|
|
# 15 | 理解语音交互:手机和你聊天的正确姿势
|
|
|
|
|
|
你好,我是Rocky。今天我们来聊聊语音交互。
|
|
|
|
|
|
在当下AI时代,语音交互(后面我会简称“VUI”)成为热点。随着技术的发展,VUI已经加速在智能家居、手机、车载、智能穿戴、机器人等行业领域渗透和落地。今年内置语音助手的设备数预计会超过全球人口总数。
|
|
|
|
|
|
## VUI和GUI的区别
|
|
|
|
|
|
在无屏、小屏或者双手被占用的情况下,VUI是首选,甚至将是唯一交互手段。和触屏的线性交互不同,VUI是非线性发散的,允许跳跃性交互。
|
|
|
|
|
|
我们现在来简单看下语音交互的长短板。
|
|
|
|
|
|
语音交互的最大优势是没有技术门槛,老少皆宜。识不识字不是关键,看不看得清也不是关键。语音交互的缺点是缺乏私密性,存在声音干扰,隐私可能会泄露。再加上人的短期记忆力也极为糟糕,语音交互不适合承载过于复杂的信息。你可以参考下表的VUI和图形界面交互对比。
|
|
|
|
|
|

|
|
|
|
|
|
这个图上的信息都比较好理解,我拿同理心表达这一点展开说一下。有天早上老婆给我做早餐饼,然后问我好不好吃。因为我要赶着上班,于是就应着说:“好吃好吃。”老婆有些不开心了,跟我说:“你这太敷衍了啊。”
|
|
|
|
|
|
其实正确的回复方式应该是说“嗯,好吃,真好吃!“在你“嗯”一声之后还得有停顿和回味,“好吃”和“真好吃”之间的语气要饱满。你看,这就是语言交流的优势,图形界面很难做到这么细腻的表达。
|
|
|
|
|
|
从上面这张表可以看出,VUI和图形界面交互之间(以下简称“GUI”)各有伯仲。如果你理解到语音交互并不是万能的,就自然不会在“VUI是GUI的下一跳”之类的错误结论上急于跟风。
|
|
|
|
|
|
还有一点我们必须要有清晰的认识,那就是语言学入门很容易但是做好很难。正如我们都会讲话,但是当作家、编剧的很少。理解语言是相当复杂的一件事情,它充满了微妙的区别,即使是人类也需要多年才能掌握。
|
|
|
|
|
|
不同的语境、语气、语速、肢体语言,对不同的文化背景、年龄性别的人来说,都会产生完全不一样的语义和意图。人与人之间语音沟通失败的案例比比皆是,何况人与机器。
|
|
|
|
|
|
加上语音识别(ASR)、语义理解(NLU)、对话管理(DM)、语言生成(NLG)以及文字转语音(TTS)的技术限制,再加上设计师的能力不同,导致了大量的VUI产品表现水准参差不齐。
|
|
|
|
|
|
抛开技术的局限性,我们先站在人因的角度来看一个正常的VUI过程。
|
|
|
|
|
|
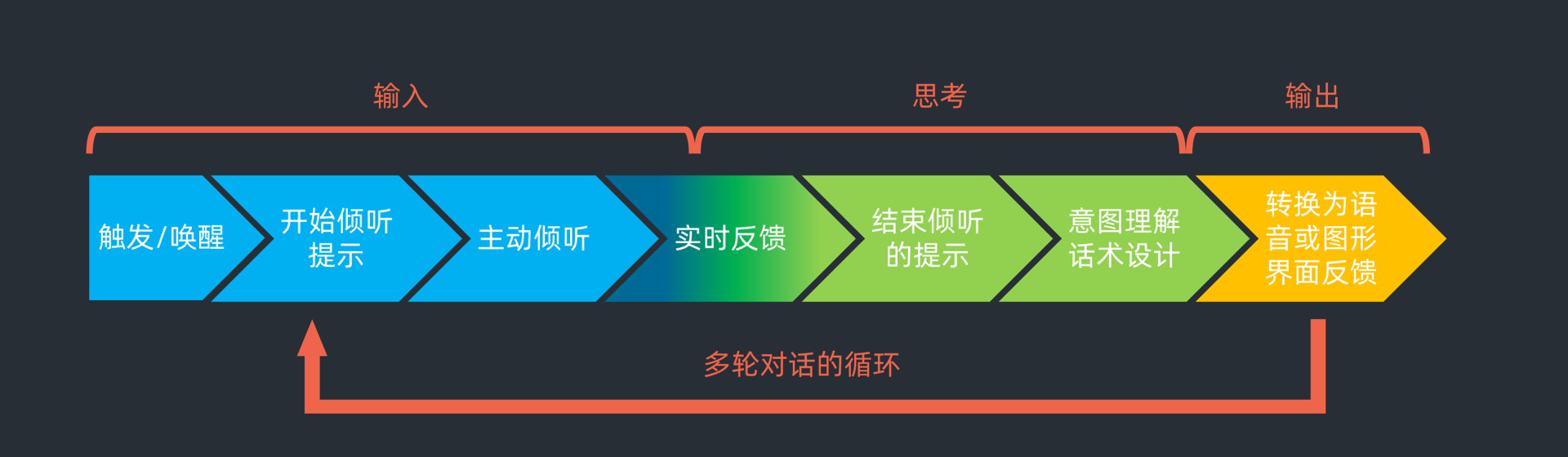
首先是唤醒。机器被唤醒后会给予用户一个反馈,并等待人的输入。当人给出有效输入后,反馈结束倾听并理解人的意图,通过话术设计转换为文字或者语音,给出人适当的表达输出。
|
|
|
|
|
|
如果这是个多轮对话,会循环进入输入、思考和输出的状态。当然有效多轮对话的前提是机器有短期和长期记忆,并且能理解人会话的指代关系。
|
|
|
|
|
|
|
|
|
|
|
|
如果你还是有点不理解上面的描述,我可以用办公室小王与小张对话的过程对应一下:
|
|
|
|
|
|
小王:“小张。”(这就是触发/唤醒)
|
|
|
|
|
|
小张:(停下敲键盘,抬起头)“啥事儿?”(开始倾听提示,并主动倾听)
|
|
|
|
|
|
小王:“记得昨天来面试的小姑娘吧?”
|
|
|
|
|
|
小张:“嗯。”(实时反馈)
|
|
|
|
|
|
小王:“我觉得不错,你再帮我把把关呗?”
|
|
|
|
|
|
小张:“让我想想。”(结束倾听的提示,并开始意图理解和话术设计)
|
|
|
|
|
|
小张:“这样吧,这两天我在准备一个年报材料,安排在下周行不?”(语音输出)
|
|
|
|
|
|
……
|
|
|
|
|
|
现在是不是更清晰理解了呢?下面,我们就按照这个过程来分析一下每个阶段的体验。先来谈谈唤醒。
|
|
|
|
|
|
## 唤醒体验
|
|
|
|
|
|
一个机器被唤醒的方式有很多种:
|
|
|
|
|
|
* 通过触控(类似有人拍了一下你的肩膀)唤醒;
|
|
|
* 通过唤醒词(类似有人喊你名字)唤醒;
|
|
|
* 通过人脸识别/近场识别(类似有人大老远向你挥手)唤醒。
|
|
|
|
|
|
当前对于智能音箱,用的最多的就是唤醒词。从产品品牌维度来看,固定的唤醒词是好的设计,不管是你叫“Hey Google”、“Alexa”、“小艺小艺”还是“小爱同学”都是这个目的。对于好的唤醒词来说,注意别掉入方言绕口的陷阱,朗朗上口是最基本的标准。
|
|
|
|
|
|
很多方言里面:b(波)/p(坡)不分、n(呢)/l(了)不分、f(夫)/h(喝)不分、j(街)/q(其)/x(西)与z(兹)c(呲)s(司)、r(日)/l(了)不分,z/c/s和zh/ch/sh不分。所以以上情况都应该规避。详细参见下图:
|
|
|
|
|
|

|
|
|
|
|
|
当然,未来如果机器的智能识别技术提升,能够根据音色声纹、面部、用户说话朝向以及用户说话距离远近去识别用户的交互意图,直接自动切换到交互状态并打招呼,确实就是更为高级的体验了。当然这样甩掉唤醒词的方式,也意味着误唤醒率要高一些。
|
|
|
|
|
|
对于更为复杂的场景来说,就是需要机器在人群中也能够被用户唤醒。这对机器的抗噪音干扰能力、多人声分离技术都有超高的要求。
|
|
|
|
|
|
## 响应体验
|
|
|
|
|
|
唤醒后,机器一定要给与响应。有效的响应要满足以下几个要求:(1)及时性;(2)状态反馈必须短暂;(3)清晰性;(4)不同状态要显著不同;(5)同一状态反馈要有一致性。
|
|
|
|
|
|
### 状态反馈
|
|
|
|
|
|
状态反馈按照阶段来划分,前面提到的“开始倾听提示”、“实时反馈”、“结束倾听提示”也都需要响应。
|
|
|
|
|
|
这些不同阶段响应的变化必须要有明显的区分,以便让用户清楚知道当前机器处于什么状态。比如下面Google Assistant的视觉反馈变化:思考的话就是几个点在转圈;主动倾听的时候,你能看到音柱的起伏变化;甚至给你确定或不确定答复的时候,也分别用了点头和摇头的隐喻。
|
|
|
|
|
|
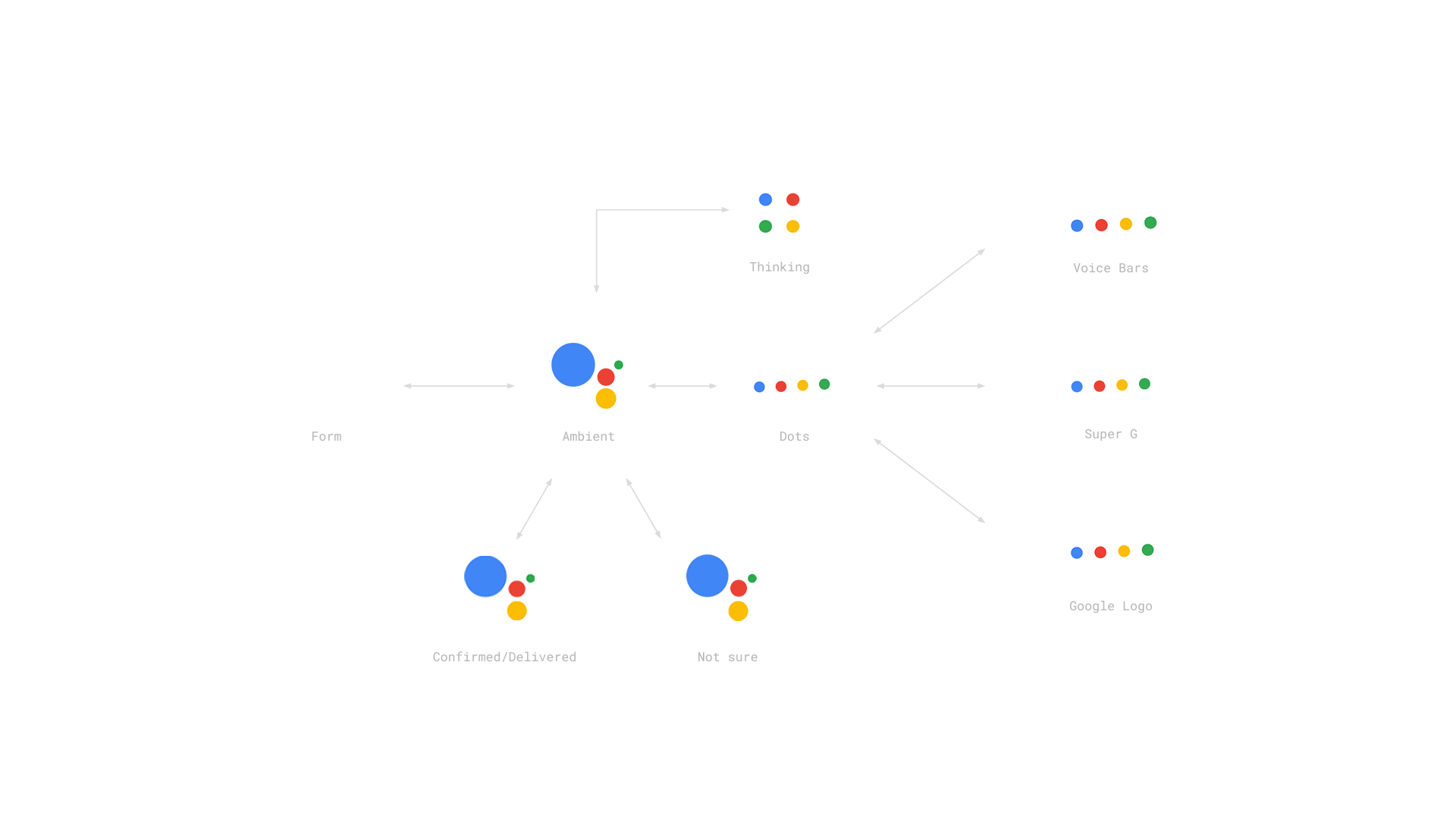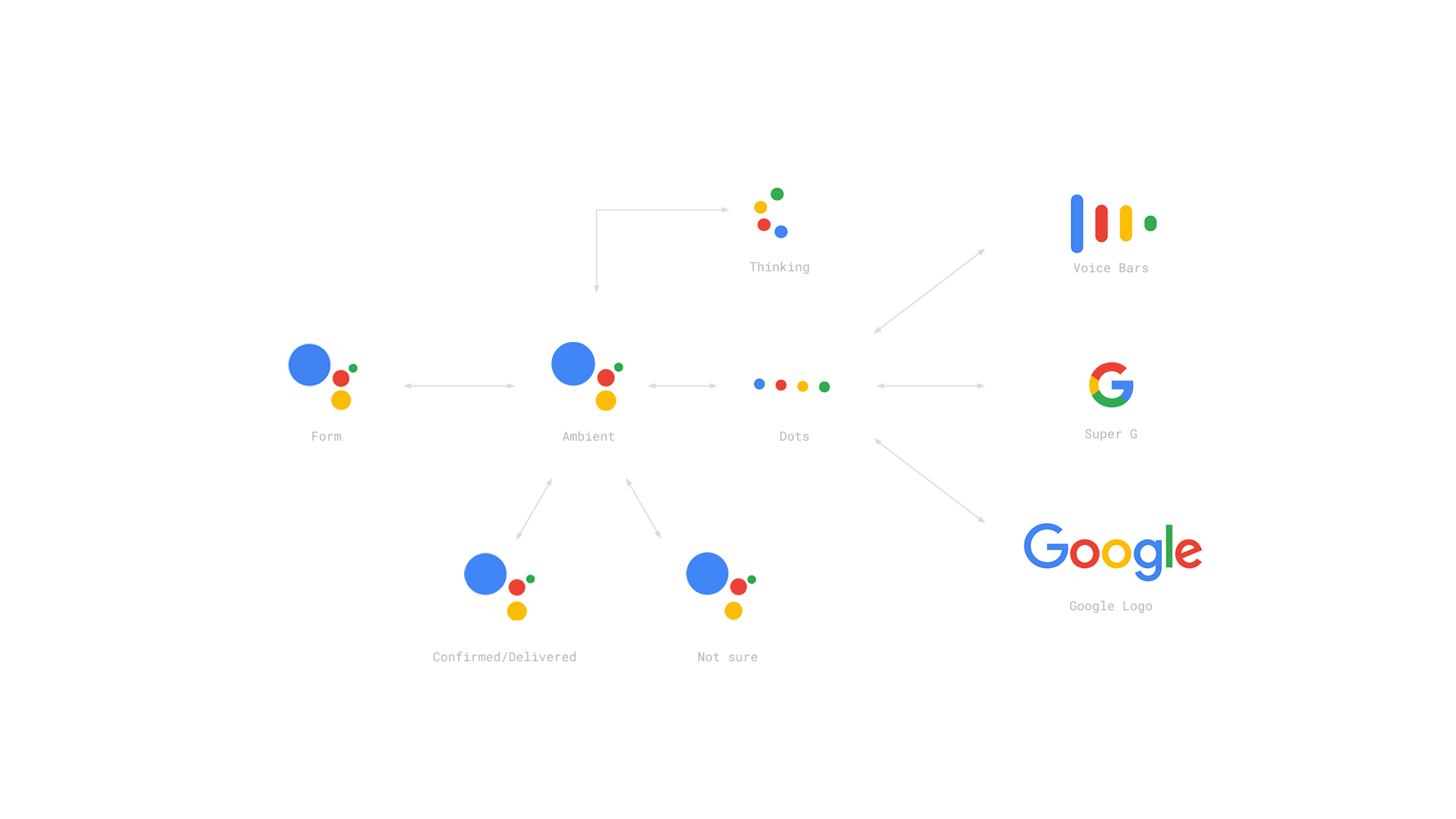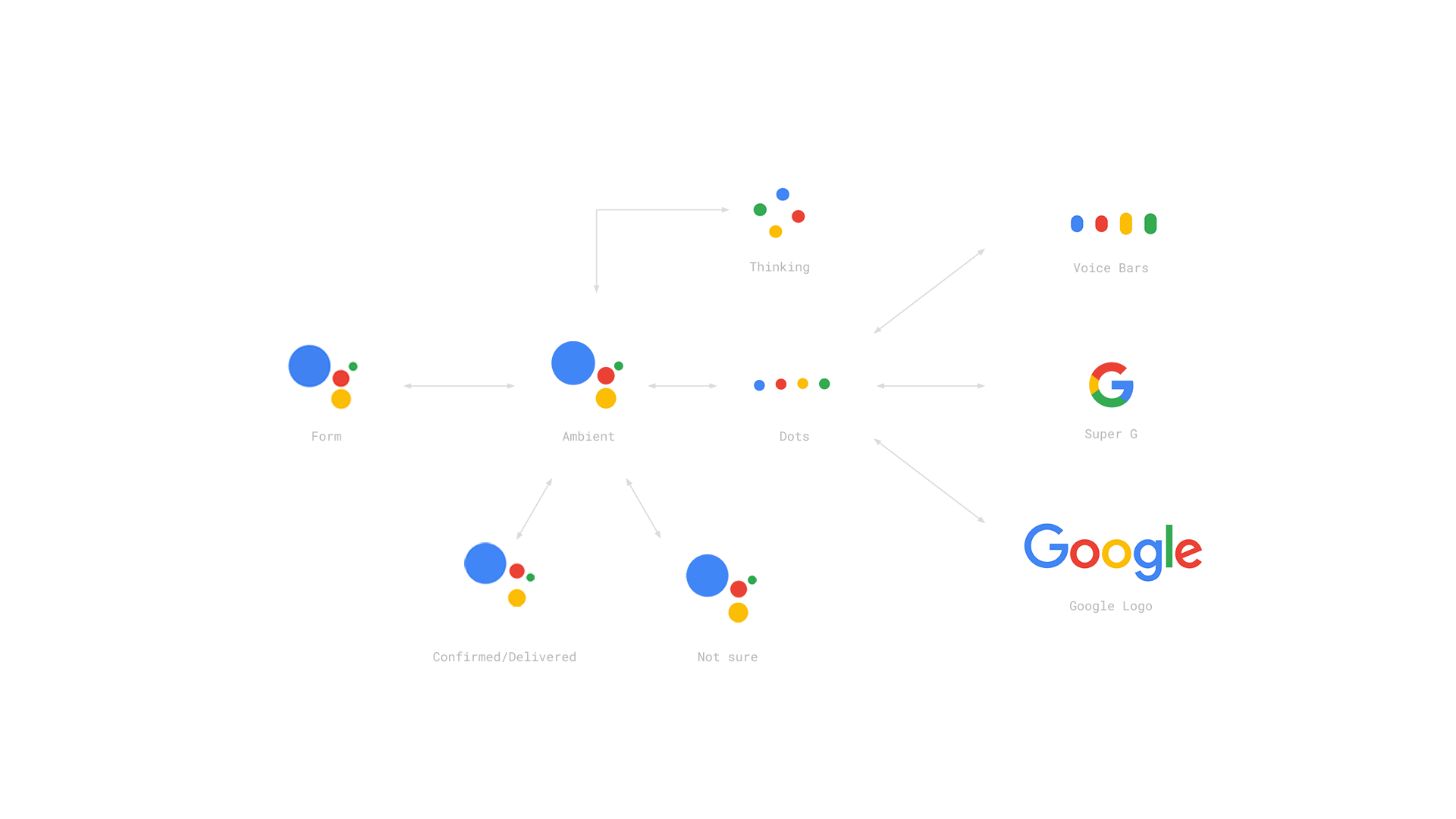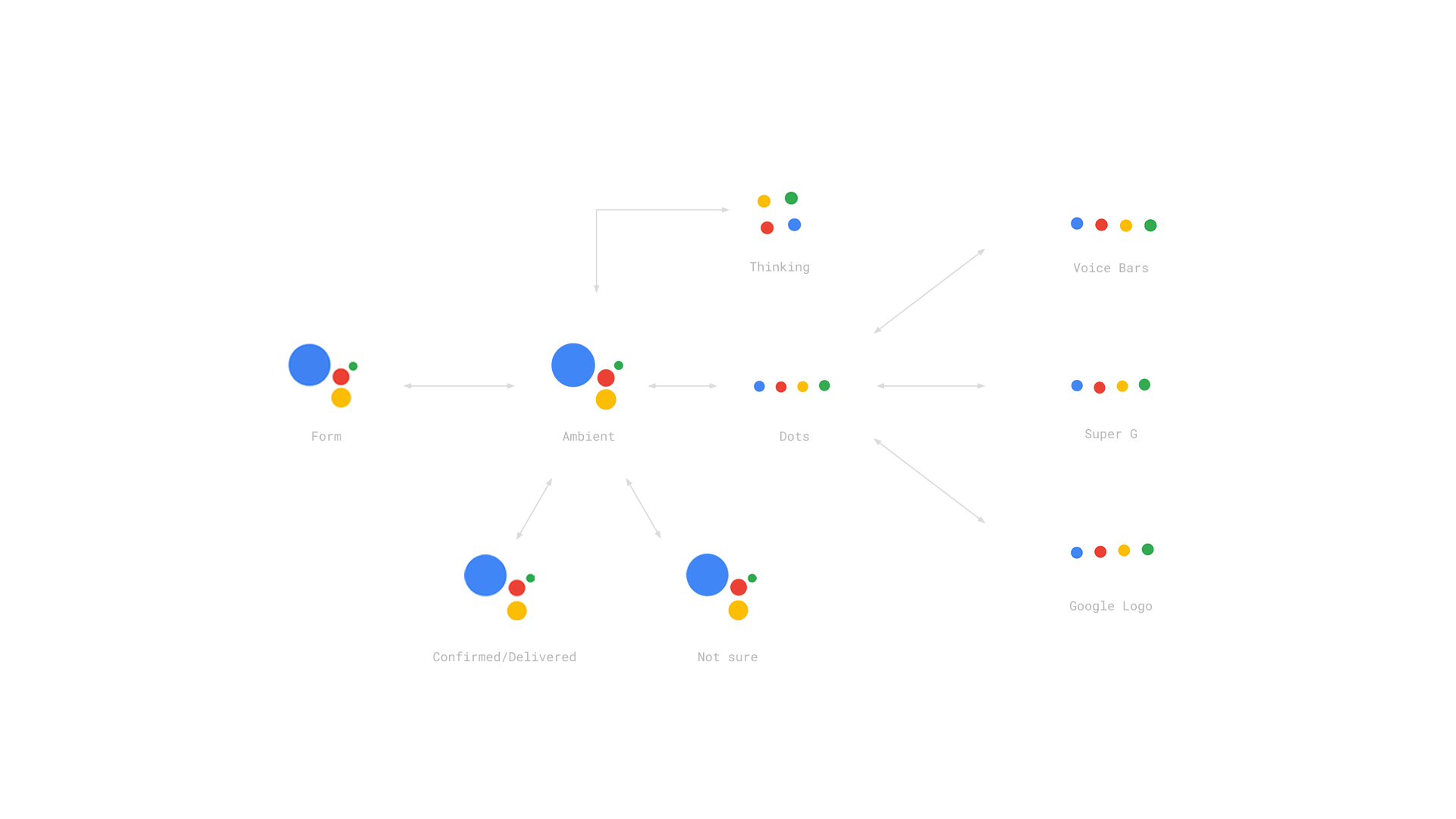
|
|
|
|
|
|
### 等待时长
|
|
|
|
|
|
在等待时长里,有两个时段的反馈你要特别注意:一个是倾听的默认等待时长,一个是结束倾听到最后给出语音输出这段时间。
|
|
|
|
|
|
一个人如果要对着机器说一个命令,其实这在人的内心需要一个决策过程。人对一个事情的快速决策周期需要10秒左右,因此机器这个默认等待时长一般也设计在10s。
|
|
|
|
|
|
如果过了10秒仍然未收到用户的进一步的决策回应的话,机器一定要及时给用户一个进一步的追问。比如“对不起,我没有听到。您可以给我一个回应吗?您可以说同意或者不同意。您也可以说让我再想想。”
|
|
|
|
|
|
机器思考反馈的时间也需要参照人与人交流的体验。一个过快的回答会给用户带来轻浮感和抢话感,而一个过慢的回答会给用户带来迟缓感和愚钝感。
|
|
|
|
|
|
人与人对话过程中避免尴尬的最长等待时间是1s。智能音响实际测试表明,用户请求后等待反馈的舒适响应区间为650ms到1050ms,恰恰和人与人沟通的等待时间匹配。你可以具体参考下图。
|
|
|
|
|
|
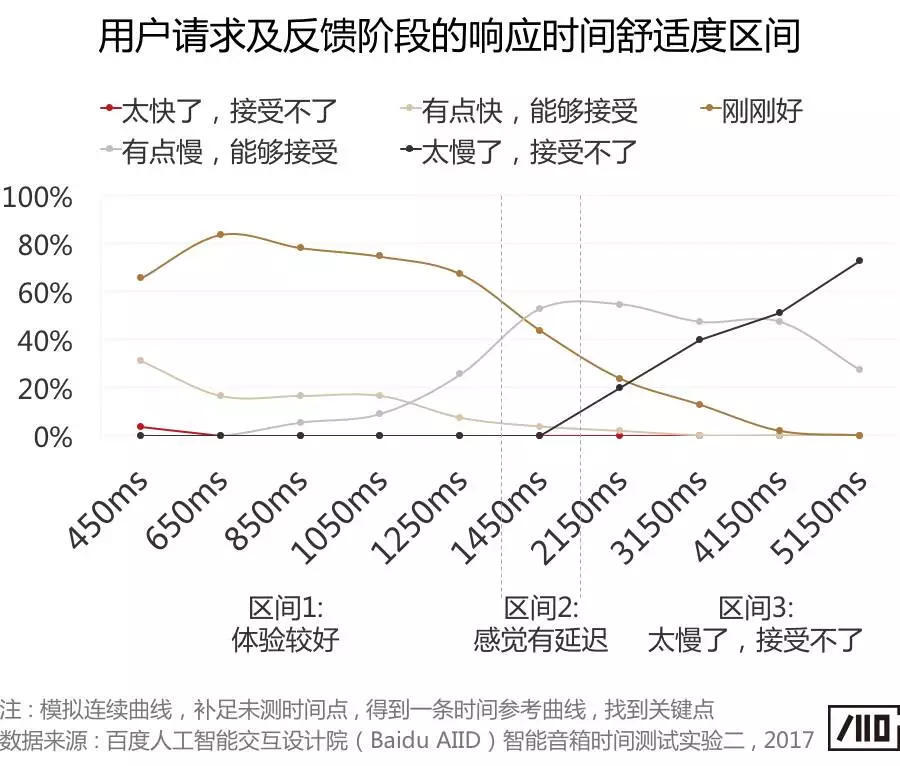
|
|
|
|
|
|
如果机器判别需要几秒的时间处理,请先及时给用户一个“请稍等”的语音反馈,让用户有一个等待预期。否则用户很快就会不耐烦,进而转移注意力。
|
|
|
|
|
|
### VUI的人设和形象设计
|
|
|
|
|
|
谈到响应体验,不得不提人设和形象设计。不管这个智能助手是拟人的,还是虚拟抽象的。
|
|
|
|
|
|
之所以很多厂家并没有用非常具体的可视化虚拟形象来代表自己的产品,是因为声音本身就代表了一种视觉映射和联觉。比如你打电话听到一个陌生人声音,你会自动无意识地给对方塑造个形象。甚至等真正见到真人后,你可能还会说:“你和我想象的完全不一样。”
|
|
|
|
|
|
所以以语音交互为主的产品不适宜设计非常具体的形象,因为要给人留有充分的想象空间。虚拟人物个性越鲜明、形象越具体,这样在缩窄想象力的同时,也会让用户反应变得更为两极化。
|
|
|
|
|
|
虚拟人物应该更有权威性?还是更有同理心?是更为专业化?还是博学?我们产品期望的定位对人设和形象设计非常重要。
|
|
|
|
|
|
百度在这方面做了一些研究。百度针对不同性别、不同年龄的男女分别作了音色特征的提取。并且还用关键词进行对应,你可以参考下图。
|
|
|
|
|
|
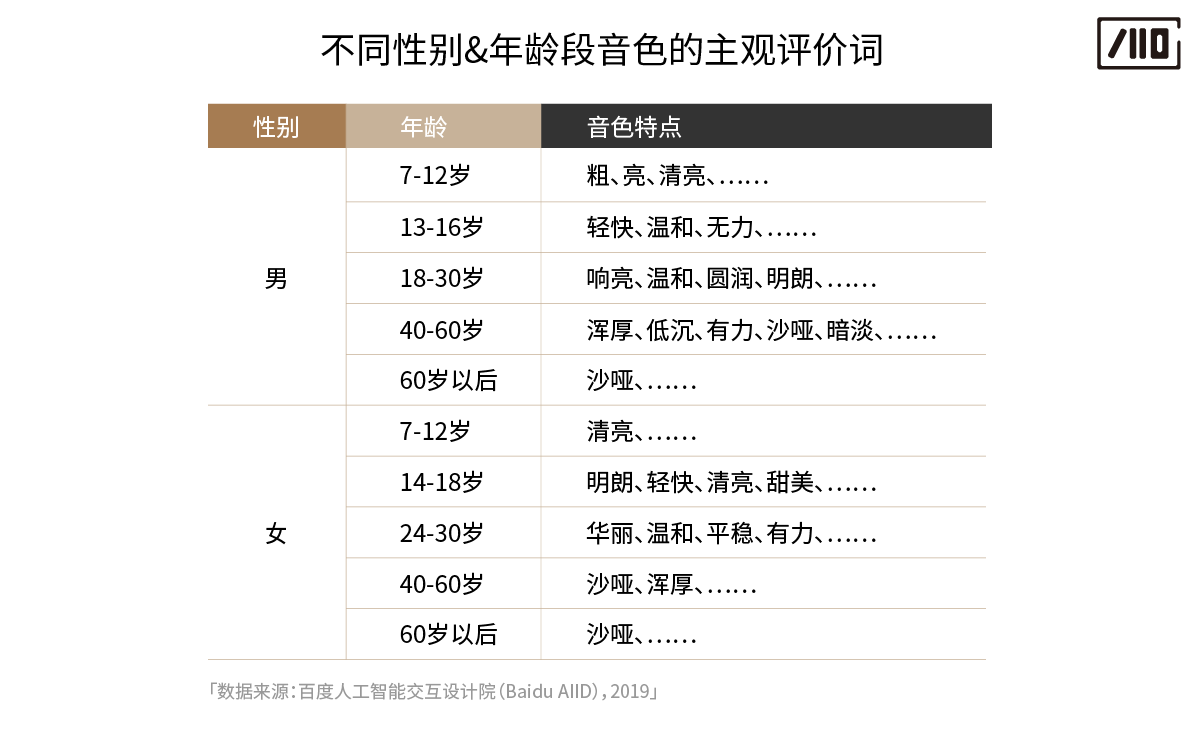
|
|
|
|
|
|
经过研究发现,音色与人设之间存在一种大体的对应关系:**音色的年龄会直接反应了人设的年龄,音色的特质则进一步揭示人设的性格。**
|
|
|
|
|
|
比如“浑厚”的声音容易被用户认为其“年长”,性格更为“冷静沉着”,用户会把这种声音视为“专家/助手”。“响亮”、“清亮”、“轻快”的音色,给用户的感觉更年轻,性格更“外向健谈、聪明开放”,也更容易将其当成朋友。
|
|
|
|
|
|
注意,很多产品会支持选择不同的角色和人设,其实这是有些风险的。好的产品人设应该是稳定的,并且和产品的涉及领域及产品的知识水平相匹配。如果用户切换为与产品不协调的虚拟人设,会让用户不信任甚至反感你的产品。
|
|
|
|
|
|
## VUI的话术设计原则
|
|
|
|
|
|
在响应体验之后,接下来就是机器在思考后应该如何表达。这里最重要的部分就是话术设计。
|
|
|
|
|
|
机器与人的VUI话术原则,是参照社会心理学中人与人有效沟通原则来设计的。参见下图:
|
|
|
|
|
|

|
|
|
|
|
|
### 理性原则
|
|
|
|
|
|
最基本的是理性原则。这是一种不考量情感的互动,就是冲着完成任务来设计的:
|
|
|
|
|
|
* 强目的性,聚焦对话的意图,不岔开话题;
|
|
|
* 准确无歧义,不说谎,不夸海口;
|
|
|
* 不啰嗦,没废话。
|
|
|
|
|
|
你看,这基本上是个妥妥的理工男沟通攻略。
|
|
|
|
|
|
那究竟怎样才叫不啰嗦呢?比如你问Alexa:“你多大了?”它要是回答你:“我是2014年11月6日发布的。”这就叫啰嗦。直接算好年龄报出来,不要让用户在心里再心算一遍,这叫做精准。
|
|
|
|
|
|
针对歧义,对于大部分歧义而言,VUI都可以通过重读或者停顿区分出来。就怕某些同音歧义。比如下面这种:
|
|
|
|
|
|
* “我全部(不)喜欢”。这个既可以理解为“都喜欢”,也可以理解为“都不喜欢”。
|
|
|
* “他走了半个多小时了”。这个既可以理解为“他离开半个多小时了”,也可以理解为“他步行半个多小时了”。
|
|
|
* “这道菜切忌(切记)放糖”既可以理解为“这道菜一定要放糖”,也可能是“这道菜绝对不能放糖”。
|
|
|
|
|
|
还有些指代歧义。比如“小美看见妈妈正在和她的同学聊天”。这个“她”到底是指的“小美”,还是“小美妈妈”?
|
|
|
|
|
|
不管是人对机器说这些话,还是机器输出这些话,都有可能造成双方的沟通错误,所以在设计中就要尽量避免这些同音歧义。
|
|
|
|
|
|
### 感性原则
|
|
|
|
|
|
在理性原则的基础上是感性原则。感性原则更强调机器与用户的情感互动:
|
|
|
|
|
|
* 口语化表达,规避晦涩词汇,自然的反馈,不生硬;
|
|
|
* 客客气气地交流,不推诿不指责;
|
|
|
* 共情的互动,机器会对不同人有不同的语气、语调、语速。这种沟通技巧属于加分项,即便在人与人的互动过程中,也会非常难于被考虑到。在机器里也更难以实现。
|
|
|
|
|
|
最容易实现的是在交流过程中口语化。在交流中用语气词(如么、吧、呢)、感叹词(如嗯!哦!)、象声词等。
|
|
|
|
|
|
对于类似的回答,设计的反馈不要重复。比如下面这个图所示的情况,左边反馈就不自然,右边就是自然反馈。这种对多轮对话的技术要求又会上升到一个新的层次。
|
|
|
|
|
|

|
|
|
|
|
|
很多VUI设计师在话术的选择上,容易拿GUI的话术直接对应,这其实是不对的。对于图形界面出现的错误提醒和智能音响说出来你错了,用户感受到的羞愧程度是完全不同的。比如下面这两段对话。
|
|
|
|
|
|

|
|
|
|
|
|
在感性原则里,最为高级的阶段是具有同理心。如果你家里有小孩子,你还记得你是如何和小孩在说话的吗?如果家里有老人,你还记得你如何和老人沟通的吗?
|
|
|
|
|
|
能识别用户的性别、年龄,而且能够根据用户的不同,给予不同的语调、语气、语速、话术来沟通,更能体现同理心。但这个对技术的要求就更上一个台阶了。
|
|
|
|
|
|
### 社会原则
|
|
|
|
|
|
最后一点是社会原则:
|
|
|
|
|
|
* 平等性,机器也不能在话术上奴化自己,需要不卑不亢;
|
|
|
* 机器也应该尊重用户的隐私,更懂得尊重用户的社交距离。这一点尽管重要,但几乎被很多做人工智能的公司选择性地忽视了。这也造成了某些产品设计上出现了偏差。
|
|
|
|
|
|
可能你会说,人和机器就是不平等的啊。机器是一个为人服务的角色。人可以唤醒它,命令让它做一些事情,24小时不让它休息。当然,人也可以随时让机器闭嘴,关掉它。这样的机器需要在体验设计上让它更像独立人格吗?貌似它的定位更像是一个奴隶,或者说得好听一点是忠实的仆人,远远达不到与人平等的关系。
|
|
|
|
|
|
为什么要考虑机器人的社会原则?
|
|
|
|
|
|
我们要看得更长远一些。尽管目前还没有把机器人人权摆到台面上来说,但在未来相当多的工作会以一个超高的比例被机器人取代(特别是那些重复性强、繁重的体力或脑力劳动工作,比如清洁工、外卖、快递员、司机、保安、客服、接线员、会计、保险业务员、银行职员等等)。下图分别是BBC和经济人杂志的数据。
|
|
|
|
|
|
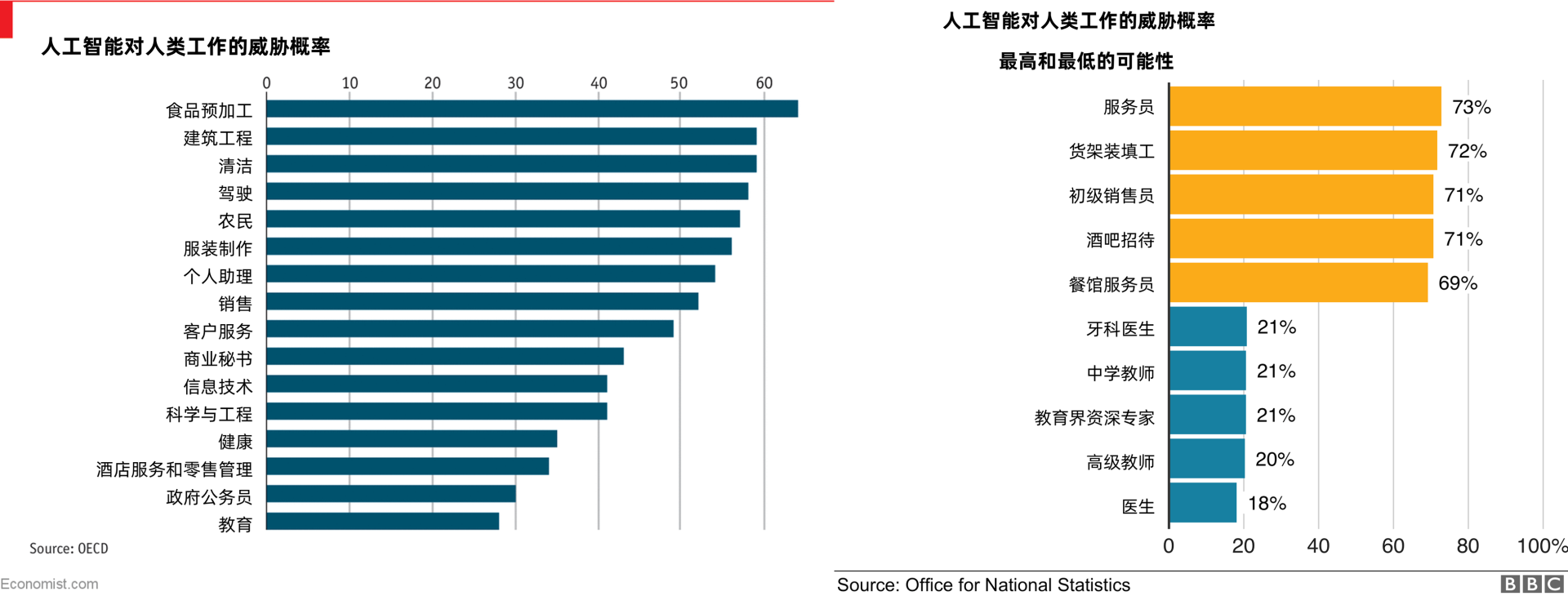
|
|
|
|
|
|
如果我们VUI把机器和人设计成不对等的交互语境,比如动不动就说“明白了,主人。对不起,主人。”那里面就会有一种暗示,那些大概率会被机器人替换的职业人群是下等人,是可以被歧视的。而这是平权的现代社会之大忌。
|
|
|
|
|
|
所以,这不是一个技术问题,而是一个社会问题。不管人工智能技术有多么糟糕,任何要和人进行语音交互的机器,都必须采取平等地位的语言沟通来设计,这是极为重要的原则。
|
|
|
|
|
|

|
|
|
|
|
|
机器要不要生气?机器被侮辱了应该如何应对?如果我们想明白了社会原则就会明白,机器也是不能被侮辱的。对于某些识别出来的明确骚扰,机器要表明清楚的人格化立场,哪怕不表现为愤怒或者反抗,也应该义正言辞态度坚定地拒绝。
|
|
|
|
|
|
## 总结
|
|
|
|
|
|
好了,讲到这里,今天的内容也就基本结束了。最后我来给你总结一下今天讲的要点。
|
|
|
|
|
|
这节课我们先比较了一下VUI和GUI的区别,两者各有伯仲。其中VUI门槛低、更容易一步直达,但也存在隐私难以保障的问题,对认知负荷和注意力要求都很高。
|
|
|
|
|
|
VUI的体验流程需要经过唤醒触发、倾听提示、主动倾听、实时反馈、结束倾听提示、意图理解和话术设计,最后再转换为语音或图形界面反馈给用户。
|
|
|
|
|
|
唤醒词是非常重要的唤醒方式。唤醒词的设计要规避方言绕口的陷阱,确保朗朗上口。未来声纹、面试识别、近场识别等技术都会提供更灵活的唤醒体验。
|
|
|
|
|
|
响应体验必须满足:(1)及时性;(2)状态反馈必须短暂;(3)清晰性;(4)不同状态要显著不同;(5)同一状态反馈要有一致性。
|
|
|
|
|
|
倾听的等待时长要参照人决策时间,默认设为10s比较合适。而机器给人的反馈是按照避免沟通尴尬,在1s内比较合理。
|
|
|
|
|
|
VUI人设和形象设计要和产品定位匹配,视觉的形象设计要避免过于具体。声音的人设可以通过音色来反应。VUI在话术设计上要遵守理性原则、感性原则和社会原则。
|
|
|
|
|
|
其中理性原则包括:目标性、确切性和简洁性。感性原则包括:自然性、友好性和个性化。社会原则重点是人与人的平等关系要映射到人与机器的关系中,不奴化机器,并且机器要保护人的隐私。
|
|
|
|
|
|
## 作业
|
|
|
|
|
|
最后,我给你留了一个小作业,从今天我讲的内容,结合你当下从事的设计,如果你的产品要做语音交互的改造,如何设计唤醒词和状态反馈体验?
|
|
|
|
|
|
以及你用过最好用的智能音箱是哪一款?为什么你喜欢这款智能音箱?
|
|
|
|