|
|
|
|
|
# 17 | SingleFlight 和 CyclicBarrier:请求合并和循环栅栏该怎么用?
|
|
|
|
|
|
|
|
|
|
|
|
你好,我是鸟窝。
|
|
|
|
|
|
|
|
|
|
|
|
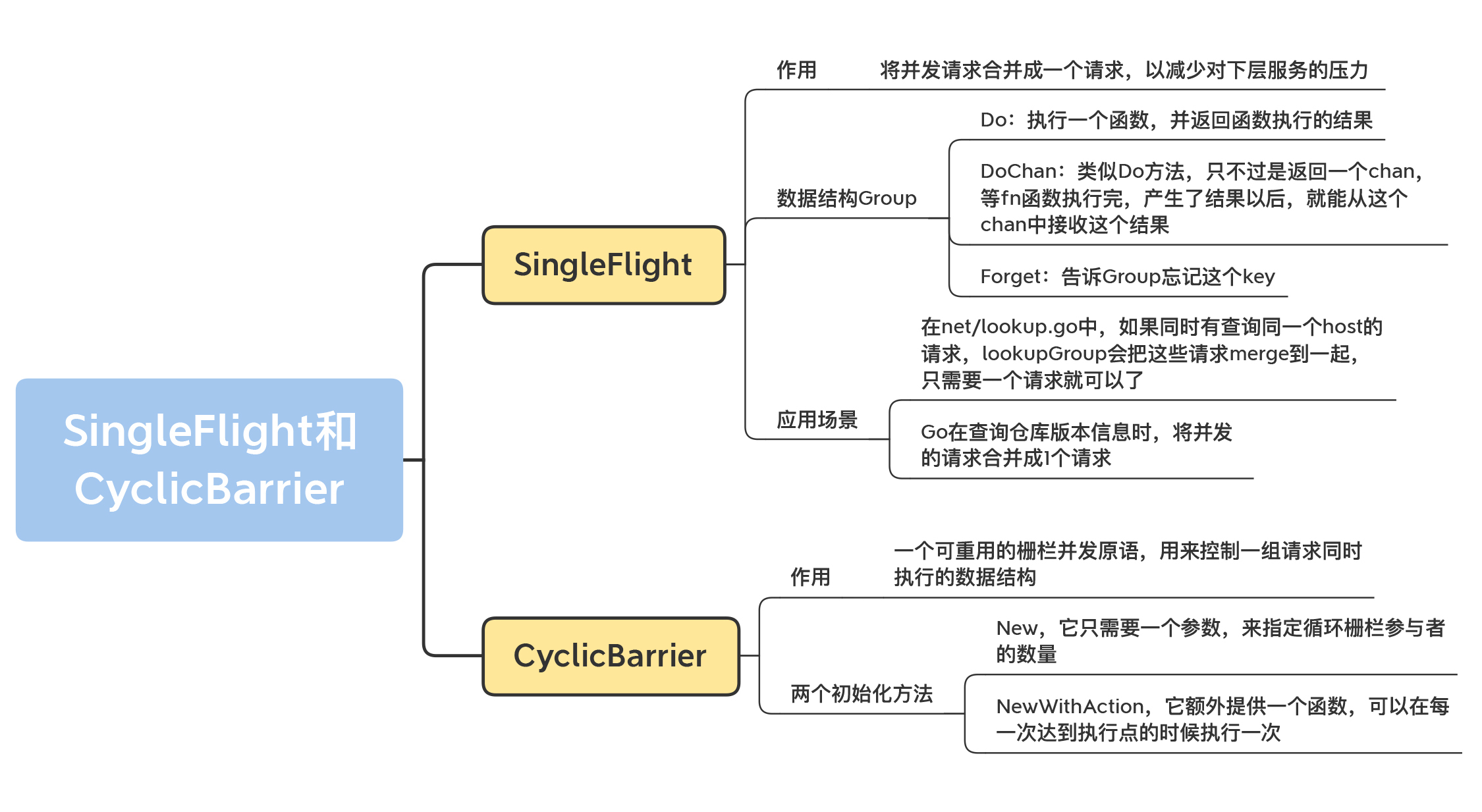
这节课,我来给你介绍两个非常重要的扩展并发原语:SingleFlight和CyclicBarrier。SingleFlight的作用是将并发请求合并成一个请求,以减少对下层服务的压力;而CyclicBarrier是一个可重用的栅栏并发原语,用来控制一组请求同时执行的数据结构。
|
|
|
|
|
|
|
|
|
|
|
|
其实,它们两个并没有直接的关系,只是内容相对来说比较少,所以我打算用最短的时间带你掌握它们。一节课就能掌握两个“武器”,是不是很高效?
|
|
|
|
|
|
|
|
|
|
|
|
# 请求合并SingleFlight
|
|
|
|
|
|
|
|
|
|
|
|
SingleFlight是Go开发组提供的一个扩展并发原语。它的作用是,在处理多个goroutine同时调用同一个函数的时候,只让一个goroutine去调用这个函数,等到这个goroutine返回结果的时候,再把结果返回给这几个同时调用的goroutine,这样可以减少并发调用的数量。
|
|
|
|
|
|
|
|
|
|
|
|
这里我想先回答一个问题:标准库中的sync.Once也可以保证并发的goroutine只会执行一次函数f,那么,SingleFlight和sync.Once有什么区别呢?
|
|
|
|
|
|
|
|
|
|
|
|
其实,sync.Once不是只在并发的时候保证只有一个goroutine执行函数f,而是会保证永远只执行一次,而SingleFlight是每次调用都重新执行,并且在多个请求同时调用的时候只有一个执行。它们两个面对的场景是不同的,**sync.Once主要是用在单次初始化场景中,而SingleFlight主要用在合并并发请求的场景中**,尤其是缓存场景。
|
|
|
|
|
|
|
|
|
|
|
|
如果你学会了SingleFlight,在面对秒杀等大并发请求的场景,而且这些请求都是读请求时,你就可以把这些请求合并为一个请求,这样,你就可以将后端服务的压力从n降到1。尤其是在面对后端是数据库这样的服务的时候,采用 SingleFlight可以极大地提高性能。那么,话不多说,就让我们开始学习SingleFlight吧。
|
|
|
|
|
|
|
|
|
|
|
|
## 实现原理
|
|
|
|
|
|
|
|
|
|
|
|
SingleFlight使用互斥锁Mutex和Map来实现。Mutex提供并发时的读写保护,Map用来保存同一个key的正在处理(in flight)的请求。
|
|
|
|
|
|
|
|
|
|
|
|
SingleFlight的数据结构是Group,它提供了三个方法。
|
|
|
|
|
|
|
|
|
|
|
|

|
|
|
|
|
|
|
|
|
|
|
|
* Do:这个方法执行一个函数,并返回函数执行的结果。你需要提供一个key,对于同一个key,在同一时间只有一个在执行,同一个key并发的请求会等待。第一个执行的请求返回的结果,就是它的返回结果。函数fn是一个无参的函数,返回一个结果或者error,而Do方法会返回函数执行的结果或者是error,shared会指示v是否返回给多个请求。
|
|
|
|
|
|
* DoChan:类似Do方法,只不过是返回一个chan,等fn函数执行完,产生了结果以后,就能从这个chan中接收这个结果。
|
|
|
|
|
|
* Forget:告诉Group忘记这个key。这样一来,之后这个key请求会执行f,而不是等待前一个未完成的fn函数的结果。
|
|
|
|
|
|
|
|
|
|
|
|
下面,我们来看具体的实现方法。
|
|
|
|
|
|
|
|
|
|
|
|
首先,SingleFlight定义一个辅助对象call,这个call就代表正在执行fn函数的请求或者是已经执行完的请求。Group代表SingleFlight。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
// 代表一个正在处理的请求,或者已经处理完的请求
|
|
|
|
|
|
type call struct {
|
|
|
|
|
|
wg sync.WaitGroup
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
// 这个字段代表处理完的值,在waitgroup完成之前只会写一次
|
|
|
|
|
|
// waitgroup完成之后就读取这个值
|
|
|
|
|
|
val interface{}
|
|
|
|
|
|
err error
|
|
|
|
|
|
|
|
|
|
|
|
// 指示当call在处理时是否要忘掉这个key
|
|
|
|
|
|
forgotten bool
|
|
|
|
|
|
dups int
|
|
|
|
|
|
chans []chan<- Result
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
// group代表一个singleflight对象
|
|
|
|
|
|
type Group struct {
|
|
|
|
|
|
mu sync.Mutex // protects m
|
|
|
|
|
|
m map[string]*call // lazily initialized
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
我们只需要查看一个Do方法,DoChan的处理方法是类似的。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
func (g *Group) Do(key string, fn func() (interface{}, error)) (v interface{}, err error, shared bool) {
|
|
|
|
|
|
g.mu.Lock()
|
|
|
|
|
|
if g.m == nil {
|
|
|
|
|
|
g.m = make(map[string]*call)
|
|
|
|
|
|
}
|
|
|
|
|
|
if c, ok := g.m[key]; ok {//如果已经存在相同的key
|
|
|
|
|
|
c.dups++
|
|
|
|
|
|
g.mu.Unlock()
|
|
|
|
|
|
c.wg.Wait() //等待这个key的第一个请求完成
|
|
|
|
|
|
return c.val, c.err, true //使用第一个key的请求结果
|
|
|
|
|
|
}
|
|
|
|
|
|
c := new(call) // 第一个请求,创建一个call
|
|
|
|
|
|
c.wg.Add(1)
|
|
|
|
|
|
g.m[key] = c //加入到key map中
|
|
|
|
|
|
g.mu.Unlock()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
g.doCall(c, key, fn) // 调用方法
|
|
|
|
|
|
return c.val, c.err, c.dups > 0
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
doCall方法会实际调用函数fn:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
func (g *Group) doCall(c *call, key string, fn func() (interface{}, error)) {
|
|
|
|
|
|
c.val, c.err = fn()
|
|
|
|
|
|
c.wg.Done()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
g.mu.Lock()
|
|
|
|
|
|
if !c.forgotten { // 已调用完,删除这个key
|
|
|
|
|
|
delete(g.m, key)
|
|
|
|
|
|
}
|
|
|
|
|
|
for _, ch := range c.chans {
|
|
|
|
|
|
ch <- Result{c.val, c.err, c.dups > 0}
|
|
|
|
|
|
}
|
|
|
|
|
|
g.mu.Unlock()
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
在这段代码中,你要注意下第7行。在默认情况下,forgotten==false,所以第8行默认会被调用,也就是说,第一个请求完成后,后续的同一个key的请求又重新开始新一次的fn函数的调用。
|
|
|
|
|
|
|
|
|
|
|
|
Go标准库的代码中就有一个SingleFlight的[实现](https://github.com/golang/go/blob/50bd1c4d4eb4fac8ddeb5f063c099daccfb71b26/src/internal/singleflight/singleflight.go),而扩展库中的SingleFlight就是在标准库的代码基础上改的,逻辑几乎一模一样,我就不多说了。
|
|
|
|
|
|
|
|
|
|
|
|
## 应用场景
|
|
|
|
|
|
|
|
|
|
|
|
了解了SingleFlight的实现原理,下面我们来看看它都应用于什么场景中。
|
|
|
|
|
|
|
|
|
|
|
|
Go代码库中有两个地方用到了SingleFlight。
|
|
|
|
|
|
|
|
|
|
|
|
第一个是在[net/lookup.go](https://github.com/golang/go/blob/b1b67841d1e229b483b0c9dd50ddcd1795b0f90f/src/net/lookup.go)中,如果同时有查询同一个host的请求,lookupGroup会把这些请求merge到一起,只需要一个请求就可以了:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
// lookupGroup merges LookupIPAddr calls together for lookups for the same
|
|
|
|
|
|
// host. The lookupGroup key is the LookupIPAddr.host argument.
|
|
|
|
|
|
// The return values are ([]IPAddr, error).
|
|
|
|
|
|
lookupGroup singleflight.Group
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
第二个是Go在查询仓库版本信息时,将并发的请求合并成1个请求:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
func metaImportsForPrefix(importPrefix string, mod ModuleMode, security web.SecurityMode) (*urlpkg.URL, []metaImport, error) {
|
|
|
|
|
|
// 使用缓存保存请求结果
|
|
|
|
|
|
setCache := func(res fetchResult) (fetchResult, error) {
|
|
|
|
|
|
fetchCacheMu.Lock()
|
|
|
|
|
|
defer fetchCacheMu.Unlock()
|
|
|
|
|
|
fetchCache[importPrefix] = res
|
|
|
|
|
|
return res, nil
|
|
|
|
|
|
|
|
|
|
|
|
// 使用 SingleFlight请求
|
|
|
|
|
|
resi, _, _ := fetchGroup.Do(importPrefix, func() (resi interface{}, err error) {
|
|
|
|
|
|
fetchCacheMu.Lock()
|
|
|
|
|
|
// 如果缓存中有数据,那么直接从缓存中取
|
|
|
|
|
|
if res, ok := fetchCache[importPrefix]; ok {
|
|
|
|
|
|
fetchCacheMu.Unlock()
|
|
|
|
|
|
return res, nil
|
|
|
|
|
|
}
|
|
|
|
|
|
fetchCacheMu.Unlock()
|
|
|
|
|
|
......
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
需要注意的是,这里涉及到了缓存的问题。上面的代码会把结果放在缓存中,这也是常用的一种解决缓存击穿的例子。
|
|
|
|
|
|
|
|
|
|
|
|
设计缓存问题时,我们常常需要解决缓存穿透、缓存雪崩和缓存击穿问题。缓存击穿问题是指,在平常高并发的系统中,大量的请求同时查询一个 key 时,如果这个key正好过期失效了,就会导致大量的请求都打到数据库上。这就是缓存击穿。
|
|
|
|
|
|
|
|
|
|
|
|
用SingleFlight来解决缓存击穿问题再合适不过了。因为,这个时候,只要这些对同一个key的并发请求的其中一个到数据库中查询,就可以了,这些并发的请求可以共享同一个结果。因为是缓存查询,不用考虑幂等性问题。
|
|
|
|
|
|
|
|
|
|
|
|
事实上,在Go生态圈知名的缓存框架groupcache中,就使用了较早的Go标准库的SingleFlight实现。接下来,我就来给你介绍一下groupcache是如何使用SingleFlight解决缓存击穿问题的。
|
|
|
|
|
|
|
|
|
|
|
|
groupcache中的SingleFlight只有一个方法:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
func (g *Group) Do(key string, fn func() (interface{}, error)) (interface{}, error)
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
SingleFlight的作用是,在加载一个缓存项的时候,合并对同一个key的load的并发请求:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
type Group struct {
|
|
|
|
|
|
。。。。。。
|
|
|
|
|
|
// loadGroup ensures that each key is only fetched once
|
|
|
|
|
|
// (either locally or remotely), regardless of the number of
|
|
|
|
|
|
// concurrent callers.
|
|
|
|
|
|
loadGroup flightGroup
|
|
|
|
|
|
......
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
func (g *Group) load(ctx context.Context, key string, dest Sink) (value ByteView, destPopulated bool, err error) {
|
|
|
|
|
|
viewi, err := g.loadGroup.Do(key, func() (interface{}, error) {
|
|
|
|
|
|
// 从cache, peer, local尝试查询cache
|
|
|
|
|
|
return value, nil
|
|
|
|
|
|
})
|
|
|
|
|
|
if err == nil {
|
|
|
|
|
|
value = viewi.(ByteView)
|
|
|
|
|
|
}
|
|
|
|
|
|
return
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
其它的知名项目如Cockroachdb(小强数据库)、CoreDNS(DNS服务器)等都有SingleFlight应用,你可以查看这些项目的代码,加深对SingleFlight的理解。
|
|
|
|
|
|
|
|
|
|
|
|
总结来说,使用SingleFlight时,可以通过合并请求的方式降低对下游服务的并发压力,从而提高系统的性能,常常用于缓存系统中。最后,我想给你留一个思考题,你觉得,SingleFlight能不能合并并发的写操作呢?
|
|
|
|
|
|
|
|
|
|
|
|
# 循环栅栏CyclicBarrier
|
|
|
|
|
|
|
|
|
|
|
|
接下来,我再给你介绍另外一个并发原语:循环栅栏(CyclicBarrier),它常常应用于重复进行一组goroutine同时执行的场景中。
|
|
|
|
|
|
|
|
|
|
|
|
[CyclicBarrier](https://github.com/marusama/cyclicbarrier)允许一组goroutine彼此等待,到达一个共同的执行点。同时,因为它可以被重复使用,所以叫循环栅栏。具体的机制是,大家都在栅栏前等待,等全部都到齐了,就抬起栅栏放行。
|
|
|
|
|
|
|
|
|
|
|
|
事实上,这个CyclicBarrier是参考[Java CyclicBarrier](https://docs.oracle.com/en/java/javase/15/docs/api/java.base/java/util/concurrent/CyclicBarrier.html)和[C# Barrier](https://docs.microsoft.com/en-us/dotnet/api/system.threading.barrier?redirectedfrom=MSDN&view=netcore-3.1)的功能实现的。Java提供了CountDownLatch(倒计时器)和CyclicBarrier(循环栅栏)两个类似的用于保证多线程到达同一个执行点的类,只不过前者是到达0的时候放行,后者是到达某个指定的数的时候放行。C# Barrier功能也是类似的,你可以查看链接,了解它的具体用法。
|
|
|
|
|
|
|
|
|
|
|
|
你可能会觉得,CyclicBarrier和WaitGroup的功能有点类似,确实是这样。不过,CyclicBarrier更适合用在“固定数量的goroutine等待同一个执行点”的场景中,而且在放行goroutine之后,CyclicBarrier可以重复利用,不像WaitGroup重用的时候,必须小心翼翼避免panic。
|
|
|
|
|
|
|
|
|
|
|
|
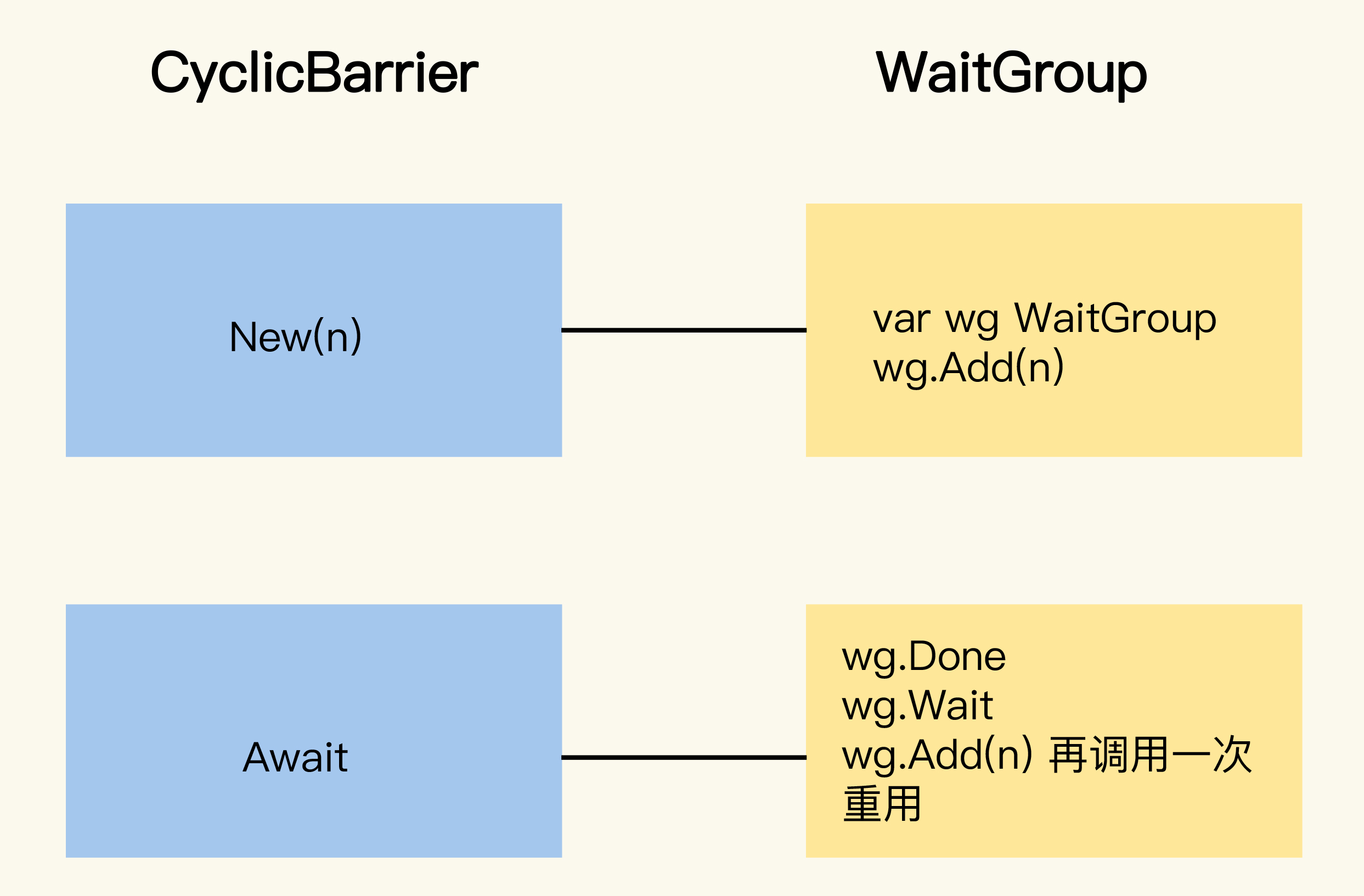
处理可重用的多goroutine等待同一个执行点的场景的时候,CyclicBarrier和WaitGroup方法调用的对应关系如下:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
可以看到,如果使用WaitGroup实现的话,调用比较复杂,不像CyclicBarrier那么清爽。更重要的是,如果想重用WaitGroup,你还要保证,将WaitGroup的计数值重置到n的时候不会出现并发问题。
|
|
|
|
|
|
|
|
|
|
|
|
WaitGroup更适合用在“一个goroutine等待一组goroutine到达同一个执行点”的场景中,或者是不需要重用的场景中。
|
|
|
|
|
|
|
|
|
|
|
|
好了,了解了CyclicBarrier的应用场景和功能,下面我们来学习下它的具体实现。
|
|
|
|
|
|
|
|
|
|
|
|
## 实现原理
|
|
|
|
|
|
|
|
|
|
|
|
CyclicBarrier有两个初始化方法:
|
|
|
|
|
|
|
|
|
|
|
|
1. 第一个是New方法,它只需要一个参数,来指定循环栅栏参与者的数量;
|
|
|
|
|
|
2. 第二个方法是NewWithAction,它额外提供一个函数,可以在每一次到达执行点的时候执行一次。具体的时间点是在最后一个参与者到达之后,但是其它的参与者还未被放行之前。我们可以利用它,做放行之前的一些共享状态的更新等操作。
|
|
|
|
|
|
|
|
|
|
|
|
这两个方法的签名如下:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
func New(parties int) CyclicBarrier
|
|
|
|
|
|
func NewWithAction(parties int, barrierAction func() error) CyclicBarrier
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
CyclicBarrier是一个接口,定义的方法如下:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
type CyclicBarrier interface {
|
|
|
|
|
|
// 等待所有的参与者到达,如果被ctx.Done()中断,会返回ErrBrokenBarrier
|
|
|
|
|
|
Await(ctx context.Context) error
|
|
|
|
|
|
|
|
|
|
|
|
// 重置循环栅栏到初始化状态。如果当前有等待者,那么它们会返回ErrBrokenBarrier
|
|
|
|
|
|
Reset()
|
|
|
|
|
|
|
|
|
|
|
|
// 返回当前等待者的数量
|
|
|
|
|
|
GetNumberWaiting() int
|
|
|
|
|
|
|
|
|
|
|
|
// 参与者的数量
|
|
|
|
|
|
GetParties() int
|
|
|
|
|
|
|
|
|
|
|
|
// 循环栅栏是否处于中断状态
|
|
|
|
|
|
IsBroken() bool
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
循环栅栏的使用也很简单。循环栅栏的参与者只需调用Await等待,等所有的参与者都到达后,再执行下一步。当执行下一步的时候,循环栅栏的状态又恢复到初始的状态了,可以迎接下一轮同样多的参与者。
|
|
|
|
|
|
|
|
|
|
|
|
有一道非常经典的并发编程的题目,非常适合使用循环栅栏,下面我们来看一下。
|
|
|
|
|
|
|
|
|
|
|
|
## 并发趣题:一氧化二氢制造工厂
|
|
|
|
|
|
|
|
|
|
|
|
题目是这样的:
|
|
|
|
|
|
|
|
|
|
|
|
> 有一个名叫大自然的搬运工的工厂,生产一种叫做一氧化二氢的神秘液体。这种液体的分子是由一个氧原子和两个氢原子组成的,也就是水。
|
|
|
|
|
|
|
|
|
|
|
|
> 这个工厂有多条生产线,每条生产线负责生产氧原子或者是氢原子,每条生产线由一个goroutine负责。
|
|
|
|
|
|
|
|
|
|
|
|
> 这些生产线会通过一个栅栏,只有一个氧原子生产线和两个氢原子生产线都准备好,才能生成出一个水分子,否则所有的生产线都会处于等待状态。也就是说,一个水分子必须由三个不同的生产线提供原子,而且水分子是一个一个按照顺序产生的,每生产一个水分子,就会打印出HHO、HOH、OHH三种形式的其中一种。HHH、OOH、OHO、HOO、OOO都是不允许的。
|
|
|
|
|
|
|
|
|
|
|
|
> 生产线中氢原子的生产线为2N条,氧原子的生产线为N条。
|
|
|
|
|
|
|
|
|
|
|
|
你可以先想一下,我们怎么来实现呢?
|
|
|
|
|
|
|
|
|
|
|
|
首先,我们来定义一个H2O辅助数据类型,它包含两个信号量的字段和一个循环栅栏。
|
|
|
|
|
|
|
|
|
|
|
|
1. semaH信号量:控制氢原子。一个水分子需要两个氢原子,所以,氢原子的空槽数资源数设置为2。
|
|
|
|
|
|
2. semaO信号量:控制氧原子。一个水分子需要一个氧原子,所以资源数的空槽数设置为1。
|
|
|
|
|
|
3. 循环栅栏:等待两个氢原子和一个氧原子填补空槽,直到任务完成。
|
|
|
|
|
|
|
|
|
|
|
|
我们来看下具体的代码:
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
package water
|
|
|
|
|
|
import (
|
|
|
|
|
|
"context"
|
|
|
|
|
|
"github.com/marusama/cyclicbarrier"
|
|
|
|
|
|
"golang.org/x/sync/semaphore"
|
|
|
|
|
|
)
|
|
|
|
|
|
// 定义水分子合成的辅助数据结构
|
|
|
|
|
|
type H2O struct {
|
|
|
|
|
|
semaH *semaphore.Weighted // 氢原子的信号量
|
|
|
|
|
|
semaO *semaphore.Weighted // 氧原子的信号量
|
|
|
|
|
|
b cyclicbarrier.CyclicBarrier // 循环栅栏,用来控制合成
|
|
|
|
|
|
}
|
|
|
|
|
|
func New() *H2O {
|
|
|
|
|
|
return &H2O{
|
|
|
|
|
|
semaH: semaphore.NewWeighted(2), //氢原子需要两个
|
|
|
|
|
|
semaO: semaphore.NewWeighted(1), // 氧原子需要一个
|
|
|
|
|
|
b: cyclicbarrier.New(3), // 需要三个原子才能合成
|
|
|
|
|
|
}
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
接下来,我们看看各条流水线的处理情况。
|
|
|
|
|
|
|
|
|
|
|
|
流水线分为氢原子处理流水线和氧原子处理流水线,首先,我们先看一下氢原子的流水线:如果有可用的空槽,氢原子的流水线的处理方法是hydrogen,hydrogen方法就会占用一个空槽(h2o.semaH.Acquire),输出一个H字符,然后等待栅栏放行。等其它的goroutine填补了氢原子的另一个空槽和氧原子的空槽之后,程序才可以继续进行。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
func (h2o *H2O) hydrogen(releaseHydrogen func()) {
|
|
|
|
|
|
h2o.semaH.Acquire(context.Background(), 1)
|
|
|
|
|
|
|
|
|
|
|
|
releaseHydrogen() // 输出H
|
|
|
|
|
|
h2o.b.Await(context.Background()) //等待栅栏放行
|
|
|
|
|
|
h2o.semaH.Release(1) // 释放氢原子空槽
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
然后是氧原子的流水线。氧原子的流水线处理方法是oxygen, oxygen方法是等待氧原子的空槽,然后输出一个O,就等待栅栏放行。放行后,释放氧原子空槽位。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
func (h2o *H2O) oxygen(releaseOxygen func()) {
|
|
|
|
|
|
h2o.semaO.Acquire(context.Background(), 1)
|
|
|
|
|
|
|
|
|
|
|
|
releaseOxygen() // 输出O
|
|
|
|
|
|
h2o.b.Await(context.Background()) //等待栅栏放行
|
|
|
|
|
|
h2o.semaO.Release(1) // 释放氢原子空槽
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
在栅栏放行之前,只有两个氢原子的空槽位和一个氧原子的空槽位。只有等栅栏放行之后,这些空槽位才会被释放。栅栏放行,就意味着一个水分子组成成功。
|
|
|
|
|
|
|
|
|
|
|
|
这个算法是不是正确呢?我们来编写一个单元测试检测一下。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
package water
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
import (
|
|
|
|
|
|
"math/rand"
|
|
|
|
|
|
"sort"
|
|
|
|
|
|
"sync"
|
|
|
|
|
|
"testing"
|
|
|
|
|
|
"time"
|
|
|
|
|
|
)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
func TestWaterFactory(t *testing.T) {
|
|
|
|
|
|
//用来存放水分子结果的channel
|
|
|
|
|
|
var ch chan string
|
|
|
|
|
|
releaseHydrogen := func() {
|
|
|
|
|
|
ch <- "H"
|
|
|
|
|
|
}
|
|
|
|
|
|
releaseOxygen := func() {
|
|
|
|
|
|
ch <- "O"
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
// 300个原子,300个goroutine,每个goroutine并发的产生一个原子
|
|
|
|
|
|
var N = 100
|
|
|
|
|
|
ch = make(chan string, N*3)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
h2o := New()
|
|
|
|
|
|
|
|
|
|
|
|
// 用来等待所有的goroutine完成
|
|
|
|
|
|
var wg sync.WaitGroup
|
|
|
|
|
|
wg.Add(N * 3)
|
|
|
|
|
|
|
|
|
|
|
|
// 200个氢原子goroutine
|
|
|
|
|
|
for i := 0; i < 2*N; i++ {
|
|
|
|
|
|
go func() {
|
|
|
|
|
|
time.Sleep(time.Duration(rand.Intn(100)) * time.Millisecond)
|
|
|
|
|
|
h2o.hydrogen(releaseHydrogen)
|
|
|
|
|
|
wg.Done()
|
|
|
|
|
|
}()
|
|
|
|
|
|
}
|
|
|
|
|
|
// 100个氧原子goroutine
|
|
|
|
|
|
for i := 0; i < N; i++ {
|
|
|
|
|
|
go func() {
|
|
|
|
|
|
time.Sleep(time.Duration(rand.Intn(100)) * time.Millisecond)
|
|
|
|
|
|
h2o.oxygen(releaseOxygen)
|
|
|
|
|
|
wg.Done()
|
|
|
|
|
|
}()
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
//等待所有的goroutine执行完
|
|
|
|
|
|
wg.Wait()
|
|
|
|
|
|
|
|
|
|
|
|
// 结果中肯定是300个原子
|
|
|
|
|
|
if len(ch) != N*3 {
|
|
|
|
|
|
t.Fatalf("expect %d atom but got %d", N*3, len(ch))
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
// 每三个原子一组,分别进行检查。要求这一组原子中必须包含两个氢原子和一个氧原子,这样才能正确组成一个水分子。
|
|
|
|
|
|
var s = make([]string, 3)
|
|
|
|
|
|
for i := 0; i < N; i++ {
|
|
|
|
|
|
s[0] = <-ch
|
|
|
|
|
|
s[1] = <-ch
|
|
|
|
|
|
s[2] = <-ch
|
|
|
|
|
|
sort.Strings(s)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
water := s[0] + s[1] + s[2]
|
|
|
|
|
|
if water != "HHO" {
|
|
|
|
|
|
t.Fatalf("expect a water molecule but got %s", water)
|
|
|
|
|
|
}
|
|
|
|
|
|
}
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
# 总结
|
|
|
|
|
|
|
|
|
|
|
|
每一个并发原语都有它存在的道理,也都有它应用的场景。
|
|
|
|
|
|
|
|
|
|
|
|
如果你没有学习CyclicBarrier,你可能只会想到,用WaitGroup来实现这个水分子制造工厂的例子。
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
type H2O struct {
|
|
|
|
|
|
semaH *semaphore.Weighted
|
|
|
|
|
|
semaO *semaphore.Weighted
|
|
|
|
|
|
wg sync.WaitGroup //将循环栅栏替换成WaitGroup
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
func New() *H2O {
|
|
|
|
|
|
var wg sync.WaitGroup
|
|
|
|
|
|
wg.Add(3)
|
|
|
|
|
|
|
|
|
|
|
|
return &H2O{
|
|
|
|
|
|
semaH: semaphore.NewWeighted(2),
|
|
|
|
|
|
semaO: semaphore.NewWeighted(1),
|
|
|
|
|
|
wg: wg,
|
|
|
|
|
|
}
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
func (h2o *H2O) hydrogen(releaseHydrogen func()) {
|
|
|
|
|
|
h2o.semaH.Acquire(context.Background(), 1)
|
|
|
|
|
|
releaseHydrogen()
|
|
|
|
|
|
|
|
|
|
|
|
// 标记自己已达到,等待其它goroutine到达
|
|
|
|
|
|
h2o.wg.Done()
|
|
|
|
|
|
h2o.wg.Wait()
|
|
|
|
|
|
|
|
|
|
|
|
h2o.semaH.Release(1)
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
func (h2o *H2O) oxygen(releaseOxygen func()) {
|
|
|
|
|
|
h2o.semaO.Acquire(context.Background(), 1)
|
|
|
|
|
|
releaseOxygen()
|
|
|
|
|
|
|
|
|
|
|
|
// 标记自己已达到,等待其它goroutine到达
|
|
|
|
|
|
h2o.wg.Done()
|
|
|
|
|
|
h2o.wg.Wait()
|
|
|
|
|
|
//都到达后重置wg
|
|
|
|
|
|
h2o.wg.Add(3)
|
|
|
|
|
|
|
|
|
|
|
|
h2o.semaO.Release(1)
|
|
|
|
|
|
}
|
|
|
|
|
|
|
|
|
|
|
|
```
|
|
|
|
|
|
|
|
|
|
|
|
你一看代码就知道了,使用WaitGroup非常复杂,而且,重用和Done方法的调用有并发的问题,程序可能panic,远远没有使用循环栅栏更加简单直接。
|
|
|
|
|
|
|
|
|
|
|
|
所以,我建议你多了解一些并发原语,甚至是从其它编程语言、操作系统中学习更多的并发原语,这样可以让你的知识库更加丰富,在面对并发场景的时候,你也能更加游刃有余。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
# 思考题
|
|
|
|
|
|
|
|
|
|
|
|
如果大自然的搬运工工厂生产的液体是双氧水(双氧水分子是两个氢原子和两个氧原子),你又该怎么实现呢?
|
|
|
|
|
|
|
|
|
|
|
|
欢迎在留言区写下你的思考和答案,我们一起交流讨论。如果你觉得有所收获,也欢迎你把今天的内容分享给你的朋友或同事。
|
|
|
|
|
|
|