深度信息。这种技术对应的手势设计,要特别注意减少遮挡的发生,或者至少要考虑遮挡情况,在设计上考虑如何在发生遮挡时也能保证正常识别。
|
||
|
||
比如某些手势中手的侧边对着摄像头,摄像头可能就无法分辨是哪个手指的变化。这种普通摄像头的手势识别,一般多用于某些典型的标准静态动作、静态表情的识别,不要尝试去做变化很多、带着加速度的手势和表情,比如下图的几种手势就是合适的。
|
||
|
||

|
||
|
||
第二种**动态手势识别**,是最高效简单的做法。它其实就是利用骨骼绑定和分析技术,把人体的身体根据骨关节进行简单的分段并做好对应的分段建模,进而检测、识别这些关节的变化来推导出来人具体的手势和体态变化。这种技术下的手势设计,必须要有清晰的骨骼关节变化。比如下面谷歌的MediaPipe的手势识别就是在一只手中定义了21个3D的关键关节点,从而提供了精准、高保真的手部动作跟踪。
|
||
|
||

|
||
|
||
第三种是**肌电(EMG)信号来实现手势识别**。这个需要一些非侵入式的穿戴设备来配合(比如手臂或腿部上戴上带着传感器的绑带或者特殊的手套),这些设备再通过蓝牙方式连接智能系统。肌电信号有其特殊的优点,它不依赖于摄像头,有着最大的移动自由度,也不必在乎遮挡问题。对于设计师而言,手势发挥的空间更大,不过缺点就是需要穿戴在用户身上。
|
||
|
||
Myo臂环就是一款典型的穿戴在手臂上的手势识别设备。这种设备有一种特别的好处就是可以帮助失去前臂和手的残障人士。因为人即便失去了前臂,人脑还是会尝试控制胳膊的肌肉。把这种设备穿戴在胳膊上,即使是残障人士也是可以控制假肢实现张开手、握手、握拳、拾起物体、旋转手臂等复杂动作。
|
||
|
||

|
||
|
||
最后一种我认为是精度最高的一种方式,就是**毫米波雷达技术**。这种技术完美规避大猩猩手臂的那种大幅度动作交互设计,能够对人体和手势的轻微的动作作出精准的跟踪,已经不仅仅是骨骼绑定的那种粗狂的颗粒度了。设计师可以进行更加细腻的手势设计,比如下图,我们通过搓捏拇指和食指的指腹就能够灵活调整手表的时间了。
|
||
|
||

|
||
|
||
不过从目前这个技术量产化的情况来看,它的商用效果和技术潜能之间还是有一定的距离的。对于设计师而言,最大的挑战在于以下三点:
|
||
|
||
* 用户无法精准地判断到底距离屏幕多远做手势是合理的;
|
||
* 什么时间可以启动手势操作;
|
||
* 不同人对同一动作的理解有偏差,如何去兼容这些理解差异性。
|
||
|
||

|
||
|
||
针对以上问题,在设计上要注意到以下三点:
|
||
|
||
* 要帮助用户找到合适距离并给予清晰的动态反馈指引,而且这种指引不能被误触发。
|
||
* 在明显判定用户准备做隔空手势时,需要在屏幕上有明显的启动状态提醒,比如一个手的形状,或者其他和业务相关的特殊界面。
|
||
* 要能在感知用户动作不合适时候,在后台做最大的算法兼容,而不是去纠正用户的手势。手势操作失败,还被指出错误,用户会产生很强的挫败感,也就无法建立其使用业务的粘性。
|
||
|
||
从刚刚说的这些点你会发现,**不同的技术对手势交互设计也有完全不同的要求**,这也叫量体裁衣的设计。
|
||
|
||
## 多模态多通道并行输入
|
||
|
||
如果我们要在一个严格的意义上来说,非接触式交互其实也只是单类型的模态交互,并不是真正的多模态交互。
|
||
|
||
**多通道获取信息不仅仅是指切换不同的通道来获取数据,也指同时从多个通道获取信息,并且能够针对上述信息进行进一步的整合,更加精准地获取用户的意图。**
|
||
|
||
比如智能系统通过计算机视觉技术感知到了用户正在盯着屏幕上的某个App,然后嘴巴说出“打开”就直接打开了这个应用。这个过程其实就是两个通道同时在配合理解用户的意图的过程,这就是多模态交互。
|
||
|
||
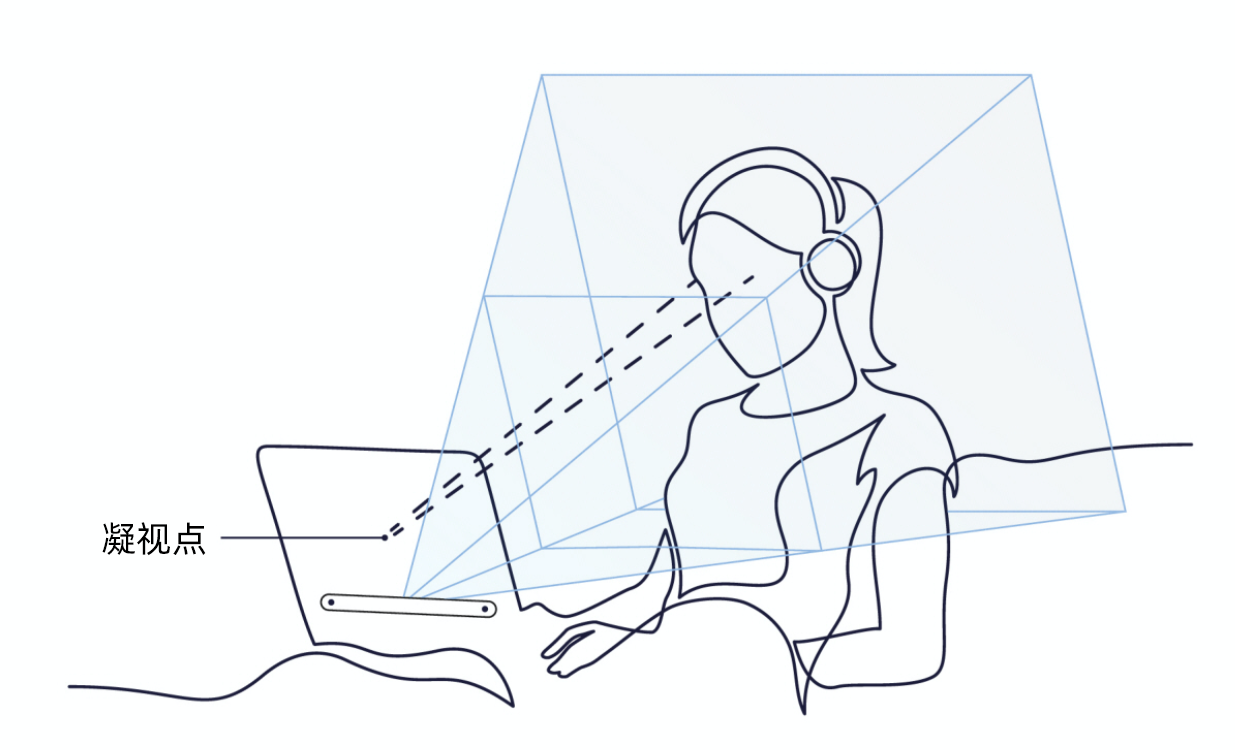
|
||
|
||
再举一个例子,假设一个电视节目增加字幕,仅仅是把通过录音设备采集到的语音数据通过语音识别算法转换为文字,那这只是一种单模态的场景。
|
||
|
||
但是如果也同时通过图像中的唇语读取技术来修正语音中的干扰及背景噪音,即视频通道的输入加上语音通道的输入进行双重的信息采集,两个一起做校对性的文字转换,这就是多模态交互了。
|
||
|
||
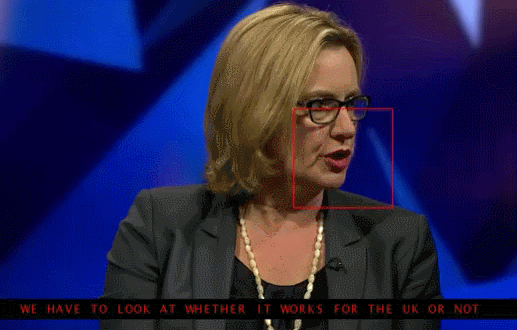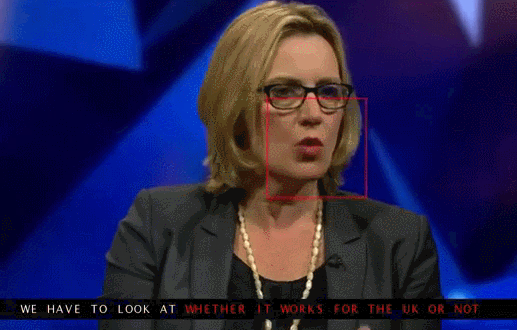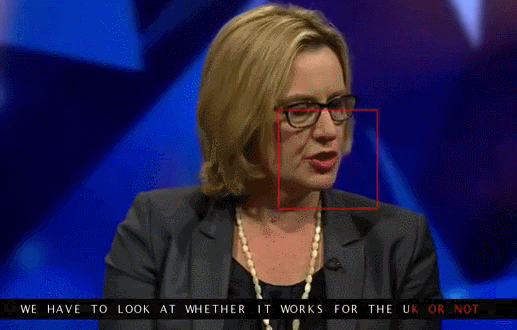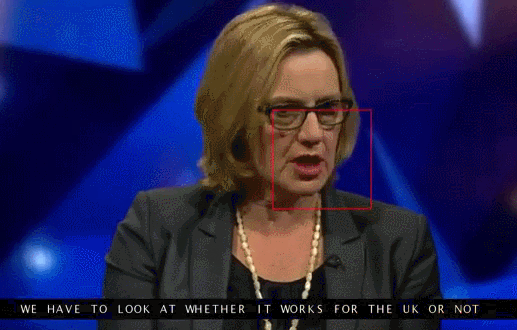
|
||
|
||
因为汽车拥有更多的传感器,所以在驾驶场景中多模态交互的运用更为常见。如果驾驶者通过说“请把温度调高5度”的语音交互指令来触发车内空调的温度调节功能,那这只是单模态的交互。
|
||
|
||
但如果汽车通过用户穿戴设备检测用户的体温,同时也通过摄像头来观察用户是否打寒颤、通过麦克风检测用户是否打喷嚏,这样将多个通道的数据进行整合分析,判断要赶紧调整温度,直到判断用户体感舒适为止,那这就是多模态交互。
|
||
|
||

|
||
|
||
监测用户是否疲劳驾驶也是一样的。我们通过同时检测用户的生物电信号(比如呼吸和心跳速度)、驾驶行为(比如是否出现驾驶者驾驶状况突变、违规异常,或者突然紧握方向盘等情况),还有用户面部状况的疲劳特征(比如是否闭眼、是否眼神游离、是否眼睑下垂、是否伴随不停瞌睡或者打哈欠的情况),综合判断疲劳状况后再给予针对性的交互输出和应对,这就是多模态交互。
|
||
|
||

|
||
|
||
在开始设计多模态交互之前,我们要先对这个场景设计有充分的认知和理解,然后再考虑可能调动的通道数量和技术准备度等情况,综合判断以提供不一样的创新体验。
|
||
|
||
你可能会问,多模态交互是不是可替代触屏交互的新可能?这其实是对多模态交互最大的误解。触屏交互本身就是模态之一,而我们的**多模态交互更像是触屏交互的升级版。我们会从更多维度来深度理解用户意图和对环境的认知,更加精准地为用户提供服务,从这个维度上来看,多模态必然是单模态的下一跳和未来。**只是这种未来的交互体验的具体形态未必唯一,也许会出现更加丰富多彩的可能。
|
||
|
||
## 总结
|
||
|
||
好了,讲到这里,今天的内容也就基本结束了。最后我来给你总结一下今天讲的要点。
|
||
|
||
今天我们重点谈了多模态交互。多模态交互包括多通道信息呈现和多通道信息收集,我们这一课主要聚焦的是后者。我们的智能系统有着丰富的传感器,是可以从非常多的维度来获取信息的。
|
||
|
||
从场景上来看,疫情导致我们对非接触交互的需求量激增,非接触交互会成为未来重点的交互手段。非接触式交互可以通过包括隔空手势、眼动凝视跟踪、身体姿态等手段来实现。关于非接触式交互你可以注意以下几个点。
|
||
|
||
* 从体验上来说,不要设计幅度过大的隔空手势动作,因为会产生大猩猩手臂效应,引起疲劳。
|
||
* 对于2D的外观建模技术,需要重点考虑遮挡发生,以及采用简单的不容易误判别的静态手势进行交互。
|
||
* 骨骼绑定是非常好的一种手势识别技术,需要设计师去根据关键关节点去设计合适的动作。
|
||
* 肌电信号穿戴设备更适合实现无障碍的设计,但存在需要用户穿戴的缺点。
|
||
* 毫米波雷达是比较理想的小幅度交互的精准交互技术,但它的商用效果和技术潜能之间还是有一定距离。
|
||
|
||
从严格意义上来讲,非接触式交互并不能称为多模态交互。你要注意的是多模态交互要具备同时从多个通道获取信息的能力。例如在驾驶场景中由于传感器更为丰富,多模态能够得到更多地运用。多模态交互方式是触屏交互的升维交互,必然会成为其未来的发展方向,但是具体表现形态可能会非常丰富多彩。
|
||
|
||
## 作业
|
||
|
||
最后我给你留了一个小作业,结合今天我讲的内容,试着思考一个你最喜欢的应用,它的哪些交互特性适合通过隔空手势的方式改造?如果适合的话,什么样的手势设计会让它更加自然流畅呢?
|
||
|