242 lines
20 KiB
Markdown
242 lines
20 KiB
Markdown
# 14|调度算法:操作系统中的进程是如何调度的?
|
||
|
||
你好,我是微扰君。
|
||
|
||
之前我们已经学习了大部分常用的数据结构和一些经典的算法思想,从今天开始,我们将正式迈入算法在真实世界的应用,感受计算机先辈们在解决实际问题时天马行空的智慧之光。希望带给你思维乐趣的同时,也能给你解决实际工作里的问题带来一些启示。
|
||
|
||
就让我们从操作系统开始说起,作为计算机软件的基石,它是计算机软硬件交汇的关键所在。
|
||
|
||
当然,操作系统同样是一个非常大的话题,不同历史时期的操作系统都背负着不同的使命。发展至今,随便一个可用的操作系统都有几千万行的代码,上上下下用到的算法肯定也非常多,我们不可能全部涉及,这次会挑出几个关键的算法或者设计来讲解,包括:计算机进程调度算法、内存页面置换算法和日志文件系统。
|
||
|
||
我们今天要学习的就是进程调度算法,也就是 Process Scheduling Algorithms。
|
||
|
||
**在许多中间件、语言设计甚至日常开发的业务系统中遇到问题时,我们常常会参考操作系统中成熟的解决办法**,进程调度就是这样一种常常被借鉴的场景,在不少语言的线程或者协程机制的设计里都有应用。
|
||
|
||
那操作系统的进程调度到底是如何设计的呢?话不多说,我们开始今天的学习。
|
||
|
||
## 进程是什么?
|
||
|
||
在聊进程调度算法之前,我们先简单复习一些操作系统相关的基础概念。
|
||
|
||
首先,我们要明白进程是什么?
|
||
|
||
我想“Process”最早被翻译成“进程”,应该指的就是“正在进行的程序”的意思。我们知道计算机是可以同时进行很多任务的,比如你现在可能就边开着浏览器阅读这篇文章,边打开着微信软件随时可以处理好友的消息。你的计算机就像一个真正的时间管理大师一样,并发而有条不紊地处理着各种复杂的任务。
|
||
|
||
但事实上,每个CPU核在同一时间只能同时运行一个程序,那计算机是如何做到看起来可以同时执行很多任务的呢?
|
||
|
||
这里就需要用到进程、线程之类的抽象了,这也是**早期计算机引入多进程的主要目的,让你的计算机看起来可以同时执行不同的任务**。
|
||
|
||
我们通常会把不同的程序分配给不同的独立进程去执行,让计算机基于一定的策略,把CPU的计算时间调度给不同的进程使用;但因为进程间切换的时间一般比较短,并不能达到人们能感知到的阈值,所以用户在使用计算机的时候就会觉得多个程序或者任务是同时,也就是并发,执行的。
|
||
|
||
如果你在Linux系统上运行一下`ps`命令,就可以看到你的计算机当前正在运行的许多进程了:
|
||
|
||
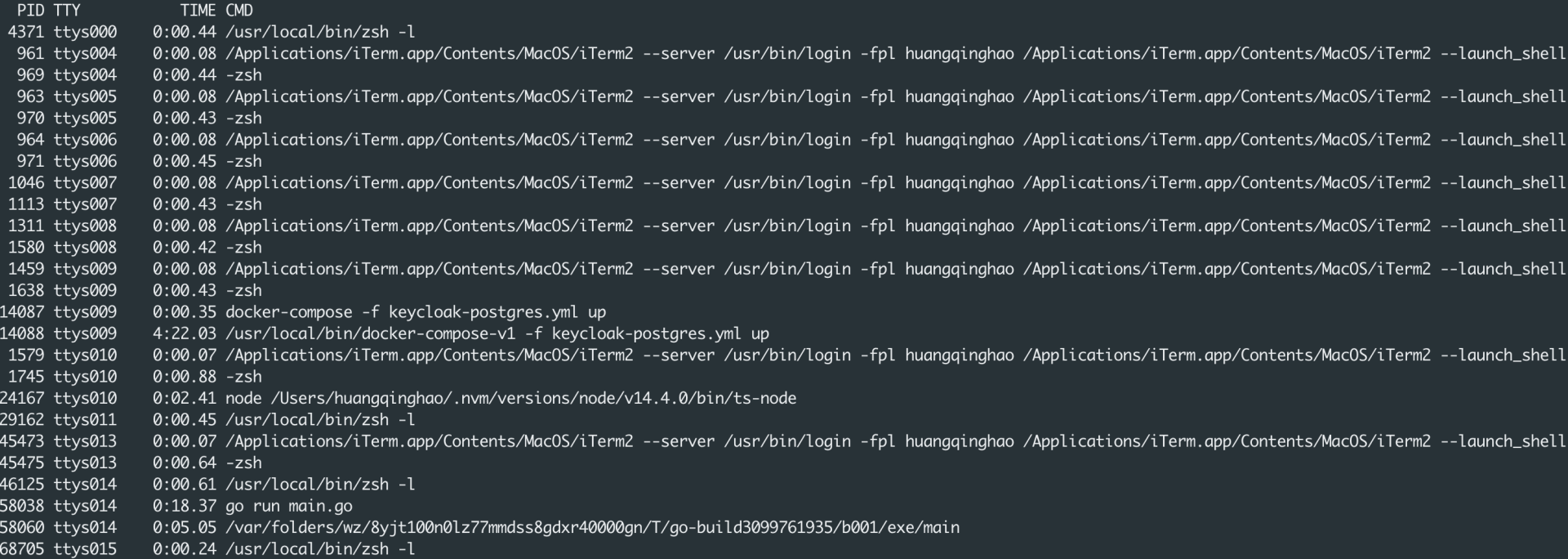
|
||
|
||
可以看到进程都会被分配一个PID,也就是进程的标识符。
|
||
|
||
而每个进程在执行程序的时候显然也要访问内存,也需要自己的程序计数器等资源,操作系统都会给每个进程独立分配这些资源。
|
||
|
||
如果把操作系统比作一家公司的CEO,进程就像这家公司的员工,每个员工当然需要被分配有自己独立的办公设备,而许多任务,就像是客户的需求。为了让这些员工可以有条不紊地完成这些需求,当然也就需要一定的调度算法。
|
||
|
||
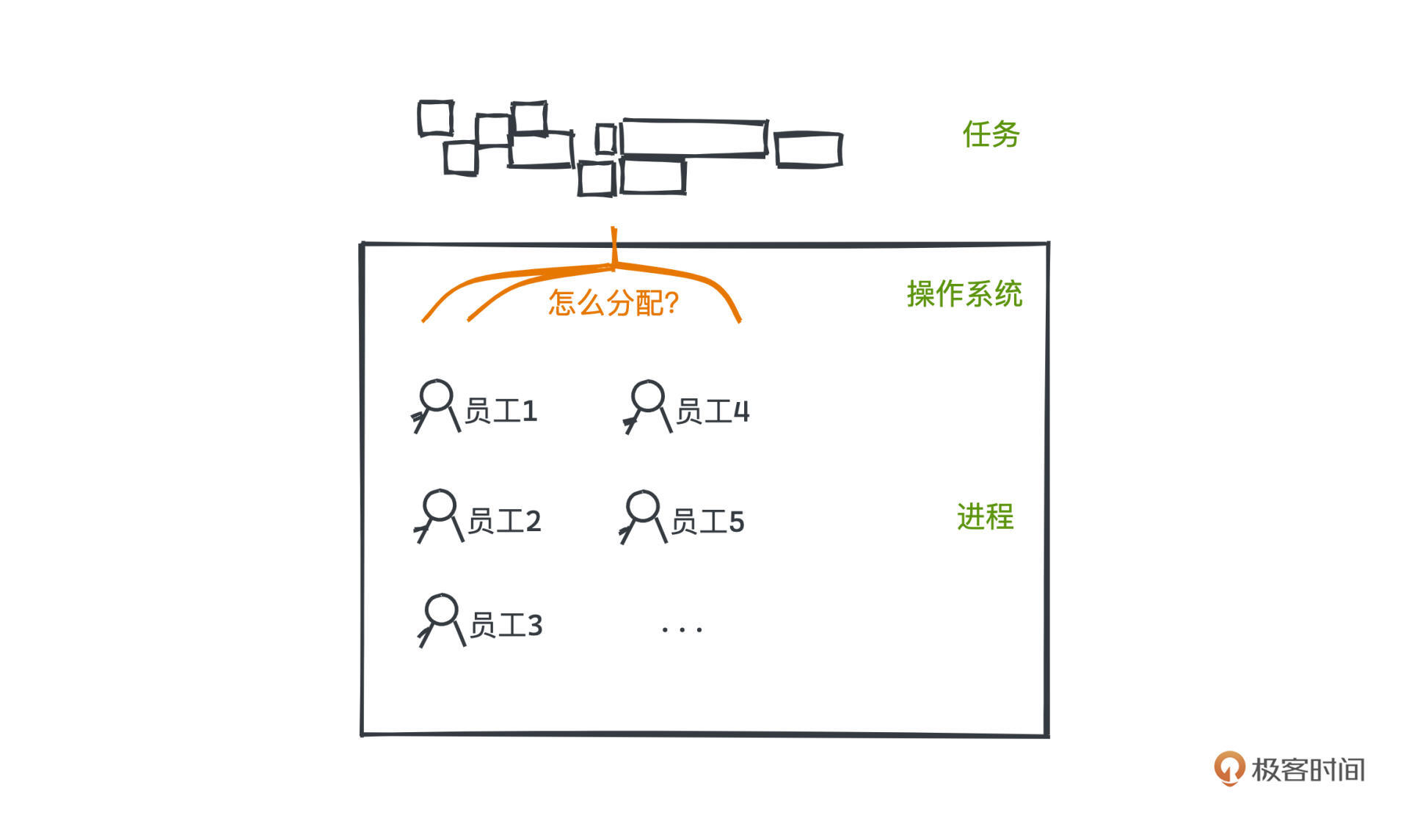
|
||
|
||
怎么实现调度呢?我们首先要介绍进程状态这个概念。其实就相当于每个员工当前的工作状态,我们只有知道各员工是空闲还是正在工作,才能科学分配需求,以高效完成更多任务。
|
||
|
||
## 进程状态
|
||
|
||
以Linux内核为例,进程的状态还是比较多的,它们都被定义在 include/linux/sched.h 下,#define 是C语言宏相关的语法,你不熟悉的话,简单理解成左边的是变量名,右边的是变量名对应的值就好了:
|
||
|
||
```java
|
||
#define TASK_RUNNING 0
|
||
#define TASK_INTERRUPTIBLE 1
|
||
#define TASK_UNINTERRUPTIBLE 2
|
||
#define __TASK_STOPPED 4
|
||
#define __TASK_TRACED 8
|
||
|
||
#define EXIT_DEAD 16
|
||
#define EXIT_ZOMBIE 32
|
||
#define EXIT_TRACE (EXIT_ZOMBIE | EXIT_DEAD)
|
||
|
||
#define TASK_DEAD 64
|
||
#define TASK_WAKEKILL 128
|
||
#define TASK_WAKING 256
|
||
#define TASK_PARKED 512
|
||
#define TASK_NOLOAD 1024
|
||
#define TASK_NEW 2048
|
||
#define TASK_STATE_MAX 4096
|
||
|
||
```
|
||
|
||
注意这里的state都是一个可以被表示成2的幂次的数字,这其实是一种常见的bitset的表示方式,方便用位运算判断状态,之后讲解布隆过滤器的时候我们再讨论。
|
||
|
||
**进程状态,本质上就是为了用有限的计算机资源合理且高效地完成更多的任务**。我们就看一种简化的模型来学习,把操作系统进程的状态分为3类:READY (就绪的) 、 RUNNING(运行的)、BLOCK(阻塞的)。
|
||
|
||
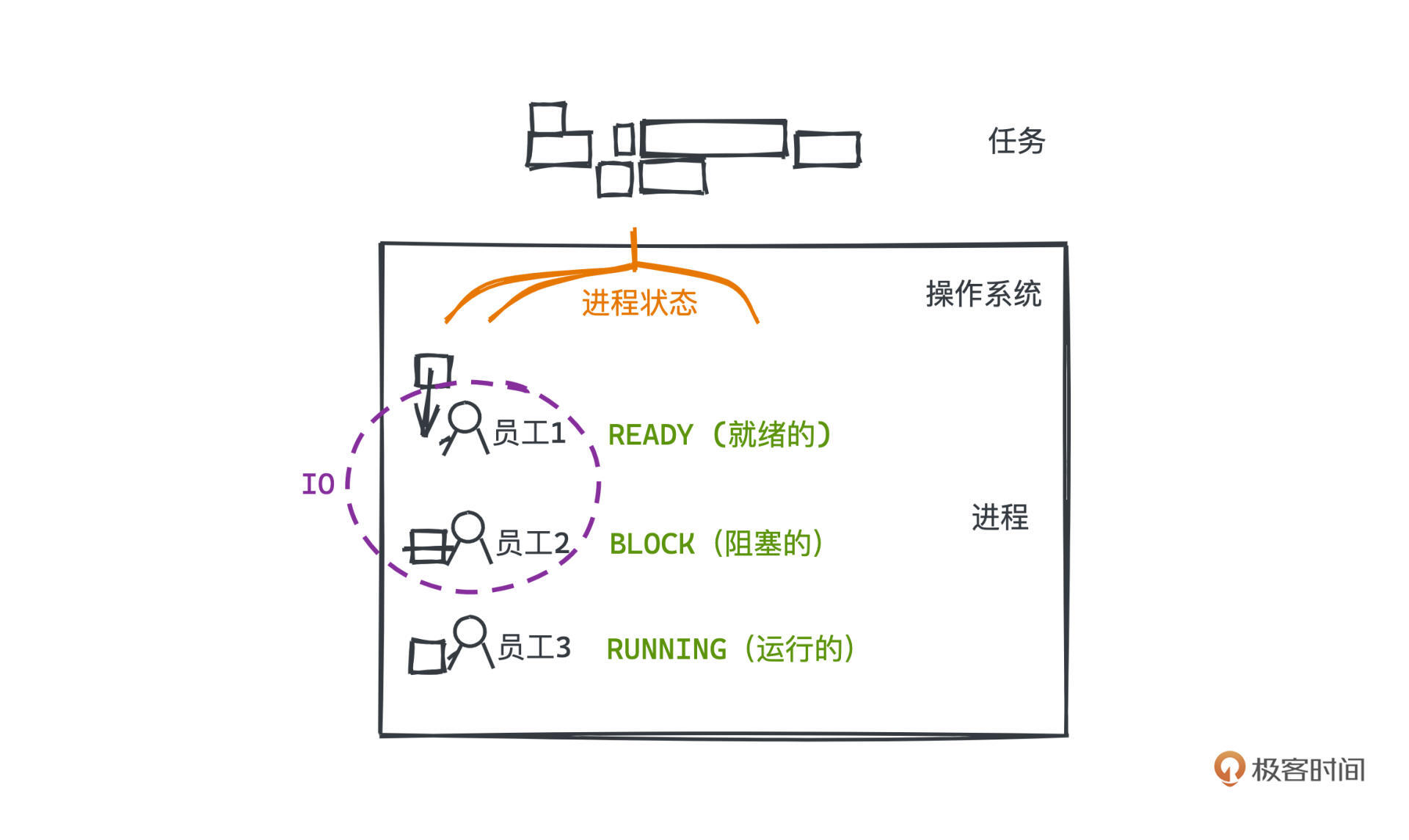
|
||
|
||
RUNNING就是程序正在执行的状态,非常好理解,READY和BLOCK要涉及程序执行中一块比较重要的耗时来源 IO。因为程序运行除了计算之外,也经常需要与外界进行交互,比如等待用户输入一串文本、或者往显示器上输出一副画面,或者从网卡接受一些数据等等,这些操作,我们一般称为IO,也就是输入输出。
|
||
|
||
计算机执行程序的时候是单进程的,如果需要等待一个IO操作才能执行后续指令,那在IO数据返回前,整个CPU就不会执行任何有意义的计算了,也就是只能放在那边空跑。用公司-员工的例子就是某个员工被一个任务阻塞了,其他员工也都只能闲着,什么都干不了,这显然不是一个好的策略。
|
||
|
||
如果有了多进程就不一样了。一个正在运行的进程,如果需要等待一个IO操作才能执行后续命令,我们就让这个进程的状态变成阻塞的。操作系统就会把当前阻塞的进程调度开,换一个可以被执行的也就是就绪的进程去运行,被调度执行的新进程现在就成为一个运行中的进程了,而那个被调度到一边的进程I/O结束后,也就会重新进入就绪状态。
|
||
|
||
过程切换就像这样:
|
||
|
||
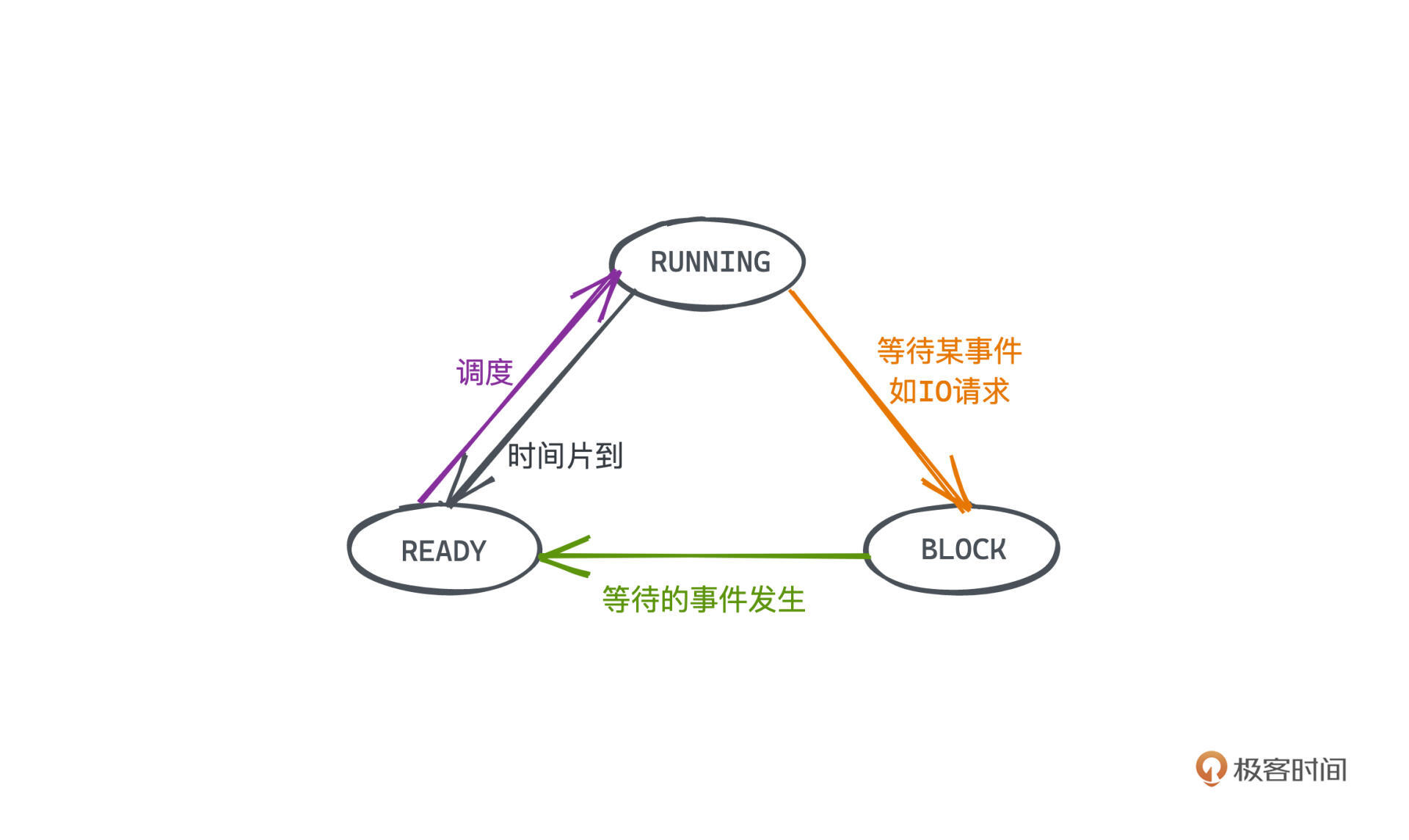
|
||
|
||
这是**进程的第二个意义:可以提高程序的性能,让我们不必再空等IO的耗时,尽可能多地利用CPU的计算资源**。
|
||
|
||
好,复习完进程相关的一些基本概念,我们进入今天的主题,调度算法。
|
||
|
||
## 调度算法
|
||
|
||
一个合理的调度算法对CPU的利用率、程序的总体运行效率、不同任务间的公平性起着决定性的作用,这并不是一件容易的事情,因为CPU的算力是各进程所需的资源,但它非常有限,于是人们发明了许多不同的调度策略。
|
||
|
||
考虑到不同任务的耗时和优先级两项指标,一般可以分为两大类策略:
|
||
|
||
* 非抢占式调度
|
||
* 抢占式调度
|
||
|
||
我们还是用公司-员工的例子来简单解释一下这两大类调度策略。
|
||
|
||
公司有许多客户的需求待处理,每个员工负责一个客户的需求,但都需要用到计算机来处理自己的需求,当然不同需求的解决时间可能不同;但是公司现在只有一台计算机,这时某个员工使用这台计算机,就好像操作系统用CPU执行某个进程。
|
||
|
||
我们的本质问题“如何用有限的计算机资源合理且高效地完成更多的任务”,现在其实就变成了如何在耗时不同的任务间合理切换进程。
|
||
|
||
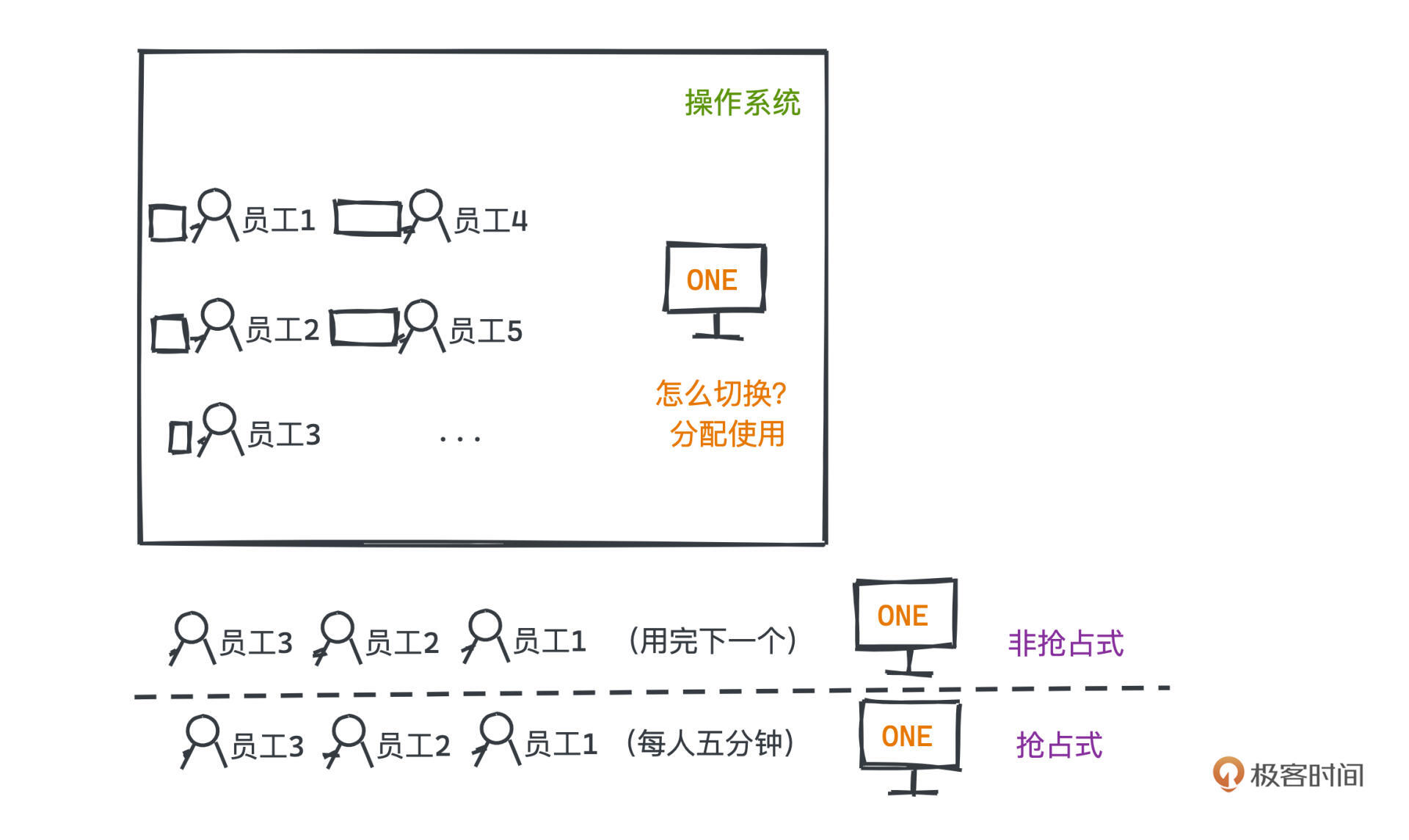
|
||
|
||
一个非常简单的想法就是让所有员工排队用这台计算机,轮到的这个员工一直使用到自己的所有工作都处理完,才让给下一个同事。这就是**非抢占式调度**的思路,操作系统调度到某个进程之后,不会对进程做任何干预,直到该进程阻塞或者结束,才会切换到其他就绪的进程。
|
||
|
||
但如果轮到的这个员工处理完自己的工作需要2小时,但后几名员工都只需要几分钟,这个排序效率就不够好了。
|
||
|
||
考虑到这种问题,就有了**抢占式调度**的策略,操作系统调度到某个进程之后会给它分配一个时间片,如果超过时间片还没有结束或者中途被阻塞,该进程会被操作系统挂起,调度其他进程来执行其他程序。这就好比在公司里加了一个协调者,如果有员工用电脑时间太长,就让他先暂停一会重新排队,先把计算机分配给其他同事。
|
||
|
||
这里进程的切换主要依赖操作系统的时钟中断,是一个比较复杂的机制,涉及计算机硬件,感兴趣的同学可以搜索时钟中断了解相关知识。
|
||
|
||
显然,抢占式调度会有更好的公平性,不容易让资源永远被个别耗时长的程序长期霸占,而让其他任务迟迟得不到运行的机会,被饿死;**但抢占式调度也带来了更多的切换次数,这会造成更高的上下文切换的成本**。
|
||
|
||
就好像不同员工如果用同一个电脑工作,那每次员工被调度开的时候,肯定要保存自己的工作状态,比如保存自己操作的一些数据并关闭文档;下一个员工来的时候,也要恢复自己之前的工作状态。这些都会产生成本。
|
||
|
||
进程的切换也是一样的,我们需要保留程序运行的状态,然后重新恢复另一个进程的运行状态,像虚拟地址空间映射也需要做相应的转换以保证进程间的隔离性。如果频繁切换就会让CPU真正用于计算的时间比例降低。
|
||
|
||
所以我们很难一概而论说哪种调度方式就是更好的,一般来说:
|
||
|
||
* 非抢占式调度,更适合调度可以忍受延迟执行的普通进程。
|
||
* 抢占式调度,更适合调度交互性要求高的实时进程。
|
||
|
||
操作系统的应用场景和任务类型很多,有些场景实时性要求就更高。像在自动驾驶场景中,一些碰撞检测或者视觉信号的检测关乎驾驶员和行人的生命安全,显然不能让它们随意被其他播放音乐之类的任务阻塞。我们一定要让这些高优先级的任务可以随时抢占优先使用CPU,而一些批处理之类的后台任务可以按照先来先到的顺序慢慢执行。
|
||
|
||
接下来,我们就以Linux中进程调度的实现为例,讲一讲基于这两类调度策略的一些常用调度算法;当然,由于操作系统中的真实源码实现涉及Linux对进程的管理和存储方式,不是一两节课能讲完的需要你自己研究,所以我们会用伪代码来讲解核心思路。
|
||
|
||
## Linux的进程
|
||
|
||
按相同的思路,Linux进程其实也分为两类,一类是有实时交互需要的,它们需要尽快返回结果,不能一直得不到执行;另一类则是普通进程,大部分优先级要求不高,可以忍受更长时间的得不到执行。
|
||
|
||
|
||
|
||
我们先来看实时交互进程中的调度算法。
|
||
|
||
### Round-Robin 算法
|
||
|
||
一种最经典的实现就是 Round-Robin 调度算法,这种算法也常常作为服务器负载均衡的算法,其主要特点就是比较简单且比较公平。
|
||
|
||
具体做法非常好理解,Round-Robin 本身从字面意义上来说就带有循环的意思,所以顾名思义,我们固定时间片段的长度,然后把所有的进程用一个队列维护,每个进程只能最多执行时间片的最大长度,比如50ms,如果还没执行完或者因为IO等原因阻塞,就得换下一个进程执行了。
|
||
|
||
**实时进程调度的算法衡量指标之一就是平衡性**,因为有实时交互需要的进程不能一直得不到执行,需要雨露均沾。比如在图形化的交互任务中,平衡性比较好的调度算法,往往就不会出现有一些计算密集型的任务过多占用CPU导致用户体验到卡顿的情况。
|
||
|
||
所以Round-Robin算法最大的优势就是不会存在某个进程执行时间太长,每个程序都可以有机会得到较早的执行。
|
||
|
||
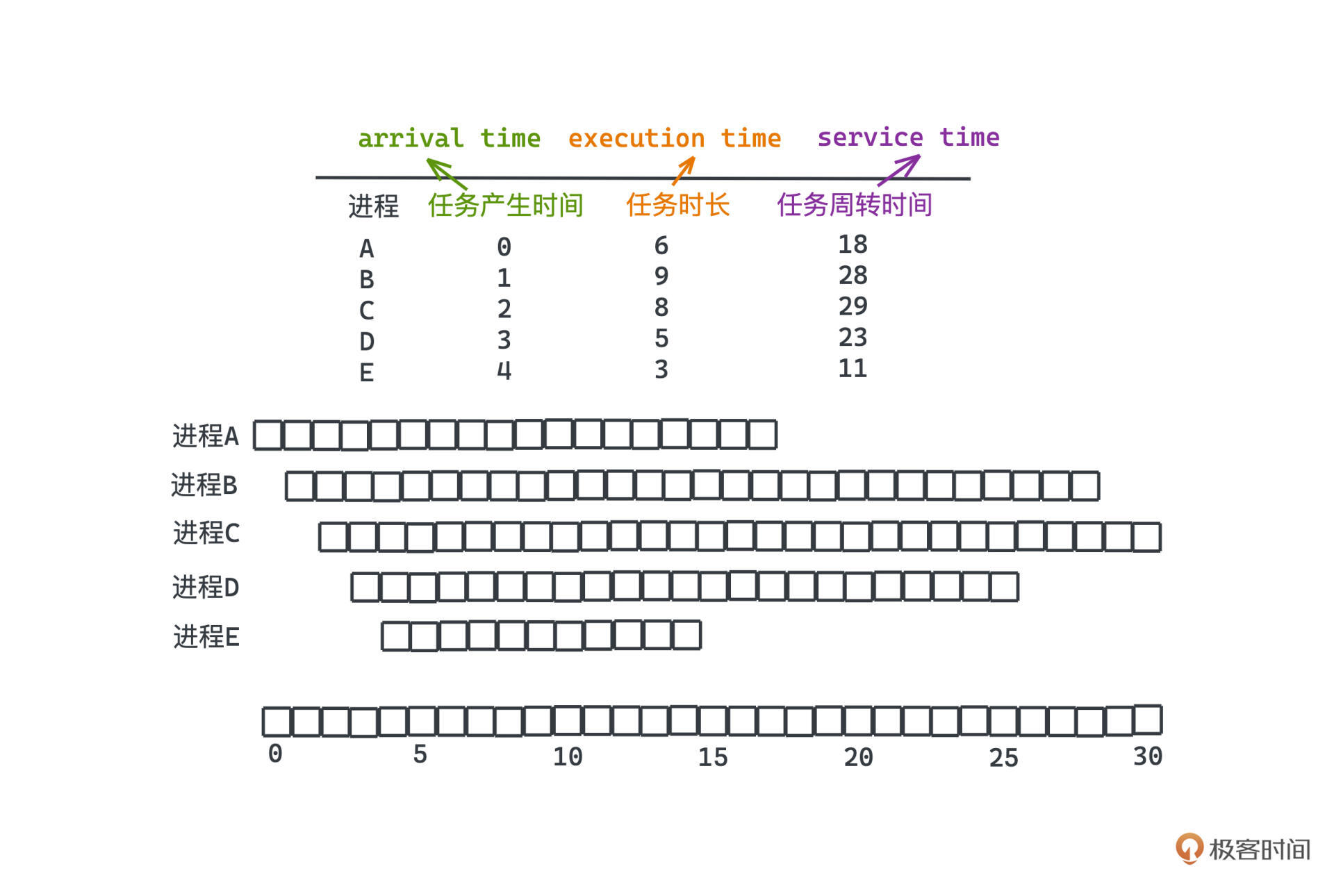
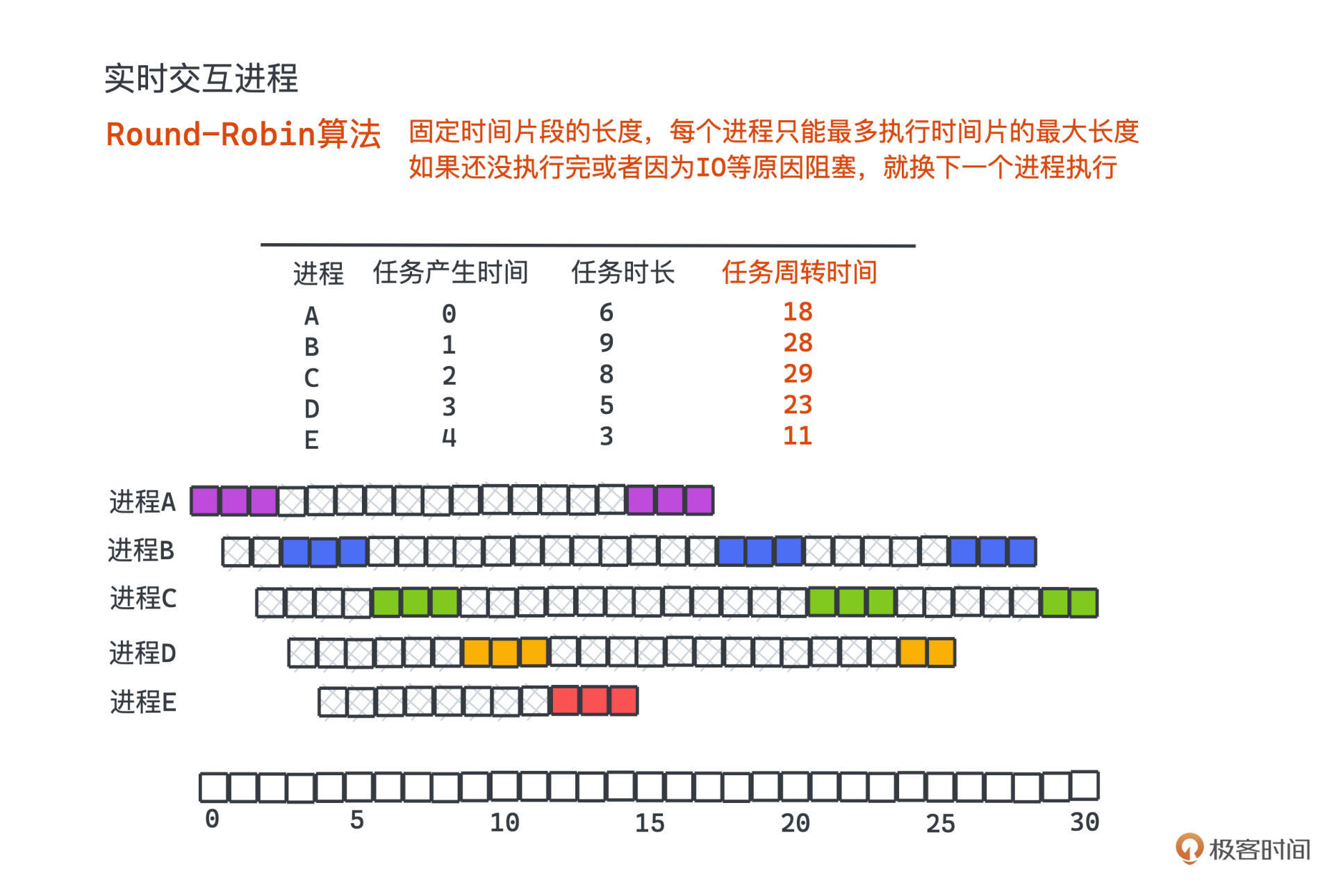
看 Round-Robin 的例子,一共有ABCDE5个进程,arrival time代表进程产生的时间,service time代表进程总共需要执行的时间,单位就是时间片的长度。
|
||
|
||
|
||
|
||
可以看到,在整个操作系统运行的时间里,这些进程都是轮流执行的,不会一直等待。
|
||
|
||
那我们选择的时间片是不是越短越好呢?
|
||
|
||
当然不是。前面说过进程切换是有开销的,每次切换都需要保存程序运行的状态,并将新的状态装载进寄存器中,这些都需要时间,这个时间大约需要1ms。
|
||
|
||
如果我们极端一点假设每个时间片只有2ms,那么每次切换到新的进程,大约需要花费1ms恢复现场和保留现场,那真正留给计算机计算的时间只占了总CPU运行时间的50%,这显然是一个极大的浪费,可能直接导致系统上所有的程序运行速度直接拖慢一倍!**一般来说,为了平衡公平性和效率,在目前的硬件架构下,常见的时间片长度为30-50ms**。
|
||
|
||
Round-Robin算法的相应逻辑翻译成伪代码也非常简单:
|
||
|
||
```java
|
||
time_slot = 50
|
||
cur_time = 0 // 用于表示运行的时间
|
||
tasks = new queue() // 用于存储所有的进程
|
||
while (!tasks.empty()) {
|
||
task = tasks.pop() // 选出队列前的进程运行
|
||
if (task.time > 50) { // 如果运行时间超过时间片长度,需要挂起当前进程
|
||
tastk.time -= 50
|
||
tasks.insert(task) // 并将该进程重新放回队列中重新排队等待下一次调度
|
||
cur_time += time_slot
|
||
} else {
|
||
cur_time += task.time
|
||
}
|
||
}
|
||
|
||
```
|
||
|
||
当然真实的上下文切换是由时钟中断所触发的,并且如果出现阻塞,当前进程也会直接被调度走,就不在代码中演示了。
|
||
|
||
在实时进程调度算法中,常用的还有高响应比优先调度 HRRN 算法和多级反馈队列调度 MFQ 算法等,简单介绍一下感兴趣可以自己搜索相关资料学习:
|
||
|
||
* HRRN 算法是一个非抢占式调度算法,按照“等待时间/执行时间”作为优先级排列,每次选择优先级最高的进程执行,直至完成。
|
||
* MFQ 算法比较复杂,建立了多个等级的队列,优先级高的队列中的进程总是优先得到调度且时间片短;优先级低的队列则不太容易调度,但调度到可以运行的时间片也更长一些。
|
||
|
||
### 普通进程调度
|
||
|
||
我们再来看看实时性要求没有那么强的普通进程是如何被调度的。
|
||
|
||
在这种场景下,我们通常关注的指标主要有两个:
|
||
|
||
* 吞吐量,系统单位时间内完成的任务数量。
|
||
* 周转时间,每个任务从提交到完成的时间。
|
||
|
||
常见的算法也都比较简单,主要有三种:FCFS先到先服务算法、SJF最短任务优先算法、SRTF最短剩余时间优先算法,这三种算法都是非抢占式的。
|
||
|
||
### FCFS
|
||
|
||
FCFS(First Come First Serve)是最简单也最直接的,其实它和我们学过的队列很像。
|
||
|
||
按照进程产生的顺序将它们放到一个队列中,每次调度的时候,直接取队列中第一个进程执行,这是一个非抢占式算法,所以直到这个任务完成或者被阻塞前,我们都会一直执行这个任务;如果这个任务被阻塞了,就重新将它加回队尾重新排队。
|
||
|
||

|
||
|
||
但不好的地方就是对短任务不是很公平,如果短任务之前有长任务,长任务就会一直执行,这样一来短任务的周转时间就被拉长了,即使完成它的时间其实很短。整体的平均周转时间也就变得比较差。
|
||
|
||
### SJF
|
||
|
||
有了FCFS的基础,我们自然想到,让短任务更优先执行,是不是就能降低平均周转时间了呢?这就是SJF(Shortest Job First)的思路,
|
||
|
||
SJF在从队列取出任务的时候,按照作业时间把待作业的任务排序,优先调度**最短可以完成的**任务。
|
||
|
||

|
||
|
||
SJF因为按各任务的需要时长排序,可能导致长任务一直得到不到执行,会被饿死,而因为最短可完成时长没有把有IO的情况纳入计算,也就出现了下一个SRTF算法。
|
||
|
||
### SRTF
|
||
|
||
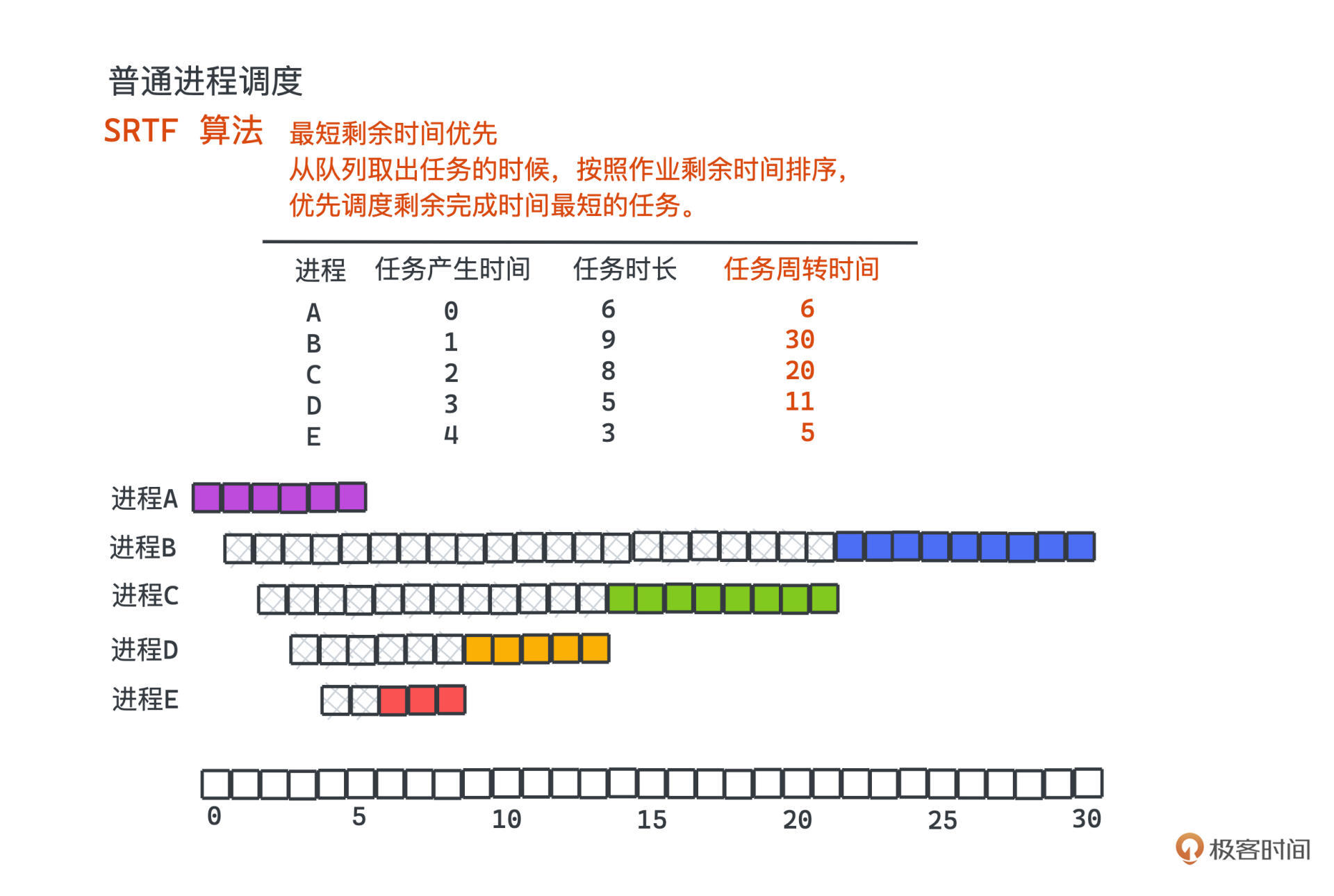
SRTF(Shortest Remaining Time First)从思想上来说和SJF差不多,只不过放回队列的时候按照作业剩余时间排序,优先调度**剩余完成时间最短的**任务。
|
||
|
||
|
||
|
||
因为都是非抢占式的调度,在没有IO的时候,SRTF其实和SJF的机制是一样的,只不过它**可以把有IO的情况也纳入到考虑范畴中**,如果任务因为阻塞主动调度开,我们再次出队的时候不会再傻傻的按照任务总时长进行排序,而是按照剩余需要的时长进行排序,尽量提高调度整体的吞吐量。
|
||
|
||
同样,SRTF基于时长的排序策略也一定程度上放弃了公平性,和SJF一样,可能导致长任务一直得到不到执行。
|
||
|
||
当然,其实还有许多特定场景的调度算法。比如有些系统中,我们会关心某些任务的截止时间,如果任务快到截止时间了,我们需要优先完成接近截止时间的任务。
|
||
|
||
## 总结
|
||
|
||
我们讲了几个主要的CPU调度算法,大致可以分为抢占式调度和非抢占式调度两大类,分别更加适合调度交互性要求高的实时进程和可以忍受延迟执行的普通进程。在实时交互进程中,有简单且较公平的Round-Robin 调度算法,在普通进程调度时,有非抢占式的FCFS先到先服务算法、SJF最短任务优先算法、SRTF最短剩余时间优先算法。
|
||
|
||
不同的调度算法,有不同的使用场景,很难说哪个算法一定比另一个更好,不同的算法只是在公平性、效率、吞吐量、等待时间等因素间做了不同的取舍,我们要根据实际的需要选择合适的调度算法。
|
||
|
||
而在许多操作系统之外的场景,相关的调度思想也有许多应用。比如服务器的负载均衡等场景下,我们就可以采用公平的 Round-Robin 算法进行类似的轮训请求;甚至在前端领域也有应用;比如,React的fiber机制也是源于操作系统的进程调度,它很好地解决了React网页应用可能因为一些diff等需要cpu密集计算的操作所带来的卡顿现象,让单线程的JS运行时有了“多线程”般的神奇能力。
|
||
|
||
### 课后作业
|
||
|
||
最后,我也留给你一个小思考题。如果让你设计一个对DDL,也就是任务最晚执行完毕时间,敏感的调度算法,你会怎么样设计呢?
|
||
|
||
欢迎你留言与我讨论,如果觉得有帮助,也欢迎你转发给你的朋友一起学习。我们下节课见~
|
||
|